
Szacowanie czasu przetwarzania klatek przez procesor i procesor graficzny (czasu renderowania klatek) jest niezbędne do zrozumienia wydajności aplikacji i znalezienia wąskich gardeł. Gdy profilujesz aplikację za pomocą AGI, Profiler systemowy udostępnia dane śledzenia, których możesz użyć do oszacowania czasu trwania klatek.
Czasy pracy procesora
W AGI możesz wyświetlić całkowity i aktywny czas klatek procesora na ścieżce procesora w profilu systemu.
Łączny czas pracy procesora
Aby zmierzyć łączny czas pracy procesora, wybierz zakres czasu, który obejmuje czas między kolejnymi zdarzeniami przesyłania klatek. Zdarzenia przesyłania klatek to eglSwapBuffers (w przypadku OpenGL) i vkQueuePresentKHR (w przypadku Vulkan).
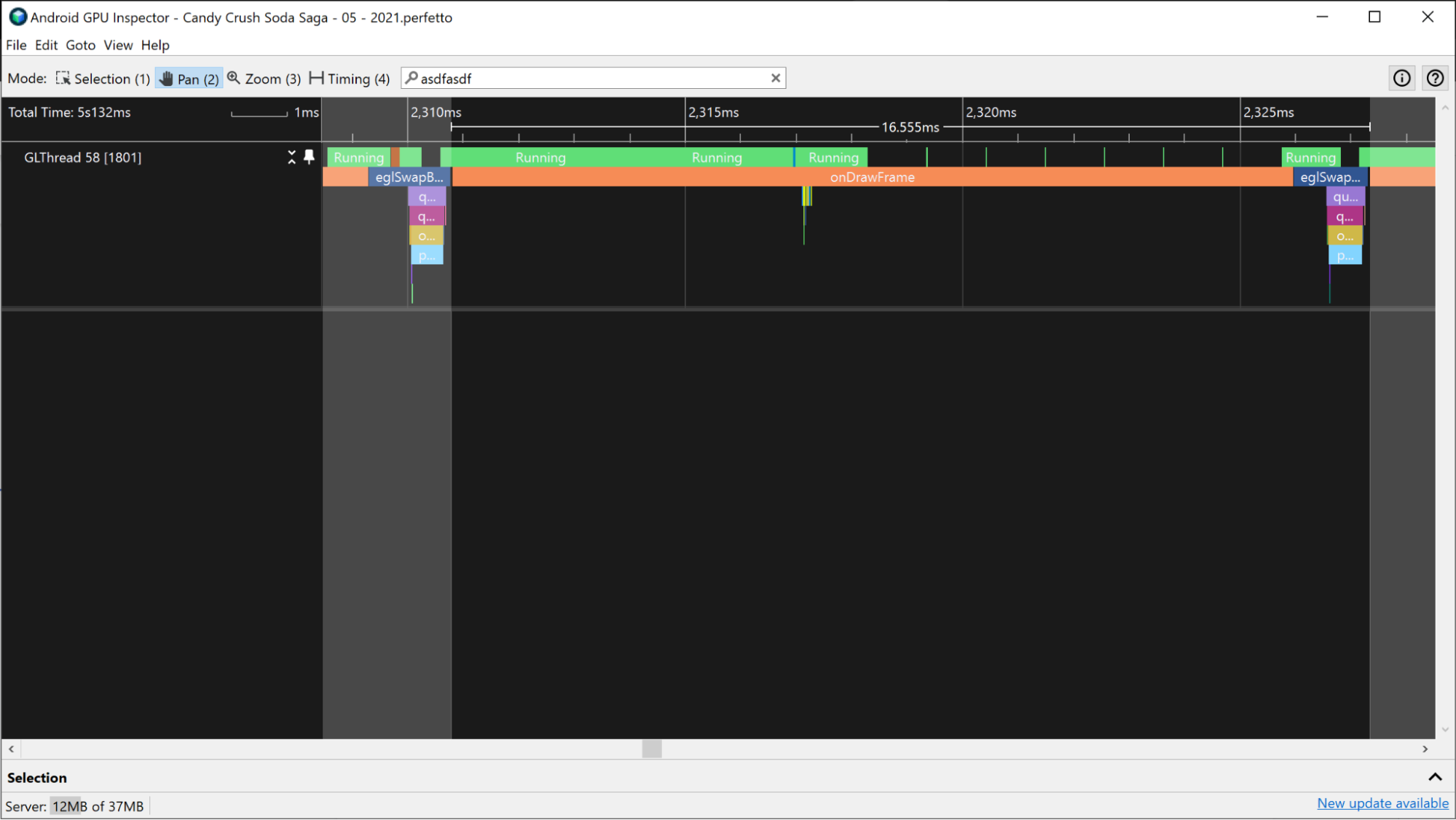
eglSwapBuffer.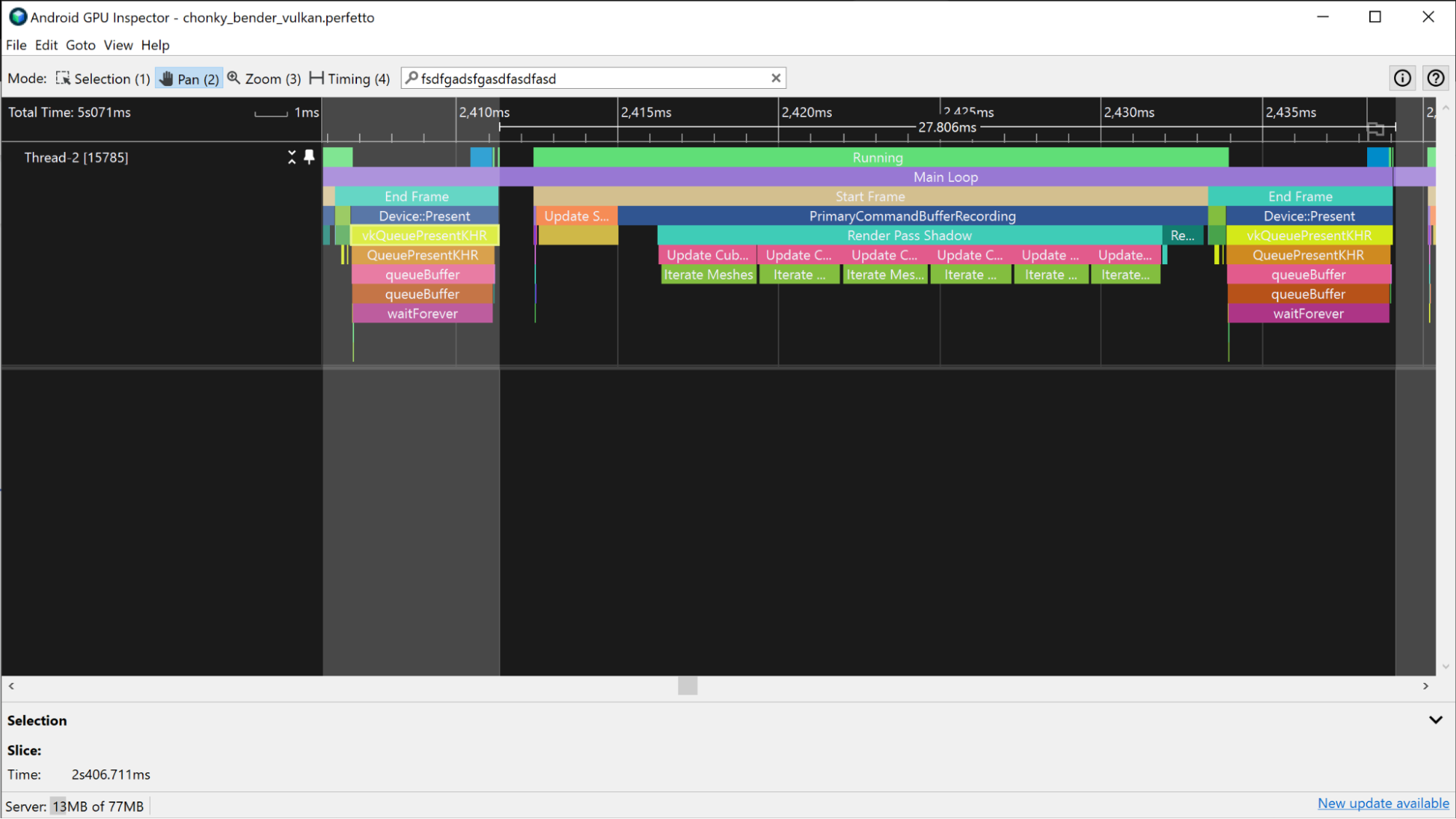
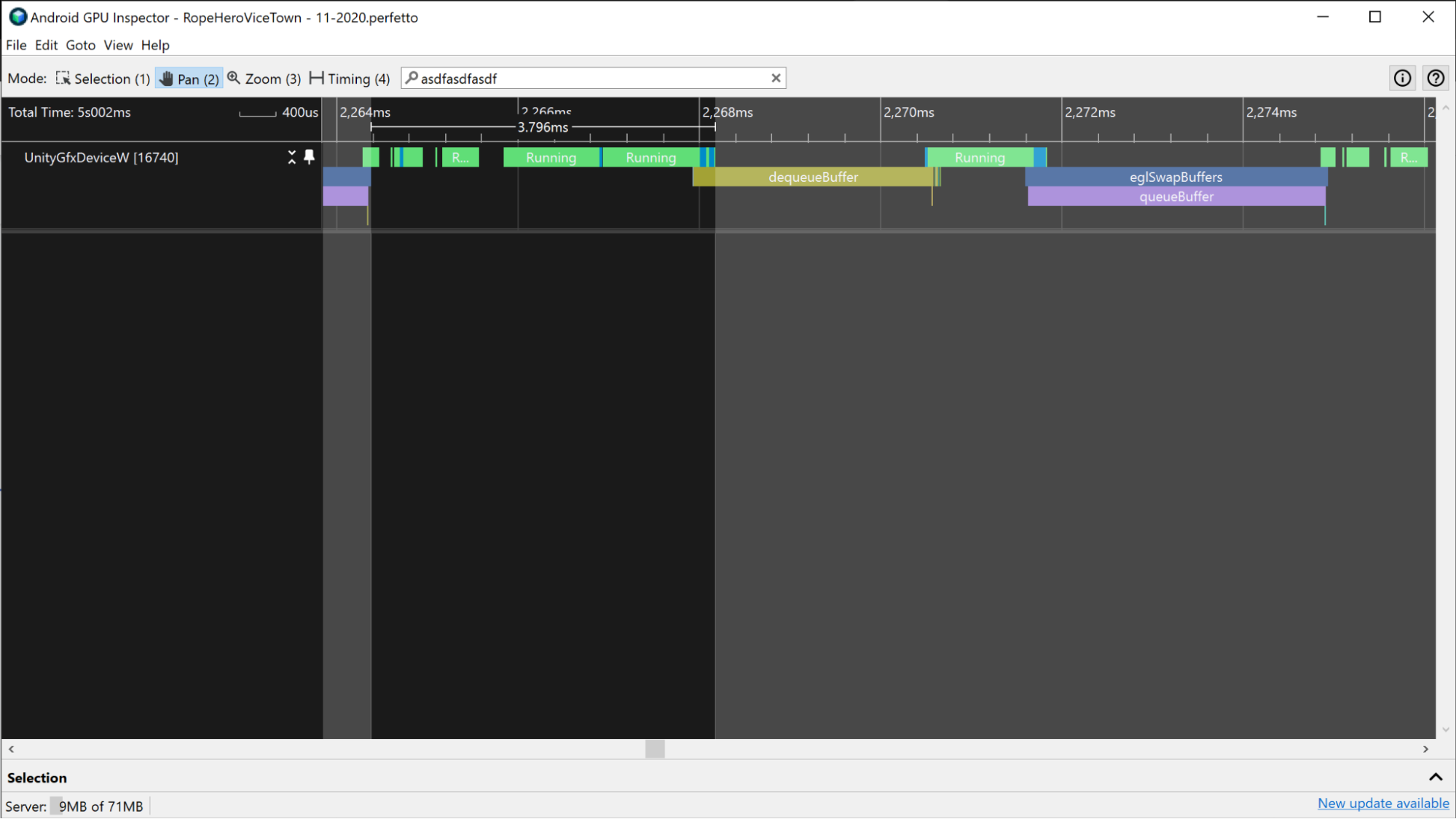
vkQueuePresentKHR.Ten pomiar jest szacunkową wartością całkowitego czasu procesora,ale nie musi odzwierciedlać aktywnego czasu procesora. Na przykład w aplikacjach, w których działanie jest ograniczone przez GPU, procesor może czekać, aż GPU zakończy pracę, zanim prześle nową klatkę. Dzieje się tak często, gdy zdarzenie dequeueBuffer, eglSwapBuffer (w przypadku OpenGL) lub vkQueuePresent (w przypadku Vulkan) zajmuje dużą część czasu procesora.
Czas oczekiwania jest uwzględniony w łącznym czasie pracy procesora, ale nie w aktywnym czasie pracy procesora.
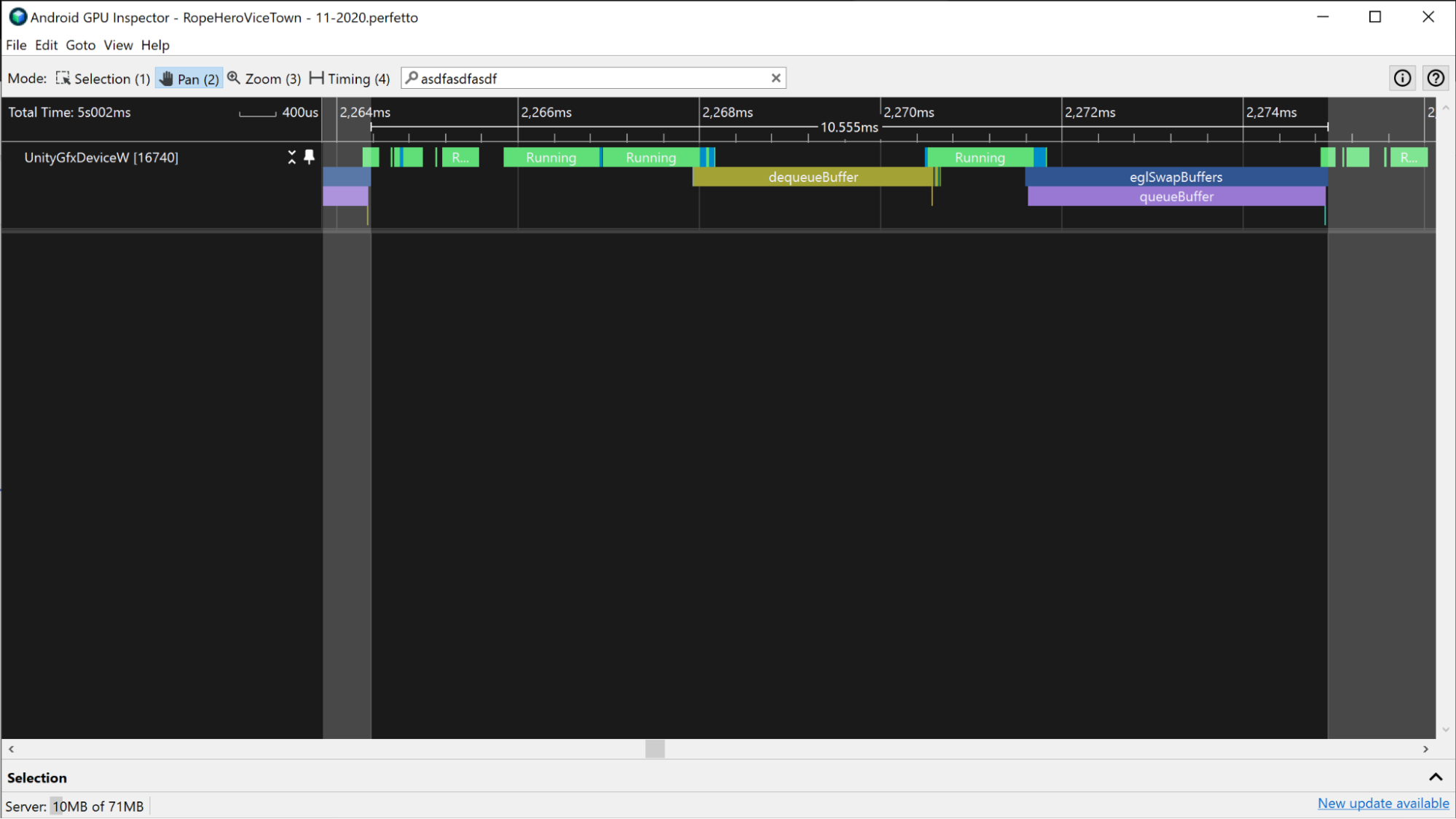
dequeueBuffer i eglSwapBuffer.
Aktywny czas pracy procesora
Aktywny czas procesora określa, kiedy procesor wykonuje kod aplikacji, nie będąc w stanie bezczynności.
Aby zmierzyć aktywny czas procesora, wyświetl wycinki Uruchomione tuż nad zdarzeniami procesora. Policz wszystkie części śladu między dwoma zdarzeniami przesłania klatki, które są w stanie Uruchomiono. Pamiętaj, aby uwzględnić działające wątki.
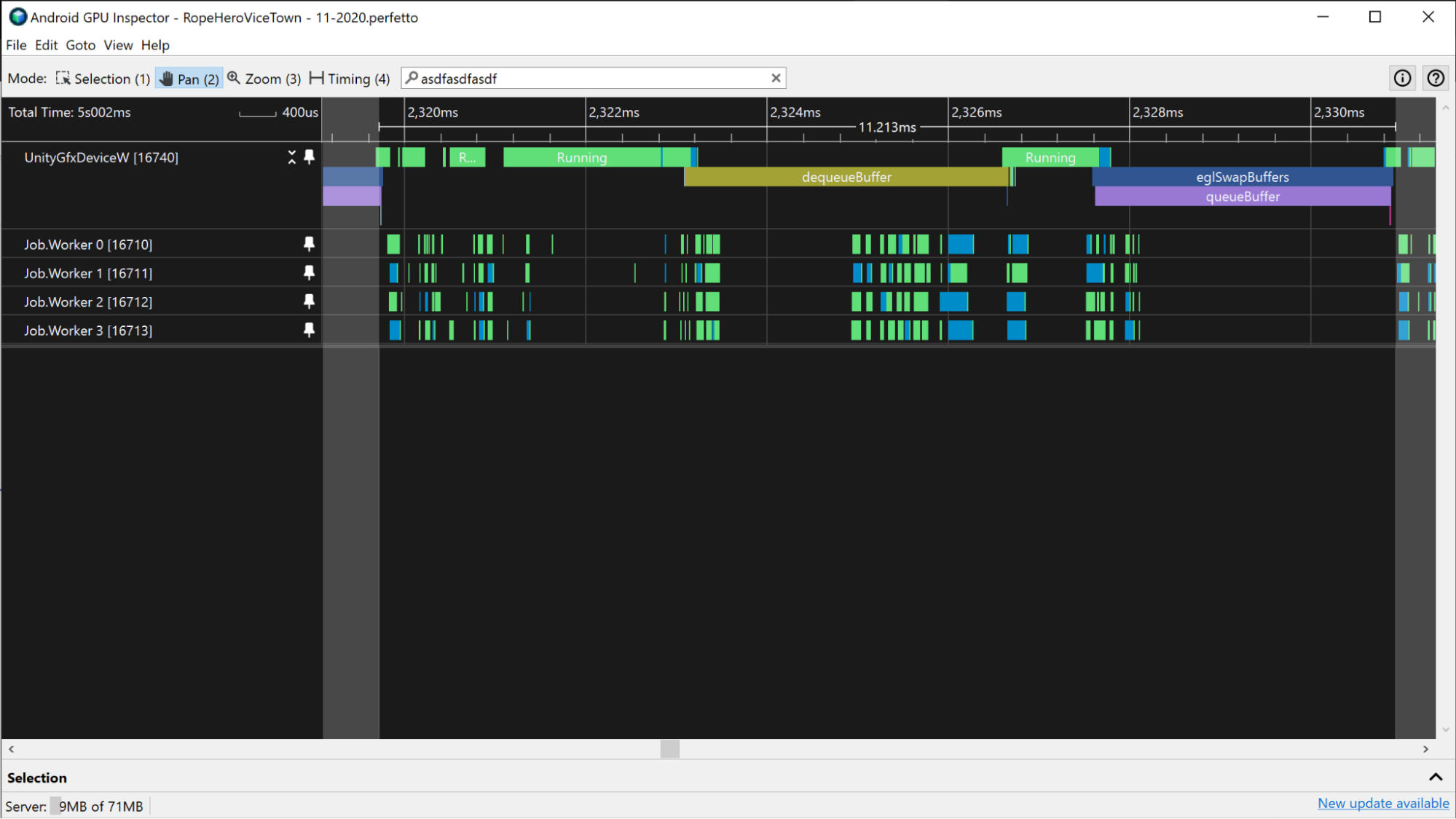
Innym sposobem pomiaru aktywnego czasu procesora jest wyświetlenie wycinków aplikacji na ścieżkach procesora. Te wycinki wskazują, kiedy procesor jest uruchomiony, i odpowiadają wycinkom Uruchomiony.
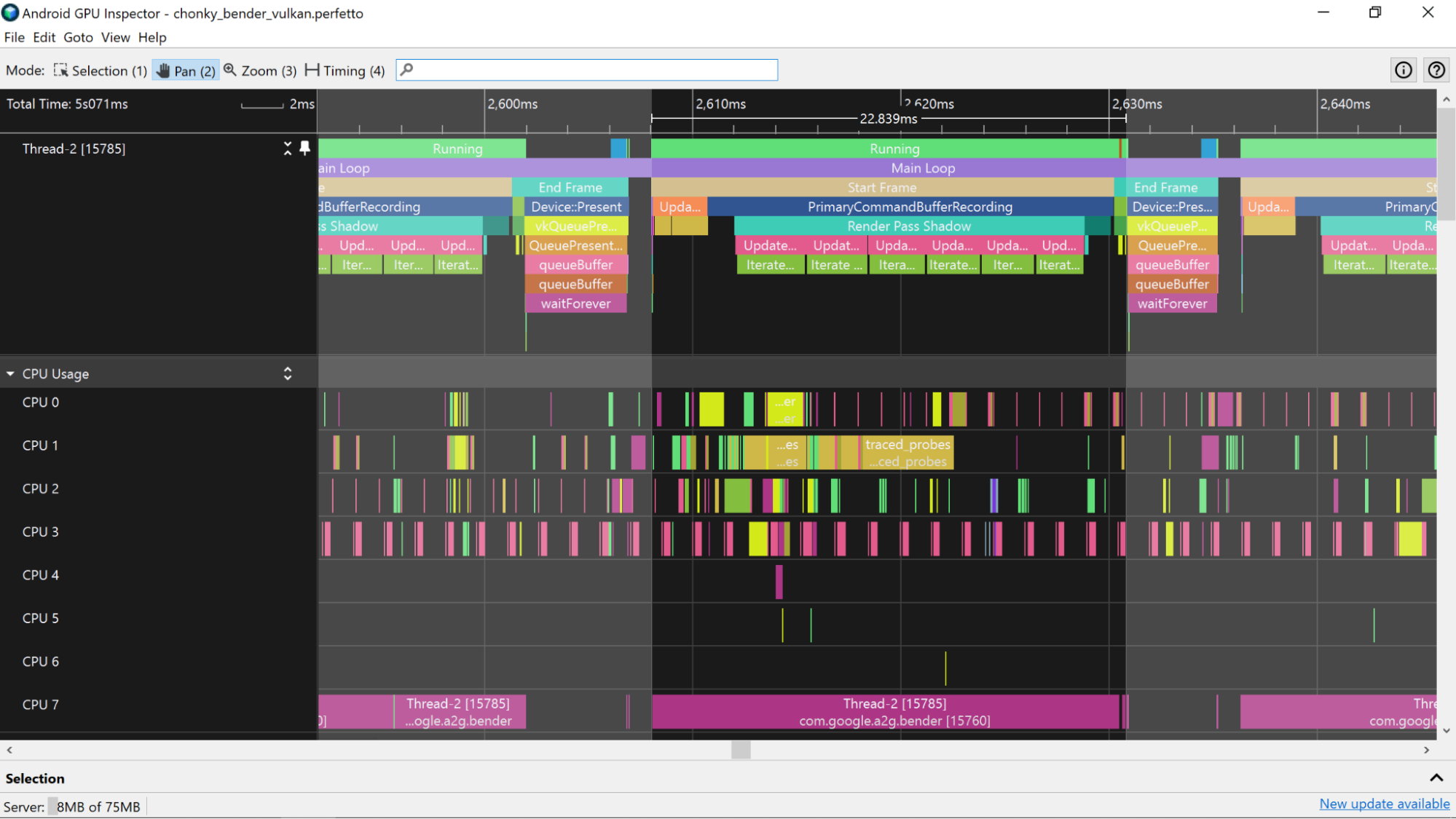
Aby ułatwić identyfikację wycinków aplikacji, możesz dodać do niej znaczniki ATrace. Będą one wyświetlane na ścieżce procesora w profilerze systemu.
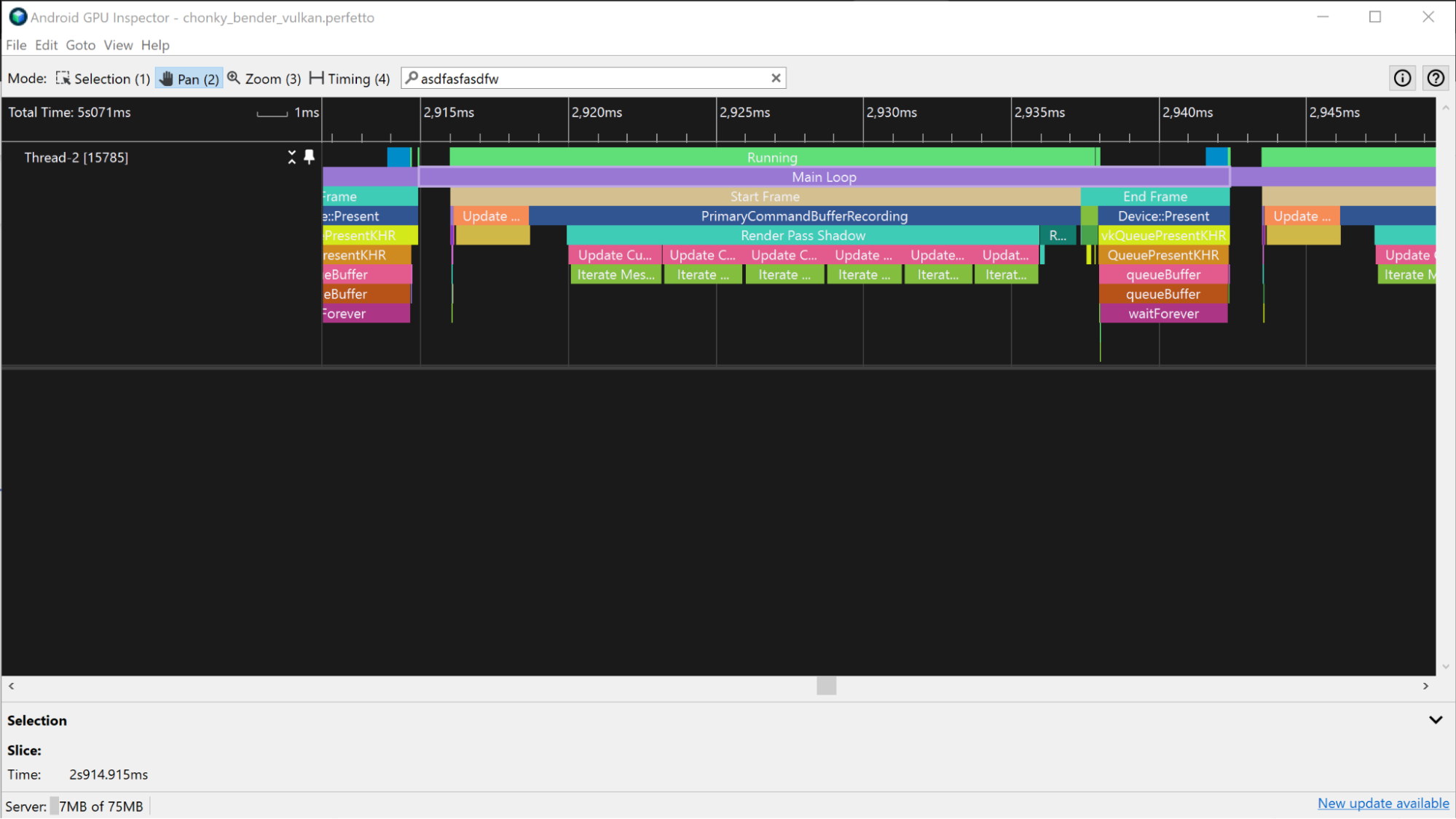
Szacowanie czasu renderowania klatek przez GPU
Aby oszacować czasy klatek GPU, możesz użyć wycinków GPU lub liczników GPU w Profilerze systemu. W przypadku korzystania z fragmentów GPU szacowanie jest dokładniejsze.
Partycje GPU
Jeśli Profiler systemowy ma dostępne informacje o wycinku GPU, możesz uzyskać bardzo dokładne informacje o czasie renderowania klatki przez GPU, mierząc łączny czas, jaki aplikacja poświęca na wykonywanie zadań związanych z jedną klatką.
Urządzenia Mali
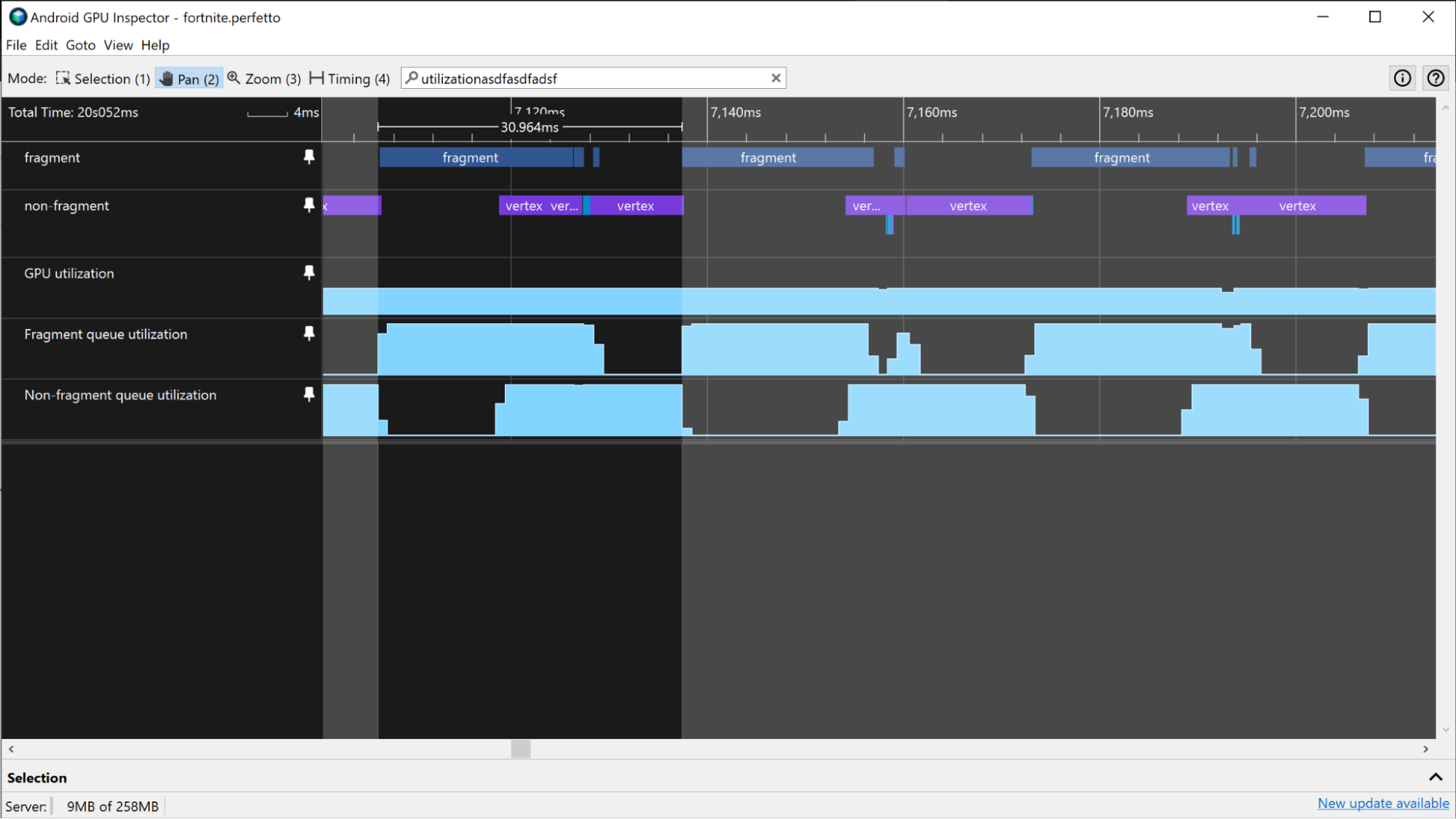
Na urządzeniach Mali wycinki GPU mają ścieżki fragmentu, niefragmentu i czasami dodatkową ścieżkę niefragmentu. W przypadku mniej złożonych klatek praca związana z fragmentami i niezwiązanymi z fragmentami jest wykonywana sekwencyjnie, więc odróżnienie pracy jednej klatki od pracy innej klatki można przeprowadzić, szukając przerw między aktywną pracą procesora graficznego.
Jeśli znasz zadania przesyłane do procesora graficznego, możesz zidentyfikować wzorzec przesłanych przebiegów renderowania, aby uzyskać informacje o tym, kiedy zaczyna się i kończy klatka.
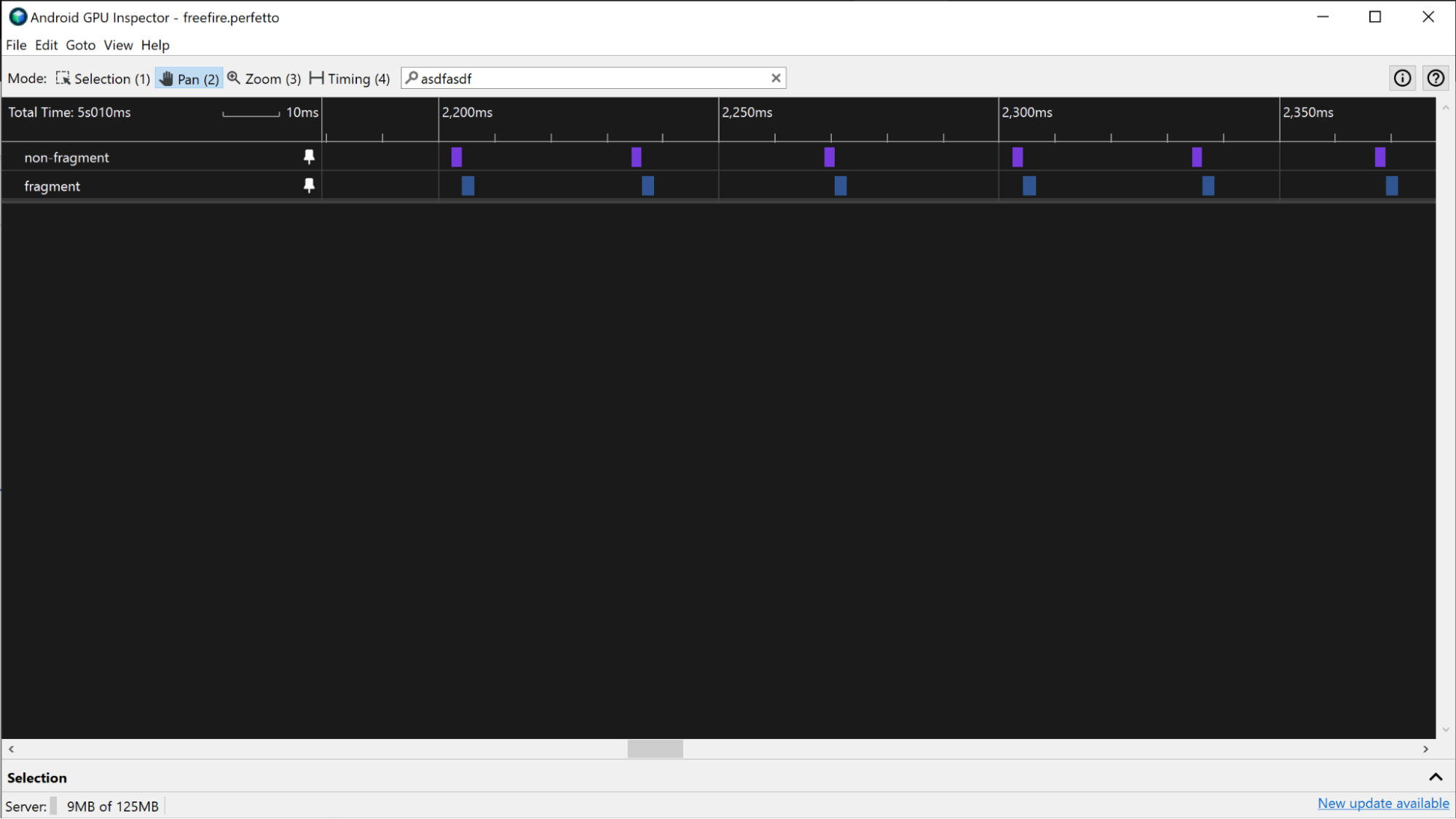
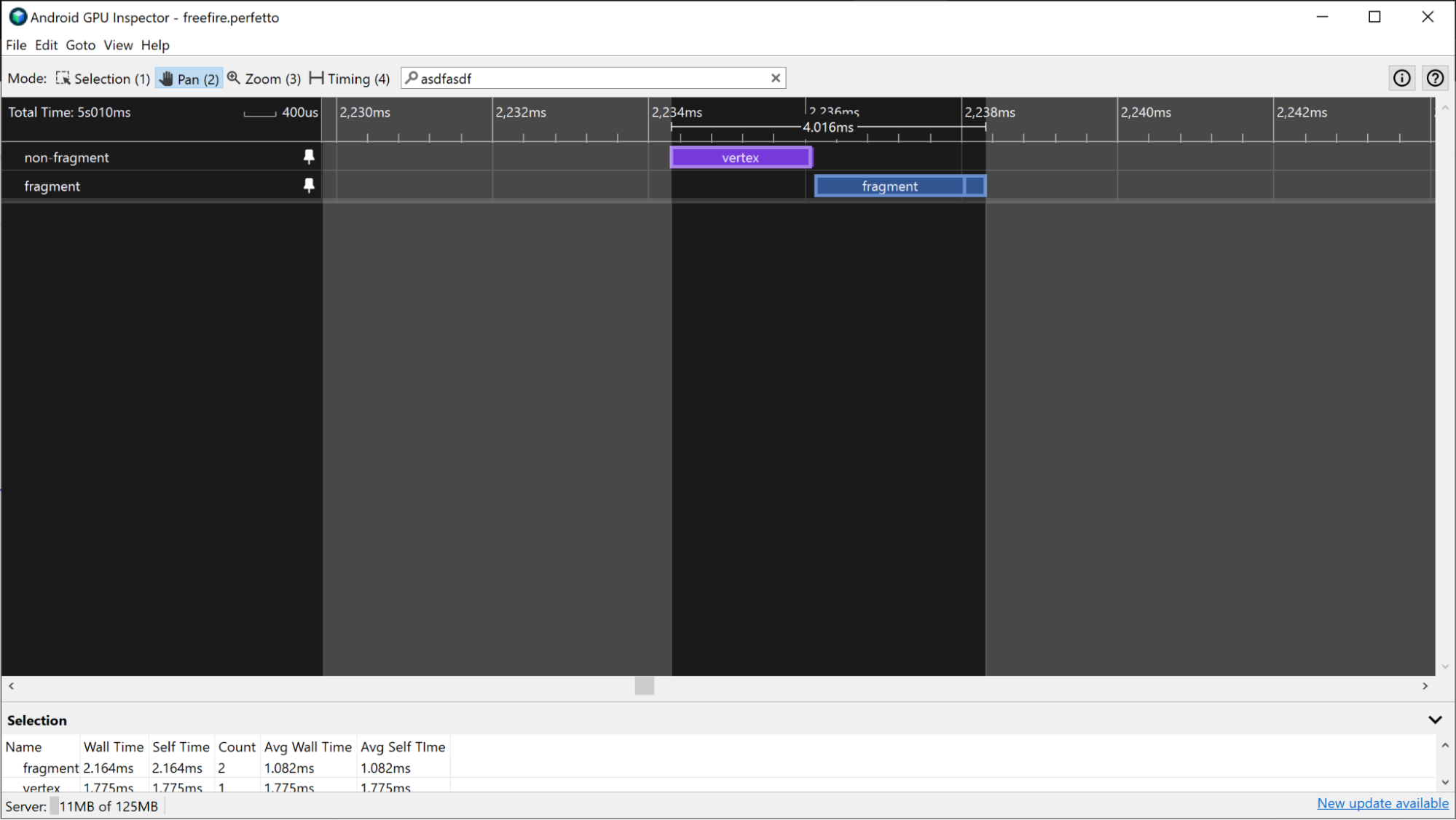
W przypadku aplikacji, które mają bardziej równoległy przepływ pracy GPU, możesz uzyskać czasy renderowania klatek przez GPU, wyszukując wszystkie klatki, które mają ten sam submissionID w panelu Selection dla każdego wycinka.
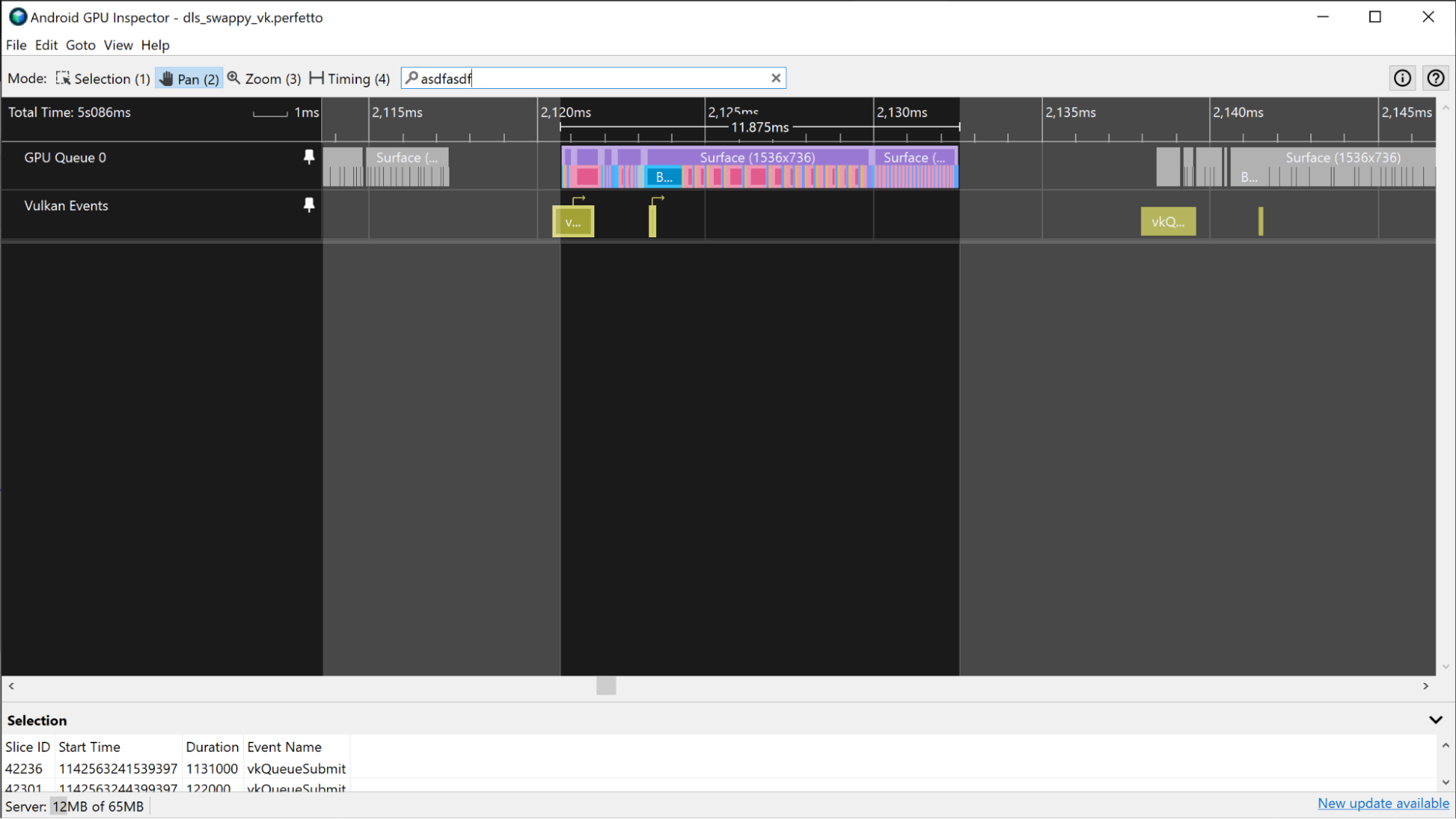
W przypadku aplikacji opartych na Vulkanie do tworzenia klatki można używać wielu przesłań. Śledź identyfikatory zgłoszeń za pomocą ścieżki Zdarzenia Vulkan, która zawiera wycinek dla każdego zgłoszenia. Wybranie wycinka przesyłania spowoduje wyróżnienie wszystkich wycinków aktywności GPU, które odpowiadają temu przesyłaniu.
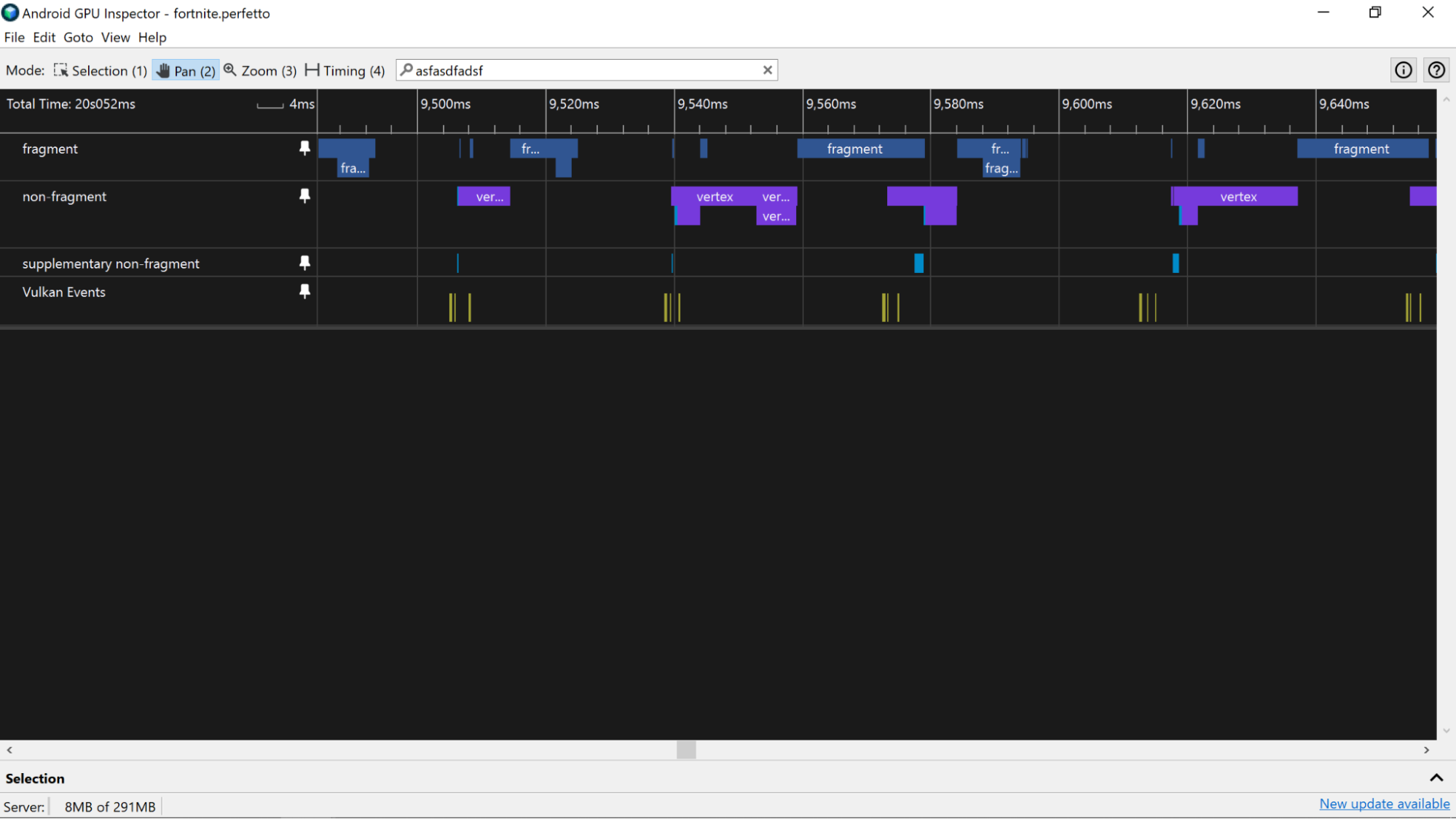
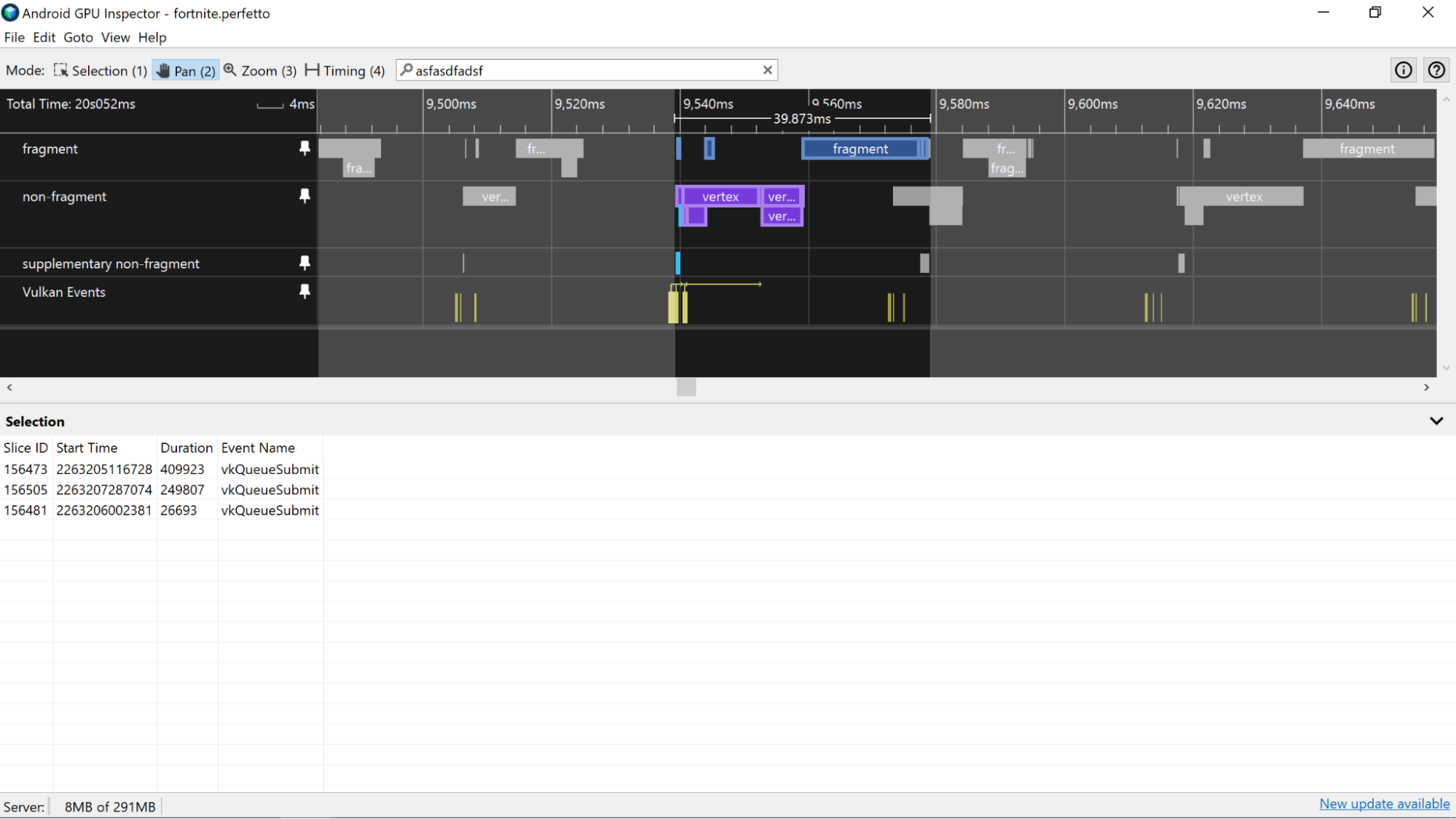
Urządzenia Adreno
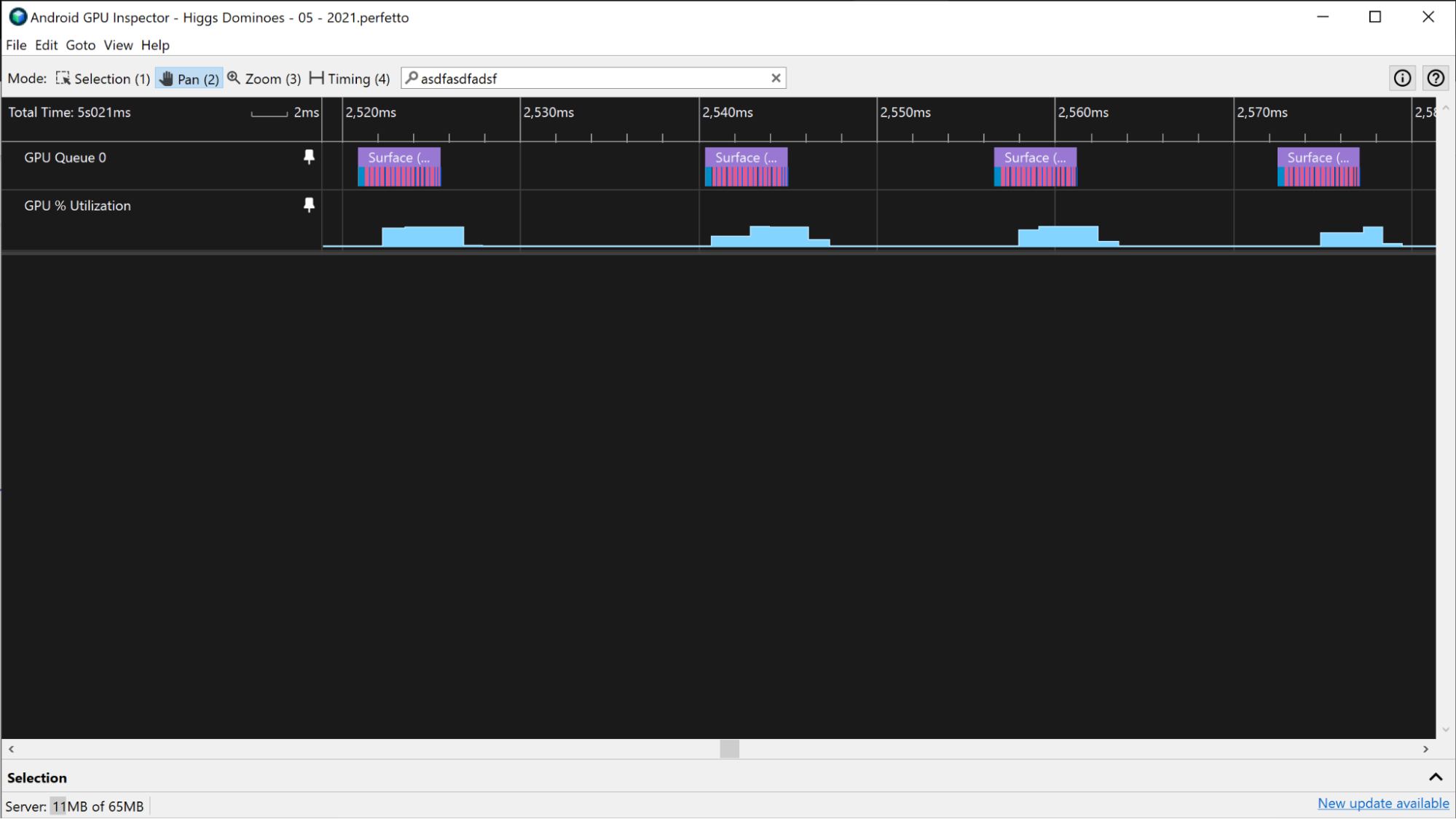
Na urządzeniach z procesorem Adreno wycinki GPU pojawiają się na ścieżce Kolejka GPU 0 i są zawsze reprezentowane sekwencyjnie. Możesz więc sprawdzić wszystkie wycinki reprezentujące przebiegi renderowania klatki i użyć ich do pomiaru czasu klatki GPU.
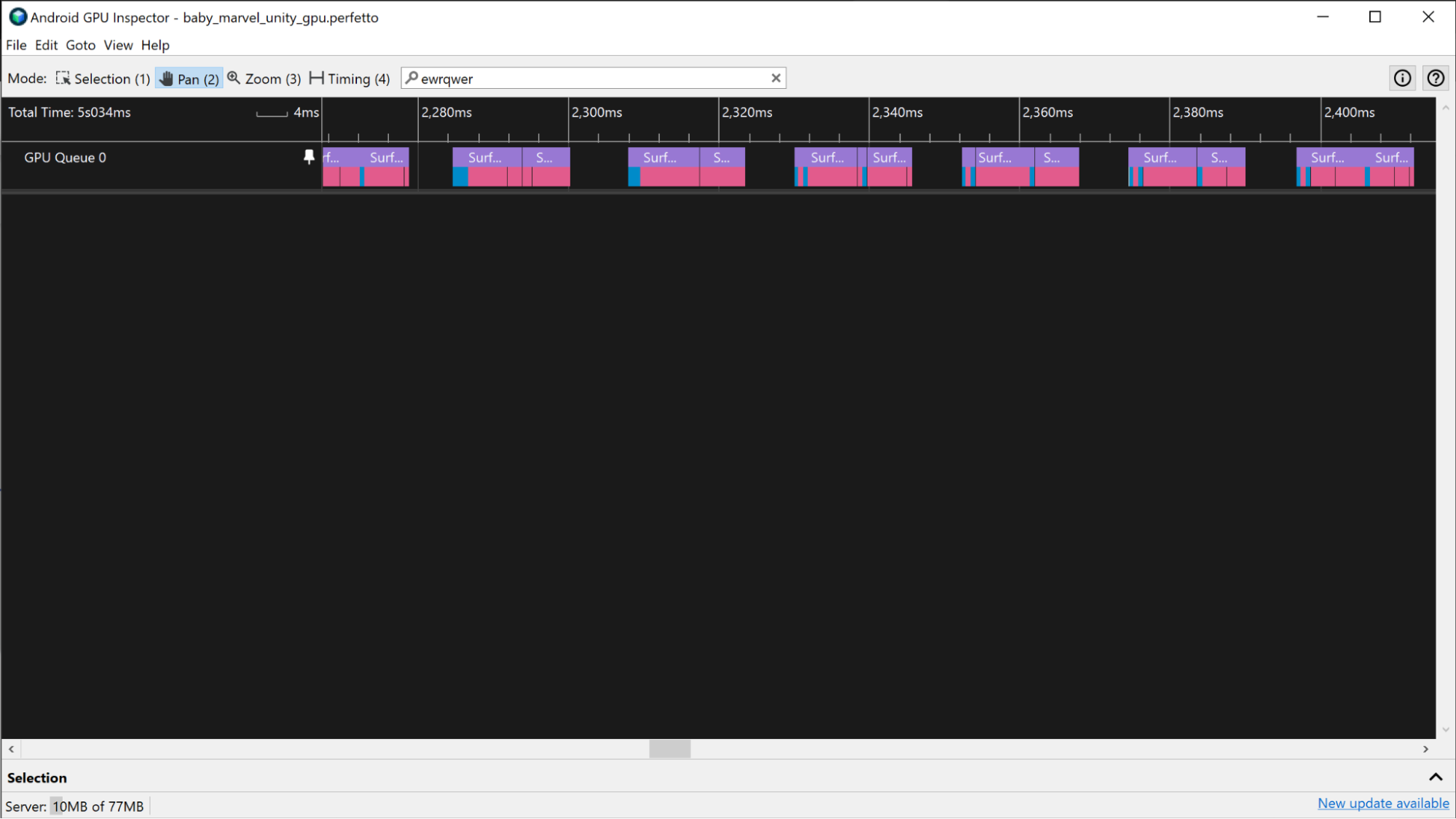
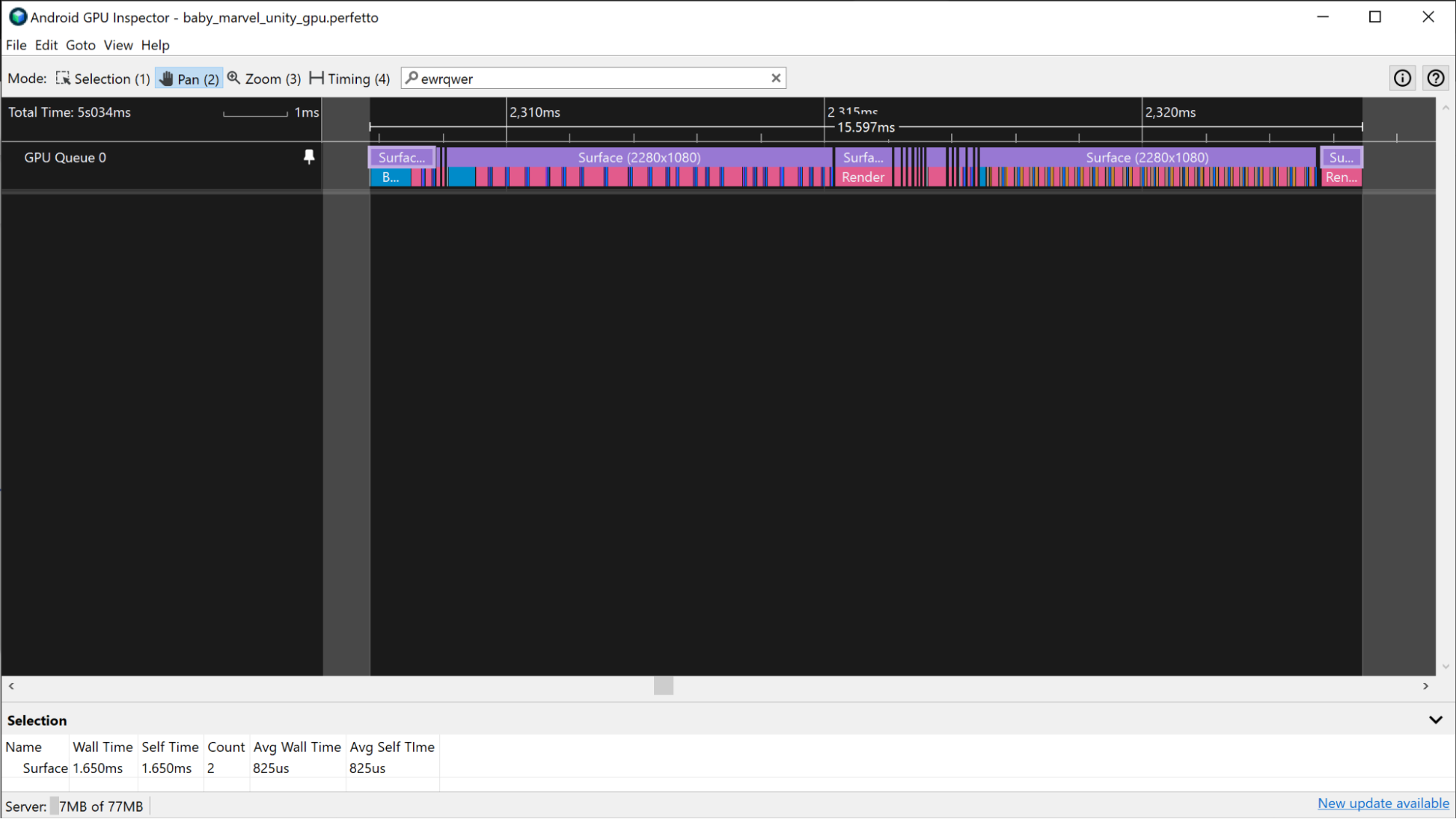
Podobnie jak w przypadku urządzenia Mali opisanego wcześniej: jeśli aplikacja korzysta z Vulkana, ścieżka Zdarzenia Vulkan zawiera informacje o pracy przesyłanej w celu wykonania klatki. Aby wyróżnić przebiegi renderowania, kliknij wycinki Vulkan Events powiązane z klatką.
W niektórych przypadkach granice klatek GPU są trudniejsze do odróżnienia, ponieważ aplikacja jest w dużym stopniu zależna od GPU. W takich przypadkach, jeśli znasz zadania przesyłane do procesora graficznego, możesz zidentyfikować wzorzec wykonywania przebiegów renderowania i na podstawie tych informacji określić granice klatek.
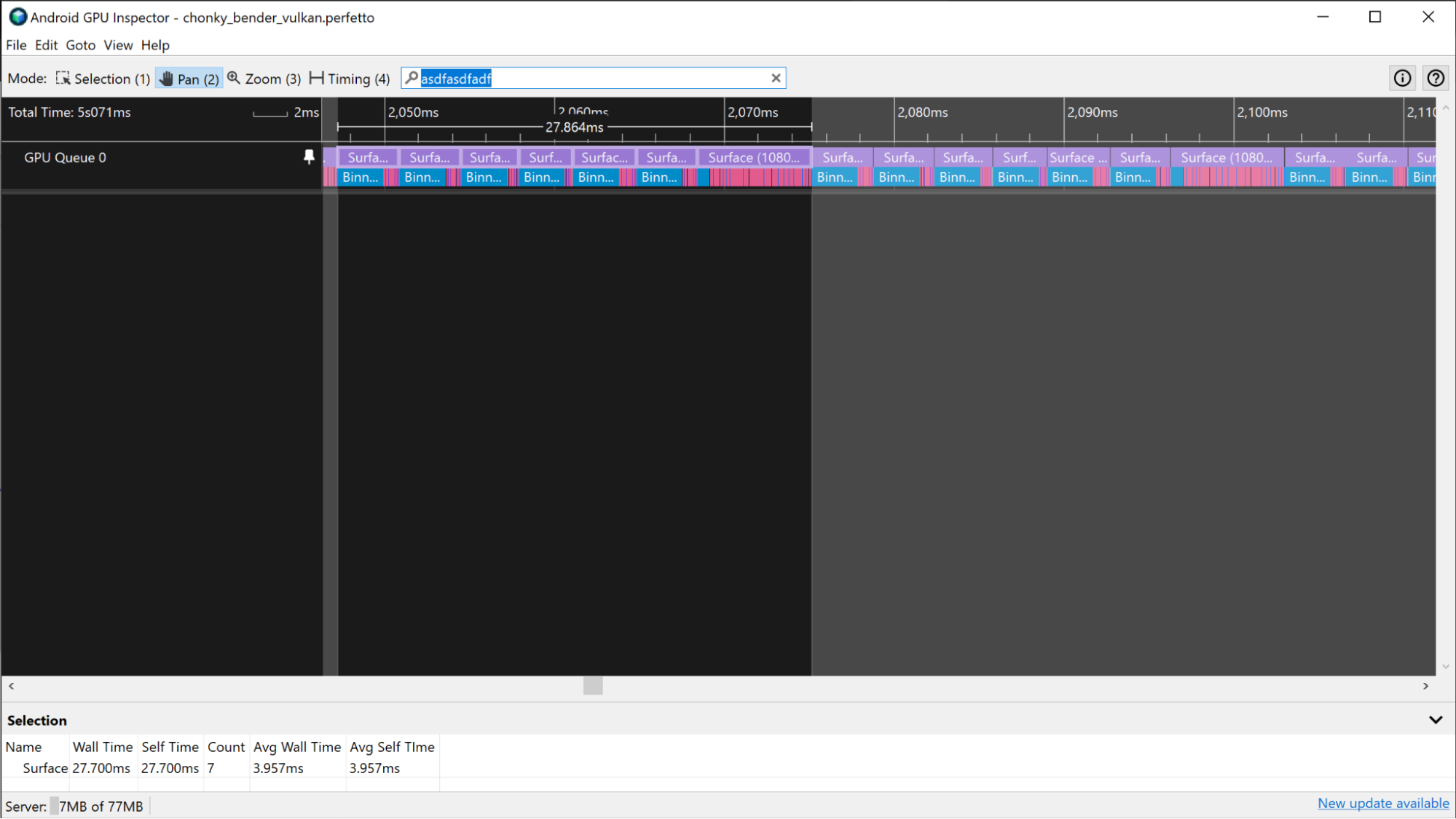
Liczniki GPU
Jeśli w śladzie nie ma informacji o wycinku GPU, możesz oszacować czas renderowania klatki GPU za pomocą ścieżek licznika GPU.
Urządzenia Mali
Na urządzeniach z układem Mali możesz użyć ścieżki Wykorzystanie GPU, aby oszacować czas renderowania klatki GPU w przypadku aplikacji, która nie wykorzystuje w dużym stopniu układu GPU. Gdy aplikacje nie wymagają dużej mocy GPU, występują w nich regularne okresy wysokiej i niskiej aktywności GPU zamiast ciągłej wysokiej aktywności. Aby oszacować czasy klatek GPU za pomocą ścieżki wykorzystania GPU, zmierz czas trwania okresów dużej aktywności na tej ścieżce.
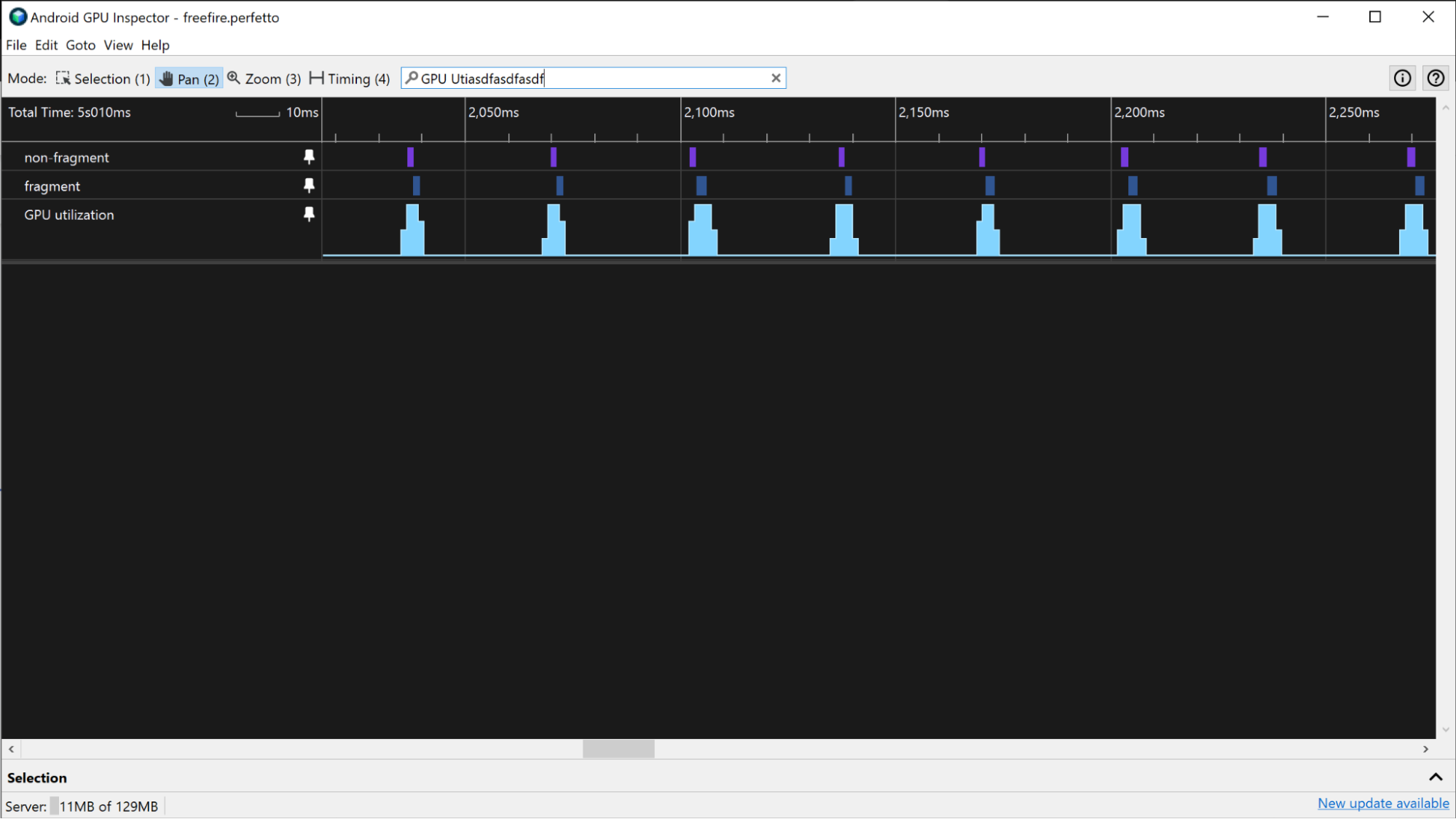
Jeśli aplikacja intensywnie korzysta z GPU, jego wykorzystanie może być stale bardzo wysokie. W takim przypadku możesz użyć ścieżek wykorzystanie kolejki fragmentów i wykorzystanie kolejki niefragmentowej, aby monitorować aktywność GPU i szacować czasy klatek GPU. Szukając wzorców w śladach fragmentów i niefragmentów, możesz uzyskać przybliżone oszacowanie granic ramki i użyć go do pomiaru czasu renderowania klatki GPU.
Urządzenia Adreno
Na urządzeniach Adreno, jeśli aplikacja nie obciąża GPU, możesz oszacować czas renderowania klatki przez GPU w taki sam sposób jak w przypadku urządzeń Mali w poprzedniej sekcji.
Jeśli aplikacja intensywnie korzysta z GPU, a odsetek wykorzystania GPU jest stale wysoki, możesz użyć ścieżek Instrukcje wierzchołków / sekundę i Instrukcje fragmentów / sekundę, aby oszacować czasy klatek GPU. Szukając wzorców w poziomach aktywności tych ścieżek, możesz zgrubnie oszacować, gdzie znajdują się granice klatki, i użyć tych informacji do pomiaru czasu renderowania klatki GPU.
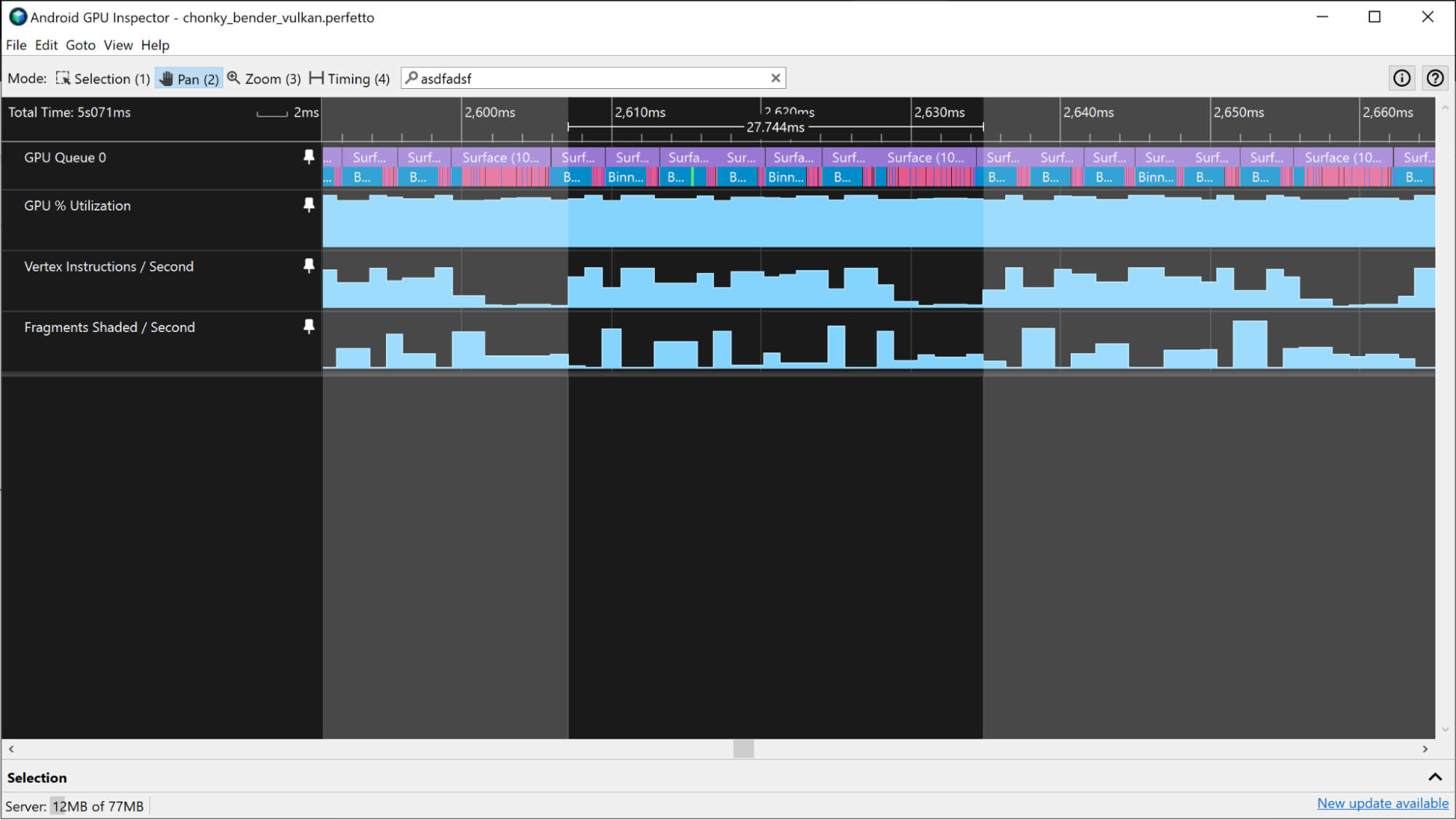
Inne ścieżki mogą zawierać podobne informacje:
- Wierzchołki cieniowane / sekunda
- Fragmenty zacienione / sekunda
- % wierzchołków cieniowania czasu
- % fragmentów cieniowania czasu