
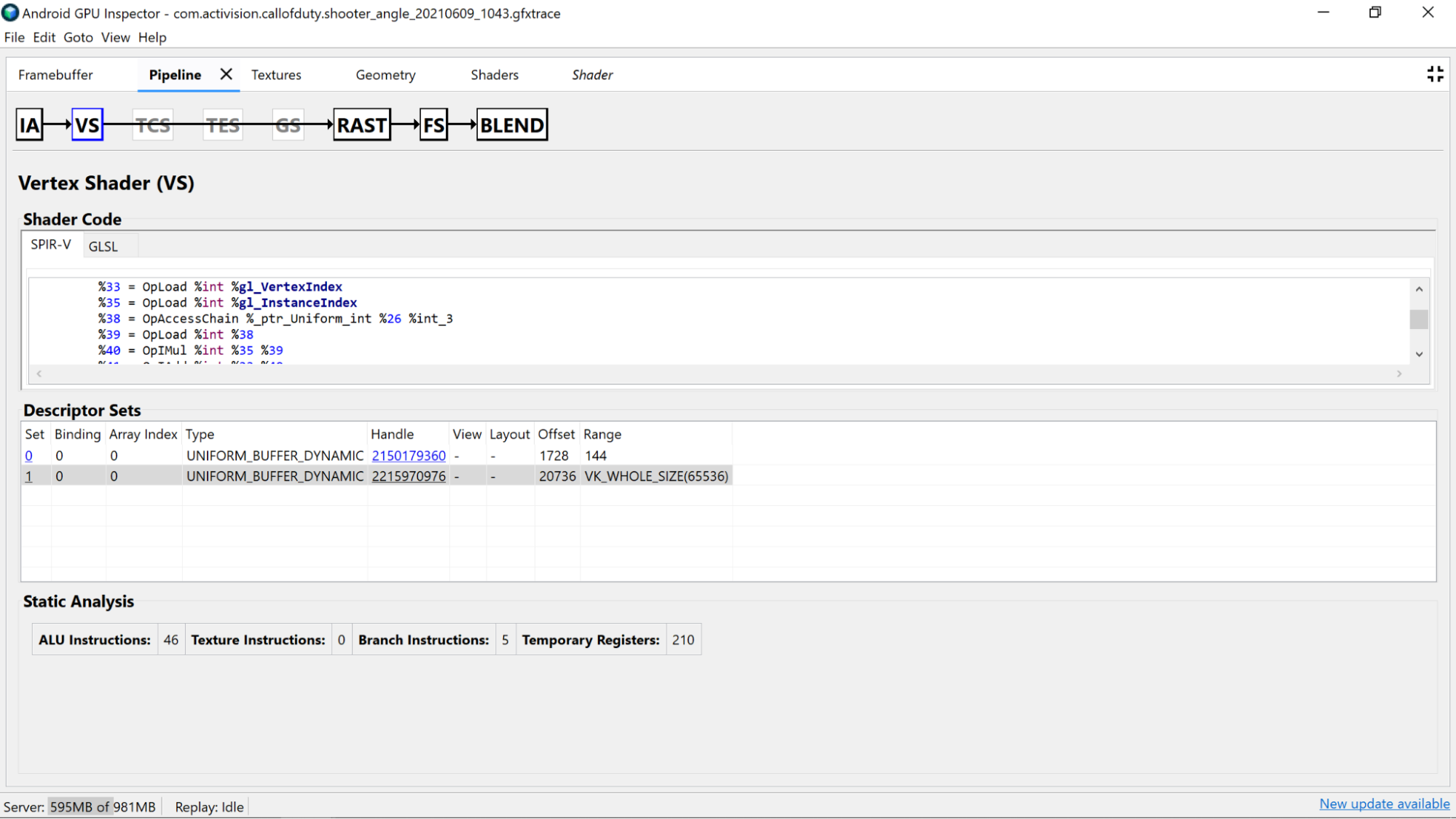
Mit AGI Frame Profiler können Sie Ihre Shader untersuchen, indem Sie einen Draw-Aufruf aus einem unserer Rendering-Passes auswählen und entweder den Bereich Vertex Shader oder Fragment Shader im Bereich Pipeline durchgehen.
Hier finden Sie nützliche Statistiken aus der statischen Analyse des Shader-Codes sowie die Standard Portable Intermediate Representation (SPIR-V)-Assembly, in die unser GLSL kompiliert wurde. Außerdem gibt es einen Tab, auf dem eine Darstellung des ursprünglichen GLSL zu sehen ist, das mit SPIR-V Cross dekompiliert wurde. Es enthält vom Compiler generierte Namen für Variablen, Funktionen und mehr und bietet zusätzlichen Kontext für das SPIR-V.
Statische Analyse
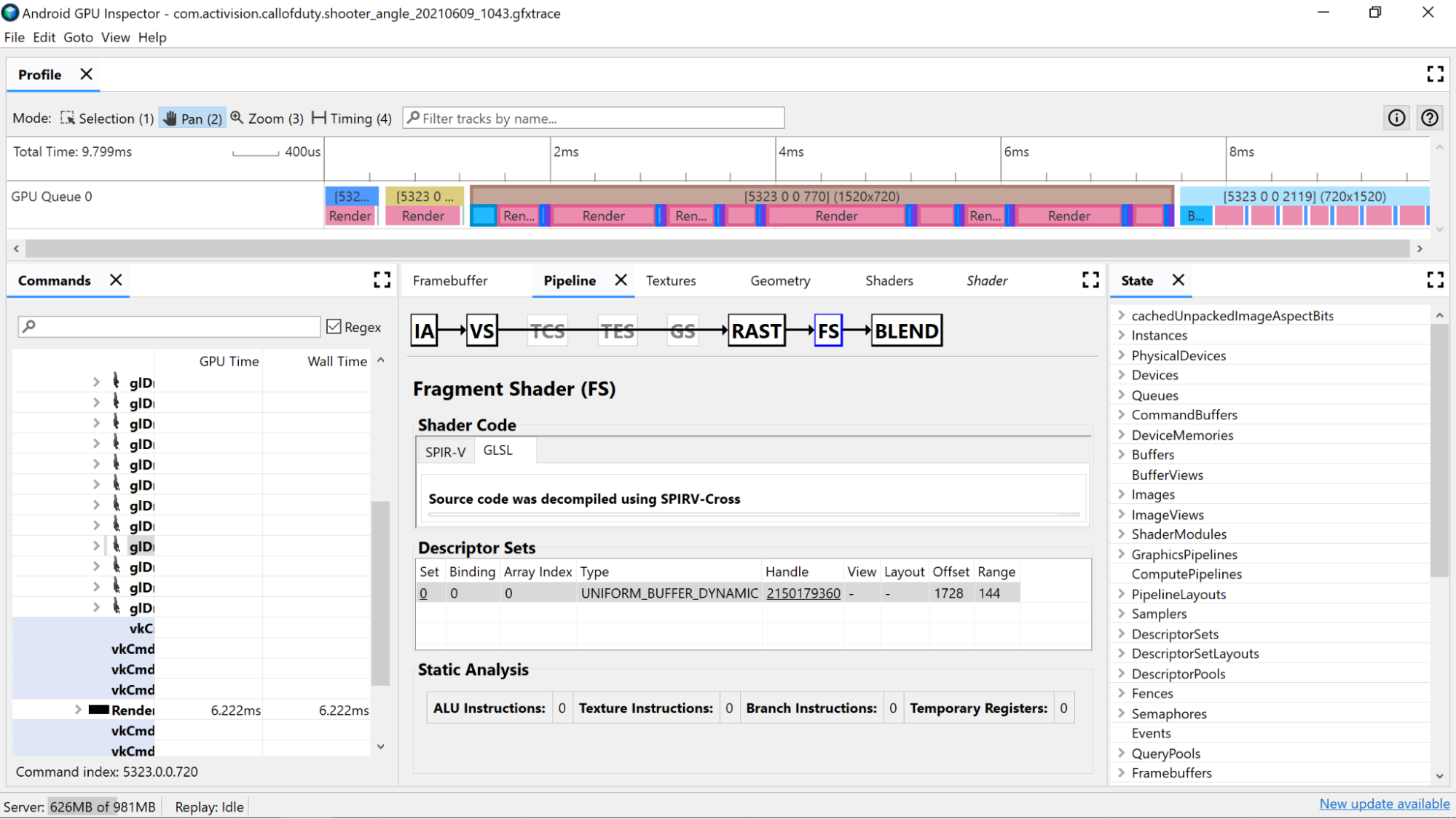
Mit Zählern für die statische Analyse können Sie Low-Level-Vorgänge im Shader ansehen.
ALU-Befehle: Diese Anzahl gibt an, wie viele ALU-Operationen (Additionen, Multiplikationen, Divisionen usw.) im Shader ausgeführt werden. Sie ist ein guter Indikator für die Komplexität des Shaders. Versuchen Sie, diesen Wert zu minimieren.
Wenn Sie allgemeine Berechnungen umgestalten oder Berechnungen im Shader vereinfachen, kann die Anzahl der erforderlichen Anweisungen reduziert werden.
Texture Instructions (Textur-Anweisungen): Diese Zahl gibt an, wie oft die Textur im Shader gesampelt wird.
- Das Sampling von Texturen kann je nach Art der Texturen, aus denen gesampelt wird, aufwendig sein. Wenn Sie den Shader-Code mit den gebundenen Texturen im Abschnitt Descriptor Sets (Deskriptorsätze) abgleichen, erhalten Sie weitere Informationen zu den verwendeten Texturtypen.
- Vermeiden Sie den zufälligen Zugriff beim Sampling von Texturen, da dieses Verhalten nicht ideal für das Zwischenspeichern von Texturen ist.
Branch Instructions (Verzweigungsanweisungen): Diese Zahl gibt die Anzahl der Verzweigungsvorgänge im Shader an. Das Minimieren von Verzweigungen ist ideal für parallelisierte Prozessoren wie die GPU und kann sogar dazu beitragen, dass der Compiler zusätzliche Optimierungen findet:
- Verwenden Sie Funktionen wie
min,maxundclamp, um Verzweigungen für numerische Werte zu vermeiden. - Kosten für die Berechnung im Vergleich zur Verzweigung testen Da in vielen Architekturen beide Pfade einer Verzweigung ausgeführt werden, gibt es viele Szenarien, in denen die Berechnung immer schneller ist als das Überspringen der Berechnung mit einer Verzweigung.
- Verwenden Sie Funktionen wie
Temporäre Register: Dies sind schnelle Register auf dem Chip, die zum Speichern der Ergebnisse von Zwischenvorgängen verwendet werden, die für Berechnungen auf der GPU erforderlich sind. Die Anzahl der Register, die für Berechnungen verfügbar sind, ist begrenzt. Wenn diese Grenze erreicht ist, muss die GPU auf anderen Off-Core-Speicher zurückgreifen, um Zwischenwerte zu speichern. Das führt zu einer Verringerung der Gesamtleistung. Dieses Limit variiert je nach GPU-Modell.
Die Anzahl der verwendeten temporären Register kann höher als erwartet sein, wenn der Shader-Compiler Vorgänge wie das Entrollen von Schleifen ausführt. Es ist daher ratsam, diesen Wert mit dem SPIR-V- oder dekompilierten GLSL-Code abzugleichen, um zu sehen, was der Code macht.
Analyse von Shader-Code
Untersuchen Sie den dekompilierten Shader-Code, um festzustellen, ob potenzielle Verbesserungen möglich sind.
- Genauigkeit: Die Genauigkeit von Shader-Variablen kann sich auf die GPU-Leistung Ihrer Anwendung auswirken.
- Verwenden Sie nach Möglichkeit den Genauigkeitsmodifikator
mediumpfür Variablen, da 16-Bit-Variablen mit mittlerer Genauigkeit (mediump) in der Regel schneller und energieeffizienter sind als 32-Bit-Variablen mit voller Genauigkeit (highp). - Wenn in den Variablendeklarationen im Shader oder oben im Shader mit einem
precision precision-qualifier typekeine Präzisionsqualifizierer zu sehen sind, wird standardmäßig die volle Präzision (highp) verwendet. Achten Sie auch auf Variablendeklarationen. - Die Verwendung von
mediumpfür die Ausgabe von Vertex-Shadern wird aus den oben beschriebenen Gründen ebenfalls bevorzugt. Außerdem wird dadurch die Speicherbandbreite und möglicherweise die Nutzung temporärer Register reduziert, die für die Interpolation erforderlich sind.
- Verwenden Sie nach Möglichkeit den Genauigkeitsmodifikator
- Einheitliche Puffer: Versuchen Sie, die Größe von Uniform Buffers so klein wie möglich zu halten (unter Einhaltung der Ausrichtungsregeln). Das macht Berechnungen besser mit dem Caching kompatibel und ermöglicht es, einheitliche Daten in schnellere On-Core-Register zu verschieben.
Nicht verwendete Vertex-Shader-Ausgaben entfernen: Wenn Sie Vertex-Shader-Ausgaben finden, die im Fragment-Shader nicht verwendet werden, entfernen Sie sie aus dem Shader, um Speicherbandbreite und temporäre Register freizugeben.
Berechnungen vom Fragment-Shader zum Vertex-Shader verschieben: Wenn im Fragment-Shader-Code Berechnungen ausgeführt werden, die unabhängig vom Zustand des zu schattierenden Fragments sind (oder richtig interpoliert werden können), ist es ideal, sie in den Vertex-Shader zu verschieben. Das liegt daran, dass der Vertex-Shader in den meisten Apps viel seltener ausgeführt wird als der Fragment-Shader.