AGI Frame Profiler vous permet d'examiner les passes de rendu individuelles utilisées pour composer une seule frame de votre application. Pour ce faire, il intercepte et enregistre tout l'état nécessaire à l'exécution de chaque appel d'API Graphics. Sur Vulkan, cela se fait de manière native à l'aide du système de couches de Vulkan. Sur OpenGL, les commandes sont interceptées à l'aide d'ANGLE, qui les convertit en appels Vulkan afin qu'elles puissent être exécutées sur le matériel.
Appareils Adreno
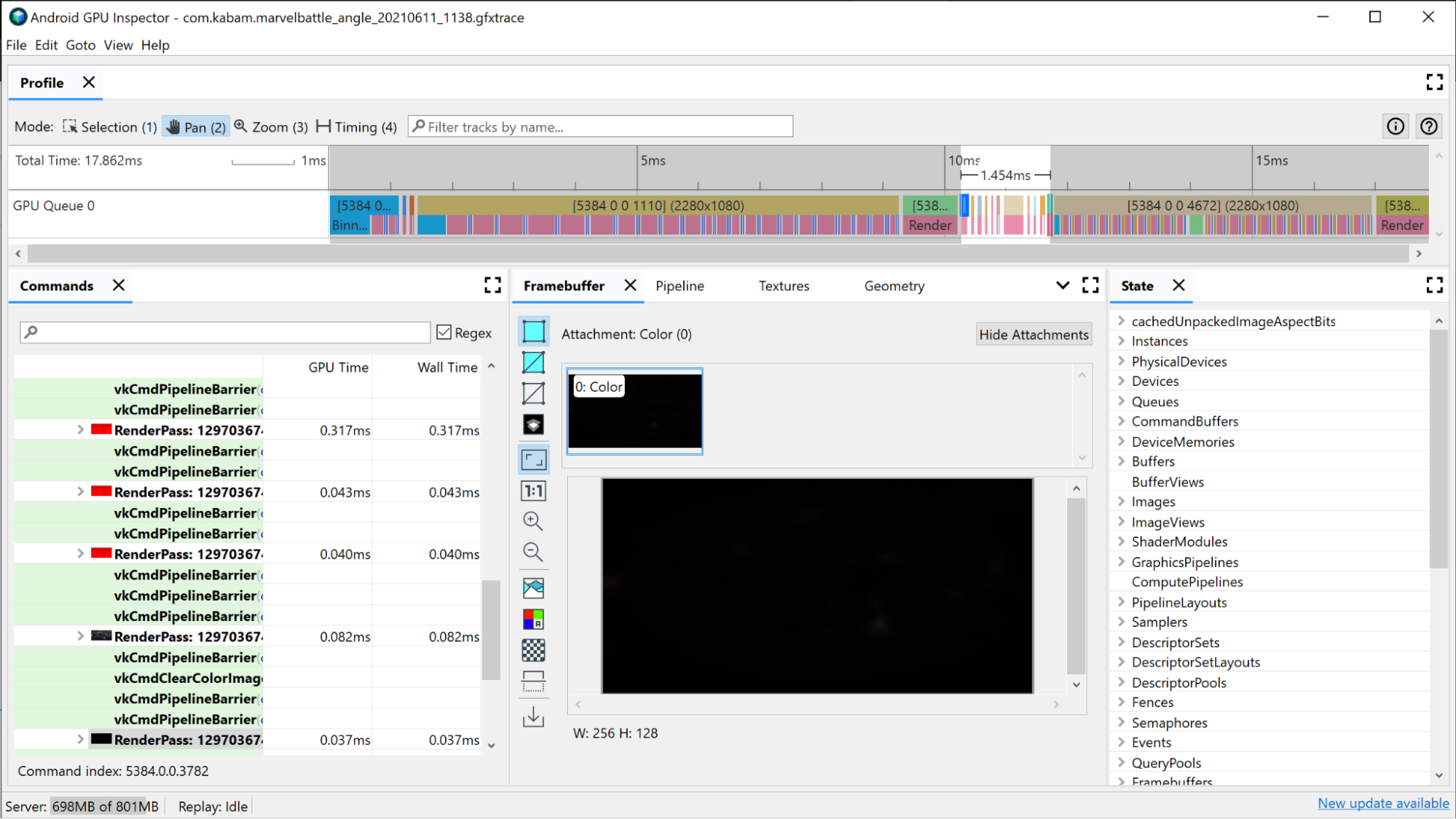
Pour identifier vos passes de rendu coûteuses, commencez par examiner la vue chronologique d'AGI en haut de la fenêtre. Cette section affiche tous les passes de rendu qui composent la composition d'une image donnée, dans l'ordre chronologique. Il s'agit de la même vue que celle qui s'afficherait dans le Profiler système si vous disposiez d'informations sur la file d'attente du GPU. Il présente également des informations de base sur le pass de rendu, telles que la résolution des framebuffers dans lesquels le rendu est effectué, ce qui peut donner un aperçu de ce qui se passe dans le pass de rendu lui-même.
Le premier critère que vous pouvez utiliser pour examiner vos passes de rendu est le temps qu'elles prennent. Le pass de rendu le plus long est probablement celui qui peut être le plus amélioré. Commencez donc par l'examiner.
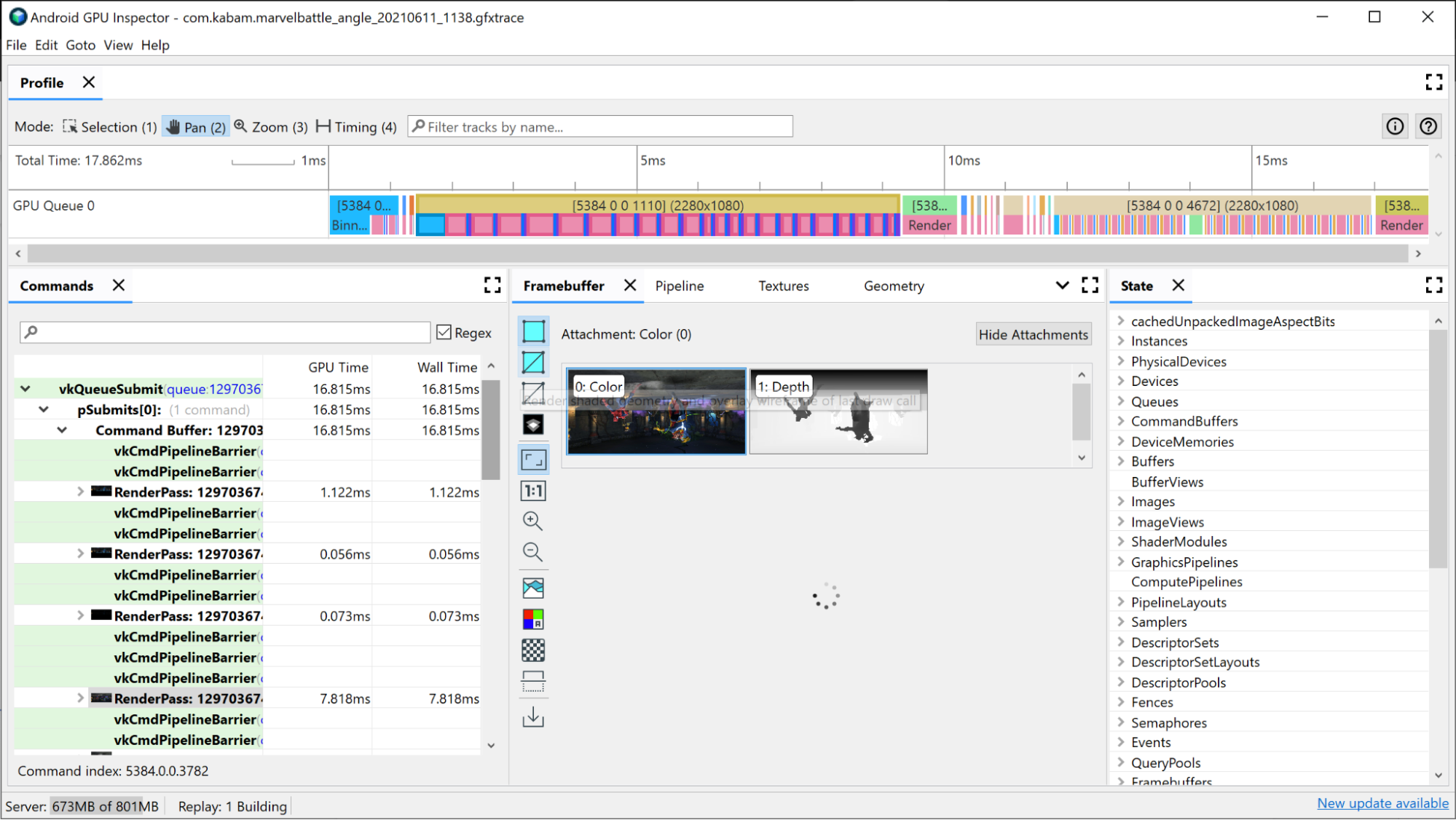
La tranche de GPU correspondant à la passe de rendu concernée présente déjà des informations sur ce qui se passe dans la passe de rendu :
- Binning : les sommets sont placés dans des bins en fonction de leur emplacement à l'écran.
- Rendu : où les pixels ou les fragments sont ombrés
- Chargement/stockage GMEM : lorsque le contenu d'une mémoire tampon de trame est chargé ou stocké depuis la mémoire interne du GPU vers la mémoire principale
Vous pouvez vous faire une bonne idée des goulots d'étranglement potentiels en examinant le temps nécessaire à chacun d'eux dans la passe de rendu. Exemple :
- Si le binning prend beaucoup de temps, cela suggère un goulot d'étranglement avec les données de vertex, ce qui indique un nombre de vertex trop élevé, des vertex trop volumineux ou d'autres problèmes liés aux vertex.
- Si le rendu prend la majorité du temps, cela suggère que l'ombrage est le goulot d'étranglement. Les causes possibles peuvent être des nuanceurs complexes, un nombre trop élevé de récupérations de textures, un rendu dans un framebuffer haute résolution lorsque ce n'est pas nécessaire ou d'autres problèmes associés.
Les chargements et les stockages GMEM sont également à prendre en compte. Il est coûteux de déplacer des éléments de la mémoire graphique vers la mémoire principale. Par conséquent, réduire le nombre d'opérations de chargement ou de stockage contribuera également à améliorer les performances. Un exemple courant consiste à avoir une profondeur/un stencil de stockage GMEM, qui écrit le tampon de profondeur/stencil dans la mémoire principale. Si vous n'utilisez pas ce tampon dans les futurs passes de rendu, cette opération de stockage peut être éliminée, ce qui vous permettra d'économiser du temps de frame et de la bande passante mémoire.
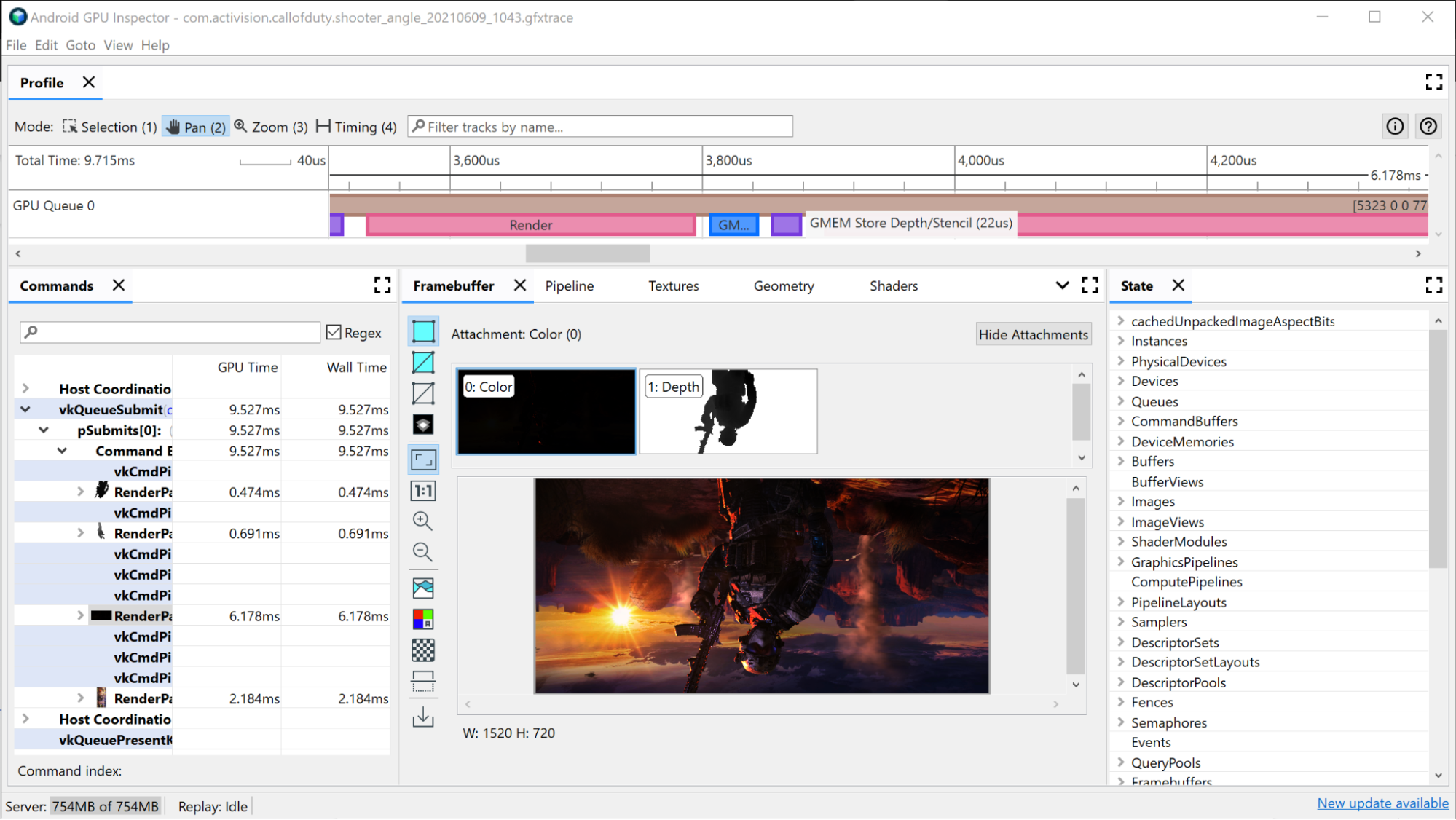
Analyse des grandes passes de rendu
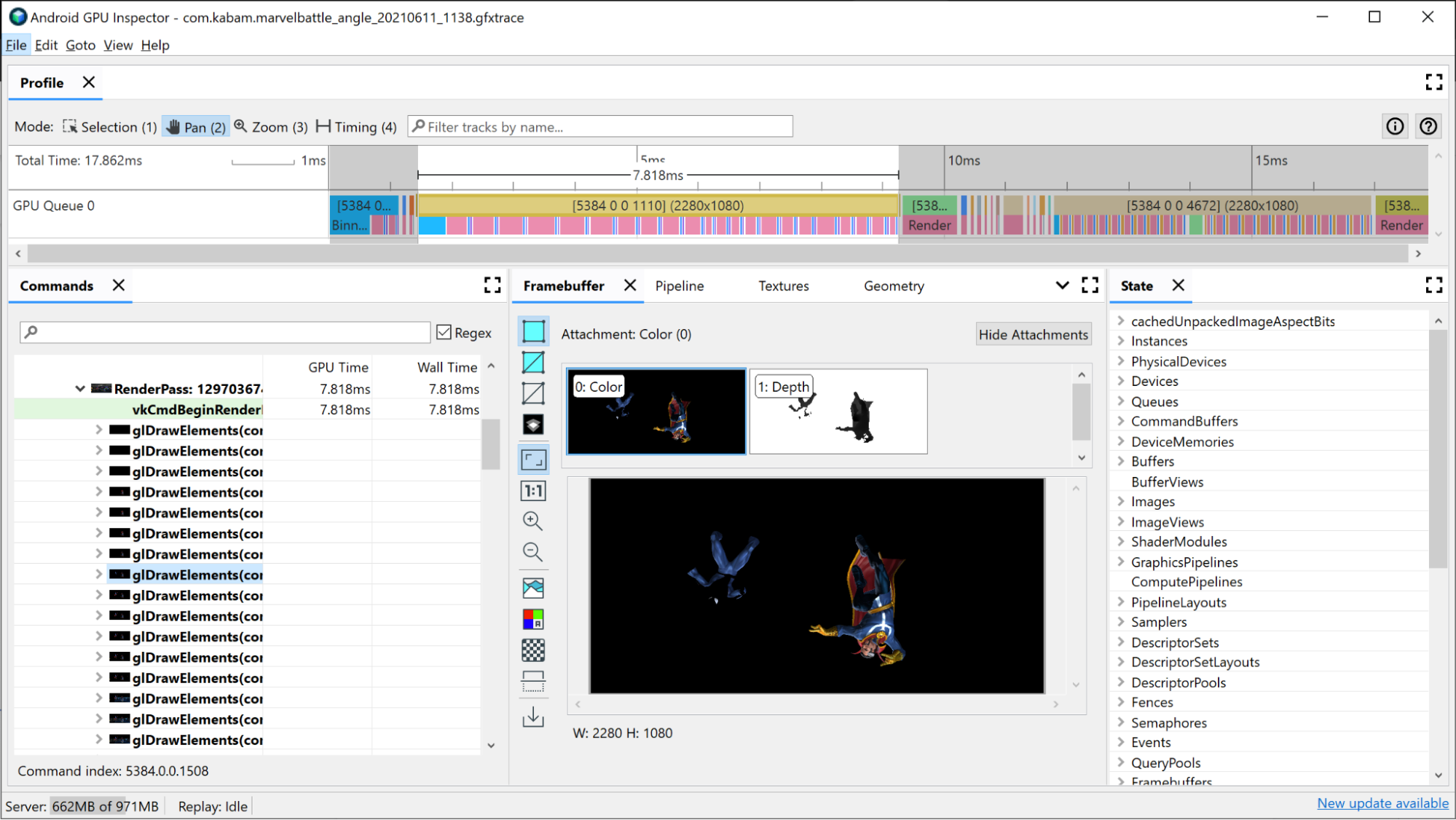
Pour afficher toutes les commandes de dessin individuelles émises pendant la passe de rendu :
Cliquez sur la passe de rendu dans la timeline. Le pass de rendu s'ouvre dans la hiérarchie du volet Commandes du Frame Profiler.
Cliquez sur le menu du pass de rendu, qui affiche toutes les commandes de dessin individuelles émises pendant le pass de rendu. S'il s'agit d'une application OpenGL, vous pouvez aller encore plus loin et voir les commandes Vulkan émises par ANGLE.
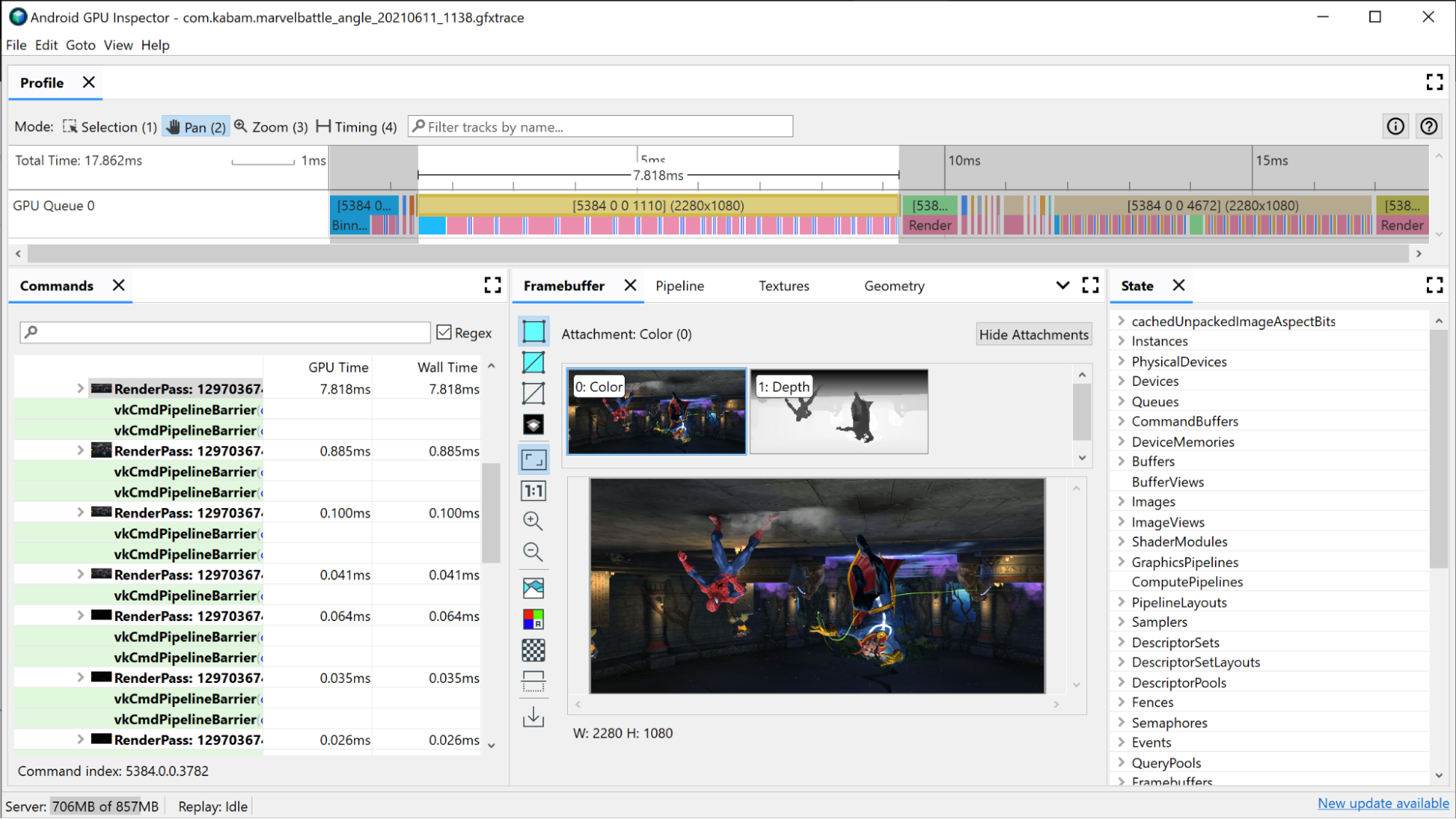
Sélectionnez l'un des appels de dessin. Le volet Framebuffer s'ouvre. Il affiche toutes les pièces jointes du framebuffer qui ont été liées lors de ce dessin, ainsi que le résultat final du dessin sur le framebuffer joint. Vous pouvez également utiliser AGI pour ouvrir les appels de dessin précédents et suivants, et comparer la différence entre les deux. Si elles sont visuellement presque identiques, cela suggère qu'il est possible d'éliminer un appel de dessin qui ne contribue pas à l'image finale.
L'ouverture du volet Pipeline pour ce tirage au sort affiche l'état utilisé par le pipeline graphique pour exécuter cet appel de tirage au sort.
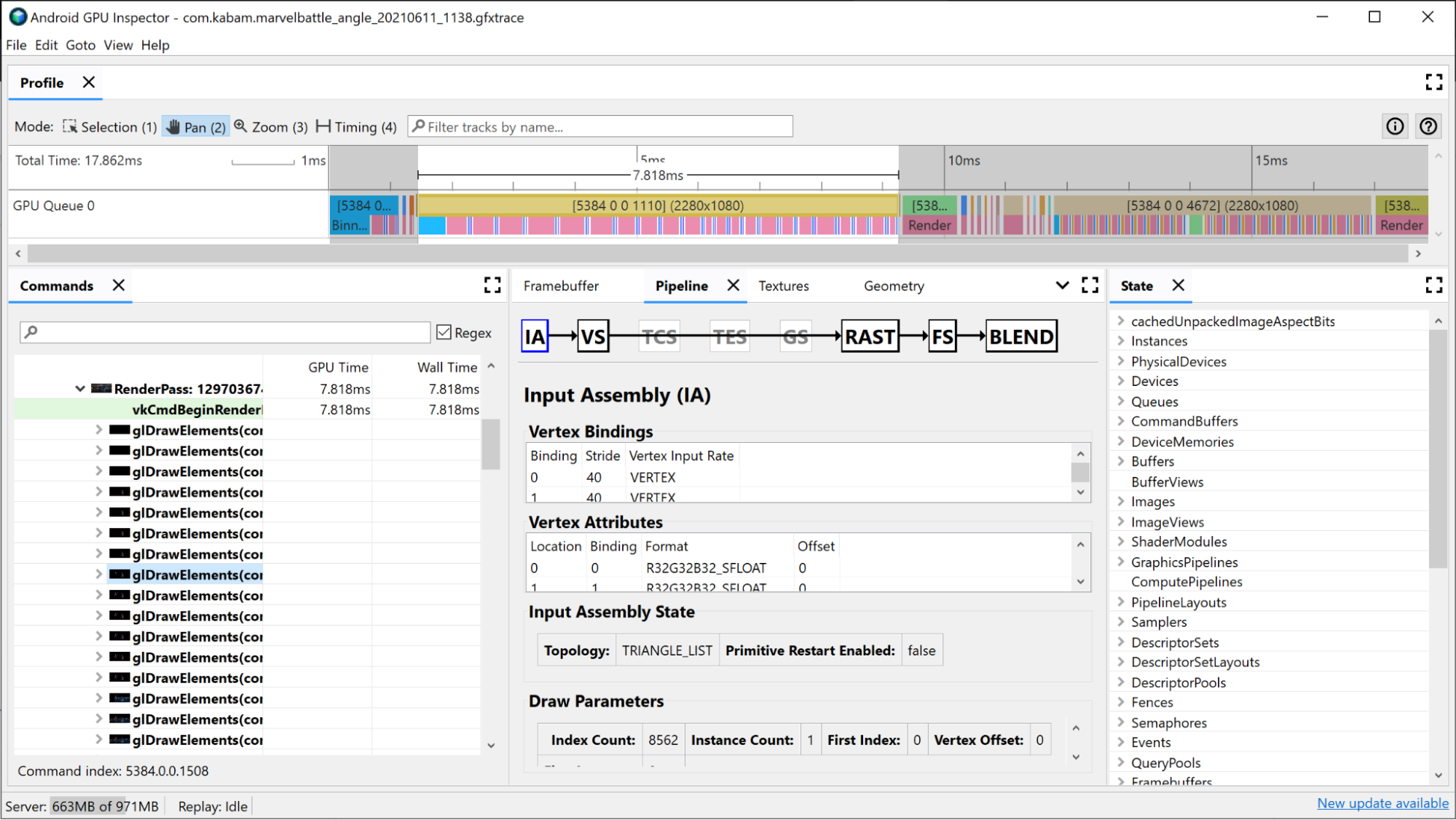
L'assembleur d'entrée fournit des informations sur la façon dont les données de vertex ont été liées à ce dessin. C'est un bon endroit pour enquêter si vous avez remarqué que le binning prend une grande partie du temps de votre passe de rendu. Vous pouvez y obtenir des informations sur le format des vertex, le nombre de vertex dessinés et la façon dont les vertex sont disposés en mémoire. Pour en savoir plus, consultez Analyser les formats de vertex.
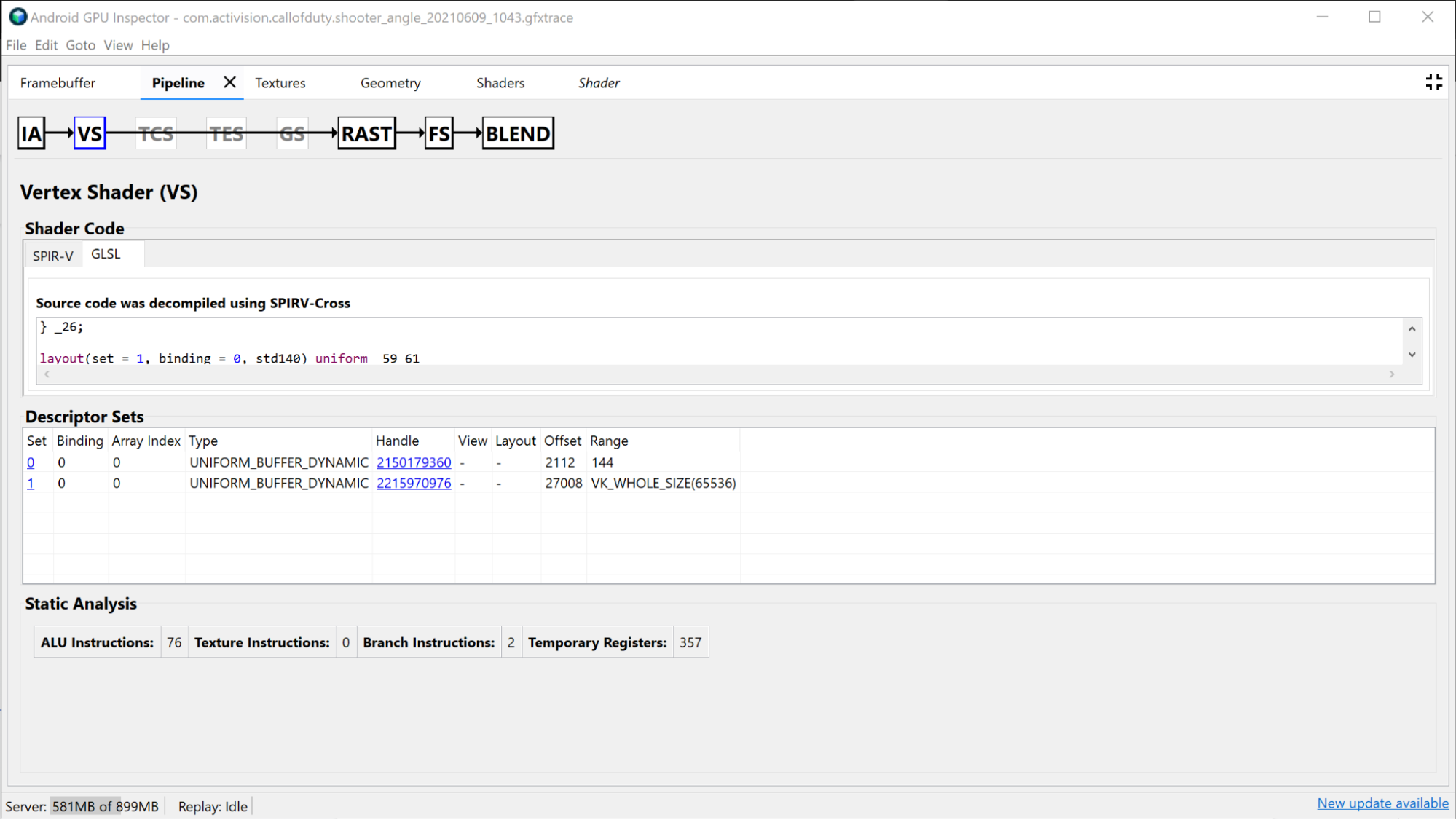
La section Vertex Shader fournit des informations sur le nuanceur de vertex que vous avez utilisé lors de ce dessin. Elle peut également être utile pour déterminer si le binning a été identifié comme un problème. Vous pouvez voir le SPIR-V et le GLSL décompilé du nuanceur utilisé, et examiner les tampons uniformes liés à cet appel. Pour en savoir plus, consultez Analyser les performances des nuanceurs.
La section Rasterizer fournit des informations sur la configuration plus fixe de l'ensemble du pipeline. Elle peut être utilisée à des fins de débogage de l'état de fonction fixe, comme le viewport, le scissor, l'état de profondeur et le mode polygone.
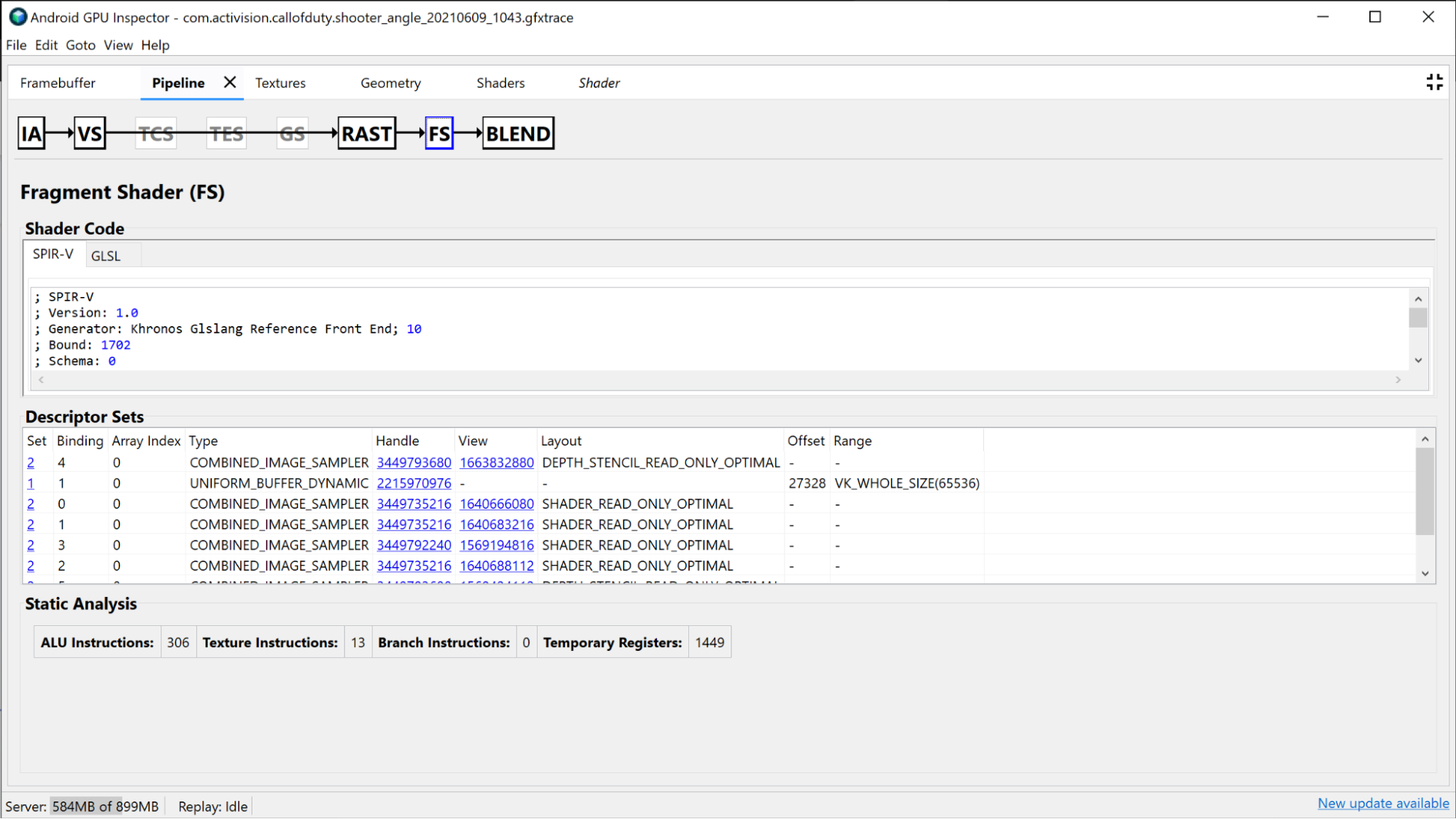
La section Fragment Shader fournit de nombreuses informations identiques à celles de la section Vertex Shader, mais spécifiques à Fragment Shader. Dans ce cas, vous pouvez voir quelles textures sont liées et les examiner en cliquant sur le handle.
Étude sur les passes de rendu plus petites
Un autre critère que vous pouvez utiliser pour améliorer les performances de votre GPU consiste à examiner les groupes de passes de rendu plus petites. En général, vous devez minimiser le nombre de passes de rendu autant que possible, car le GPU met du temps à mettre à jour l'état d'une passe de rendu à une autre. Ces passes de rendu plus petites sont généralement utilisées pour générer des cartes d'ombre, appliquer un flou gaussien, estimer la luminance, appliquer des effets de post-traitement ou afficher l'UI. Certains d'entre eux peuvent potentiellement être regroupés dans un seul pass de rendu, voire éliminés complètement s'ils n'affectent pas suffisamment l'image globale pour justifier le coût.