
버텍스 데이터의 메모리 대역폭은 게임의 GPU 성능에 잠재적인 병목 현상이 될 수 있습니다. AGI 시스템 프로필에는 버텍스 메모리 대역폭 문제를 진단하는 데 도움이 되는 몇 가지 카운터가 있습니다.
Qualcomm Adreno 카운터
Qualcomm Adreno GPU가 탑재된 기기에서 주목할 만한 카운터는 다음과 같습니다.
| 카운터 | 설명 |
|---|---|
| 버텍스 메모리 읽기 | 외부 메모리에서 읽은 버텍스 데이터의 대역폭입니다. |
| 평균 바이트/버텍스 | 버텍스 데이터의 평균 크기(바이트)입니다. |
| % 버텍스 가져오기 중단 | GPU가 버텍스 데이터에서 차단되는 클록 주기의 비율입니다. |
ARM Mali 카운터 (작업 중)
ARM Mali GPU가 탑재된 기기에서 주목할 만한 카운터는 다음과 같습니다.
| 카운터 | 설명 |
|---|---|
| 외부 메모리에서 읽기/쓰기 비트 로드 | 셰이더 코어에서 평균화된 읽기/쓰기 단위로 외부 메모리에서 읽은 데이터 비트입니다. |
| L2 캐시에서 읽기/쓰기 비트 로드 | 셰이더 코어에서 평균화된 읽기/쓰기 단위로 L2 캐시에서 읽은 데이터 비트입니다. |
| [더보기] |
평균 읽기 비트에서 전체 대역폭을 계산하려면 카운터 값에 버스 너비 (일반적으로 16바이트)와 총 셰이더 코어 수를 곱합니다. [더보기]
카운터 분석
이러한 카운터의 동작을 측정하려면 단일 GPU 프레임의 평균 및 최대 대역폭을 측정하면 됩니다. 이는 연속된 GPU 사용률 블록으로 구분할 수 있습니다.
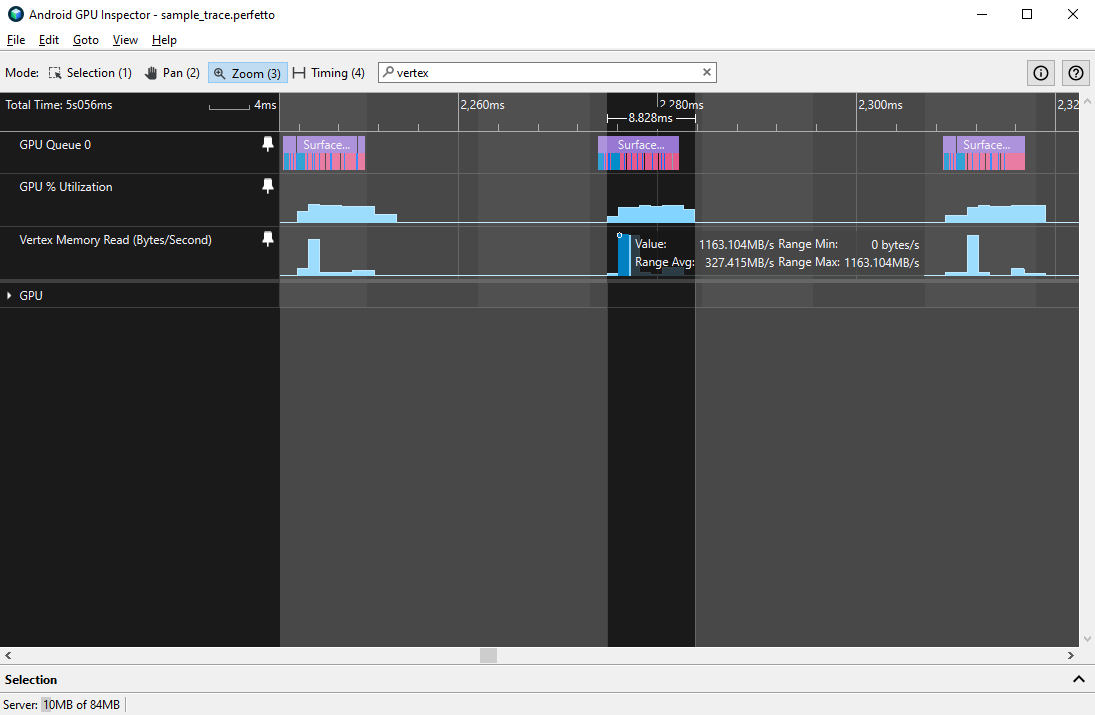
최대 버텍스 메모리 읽기 대역폭은 1.5GBps 이하, 평균 대역폭은 500MBps 이하로 설정하는 것이 좋습니다. 값이 높을수록 다음과 같은 몇 가지 일반적인 문제 중 하나를 나타냅니다.
- 버텍스 크기가 너무 큼: 버텍스에 큰 버텍스 속성이 있거나 버텍스 속성이 많으면 버텍스 셰이딩 시간에 큰 영향을 미칠 수 있습니다.
- 버텍스 속성 스트림이 분할되지 않음: 버텍스 속성이 단일 버퍼에 인터리브되어 캐시 효율성이 저하됩니다.
- 프레임당 제출된 버텍스가 너무 많음: 복잡한 모델 또는 많은 모델은 더 큰 대역폭을 차지하고 셰이딩하는 데 더 오래 걸릴 수 있습니다.
버텍스 크기 문제는 평균 바이트 / 버텍스 트랙을 통해 진단할 수도 있습니다. 이 트랙은 32바이트 또는 버텍스 이하로 설정하는 것이 좋습니다.
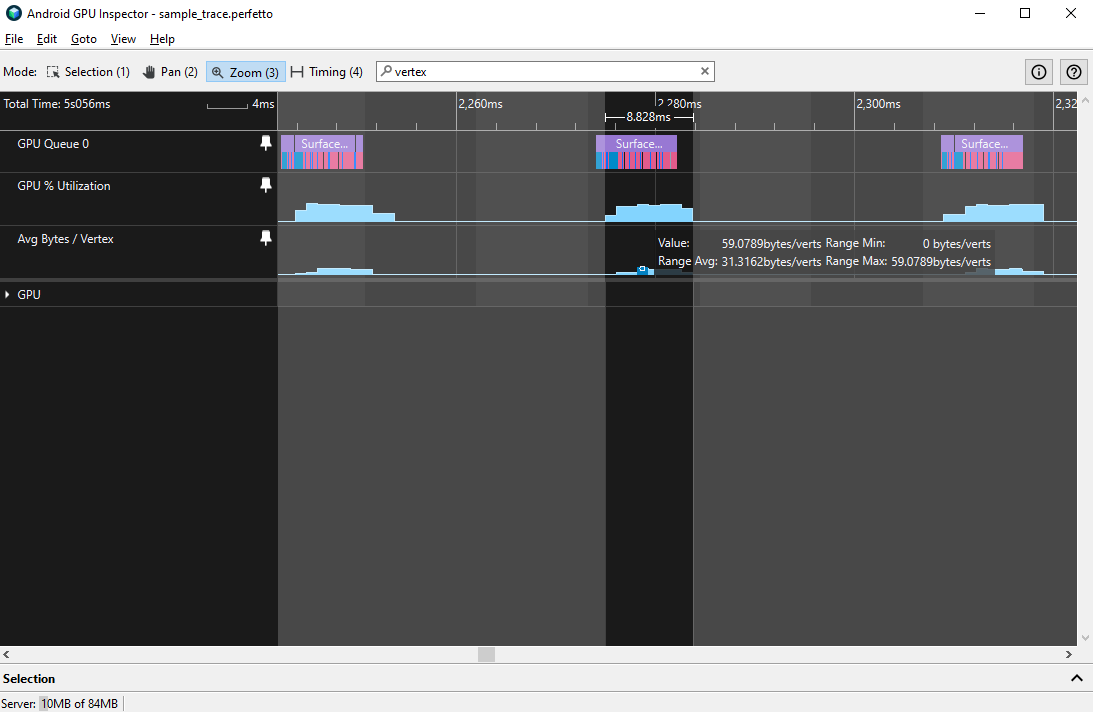
이러한 문제 중 어떤 문제가 발생하고 있는지 진단하는 가장 좋은 방법은 프레임 프로필 트레이스를 가져와 버텍스 형식을 분석하는 것입니다.