Profilowanie klatek AGI umożliwia sprawdzanie poszczególnych przebiegów renderowania, które są używane do tworzenia pojedynczej klatki aplikacji. W tym celu przechwytuje i rejestruje wszystkie stany niezbędne do wykonania każdego wywołania interfejsu API grafiki. W przypadku Vulkana odbywa się to natywnie za pomocą systemu warstw Vulkana. W przypadku OpenGL polecenia są przechwytywane za pomocą ANGLE, który przekształca polecenia OpenGL w wywołania Vulkan, aby można było je wykonywać na sprzęcie.
Urządzenia Adreno
Aby zidentyfikować kosztowne przebiegi renderowania, najpierw spójrz na widok osi czasu w AGI u góry okna. Wyświetla wszystkie przebiegi renderowania, które składają się na kompozycję danej klatki, w kolejności chronologicznej. Jest to ten sam widok, który byłby widoczny w profilerze systemu, gdyby zawierał informacje o kolejce GPU. Zawiera też podstawowe informacje o przekazywaniu renderowania, np. rozdzielczość buforów ramki, do których renderowane są dane. Może to pomóc w zrozumieniu, co dzieje się w trakcie przekazywania renderowania.
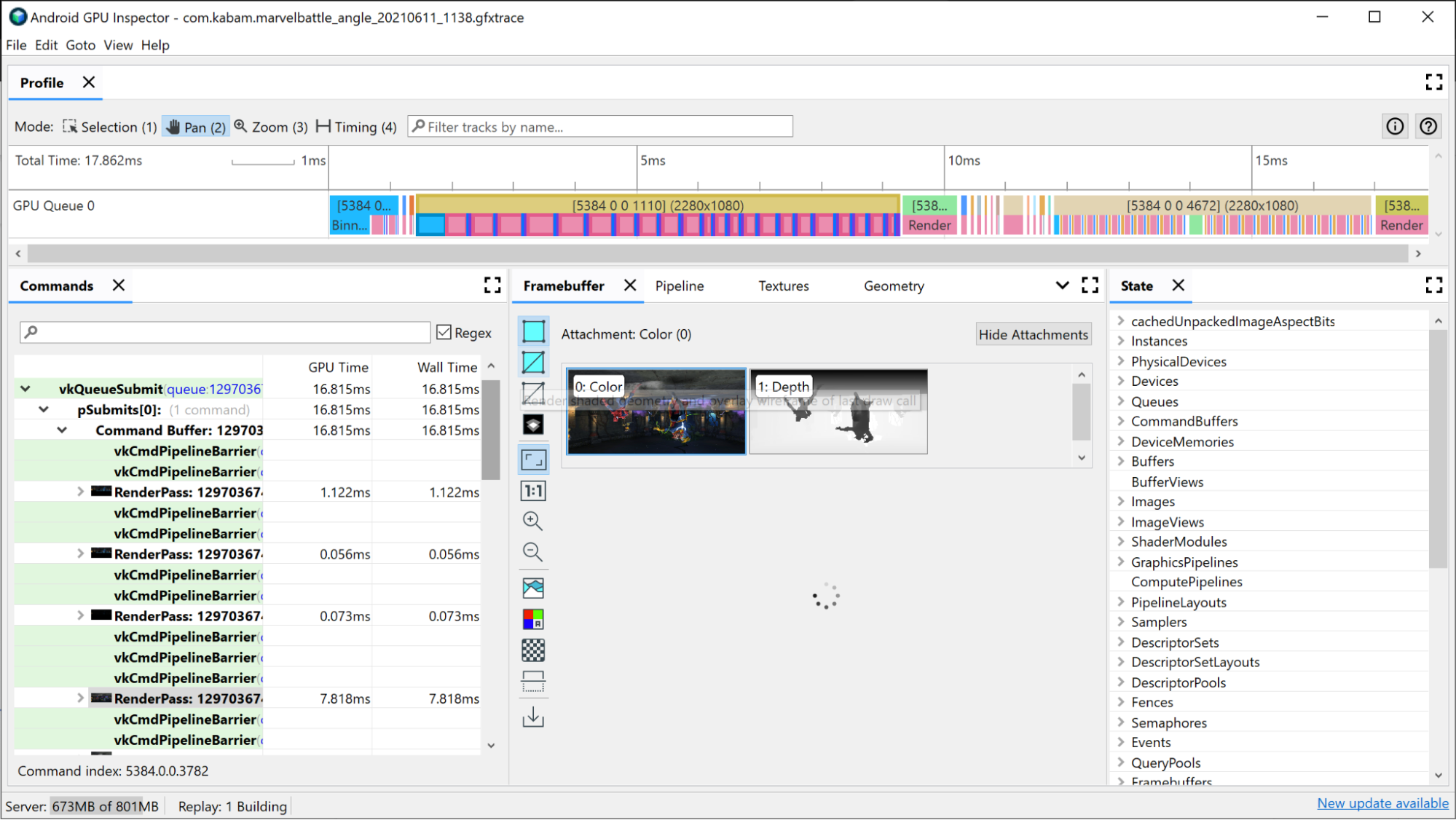
Pierwszym kryterium, którego możesz użyć do analizy przejść renderowania, jest czas ich trwania. Najdłuższy przebieg renderowania będzie prawdopodobnie tym, w którym można wprowadzić najwięcej ulepszeń, więc zacznij od niego.
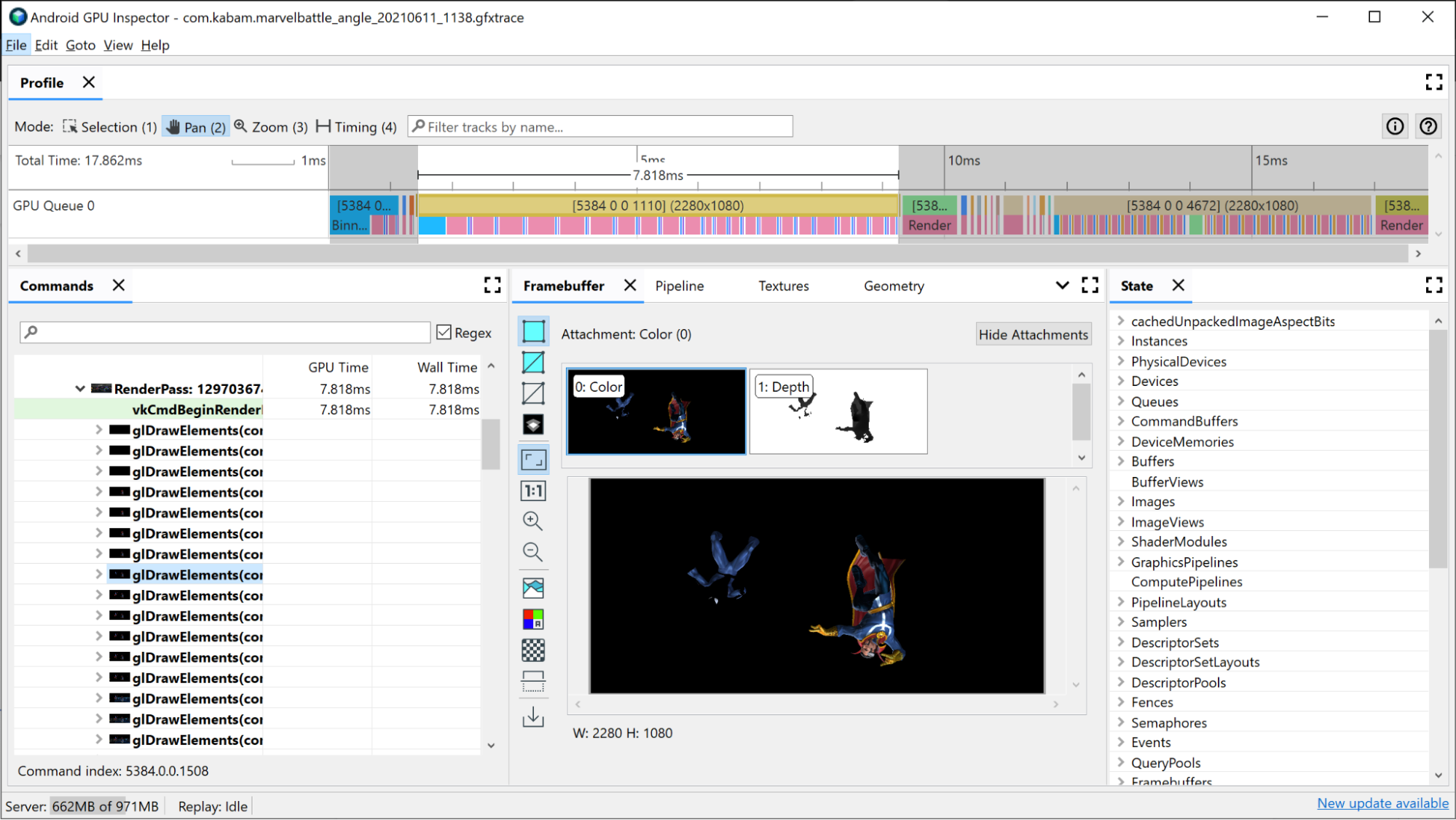
W przypadku odpowiedniego etapu renderowania wycinek GPU będzie już zawierać pewne informacje o tym, co się na nim dzieje:
- Podział na przedziały: wierzchołki są umieszczane w przedziałach na podstawie tego, gdzie znajdują się na ekranie.
- Renderowanie: gdzie piksele lub fragmenty są cieniowane
- GMEM load/store: gdy zawartość bufora ramki jest wczytywana lub zapisywana z wewnętrznej pamięci GPU do pamięci głównej.
Aby dowiedzieć się, gdzie mogą wystąpić potencjalne wąskie gardła, sprawdź, ile czasu zajmuje każda z tych czynności w ramach przepustki renderowania. Na przykład:
- Jeśli grupowanie zajmuje dużo czasu, oznacza to wąskie gardło w przypadku danych wierzchołków, co sugeruje zbyt dużą liczbę wierzchołków, duże wierzchołki lub inne problemy z nimi związane.
- Jeśli renderowanie zajmuje większość czasu, oznacza to, że wąskim gardłem jest cieniowanie. Przyczyną mogą być złożone shadery, zbyt wiele pobrań tekstur, renderowanie do bufora ramki o wysokiej rozdzielczości, gdy nie jest to konieczne, lub inne powiązane problemy.
Warto też pamiętać o ładowaniu i przechowywaniu GMEM. Przenoszenie danych z pamięci graficznej do pamięci głównej jest kosztowne, więc zminimalizowanie liczby operacji wczytywania i zapisywania również pomoże zwiększyć wydajność. Typowym przykładem jest przechowywanie w pamięci GMEM bufora głębi/szablonu, który zapisuje bufor głębi/szablonu w pamięci głównej. Jeśli nie używasz tego bufora w przyszłych przebiegach renderowania, tę operację przechowywania można wyeliminować, co pozwoli zaoszczędzić czas klatki i przepustowość pamięci.
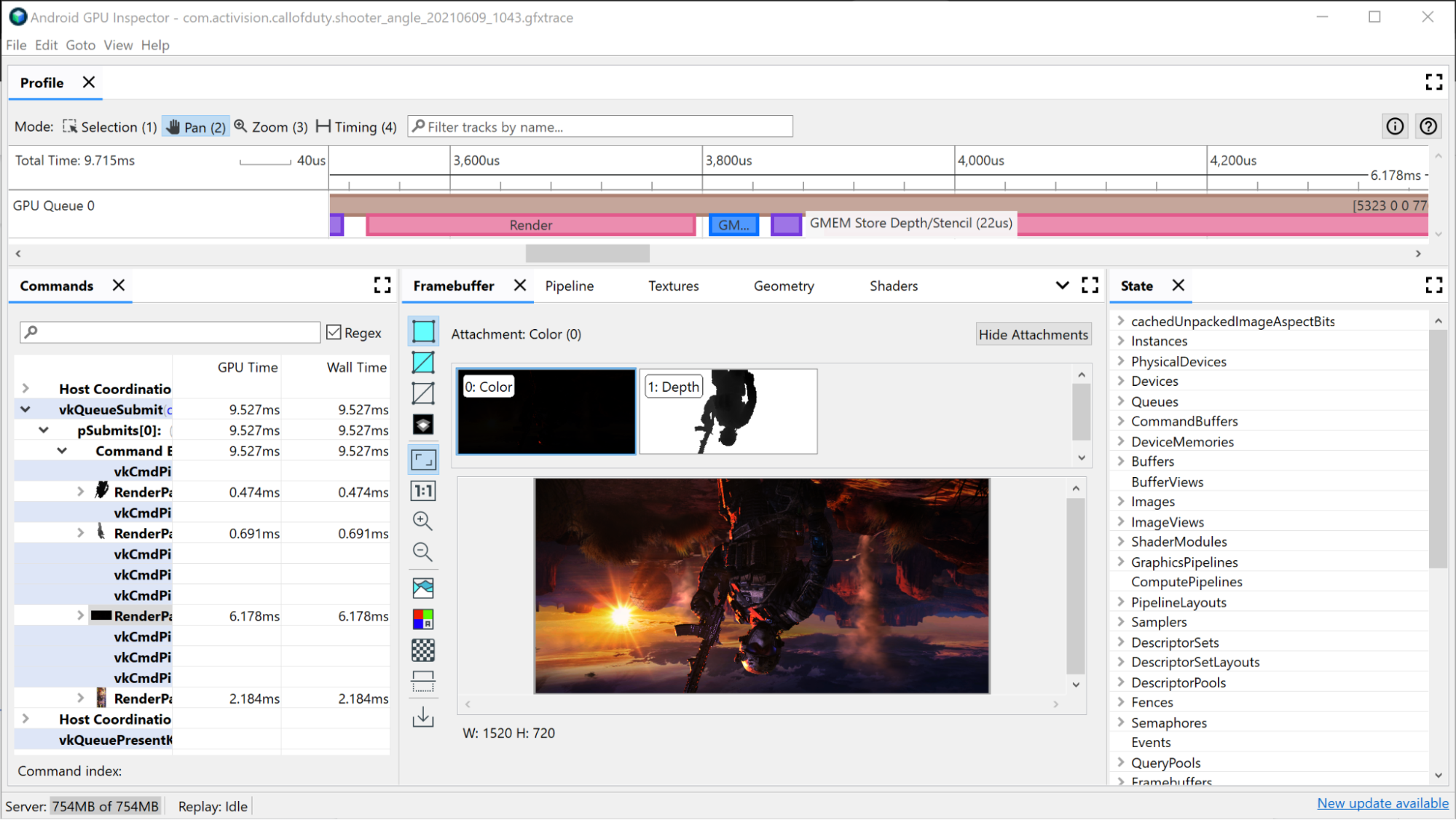
Analiza dużego przejścia renderowania
Aby zobaczyć wszystkie poszczególne polecenia rysowania wydane podczas przekazywania renderowania:
Kliknij warstwę renderowania na osi czasu. Spowoduje to otwarcie przepustki renderowania w hierarchii w panelu Polecenia profilera klatek.
Kliknij menu przepustki renderowania, w którym wyświetlają się wszystkie poszczególne polecenia rysowania wydane podczas przepustki renderowania. Jeśli jest to aplikacja OpenGL, możesz zagłębić się w szczegóły i zobaczyć polecenia Vulkan wydane przez ANGLE.
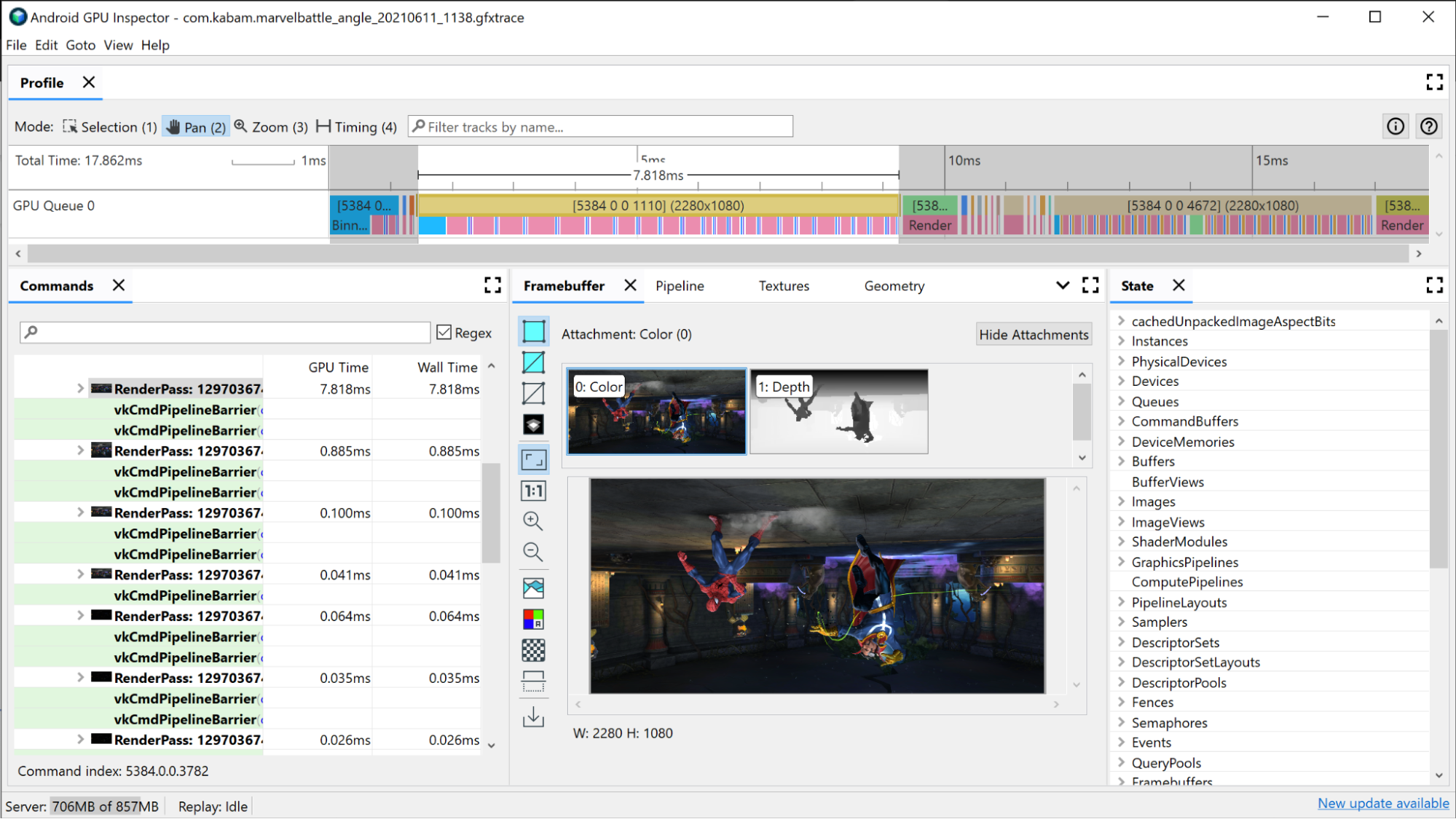
Wybierz jedno z wywołań rysowania. Otworzy się panel Framebuffer, w którym zobaczysz wszystkie załączniki bufora ramki, które zostały powiązane podczas tego rysowania, oraz końcowy wynik rysowania w załączonym buforze ramki. Możesz też użyć AGI, aby otworzyć poprzednie i następne wywołania rysowania oraz porównać różnice między nimi. Jeśli są one niemal identyczne wizualnie, oznacza to, że można wyeliminować wywołanie rysowania, które nie ma wpływu na obraz końcowy.
Otwarcie panelu Potok dla tego wywołania rysowania pokazuje stan używany przez potok graficzny do wykonania tego wywołania.
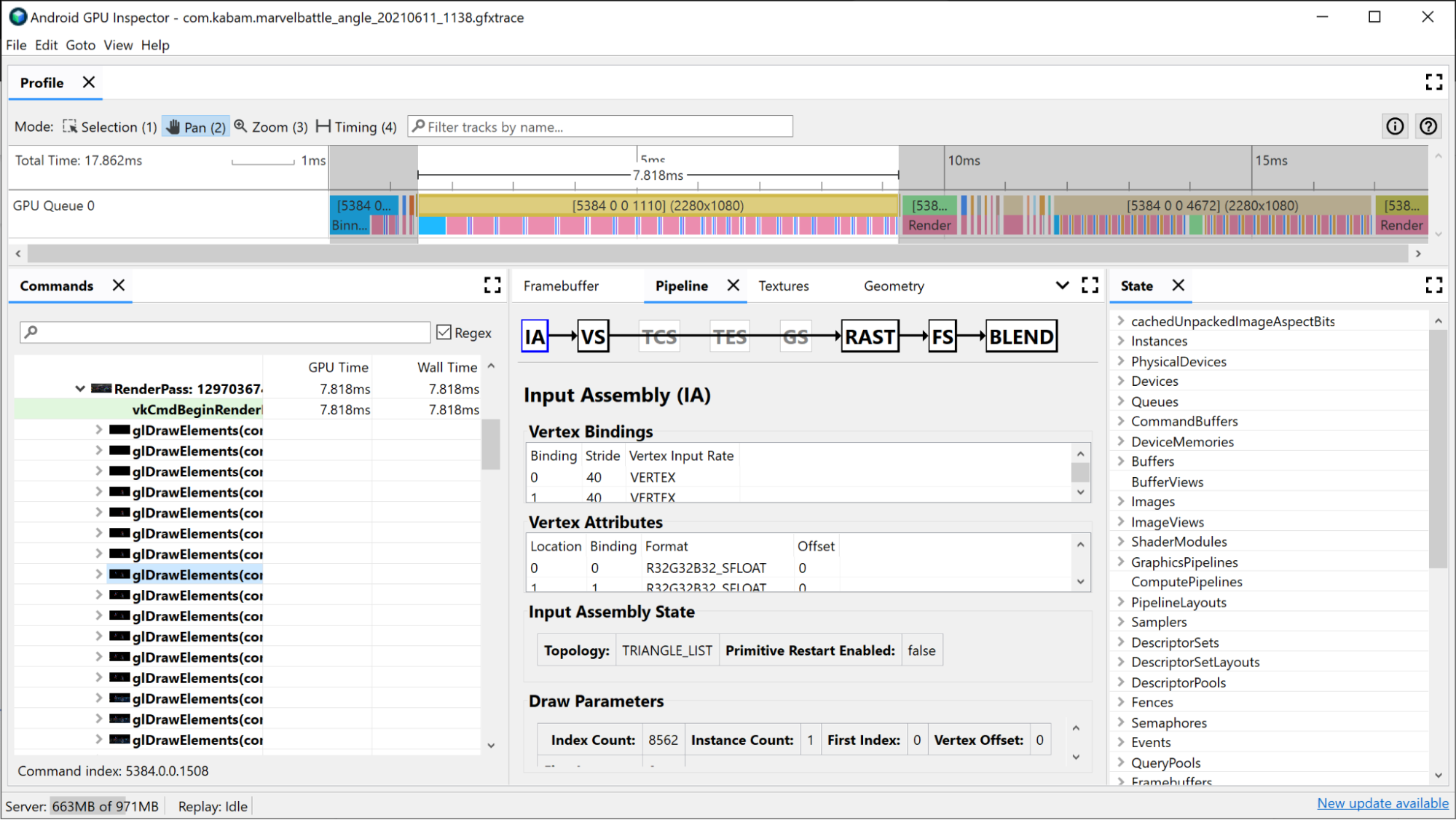
Moduł Input Assembler zawiera informacje o tym, jak dane wierzchołków zostały powiązane z tym rysowaniem. Warto to sprawdzić, jeśli zauważysz, że proces binningu zajmuje dużą część czasu renderowania. Możesz tu uzyskać informacje o formacie wierzchołków, liczbie narysowanych wierzchołków i sposobie ich rozmieszczenia w pamięci. Więcej informacji znajdziesz w sekcji Analizowanie formatów wierzchołków.
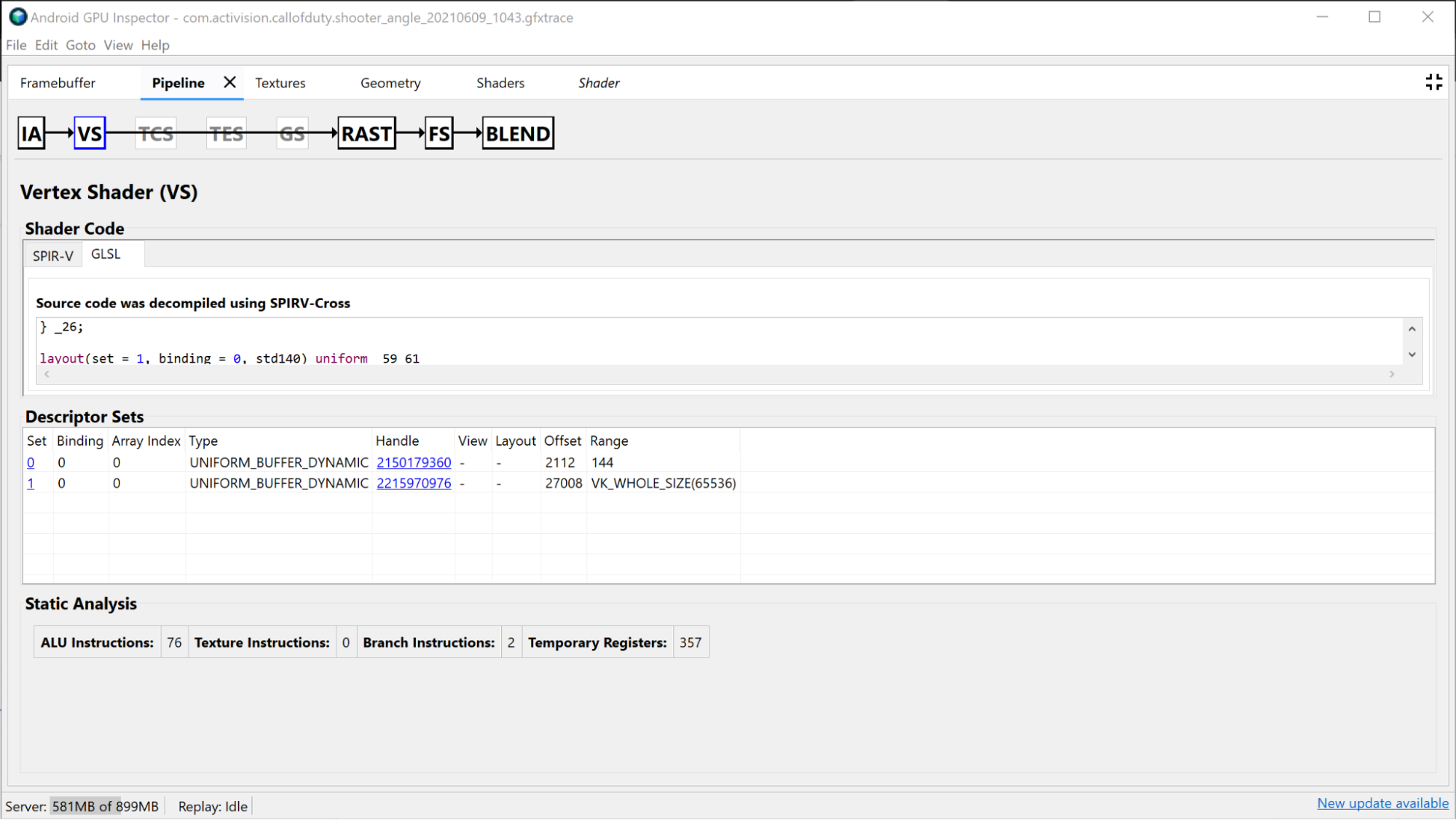
Sekcja Vertex Shader zawiera informacje o shaderze wierzchołków używanym podczas tego rysowania. Może też być dobrym miejscem do sprawdzenia, czy problemem jest grupowanie. Możesz wyświetlić SPIR-V i zdekompilowany GLSL użytego shadera oraz sprawdzić powiązane bufory jednolite dla tego wywołania. Więcej informacji znajdziesz w artykule Analizowanie wydajności cieniowania.
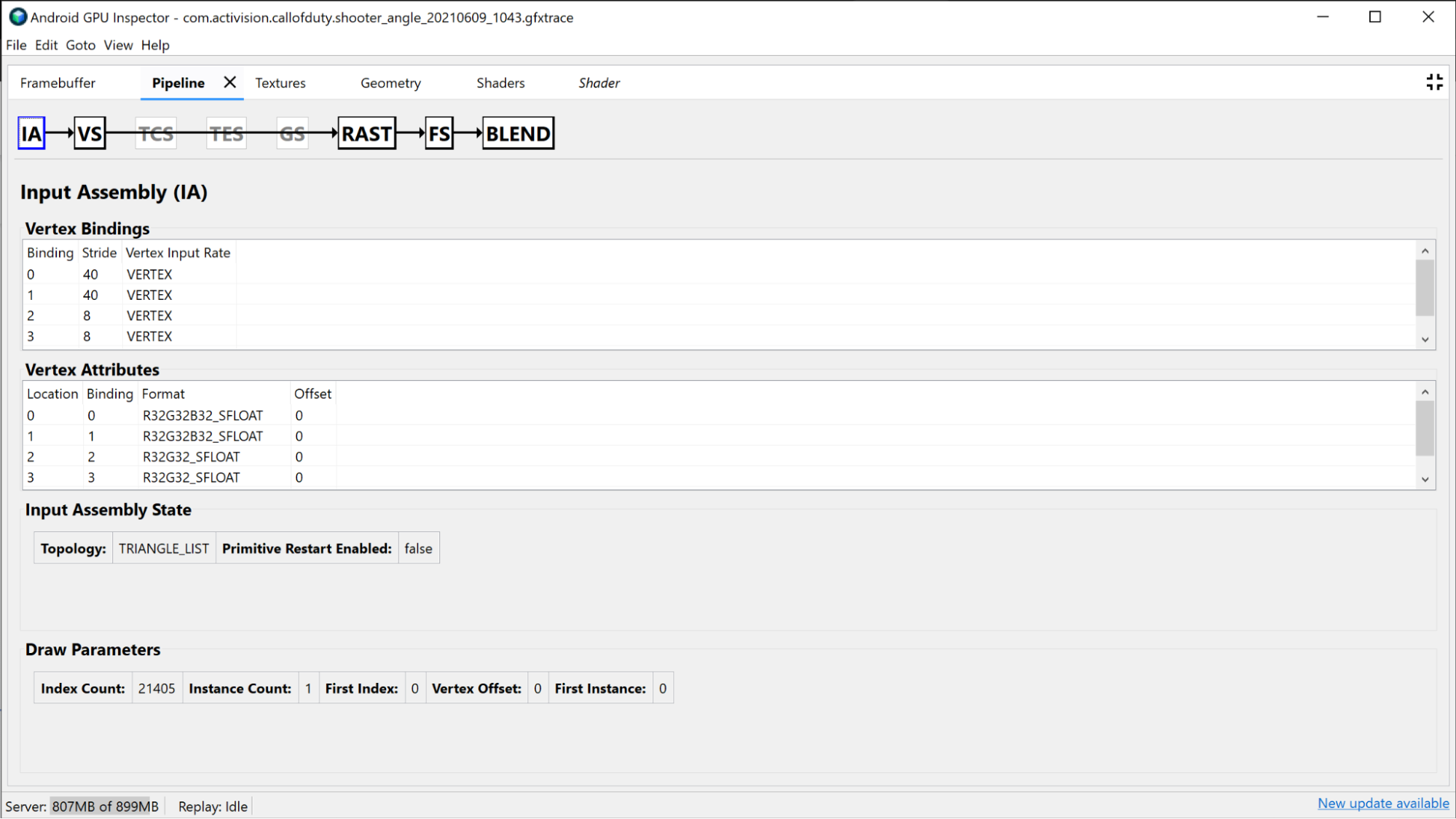
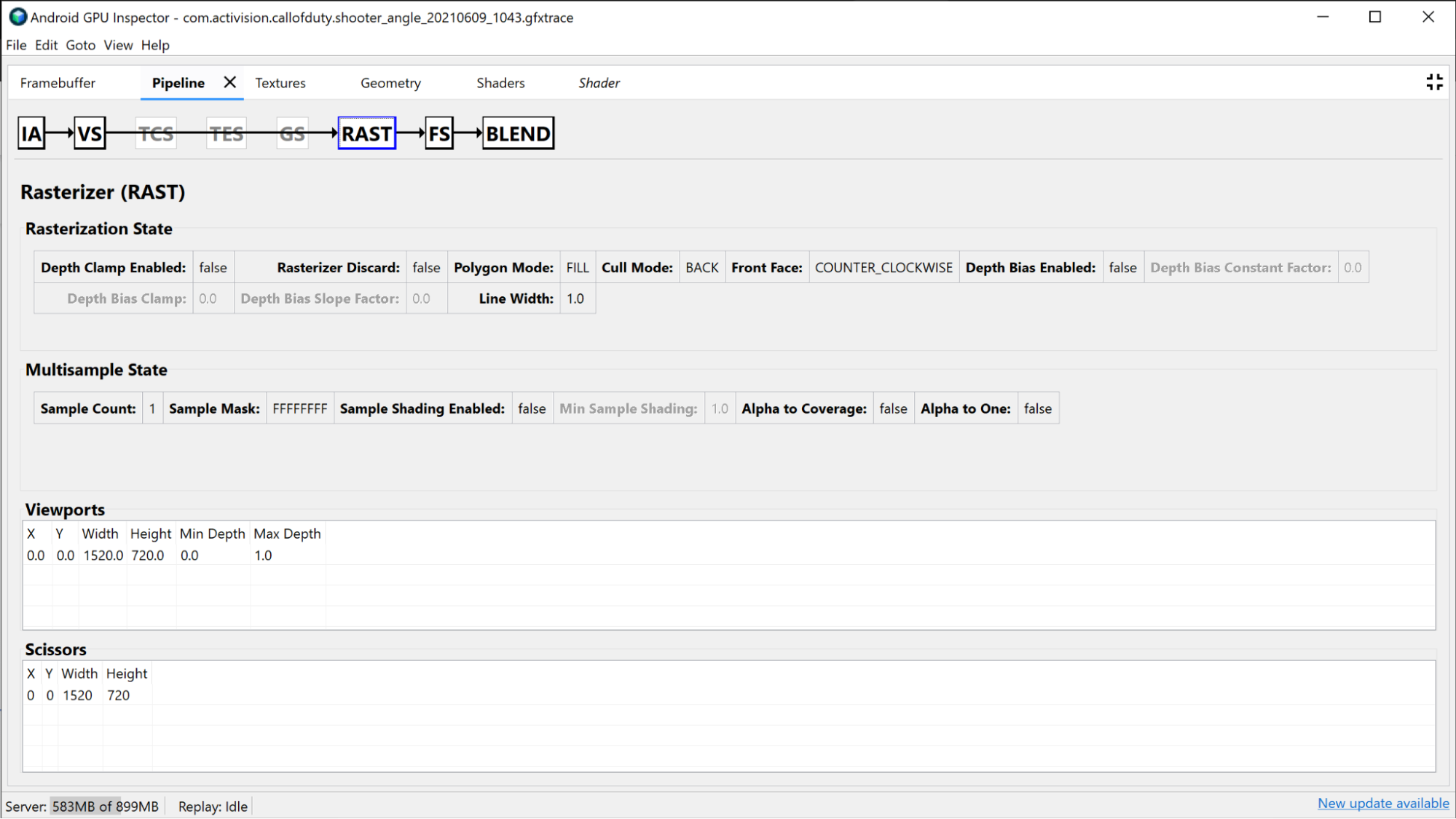
Sekcja Rasterizer zawiera informacje o bardziej stałej konfiguracji potoku i może być używana do debugowania stanu funkcji stałych, takich jak widok, obszar przycinania, stan głębi i tryb wielokąta.
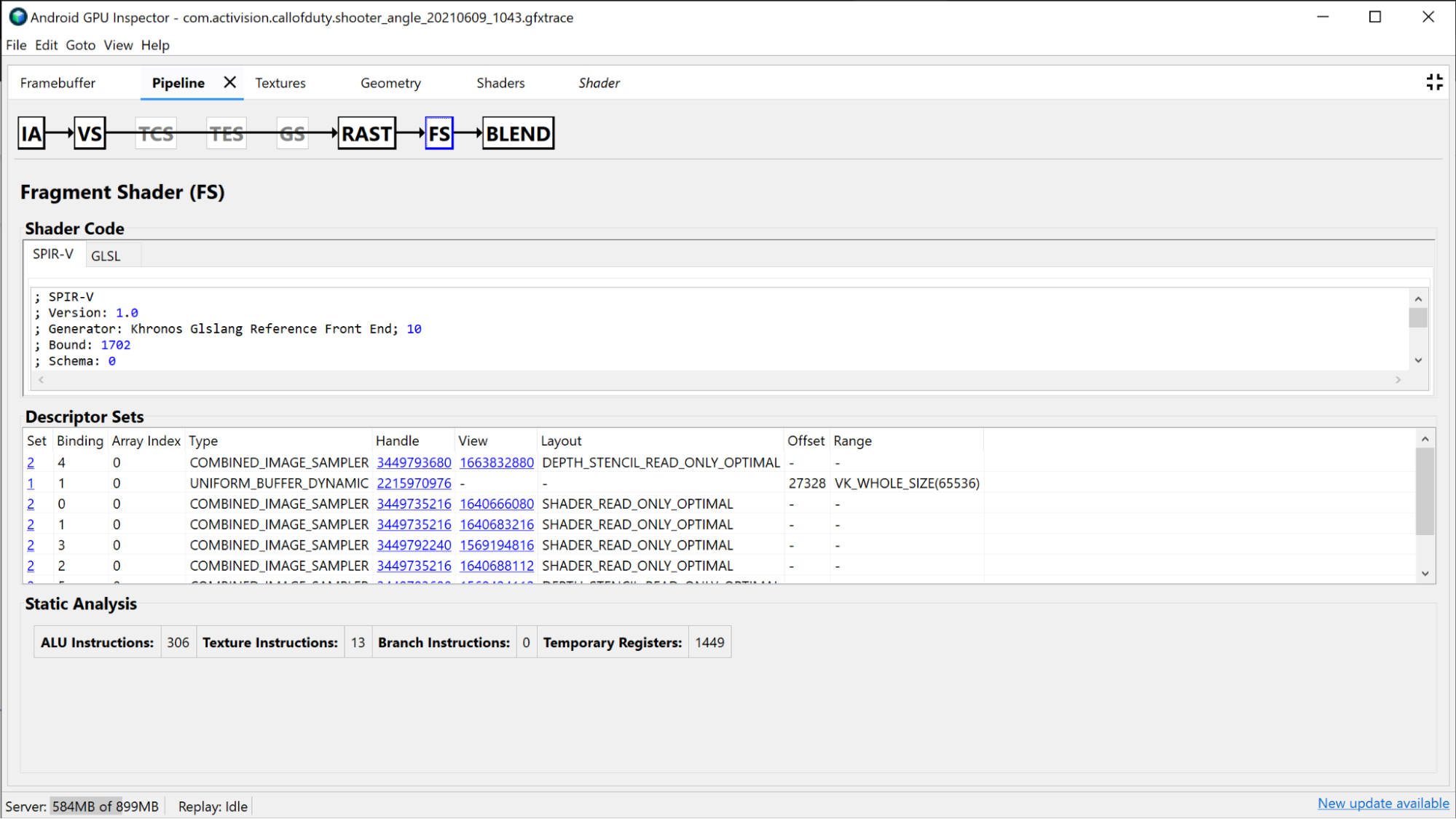
Sekcja Fragment Shader zawiera wiele informacji, które można znaleźć w sekcji Vertex Shader, ale są one specyficzne dla Fragment Shader. W tym przypadku możesz zobaczyć, które tekstury są powiązane, i sprawdzić je, klikając uchwyt.
Analiza mniejszego etapu renderowania
Innym kryterium, które możesz wykorzystać do poprawy wydajności procesora graficznego, jest przyjrzenie się grupom mniejszych przebiegów renderowania. Ogólnie rzecz biorąc, warto jak najbardziej zminimalizować liczbę przebiegów renderowania, ponieważ aktualizacja stanu przez procesor graficzny z jednego przebiegu renderowania do drugiego zajmuje czas. Te mniejsze przebiegi renderowania są zwykle używane do generowania map cieni, stosowania rozmycia Gaussa, szacowania luminancji, stosowania efektów przetwarzania końcowego lub renderowania interfejsu. Niektóre z nich można potencjalnie połączyć w jedną przepustkę renderowania lub nawet całkowicie wyeliminować, jeśli nie wpływają na ogólny obraz w stopniu uzasadniającym koszty.