AGI Frame Profiler te permite examinar pases de renderización individuales que se usan para componer un solo fotograma de tu app. Para ello, intercepta y registra todo el estado necesario para ejecutar cada llamada a la API de gráficos. En Vulkan, esto se hace de forma nativa usando el sistema de capas de Vulkan. En OpenGL, los comandos se interceptan mediante ANGLE, que convierte los comandos de OpenGL en llamadas de Vulkan para que se puedan ejecutar en el hardware.
Dispositivos Adreno
Para identificar tus pases de renderización costosos, primero consulta la vista de cronograma de AGI en la parte superior de la ventana. Aquí se muestran todos los pases de renderización que comprenden la composición de un fotograma determinado de forma cronológica. Es la misma vista que verías en el Generador de perfiles del sistema si tuvieras información de la cola de GPU. También se presenta información básica sobre el pase de renderización, como la resolución de los búferes de fotogramas a los que se renderiza, lo que puede proporcionar información sobre lo que sucede en el pase de renderización en sí.
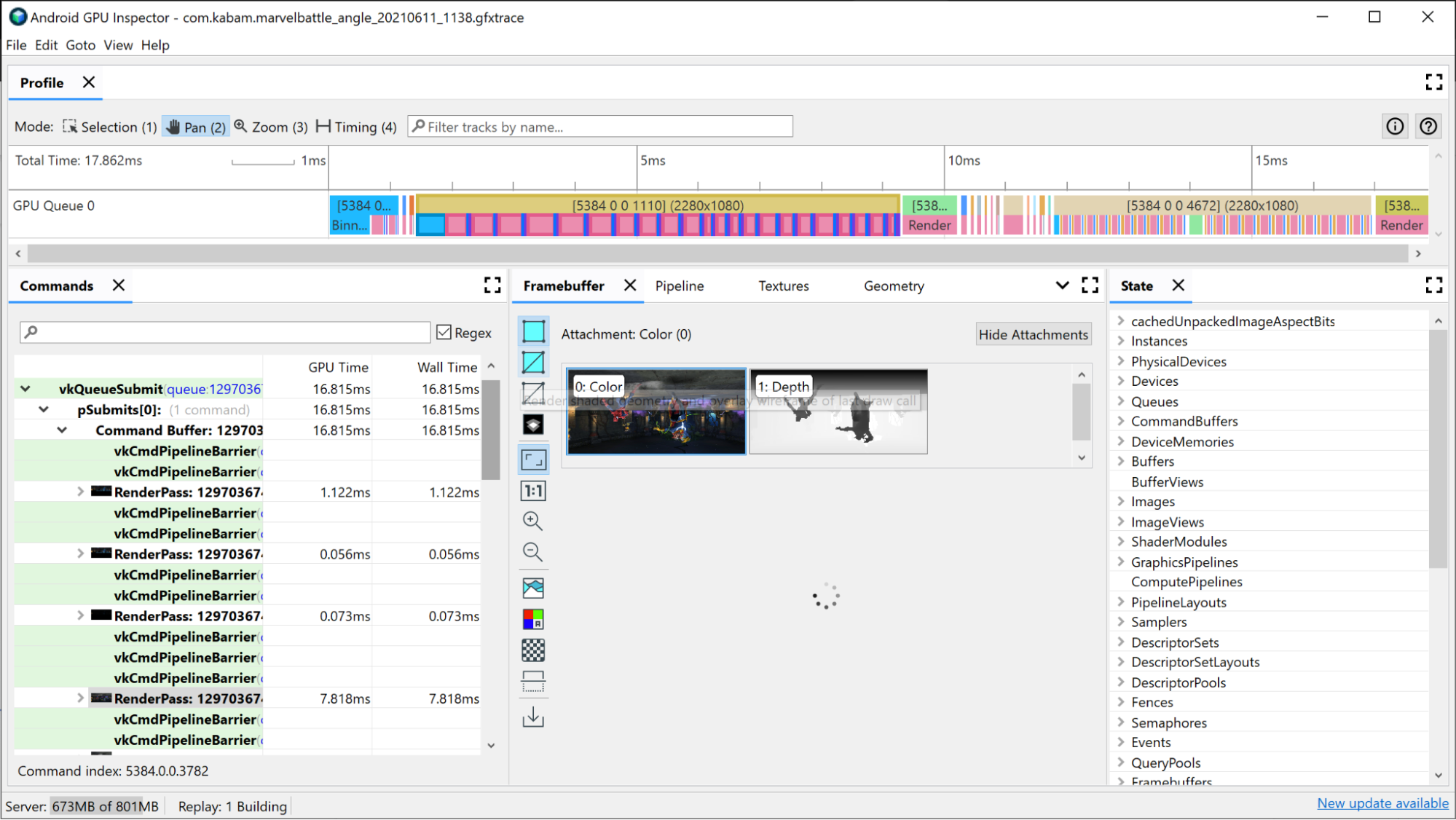
El primer criterio que puedes usar para investigar los pases de procesamiento es cuánto tiempo tardan. Lo más probable es que el pase de renderización más largo sea el que tiene el mayor potencial de mejora, así que comienza por analizarlo.
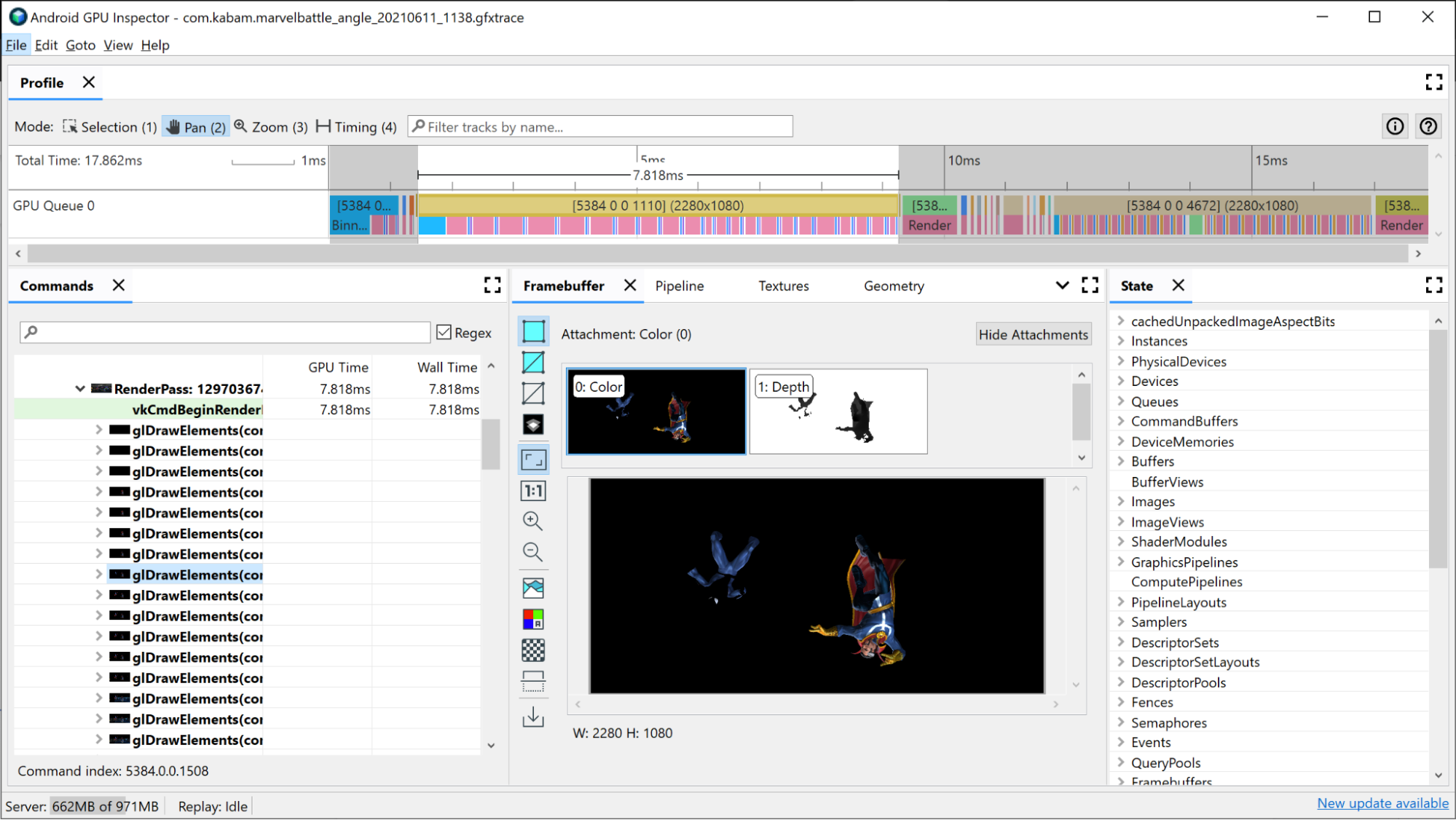
La porción de GPU correspondiente al pase de renderización relevante ya presentará información sobre lo que sucede dentro del pase de renderización:
- Discretización: Cuando los vértices se colocan en discretizaciones según el lugar donde se ubiquen en la pantalla
- Renderización: Donde los píxeles o fragmentos están sombreados
- Carga/almacenamiento de GMEM: Cuando se carga o almacena el contenido de un búfer de fotogramas desde la memoria interna de la GPU hacia la memoria principal
Para tener una idea de dónde pueden encontrarse los posibles cuellos de botella, observa el tiempo que tarda cada uno de ellos en el pase de renderización. Por ejemplo:
- Si la discretización toma una gran cantidad de tiempo, esto sugiere un cuello de botella con datos de vértices que sugiere demasiados vértices o vértices grandes, o bien otros problemas relacionados con estos.
- Si el procesamiento requiere la mayor parte del tiempo, esto sugiere que el sombreado es el cuello de botella. Las causas posibles pueden ser sombreadores complejos, demasiadas recuperaciones de texturas, la renderización en un búfer de fotogramas de alta resolución cuando no es necesario o hay otros problemas relacionados.
Las cargas y tiendas de GMEM también son algo a tener en cuenta. Resulta costoso mover elementos de la memoria de gráficos a la memoria principal, por lo que minimizar la cantidad de operaciones de carga o almacenamiento también ayudará con el rendimiento. Un ejemplo común de esto es tener una plantilla o profundidad de almacén de GMEM, que escribe el búfer de profundidad o símbolos en la memoria principal. Si no usas ese búfer en futuros pases de renderización, esta operación de almacenamiento se puede eliminar y ahorrarás tiempo de fotogramas y ancho de banda de memoria.
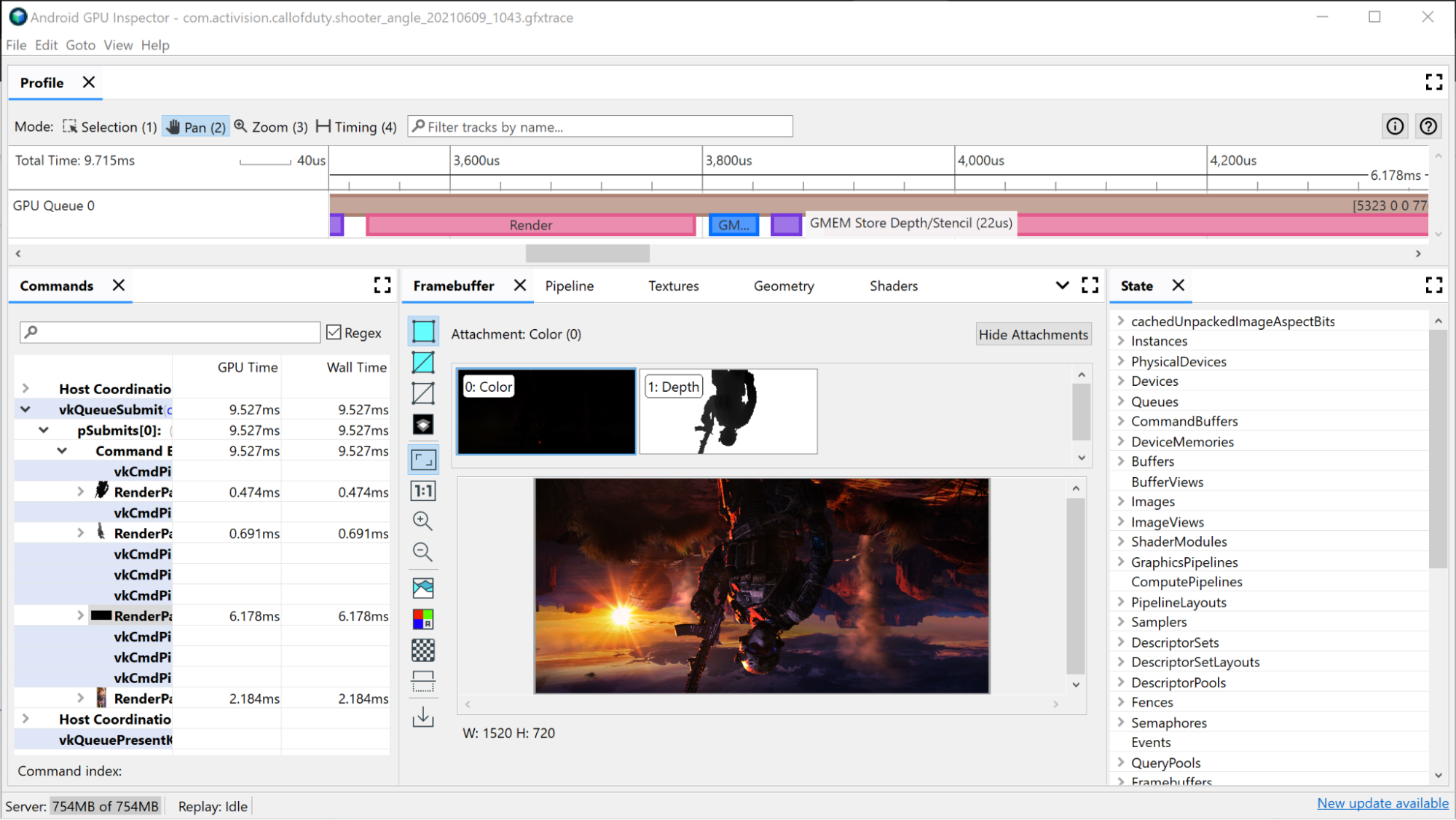
Investigación de pase de procesamiento grande
Para ver todos los comandos de dibujo individuales que se emitieron durante el pase de renderización, haz lo siguiente:
Haz clic en el pase de renderización en el cronograma. Esto abrirá el pase de renderización en la jerarquía que se encuentra en el panel Commands del Generador de perfiles de marcos.
Haz clic en el menú del pase de renderización, en el que se muestran todos los comandos de dibujo individuales que se emitieron durante el pase. Si se trata de una aplicación OpenGL, puedes investigar aún más y ver los comandos de Vulkan emitidos por ANGLE.
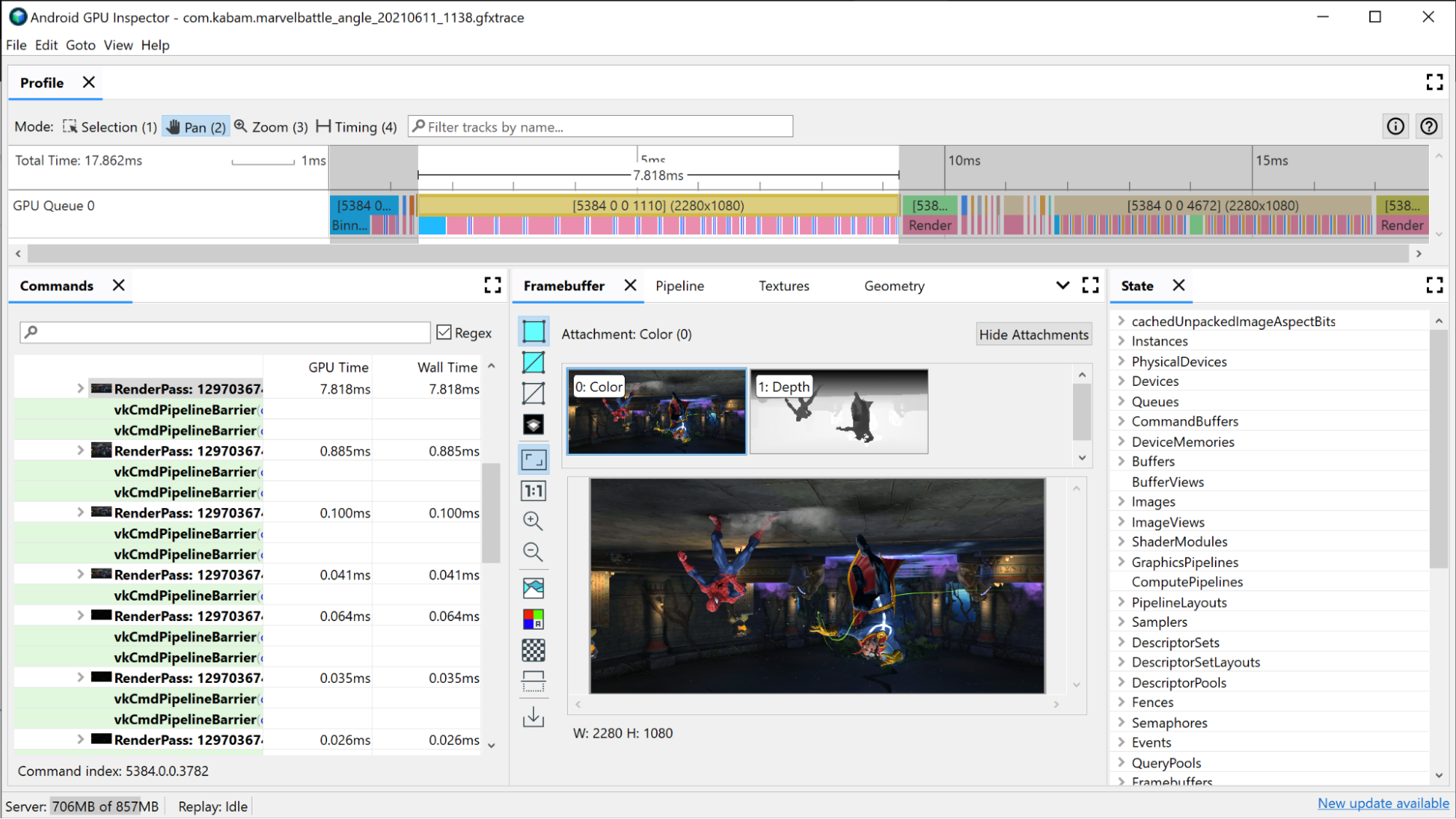
Selecciona una de las llamadas de dibujo. Se abrirá el panel Framebuffer, que muestra todos los adjuntos de búfer de fotogramas que se vincularon durante este dibujo, y el resultado final de esta en el búfer de fotogramas conectado. Aquí también puedes usar AGI para abrir las llamadas de dibujo anterior y siguiente, y comparar la diferencia entre ambas. Si son visualmente casi idénticos, esto sugiere una oportunidad para eliminar una llamada de dibujo que no contribuye a la imagen final.
Cuando abres el panel Pipeline para este dibujo, se muestra el estado que usa la canalización de gráficos a fin de ejecutar esta llamada de dibujo.
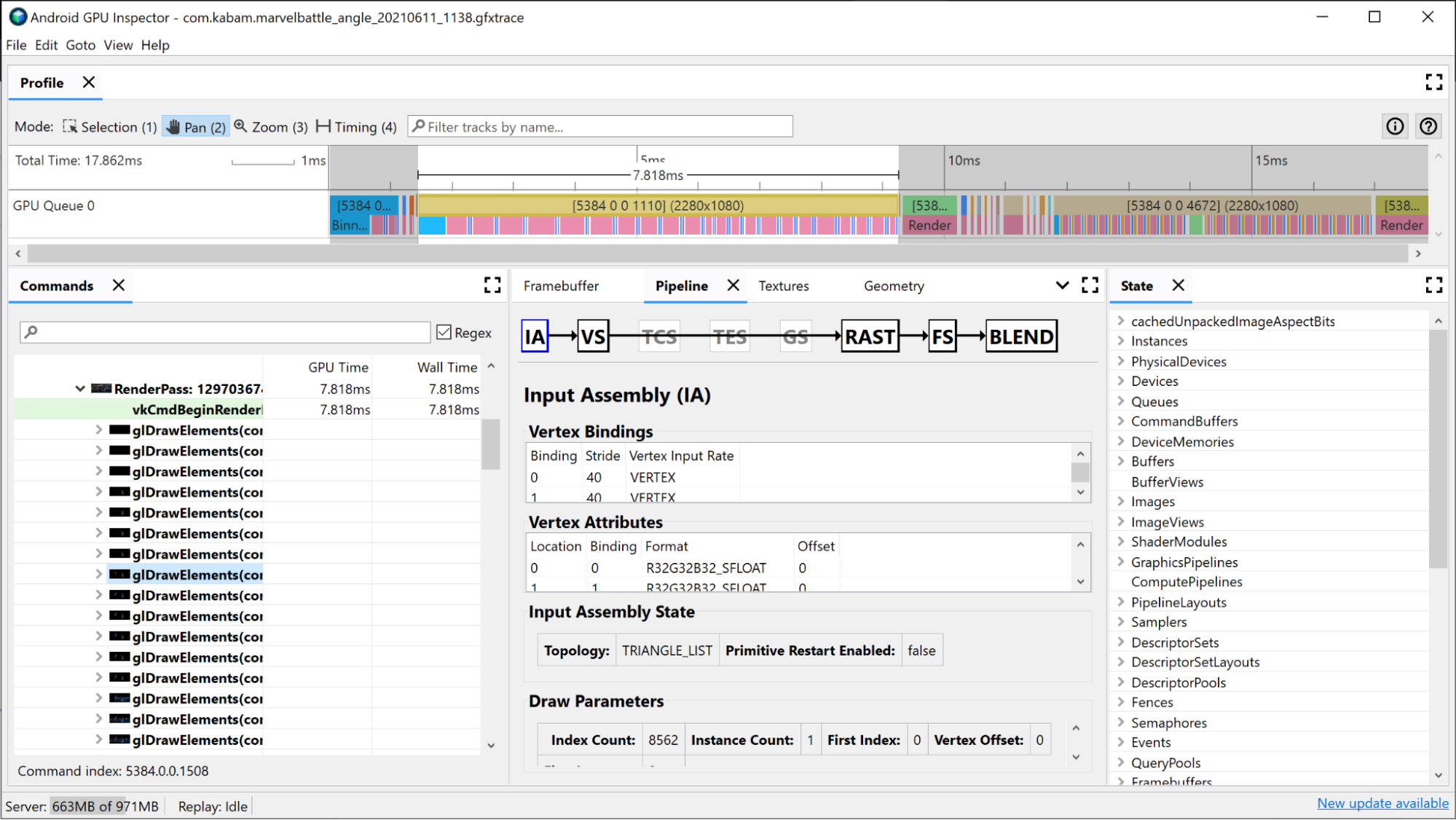
El ensamblador de entrada proporciona información sobre cómo se vincularon los datos de vértices a este dibujo. Esta es una buena área para investigar si notaste que la discretización ocupa una gran parte del tiempo de tu pase de renderización. Aquí puedes obtener información sobre el formato de vértices, la cantidad de vértices dibujados y cómo estos se disponen en la memoria. Para obtener más información al respecto, consulta Analiza formatos de vértices.
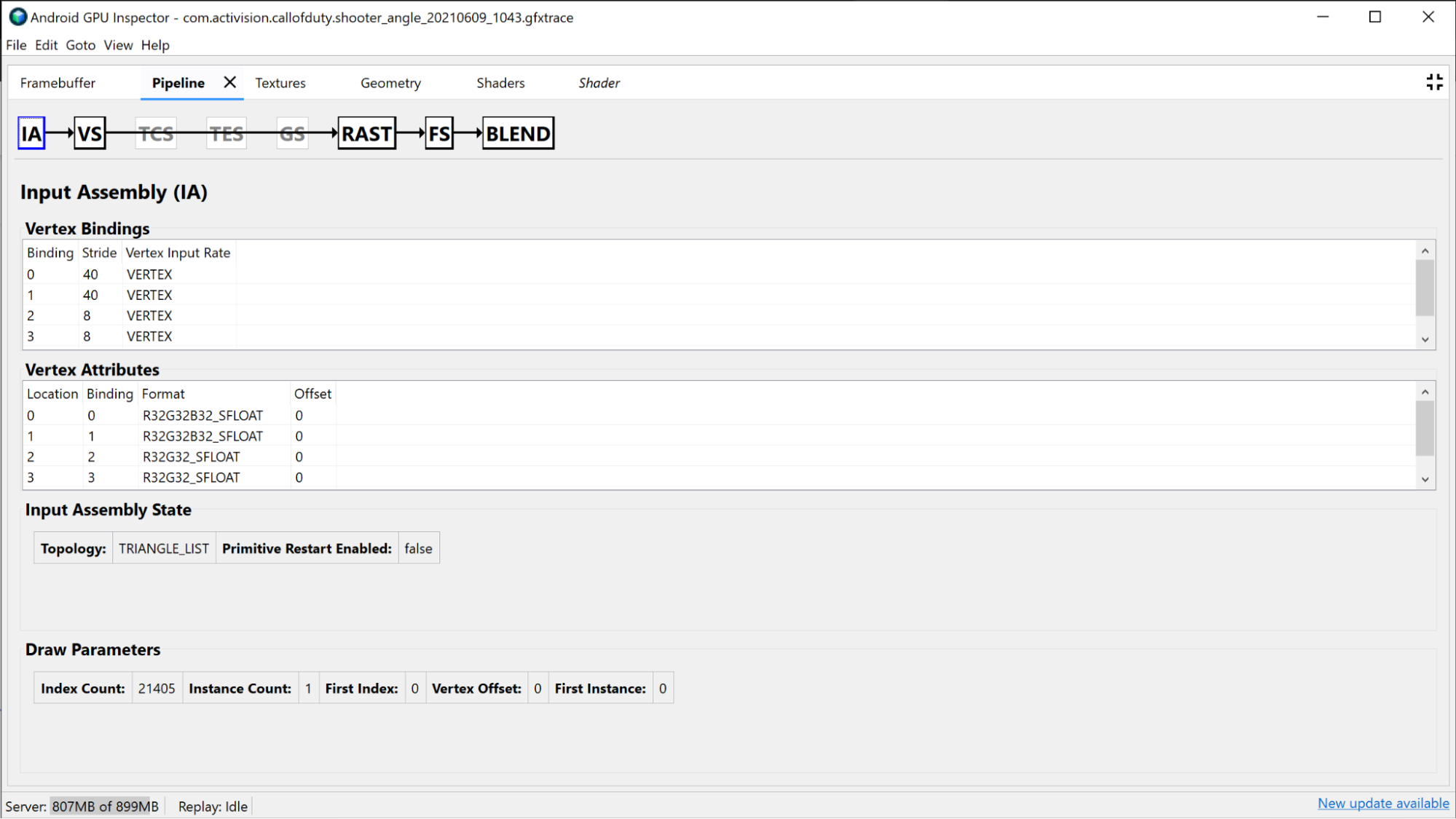
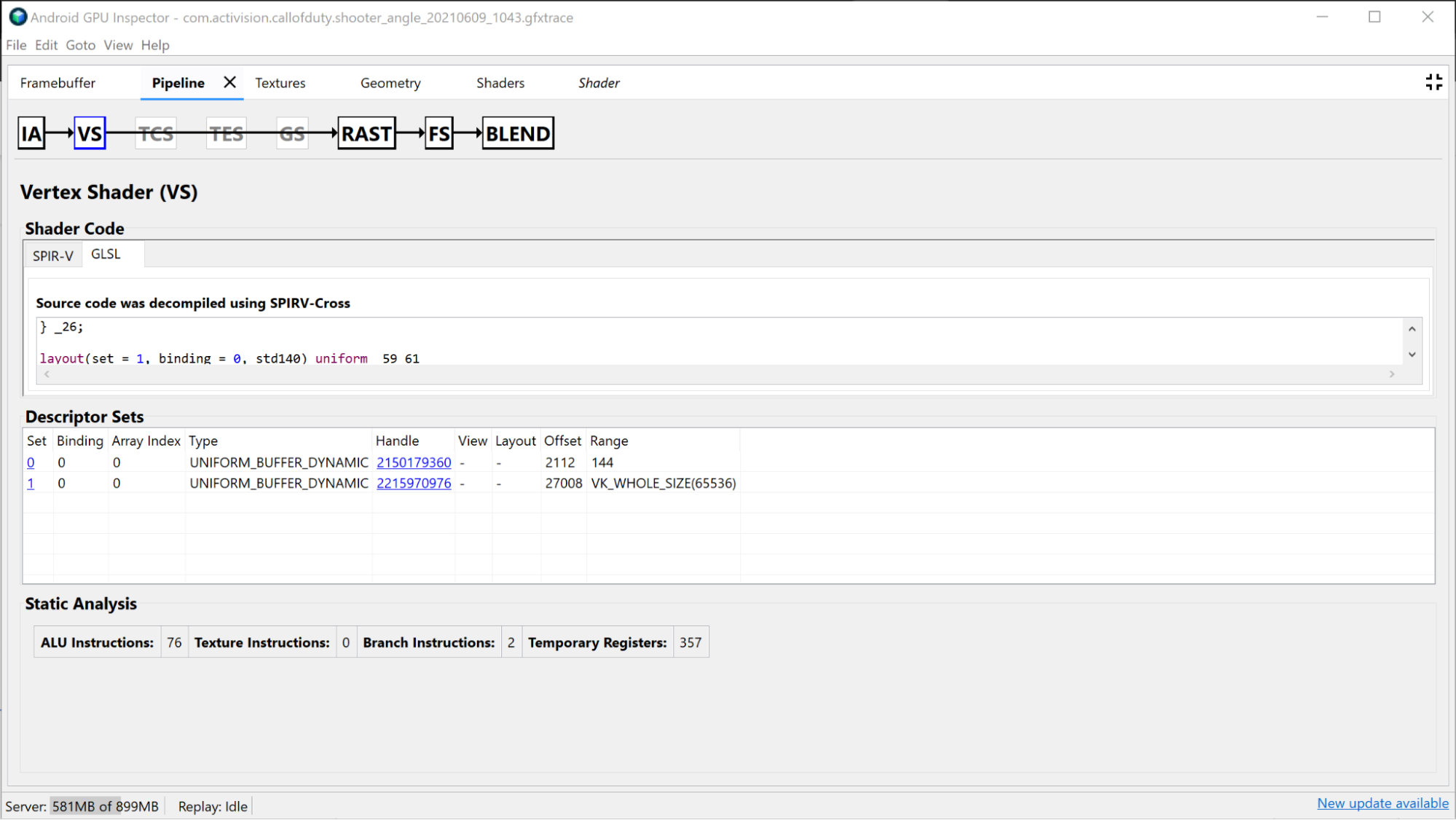
En la sección Sombreador de Vertex, se proporciona información sobre el sombreador de vértices que usaste durante este dibujo y también puede ser un buen lugar para investigar si la discretización se identificó como un problema. Puedes ver el SPIR-V y el GLSL descompilado del sombreador utilizado y, además, investigar los Uniform Buffers vinculados para esta llamada. Consulta Cómo analizar el rendimiento del sombreador para obtener más detalles.
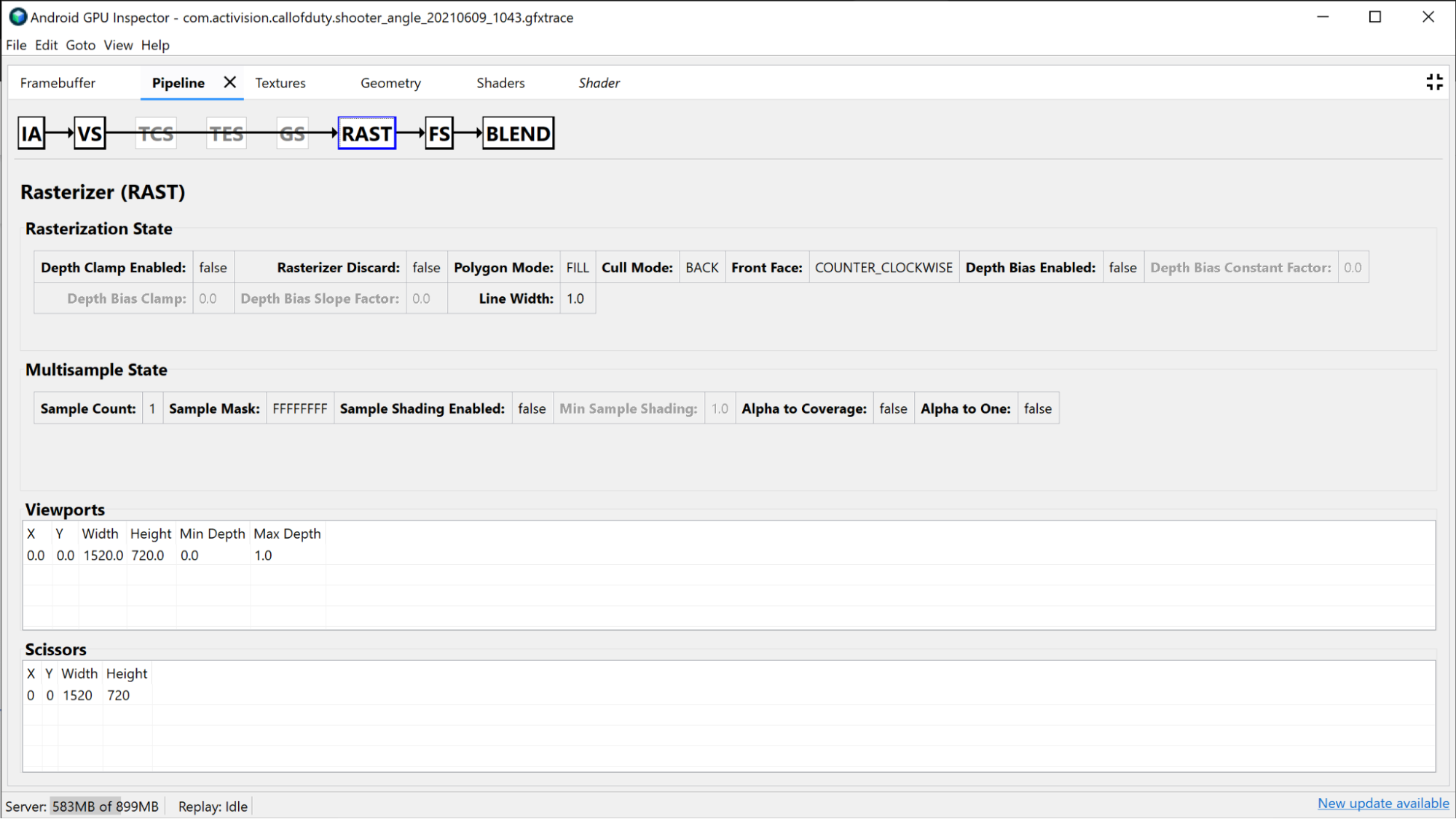
En la sección Rasterizador, se muestra información sobre la configuración de funciones más fijas de la canalización y se puede usar más para depurar fines de depuración del estado de funciones fijas, como viewport, tijera, estado de profundidad y modo de polígono.
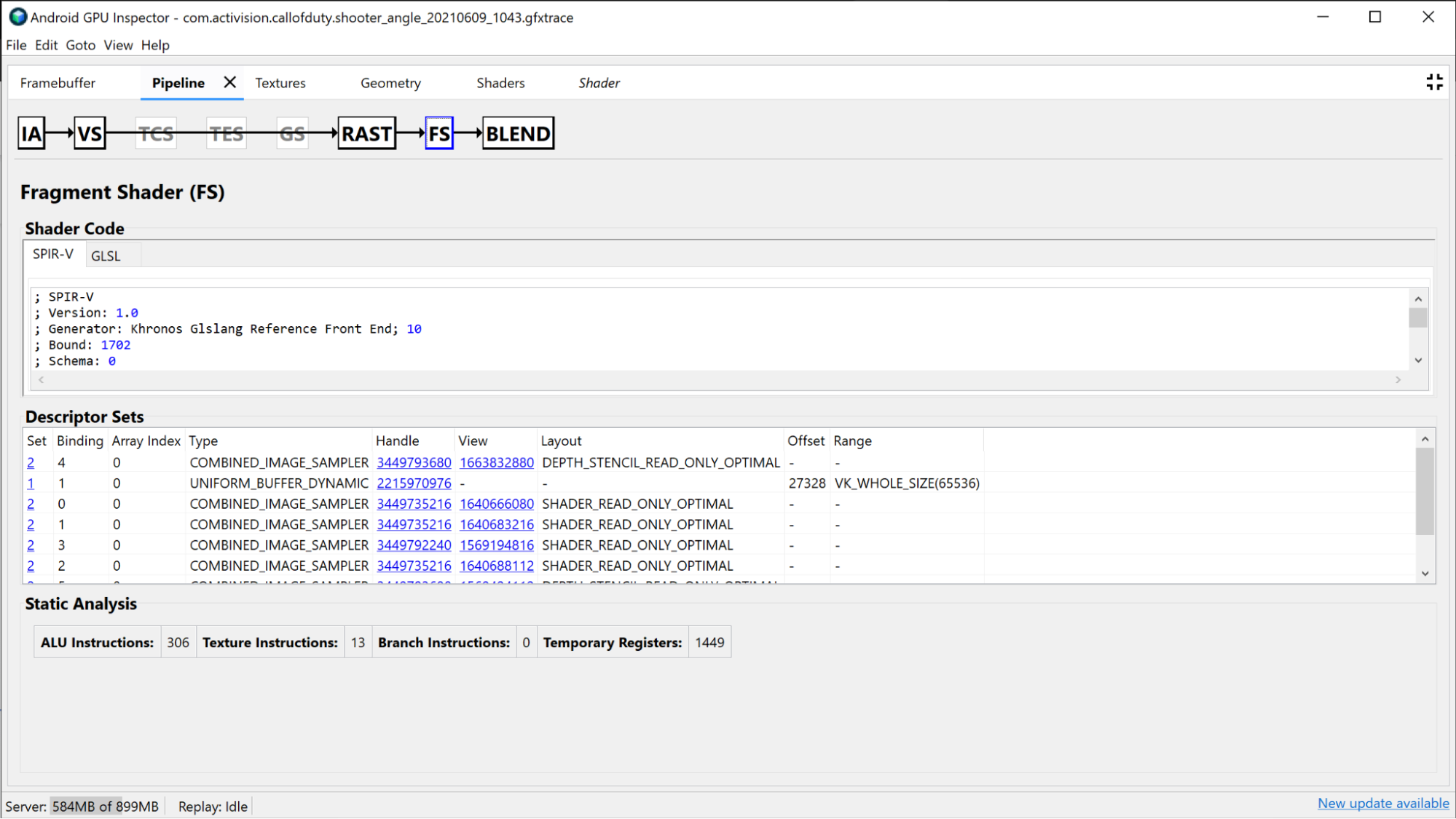
La sección Sombreador de fragmentos proporciona mucha de la misma información que se encuentra en la sección Sombreador de Vertex, pero específica del Sombreador de fragmentos. En este caso, puedes ver qué texturas se vinculan e investigarlas haciendo clic en el controlador.
Investigación de pase de renderización más pequeña
Otro criterio que puedes usar para mejorar el rendimiento de tu GPU es la observación de grupos de pases de procesamiento más pequeños. En general, debes minimizar la cantidad de pases de renderización tanto como sea posible, ya que la GPU tarda un tiempo en actualizar el estado de un pase de procesamiento a otro. Por lo general, estos pases de renderización más pequeños se usan para generar mapas de sombras, aplicar un desenfoque gaussiano, estimar la luminancia, realizar efectos de procesamiento posterior o renderizar la IU. Algunas de ellas podrían consolidarse en un solo pase de renderización o incluso eliminarse por completo si no afectan a la imagen general lo suficiente como para justificar el costo.