
AGI Frame Profiler позволяет вам исследовать ваши шейдеры, выбрав вызов отрисовки на одном из наших проходов рендеринга и просмотрев раздел «Вершинный шейдер» или раздел «Фрагментный шейдер» на панели «Конвейер» .
Здесь вы найдете полезную статистику, полученную в результате статического анализа кода шейдера, а также сборки стандартного переносимого промежуточного представления (SPIR-V), в которую был скомпилирован наш GLSL. Также имеется вкладка для просмотра представления исходного GLSL (с сгенерированными компилятором именами для переменных, функций и т. д.), которое было декомпилировано с помощью SPIR-V Cross, чтобы обеспечить дополнительный контекст для SPIR-V.
Статический анализ
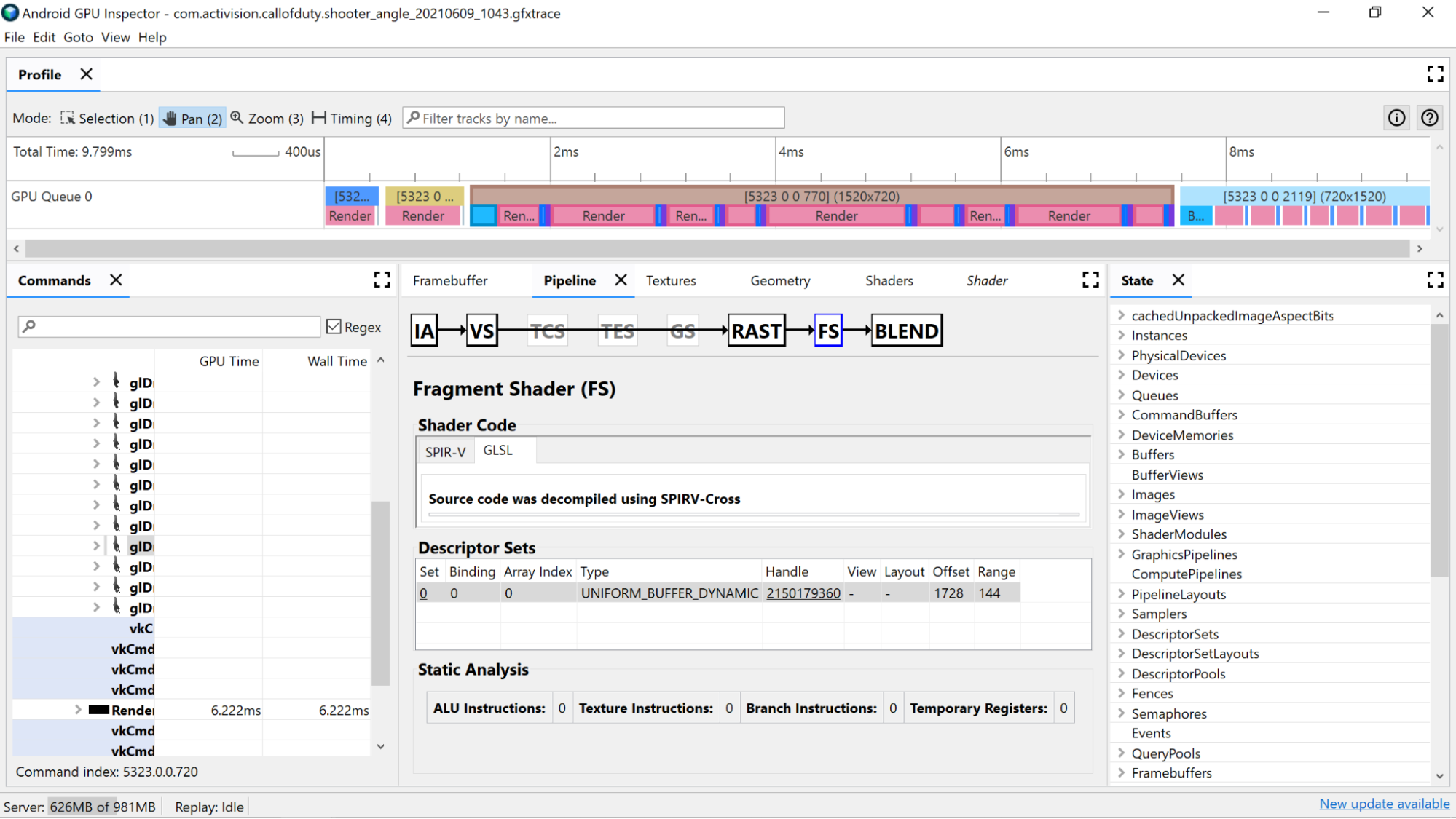
Используйте счетчики статического анализа для просмотра низкоуровневых операций в шейдере.
Инструкции ALU : этот счетчик показывает количество операций ALU (сложение, умножение, деление и т. д.), выполняемых в шейдере, и является хорошим показателем сложности шейдера. Постарайтесь минимизировать это значение.
Рефакторинг общих вычислений или упрощение вычислений, выполняемых в шейдере, могут помочь уменьшить количество необходимых инструкций.
Инструкции по текстурам : этот счетчик показывает, сколько раз в шейдере происходит выборка текстуры.
- Выборка текстур может быть дорогостоящей в зависимости от типа текстур, из которых производится выборка, поэтому перекрестные ссылки на код шейдера с привязанными текстурами, найденными в разделе «Наборы дескрипторов» , могут предоставить дополнительную информацию о типах используемых текстур.
- Избегайте произвольного доступа при выборке текстур, поскольку такое поведение не идеально подходит для кэширования текстур.
Инструкции ветвления : этот счетчик показывает количество операций ветвления в шейдере. Минимизация ветвления идеально подходит для параллельных процессоров, таких как графический процессор, и может даже помочь компилятору найти дополнительные оптимизации:
- Используйте такие функции, как
min,maxиclamp, чтобы избежать необходимости ветвления по числовым значениям. - Проверьте стоимость вычислений при ветвлении. Поскольку оба пути ветки выполняются во многих архитектурах, существует множество сценариев, в которых всегда выполнение вычислений происходит быстрее, чем пропуск вычислений с помощью ветки.
- Используйте такие функции, как
Временные регистры : это быстрые встроенные регистры, которые используются для хранения результатов промежуточных операций, необходимых для вычислений на графическом процессоре. Существует ограничение на количество регистров, доступных для вычислений, прежде чем графическому процессору придется использовать другую внеъядерную память для хранения промежуточных значений, что снижает общую производительность. (Этот предел зависит от модели графического процессора.)
Количество используемых временных регистров может оказаться больше, чем ожидалось, если компилятор шейдеров выполняет такие операции, как развертывание циклов, поэтому полезно сопоставить это значение с SPIR-V или декомпилированным GLSL, чтобы увидеть, что делает код.
Анализ шейдерного кода
Исследуйте сам декомпилированный код шейдера, чтобы определить, возможны ли какие-либо потенциальные улучшения.
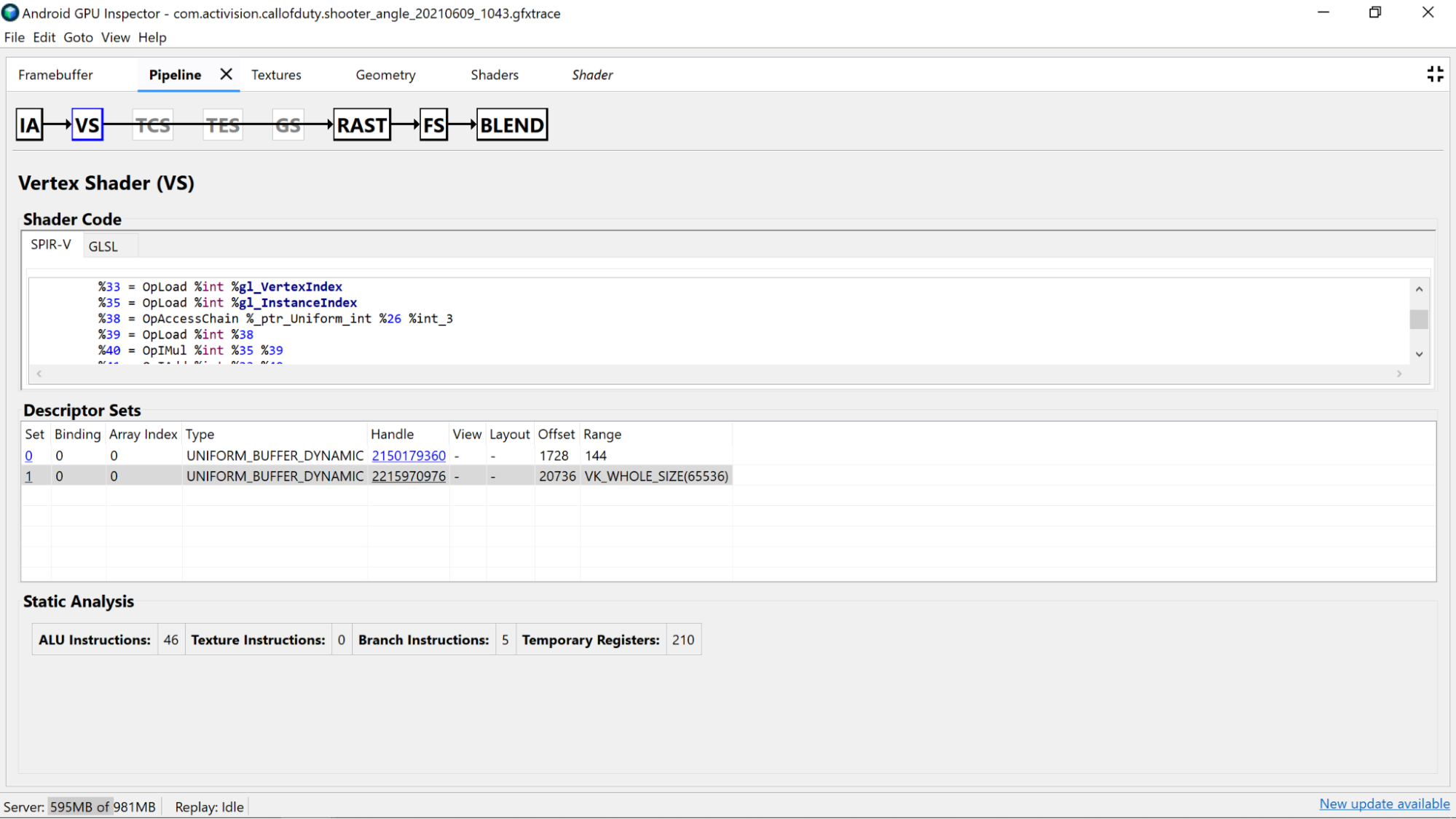
- Точность . Точность переменных шейдера может повлиять на производительность графического процессора вашего приложения.
- Попробуйте использовать модификатор точности
mediumpдля переменных везде, где это возможно, поскольку 16-битные переменные средней точности (mediump) обычно работают быстрее и более энергоэффективны, чем 32-битные переменные полной точности (highp). - Если вы не видите никаких квалификаторов точности в шейдере в объявлениях переменных или в верхней части шейдера с
precision precision-qualifier type, по умолчанию используется полная точность (highp). Обязательно обратите внимание на объявления переменных. - Использование
mediumpдля вывода вершинного шейдера также является предпочтительным по тем же причинам, которые описаны выше, а также дает преимущество в уменьшении пропускной способности памяти и потенциально использовании временного регистра, необходимого для выполнения интерполяции.
- Попробуйте использовать модификатор точности
- Единые буферы : старайтесь, чтобы размер унифицированных буферов был как можно меньшим (при соблюдении правил выравнивания). Это помогает сделать вычисления более совместимыми с кэшированием и потенциально позволяет перемещать унифицированные данные в более быстрые регистры ядра.
Удалите неиспользуемые выходные данные вершинного шейдера . Если вы обнаружите, что выходные данные вершинного шейдера не используются во фрагментном шейдере, удалите их из шейдера, чтобы освободить пропускную способность памяти и временные регистры.
Переместить вычисления из фрагментного шейдера в вершинный шейдер . Если код фрагментного шейдера выполняет вычисления, которые не зависят от состояния, специфичного для закрашиваемого фрагмента (или могут быть правильно интерполированы), идеальным решением является перемещение его в вершинный шейдер. Причина этого в том, что в большинстве приложений вершинный шейдер запускается гораздо реже по сравнению с фрагментным шейдером.