
AGI फ़्रेम प्रोफ़ाइलर की मदद से, अपने शेडर की जांच की जा सकती है. इसके लिए, हमारे रेंडर पास में से कोई ड्रॉ कॉल चुनें. इसके बाद, पाइपलाइन पैन के वर्टेक्स शेडर सेक्शन या फ़्रैगमेंट शेडर सेक्शन पर जाएं.
यहां आपको शेडर कोड के स्टैटिक विश्लेषण से मिले काम के आंकड़े मिलेंगे. साथ ही, स्टैंडर्ड पोर्टेबल इंटरमीडिएट रिप्रेजेंटेशन (एसपीआईआर-वी) असेंबली भी मिलेगी, जिसमें हमारे GLSL को कंपाइल किया गया है. SPIR-V Cross की मदद से डीकंपाइल किए गए ओरिजनल GLSL (इसमें कंपाइलर से जनरेट किए गए नाम वाले वैरिएबल, फ़ंक्शन वगैरह शामिल हैं) को देखने के लिए भी एक टैब मौजूद है. इससे SPIR-V के बारे में ज़्यादा जानकारी मिलती है.
स्टैटिक विश्लेषण
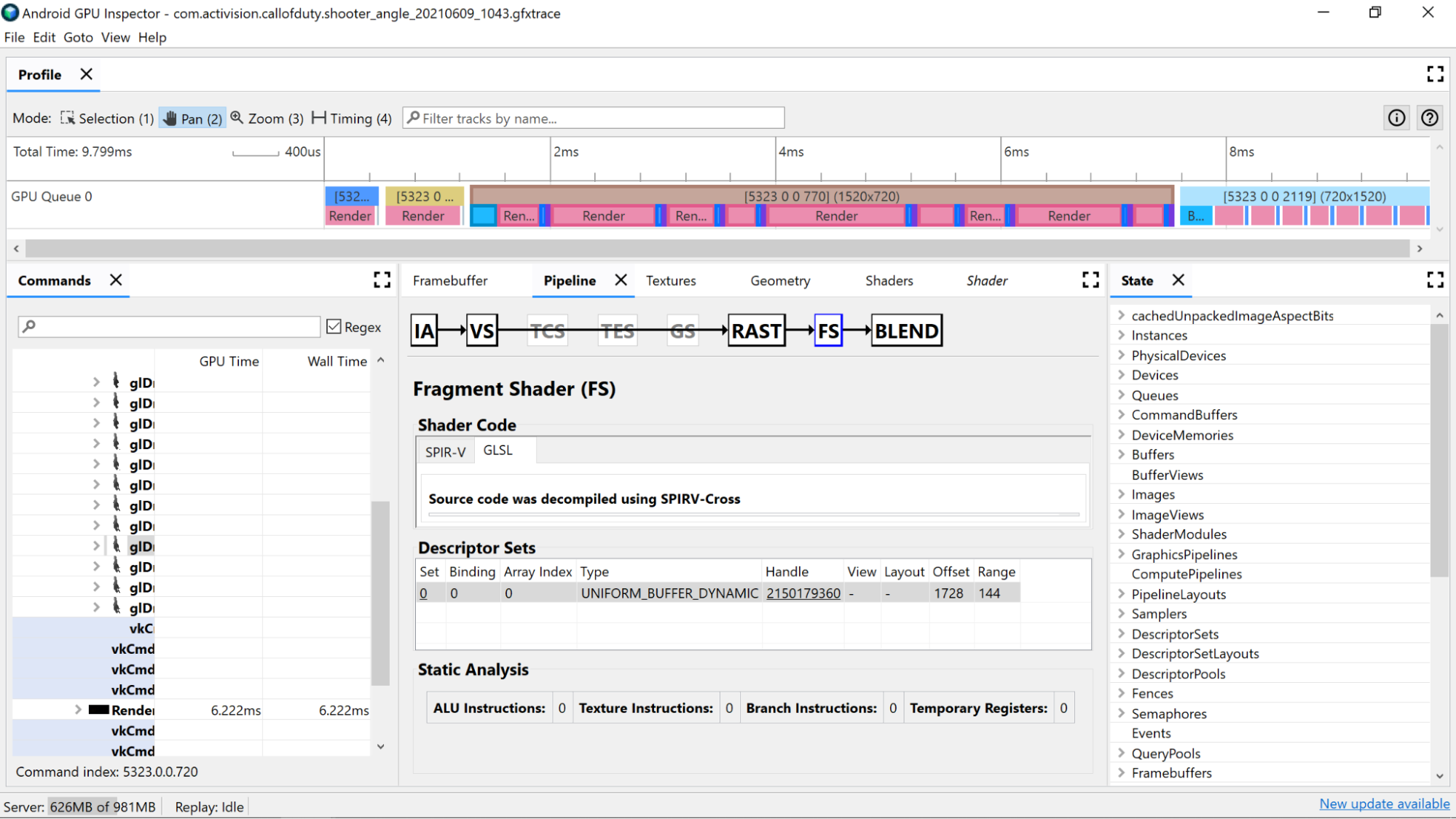
शेडर में कम लेवल के ऑपरेशन देखने के लिए, स्टैटिक विश्लेषण काउंटर का इस्तेमाल करें.
एएलयू निर्देश: इस संख्या से पता चलता है कि शेडर में एएलयू के कितने ऑपरेशन (जोड़ना, गुणा करना, भाग देना वगैरह) किए जा रहे हैं. इससे यह भी पता चलता है कि शेडर कितना जटिल है. इस वैल्यू को कम करने की कोशिश करें.
सामान्य कंप्यूटेशन को रीफ़ैक्टर करने या शेडर में किए गए कंप्यूटेशन को आसान बनाने से, ज़रूरी निर्देशों की संख्या कम की जा सकती है.
टेक्सचर के निर्देश: इस संख्या से पता चलता है कि शेडर में टेक्सचर सैंपलिंग कितनी बार होती है.
- टेक्सचर सैंपलिंग में ज़्यादा खर्च आ सकता है. यह इस बात पर निर्भर करता है कि किस तरह के टेक्सचर से सैंपल लिया जा रहा है. इसलिए, डिसक्रिप्टर सेट सेक्शन में मौजूद बाउंड टेक्सचर के साथ शेडर कोड को क्रॉस-रेफ़रंस करने से, इस्तेमाल किए जा रहे टेक्सचर के टाइप के बारे में ज़्यादा जानकारी मिल सकती है.
- टेक्सचर की सैंपलिंग करते समय, रैंडम ऐक्सेस से बचें. ऐसा इसलिए, क्योंकि यह तरीका टेक्सचर-कैशिंग के लिए सही नहीं है.
ब्रांच के निर्देश: इस संख्या से, शेडर में ब्रांच ऑपरेशन की संख्या का पता चलता है. पैरलल प्रोसेसर, जैसे कि जीपीयू पर ब्रांचिंग को कम करना सबसे सही होता है. इससे कंपाइलर को ज़्यादा ऑप्टिमाइज़ेशन ढूंढने में भी मदद मिल सकती है:
min,max, औरclampजैसे फ़ंक्शन का इस्तेमाल करें, ताकि आपको संख्यात्मक वैल्यू के आधार पर ब्रांच बनाने की ज़रूरत न पड़े.- ब्रांचिंग पर कंप्यूटेशन की लागत की जांच करें. कई आर्किटेक्चर में, ब्रांच के दोनों पाथ को एक्ज़ीक्यूट किया जाता है. इसलिए, कई ऐसे मामले होते हैं जिनमें ब्रांच के साथ कंप्यूटेशन को स्किप करने के बजाय, हमेशा कंप्यूटेशन करना ज़्यादा तेज़ होता है.
टेंपररी रजिस्टर: ये तेज़ और ऑन-कोर रजिस्टर होते हैं. इनका इस्तेमाल, GPU पर कंप्यूटेशन के लिए ज़रूरी इंटरमीडिएट ऑपरेशनों के नतीजों को सेव करने के लिए किया जाता है. कंप्यूटेशन के लिए उपलब्ध रजिस्टर की संख्या सीमित होती है. इससे पहले कि जीपीयू को इंटरमीडिएट वैल्यू सेव करने के लिए, अन्य ऑफ-कोर मेमोरी का इस्तेमाल करना पड़े, इससे परफ़ॉर्मेंस कम हो जाती है. (यह सीमा, जीपीयू मॉडल के हिसाब से अलग-अलग होती है.)
अगर शेडर कंपाइलर, लूप को अनरोल करने जैसी कार्रवाइयां करता है, तो इस्तेमाल किए गए रजिस्टर की संख्या उम्मीद से ज़्यादा हो सकती है. इसलिए, इस वैल्यू की तुलना SPIR-V या डीकंपाइल किए गए GLSL से करना अच्छा होता है, ताकि यह पता चल सके कि कोड क्या कर रहा है.
शेडर कोड का विश्लेषण
डीकंपाइल किए गए शेडर कोड की जांच करें. इससे यह पता चलेगा कि क्या इसमें कोई सुधार किया जा सकता है.
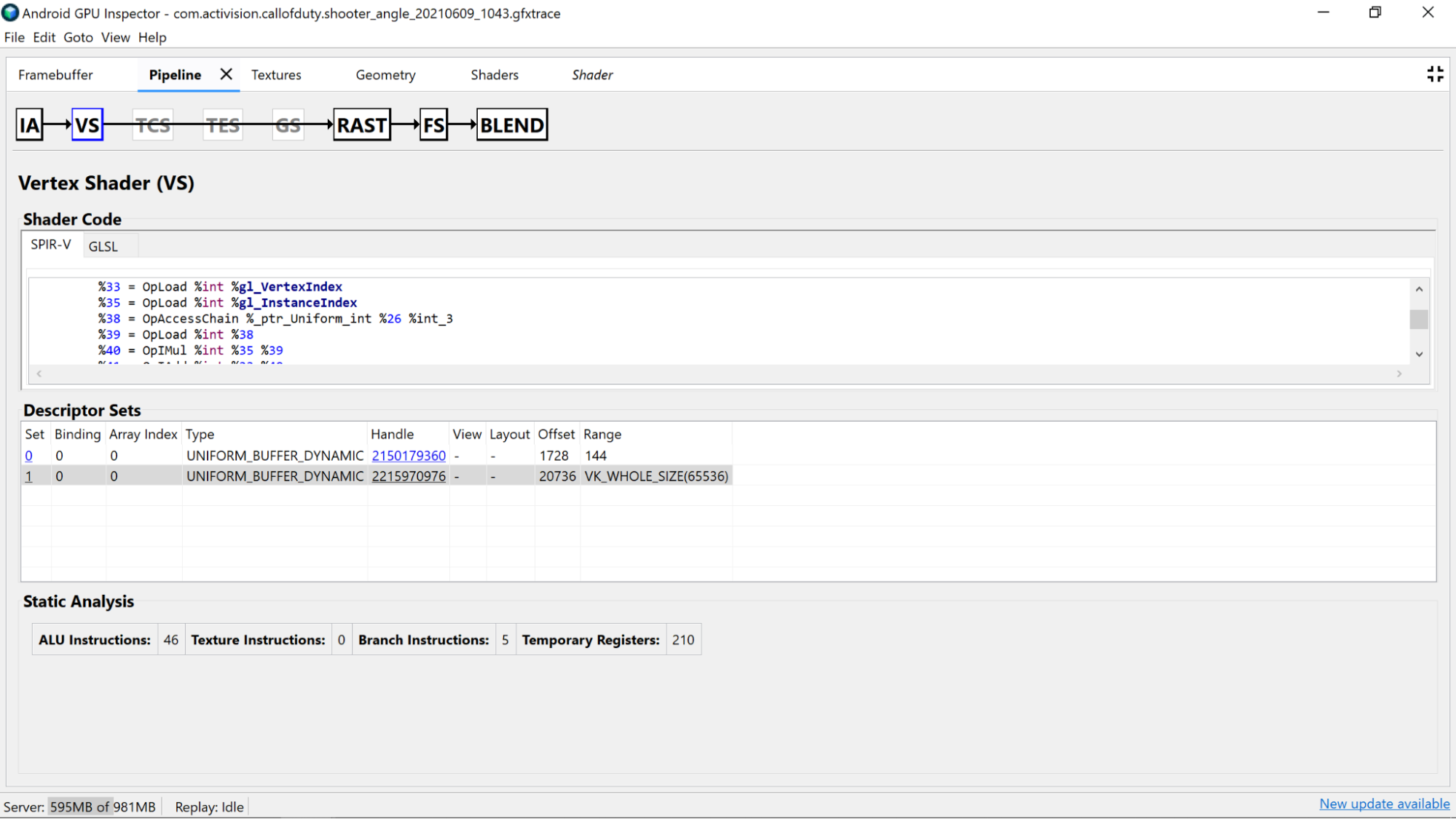
- सटीकता: शेडर वैरिएबल की सटीकता से, आपके ऐप्लिकेशन के GPU परफ़ॉर्मेंस पर असर पड़ सकता है.
- जहां भी हो सके, वैरिएबल पर
mediumpप्रिसिज़न मॉडिफ़ायर का इस्तेमाल करें. ऐसा इसलिए, क्योंकि मीडियम प्रिसिज़न (mediump) वाले 16-बिट वैरिएबल, आम तौर पर फ़ुल प्रिसिज़न (highp) वाले 32-बिट वैरिएबल की तुलना में ज़्यादा तेज़ और कम बैटरी खर्च करते हैं. - अगर आपको वैरिएबल डिक्लेरेशन के लिए शेडर में या
precision precision-qualifier typeके साथ शेडर के सबसे ऊपर कोई प्रेसिज़न क्वालिफ़ायर नहीं दिखता है, तो यह डिफ़ॉल्ट रूप से फ़ुल प्रेसिज़न (highp) पर सेट होता है. वैरिएबल डिक्लेरेशन भी देखें. - ऊपर बताए गए कारणों से, वर्टेक्स शेडर आउटपुट के लिए
mediumpका इस्तेमाल करना भी बेहतर होता है. इससे मेमोरी बैंडविड्थ कम करने में भी मदद मिलती है. साथ ही, इंटरपोलेशन करने के लिए ज़रूरी अस्थायी रजिस्टर के इस्तेमाल को भी कम किया जा सकता है.
- जहां भी हो सके, वैरिएबल पर
- यूनिफ़ॉर्म बफ़र: अलाइनमेंट के नियमों का पालन करते हुए, यूनिफ़ॉर्म बफ़र का साइज़ जितना हो सके उतना छोटा रखें. इससे कंप्यूटेशन को कैश मेमोरी के साथ ज़्यादा कंपैटिबल बनाने में मदद मिलती है. साथ ही, इससे एक जैसे डेटा को तेज़ी से ऑन-कोर रजिस्टर में प्रमोट किया जा सकता है.
इस्तेमाल नहीं किए गए वर्टेक्स शेडर आउटपुट हटाएं: अगर आपको फ़्रैगमेंट शेडर में वर्टेक्स शेडर आउटपुट का इस्तेमाल नहीं किया जा रहा है, तो उन्हें शेडर से हटा दें. इससे मेमोरी बैंडविड्थ और अस्थायी रजिस्टर खाली हो जाएंगे.
कैलकुलेशन को फ़्रैगमेंट शेडर से वर्टेक्स शेडर में ले जाएं: अगर फ़्रैगमेंट शेडर कोड ऐसी कैलकुलेशन करता है जो शेड किए जा रहे फ़्रैगमेंट की स्थिति से अलग होती हैं या जिन्हें सही तरीके से इंटरपोलेट किया जा सकता है, तो उन्हें वर्टेक्स शेडर में ले जाना सबसे सही होता है. इसकी वजह यह है कि ज़्यादातर ऐप्लिकेशन में, फ़्रैगमेंट शेडर की तुलना में वर्टेक्स शेडर बहुत कम बार चलता है.