
AGI Frame Profiler به شما این امکان را میدهد که با انتخاب یک فراخوانی از یکی از پاسهای رندر ما، و عبور از بخش Vertex Shader یا Fragment Shader در پنجره Pipeline ، سایهزنهای خود را بررسی کنید.
در اینجا آمار مفیدی را خواهید یافت که از تجزیه و تحلیل استاتیک کد سایه زن، و همچنین مجموعه استاندارد قابل حمل متوسط (SPIR-V) که GLSL ما به آن کامپایل شده است، بیابید. همچنین یک برگه برای مشاهده نمایشی از GLSL اصلی (با نام های تولید شده از کامپایلر برای متغیرها، توابع و موارد دیگر) وجود دارد که با SPIR-V Cross decompiled شده است تا زمینه اضافی برای SPIR-V فراهم شود.
تجزیه و تحلیل استاتیک
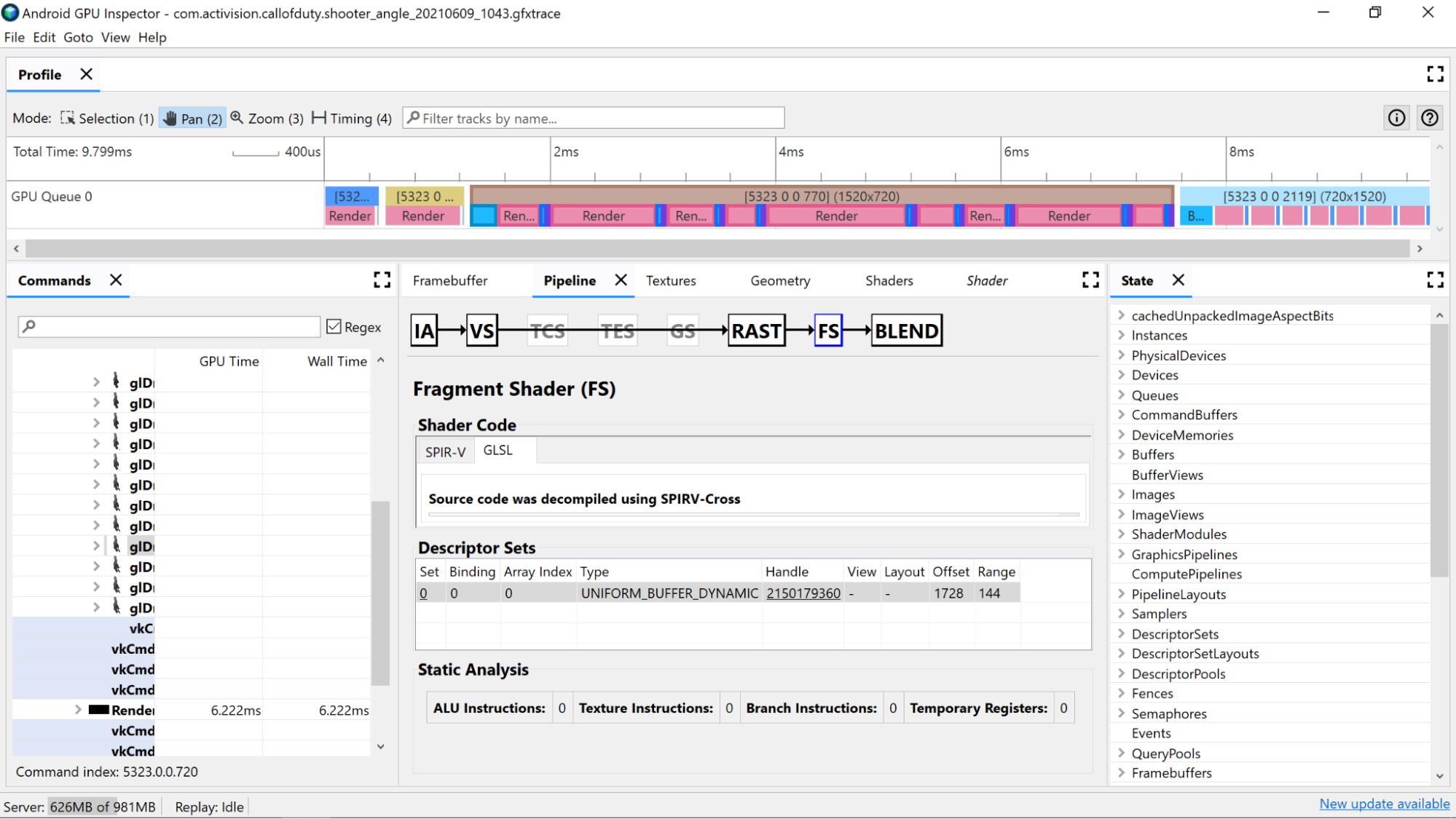
از شمارنده های تحلیل استاتیک برای مشاهده عملیات سطح پایین در سایه زن استفاده کنید.
دستورالعمل های ALU : این شمارش تعداد عملیات ALU (جمع، ضرب، تقسیم، و موارد دیگر) را نشان می دهد که در سایه زن اجرا می شوند و یک پروکسی خوب برای پیچیدگی سایه زن است. سعی کنید این مقدار را به حداقل برسانید.
تغییر محاسبات رایج یا ساده کردن محاسبات انجام شده در سایه زن می تواند به کاهش تعداد دستورالعمل های مورد نیاز کمک کند.
دستورالعملهای بافت : این شمارش تعداد دفعاتی که نمونهبرداری بافت در سایهزن انجام میشود را نشان میدهد.
- نمونهبرداری بافت بسته به نوع بافتهایی که از آنها نمونهبرداری میشود میتواند گران باشد، بنابراین ارجاع متقابل کد سایهزن با بافتهای محدود موجود در بخش Descriptor Sets میتواند اطلاعات بیشتری در مورد انواع بافتهای مورد استفاده ارائه دهد.
- هنگام نمونهبرداری از بافتها از دسترسی تصادفی اجتناب کنید، زیرا این رفتار برای ذخیرهسازی بافت ایدهآل نیست.
دستورالعمل های شعبه : این شمارش تعداد عملیات شعبه را در سایه زن نشان می دهد. به حداقل رساندن انشعاب در پردازنده های موازی مانند GPU ایده آل است و حتی می تواند به کامپایلر کمک کند تا بهینه سازی های اضافی را پیدا کند:
- از توابعی مانند
min،maxوclampاستفاده کنید تا نیازی به انشعاب در مقادیر عددی نباشد. - هزینه محاسبات را روی انشعاب آزمایش کنید. از آنجا که هر دو مسیر یک شاخه در بسیاری از معماری ها اجرا می شوند، سناریوهای زیادی وجود دارد که انجام محاسبات همیشه سریعتر از پرش از محاسبات با یک شاخه است.
- از توابعی مانند
ثبتهای موقت : اینها رجیسترهای سریع و درون هستهای هستند که برای نگهداری نتایج عملیات میانی مورد نیاز محاسبات روی GPU استفاده میشوند. محدودیتی برای تعداد رجیسترهای موجود برای محاسبات وجود دارد، قبل از اینکه GPU مجبور به استفاده از سایر حافظه های خارج از هسته برای ذخیره مقادیر میانی شود و عملکرد کلی را کاهش دهد. (این محدودیت بسته به مدل GPU متفاوت است.)
اگر کامپایلر سایه زن عملیات هایی مانند حلقه های باز کردن را انجام دهد، ممکن است تعداد ثبات های موقت مورد استفاده بیشتر از حد انتظار باشد، بنابراین خوب است که این مقدار را با SPIR-V یا GLSL دیکامپایل شده ارجاع دهید تا ببینید کد چه کار می کند.
تحلیل کد سایه زن
خود کد شیدر دکامپایل شده را بررسی کنید تا مشخص شود که آیا امکان بهبود بالقوه وجود دارد یا خیر.
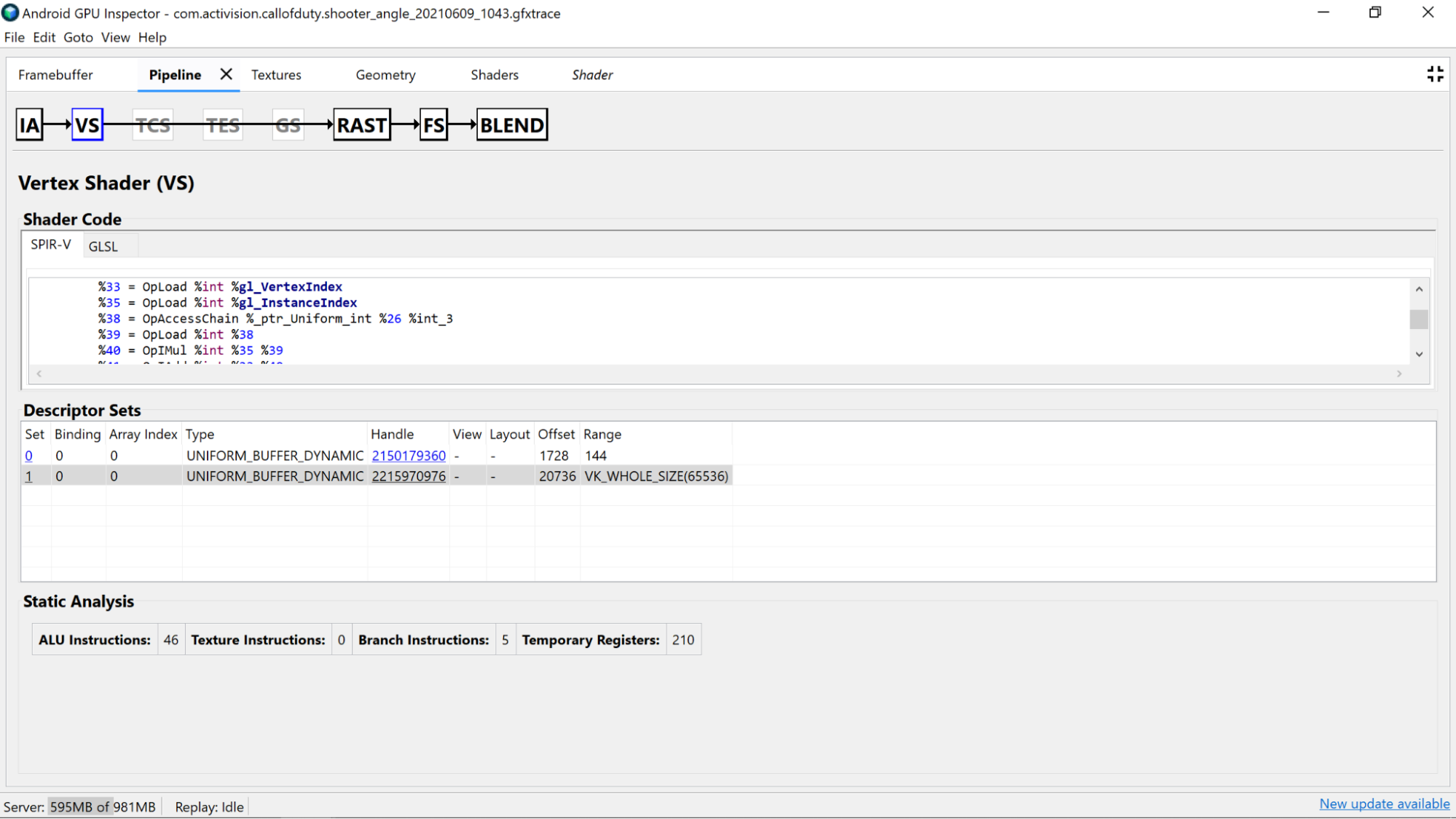
- دقت : دقت متغیرهای سایه زن می تواند بر عملکرد GPU برنامه شما تأثیر بگذارد.
- سعی کنید تا حد امکان از اصلاح کننده دقت
mediumpروی متغیرها استفاده کنید، زیرا متغیرهای 16 بیتی با دقت متوسط (mediump) معمولا سریعتر و کارآمدتر از متغیرهای 32 بیتی با دقت کامل (highp) هستند. - اگر در سایهزن در اعلانهای متغیر، یا در بالای سایهزن با
precision precision-qualifier type، هیچ معیار دقیقی را نمیبینید، بهطور پیشفرض روی دقت کامل (highp) تنظیم میشود. حتماً به اعلان های متغیر نیز توجه کنید. - استفاده از
mediumpبرای خروجی سایه زن راس نیز به همان دلایلی که در بالا توضیح داده شد ترجیح داده می شود، و همچنین دارای مزیت کاهش پهنای باند حافظه و استفاده بالقوه ثبت موقت مورد نیاز برای انجام درون یابی است.
- سعی کنید تا حد امکان از اصلاح کننده دقت
- بافرهای یکنواخت : سعی کنید اندازه بافرهای یکنواخت را تا حد امکان کوچک نگه دارید (در حالی که قوانین تراز را حفظ می کنید). این امر به سازگاری بیشتر محاسبات با حافظه پنهان کمک می کند و به طور بالقوه امکان ارتقای داده های یکنواخت را به رجیسترهای داخلی سریعتر می دهد.
حذف خروجیهای سایهزن Vertex استفادهنشده : اگر متوجه شدید که خروجیهای سایهزن رأس در سایهزن قطعه استفاده نمیشوند، آنها را از سایهزن حذف کنید تا پهنای باند حافظه و ثباتهای موقت آزاد شود.
انتقال محاسبات از Fragment Shader به Vertex Shader : اگر کد shader fragment محاسباتی را انجام می دهد که مستقل از حالت خاص قطعه در حال سایه زدن هستند (یا می توانند به درستی درون یابی شوند)، انتقال آن به سایه زن راس ایده آل است. دلیل این امر این است که در اکثر برنامه ها، سایه زن رأس در مقایسه با شیدر قطعه بسیار کمتر اجرا می شود.
AGI Frame Profiler به شما این امکان را میدهد تا با انتخاب یک فراخوانی از یکی از پاسهای رندر ما، و گذر از بخش Vertex Shader یا Fragment Shader در پنجره Pipeline ، شیدرهای خود را بررسی کنید.
در اینجا آمار مفیدی را خواهید یافت که از تجزیه و تحلیل استاتیک کد سایه زن، و همچنین مجموعه استاندارد قابل حمل متوسط (SPIR-V) که GLSL ما به آن کامپایل شده است، بیابید. همچنین یک برگه برای مشاهده نمایشی از GLSL اصلی (با نام های تولید شده از کامپایلر برای متغیرها، توابع و موارد دیگر) وجود دارد که با SPIR-V Cross decompiled شده است تا زمینه اضافی برای SPIR-V فراهم شود.
تجزیه و تحلیل استاتیک
از شمارنده های تحلیل استاتیک برای مشاهده عملیات سطح پایین در سایه زن استفاده کنید.
دستورالعمل های ALU : این شمارش تعداد عملیات ALU (جمع، ضرب، تقسیم، و موارد دیگر) را نشان می دهد که در سایه زن اجرا می شوند و یک پروکسی خوب برای پیچیدگی سایه زن است. سعی کنید این مقدار را به حداقل برسانید.
تغییر محاسبات رایج یا ساده کردن محاسبات انجام شده در سایه زن می تواند به کاهش تعداد دستورالعمل های مورد نیاز کمک کند.
دستورالعملهای بافت : این شمارش تعداد دفعاتی که نمونهبرداری بافت در سایهزن انجام میشود را نشان میدهد.
- نمونهبرداری بافت بسته به نوع بافتهایی که از آنها نمونهبرداری میشود میتواند گران باشد، بنابراین ارجاع متقابل کد سایهزن با بافتهای محدود موجود در بخش Descriptor Sets میتواند اطلاعات بیشتری در مورد انواع بافتهای مورد استفاده ارائه دهد.
- هنگام نمونهبرداری از بافتها از دسترسی تصادفی اجتناب کنید، زیرا این رفتار برای ذخیرهسازی بافت ایدهآل نیست.
دستورالعمل های شعبه : این شمارش تعداد عملیات شعبه را در سایه زن نشان می دهد. به حداقل رساندن انشعاب در پردازنده های موازی مانند GPU ایده آل است و حتی می تواند به کامپایلر کمک کند تا بهینه سازی های اضافی را پیدا کند:
- از توابعی مانند
min،maxوclampاستفاده کنید تا نیازی به انشعاب در مقادیر عددی نباشد. - هزینه محاسبات را روی انشعاب آزمایش کنید. از آنجا که هر دو مسیر یک شاخه در بسیاری از معماری ها اجرا می شوند، سناریوهای زیادی وجود دارد که انجام محاسبات همیشه سریعتر از پرش از محاسبات با یک شاخه است.
- از توابعی مانند
ثبتهای موقت : اینها رجیسترهای سریع و درون هستهای هستند که برای نگهداری نتایج عملیات میانی مورد نیاز محاسبات روی GPU استفاده میشوند. محدودیتی برای تعداد رجیسترهای موجود برای محاسبات وجود دارد، قبل از اینکه GPU مجبور به استفاده از سایر حافظه های خارج از هسته برای ذخیره مقادیر میانی شود و عملکرد کلی را کاهش دهد. (این محدودیت بسته به مدل GPU متفاوت است.)
اگر کامپایلر سایه زن عملیات هایی مانند حلقه های باز کردن را انجام دهد، ممکن است تعداد ثبات های موقت مورد استفاده بیشتر از حد انتظار باشد، بنابراین خوب است که این مقدار را با SPIR-V یا GLSL دیکامپایل شده ارجاع دهید تا ببینید کد چه کار می کند.
تحلیل کد سایه زن
خود کد شیدر دکامپایل شده را بررسی کنید تا مشخص شود که آیا امکان بهبود بالقوه وجود دارد یا خیر.
- دقت : دقت متغیرهای سایه زن می تواند بر عملکرد GPU برنامه شما تأثیر بگذارد.
- سعی کنید تا حد امکان از اصلاح کننده دقت
mediumpروی متغیرها استفاده کنید، زیرا متغیرهای 16 بیتی با دقت متوسط (mediump) معمولا سریعتر و کارآمدتر از متغیرهای 32 بیتی با دقت کامل (highp) هستند. - اگر در سایهزن در اعلانهای متغیر، یا در بالای سایهزن با
precision precision-qualifier type، هیچ معیار دقیقی را نمیبینید، بهطور پیشفرض روی دقت کامل (highp) تنظیم میشود. حتماً به اعلان های متغیر نیز توجه کنید. - استفاده از
mediumpبرای خروجی سایه زن راس نیز به همان دلایلی که در بالا توضیح داده شد ترجیح داده می شود، و همچنین دارای مزیت کاهش پهنای باند حافظه و استفاده بالقوه ثبت موقت مورد نیاز برای انجام درون یابی است.
- سعی کنید تا حد امکان از اصلاح کننده دقت
- بافرهای یکنواخت : سعی کنید اندازه بافرهای یکنواخت را تا حد امکان کوچک نگه دارید (در حالی که قوانین تراز را حفظ می کنید). این امر به سازگاری بیشتر محاسبات با حافظه پنهان کمک می کند و به طور بالقوه امکان ارتقای داده های یکنواخت را به رجیسترهای داخلی سریعتر می دهد.
حذف خروجیهای سایهزن Vertex استفادهنشده : اگر متوجه شدید که خروجیهای سایهزن رأس در سایهزن قطعه استفاده نمیشوند، آنها را از سایهزن حذف کنید تا پهنای باند حافظه و ثباتهای موقت آزاد شود.
انتقال محاسبات از Fragment Shader به Vertex Shader : اگر کد shader fragment محاسباتی را انجام می دهد که مستقل از حالت خاص قطعه در حال سایه زدن هستند (یا می توانند به درستی درون یابی شوند)، انتقال آن به سایه زن راس ایده آل است. دلیل این امر این است که در اکثر برنامه ها، سایه زن رأس در مقایسه با شیدر قطعه بسیار کمتر اجرا می شود.
AGI Frame Profiler به شما این امکان را میدهد تا با انتخاب یک فراخوانی از یکی از پاسهای رندر ما، و گذر از بخش Vertex Shader یا Fragment Shader در پنجره Pipeline ، شیدرهای خود را بررسی کنید.
در اینجا آمار مفیدی را خواهید یافت که از تجزیه و تحلیل استاتیک کد سایه زن، و همچنین مجموعه استاندارد قابل حمل متوسط (SPIR-V) که GLSL ما به آن کامپایل شده است، بیابید. همچنین یک برگه برای مشاهده نمایشی از GLSL اصلی (با نام های تولید شده از کامپایلر برای متغیرها، توابع و موارد دیگر) وجود دارد که با SPIR-V Cross decompiled شده است تا زمینه اضافی برای SPIR-V فراهم شود.
تجزیه و تحلیل استاتیک
از شمارنده های تحلیل استاتیک برای مشاهده عملیات سطح پایین در سایه زن استفاده کنید.
دستورالعمل های ALU : این شمارش تعداد عملیات ALU (جمع، ضرب، تقسیم، و موارد دیگر) را نشان می دهد که در سایه زن اجرا می شوند و یک پروکسی خوب برای پیچیدگی سایه زن است. سعی کنید این مقدار را به حداقل برسانید.
تغییر محاسبات رایج یا ساده کردن محاسبات انجام شده در سایه زن می تواند به کاهش تعداد دستورالعمل های مورد نیاز کمک کند.
دستورالعملهای بافت : این شمارش تعداد دفعاتی که نمونهبرداری بافت در سایهزن انجام میشود را نشان میدهد.
- نمونهبرداری بافت بسته به نوع بافتهایی که از آنها نمونهبرداری میشود میتواند گران باشد، بنابراین ارجاع متقابل کد سایهزن با بافتهای محدود موجود در بخش Descriptor Sets میتواند اطلاعات بیشتری در مورد انواع بافتهای مورد استفاده ارائه دهد.
- هنگام نمونهبرداری از بافتها از دسترسی تصادفی اجتناب کنید، زیرا این رفتار برای ذخیرهسازی بافت ایدهآل نیست.
دستورالعمل های شعبه : این شمارش تعداد عملیات شعبه را در سایه زن نشان می دهد. به حداقل رساندن انشعاب در پردازنده های موازی مانند GPU ایده آل است و حتی می تواند به کامپایلر کمک کند تا بهینه سازی های اضافی را پیدا کند:
- از توابعی مانند
min،maxوclampاستفاده کنید تا نیازی به انشعاب در مقادیر عددی نباشد. - هزینه محاسبات را روی انشعاب آزمایش کنید. از آنجا که هر دو مسیر یک شاخه در بسیاری از معماری ها اجرا می شوند، سناریوهای زیادی وجود دارد که انجام محاسبات همیشه سریعتر از پرش از محاسبات با یک شاخه است.
- از توابعی مانند
ثبتهای موقت : اینها رجیسترهای سریع و درون هستهای هستند که برای نگهداری نتایج عملیات میانی مورد نیاز محاسبات روی GPU استفاده میشوند. محدودیتی برای تعداد رجیسترهای موجود برای محاسبات وجود دارد، قبل از اینکه GPU مجبور به استفاده از سایر حافظه های خارج از هسته برای ذخیره مقادیر میانی شود و عملکرد کلی را کاهش دهد. (این محدودیت بسته به مدل GPU متفاوت است.)
اگر کامپایلر سایه زن عملیات هایی مانند حلقه های باز کردن را انجام دهد، ممکن است تعداد ثبات های موقت مورد استفاده بیشتر از حد انتظار باشد، بنابراین خوب است که این مقدار را با SPIR-V یا GLSL دیکامپایل شده ارجاع دهید تا ببینید کد چه کار می کند.
تحلیل کد سایه زن
خود کد شیدر دکامپایل شده را بررسی کنید تا مشخص شود که آیا امکان بهبود بالقوه وجود دارد یا خیر.
- دقت : دقت متغیرهای سایه زن می تواند بر عملکرد GPU برنامه شما تأثیر بگذارد.
- سعی کنید تا حد امکان از اصلاح کننده دقت
mediumpروی متغیرها استفاده کنید، زیرا متغیرهای 16 بیتی با دقت متوسط (mediump) معمولا سریعتر و کارآمدتر از متغیرهای 32 بیتی با دقت کامل (highp) هستند. - اگر هیچ معیار دقیقی را در سایهزن در اعلانهای متغیر نمیبینید، یا در بالای سایهزن با
precision precision-qualifier type، دقت کامل را پیشفرض میکند (highp). حتماً به اعلان های متغیر نیز توجه کنید. - استفاده از
mediumpبرای خروجی سایه زن راس نیز به همان دلایلی که در بالا توضیح داده شد ترجیح داده می شود، و همچنین دارای مزیت کاهش پهنای باند حافظه و استفاده بالقوه ثبت موقت مورد نیاز برای انجام درون یابی است.
- سعی کنید تا حد امکان از اصلاح کننده دقت
- بافرهای یکنواخت : سعی کنید اندازه بافرهای یکنواخت را تا حد امکان کوچک نگه دارید (در حالی که قوانین تراز را حفظ می کنید). این امر به سازگاری بیشتر محاسبات با حافظه پنهان کمک می کند و به طور بالقوه امکان ارتقای داده های یکنواخت را به رجیسترهای داخلی سریعتر می دهد.
حذف خروجیهای سایهزن Vertex استفادهنشده : اگر متوجه شدید که خروجیهای سایهزن رأس در سایهزن قطعه استفاده نمیشوند، آنها را از سایهزن حذف کنید تا پهنای باند حافظه و ثباتهای موقت آزاد شود.
انتقال محاسبات از Fragment Shader به Vertex Shader : اگر کد shader fragment محاسباتی را انجام می دهد که مستقل از حالت خاص قطعه در حال سایه زدن هستند (یا می توانند به درستی درون یابی شوند)، انتقال آن به سایه زن راس ایده آل است. دلیل این امر این است که در اکثر برنامه ها، سایه زن رأس در مقایسه با شیدر قطعه بسیار کمتر اجرا می شود.
AGI Frame Profiler به شما این امکان را میدهد تا با انتخاب یک فراخوانی از یکی از پاسهای رندر ما، و گذر از بخش Vertex Shader یا Fragment Shader در پنجره Pipeline ، شیدرهای خود را بررسی کنید.
در اینجا آمار مفیدی را خواهید یافت که از تجزیه و تحلیل استاتیک کد سایه زن، و همچنین مجموعه استاندارد قابل حمل متوسط (SPIR-V) که GLSL ما به آن کامپایل شده است، بیابید. همچنین یک برگه برای مشاهده نمایشی از GLSL اصلی (با نام های تولید شده از کامپایلر برای متغیرها، توابع و موارد دیگر) وجود دارد که با SPIR-V Cross decompiled شده است تا زمینه اضافی برای SPIR-V فراهم شود.
تجزیه و تحلیل استاتیک
از شمارنده های تحلیل استاتیک برای مشاهده عملیات سطح پایین در سایه زن استفاده کنید.
دستورالعمل های ALU : این شمارش تعداد عملیات ALU (جمع، ضرب، تقسیم، و موارد دیگر) را نشان می دهد که در سایه زن اجرا می شوند و یک پروکسی خوب برای پیچیدگی سایه زن است. سعی کنید این مقدار را به حداقل برسانید.
تغییر محاسبات رایج یا ساده کردن محاسبات انجام شده در سایه زن می تواند به کاهش تعداد دستورالعمل های مورد نیاز کمک کند.
دستورالعملهای بافت : این شمارش تعداد دفعاتی که نمونهبرداری بافت در سایهزن انجام میشود را نشان میدهد.
- نمونهبرداری بافت بسته به نوع بافتهایی که از آنها نمونهبرداری میشود میتواند گران باشد، بنابراین ارجاع متقابل کد سایهزن با بافتهای محدود موجود در بخش Descriptor Sets میتواند اطلاعات بیشتری در مورد انواع بافتهای مورد استفاده ارائه دهد.
- هنگام نمونهبرداری از بافتها از دسترسی تصادفی اجتناب کنید، زیرا این رفتار برای ذخیرهسازی بافت ایدهآل نیست.
دستورالعمل های شعبه : این شمارش تعداد عملیات شعبه را در سایه زن نشان می دهد. به حداقل رساندن انشعاب در پردازنده های موازی مانند GPU ایده آل است و حتی می تواند به کامپایلر کمک کند تا بهینه سازی های اضافی را پیدا کند:
- از توابعی مانند
min،maxوclampاستفاده کنید تا نیازی به انشعاب در مقادیر عددی نباشد. - هزینه محاسبات را روی انشعاب آزمایش کنید. از آنجا که هر دو مسیر یک شاخه در بسیاری از معماری ها اجرا می شوند، سناریوهای زیادی وجود دارد که انجام محاسبات همیشه سریعتر از پرش از محاسبات با یک شاخه است.
- از توابعی مانند
ثبتهای موقت : اینها رجیسترهای سریع و درون هستهای هستند که برای نگهداری نتایج عملیات میانی مورد نیاز محاسبات روی GPU استفاده میشوند. محدودیتی برای تعداد رجیسترهای موجود برای محاسبات وجود دارد، قبل از اینکه GPU مجبور به استفاده از سایر حافظه های خارج از هسته برای ذخیره مقادیر میانی شود و عملکرد کلی را کاهش دهد. (این محدودیت بسته به مدل GPU متفاوت است.)
اگر کامپایلر سایه زن عملیات هایی مانند حلقه های باز کردن را انجام دهد، ممکن است تعداد ثبات های موقت مورد استفاده بیشتر از حد انتظار باشد، بنابراین خوب است که این مقدار را با SPIR-V یا GLSL دیکامپایل شده ارجاع دهید تا ببینید کد چه کار می کند.
تحلیل کد سایه زن
خود کد شیدر دکامپایل شده را بررسی کنید تا مشخص شود که آیا امکان بهبود بالقوه وجود دارد یا خیر.
- دقت : دقت متغیرهای سایه زن می تواند بر عملکرد GPU برنامه شما تأثیر بگذارد.
- سعی کنید تا حد امکان از اصلاح کننده دقت
mediumpروی متغیرها استفاده کنید، زیرا متغیرهای 16 بیتی با دقت متوسط (mediump) معمولا سریعتر و کارآمدتر از متغیرهای 32 بیتی با دقت کامل (highp) هستند. - اگر در سایهزن در اعلانهای متغیر، یا در بالای سایهزن با
precision precision-qualifier type، هیچ معیار دقیقی را نمیبینید، بهطور پیشفرض روی دقت کامل (highp) تنظیم میشود. حتماً به اعلان های متغیر نیز توجه کنید. - استفاده از
mediumpبرای خروجی سایه زن راس نیز به همان دلایلی که در بالا توضیح داده شد ترجیح داده می شود، و همچنین دارای مزیت کاهش پهنای باند حافظه و استفاده بالقوه ثبت موقت مورد نیاز برای انجام درون یابی است.
- سعی کنید تا حد امکان از اصلاح کننده دقت
- بافرهای یکنواخت : سعی کنید اندازه بافرهای یکنواخت را تا حد امکان کوچک نگه دارید (در حالی که قوانین تراز را حفظ می کنید). این امر به سازگاری بیشتر محاسبات با حافظه پنهان کمک می کند و به طور بالقوه امکان ارتقای داده های یکنواخت را به رجیسترهای داخلی سریعتر می دهد.
حذف خروجیهای سایهزن Vertex استفادهنشده : اگر متوجه شدید که خروجیهای سایهزن رأس در سایهزن قطعه استفاده نمیشوند، آنها را از سایهزن حذف کنید تا پهنای باند حافظه و ثباتهای موقت آزاد شود.
انتقال محاسبات از Fragment Shader به Vertex Shader : اگر کد shader fragment محاسباتی را انجام می دهد که مستقل از حالت خاص قطعه در حال سایه زدن هستند (یا می توانند به درستی درون یابی شوند)، انتقال آن به سایه زن راس ایده آل است. دلیل این امر این است که در اکثر برنامه ها، سایه زن رأس در مقایسه با شیدر قطعه بسیار کمتر اجرا می شود.