
El Generador de perfiles de marcos de AGI te permite investigar tus sombreadores. Para ello, selecciona una llamada de dibujo de uno de nuestros pases de renderización y revisa la sección Vertex Shader o Fragment Shader del panel Pipeline.
Aquí encontrarás estadísticas útiles que provienen del análisis estático del código del sombreador, así como del ensamblaje de Representación Intermedia Portable Estándar (SPIR-V) en el que se compiló nuestra GLSL. También hay una pestaña para ver una representación de la GLSL original (con nombres generados por el compilador para variables, funciones y más) que se descompiló con SPIR-V Cross, a fin de proporcionar contexto adicional para SPIR-V.
Análisis estático
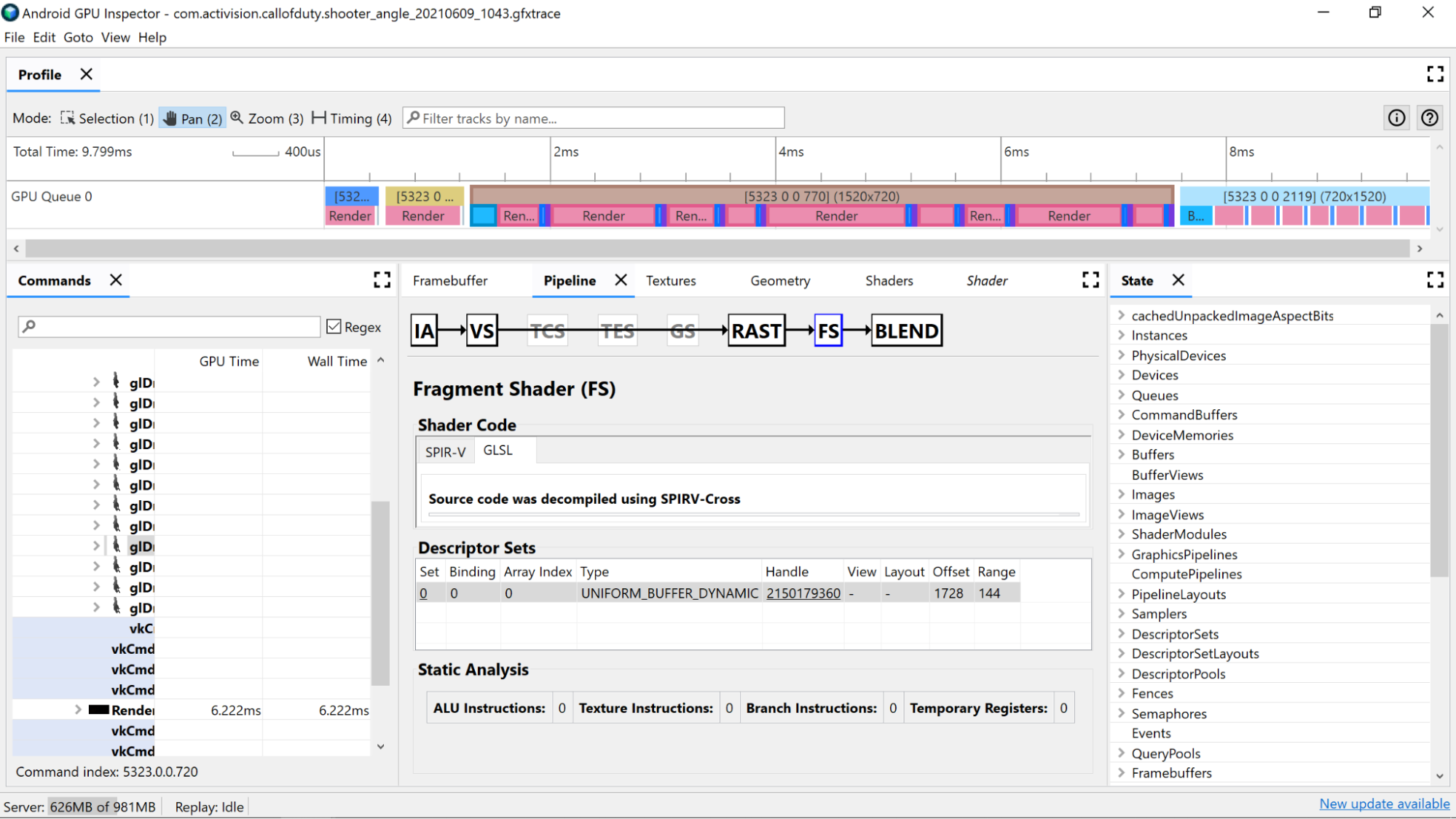
Usa contadores de análisis estáticos para ver las operaciones de bajo nivel en el sombreador.
Instrucciones de ALU: Este recuento muestra la cantidad de operaciones de ALU (agregaciones, multiplicaciones, divisiones y más) que se ejecutan dentro del sombreador y es un buen indicador de la complejidad del sombreador. Intenta minimizar este valor.
La refactorización de cálculos comunes o simplificar los cálculos realizados en el sombreador puede ayudar a reducir la cantidad de instrucciones necesarias.
Instrucciones de textura: Este recuento muestra la cantidad de veces que se produce un muestreo de textura en el sombreador.
- El muestreo de texturas puede ser costoso según el tipo de texturas de las que se realice la muestra, por lo que comparar el código del sombreador con las texturas vinculadas que se encuentran en la sección Conjuntos de descriptores puede proporcionar más información sobre los tipos de texturas que se usan.
- Evita el acceso aleatorio cuando muestres texturas, ya que este comportamiento no es ideal para el almacenamiento en caché de texturas.
Instrucciones de rama: Este recuento muestra la cantidad de operaciones de rama en el sombreador. Minimizar la ramificación es ideal en procesadores en paralelo, como la GPU, y hasta puede ayudar al compilador a encontrar optimizaciones adicionales:
- Usa funciones como
min,maxyclamppara evitar la necesidad de ramificarse en valores numéricos. - Prueba el costo del procesamiento sobre la ramificación. Debido a que ambas rutas de acceso de una rama se ejecutan en muchas arquitecturas, hay muchas situaciones en las que realizar el procesamiento siempre es más rápido que omitirlo con una rama.
- Usa funciones como
Registros temporales: Son registros rápidos en el núcleo que se usan para conservar los resultados de las operaciones intermedias que requieren los cálculos en la GPU. Existe un límite en la cantidad de registros disponibles para los procesamientos antes de que la GPU tenga que utilizar otra memoria fuera del núcleo para almacenar valores intermedios, lo que reduce el rendimiento general. (Este límite varía según el modelo de GPU).
La cantidad de registros temporales que se usan puede ser mayor de lo esperado si el compilador de sombreadores realiza operaciones como desenrollar bucles. Por lo tanto, se recomienda hacer una referencia cruzada de este valor con SPIR-V o GLSL descompilado para ver qué hace el código.
Análisis de código de sombreadores
Investiga el código del sombreador descompilado para determinar si hay posibles mejoras.
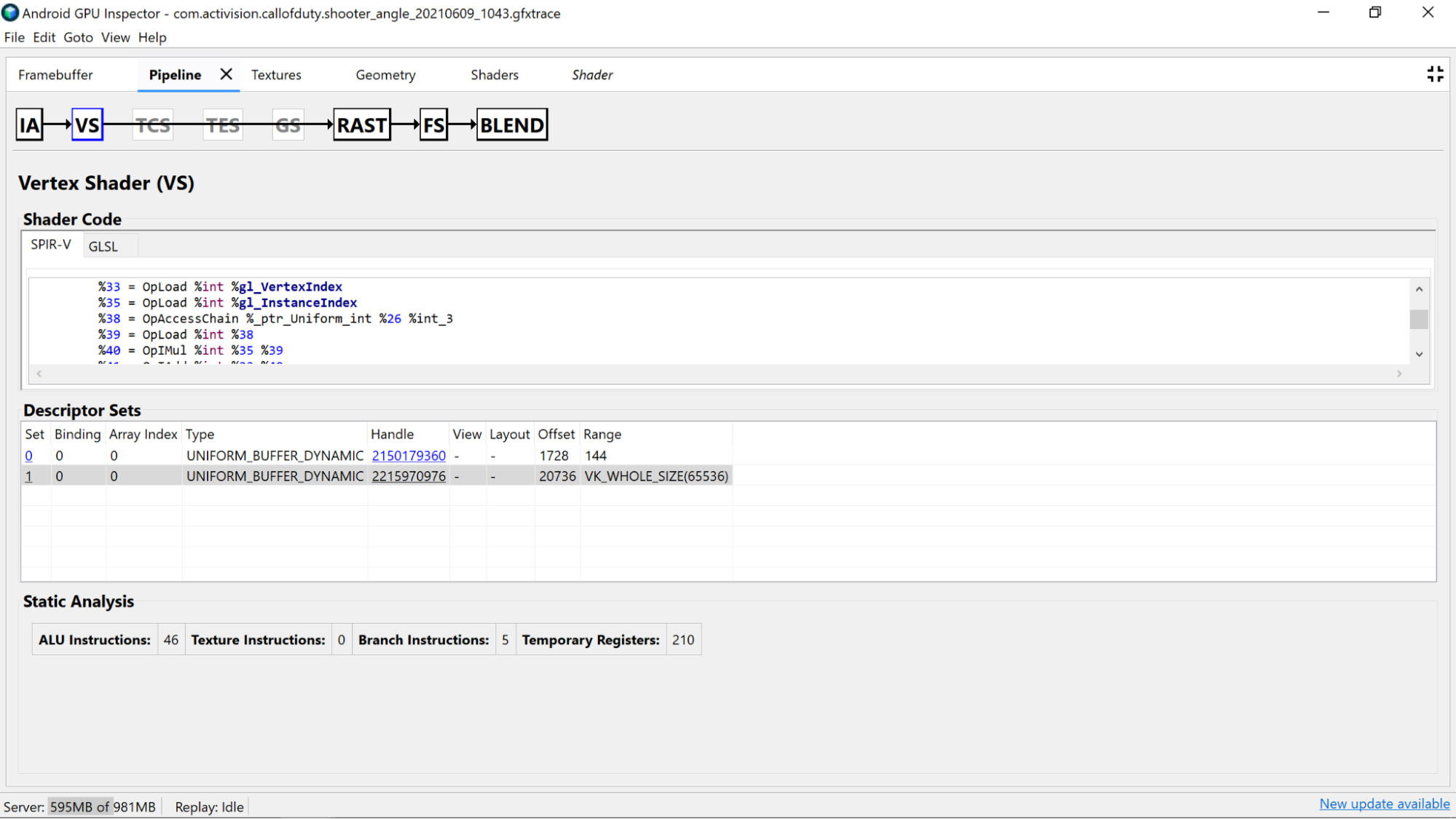
- Precisión: La precisión de las variables del sombreador puede afectar el rendimiento de la GPU de tu aplicación.
- Intenta usar el modificador de precisión
mediumpen variables siempre que sea posible, ya que las variables de precisión media (mediump) de 16 bits suelen ser más rápidas y eficientes en términos de energía que las variables de precisión completa (highp) de 32 bits. - Si no ves ningún calificador de precisión en el sombreador de las declaraciones de variables o en la parte superior del sombreador con un
precision precision-qualifier type, el valor predeterminado es la precisión completa (highp). Asegúrate de observar también las declaraciones de las variables. - También es preferible usar
mediumppara la salida del sombreador de vértices por los mismos motivos descritos anteriormente; además, tiene el beneficio de reducir el ancho de banda de la memoria y el posible uso de registros temporales necesarios para realizar la interpolación.
- Intenta usar el modificador de precisión
- Búferes uniformes: Intenta mantener el tamaño de los búferes uniformes lo más pequeño posible (y al mismo tiempo mantener las reglas de alineación). Esto ayuda a que los cálculos sean más compatibles con el almacenamiento en caché y, potencialmente, permita que los datos uniformes se promuevan a registros más rápidos en el núcleo.
Quita los resultados del sombreador de Vertex que no se usen: Si encuentras que los resultados del sombreador de vértices no se usan en el sombreador de fragmentos, quítalos del sombreador para liberar ancho de banda de memoria y registros temporales.
Mueve los cálculos del sombreador de fragmentos al sombreador de Vertex: si el código del sombreador de fragmentos realiza cálculos que son independientes del estado específico del fragmento que se está sombreando (o que se pueden interpolar correctamente), lo ideal es moverlo al sombreador de vértices. Esto se debe a que, en la mayoría de las apps, el sombreador de vértices se ejecuta con mucha menos frecuencia en comparación con el sombreador de fragmentos.