앱의 메모리 사용량 특성은 앱 성능의 기본적인 측면입니다. 시스템 프로파일러를 사용하여 사용 가능한 GPU 카운터 정보를 확인하여 이러한 특성을 분석할 수 있습니다.
Adreno 기기
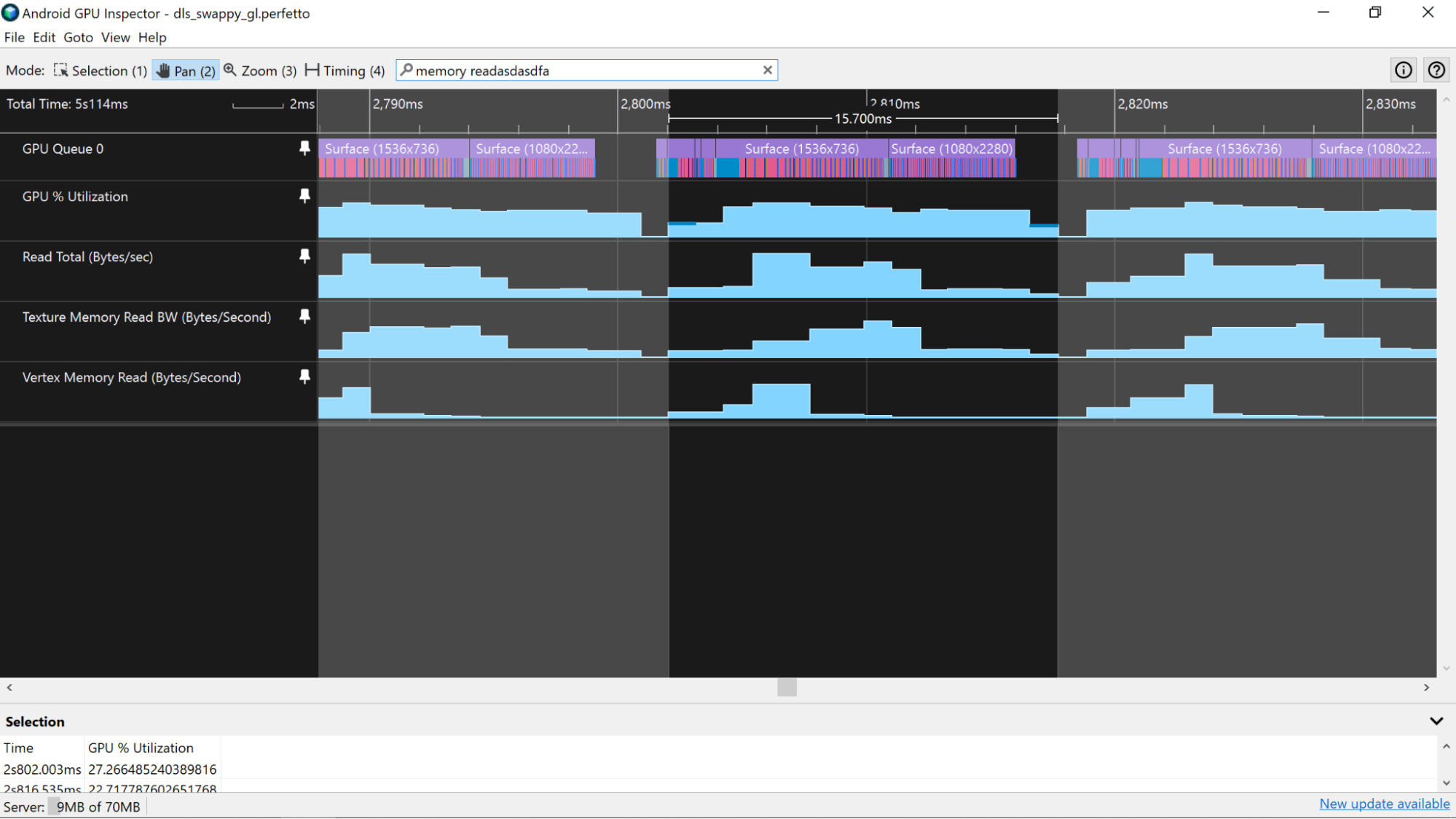
Adreno 기기에서는 CPU 및 GPU 프레임 처리 시간 추정에 설명된 대로 단일 GPU 프레임과 일치하는 기간을 먼저 강조 표시합니다. GPU 사용률 또는 유사한 카운터 트랙을 사용하여 프레임 시간 경계를 설정하는 방법을 설명하는 페이지를 참고하세요. 카운터는 모두 동일한 타이밍 기법을 사용하므로 카운터 트랙 데이터와 독립적으로 데이터가 수집되는 GPU 슬라이스에서 파생된 프레임 시간 경계를 사용하는 것보다 메모리 사용률을 더 정확하게 추정할 수 있습니다.
읽기/쓰기 합계
프로파일러에서 단일 프레임을 강조 표시한 후 Read Total (Bytes/sec) 및 Write Total (Bytes/sec) 카운터를 살펴보세요. 이러한 카운터는 단일 프레임에서 메모리 버스를 통과하는 데이터의 양을 전반적으로 파악하는 데 유용합니다. 메모리 대역폭은 모바일 기기에서 배터리 소모의 큰 원인이므로 버스를 통해 전송하는 데이터 양을 최소화하는 것이 좋습니다.
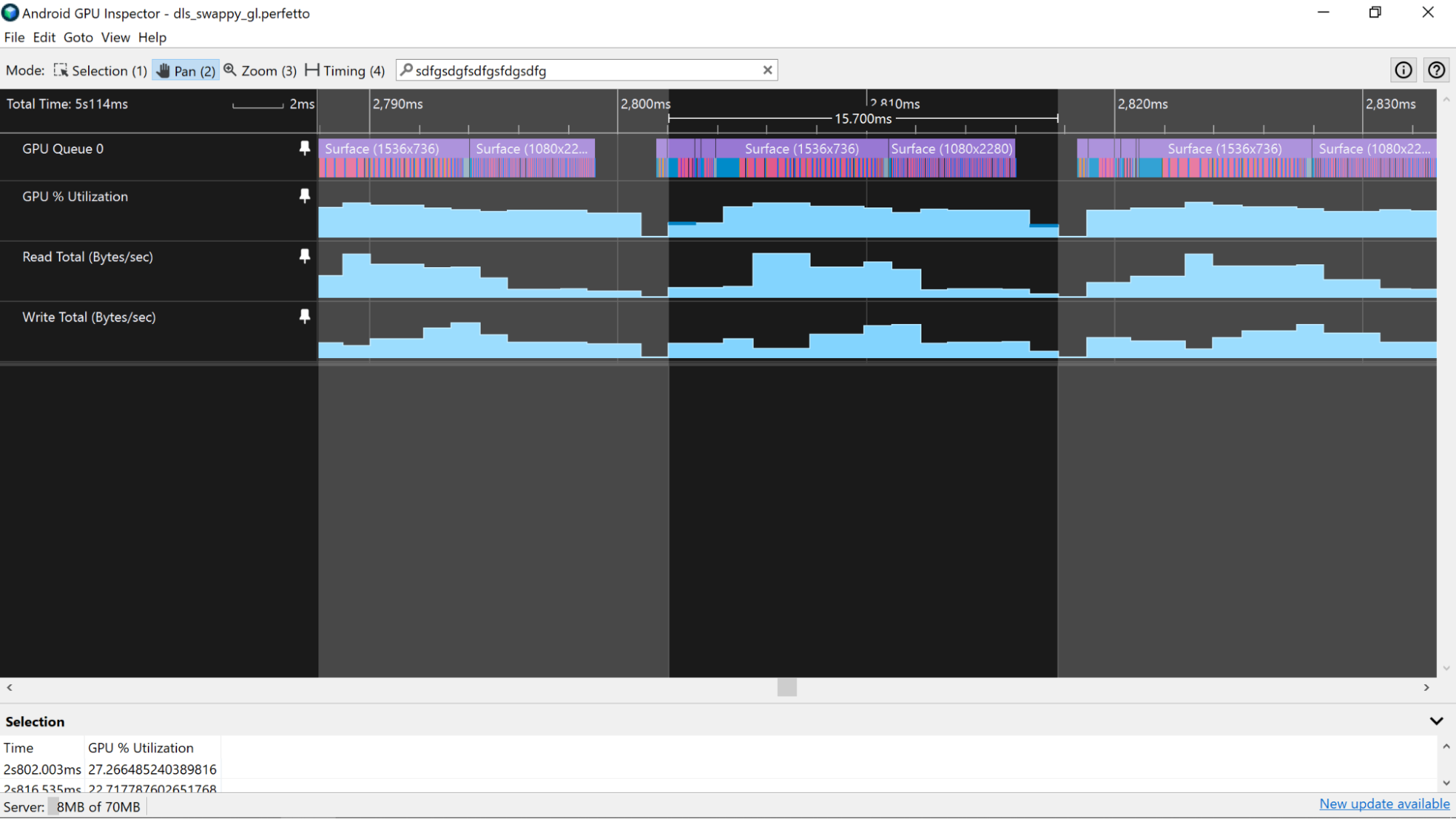
Vertex Memory Read (Bytes/Second) 및 Texture Memory Read (Bytes/Second) 카운터를 검사하여 꼭짓점 및 텍스처 데이터에 사용된 대역폭의 부분을 확인할 수도 있습니다.
이러한 값에 대해 '양호'하다고 생각하는 것은 앱에 표시되는 워크로드 유형에 따라 다릅니다. 예를 들어 2D 애플리케이션에서는 비교적 큰(~2GB/s 이상) 텍스처 메모리 읽기 대역폭이 사용될 수 있지만 꼭짓점 메모리 대역폭은 매우 적을 수 있습니다 (~50MB/s). 자세한 내용은 꼭짓점 메모리 대역폭 분석 및 텍스처 메모리 대역폭 사용량 분석 문서를 참고하세요.
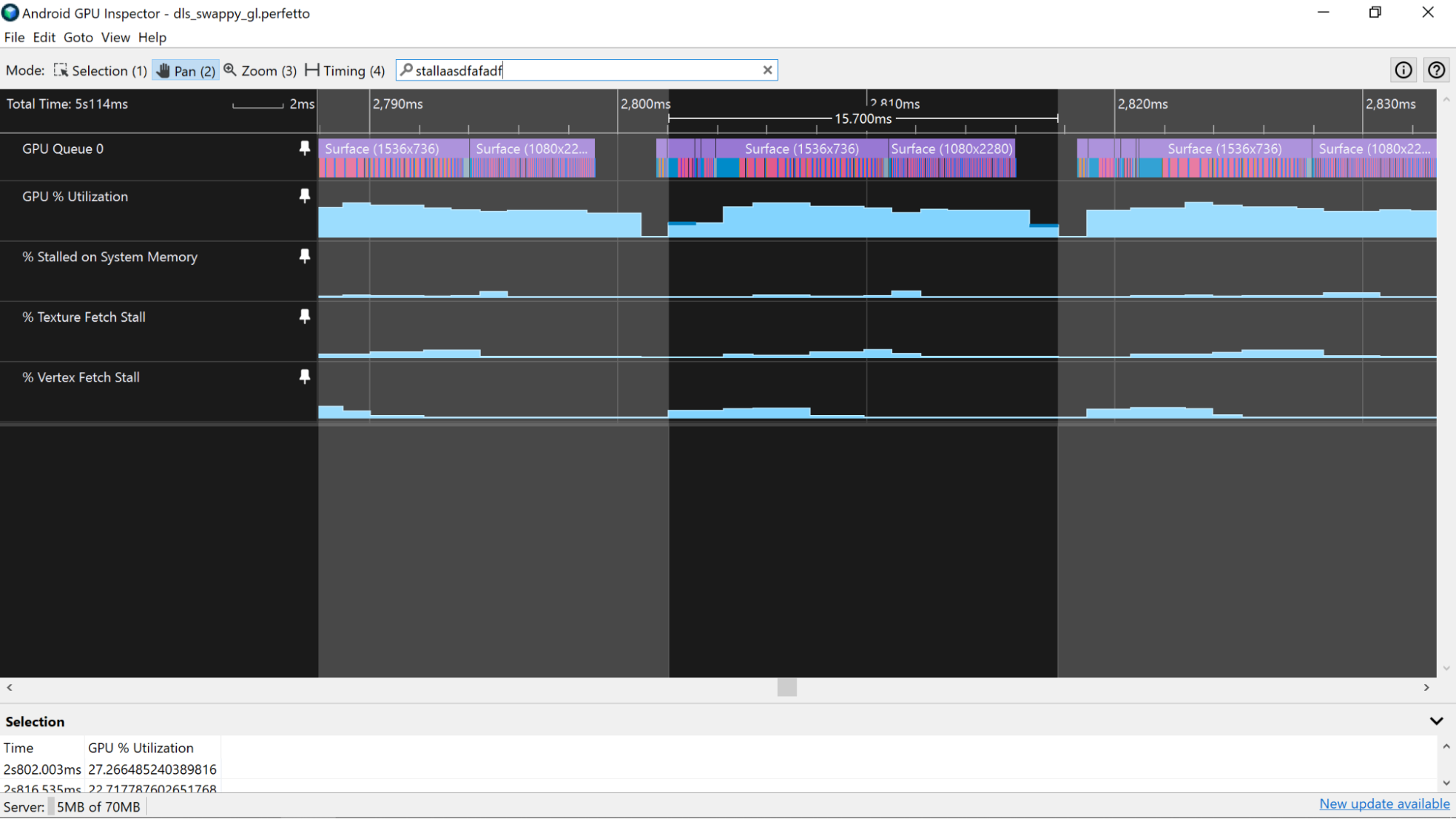
가판대 가져오기
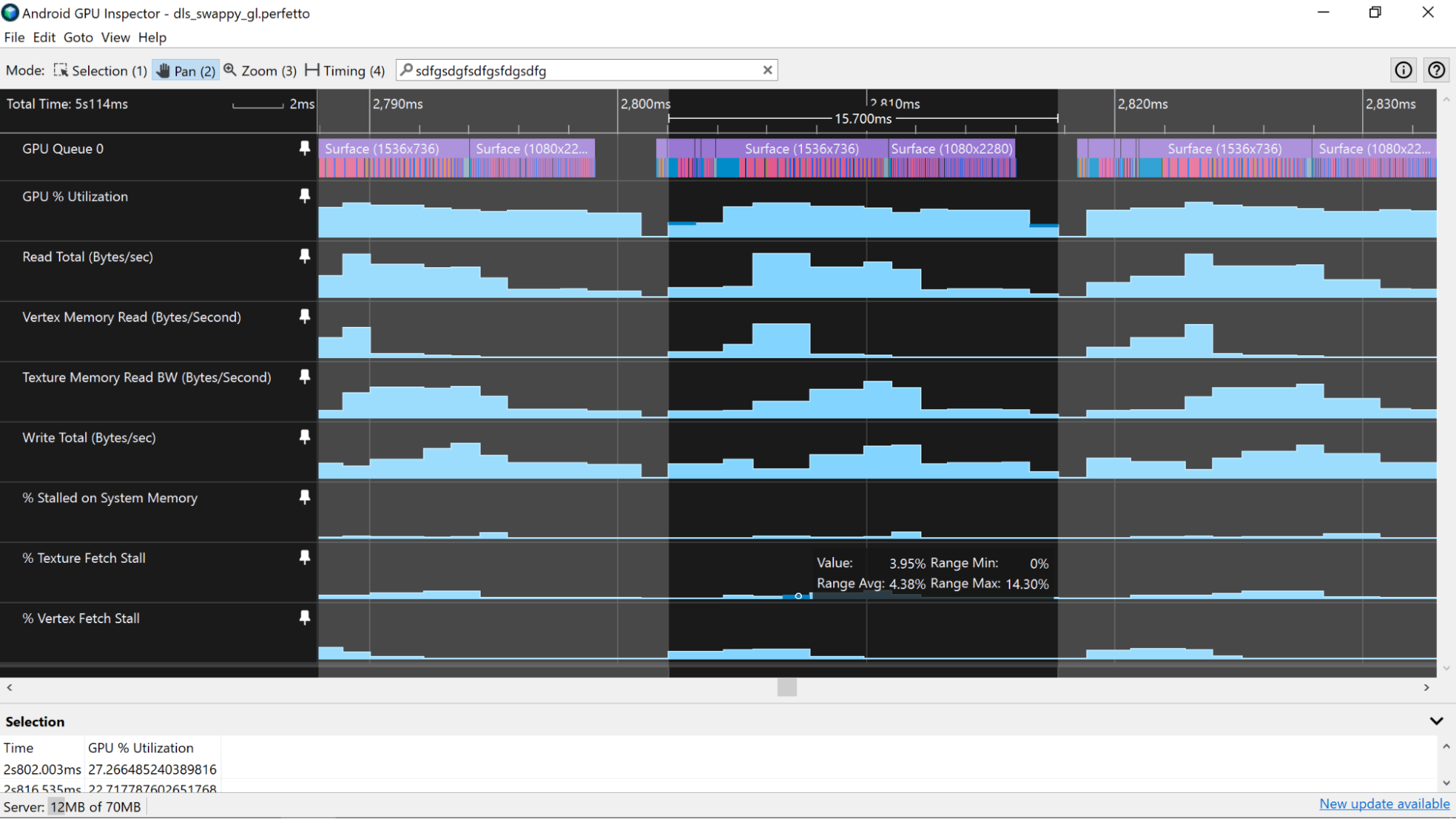
% Vertex Fetch Stall, % Texture Fetch Stall, % Stall on System Memory 카운터를 살펴보세요. 애플리케이션의 전반적인 메모리 성능에 관한 힌트를 얻을 수 있습니다. 값이 5%를 넘으면 앱이 메모리에 데이터를 효율적으로 배치하지 않거나 캐시를 활용하기 위해 데이터를 효율적으로 액세스하지 않는다는 의미입니다. 이러한 유형의 애셋에 대한 메모리 사용량을 개선하는 방법에 관한 자세한 내용은 꼭짓점 메모리 대역폭 분석 및 텍스처 메모리 대역폭 사용량 분석을 참고하세요.
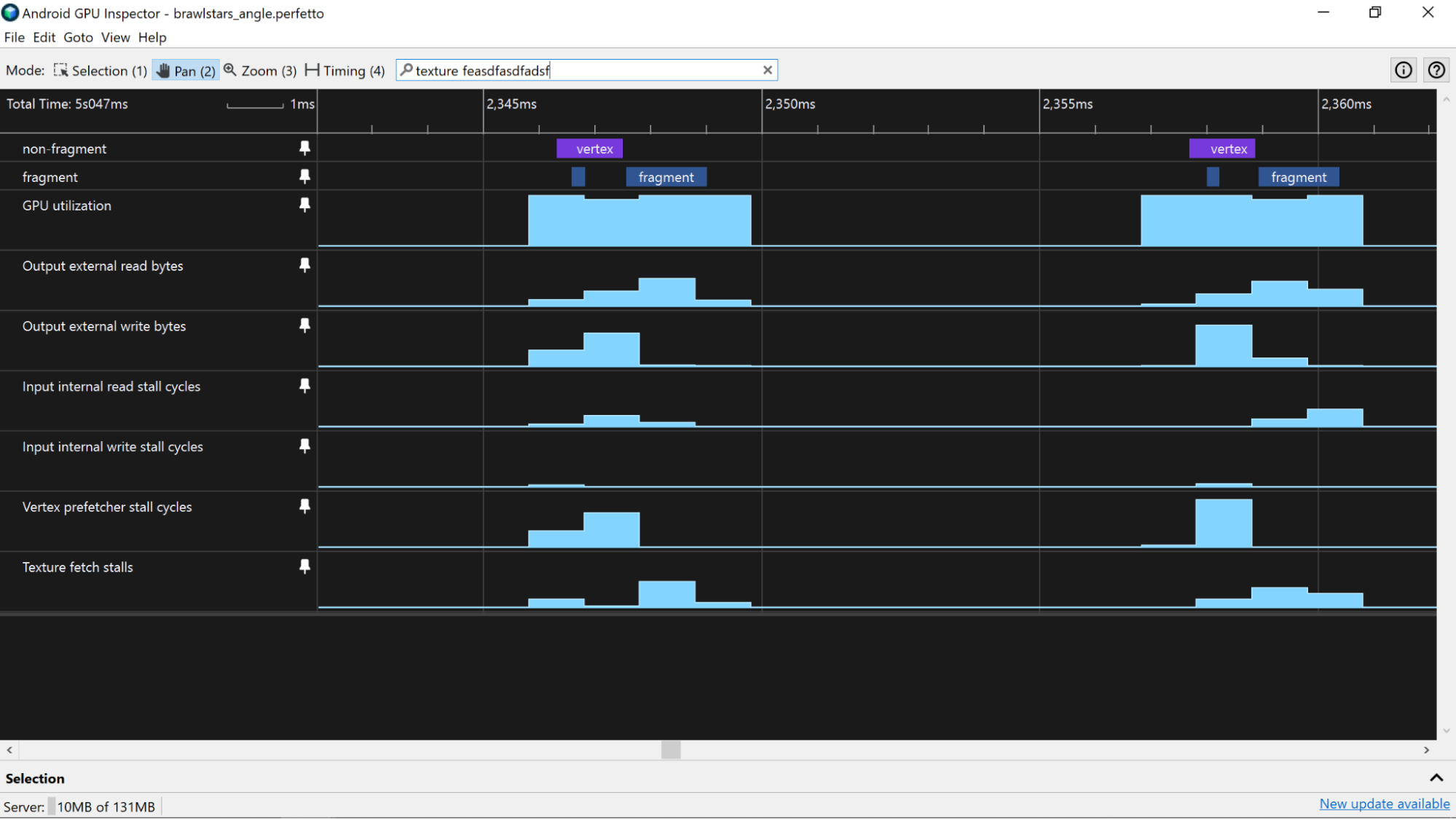
말리 기기
Mali 기기에서는 CPU 및 GPU 프레임 처리 시간 추정에 설명된 대로 단일 GPU 프레임과 일치하는 기간을 먼저 강조 표시합니다. GPU 사용률 또는 유사한 카운터 트랙을 사용하여 프레임 시간 경계를 설정하는 방법을 설명하는 페이지를 참고하세요. 카운터는 모두 동일한 타이밍 기법을 사용하므로 카운터 트랙 데이터와 독립적으로 데이터가 수집되는 GPU 슬라이스에서 파생된 프레임 시간 경계를 사용하는 것보다 메모리 사용률을 더 정확하게 추정할 수 있습니다.
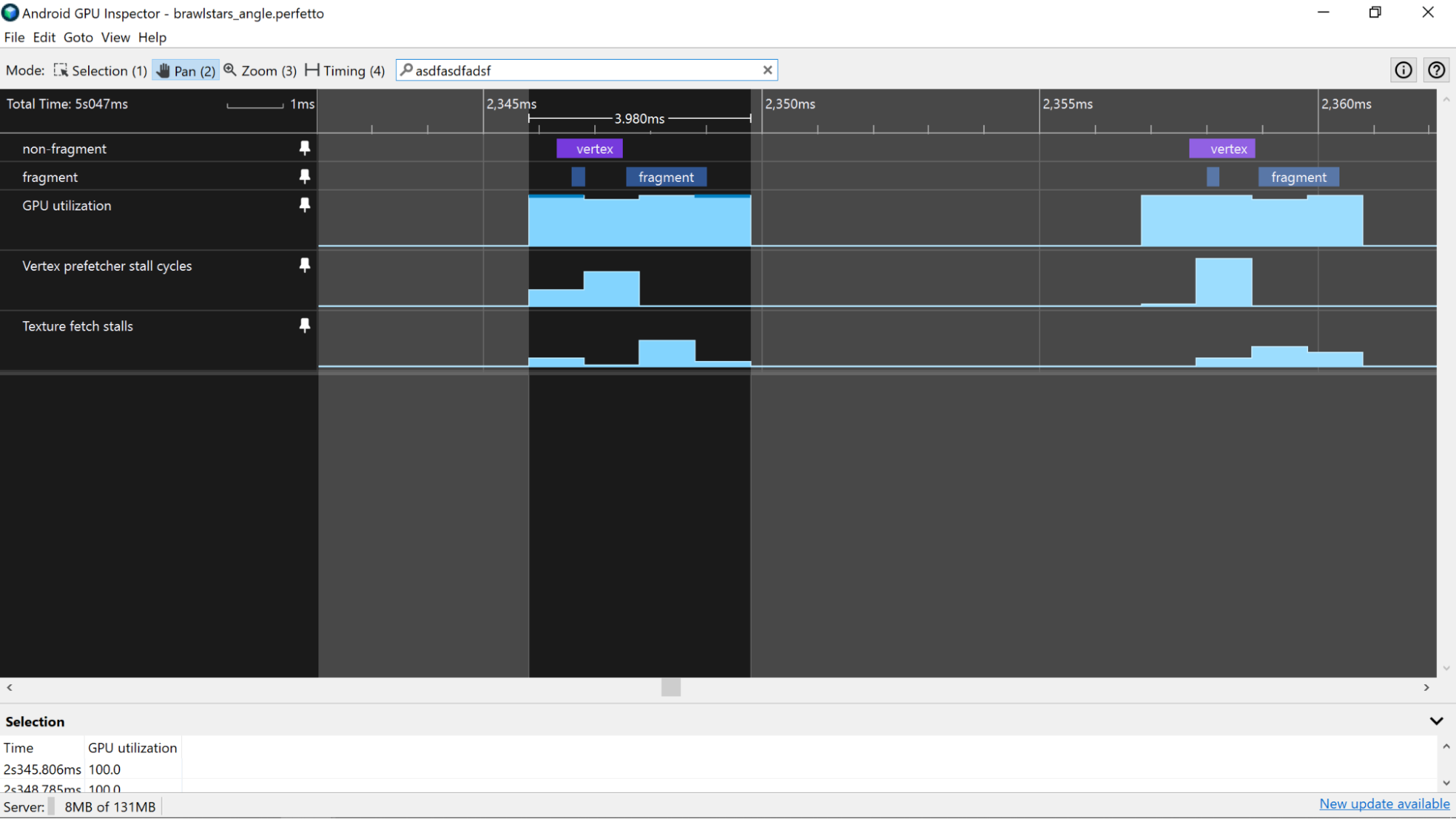
외부 합계 출력
시스템 프로파일러에서 단일 프레임을 강조 표시한 후 출력 외부 읽기 바이트 출력 외부 쓰기 바이트 카운터를 확인합니다. 이러한 카운터는 단일 프레임에서 메모리 버스를 통과하는 데이터의 양을 전반적으로 파악하는 데 유용합니다. 메모리 대역폭은 모바일 기기에서 배터리 소모의 큰 원인이므로 버스를 통해 전송하는 데이터 양을 최소화하는 것이 좋습니다.
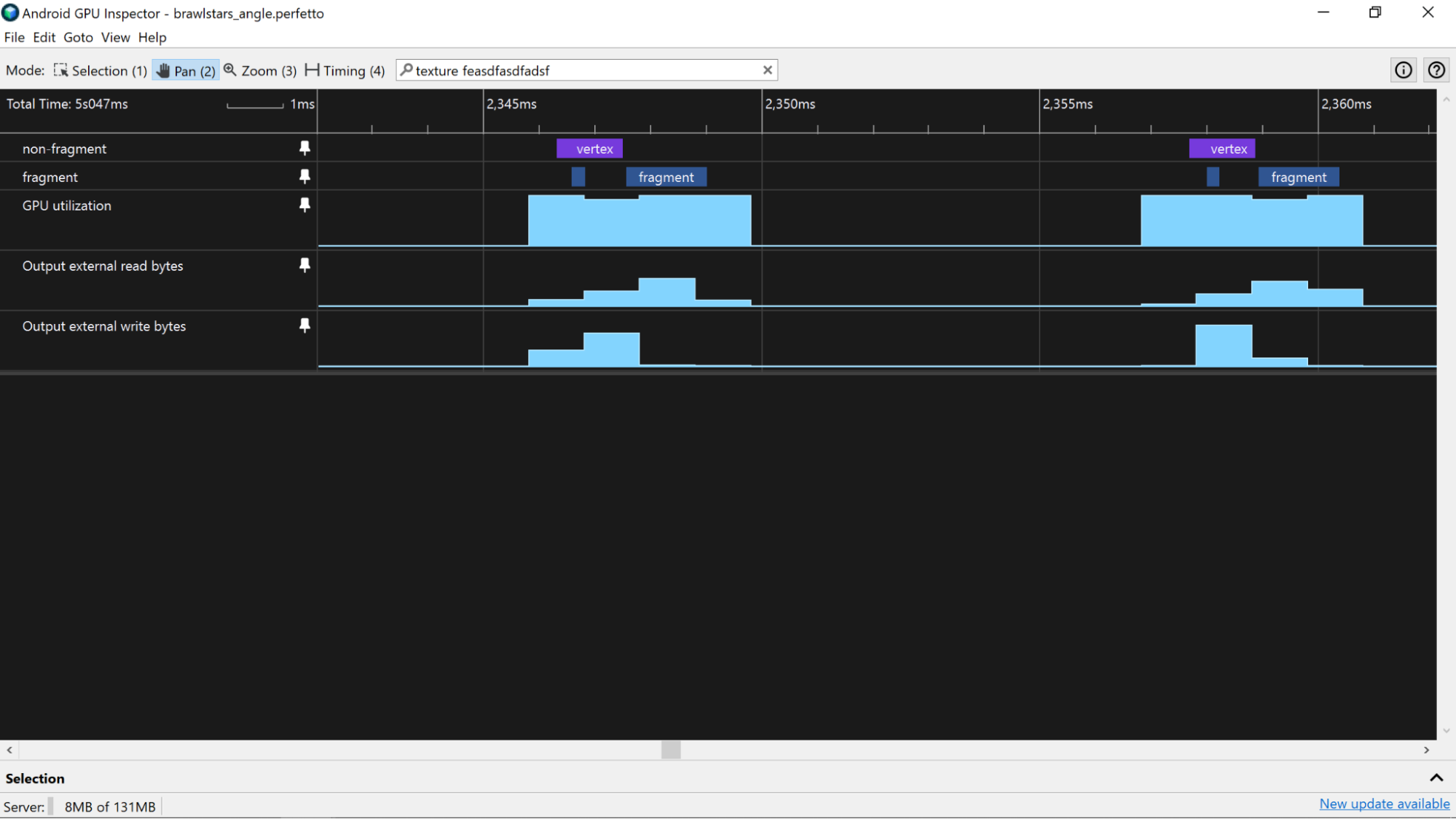
내부 합계 입력
캐시 자체에 관한 정보를 제공하는 카운터도 있습니다. 관심 있는 카운터는 '입력 내부 [읽기|쓰기] 정지 주기'입니다. 이 값이 높을수록 캐시에 성공적으로 도달했지만 읽기 요청이 너무 많이 이루어져 셰이더 코드가 메모리에 액세스하기를 기다리며 정지된다는 의미입니다.
가판대 가져오기
다음으로 살펴볼 수 있는 카운터는 Vertex Prefetcher Stall Cycles 및 Texture Fetch Stall 카운터입니다. 이러한 카운터를 통해 애플리케이션의 전반적인 메모리 성능에 관한 힌트를 얻을 수 있습니다. 값이 5% 보다 높으면 메모리에 데이터를 효율적으로 배치하지 않거나 캐시를 활용하기 위해 데이터를 효율적으로 액세스하지 않는다는 의미입니다. 이러한 유형의 애셋에 대한 메모리 사용량을 개선하는 방법을 자세히 알아보려면 [꼭짓점|텍스처] 메모리 대역폭 분석 도움말을 참고하세요.