
AGI Frame Profiler cho phép bạn kiểm tra các chương trình đổ bóng bằng cách chọn một lệnh gọi vẽ từ một trong các lượt kết xuất của chúng tôi và chuyển qua phần Vertex Shader (Chương trình đổ bóng đỉnh) hoặc phần Fragment Shader (Chương trình đổ bóng mảnh) của ngăn Pipeline (Quy trình).
Tại đây, bạn sẽ thấy các số liệu thống kê hữu ích từ quá trình phân tích tĩnh mã chương trình đổ bóng, cũng như hợp ngữ Đại diện trung gian di động tiêu chuẩn (SPIR-V) mà GLSL của chúng tôi đã được biên dịch. Ngoài ra, còn có một thẻ để xem bản trình bày của GLSL gốc (với tên do trình biên dịch tạo cho các biến, hàm và nhiều thành phần khác) đã được dịch ngược bằng SPIR-V Cross, nhằm cung cấp thêm bối cảnh cho SPIR-V.
Phân tích tĩnh
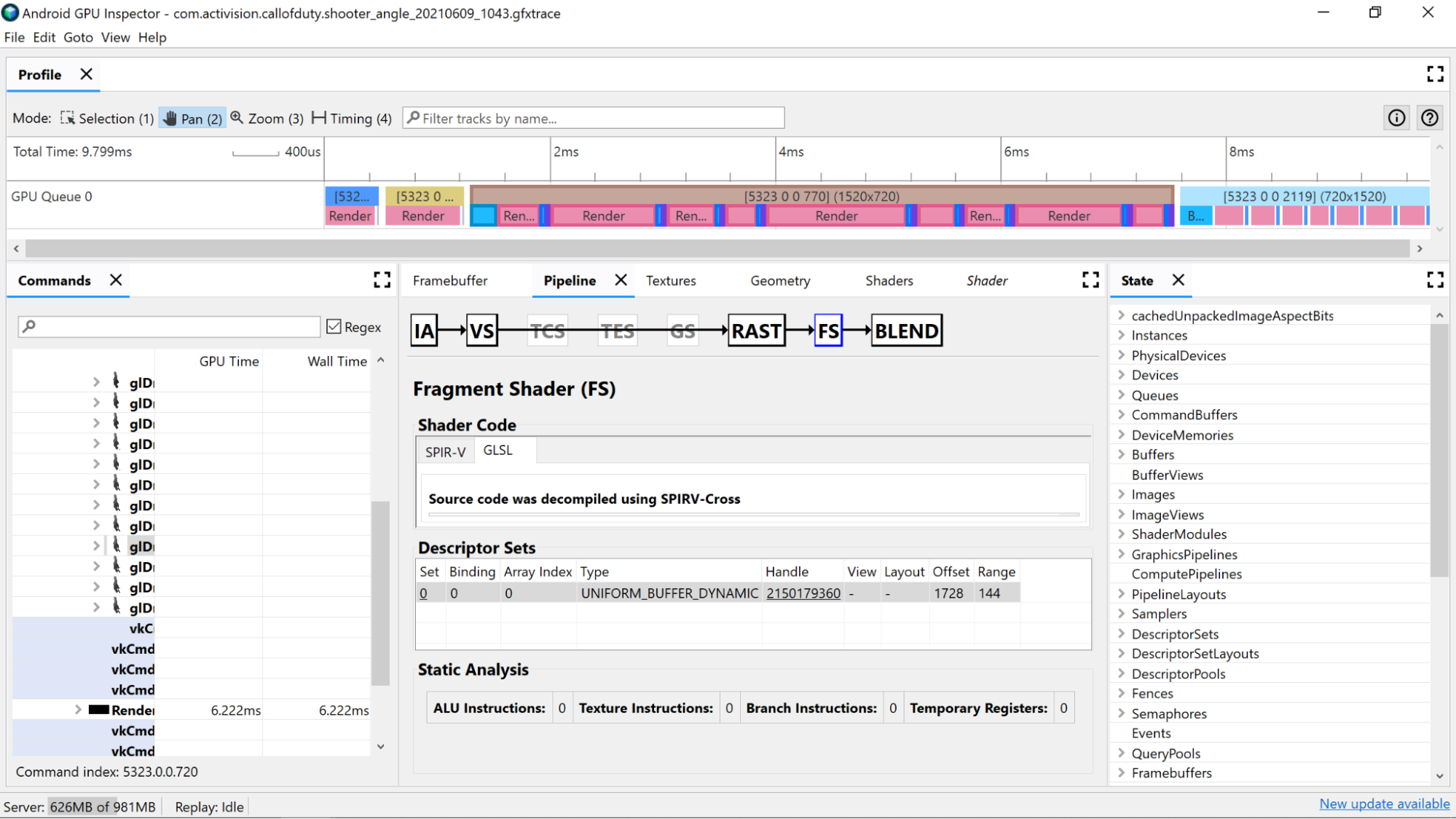
Sử dụng các bộ đếm phân tích tĩnh để xem các thao tác cấp thấp trong chương trình đổ bóng.
Hướng dẫn ALU: Số liệu này cho biết số lượng hoạt động ALU (cộng, nhân, chia, v.v.) đang được thực thi trong chương trình đổ bóng và là một chỉ số đại diện tốt cho mức độ phức tạp của chương trình đổ bóng. Hãy cố gắng giảm thiểu giá trị này.
Tái cấu trúc các phép tính thông thường hoặc đơn giản hoá các phép tính được thực hiện trong chương trình đổ bóng có thể giúp giảm số lượng chỉ dẫn cần thiết.
Hướng dẫn về hoạ tiết: Số liệu này cho biết số lần lấy mẫu hoạ tiết xảy ra trong chương trình đổ bóng.
- Việc lấy mẫu hoạ tiết có thể tốn kém tuỳ thuộc vào loại hoạ tiết được lấy mẫu, vì vậy, việc tham chiếu chéo mã chương trình đổ bóng với các hoạ tiết được liên kết có trong phần Descriptor Sets (Tập hợp mô tả) có thể cung cấp thêm thông tin về các loại hoạ tiết đang được sử dụng.
- Tránh truy cập ngẫu nhiên khi lấy mẫu hoạ tiết, vì hành vi này không phù hợp với việc lưu vào bộ nhớ đệm hoạ tiết.
Hướng dẫn về nhánh: Số liệu này cho biết số lượng thao tác nhánh trong chương trình đổ bóng. Giảm thiểu việc phân nhánh là lựa chọn lý tưởng trên các bộ xử lý song song như GPU, và thậm chí có thể giúp trình biên dịch tìm thấy các hoạt động tối ưu hoá bổ sung:
- Sử dụng các hàm như
min,maxvàclampđể tránh phải phân nhánh trên các giá trị số. - Kiểm thử chi phí tính toán trên các nhánh. Vì cả hai đường dẫn của một nhánh đều được thực thi trong nhiều cấu trúc, nên có nhiều trường hợp mà việc luôn thực hiện tính toán sẽ nhanh hơn so với việc bỏ qua tính toán bằng một nhánh.
- Sử dụng các hàm như
Các thanh ghi tạm thời: Đây là các thanh ghi nhanh, trên lõi được dùng để lưu giữ kết quả của các hoạt động trung gian mà các phép tính trên GPU yêu cầu. Có một giới hạn về số lượng thanh ghi có sẵn cho các phép tính trước khi GPU phải tràn vào việc sử dụng bộ nhớ ngoài lõi khác để lưu trữ các giá trị trung gian, làm giảm hiệu suất tổng thể. (Giới hạn này thay đổi tuỳ thuộc vào kiểu GPU.)
Số lượng thanh ghi tạm thời được sử dụng có thể cao hơn dự kiến nếu trình biên dịch chương trình đổ bóng thực hiện các thao tác như mở vòng lặp, vì vậy, bạn nên tham chiếu chéo giá trị này với SPIR-V hoặc GLSL đã biên dịch ngược để xem mã đang làm gì.
Phân tích mã chương trình đổ bóng
Khám phá chính mã đổ bóng đã dịch ngược để xác định xem có thể cải thiện gì hay không.
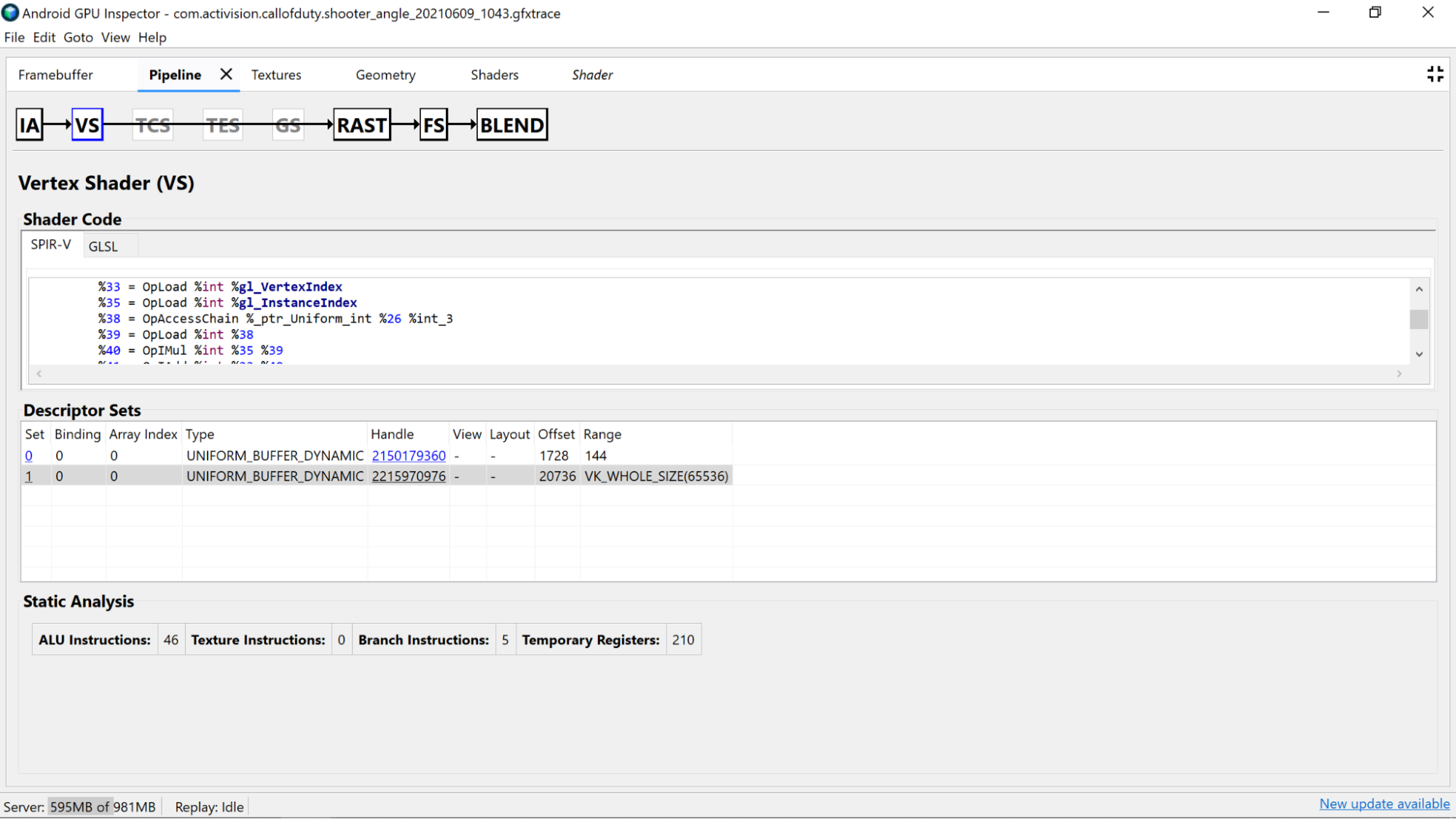
- Độ chính xác: Độ chính xác của các biến chương trình đổ bóng có thể ảnh hưởng đến hiệu suất GPU của ứng dụng.
- Hãy thử sử dụng bộ sửa đổi độ chính xác
mediumptrên các biến bất cứ khi nào có thể, vì các biến 16 bit có độ chính xác trung bình (mediump) thường nhanh hơn và tiết kiệm điện hơn so với các biến 32 bit có độ chính xác đầy đủ (highp). - Nếu bạn không thấy bất kỳ bộ đủ điều kiện độ chính xác nào trong chương trình đổ bóng trên các khai báo biến hoặc ở đầu chương trình đổ bóng có
precision precision-qualifier type, thì chương trình sẽ mặc định là độ chính xác đầy đủ (highp). Hãy nhớ xem cả các khai báo biến. - Bạn cũng nên dùng
mediumpcho đầu ra của chương trình đổ bóng đỉnh vì những lý do tương tự như mô tả ở trên, đồng thời có lợi ích là giảm băng thông bộ nhớ và có thể giảm mức sử dụng thanh ghi tạm thời cần thiết để thực hiện nội suy.
- Hãy thử sử dụng bộ sửa đổi độ chính xác
- Vùng đệm đồng nhất: Cố gắng giữ kích thước của Vùng đệm đồng nhất nhỏ nhất có thể (trong khi vẫn duy trì các quy tắc căn chỉnh). Điều này giúp các phép tính tương thích hơn với việc lưu vào bộ nhớ đệm và có thể cho phép dữ liệu đồng nhất được chuyển đến các thanh ghi trên lõi nhanh hơn.
Xoá các đầu ra Vertex Shader không dùng đến: Nếu bạn thấy các đầu ra vertex shader không được dùng trong fragment shader, hãy xoá chúng khỏi shader để giải phóng băng thông bộ nhớ và các thanh ghi tạm thời.
Di chuyển phép tính từ Trình đổ bóng phân mảnh sang Trình đổ bóng đỉnh: Nếu mã trình đổ bóng phân mảnh thực hiện các phép tính độc lập với trạng thái dành riêng cho phân mảnh đang được đổ bóng (hoặc có thể được nội suy đúng cách), thì việc di chuyển mã đó sang trình đổ bóng đỉnh là lựa chọn lý tưởng. Lý do là trong hầu hết các ứng dụng, chương trình đổ bóng đỉnh chạy ít thường xuyên hơn nhiều so với chương trình đổ bóng phân mảnh.