
AGI Frame Profiler vous permet d'examiner vos nuanceurs en sélectionnant un appel de dessin à partir de l'un de nos passes de rendu, puis en parcourant la section Vertex Shader ou Fragment Shader du volet Pipeline.
Vous y trouverez des statistiques utiles issues de l'analyse statique du code du nuanceur, ainsi que l'assemblage Standard Portable Intermediate Representation (SPIR-V) dans lequel notre GLSL a été compilé. Un onglet permet également d'afficher une représentation du GLSL d'origine (avec les noms générés par le compilateur pour les variables, les fonctions, etc.) qui a été décompilé avec SPIR-V Cross, afin de fournir un contexte supplémentaire pour le SPIR-V.
Analyse statique
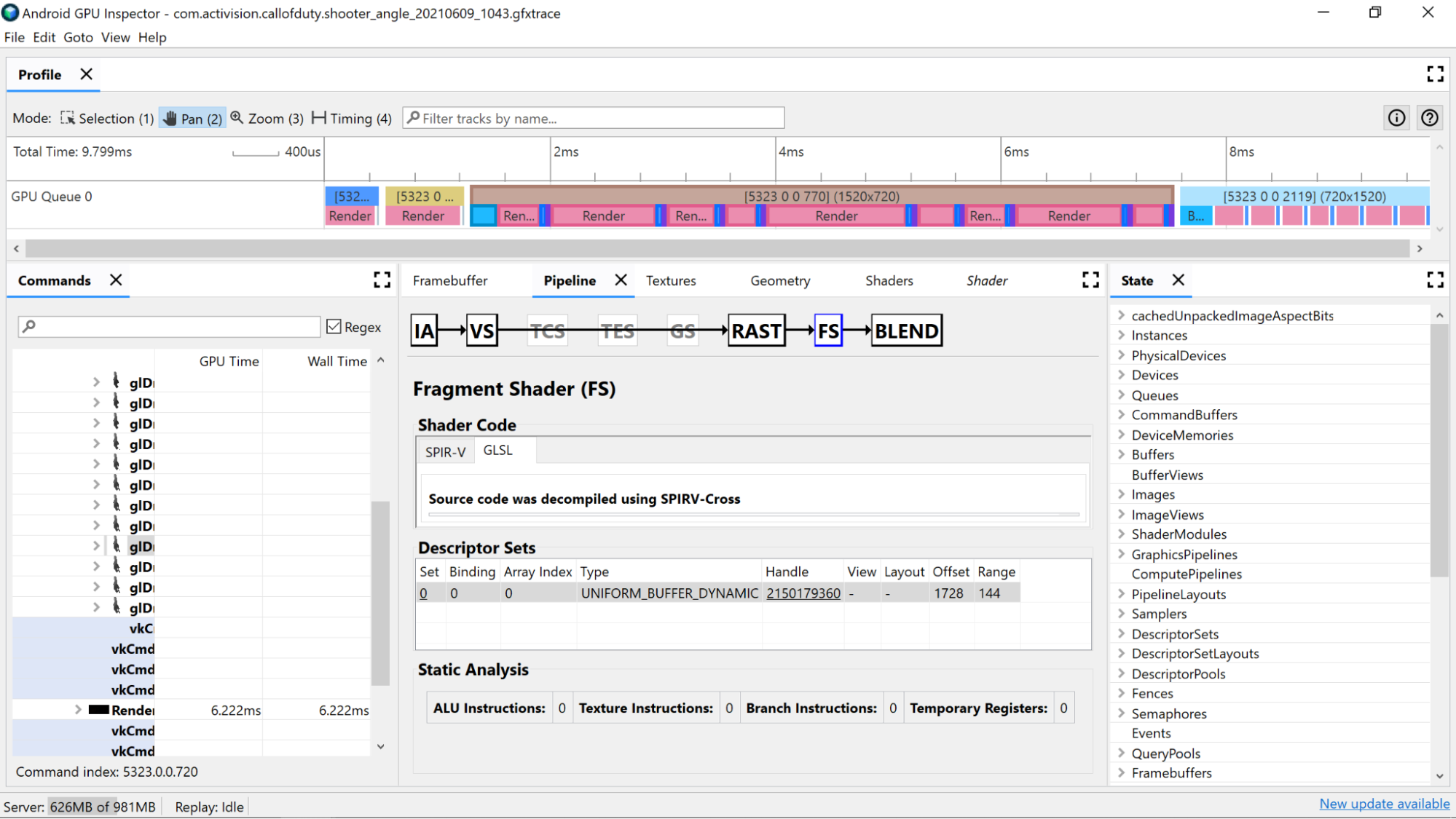
Utilisez les compteurs d'analyse statique pour afficher les opérations de bas niveau dans le nuanceur.
Instructions ALU : ce nombre indique le nombre d'opérations ALU (additions, multiplications, divisions, etc.) exécutées dans le nuanceur. Il s'agit d'un bon indicateur de la complexité du nuanceur. Essayez de minimiser cette valeur.
La refactorisation des calculs courants ou la simplification des calculs effectués dans le nuanceur peuvent aider à réduire le nombre d'instructions nécessaires.
Instructions de texture : ce nombre indique le nombre de fois où l'échantillonnage de texture se produit dans le nuanceur.
- L'échantillonnage de textures peut être coûteux selon le type de textures à partir desquelles l'échantillonnage est effectué. Par conséquent, la vérification croisée du code du nuanceur avec les textures liées trouvées dans la section Ensembles de descripteurs peut fournir plus d'informations sur les types de textures utilisées.
- Évitez l'accès aléatoire lors de l'échantillonnage des textures, car ce comportement n'est pas idéal pour la mise en cache des textures.
Instructions de branche : ce nombre indique le nombre d'opérations de branche dans le nuanceur. La réduction des branchements est idéale sur les processeurs parallélisés tels que le GPU, et peut même aider le compilateur à trouver des optimisations supplémentaires :
- Utilisez des fonctions telles que
min,maxetclamppour éviter d'avoir à créer des branches en fonction de valeurs numériques. - Testez le coût de calcul sur la ramification. Étant donné que les deux chemins d'une branche sont exécutés dans de nombreuses architectures, il existe de nombreux scénarios dans lesquels le calcul est toujours plus rapide que l'omission du calcul avec une branche.
- Utilisez des fonctions telles que
Registres temporaires : il s'agit de registres rapides sur le cœur qui sont utilisés pour stocker les résultats des opérations intermédiaires requises par les calculs sur le GPU. Le nombre de registres disponibles pour les calculs est limité avant que le GPU ne doive utiliser d'autres mémoires hors cœur pour stocker les valeurs intermédiaires, ce qui réduit les performances globales. (Cette limite varie selon le modèle de GPU.)
Le nombre de registres temporaires utilisés peut être plus élevé que prévu si le compilateur de nuanceurs effectue des opérations telles que le déroulement de boucles. Il est donc judicieux de croiser cette valeur avec le SPIR-V ou le GLSL décompilé pour voir ce que fait le code.
Analyse du code du nuanceur
Examinez le code du nuanceur décompilé lui-même pour déterminer si des améliorations potentielles sont possibles.
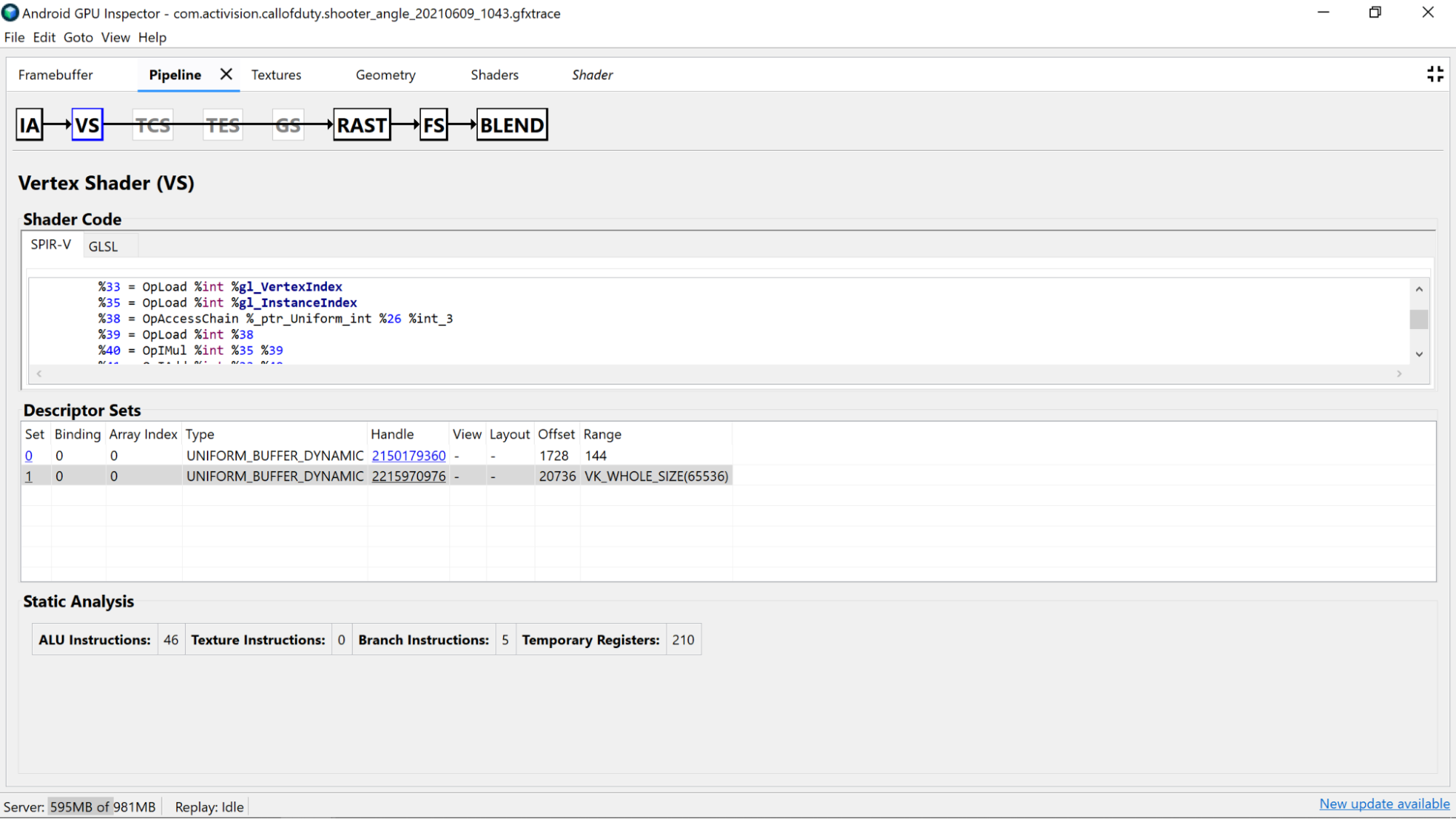
- Précision : la précision des variables de nuanceur peut avoir un impact sur les performances du GPU de votre application.
- Essayez d'utiliser le modificateur de précision
mediumpsur les variables chaque fois que possible, car les variables 16 bits de précision moyenne (mediump) sont généralement plus rapides et plus économes en énergie que les variables 32 bits de précision totale (highp). - Si vous ne voyez aucun qualificatif de précision dans le nuanceur sur les déclarations de variables, ou en haut du nuanceur avec un
precision precision-qualifier type, la précision par défaut est la précision complète (highp). Assurez-vous également de consulter les déclarations de variables. - L'utilisation de
mediumppour la sortie du nuanceur de vertex est également préférable pour les mêmes raisons que celles décrites ci-dessus. Elle présente également l'avantage de réduire la bande passante mémoire et l'utilisation potentielle de registres temporaires nécessaires à l'interpolation.
- Essayez d'utiliser le modificateur de précision
- Tampons uniformes : essayez de réduire au maximum la taille des tampons uniformes (tout en respectant les règles d'alignement). Cela permet de rendre les calculs plus compatibles avec la mise en cache et peut permettre de promouvoir les données uniformes vers des registres sur cœur plus rapides.
Supprimez les sorties de nuanceur de vertex inutilisées : si vous constatez que des sorties de nuanceur de vertex ne sont pas utilisées dans le nuanceur de fragment, supprimez-les du nuanceur pour libérer de la bande passante mémoire et des registres temporaires.
Déplacer le calcul du nuanceur de fragment vers le nuanceur de vertex : si le code du nuanceur de fragment effectue des calculs indépendants de l'état spécifique au fragment ombré (ou peut être interpolé correctement), il est idéal de le déplacer vers le nuanceur de vertex. En effet, dans la plupart des applications, le nuanceur de sommets est exécuté beaucoup moins souvent que le nuanceur de fragments.