
AGI 프레임 프로파일러를 사용하면 렌더링 패스 중 하나에서 그리기 호출을 선택하고 파이프라인 창의 Vertex Shader 섹션 또는 Fragment Shader 섹션을 통해 셰이더를 조사할 수 있습니다.
여기에서는 셰이더 코드의 정적 분석과 GLSL로 컴파일된 Standard Portable Intermediate Representation(SPIR-V) 어셈블리에서 가져온 유용한 통계를 확인할 수 있습니다. SPIR-V Cross로 디컴파일된 원본 GLSL의 표현 (컴파일러에서 생성된 변수, 함수 등의 이름 포함)을 볼 수 있는 탭도 있어 SPIR-V에 관한 추가 컨텍스트를 제공합니다.
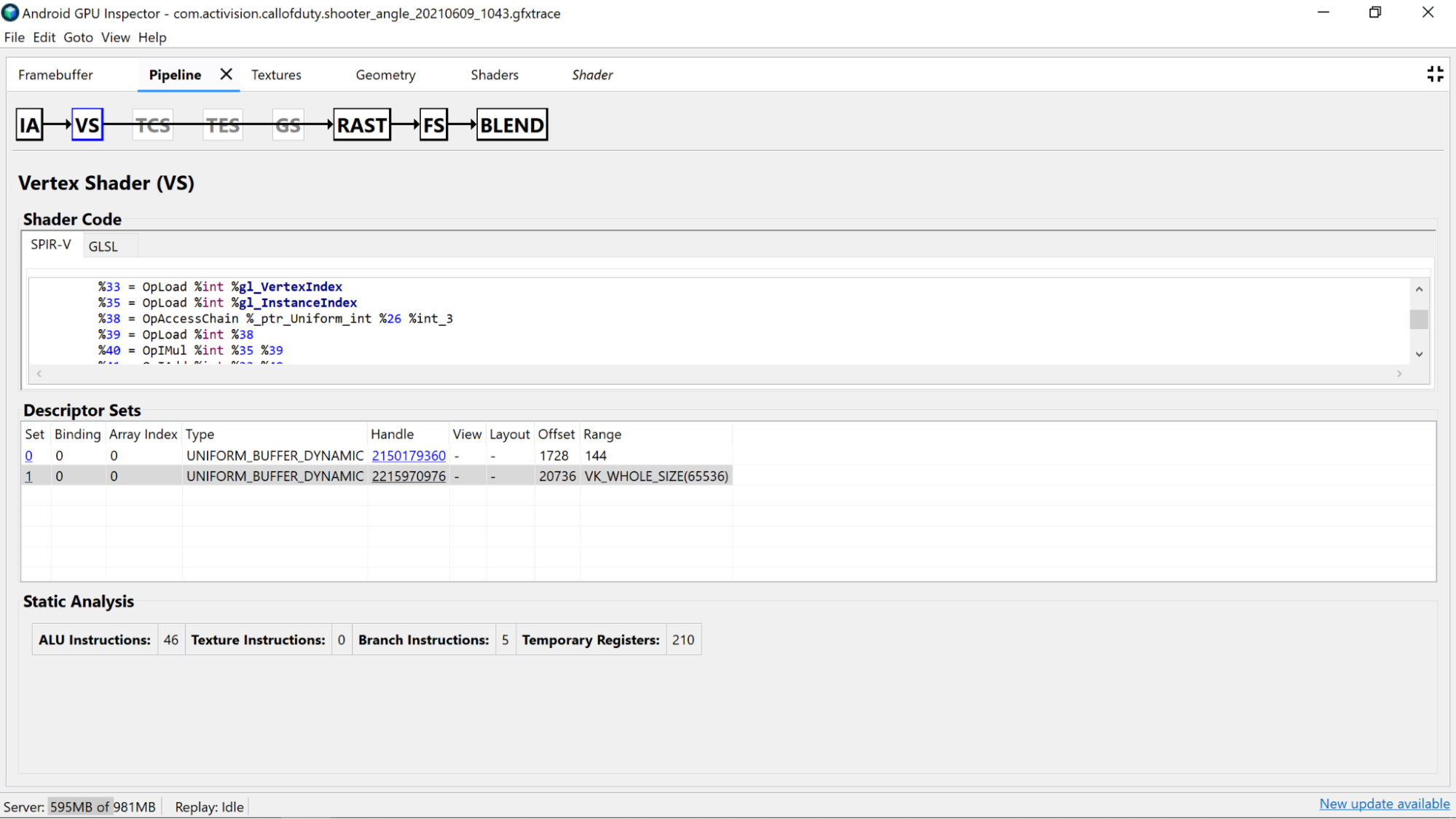
정적 분석
정적 분석 카운터를 사용하여 셰이더의 하위 수준 작업을 봅니다.
ALU 명령: 이 수는 셰이더 내에서 실행되는 ALU 연산(더하기, 곱하기, 나눗셈 등)의 수를 나타내며 셰이더의 복잡성을 나타내는 좋은 프록시입니다. 이 값을 최소화해 보세요.
일반적인 계산을 리팩터링하거나 셰이더에서 실행되는 계산을 단순화하면 필요한 명령 수를 줄이는 데 도움이 될 수 있습니다.
텍스처 안내: 이 수는 셰이더에서 텍스처 샘플링이 발생하는 횟수를 보여줍니다.
- 텍스처 샘플링은 샘플링되는 텍스처 유형에 따라 비용이 많이 들 수 있으므로 셰이더 코드를 설명자 세트 섹션에 있는 바인드 텍스처와 교차 참조하면 사용 중인 텍스처 유형에 관한 자세한 정보를 제공할 수 있습니다.
- 텍스처를 샘플링할 때 무작위 액세스를 피합니다. 이 동작은 텍스처 캐싱에 적합하지 않기 때문입니다.
브랜치 안내: 이 수는 셰이더의 브랜치 작업 수를 보여줍니다. GPU와 같은 병렬화된 프로세서에서 분기를 최소화하는 것이 이상적이며 컴파일러가 추가 최적화를 찾는 데 도움이 될 수도 있습니다.
- 숫자 값을 분기할 필요가 없도록
min,max,clamp과 같은 함수를 사용합니다. - 분기를 통한 계산 비용을 테스트합니다. 브랜치의 두 경로는 모두 많은 아키텍처에서 실행되므로 항상 계산을 실행하는 것이 브랜치를 사용한 계산을 건너뛰는 것보다 더 빠른 시나리오가 많습니다.
- 숫자 값을 분기할 필요가 없도록
임시 레지스터: GPU에서의 계산에 필요한 중간 작업의 결과를 저장하는 데 사용되는 빠른 온코어 레지스터입니다. GPU가 다른 오프코어 메모리를 사용하여 중간 값을 저장하도록 스필오버하기 전에 계산에 사용할 수 있는 레지스터 수에 제한이 있으므로 전반적인 성능이 저하됩니다. (이 한도는 GPU 모델에 따라 다릅니다.)
셰이더 컴파일러가 언롤링 루프와 같은 작업을 실행하는 경우 사용되는 임시 레지스터의 수가 예상보다 많을 수 있으므로 이 값을 SPIR-V 또는 디컴파일된 GLSL과 교차 참조하여 코드가 실행하는 작업을 확인하는 것이 좋습니다.
셰이더 코드 분석
디컴파일된 셰이더 코드 자체를 조사하여 가능한 개선 사항이 있는지 확인합니다.
- 정밀도: 셰이더 변수의 정밀도는 애플리케이션의 GPU 성능에 영향을 줄 수 있습니다.
- 가능한 경우 변수에
mediump정밀도 수정자를 사용해 보세요. 중간 정밀도 (mediump) 16비트 변수는 일반적으로 전체 정밀도 (highp) 32비트 변수보다 빠르고 전력 효율성이 높기 때문입니다. - 변수 선언 시 셰이더 또는
precision precision-qualifier type가 있는 셰이더 상단에 정밀도 한정자가 표시되지 않으면 기본값은 전체 정밀도(highp)입니다. 변수 선언도 확인해야 합니다. - 위에서 설명한 것과 같은 이유로 꼭짓점 셰이더 출력에
mediump를 사용하는 것이 좋으며, 메모리 대역폭과 보간을 실행하는 데 필요한 임시 레지스터 사용량을 줄일 수 있는 이점도 있습니다.
- 가능한 경우 변수에
- 균일 버퍼: 정렬 규칙은 유지하면서 균일 버퍼의 크기를 가능한 한 작게 유지합니다. 이렇게 하면 계산과 캐싱의 호환성이 향상되고 균일한 데이터를 더 빠른 온코어 레지스터로 승격할 수 있습니다.
사용하지 않는 Vertex 셰이더 출력 삭제: 프래그먼트 셰이더에서 사용되지 않는 꼭짓점 셰이더 출력이 있으면 셰이더에서 삭제하여 메모리 대역폭과 임시 레지스터의 여유 공간을 확보합니다.
프래그먼트 셰이더에서 Vertex 셰이더로 계산 이동: 프래그먼트 셰이더 코드가 음영 처리되는 (또는 제대로 보간할 수 있는) 프래그먼트와 무관한 상태와 무관한 계산을 실행하는 경우 꼭짓점 셰이더로 이동하는 것이 좋습니다. 그 이유는 대부분의 앱에서 꼭짓점 셰이더가 프래그먼트 셰이더에 비해 훨씬 덜 실행되기 때문입니다.