AGI Frame Profiler を使用すると、アプリの単一フレームを構成するために使用される個々のレンダリングパスを調べることができます。これは、各グラフィック API 呼び出しの実行に必要なすべての状態をインターセプトして記録することで実現します。Vulkan では、Vulkan のレイヤ化システムを使用してネイティブにこの処理を行っています。OpenGL では、コマンドが ANGLE を使用してインターセプトされます。ANNGLE は、OpenGL コマンドを Vulkan の呼び出しに変換して、ハードウェア上で実行できるようにします。
Adreno デバイス
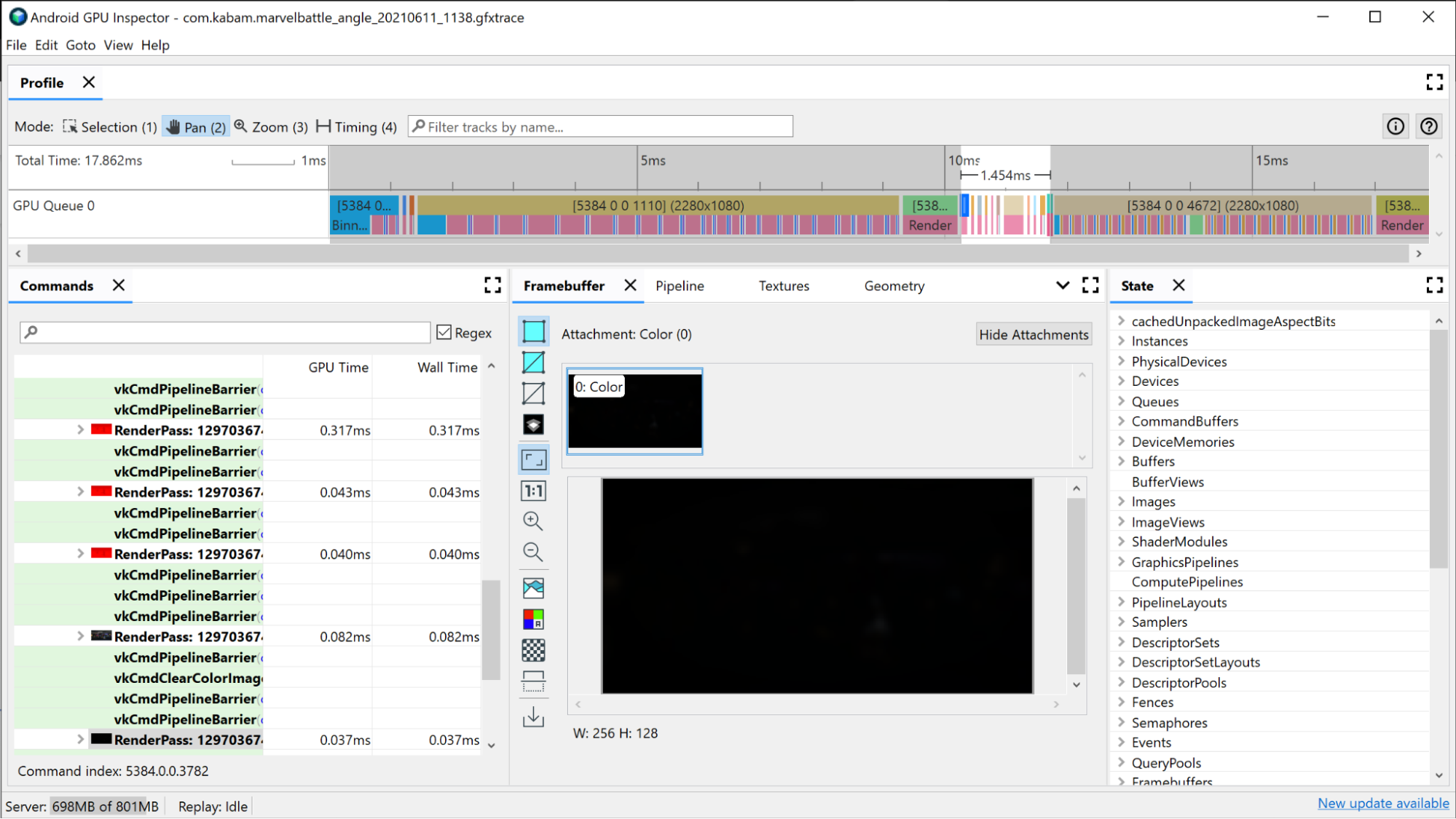
負荷の高いレンダリング パスを特定するには、まずウィンドウの上部にある AGI のタイムライン ビューを確認します。これにより、特定のフレームの合成を構成するすべてのレンダリング パスが時系列で表示されます。これは、GPU キュー情報がある場合に System Profiler に表示されるものと同じビューです。また、レンダリングされるフレームバッファの解像度など、レンダリングパスに関する基本情報も示されるため、レンダリングパス自体で何が起こっているのかに関するインサイトを得ることができます。
レンダリングパスを調査する際に使用できる最初の基準は、レンダリングパスにどれくらいの時間がかかっているかです。最も長いレンダリング パスは、改善の可能性が最も高いレンダリング パスである可能性が高いため、まずそちらを確認します。
![[Frame Timeline] ビューで最長のレンダリング パスを特定する](https://developer.android.com/static/images/agi/renderpass-images/image5.png?authuser=19&hl=ja)
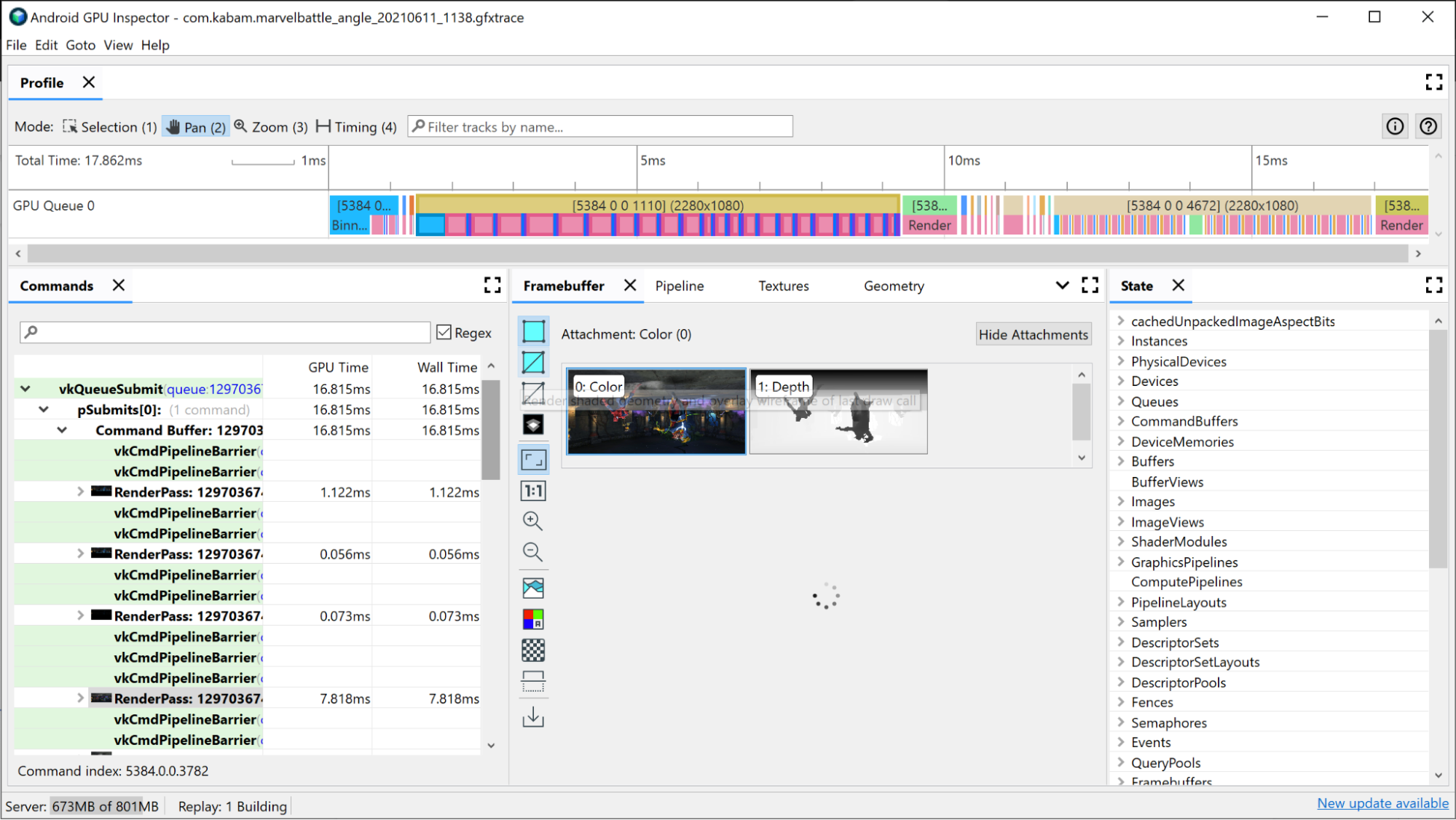
関連するレンダリングパスに関連する GPU スライスは、レンダリングパス内で起こっていることに関するいくつかの情報をすでに提示しています。
- ビニング: 画面上の位置に基づいて、頂点がビンに配置される場所
- レンダリング: ピクセルやフラグメントがシェーディングされる場所
- GMEM ロード/ストア: フレームバッファの内容が内部 GPU メモリからメインメモリにロードまたは保存されること
レンダリングパス内でそれぞれの所要時間を調べることで、ボトルネックになりそうな場所がよくわかります。次に例を示します。
- ビニングに多くの時間が費やされている場合は、頂点データによるボトルネックがあり、頂点が多すぎる、頂点が大きすぎる、または頂点に関連するその他の問題が発生していることを示している可能性があります。
- レンダリングに多くの時間が費やされている場合は、シェーディングがボトルネックであることを示しています。原因としては、複雑なシェーダー、テクスチャのフェッチが多すぎる、不要な場合に高解像度のフレームバッファへのレンダリングなど、その他の関連する問題が考えられます。
GMEM の読み込みと店舗についても念頭に置いてください。グラフィック メモリからメインメモリに何かを移動するには費用がかかるため、読み込み操作やストア操作の量を最小限に抑えることもパフォーマンスの向上に役立ちます。一般的な例としては、深度/ステンシルのバッファをメインメモリに書き出す GMEM ストアデプス/ステンシルがあります。将来のレンダリングパスでそのバッファを使用しない場合は、このストア オペレーションが不要になり、フレーム時間とメモリ帯域幅を節約できます。
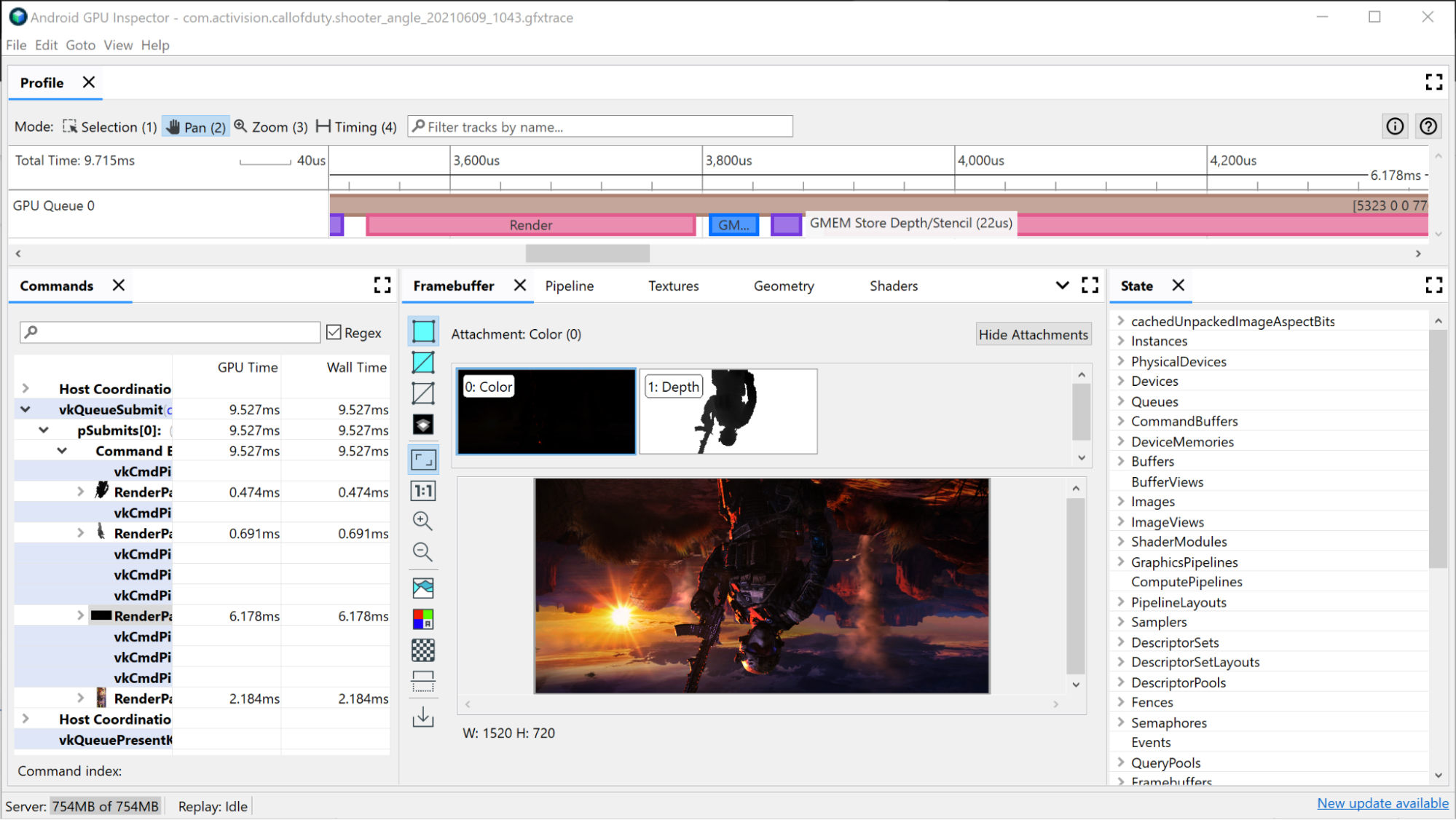
大規模なレンダリングパスの調査
レンダリングパス中に発行された個々の描画コマンドをすべて表示するには:
タイムラインでレンダリングパスをクリックします。これにより、[Frame Profiler] の [Commands] ペインにある階層でレンダリングパスが開きます。
レンダリングパスのメニューをクリックすると、レンダリングパス中に発行された個々の描画コマンドがすべて表示されます。これが OpenGL アプリの場合は、さらに掘り下げて、ANGLE が発行する Vulkan コマンドを確認できます。
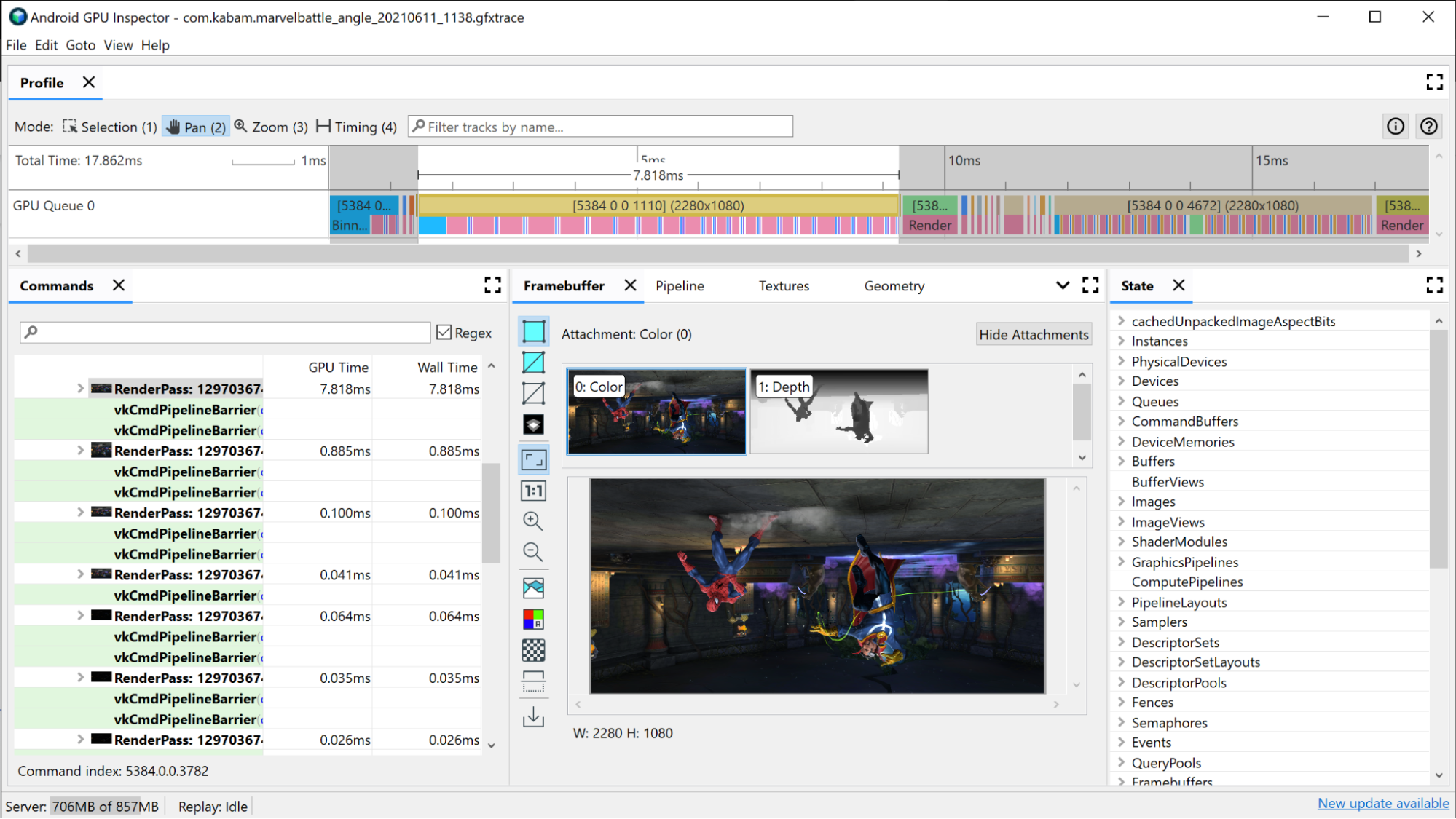
いずれかの描画呼び出しを選択します。[フレームバッファ] ペインが開き、この描画中にバインドされたすべてのフレームバッファ アタッチメントと、アタッチされたフレームバッファへの描画の最終結果が表示されます。ここでは、AGI を使用して前の描画呼び出しと次の描画呼び出しを開き、両者の違いを比較することもできます。両者が見た目ほぼ同じであれば、最終的な画像に影響を与えない描画呼び出しを削除できる機会があることがわかります。
この描画の [Pipeline] ペインを開くと、グラフィック パイプラインがこの描画呼び出しを実行するために使用する状態が表示されます。
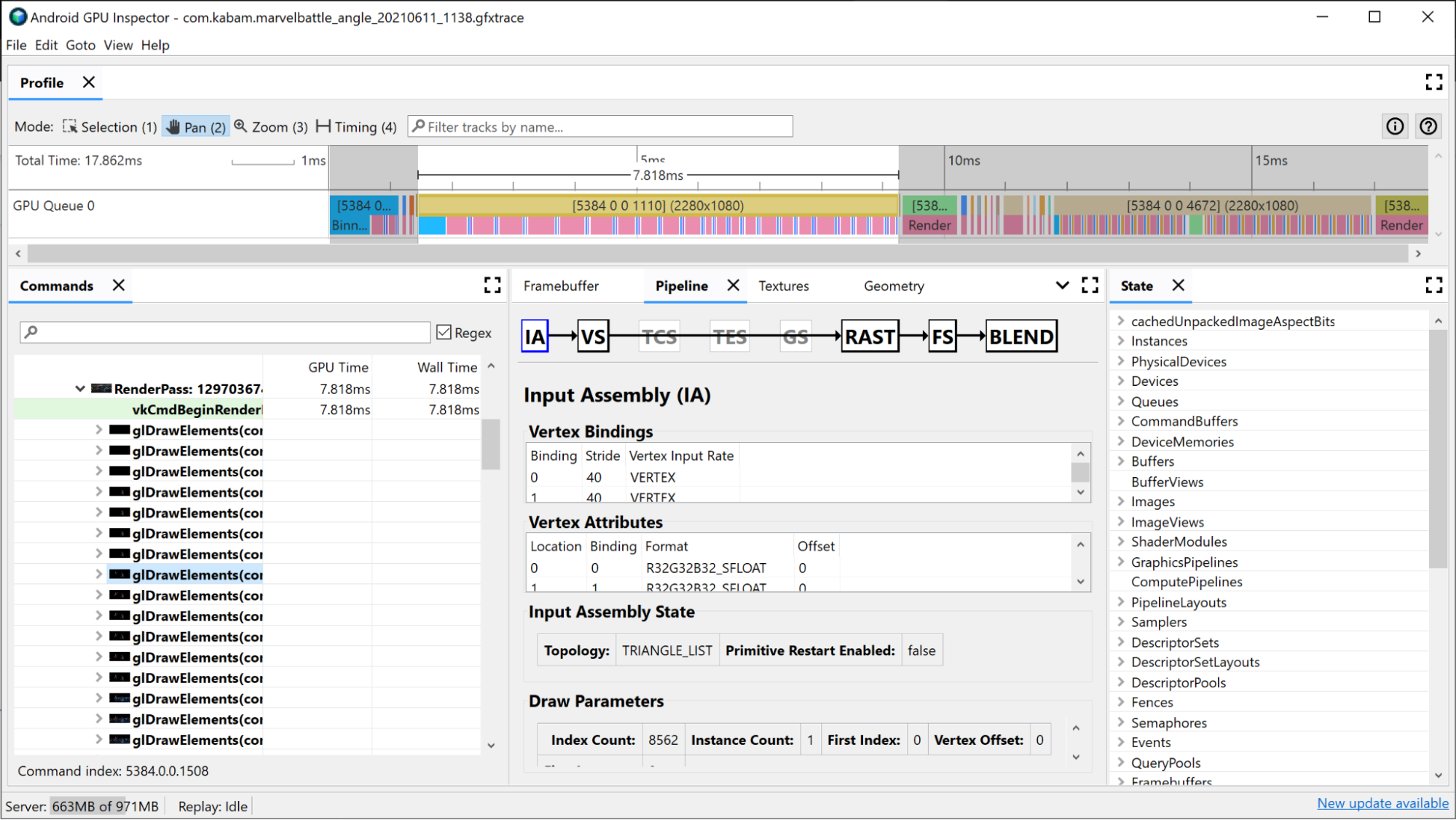
入力アセンブラは、頂点データがこの描画にどのようにバインドされたかに関する情報を提供します。ビニングがレンダリングパスの時間の大半を占めていることに気付いた場合は、ここを調査するとよいでしょう。ここでは、頂点の形式、描画される頂点の数、メモリ内での頂点のレイアウトに関する情報を確認できます。詳細については、頂点の形式を分析するをご覧ください。
![[Pipeline] ペインの入力アセンブラ セクション](https://developer.android.com/static/images/agi/renderpass-images/image11.png?authuser=19&hl=ja)
[Vertex Shader] セクションには、この描画中に使用した頂点シェーダーに関する情報が表示されます。また、ビニングが問題として識別されたかどうかを調べることもできます。使用されているシェーダーの SPIR-V と逆コンパイルされた GLSL が表示され、この呼び出しにバインドされている Uniform Buffer を調べることができます。詳細については、シェーダーのパフォーマンスを分析するをご覧ください。
![[パイプライン] ペインの [Vertex Shader] セクション](https://developer.android.com/static/images/agi/renderpass-images/image3.png?authuser=19&hl=ja)
[ラスタライザ] セクションには、パイプラインの固定関数の設定に関する情報が表示されます。これは、ビューポート、シザー、深度状態、ポリゴンモードなど、固定関数の状態をデバッグする目的で使用できます。
![[パイプライン] ペインの [ラスタライザ] セクション](https://developer.android.com/static/images/agi/renderpass-images/image2.png?authuser=19&hl=ja)
[Fragment Shader] セクションには、Vertex Shader セクションに記載されているものと同じ情報が多数含まれていますが、その多くがフラグメント シェーダーに固有のものです。この場合、どのテクスチャがバインドされているかを実際に確認し、ハンドルをクリックして調査できます。
![[Pipeline] ペインの [Fragment Shader] セクション](https://developer.android.com/static/images/agi/renderpass-images/image7.png?authuser=19&hl=ja)
レンダリングパスの調査を縮小
GPU のパフォーマンスを改善するために使用できるもう 1 つの基準は、小さなレンダリングパスのグループを調べることです。一般に、GPU があるレンダリングパスから別のレンダリングパスに状態を更新するのに時間がかかるため、レンダリング パスの量は可能な限り最小限に抑える必要があります。通常、こうした小さいレンダリング パスは、シャドウ マップの生成、ガウス ブラーの適用、輝度の推定、後処理効果の実行、UI のレンダリングなどに使用されます。そのうちのいくつかは、1 つのレンダリング パスに統合できる可能性があります。また、費用に見合うほど画像全体に影響を与えない場合は完全に除外されることもあります。