
L'affichage des traces du Profileur de processeur permet d'afficher les informations des traces enregistrées de plusieurs façons.
Pour les traces de méthode et de fonction, vous pouvez afficher l'onglet Call Chart (Graphique d'appel) directement dans la chronologie Threads, et les onglets Flame Chart (Graphique de flammes), Top Down (De haut en bas), Bottom Up (De bas en haut) et Events (Événements) à partir du volet Analysis (Analyse). Pour les frames de pile d'appel, vous pouvez afficher la partie du code qui a été exécutée et la raison pour laquelle elle a été appelée. Pour les traces système, vous pouvez afficher l'onglet Trace Events (Événements de trace) directement dans la chronologie Threads, et les onglets Flame Chart (Graphique de flammes), Top Down (De haut en bas), Bottom Up (De bas en haut) et Events (Événements) à partir du volet Analysis (Analyse).
Des raccourcis clavier et souris sont disponibles pour faciliter la navigation dans l'onglet Call Charts (Graphiques d'appel) ou Trace Events (Événements de trace).
Inspecter les traces à l'aide du graphique d'appel
Le graphique d'appel fournit une représentation graphique d'une trace de méthode ou de fonction, où la période et la durée d'un appel sont représentées sur l'axe horizontal, et les appelés sont indiqués le long de l'axe vertical. Les appels aux API système sont affichés en orange, les appels aux méthodes de votre application en vert et les appels aux API tierces (y compris les API du langage Java) en bleu. La figure 4 montre un exemple de graphique d'appel illustrant le concept de temps propre, de temps enfants et de temps total pour une méthode ou une fonction donnée. Pour en savoir plus sur ces concepts, consultez la section Inspecter les traces à l'aide des onglets "De haut en bas" et "De bas en haut".
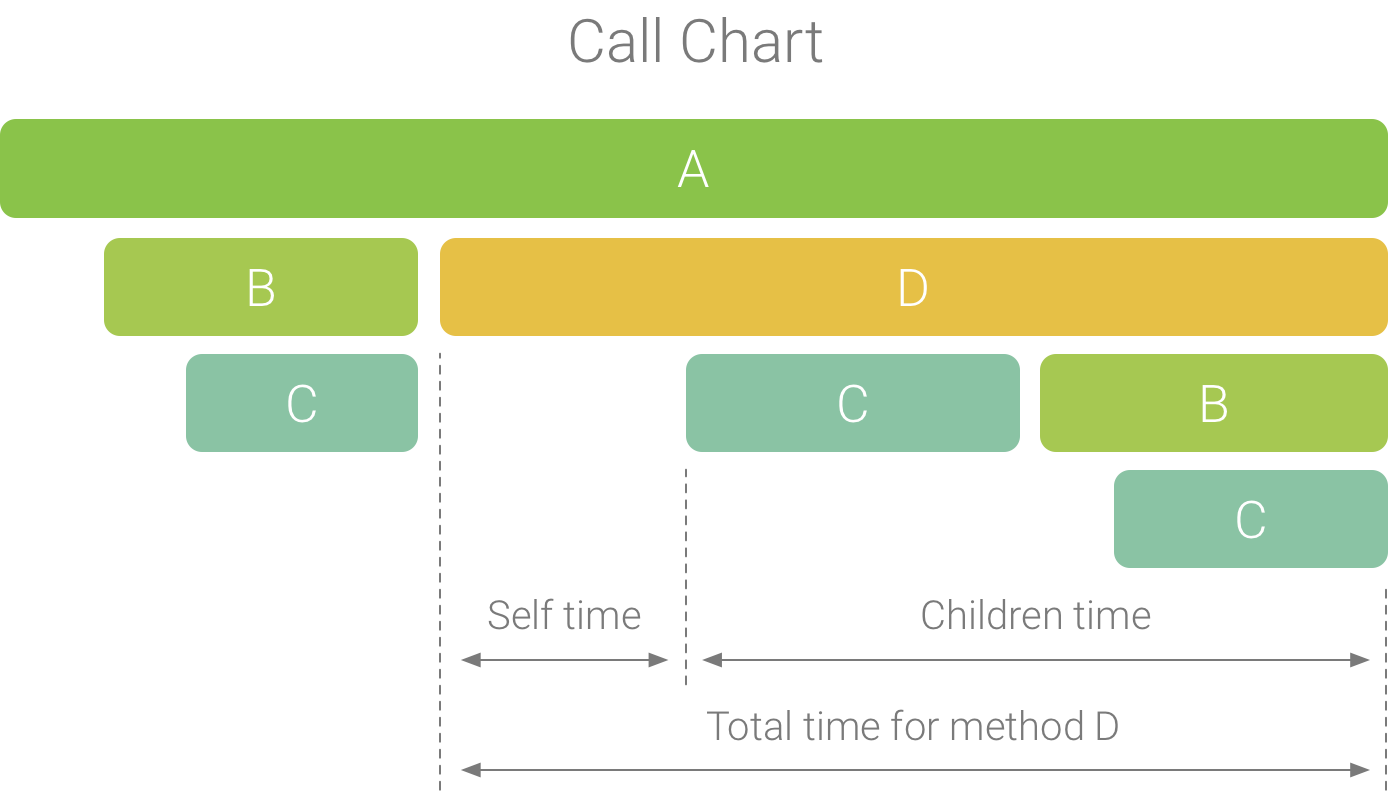
Figure 1 : Exemple de graphique d'appel illustrant le temps propre, le temps enfants et le temps total pour la méthode D.
Conseil : Pour accéder au code source d'une méthode ou d'une fonction, effectuez un clic droit dessus, puis sélectionnez Jump to Source (Accéder à la source). Cette opération est possible à partir de n'importe quel onglet du volet "Analyse".
Inspecter les traces à l'aide de l'onglet "Graphique de flammes"
L'onglet Flame Chart (Graphique de flammes) fournit un graphique d'appel inversé qui agrège les piles d'appels identiques. En d'autres termes, les méthodes ou fonctions identiques qui partagent la même séquence d'appelants sont collectées et représentées sous la forme d'une barre plus longue dans un graphique de flammes (plutôt que de les afficher sous la forme de plusieurs barres plus courtes, comme c'est le cas dans un graphique d'appel). Cela vous permet d'identifier plus facilement les méthodes ou fonctions qui consomment le plus de temps. Toutefois, cela signifie également que l'axe horizontal ne représente pas une chronologie, mais plutôt la durée d'exécution relative de chaque méthode ou fonction.
Pour illustrer ce concept, prenons l'exemple du graphique d'appel de la figure 2. Notez que la méthode D effectue plusieurs appels à B (B1, B2 et B3) et que certains de ces appels à B effectuent un appel à C (C1 et C3).
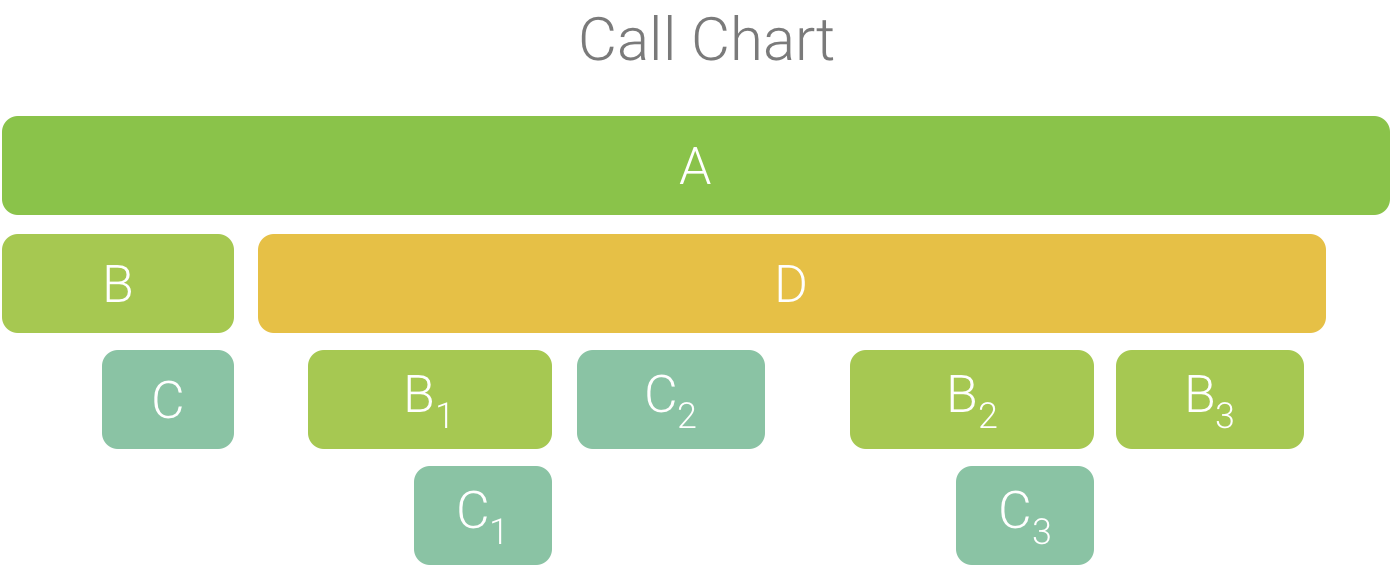
Figure 2. Graphique d'appel avec plusieurs appels de méthode partageant une séquence d'appelants commune.
Étant donné que B1, B2 et B3 partagent la même séquence d'appelants (A → D → B), ils sont agrégés, comme illustré à la figure 3. De même, C1 et C3 sont agrégés, car ils partagent la même séquence d'appelants (A → D → B → C). Notez que C2 n'est pas inclus, car il a une séquence d'appelants différente (A → D → C).
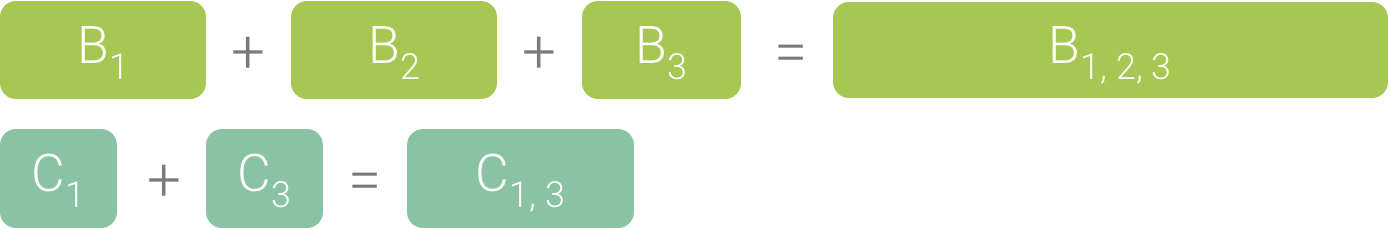
Figure 3. Agrégation de méthodes identiques qui partagent la même pile d'appel.
Les appels agrégés sont utilisés pour la création du graphique de flammes, comme illustré à la figure 4. Notez que, pour un appel donné dans un graphique de flammes, les appelés qui consomment le plus de temps CPU apparaissent en premier.
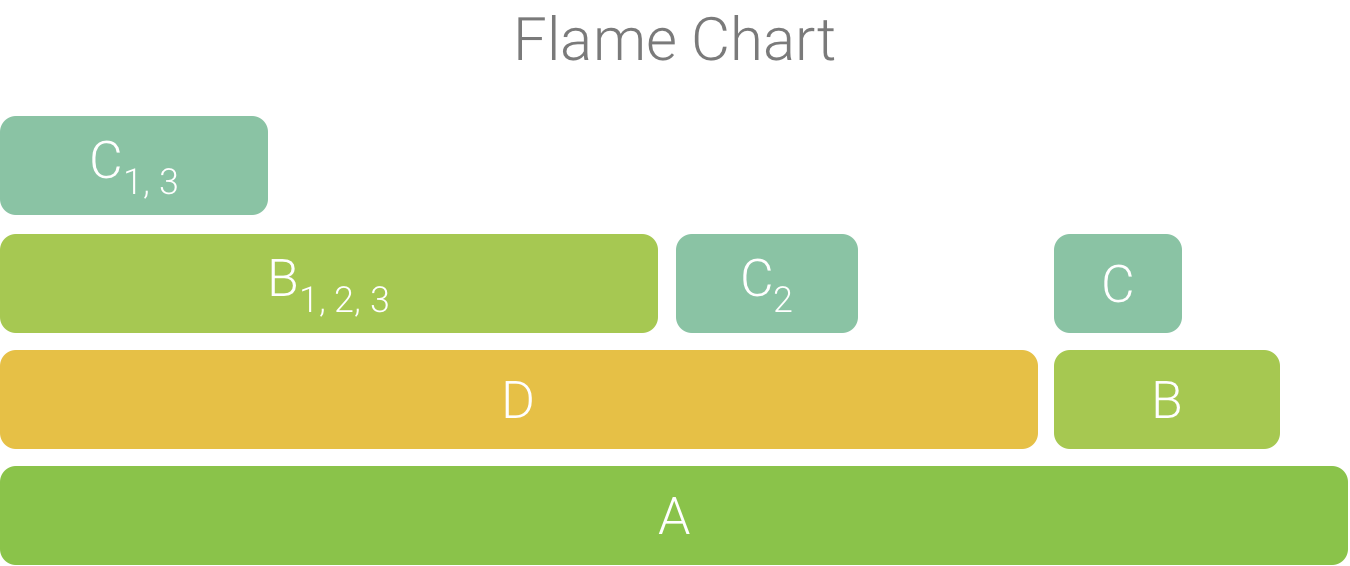
Figure 4. Représentation sous forme de graphique de flammes du graphique d'appel illustré à la figure 5.
Inspecter les traces à l'aide des onglets "De haut en bas" et "De bas en haut"
L'onglet Top Down affiche une liste d'appels dans laquelle le développement d'un nœud de méthode ou de fonction affiche les appelés. La figure 5 illustre un graphique de haut en bas pour le graphique d'appel de la figure 1. Chaque flèche du graphique pointe d'un appelant vers un appelé.
Comme le montre la figure 5, le développement du nœud de la méthode A dans l'onglet Top Down affiche les appelés de cette méthode, à savoir les méthodes B et D. Ensuite, le développement du nœud de la méthode D expose ses appelés, les méthodes B et C, et ainsi de suite. À l'instar de l'onglet Flame chart, l'arborescence de haut en bas agrège les informations de trace pour les méthodes identiques qui partagent la même pile d'appel. En d'autres termes, l'onglet Flame chart fournit une représentation graphique de l'onglet Top Down.
L'onglet Top Down fournit les informations suivantes pour décrire le temps CPU consacré à chaque appel (les durées sont également exprimées sous la forme d'un pourcentage du temps total du thread sur la plage sélectionnée) :
- Self (Parent) : temps passé par l'appel de méthode ou de fonction à exécuter son propre code, et non celui de ses appelés, comme le montre la figure 1 pour la méthode D.
- Children (Enfants) : temps passé par l'appel de méthode ou de fonction à exécuter ses appelés, et non son propre code, comme le montre la figure 1 pour la méthode D.
- Total : somme des durées Self et Children de la méthode. Il s'agit du temps total que l'application a passé à exécuter un appel, comme le montre la figure 1 pour la méthode D.
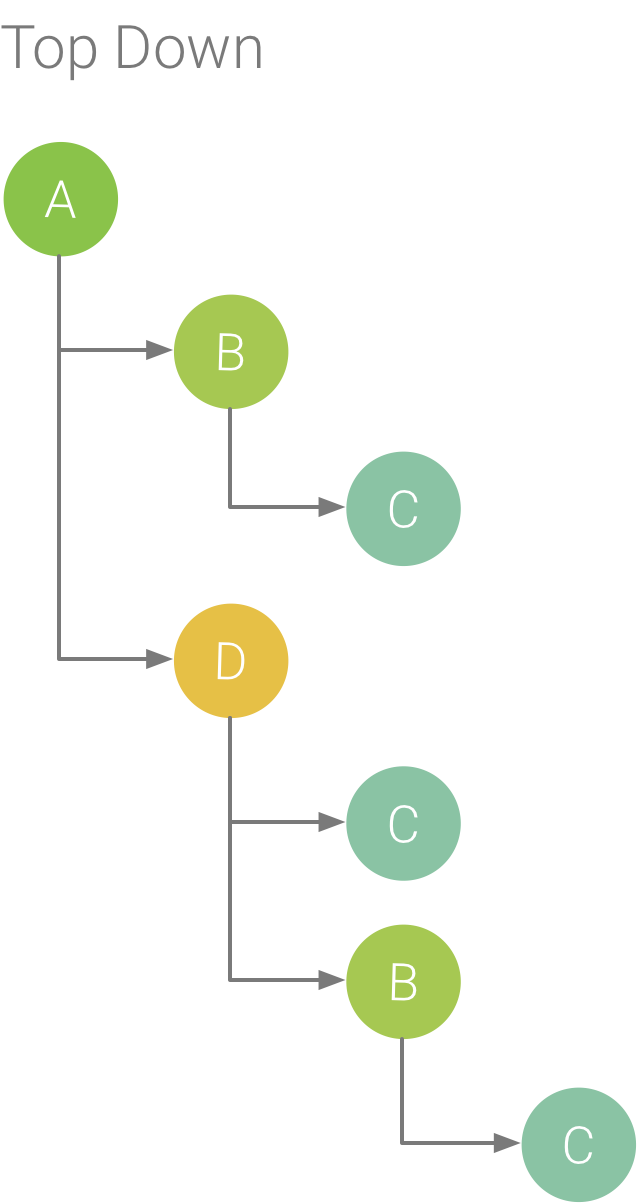
Figure 5. Arborescence de haut en bas.
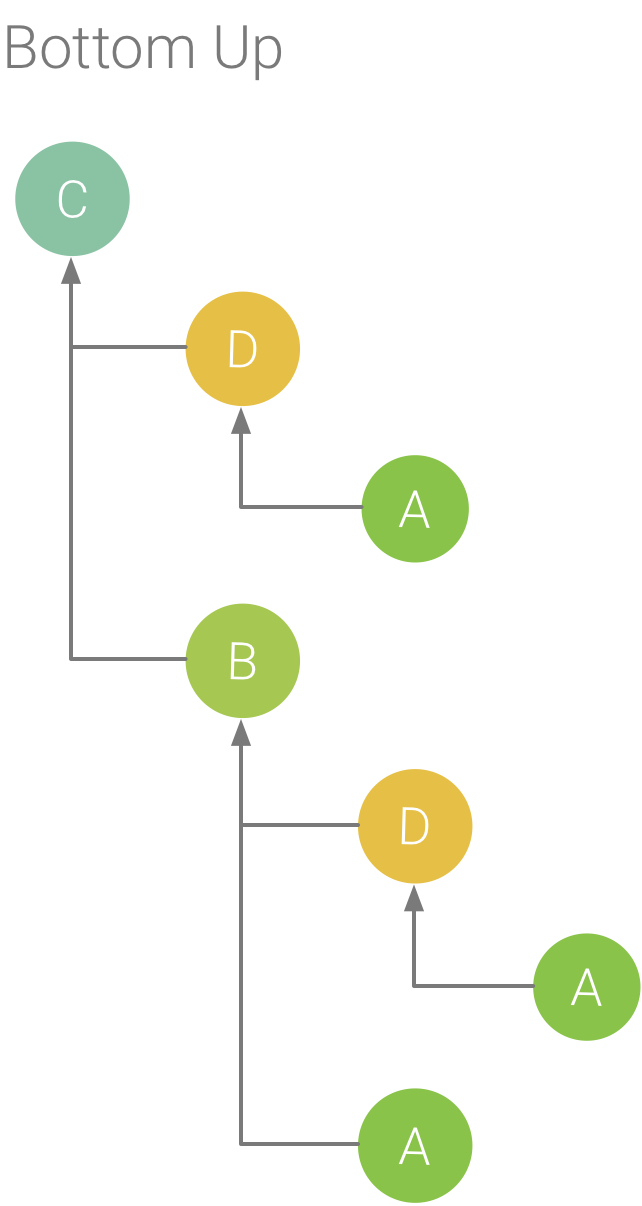
Figure 6. Arborescence de bas en haut pour la méthode C de la figure 5.
L'onglet Bottom Up affiche une liste d'appels dans laquelle le développement du nœud d'une méthode ou d'une fonction affiche les appelants. À l'aide de l'exemple de trace illustré à la figure 5, la figure 6 présente une arborescence de bas en haut pour la méthode C. L'ouverture du nœud de la méthode C dans l'arborescence de bas en haut affiche chacun de ses appelants uniques, les méthodes B et D. Bien que B appelle C à deux reprises, B n'apparaît qu'une seule fois lors du développement du nœud pour la méthode C dans l'arborescence de bas en haut. Ensuite, le développement du nœud de la méthode B affiche ses appelants, les méthodes A et D.
L'onglet Bottom Up est utile pour trier les méthodes ou fonctions suivant leur consommation de temps CPU. Vous pouvez inspecter chaque nœud pour identifier les appelants qui consacrent le plus de temps CPU à appeler ces méthodes ou fonctions. Par rapport à l'arborescence de haut en bas, les informations de durée de chaque méthode ou fonction d'une arborescence de bas en haut font référence à la méthode située en haut de chaque arborescence (nœud supérieur). Le temps CPU est également représenté sous la forme d'un pourcentage du temps total du thread au cours de cet enregistrement. Le tableau suivant vous explique comment interpréter les informations de durée pour le nœud supérieur et ses appelants (sous-nœuds).
| Propre | Enfants | Total | |
|---|---|---|---|
| Méthode ou fonction située au sommet de l'arborescence de bas en haut (nœud supérieur) | Représente le temps total passé par la méthode ou fonction à exécuter son propre code, et non celui de ses appelés. Par rapport à l'arborescence de haut en bas, ces informations de durée représentent la somme de tous les appels à cette méthode ou fonction pendant la durée de l'enregistrement. | Représente le temps total passé par la méthode ou fonction à exécuter ses appelés, et non son propre code. Par rapport à l'arborescence de haut en bas, ces informations de durée représentent la somme de tous les appels aux appelés de cette méthode ou fonction pendant la durée de l'enregistrement. | Somme du temps propre et du temps enfants. |
| Appelants (sous-nœuds) | Représente le temps propre total de l'appelé lorsqu'il est appelé par l'appelant. En utilisant comme exemple l'arborescence de bas en haut de la figure 6, le temps propre de la méthode B correspond à la somme des temps propres de chaque exécution de la méthode C lorsqu'elle est appelée par B. | Représente le temps enfants total de l'appelé lorsqu'il est appelé par l'appelant. En utilisant comme exemple l'arborescence de bas en haut de la figure 6, le temps enfants de la méthode B correspond à la somme des temps enfants de chaque exécution de la méthode C lorsqu'elle est appelée par B. | Somme du temps propre et du temps enfants. |
Remarque : Pour un enregistrement donné, Android Studio cesse de collecter de nouvelles données lorsque le profileur atteint la taille de fichier maximale (cependant, cela n'arrête pas l'enregistrement). En règle générale, cela se produit beaucoup plus rapidement lors de l'exécution de traces instrumentées, car ce type de traçage collecte davantage de données en moins de temps qu'une trace échantillonnée. Si vous étendez la durée d'inspection à une période de l'enregistrement qui s'est produite après avoir atteint la limite, les données temporelles du volet de trace ne changent pas (car aucune nouvelle donnée n'est disponible). De plus, le volet de trace affiche NaN pour les informations de durée lorsque vous ne sélectionnez que la partie d'un enregistrement pour laquelle aucune donnée n'est disponible.
Inspecter les traces à l'aide du tableau "Événements"
Le tableau "Événements" reprend tous les appels du thread actuellement sélectionné. Vous pouvez les trier en cliquant sur les en-têtes de colonne. Lorsque vous sélectionnez une ligne du tableau, vous pouvez parcourir la chronologie jusqu'à l'heure de début et l'heure de fin de l'appel sélectionné. Cela vous permet de localiser avec précision les événements dans la chronologie.
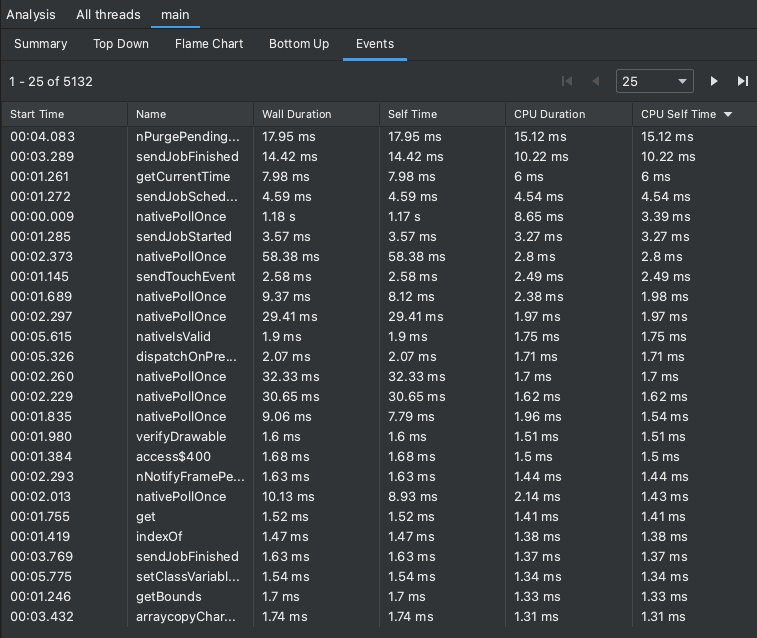
Figure 7. Affichage de l'onglet "Événements" du volet "Analyse".
Inspecter les frames de la pile d'appel
Les piles d'appels sont utiles pour comprendre quelle partie du code a été exécutée, ainsi que la raison de l'appel. Si un exemple d'enregistrement de pile d'appel est collecté pour un programme Java/Kotlin, la pile d'appel contient, en général, non seulement du code Java/Kotlin, mais aussi des frames du code natif JNI, la machine virtuelle Java (par exemple,
android::AndroidRuntime::start) et le noyau système ([kernel.kallsyms]+offset). Cela est dû au fait qu'un programme Java/Kotlin s'exécute généralement via une machine virtuelle Java. Le code natif est nécessaire pour l'exécution du programme proprement dit, et pour que celui-ci communique avec le système et le matériel. Le profileur présente ces frames pour plus de précision. Toutefois, l'utilité de ces frames d'appel supplémentaires dépendra de l'examen que vous avez effectué. Le profileur permet de réduire les frames qui ne vous intéressent pas afin de masquer les informations qui ne sont pas pertinentes pour votre enquête.
Dans l'exemple ci-dessous, la trace comporte de nombreux frames étiquetés [kernel.kallsyms]+offset, qui ne sont pas utiles actuellement pour le développement.
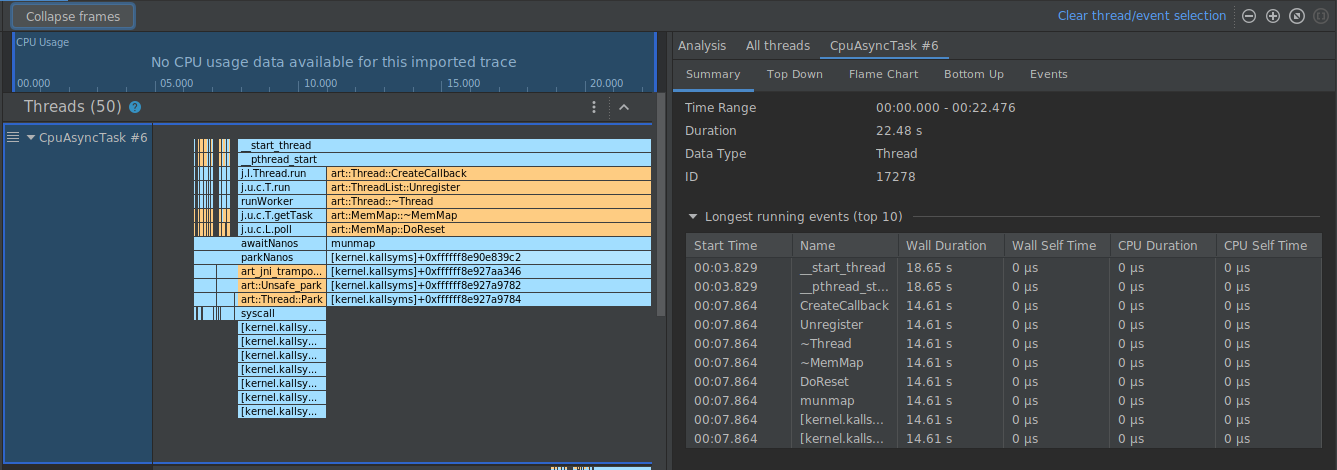
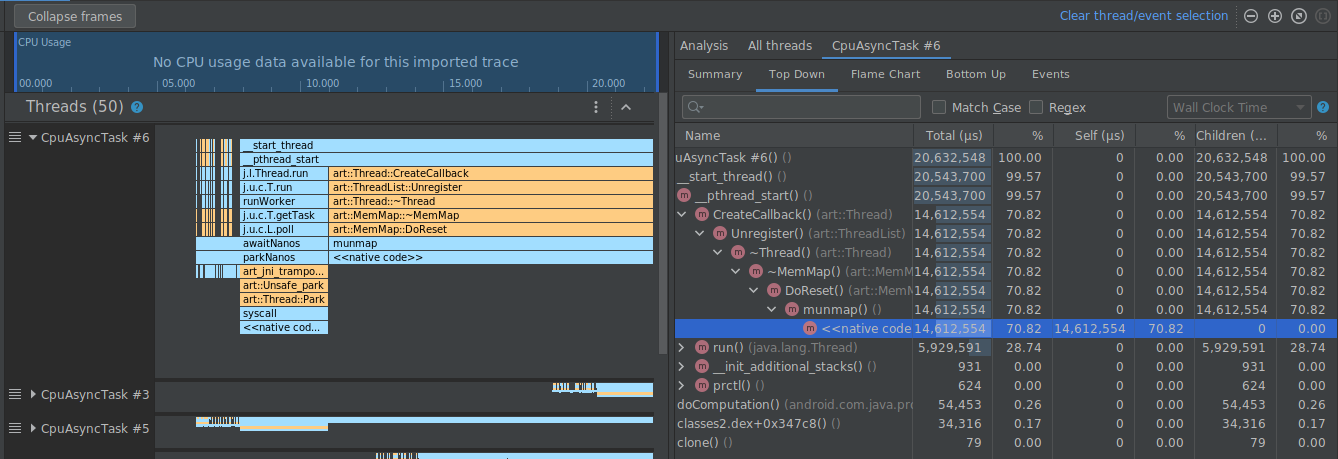
Pour réduire ces frames en un seul, vous devez sélectionner le bouton Collapse frames (Réduire les frames) dans la barre d'outils, choisir les chemins d'accès à réduire, puis sélectionner le bouton Apply (Appliquer) pour appliquer vos modifications. Dans cet exemple, le chemin d'accès est [kernel.kallsyms].
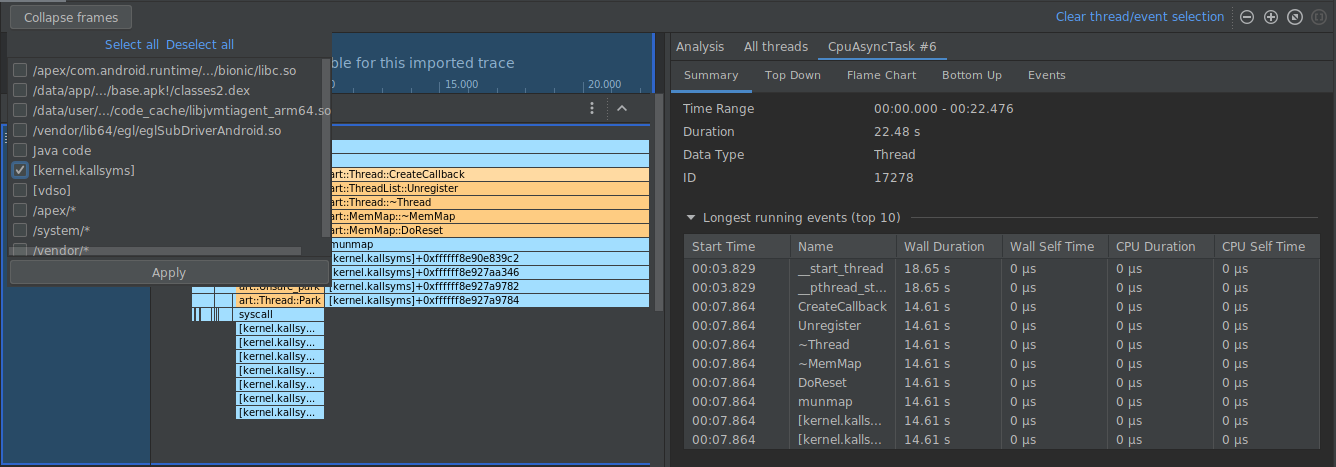
Cette opération réduit les frames correspondant au chemin d'accès sélectionné à la fois dans les panneaux de gauche et de droite, comme illustré ci-dessous.
Inspecter les traces système
Lorsque vous inspectez une trace système, vous pouvez examiner les événements de trace (Trace Events) dans la chronologie Threads pour afficher les détails des événements qui se produisent sur chaque thread. Passez le pointeur de la souris sur un événement pour afficher son nom et le temps passé dans chaque état. Cliquez sur un événement pour afficher plus d'informations dans le volet Analysis (Analyse).
Inspecter les traces système : cœurs de processeur
Outre les données de planification du processeur, les traces système contiennent la fréquence du processeur par cœur. Cela montre la quantité d'activité sur chaque cœur et peut vous aider à identifier ceux qui sont les "grands" ou "petits" cœurs dans les processeurs mobiles modernes.
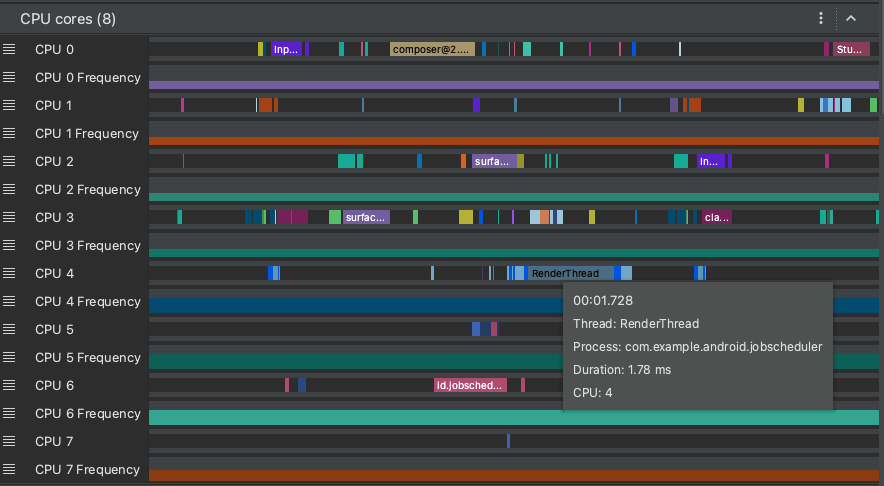
Figure 8. Affichage de l'activité du processeur et des événements de trace du thread de rendu.
Le volet CPU Cores (Cœurs de processeur) comme illustré à la figure 8 affiche l'activité de thread planifiée sur chaque cœur. Passez le pointeur de la souris sur une activité de thread pour voir sur quel thread ce cœur s'exécute à un moment donné.
Pour en savoir plus sur l'inspection des informations de la trace système, consultez la section Examiner les problèmes de performances de l'UI dans la documentation systrace.
Inspecter les traces système : chronologie du rendu des frames
Vous pouvez examiner le temps nécessaire à votre application pour afficher chaque frame du thread principal et à RenderThread pour identifier les goulots d'étranglement qui provoquent des à-coups dans l'UI et des fréquences d'images faibles. Pour savoir comment utiliser les traces système pour réduire les à-coups dans l'UI et en rechercher la cause, consultez Détection des à-coups dans l'interface utilisateur.
Inspecter les traces système : mémoire de processus (RSS)
Pour les applications déployées sur des appareils équipés d'Android 9 ou version ultérieure, la section Process Memory (RSS) (Mémoire de processus (RSS)) indique la quantité de mémoire physique actuellement utilisée par l'application.

Figure 9. Affichage de la mémoire physique dans le profileur.
Total
Il s'agit de la quantité totale de mémoire physique actuellement utilisée par votre processus. Sur les systèmes basés sur Unix, c'est ce qu'on appelle la "taille du jeu résident" (ou "resident set size", RSS). Elle combine toute la mémoire utilisée par les allocations anonymes, les mappages de fichiers et les allocations de mémoire partagées.
Dans l'environnement de développement Windows, c'est l'équivalent de la taille de la page de travail.
Allocated (Alloué)
Ce compteur surveille la quantité de mémoire physique actuellement utilisée par les allocations de mémoire normales du processus. Il s'agit d'allocations anonymes (non sauvegardées par un fichier spécifique) et privées (non partagées). Dans la plupart des applications, elles sont constituées d'allocations de segments de mémoire (avec malloc ou new) et de mémoire de pile. Lorsqu'elles sont échangées depuis la mémoire physique, ces allocations sont écrites dans le fichier d'échange du système.
File Mappings (Mappages de fichiers)
Ce compteur surveille la quantité de mémoire physique utilisée par le processus pour les mappages de fichiers, c'est-à-dire la mémoire mappée à partir des fichiers dans une région de mémoire par le gestionnaire de mémoire.
Shared (Partagé)
Ce compteur surveille la quantité de mémoire physique utilisée pour partager la mémoire entre ce processus et les autres processus du système.