
アプリ アーキテクチャは、高品質の Android アプリケーションの基盤です。適切に定義されたアーキテクチャを使用すると、スマートフォン、タブレット、折りたたみ式デバイス、ChromeOS デバイス、車載ディスプレイ、XR など、拡大し続ける Android デバイスのエコシステムに対応できる、スケーラブルで保守しやすいアプリを作成できます。
アプリの構成
標準的な Android アプリは、複数のアプリ コンポーネント(サービス、コンテンツ プロバイダ、ブロードキャスト レシーバなど)で構成されています。これらのコンポーネントは、アプリ マニフェストで宣言します。
アプリのユーザー インターフェースもコンポーネントです。以前は、複数の アクティビティを使用して UI が構築されていました
。しかし、最近のアプリではシングル アクティビティ アーキテクチャが使用されています。1 つの Activity が、画面または Jetpack Compose のデスティネーションのコンテナとして機能します。
複数のフォーム ファクタ
アプリは、スマートフォンだけでなく、 タブレット、折りたたみ式デバイス、 ChromeOS デバイスなど、さまざまなフォーム ファクタで実行できます。アプリが常に縦向きまたは横向きに固定されるとは限りません。デバイスの回転や折りたたみ式デバイスの折りたたみ / 展開などの構成変更により、アプリは UI を再構成する必要があり、アプリの状態に影響します。
リソースの制約
モバイル デバイス(大画面デバイスを含む)はリソースに限りがあるため、オペレーティング システムは、他のプロセスにリソースを割り当てるために、アプリのプロセスを任意のタイミングで停止する可能性があります。
起動条件の変動
リソースに限りがある環境では、アプリのコンポーネントは個別に順不同で起動される可能性があります。また、オペレーティング システムやユーザーによって随時破棄される可能性があります。そのため、アプリのデータや状態をアプリ コンポーネントに保存しないでください。アプリ コンポーネントは、互いに独立した自己完結型にしてください。
アーキテクチャに関する一般的な原則
アプリのデータや状態の保存にアプリ コンポーネントを使用できないとなると、アプリをどのように設計すればよいのでしょうか。
Android アプリのサイズが大きくなるにつれ、アプリを拡張できるアーキテクチャを定義することが重要になります。適切に設計されたアプリ アーキテクチャでは、アプリの各部分の境界と、各部分が担う役割を定義します。
関心の分離
具体的な原則に沿ってアプリ アーキテクチャを設計します。
最も重要な原則は関心の分離です。 つまり、明確に定義された役割と境界を持つメソッド、クラス、ファイル、パッケージ、モジュール、レイヤ にアプリを分割します。
すべてのコードを 1 つの Activity に記述するのはよくある間違いです。
Activity の主な役割は、アプリの UI をホストすることです。Android OS は、画面の回転などのユーザー操作や、メモリ不足などのシステム イベントに応じて、`Activity` のライフサイクルを制御し、頻繁に破棄して再作成します。
このような一時的な性質のため、アプリのデータや状態を保持するのには適していません。Activity にデータを保存すると、コンポーネントが再作成されたときにデータが失われます。データの永続性を確保し、安定したユーザー エクスペリエンスを提供するには、これらの UI コンポーネントに状態を委ねないでください。
アダプティブ レイアウト
デバイスの向きの変更やアプリ ウィンドウのサイズの変更など、構成の変更を適切に処理するアプリを構築します。アダプティブな正規レイアウトを実装して、さまざまなフォーム ファクタで 最適なユーザー エクスペリエンスを提供します。
UI をデータモデルで操作する
もう 1 つの重要な原則は、UI をデータモデルで操作することです(永続モデルをおすすめします)。データモデルはアプリのデータを表し、アプリの UI 要素やその他のコンポーネントから独立しています。つまり、UI とアプリ コンポーネントのライフサイクルには関連付けられませんが、OS がアプリのプロセスをメモリから削除することを決定したときは、破棄されます。
永続モデルが望ましい理由として、次の点が挙げられます。
Android OS がアプリを破棄してリソースを解放してもデータが失われない。
ネットワーク接続が不安定または利用不可の場合でもアプリが動作し続ける。
アプリ アーキテクチャをデータモデル クラスに基づいて構築すると、アプリの堅牢性とテストのしやすさを高めることができます。
信頼できる唯一の情報源
アプリ内で新しいデータ型を定義するときは、信頼できる唯一の情報源(SSOT)を割り当てます。SSOT はそのデータの「オーナー」であり、SSOT のみがそのデータを変更またはミューテーションできます。 そのために、SSOT は不変の型を使用してデータを公開します。SSOT がデータを変更するには、関数を公開するか、他の型が呼び出すことができるイベントを受け取ります。
このパターンには、次のようないくつかのメリットがあります。
- 特定のデータ型に対するすべての変更を 1 か所に集約できる
- 他の型によって改ざんされないようにデータを保護できる
- データに対する変更が追跡しやすくなり、バグを見つけやすくなる
オフライン ファーストのアプリでは、アプリデータの信頼できる情報源は、通常はデータベースです。場合によっては、信頼できる情報源は
ViewModelになります。
単方向データフロー
単方向データフロー(UDF)パターンでは、信頼できる唯一の情報源の原則が よく使用されます。UDF では、状態 は一方向にのみ流れます(通常は親コンポーネントから子コンポーネント)。データを変更するイベントはその反対方向に流れます。
Android では、一般的に状態またはデータは、上位スコープの階層の型から下位スコープの階層の型に流れます。一般的にイベントは、下位スコープの型からトリガーされ、対応するデータ型の SSOT に到達するまで流れます。たとえば、一般的にアプリデータはデータソースから UI に流れます。ボタンの押下などのユーザー イベントは UI から SSOT に流れ、SSOT でアプリデータが変更されて、不変の型で公開されます。
このパターンにより、データの整合性の保証が向上し、間違いの発生が減り、デバッグが簡単になります。つまり、SSOT パターンのすべてのメリットが実現されます。
UDF について詳しくは、 Jetpack Compose の単方向データフローをご覧ください。
アプリの推奨アーキテクチャ
アーキテクチャに関する一般的な原則を考慮して、各アプリを少なくとも 2 つのレイヤで設計します。
- UI レイヤ: 画面にアプリデータを表示します。
- データレイヤ: アプリのビジネス ロジックを含み、アプリデータを公開します。
ドメインレイヤというレイヤを追加することで、UI レイヤとデータレイヤの間のやり取りを簡素化でき、再利用できます。
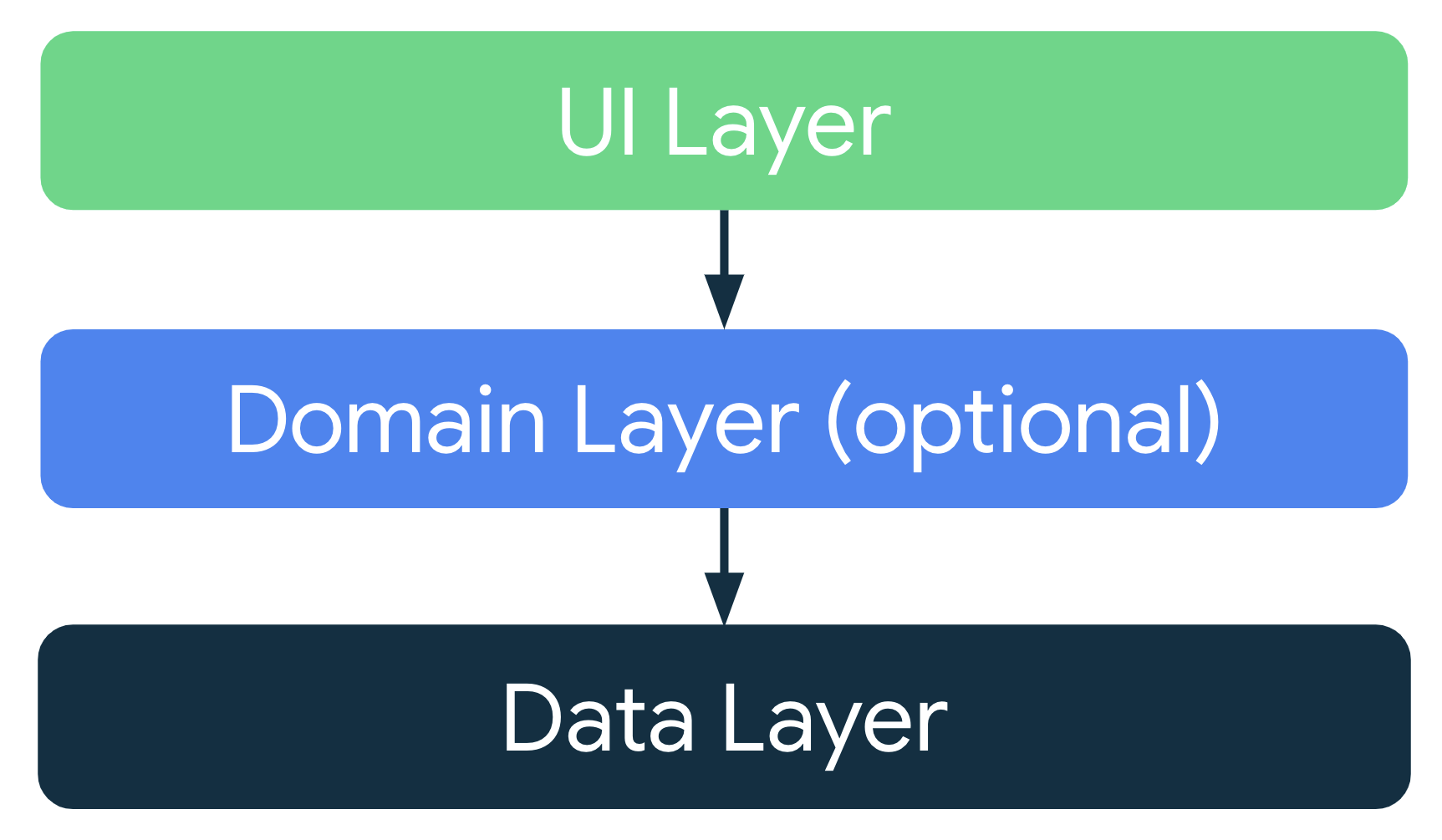
最新のアプリ アーキテクチャ
最新の Android アプリ アーキテクチャでは、次の手法が使用されています。
- アダプティブで階層的なアーキテクチャ
- アプリのすべてのレイヤにおける単方向データフロー(UDF)
- UI の複雑さを管理する状態ホルダーを含む UI レイヤ
- コルーチンとフロー
- 依存関係挿入のベスト プラクティス
詳しくは、 Android アーキテクチャの推奨事項をご覧ください。
UI レイヤ
UI レイヤ(またはプレゼンテーション レイヤ)の役割は、アプリデータを画面に表示することです。 ユーザー操作(ボタンの押下など)または外部入力(ネットワーク レスポンスなど)によってデータが変更されるたびに、変更を反映するように UI を更新します。
UI レイヤは次の 2 種類の構成要素で構成されています。
- データを画面にレンダリングする UI 要素。これらの要素は、 Jetpack Compose 関数を使用して作成し、アダプティブ レイアウトをサポートします。
- データを保持して UI に公開し、ロジックを処理する状態ホルダー(
ViewModel)。状態ホルダーは、状態を提供する UI 要素と同じ期間存続する必要があります。たとえば、画面の ViewModel は、画面がアプリのナビゲーション バックスタックから削除されるまでメモリに保持する必要があります。詳しくは、状態の有効期間をご覧ください。
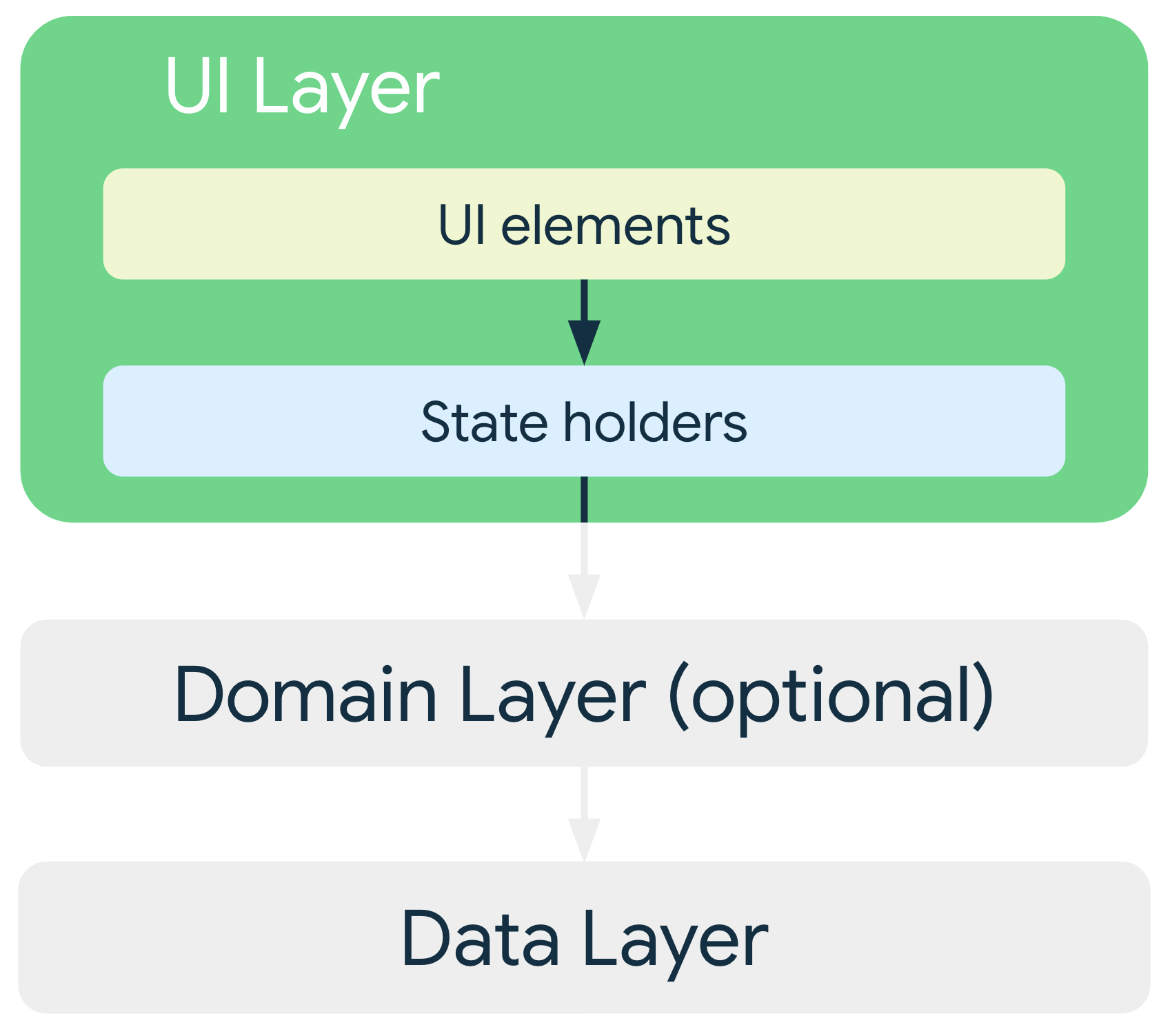
アダプティブ UI の場合、ViewModel オブジェクトなどの状態ホルダーは、さまざまな ウィンドウ サイズクラスに対応する UI 状態を
公開します。currentWindowAdaptiveInfo() を使用して、この UI 状態を取得できます。その後、NavigationSuiteScaffold などのコンポーネントは、この情報を使用して、使用可能な画面スペースに基づいてさまざまなナビゲーション パターン(NavigationBar、NavigationRail、NavigationDrawer など)を自動的に切り替えることができます。
詳しくは、UI レイヤと Compose UI アーキテクチャをご覧ください。
アダプティブ アプリとナビゲーションについて詳しくは、 アダプティブ アプリを作成するおよび アダプティブ ナビゲーションを作成するをご覧ください。
データレイヤ
アプリのデータレイヤには、ビジネス ロジックが含まれています。 ビジネス ロジックはアプリに価値をもたらすものであり、アプリがデータを作成、保存、変更する方法を決定するルールで構成されています。
データレイヤは、それぞれが 0 から多数のデータソースを含むことができるリポジトリで構成されています。アプリで処理するデータの種類ごとにリポジトリ クラスを作成します。たとえば、映画に関するデータであれば MoviesRepository クラス、支払いに関するデータであれば PaymentsRepository クラスを作成します。
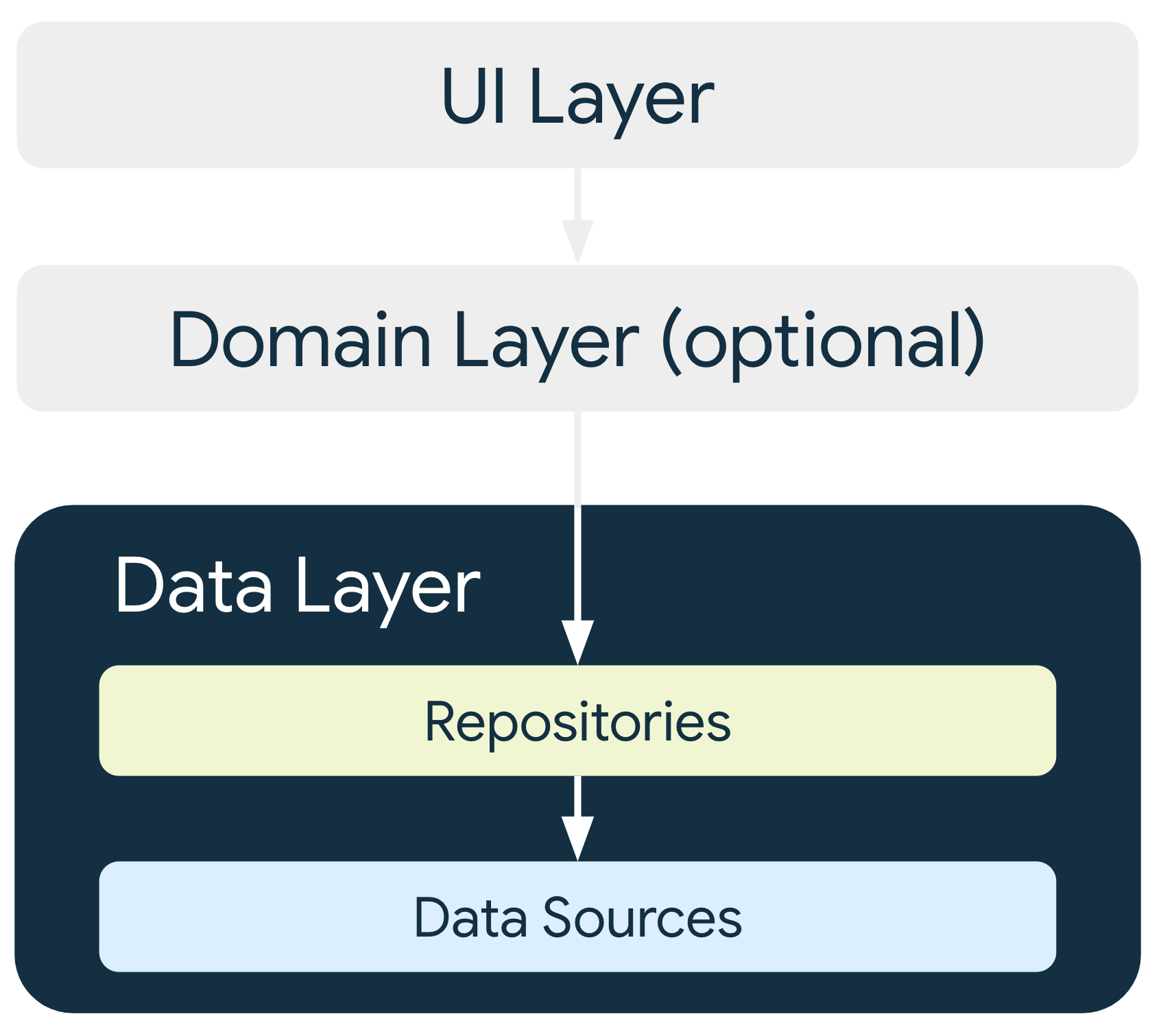
リポジトリ クラスは、次のことを担います。
- アプリの他の部分にデータを公開する
- データの変更を一元管理する
- 複数のデータソース間の競合を解決する
- アプリの他の部分からデータソースを抽象化する
- ビジネス ロジックを格納する
各データソース クラスは、ファイル、ネットワーク ソース、ローカル データベースなど、1 つのデータソースのみを処理する役割を担います。 データソース クラスは、データ オペレーションのためにアプリとシステムの橋渡しをします。
詳しくは、データレイヤのページをご覧ください。
ドメインレイヤ
ドメインレイヤは、UI レイヤとデータレイヤの間に位置するオプションのレイヤです。
ドメインレイヤは、複雑なビジネス ロジック、または複数の ViewModel で再利用される単純なビジネス ロジックをカプセル化します。すべてのアプリにこのような要件があるわけではないため、ドメインレイヤはオプションです。複雑さに対処する場合や再利用性を優先する場合など、必要な場合にのみ使用してください。
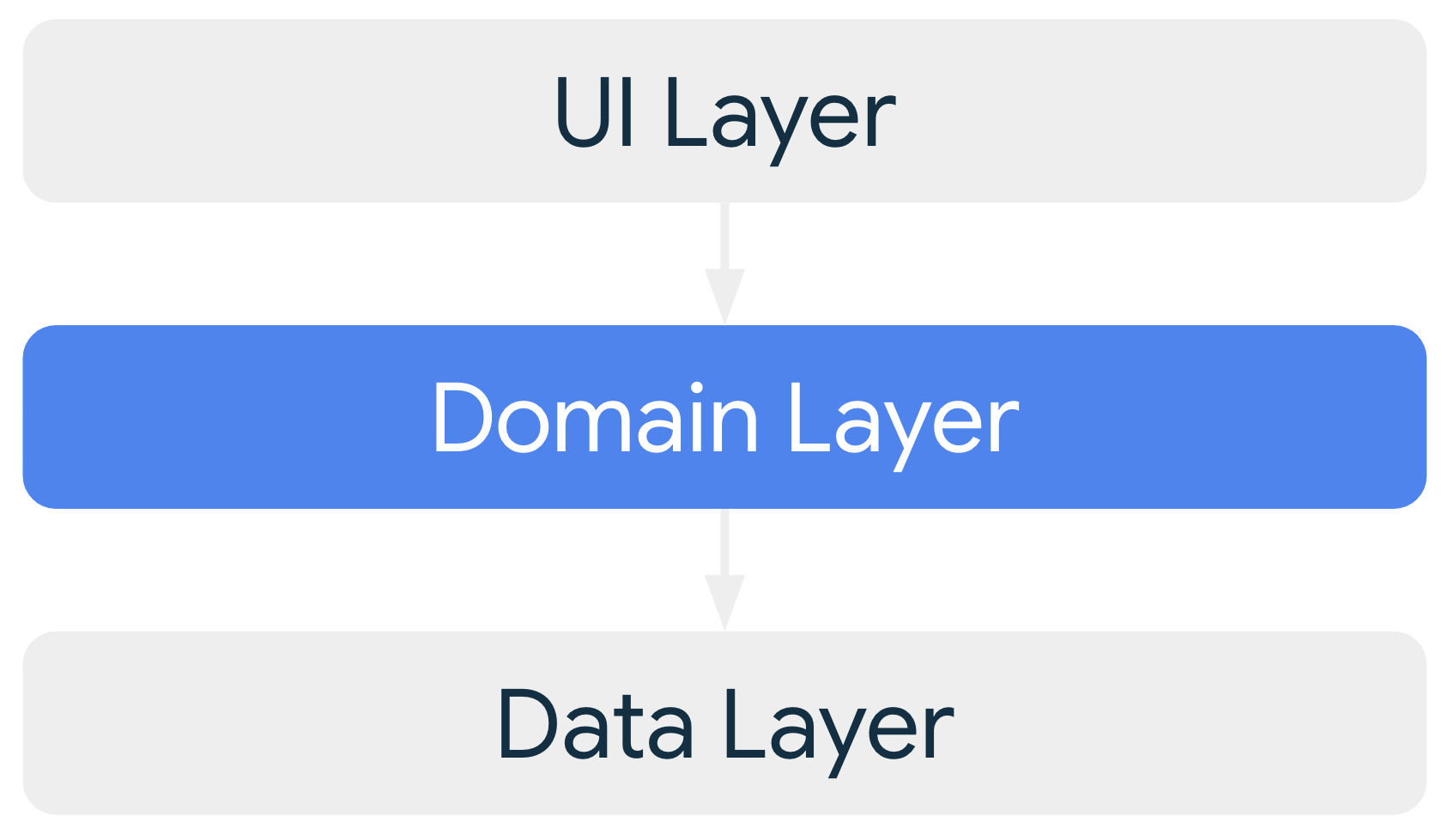
通常、ドメインレイヤのクラスをユースケースまたはインタラクターと呼びます。
各ユースケースは 1 つの機能を担います。たとえば、複数の ViewModel がタイムゾーンに基づいて適切なメッセージを画面に表示する場合、アプリに GetTimeZoneUseCase クラスを持たせることができます。
詳しくは、ドメインレイヤのページをご覧ください。
コンポーネント間の依存関係を管理する
アプリのクラスは、適切に機能するために他のクラスに依存しています。次のいずれかのデザイン パターンを使用して、特定のクラスの依存関係を収集できます。
- 依存性の注入(DI): 依存性の注入を利用すると、クラス の依存関係を構築することなく定義できます。ランタイムには、別のクラスがこの依存関係を提供します。
- サービス ロケータ: サービス ロケータ パターンでは、クラスが依存関係を作成せずに取得できるレジストリが提供されます。
こうしたパターンでは、コードが重複して煩雑になることなく依存関係を明確に管理できるため、コードの拡張が可能になります。また、テスト版と製品版の実装を簡単に切り替えることができます。
一般的なベスト プラクティス
プログラミングは創造的な活動であり、Android アプリの作成も例外ではありません。問題の解決方法は数多くあります。複数の Activity やフラグメント間でデータをやり取りする、リモートデータを取得してオフライン モード用にローカルで永続化するなど、重要なアプリで対処する一般的なシナリオにはさまざまなものがあります。
以下の推奨事項は必須ではありませんが、ほとんどの場合これに沿うことで、コードベースの堅牢性を高め、テストとメンテナンスを容易に実施できるようになります。
アプリのコンポーネントにデータを格納しないでください。
アプリのエントリ ポイント(アクティビティ、サービス、ブロードキャスト レシーバなど)をデータソースとして指定しないでください。エントリ ポイントが他のコンポーネントと連携して、そのエントリ ポイントに関連するデータのサブセットのみを取得するようにします。各アプリ コンポーネントの生存期間は、ユーザーによるデバイスの操作やシステムの容量によって短くなります。
Android クラスへの依存を減らします。
アプリ コンポーネントを、Android フレームワーク
SDK API に依存する唯一のクラスにします。ContextToastそこからアプリの他のクラスを抽象化すると、テストがしやすくなり、アプリ内の
結合を軽減できます。
アプリのモジュール間の責任の境界を明確に定義します。
ネットワークからデータを読み込むコードを、コードベース内の複数のクラスやパッケージに散在させないでください。同様に、関連のない複数の処理(データ キャッシングとデータ バインディングなど)を同じクラスで定義しないでください。 アプリの推奨アーキテクチャに沿ってください。
各モジュールからの公開はできるだけ行わないでください。
内部実装の詳細を公開するショートカットを作成しないでください。短期的には時間を少し節約できるかもしれませんが、コードベースが発展するにつれて何倍もの技術的負債を負うことになる可能性があります。
アプリのユニークなコアに焦点を当てて、他のアプリとの差別化を図ります。
同じボイラープレート コードを何度も書いてすでにあるものを作り直すのではなく、 アプリを特別なものにすることに時間とエネルギーを集中させましょう。繰り返しのボイラープレート コードの記述には Jetpack ライブラリやその他の推奨ライブラリを利用してください。
正規レイアウトとアプリ設計パターンを使用します。
Jetpack Compose ライブラリには、アダプティブ ユーザー インターフェースを構築するための堅牢な API が用意されています。アプリで正規レイアウトを使用して、 複数のフォーム ファクタとディスプレイ サイズでユーザー エクスペリエンスを最適化します。アプリ設計パターンの ギャラリーを確認して、ユースケースに最適なレイアウトを 選択します。
構成変更の前後で UI の状態を保存します。
アダプティブ レイアウトを設計する場合は、ディスプレイのサイズ変更、折りたたみ、画面の向きの変更などの構成変更の前後で UI の状態を保持します。アーキテクチャでは、ユーザーの現在の状態が維持され、シームレスなエクスペリエンスが提供されることを確認する必要があります。
再利用可能でコンポーズ可能な UI コンポーネントを設計します。
アダプティブ デザインをサポートするために、再利用可能でコンポーズ可能な UI コンポーネントを構築します。 これにより、大幅なリファクタリングを行わずに、さまざまな画面サイズや姿勢に合わせてコンポーネントを組み合わせたり、配置を変更したりできます。
アプリの各部分を個別にテストできるようにする方法を検討します。
ネットワークからデータを取得するための明確に定義された API を用意することで、そのデータをローカル データベースに永続化するモジュールを簡単にテストできるようになります。そうせずに、2 つの関数のロジックを 1 か所に混在させたり、ネットワーク用のコードをコードベース全体に分散させたりすると、不可能ではないにしても、テストが極めて困難になります。
型は同時実行ポリシーに関する責任を負います。
ある型が時間のかかるブロック処理を実行している場合、その型は適切なスレッドに計算を移動する責任を負います。型は、実行している計算の種類と、その計算をどのスレッドで実行する必要があるかを認識します。 型はメインセーフである(つまり、ブロックせずにメインスレッドから安全に呼び出せる)ことが必要です。
データの関連性と新鮮さをできる限り維持します。
こうすることで、デバイスがオフライン モードのときでも、ユーザーがアプリの機能を利用できるようになります。すべてのユーザーが常に高速な接続を利用できるわけではなく、たとえ利用できるとしても、混雑した場所では受信不良が起きる可能性があることに留意してください。
アーキテクチャのメリット
優れたアーキテクチャをアプリに実装することは、プロジェクト チームとエンジニアリング チームに次のような多くのメリットをもたらします。
- アプリ全体の保守性、品質、堅牢性が向上します。
- アプリのスケーリングが可能になります。より多くの人々とチームが、コードの競合を最小限に抑えながら、同じコードベースで開発に寄与できます。
- オンボーディングに役立ちます。アーキテクチャによってプロジェクトに整合性がもたらされるため、新しいメンバーが速やかにチームに適応し、短時間でより効率的に作業できるようになります。
- テストが簡単になります。優れたアーキテクチャでは、一般的にテストしやすいシンプルな型が推奨されます。
- 適切に定義されたプロセスを使用して、体系的にバグを調査できます。
優れたアーキテクチャの実装には事前の準備時間の投資が必要ですが、ユーザーにも直接的な影響を及ぼします。エンジニアリング チームの生産性が高まることで、アプリの安定性と機能性が向上します。
サンプル
次のサンプルは、優れたアプリ アーキテクチャを実証するものです。