
Während die UI-Schicht UI-bezogenen Status und UI-Logik enthält, enthält die Datenschicht Anwendungsdaten und Geschäftslogik. Die Geschäftslogik ist das, was Ihrer App Wert verleiht. Sie besteht aus realen Geschäftsregeln, die bestimmen, wie Anwendungsdaten erstellt, gespeichert und geändert werden müssen.
Durch diese Trennung von Belangen kann die Datenschicht auf mehreren Bildschirmen verwendet werden. Außerdem können Informationen zwischen verschiedenen Teilen der App ausgetauscht und Geschäftslogik außerhalb der Benutzeroberfläche für Unit-Tests reproduziert werden. Weitere Informationen zu den Vorteilen der Datenschicht finden Sie auf der Seite Architekturübersicht.
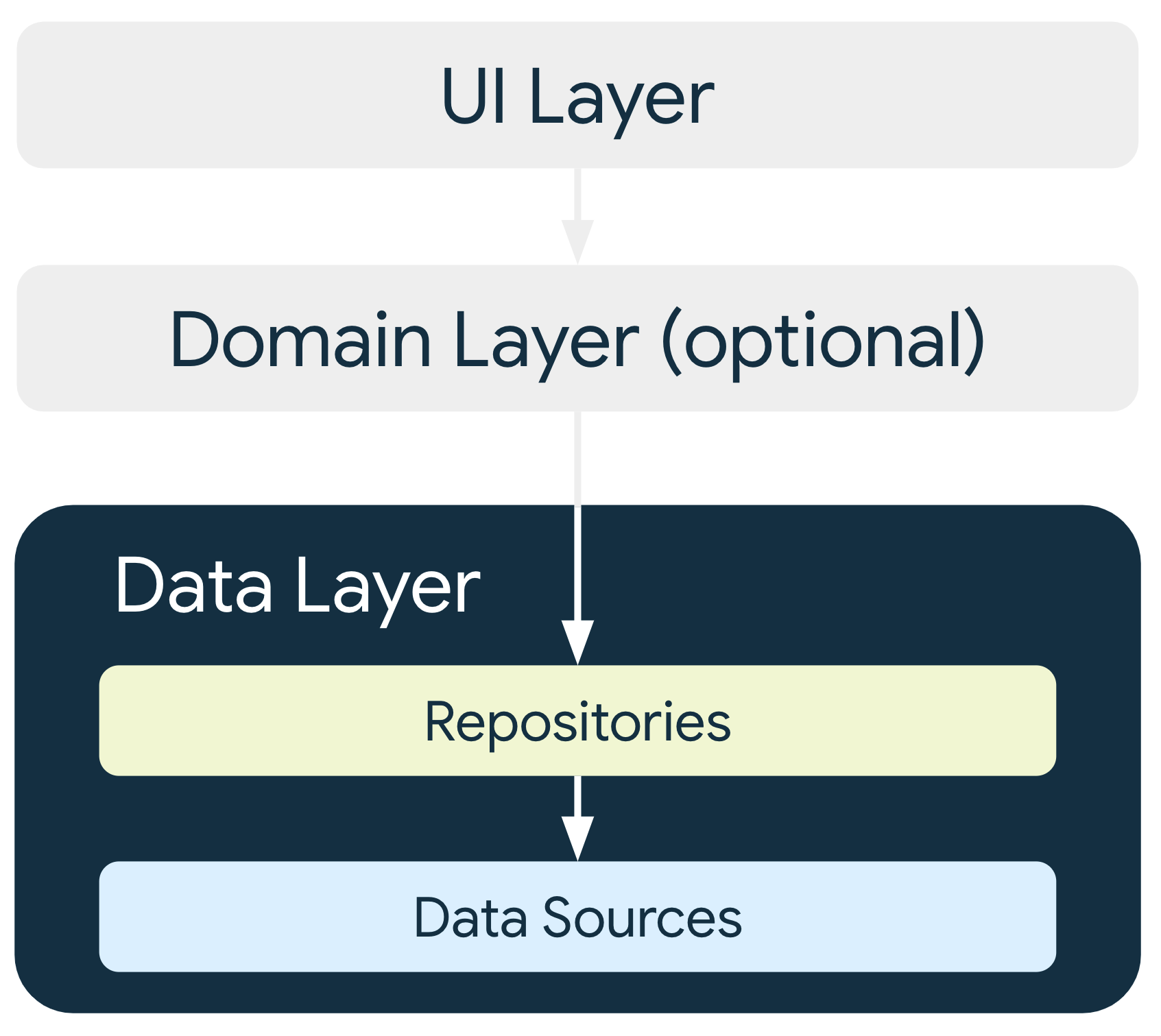
Architektur der Datenschicht
Die Datenschicht besteht aus Repositories, die jeweils null bis viele Datenquellen enthalten können. Sie sollten für jeden Datentyp, den Sie in Ihrer App verarbeiten, eine Repository-Klasse erstellen. Sie können beispielsweise eine MoviesRepository-Klasse für Daten zu Filmen oder eine PaymentsRepository-Klasse für Daten zu Zahlungen erstellen.
Repository-Klassen sind für die folgenden Aufgaben verantwortlich:
- Daten für den Rest der App verfügbar machen.
- Änderungen an den Daten zentralisieren.
- Konflikte zwischen mehreren Datenquellen beheben
- Datenquellen vom Rest der App abstrahieren
- Enthält Geschäftslogik.
Jede Datenquellenklasse sollte nur für die Verarbeitung einer Datenquelle zuständig sein. Das kann eine Datei, eine Netzwerkquelle oder eine lokale Datenbank sein. Datenquellenklassen sind die Brücke zwischen der Anwendung und dem System für Datenvorgänge.
Andere Ebenen in der Hierarchie sollten nie direkt auf Datenquellen zugreifen. Die Einstiegspunkte in die Datenschicht sind immer die Repository-Klassen. State-Holder-Klassen (siehe Anleitung für die UI-Schicht) oder Use-Case-Klassen (siehe Anleitung für die Domänenschicht) sollten niemals eine Datenquelle als direkte Abhängigkeit haben. Wenn Sie Repository-Klassen als Einstiegspunkte verwenden, können die verschiedenen Ebenen der Architektur unabhängig voneinander skaliert werden.
Die von dieser Ebene bereitgestellten Daten sollten unveränderlich sein, damit sie nicht von anderen Klassen manipuliert werden können. Dadurch würde das Risiko bestehen, dass die Werte in einen inkonsistenten Zustand geraten. Unveränderliche Daten können auch sicher von mehreren Threads verarbeitet werden. Weitere Informationen finden Sie im Abschnitt zu Threads.
Gemäß den Best Practices für die Abhängigkeitsinjektion werden Datenquellen als Abhängigkeiten im Konstruktor des Repositorys verwendet:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
APIs bereitstellen
Klassen in der Datenschicht stellen in der Regel Funktionen bereit, mit denen einmalige CRUD-Aufrufe (Create, Read, Update, Delete) ausgeführt oder Benachrichtigungen über Datenänderungen im Zeitverlauf empfangen werden können. Die Datenschicht sollte für jeden dieser Fälle Folgendes bereitstellen:
- Für einmalige Vorgänge sollten Sie suspend-Funktionen bereitstellen.
- Wenn Sie Flows verfügbar machen, werden Sie über Datenänderungen im Zeitverlauf benachrichtigt.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Namenskonventionen in diesem Leitfaden
In diesem Leitfaden werden Repository-Klassen nach den Daten benannt, für die sie zuständig sind. Die Konvention lautet so:
Datentyp + Repository.
Beispiel: NewsRepository, MoviesRepository oder PaymentsRepository.
Datenquellenklassen werden nach den Daten benannt, für die sie zuständig sind, und nach der Quelle, die sie verwenden. Die Konvention lautet so:
Datentyp + Quelltyp + DataSource.
Verwenden Sie für den Datentyp Remote oder Local, um allgemeiner zu sein, da sich Implementierungen ändern können. Beispiel: NewsRemoteDataSource oder NewsLocalDataSource. Wenn die Quelle wichtig ist, können Sie sie genauer angeben. Beispiel: NewsNetworkDataSource oder NewsDiskDataSource.
Benennen Sie die Datenquelle nicht nach einem Implementierungsdetail, z. B. UserSharedPreferencesDataSource, da Repositorys, die diese Datenquelle verwenden, nicht wissen sollten, wie die Daten gespeichert werden. Wenn Sie diese Regel befolgen, können Sie die Implementierung der Datenquelle ändern (z. B. von SharedPreferences zu DataStore migrieren), ohne die Ebene zu beeinträchtigen, die diese Quelle aufruft.
Mehrere Repository-Ebenen
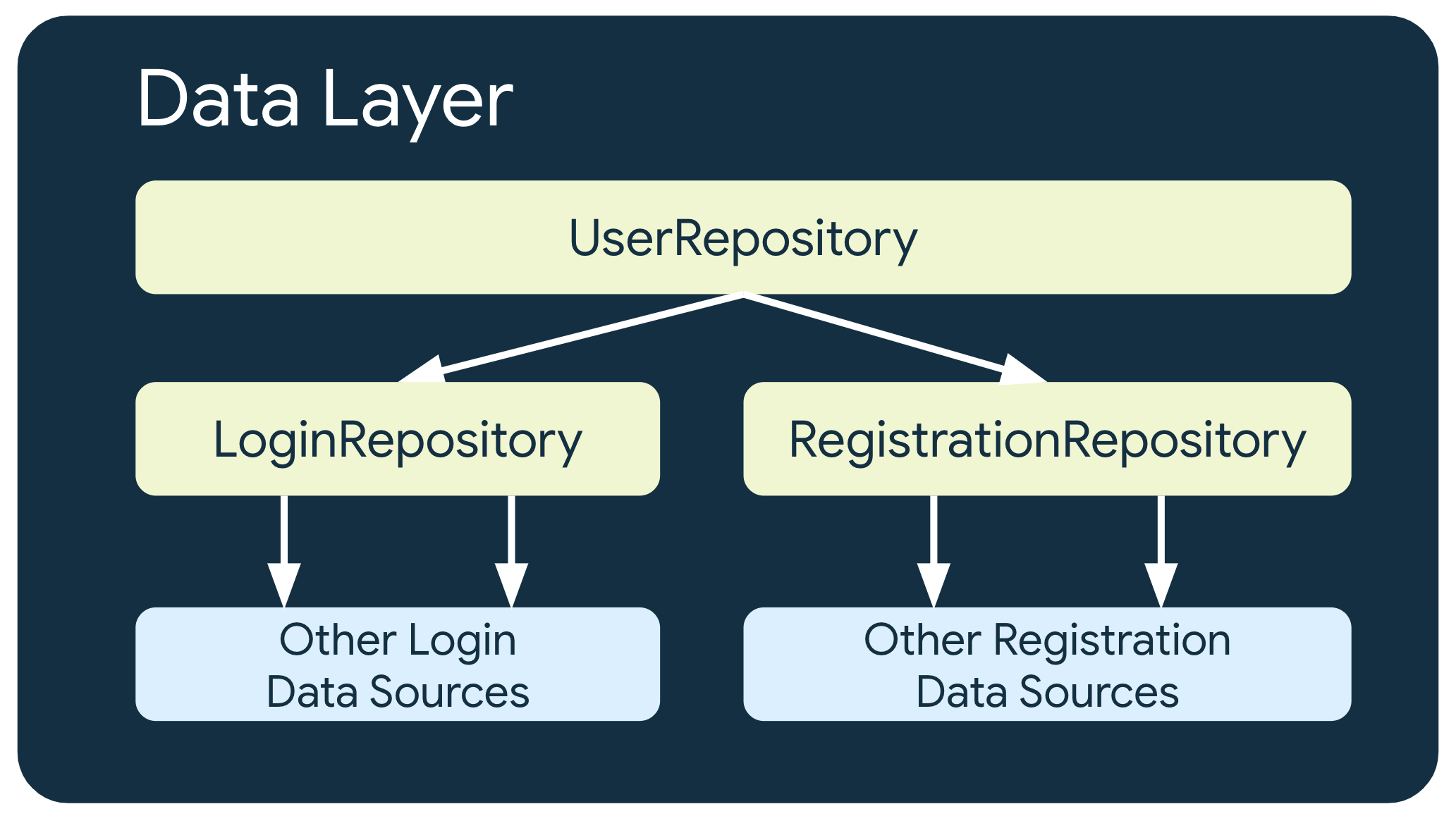
In einigen Fällen mit komplexeren geschäftlichen Anforderungen muss ein Repository möglicherweise von anderen Repositories abhängig sein. Das kann daran liegen, dass die betreffenden Daten eine Aggregation aus mehreren Datenquellen sind oder dass die Verantwortung in einer anderen Repository-Klasse gekapselt werden muss.
Ein Repository, das Nutzerauthentifizierungsdaten verarbeitet, UserRepository, kann beispielsweise von anderen Repositories wie LoginRepository und RegistrationRepository abhängig sein, um seine Anforderungen zu erfüllen.
Source of Truth
Es ist wichtig, dass in jedem Repository eine Single Source of Truth definiert wird. Die Single Source of Truth enthält immer konsistente, korrekte und aktuelle Daten. Die Daten, die über das Repository bereitgestellt werden, sollten immer direkt aus der Quelle der Wahrheit stammen.
Die zentrale Informationsquelle kann eine Datenquelle sein, z. B. die Datenbank, oder auch ein In-Memory-Cache, den das Repository möglicherweise enthält. In Repositories werden verschiedene Datenquellen kombiniert und alle potenziellen Konflikte zwischen den Datenquellen behoben, um die zentrale Informationsquelle regelmäßig oder aufgrund eines Nutzereingabeereignisses zu aktualisieren.
Verschiedene Repositories in Ihrer App können unterschiedliche „Sources of Truth“ haben. Die Klasse LoginRepository verwendet beispielsweise möglicherweise ihren Cache als Quelle der Wahrheit und die Klasse PaymentsRepository die Netzwerkdatenquelle.
Um die Offline-First-Unterstützung zu ermöglichen, empfehlen wir eine lokale Datenquelle wie eine Datenbank als Source of Truth.
Threading
Das Aufrufen von Datenquellen und ‑repositories sollte main-safe sein, d. h., es sollte sicher sein, sie vom Hauptthread aus aufzurufen. Diese Klassen sind dafür verantwortlich, die Ausführung ihrer Logik auf den entsprechenden Thread zu verschieben, wenn lang andauernde blockierende Vorgänge ausgeführt werden. Beispielsweise sollte es für eine Datenquelle main-safe sein, aus einer Datei zu lesen, oder für ein Repository, eine aufwendige Filterung einer großen Liste durchzuführen.
Beachten Sie, dass die meisten Datenquellen bereits Main-Safe-APIs wie die von Room, Retrofit oder Ktor bereitgestellten Methodenaufrufe für das Aussetzen bereitstellen. Ihr Repository kann diese APIs nutzen, wenn sie verfügbar sind.
Weitere Informationen zu Threads finden Sie im Leitfaden zur Hintergrundverarbeitung. Für Kotlin-Nutzer sind Coroutines die empfohlene Option.
Lebenszyklus
Instanzen von Klassen in der Datenschicht bleiben im Arbeitsspeicher, solange sie von einem Root für die automatische Speicherbereinigung aus erreichbar sind. Das ist in der Regel der Fall, wenn sie von anderen Objekten in Ihrer App referenziert werden.
Wenn eine Klasse In-Memory-Daten enthält, z. B. einen Cache, möchten Sie möglicherweise dieselbe Instanz dieser Klasse für einen bestimmten Zeitraum wiederverwenden. Dies wird auch als Lebenszyklus der Klasseninstanz bezeichnet.
Wenn die Verantwortung der Klasse für die gesamte Anwendung entscheidend ist, können Sie eine Instanz dieser Klasse auf die Application-Klasse beschränken. Dadurch folgt die Instanz dem Lebenszyklus der Anwendung. Wenn Sie dieselbe Instanz nur in einem bestimmten Ablauf in Ihrer App wiederverwenden müssen, z. B. im Registrierungs- oder Anmeldeablauf, sollten Sie die Instanz auf die Klasse beschränken, die den Lebenszyklus dieses Ablaufs besitzt. Sie können beispielsweise einen RegistrationRepository, der In-Memory-Daten enthält, auf den RegistrationActivity oder auf einen Backstack mit einem NavEntryDecorator beschränken.
Der Lebenszyklus jeder Instanz ist ein wichtiger Faktor bei der Entscheidung, wie Abhängigkeiten in Ihrer App bereitgestellt werden. Es wird empfohlen, Best Practices für die Abhängigkeitsinjektion zu befolgen, bei denen die Abhängigkeiten verwaltet und auf Abhängigkeitscontainer beschränkt werden können. Weitere Informationen zu Scoping in Android finden Sie im Blogpost Scoping in Android and Hilt.
Geschäftsmodelle darstellen
Die Datenmodelle, die Sie über die Datenschicht verfügbar machen möchten, sind möglicherweise eine Teilmenge der Informationen, die Sie aus den verschiedenen Datenquellen erhalten. Im Idealfall sollten die verschiedenen Datenquellen – sowohl Netzwerk- als auch lokale – nur die Informationen zurückgeben, die Ihre Anwendung benötigt. Das ist jedoch selten der Fall.
Stellen Sie sich beispielsweise einen News API-Server vor, der nicht nur die Artikelinformationen, sondern auch den Bearbeitungsverlauf, Nutzerkommentare und einige Metadaten zurückgibt:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
Die App benötigt nicht so viele Informationen zum Artikel, da sie nur den Inhalt des Artikels auf dem Bildschirm anzeigt, zusammen mit grundlegenden Informationen zum Autor. Es empfiehlt sich, Modellklassen zu trennen und in den Repositories nur die Daten verfügbar zu machen, die für die anderen Ebenen der Hierarchie erforderlich sind. So können Sie beispielsweise die ArticleApiModel aus dem Netzwerk entfernen, um eine Article-Modellklasse für die Domain- und UI-Ebenen verfügbar zu machen:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Die Trennung von Modellklassen bietet folgende Vorteile:
- Dadurch wird der Arbeitsspeicher der App geschont, da nur die benötigten Daten abgerufen werden.
- Sie passt externe Datentypen an die von Ihrer App verwendeten Datentypen an. Ihre App verwendet beispielsweise möglicherweise einen anderen Datentyp für die Darstellung von Datumsangaben.
- Es bietet eine bessere Trennung der Belange. So können beispielsweise Mitglieder eines großen Teams einzeln an den Netzwerk- und UI-Layern einer Funktion arbeiten, wenn die Modellklasse im Voraus definiert ist.
Sie können diese Vorgehensweise auch auf andere Teile Ihrer App-Architektur ausweiten und separate Modellklassen definieren, z. B. in Datenquellenklassen und ViewModels. Dazu müssen Sie jedoch zusätzliche Klassen und Logik definieren, die Sie richtig dokumentieren und testen sollten. Es wird empfohlen, neue Modelle zu erstellen, wenn eine Datenquelle Daten empfängt, die nicht den Erwartungen des Rests Ihrer App entsprechen.
Arten von Datenvorgängen
Die Datenschicht kann verschiedene Arten von Vorgängen verarbeiten, je nachdem, wie wichtig sie sind: UI-orientierte, app-orientierte und geschäftsorientierte Vorgänge.
UI-orientierte Vorgänge
UI-orientierte Vorgänge sind nur relevant, wenn sich der Nutzer auf einem bestimmten Bildschirm befindet. Sie werden abgebrochen, wenn der Nutzer diesen Bildschirm verlässt. Ein Beispiel ist die Anzeige von Daten aus der Datenbank.
UI-orientierte Vorgänge werden in der Regel von der UI-Ebene ausgelöst und folgen dem Lebenszyklus des Aufrufers, z. B. dem Lebenszyklus des ViewModel. Ein Beispiel für einen UI-orientierten Vorgang finden Sie im Abschnitt Netzwerkanfrage stellen.
App-orientierte Vorgänge
App-bezogene Vorgänge sind relevant, solange die App geöffnet ist. Wenn die App geschlossen oder der Prozess beendet wird, werden diese Vorgänge abgebrochen. Ein Beispiel ist das Zwischenspeichern des Ergebnisses einer Netzwerkanfrage, damit es bei Bedarf später verwendet werden kann. Weitere Informationen finden Sie im Abschnitt In-Memory-Datencaching implementieren.
Diese Vorgänge folgen in der Regel dem Lebenszyklus der Klasse Application oder der Datenschicht. Ein Beispiel finden Sie im Abschnitt Vorgang länger als auf dem Bildschirm anzeigen.
Geschäftsorientierte Abläufe
Geschäftsorientierte Vorgänge können nicht abgebrochen werden. Sie sollten das Beenden des Prozesses überstehen. Ein Beispiel ist das Abschließen des Uploads eines Fotos, das der Nutzer in seinem Profil posten möchte.
Für geschäftsorientierte Vorgänge empfehlen wir die Verwendung von WorkManager. Weitere Informationen finden Sie im Abschnitt Aufgaben mit WorkManager planen.
Fehler anzeigen
Interaktionen mit Repositories und Datenquellen können entweder erfolgreich sein oder eine Ausnahme auslösen, wenn ein Fehler auftritt. Für Coroutinen und Flows sollten Sie den integrierten Fehlerbehandlungsmechanismus von Kotlin verwenden. Verwenden Sie für Fehler, die durch Suspend-Funktionen ausgelöst werden könnten, gegebenenfalls try/catch-Blöcke und in Abläufen den Operator catch. Bei diesem Ansatz wird erwartet, dass die UI-Ebene Ausnahmen beim Aufrufen der Datenschicht verarbeitet.
Die Datenschicht kann verschiedene Arten von Fehlern erkennen und verarbeiten und sie mithilfe benutzerdefinierter Ausnahmen verfügbar machen, z. B. UserNotAuthenticatedException.
Weitere Informationen zu Fehlern in Coroutinen finden Sie im Blogpost Exceptions in coroutines.
Allgemeine Aufgaben
In den folgenden Abschnitten finden Sie Beispiele für die Verwendung und Architektur der Datenschicht für bestimmte Aufgaben, die in Android-Apps häufig vorkommen. Die Beispiele basieren auf der typischen Nachrichten-App, die weiter oben im Leitfaden erwähnt wurde.
Netzwerkanfrage stellen
Das Senden einer Netzwerkanfrage ist eine der häufigsten Aufgaben, die eine Android-App ausführen kann. In der News-App müssen dem Nutzer die neuesten Nachrichten angezeigt werden, die aus dem Netzwerk abgerufen werden. Daher benötigt die App eine Datenquellenklasse zum Verwalten von Netzwerkoperationen: NewsRemoteDataSource. Damit die Informationen für den Rest der App verfügbar sind, wird ein neues Repository erstellt, das Vorgänge für Nachrichtendaten verarbeitet: NewsRepository.
Die Anforderung besteht darin, dass die neuesten Nachrichten immer aktualisiert werden müssen, wenn der Nutzer den Bildschirm öffnet. Daher ist dies ein UI-orientierter Vorgang.
Datenquelle erstellen
Die Datenquelle muss eine Funktion bereitstellen, die die neuesten Nachrichten zurückgibt: eine Liste von ArticleHeadline-Instanzen. Die Datenquelle muss eine Möglichkeit bieten, die neuesten Nachrichten aus dem Netzwerk auf eine Weise zu erhalten, die nicht gegen die Richtlinien verstößt. Dazu muss eine Abhängigkeit von CoroutineDispatcher oder Executor bestehen, damit die Aufgabe ausgeführt werden kann.
Eine Netzwerkanfrage ist ein einmaliger Aufruf, der von einer neuen fetchLatestNews()-Methode verarbeitet wird:
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
Die NewsApi-Schnittstelle verbirgt die Implementierung des Netzwerk-API-Clients. Es spielt keine Rolle, ob die Schnittstelle von Retrofit oder HttpURLConnection unterstützt wird. Wenn Sie sich auf Schnittstellen verlassen, können API-Implementierungen in Ihrer App ausgetauscht werden.
Repository erstellen
Da für diese Aufgabe keine zusätzliche Logik in der Repository-Klasse erforderlich ist, fungiert NewsRepository als Proxy für die Netzwerkdatenquelle. Die Vorteile dieser zusätzlichen Abstraktionsebene werden im Abschnitt In-Memory-Caching erläutert.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Informationen dazu, wie Sie die Repository-Klasse direkt über den UI-Layer verwenden, finden Sie im Leitfaden UI-Layer.
In-Memory-Daten-Caching implementieren
Angenommen, es wird eine neue Anforderung für die Nachrichten-App eingeführt: Wenn der Nutzer den Bildschirm öffnet, müssen ihm zwischengespeicherte Nachrichten präsentiert werden, wenn zuvor eine Anfrage gestellt wurde. Andernfalls sollte die App eine Netzwerkanfrage senden, um die neuesten Nachrichten abzurufen.
Gemäß der neuen Anforderung muss die App die neuesten Nachrichten im Arbeitsspeicher behalten, solange der Nutzer die App geöffnet hat. Daher handelt es sich um einen app-orientierten Vorgang.
Caches
Sie können Daten beibehalten, während der Nutzer Ihre App verwendet, indem Sie In-Memory-Caching hinzufügen. Caches sind dazu gedacht, bestimmte Informationen für einen bestimmten Zeitraum im Arbeitsspeicher zu speichern – in diesem Fall so lange, wie der Nutzer die App verwendet. Cache-Implementierungen können unterschiedliche Formen annehmen. Sie können von einfachen veränderlichen Variablen bis hin zu komplexeren Klassen reichen, die vor Lese-/Schreibvorgängen in mehreren Threads schützen. Je nach Anwendungsfall kann das Caching im Repository oder in Datenquellenklassen implementiert werden.
Ergebnis der Netzwerkanfrage im Cache speichern
Der Einfachheit halber wird in NewsRepository eine veränderliche Variable verwendet, um die neuesten Nachrichten zu speichern. Um Lese- und Schreibvorgänge aus verschiedenen Threads zu schützen, wird ein Mutex verwendet. Weitere Informationen zu gemeinsam genutztem veränderlichem Status und Nebenläufigkeit finden Sie in der Kotlin-Dokumentation.
Bei der folgenden Implementierung werden die neuesten Nachrichteninformationen in einer Variablen im Repository zwischengespeichert, die mit einem Mutex schreibgeschützt ist. Wenn die Netzwerkanfrage erfolgreich ist, werden die Daten der Variablen latestNews zugewiesen.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Vorgang länger als auf dem Bildschirm angezeigt ausführen
Wenn der Nutzer den Bildschirm verlässt, während die Netzwerkanfrage läuft, wird sie abgebrochen und das Ergebnis wird nicht im Cache gespeichert. NewsRepository sollte die CoroutineScope des Anrufers nicht verwenden, um diese Logik auszuführen. Stattdessen sollte NewsRepository ein CoroutineScope verwenden, das an seinen Lebenszyklus gebunden ist.
Das Abrufen der neuesten Nachrichten muss ein apporientierter Vorgang sein.
Um die Best Practices für die Abhängigkeitsinjektion zu befolgen, sollte NewsRepository im Konstruktor einen Bereich als Parameter erhalten, anstatt einen eigenen CoroutineScope zu erstellen. Da die meisten Aufgaben in Repositories in Hintergrundthreads ausgeführt werden sollten, müssen Sie CoroutineScope entweder mit Dispatchers.Default oder mit Ihrem eigenen Thread-Pool konfigurieren.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Da NewsRepository bereit ist, app-orientierte Vorgänge mit dem externen CoroutineScope auszuführen, muss es den Aufruf an die Datenquelle ausführen und das Ergebnis in einer neuen, von diesem Bereich gestarteten Coroutine speichern:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async wird verwendet, um die Coroutine im externen Bereich zu starten. await wird für die neue Coroutine aufgerufen, um die Ausführung zu unterbrechen, bis die Netzwerkanfrage zurückkommt und das Ergebnis im Cache gespeichert wird. Wenn der Nutzer zu diesem Zeitpunkt noch auf dem Bildschirm ist, werden ihm die neuesten Nachrichten angezeigt. Wenn er sich vom Bildschirm entfernt, wird await abgebrochen, die Logik in async wird aber weiterhin ausgeführt.
Weitere Informationen zu Mustern für CoroutineScope
Daten auf der Festplatte speichern und abrufen
Angenommen, Sie möchten Daten wie Lesezeichen für Nachrichten und Nutzereinstellungen speichern. Diese Art von Daten muss auch nach dem Beenden des Prozesses verfügbar sein und auch dann zugänglich sein, wenn der Nutzer nicht mit dem Netzwerk verbunden ist.
Wenn die Daten, mit denen Sie arbeiten, die Prozessbeendigung überdauern müssen, müssen Sie sie auf eine der folgenden Arten auf der Festplatte speichern:
- Für große Datasets, die abgefragt werden müssen, Referenzintegrität erfordern oder teilweise aktualisiert werden müssen, speichern Sie die Daten in einer Room-Datenbank. Im Beispiel der News-App könnten die Nachrichtenartikel oder Autoren in der Datenbank gespeichert werden.
- Verwenden Sie für kleine Datasets, die nur abgerufen und festgelegt werden müssen (nicht abgefragt oder teilweise aktualisiert), DataStore. Im Beispiel der News-App könnten das bevorzugte Datumsformat des Nutzers oder andere Anzeigeeinstellungen in DataStore gespeichert werden.
- Verwenden Sie für Datenblöcke wie ein JSON-Objekt eine Datei.
Wie im Abschnitt Source of Truth beschrieben, funktioniert jede Datenquelle nur mit einer Quelle und entspricht einem bestimmten Datentyp (z. B. News, Authors, NewsAndAuthors oder UserPreferences). Klassen, die die Datenquelle verwenden, sollten nicht wissen, wie die Daten gespeichert werden, z. B. in einer Datenbank oder in einer Datei.
Raum als Datenquelle
Da jede Datenquelle nur für die Verarbeitung einer Quelle für einen bestimmten Datentyp zuständig sein sollte, würde eine Room-Datenquelle entweder ein Data Access Object (DAO) oder die Datenbank selbst als Parameter erhalten. Beispiel: NewsLocalDataSource kann eine Instanz von NewsDao als Parameter verwenden und AuthorsLocalDataSource eine Instanz von AuthorsDao.
In einigen Fällen, wenn keine zusätzliche Logik erforderlich ist, können Sie das DAO direkt in das Repository einfügen, da das DAO eine Schnittstelle ist, die Sie in Tests problemlos ersetzen können.
Weitere Informationen zur Verwendung der Room APIs finden Sie in den Room-Leitfäden.
DataStore als Datenquelle
DataStore eignet sich hervorragend zum Speichern von Schlüssel/Wert-Paaren wie Nutzereinstellungen. Beispiele hierfür sind das Zeitformat, Benachrichtigungseinstellungen und die Frage, ob Nachrichtenartikel nach dem Lesen ein- oder ausgeblendet werden sollen. DataStore kann auch typisierte Objekte mit Protobufs speichern.
Wie bei jedem anderen Objekt sollte eine von DataStore unterstützte Datenquelle Daten enthalten, die einem bestimmten Typ oder einem bestimmten Teil der App entsprechen. Das gilt umso mehr für DataStore, da DataStore-Lesevorgänge als Flow bereitgestellt werden, der jedes Mal ausgegeben wird, wenn ein Wert aktualisiert wird. Aus diesem Grund sollten Sie zusammengehörige Einstellungen im selben DataStore speichern.
Sie könnten beispielsweise ein NotificationsDataStore haben, das nur benachrichtigungsbezogene Einstellungen verarbeitet, und ein NewsPreferencesDataStore, das nur Einstellungen für den News-Bildschirm verarbeitet. So können Sie die Updates besser eingrenzen, da der newsScreenPreferencesDataStore.data-Flow nur ausgegeben wird, wenn sich eine Einstellung ändert, die sich auf diesen Bildschirm bezieht. Das bedeutet auch, dass der Lebenszyklus des Objekts kürzer sein kann, da es nur so lange aktiv sein kann, wie der Nachrichtenbildschirm angezeigt wird.
Weitere Informationen zur Verwendung der DataStore APIs finden Sie in den DataStore-Leitfäden.
Datei als Datenquelle
Wenn Sie mit großen Objekten wie einem JSON-Objekt oder einer Bitmap arbeiten, müssen Sie ein File-Objekt verwenden und den Wechsel von Threads verarbeiten.
Weitere Informationen zum Arbeiten mit Dateispeicher finden Sie auf der Seite Speicher – Übersicht.
Aufgaben mit WorkManager planen
Angenommen, es wird eine weitere neue Anforderung für die News-App eingeführt: Die App muss dem Nutzer die Möglichkeit bieten, die neuesten Nachrichten regelmäßig und automatisch abzurufen, solange das Gerät aufgeladen und mit einem Netzwerk ohne Datenlimit verbunden ist. Daher ist dies ein geschäftsorientierter Vorgang. So können Nutzer auch dann aktuelle Nachrichten sehen, wenn das Gerät keine Verbindung hat, wenn sie die App öffnen.
Mit WorkManager lassen sich asynchrone und zuverlässige Aufgaben einfach planen und Einschränkungen verwalten. Sie ist die empfohlene Bibliothek für persistente Aufgaben. Für die oben definierte Aufgabe wird die Klasse Worker erstellt: RefreshLatestNewsWorker. Diese Klasse verwendet NewsRepository als Abhängigkeit, um die neuesten Nachrichten abzurufen und auf der Festplatte zu speichern.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
Die Geschäftslogik für diese Art von Aufgabe sollte in einer eigenen Klasse gekapselt und als separate Datenquelle behandelt werden. WorkManager ist dann nur dafür verantwortlich, dass die Arbeit in einem Hintergrundthread ausgeführt wird, wenn alle Einschränkungen erfüllt sind. Wenn Sie sich an dieses Muster halten, können Sie Implementierungen in verschiedenen Umgebungen bei Bedarf schnell austauschen.
In diesem Beispiel muss der nachrichtenspezifische Task von NewsRepository aufgerufen werden. Dazu ist eine neue Datenquelle als Abhängigkeit erforderlich, NewsTasksDataSource, die so implementiert wird:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Diese Arten von Klassen sind nach den Daten benannt, für die sie verantwortlich sind, z. B. NewsTasksDataSource oder PaymentsTasksDataSource. Alle Aufgaben, die sich auf einen bestimmten Datentyp beziehen, sollten in derselben Klasse gekapselt werden.
Wenn die Aufgabe beim Start der App ausgelöst werden muss, empfiehlt es sich, die WorkManager-Anfrage mit der App Startup-Bibliothek auszulösen, die das Repository über ein Initializer aufruft.
Weitere Informationen zur Verwendung der WorkManager-APIs finden Sie in den WorkManager-Leitfäden.
Test
Best Practices für die Abhängigkeitsinjektion sind beim Testen Ihrer App hilfreich. Außerdem ist es sinnvoll, sich auf Schnittstellen für Klassen zu verlassen, die mit externen Ressourcen kommunizieren. Wenn Sie eine Einheit testen, können Sie gefälschte Versionen ihrer Abhängigkeiten einschleusen, um den Test deterministisch und zuverlässig zu machen.
Einheitentests
Beim Testen der Datenschicht gelten die allgemeinen Testrichtlinien. Verwenden Sie für Unit-Tests bei Bedarf echte Objekte und simulieren Sie alle Abhängigkeiten, die auf externe Quellen zugreifen, z. B. das Lesen aus einer Datei oder aus dem Netzwerk.
Integrationstests
Integrationstests, die auf externe Quellen zugreifen, sind in der Regel weniger deterministisch, da sie auf einem echten Gerät ausgeführt werden müssen. Wir empfehlen, diese Tests in einer kontrollierten Umgebung auszuführen, um die Integrationstests zuverlässiger zu machen.
Für Datenbanken ermöglicht Room das Erstellen einer In-Memory-Datenbank, die Sie in Ihren Tests vollständig steuern können. Weitere Informationen finden Sie auf der Seite Datenbank testen und debuggen.
Für die Vernetzung gibt es beliebte Bibliotheken wie WireMock oder MockWebServer, mit denen Sie HTTP- und HTTPS-Aufrufe faken und überprüfen können, ob die Anfragen wie erwartet gesendet wurden.
Zusätzliche Ressourcen
Beispiele
- Jetcaster
- Architektur-Startvorlage (Multi-Modul)
- Architektur
- Architektur-Startvorlage (einzelnes Modul)
- Now in Android App
Empfehlungen für Sie
- Hinweis: Linktext wird angezeigt, wenn JavaScript deaktiviert ist.
- Domänenebene
- Offline-First-App erstellen
- Zustandsproduktion in der Benutzeroberfläche