
Eine Offline-First-App ist eine App, die alle oder einen wichtigen Teil ihrer Hauptfunktionen ohne Internetzugang ausführen kann. Das bedeutet, dass ein Teil oder die gesamte Geschäftslogik offline ausgeführt werden kann.
Überlegungen zum Erstellen einer Offline-First-App beginnen in der Datenebene, die Zugriff auf Anwendungsdaten und Geschäftslogik bietet. Gelegentlich muss die App diese Daten aus Quellen außerhalb des Geräts aktualisieren. Dazu muss es möglicherweise auf Netzwerkressourcen zugreifen, um auf dem neuesten Stand zu bleiben.
Die Netzwerkverfügbarkeit kann nicht immer garantiert werden. Geräte haben häufig Phasen mit einer instabilen oder langsamen Netzwerkverbindung. Folgendes kann auftreten:
- Begrenzte Internetbandbreite
- Vorübergehende Verbindungsunterbrechungen, z. B. in einem Aufzug oder Tunnel
- Gelegentlicher Datenzugriff, z. B. bei reinen WLAN-Tablets
Unabhängig vom Grund kann eine App unter diesen Umständen oft ausreichend funktionieren. Damit Ihre App offline richtig funktioniert, muss sie Folgendes können:
- Auch ohne zuverlässige Netzwerkverbindung nutzbar bleiben
- Nutzern sofort lokale Daten präsentieren, anstatt auf den Abschluss oder Fehler des ersten Netzwerkaufrufs zu warten
- Daten so abrufen, dass der Akku- und Datenstatus berücksichtigt wird, z. B. indem Datenabrufe nur unter optimalen Bedingungen angefordert werden, z. B. beim Aufladen oder bei einer WLAN-Verbindung
Eine App, die diese Kriterien erfüllt, wird oft als „Offline-First-App“ bezeichnet.
Offline-First-App entwerfen
Beginnen Sie beim Design einer Offline-First-App mit der Datenebene und den beiden Hauptvorgängen, die Sie für App-Daten ausführen können:
- Lesen: Daten werden abgerufen, um von anderen Teilen der App verwendet zu werden, z. B. um Informationen für den Nutzer anzuzeigen. In Compose wird dies in der Regel durch Beobachten des Status erreicht. Wenn die Benutzeroberfläche die lokale Datenquelle als Status beobachtet, werden auf dem Bildschirm automatisch die neuesten lokalen Daten angezeigt.
- Schreiben: Nutzereingaben werden für den späteren Abruf gespeichert. In Compose wird dies in der Regel durch Ereignisse und Aktionen erreicht, die von der Benutzeroberfläche an das ViewModel gesendet werden.
Repositories in der Datenschicht sind dafür verantwortlich, Datenquellen zu kombinieren, um App-Daten bereitzustellen. In einer Offline-First-App muss es mindestens eine Datenquelle geben, für deren wichtigste Aufgaben kein Netzwerkzugriff erforderlich ist. Eine dieser wichtigen Aufgaben ist das Lesen von Daten.
Daten in einer Offline-First-App modellieren
Eine Offline-First-App hat für jedes Repository, das Netzwerkressourcen nutzt, mindestens zwei Datenquellen:
- Die lokale Datenquelle
- Die Netzwerkdatenquelle
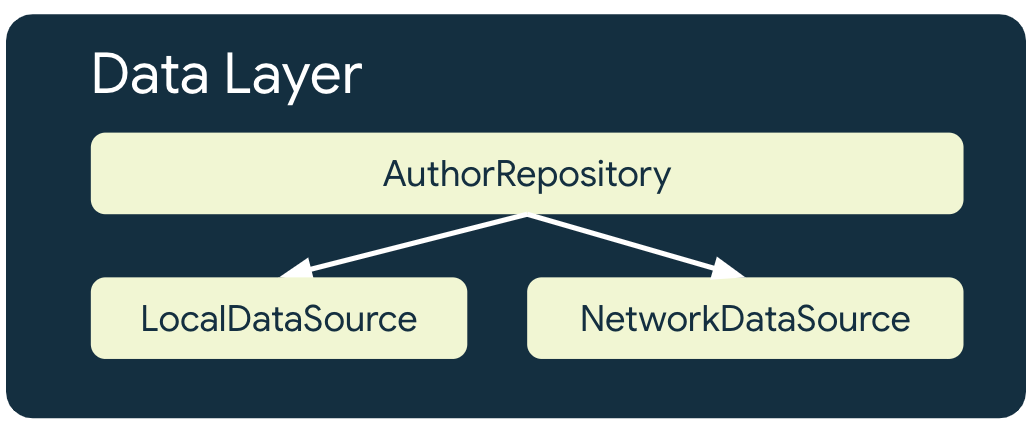
Die lokale Datenquelle
Die lokale Datenquelle ist die kanonische Source of Truth für die App. Sie sollte die einzige Quelle für alle Daten sein, die von höheren Ebenen der App gelesen werden. So wird die Datenkonsistenz zwischen den Verbindungsstatus sichergestellt. Die lokale Datenquelle wird häufig durch Speicher unterstützt, der auf der Festplatte gespeichert wird. Einige gängige Methoden zum Speichern von Daten auf dem Laufwerk sind:
- Strukturierte Datenquellen wie relationale Datenbanken wie Room
- Unstrukturierte Datenquellen, z. B. Protokollzwischenspeicher mit DataStore
- Einfache Dateien
Die Netzwerkdatenquelle
Die Netzwerkdatenquelle ist der tatsächliche Status der Anwendung. Im besten Fall wird die lokale Datenquelle mit der Netzwerkdatenquelle synchronisiert. Die lokale Datenquelle kann auch hinter der Netzwerkdatenquelle zurückbleiben. In diesem Fall muss die App aktualisiert werden, wenn sie wieder online ist. Umgekehrt kann die Netzwerkdatenquelle hinter der lokalen Datenquelle zurückbleiben, bis die App sie aktualisieren kann, wenn die Verbindung wiederhergestellt wird. Die Domain- und UI-Ebenen der App dürfen niemals direkt mit der Netzwerkebene kommunizieren. Der Hosting-repository ist für die Kommunikation mit dem repository und die Aktualisierung der lokalen Datenquelle verantwortlich.
Ressourcen verfügbar machen
Die lokalen und Netzwerkdatenquellen können sich grundlegend darin unterscheiden, wie Ihre App Daten daraus lesen und darin schreiben kann. Das Abfragen einer lokalen Datenquelle kann schnell und flexibel erfolgen, z. B. mit SQL-Abfragen. Netzwerkdatenquellen können dagegen langsam und eingeschränkt sein, z. B. wenn Sie inkrementell per ID auf RESTful-Ressourcen zugreifen. Daher benötigt jede Datenquelle oft eine eigene Darstellung der bereitgestellten Daten. Die lokale Datenquelle und die Netzwerkdatenquelle haben daher möglicherweise eigene Modelle.
Die folgende Verzeichnisstruktur veranschaulicht dieses Konzept. AuthorEntity steht für einen Autor, der aus der lokalen Datenbank der App gelesen wurde, und NetworkAuthor für einen Autor, der über das Netzwerk serialisiert wurde:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Im Folgenden finden Sie die Details zu AuthorEntity und NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Es empfiehlt sich, sowohl AuthorEntity als auch NetworkAuthor in der Datenschicht zu belassen und einen dritten Typ für externe Ebenen bereitzustellen. So werden externe Ebenen vor geringfügigen Änderungen in den lokalen und Netzwerkdatenquellen geschützt, die das Verhalten der App nicht grundlegend ändern. Das wird im folgenden Snippet veranschaulicht:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Das Netzwerkmodell kann dann eine Erweiterungsmethode definieren, um es in das lokale Modell zu konvertieren. Das lokale Modell hat eine ähnliche Methode, um es in die externe Darstellung zu konvertieren, wie im folgenden Snippet gezeigt:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Lesevorgänge
Lesevorgänge sind der grundlegende Vorgang für App-Daten in einer Offline-First-App. Sie müssen daher dafür sorgen, dass Ihre App die Daten lesen kann und dass sie neue Daten anzeigen kann, sobald sie verfügbar sind. Eine App, die das kann, ist eine reaktive App, da sie Lese-APIs mit beobachtbaren Typen bereitstellt.
Im folgenden Snippet gibt OfflineFirstTopicRepository Flow für alle Lese-APIs zurück. So kann es seine Leser benachrichtigen, wenn es Aktualisierungen von der Netzwerkdatenquelle erhält. Mit anderen Worten: Das OfflineFirstTopicRepository kann Änderungen übertragen, wenn seine lokale Datenquelle ungültig wird. Daher muss jeder Leser der OfflineFirstTopicRepository auf Datenänderungen vorbereitet sein, die ausgelöst werden können, wenn die Netzwerkverbindung zur App wiederhergestellt wird. Außerdem liest OfflineFirstTopicRepository Daten direkt aus der lokalen Datenquelle. Die Leser können nur über Datenänderungen informiert werden, wenn die lokale Datenquelle zuerst aktualisiert wird.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
In einer Jetpack Compose-App verwenden Sie ein ViewModel, um die Datenschicht und die Benutzeroberfläche zu verbinden.
Konvertieren Sie im ViewModel Flow mithilfe des Operators stateIn in StateFlow. Composables erfassen diese Status dann mit collectAsStateWithLifecycle() und verwalten Abos automatisch auf lebenszyklusbewusste Weise.
Weitere Informationen zu collectAsStateWithLifecycle() finden Sie unter Zustand und Jetpack Compose.
Strategien zur Fehlerbehandlung
Je nach Datenquelle, in der Fehler auftreten können, gibt es unterschiedliche Möglichkeiten, mit ihnen in Offline-First-Apps umzugehen. In den folgenden Unterabschnitten werden diese Strategien beschrieben.
Lokale Datenquelle
Versuchen Sie, Fehler beim Lesen aus der lokalen Datenquelle zu minimieren. Um Leser vor Fehlern zu schützen, verwenden Sie den Operator catch für die Flow, aus denen der Leser Daten erfasst.
Sie können den Operator catch in einem ViewModel so verwenden:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Für einen robusteren Ansatz sollten Sie eine LCE-Lösung (Loading Content Error) in Betracht ziehen. In LCE wird bei einem Lesefehler ein Fehlerstatus angezeigt. Normalerweise erreichen Sie LCE, indem Sie die UI-Zustände als versiegelte Kotlin-Klassen modellieren.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Netzwerkdatenquelle
Wenn beim Lesen von Daten aus einer Netzwerkdatenquelle Fehler auftreten, muss die App eine Heuristik verwenden, um das Abrufen von Daten zu wiederholen. Häufige Heuristiken sind:
Exponentielle Backoffs
Beim exponentiellen Backoff versucht die App wiederholt, Daten aus der Netzwerkdatenquelle zu lesen, wobei die Zeitintervalle immer länger werden, bis der Vorgang erfolgreich ist oder andere Bedingungen das Beenden des Vorgangs erzwingen.
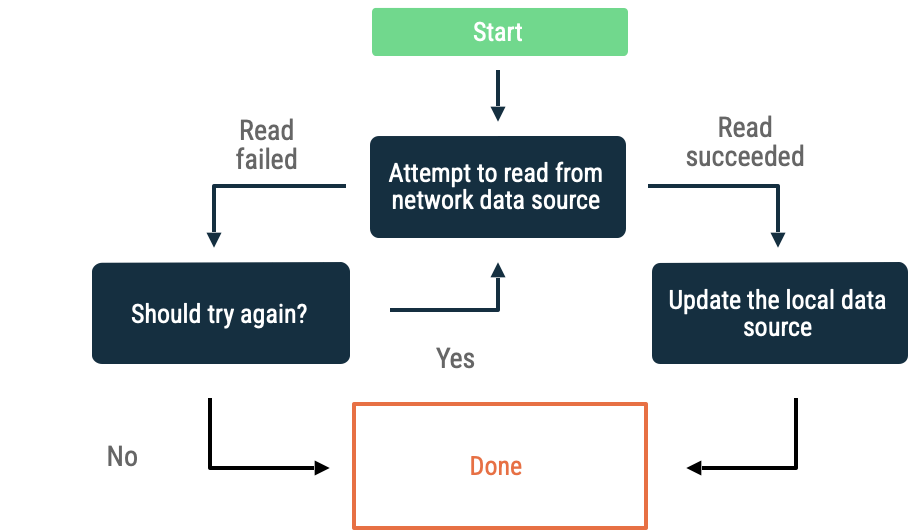
Kriterien zur Bewertung, ob die App weiterhin Backoff-Versuche unternimmt:
- Die Art des Fehlers, der in der Netzwerkdatenquelle angegeben wurde. Wiederholen Sie beispielsweise Netzwerkaufrufe, die einen Fehler zurückgeben, der auf eine fehlende Verbindung hinweist. Wiederholen Sie HTTP-Anfragen, die nicht autorisiert sind, erst, wenn die richtigen Anmeldedaten verfügbar sind.
- Maximal zulässige Anzahl von Wiederholungsversuchen.
Überwachung der Netzwerkverbindung
Bei diesem Ansatz werden Leseanfragen in die Warteschlange gestellt, bis die App sicher ist, dass sie eine Verbindung zur Netzwerkdatenquelle herstellen kann. Sobald eine Verbindung hergestellt wurde, wird die Leseanfrage aus der Warteschlange entfernt, die Daten werden gelesen und die lokale Datenquelle wird aktualisiert. Unter Android wird diese Warteschlange möglicherweise mit einer Room-Datenbank verwaltet und als persistente Aufgabe mit WorkManager geleert.
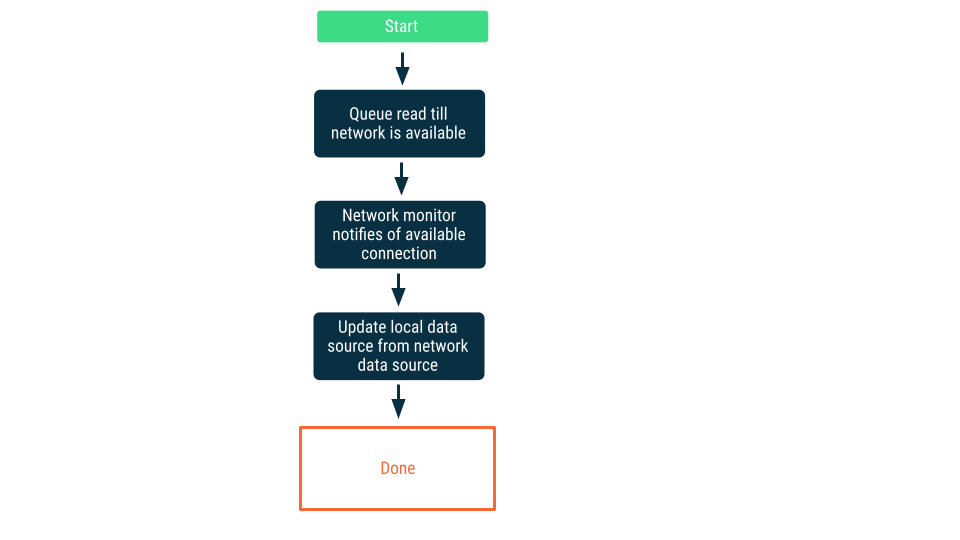
Schreibvorgänge
Die empfohlene Methode zum Lesen von Daten in einer Offline-First-App ist die Verwendung von beobachtbaren Typen. Das Äquivalent für Schreib-APIs sind asynchrone APIs wie z. B. Suspend-Funktionen. So wird der UI-Thread nicht blockiert und die Fehlerbehandlung wird vereinfacht, da Schreibvorgänge in Offline-First-Apps fehlschlagen können, wenn eine Netzwerkbegrenzung überschritten wird.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
Im vorherigen Snippet ist die asynchrone API der Wahl Coroutines, da die Methode angehalten wird.
Schreibstrategien
Beim Schreiben von Daten in Offline-First-Apps gibt es drei Strategien, die infrage kommen. Welche Option Sie auswählen, hängt vom Typ der geschriebenen Daten und den Anforderungen der App ab:
Nur Online-Schreibvorgänge
Versuchen Sie, die Daten über die Netzwerkgrenze hinweg zu schreiben. Bei Erfolg wird die lokale Datenquelle aktualisiert. Andernfalls wird eine Ausnahme ausgelöst und es liegt am Aufrufer, angemessen zu reagieren.
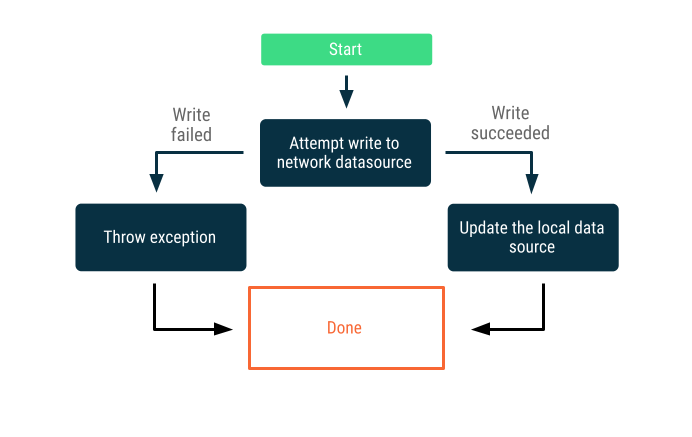
Diese Strategie wird häufig für Schreibtransaktionen verwendet, die online in nahezu Echtzeit erfolgen müssen, z. B. eine Banküberweisung. Da Schreibvorgänge fehlschlagen können, ist es oft notwendig, dem Nutzer mitzuteilen, dass der Schreibvorgang fehlgeschlagen ist, oder den Nutzer daran zu hindern, überhaupt Daten zu schreiben. Hier sind einige Strategien, die Sie in diesen Szenarien anwenden können:
- Wenn eine App Internetzugriff zum Schreiben von Daten benötigt, können Sie dem Nutzer keine Benutzeroberfläche zum Schreiben von Daten präsentieren oder sie zumindest deaktivieren.
- Sie können eine
AlertDialogverwenden, die der Nutzer nicht schließen kann, oder eineSnackbar, um den Nutzer darüber zu informieren, dass er offline ist.
Schreibvorgänge in der Warteschlange
Wenn Sie ein Objekt haben, das Sie schreiben möchten, fügen Sie es in eine Warteschlange ein. Wenn die App wieder online ist, leeren Sie die Warteschlange mit exponentiellem Backoff. Unter Android ist das Leeren einer Offline-Warteschlange eine persistente Aufgabe, die häufig an WorkManager delegiert wird.
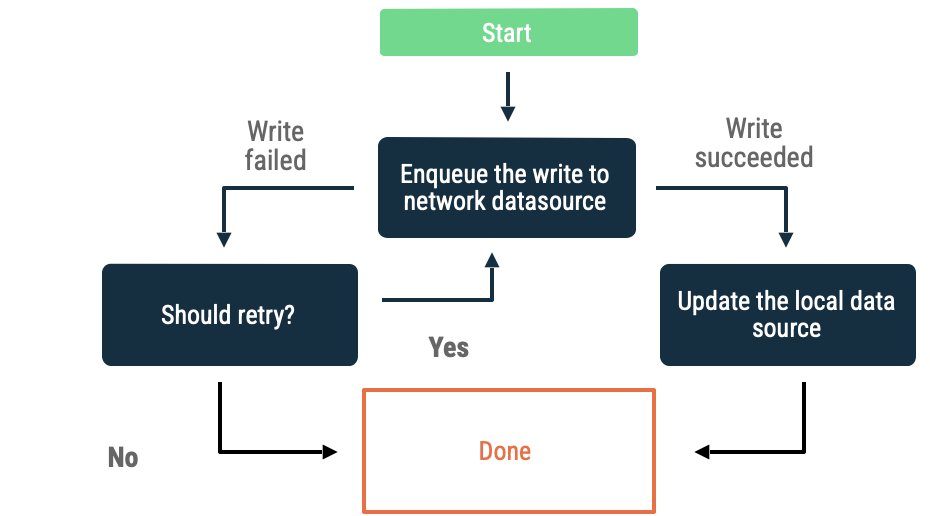
Dieser Ansatz ist in den folgenden Szenarien eine gute Wahl:
- Es ist nicht unbedingt erforderlich, dass die Daten jemals in das Netzwerk geschrieben werden.
- Die Transaktion ist nicht zeitkritisch.
- Es ist nicht unbedingt erforderlich, dass der Nutzer über das Scheitern des Vorgangs informiert wird.
Anwendungsfälle für diesen Ansatz sind unter anderem Analyseereignisse und Logging.
Verzögerte Schreibvorgänge
Schreiben Sie zuerst in die lokale Datenquelle und stellen Sie den Schreibvorgang dann in die Warteschlange, um das Netzwerk so schnell wie möglich zu benachrichtigen. Das ist nicht trivial, da es zu Konflikten zwischen den Netzwerk- und lokalen Datenquellen kommen kann, wenn die App wieder online ist. Weitere Informationen finden Sie im nächsten Abschnitt zur Konfliktlösung.
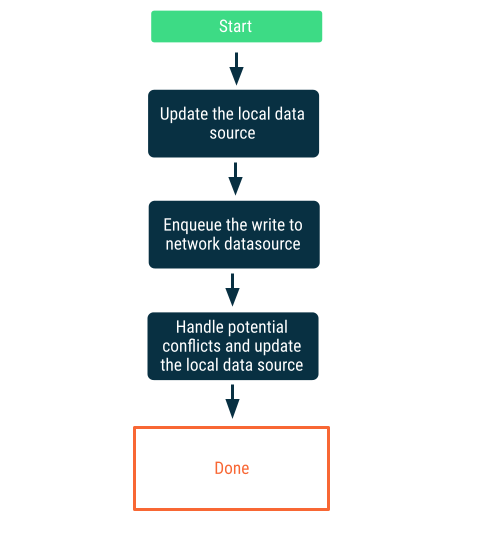
Dieser Ansatz ist die richtige Wahl, wenn die Daten für die App von entscheidender Bedeutung sind. In einer Offline-First-App für To-do-Listen ist es beispielsweise wichtig, dass alle Aufgaben, die der Nutzer offline hinzufügt, lokal gespeichert werden, um das Risiko von Datenverlust zu vermeiden.
Synchronisierung und Konfliktlösung
Wenn eine Offline-First-App die Verbindung wiederherstellt, müssen die Daten in der lokalen Datenquelle mit denen in der Netzwerkdatenquelle abgeglichen werden. Dieser Vorgang wird als Synchronisierung bezeichnet. Es gibt zwei Hauptmethoden, mit denen eine App mit ihrer Netzwerkdatenquelle synchronisiert werden kann:
- Pull-basierte Synchronisierung
- Push-basierte Synchronisierung
Pull-basierte Synchronisierung
Bei der Pull-basierten Synchronisierung stellt die App eine Verbindung zum Netzwerk her, um die neuesten Anwendungsdaten bei Bedarf zu lesen. Eine gängige Heuristik für diesen Ansatz ist die Navigation. Die App ruft Daten erst ab, kurz bevor sie dem Nutzer präsentiert werden.
Dieser Ansatz eignet sich am besten, wenn die App mit kurzen bis mittellangen Zeiträumen ohne Netzwerkverbindung rechnet. Das liegt daran, dass die Datenaktualisierung opportunistisch erfolgt. Bei längeren Zeiträumen ohne Verbindung steigt die Wahrscheinlichkeit, dass der Nutzer versucht, App-Ziele mit einem Cache zu besuchen, der entweder veraltet oder leer ist.
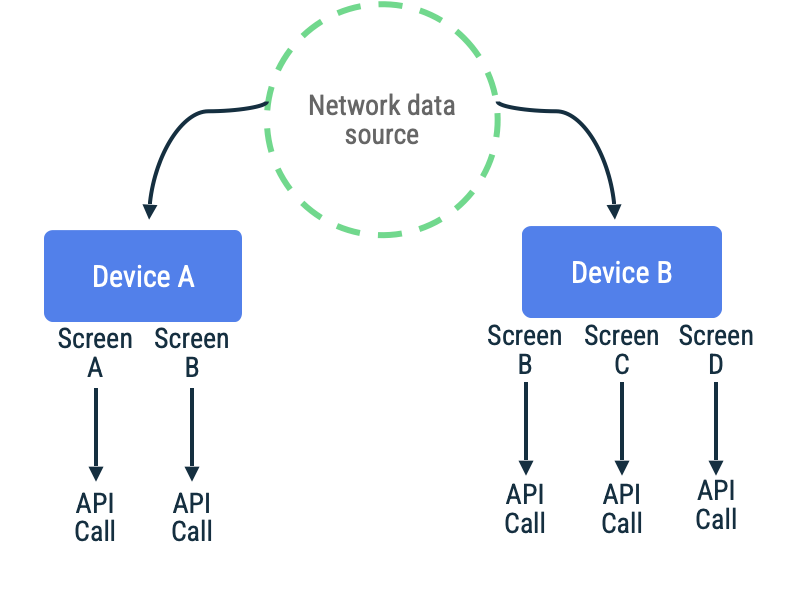
Stellen Sie sich eine App vor, in der Seitentokens verwendet werden, um Elemente in einer endlosen Scrollliste für einen bestimmten Bildschirm abzurufen. Die Implementierung kann das Netzwerk verzögert kontaktieren, die Daten in der lokalen Datenquelle speichern und dann aus der lokalen Datenquelle lesen, um dem Nutzer Informationen zu präsentieren. Wenn keine Netzwerkverbindung besteht, fordert das Repository möglicherweise nur Daten von der lokalen Datenquelle an. Dieses Muster wird von der Jetpack Paging Library mit der API RemoteMediator verwendet.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Die Vor- und Nachteile der pullbasierten Synchronisierung sind in der folgenden Tabelle zusammengefasst:
| Vorteile | Nachteile |
|---|---|
| Relativ einfach zu implementieren. | Hohe Datennutzung Das liegt daran, dass bei wiederholten Besuchen eines Navigationsziels unnötigerweise unveränderte Informationen abgerufen werden. Sie können dieses Problem durch geeignetes Caching beheben. Dies kann in der UI-Ebene mit dem Operator cachedIn oder in der Netzwerkebene mit einem HTTP-Cache erfolgen. |
| Nicht benötigte Daten werden nie abgerufen. | Lässt sich nicht gut mit relationalen Daten skalieren, da das abgerufene Modell in sich geschlossen sein muss. Wenn das zu synchronisierende Modell von anderen Modellen abhängt, die abgerufen werden müssen, um es zu füllen, wird das oben erwähnte Problem mit der hohen Datennutzung noch wichtiger. Außerdem können dadurch Abhängigkeiten zwischen den Repositories des übergeordneten Modells und den Repositories des verschachtelten Modells entstehen. |
Push-basierte Synchronisierung
Bei der Push-basierten Synchronisierung versucht die lokale Datenquelle, einen Replikatsatz der Netzwerkdatenquelle so gut wie möglich nachzubilden. Beim ersten Start wird proaktiv eine angemessene Menge an Daten abgerufen, um eine Baseline festzulegen. Danach verlässt es sich auf Benachrichtigungen vom Server, um es zu informieren, wenn diese Daten veraltet sind.
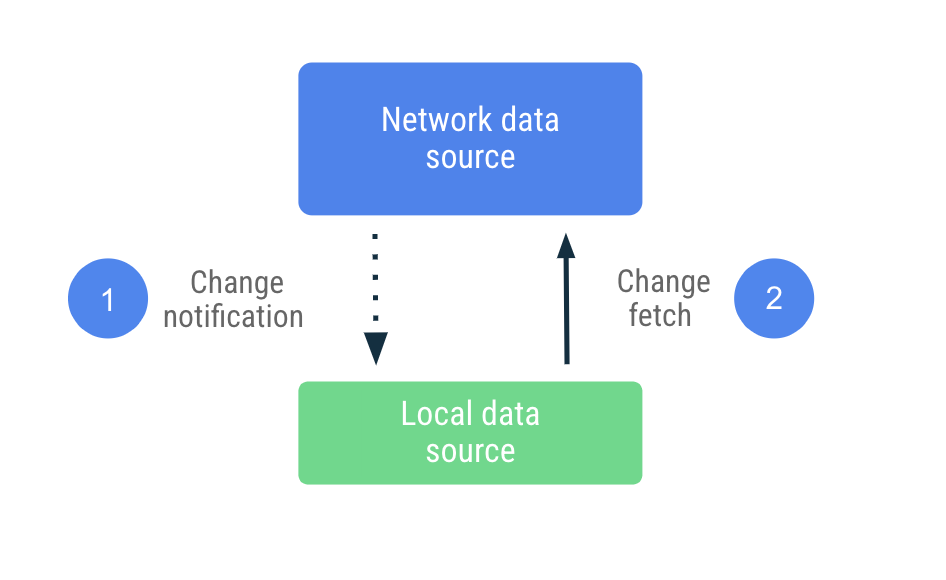
Nach Erhalt der Benachrichtigung über veraltete Daten stellt die App eine Verbindung zum Netzwerk her, um nur die Daten zu aktualisieren, die als veraltet markiert wurden. Diese Aufgabe wird an die Repository delegiert, die die Netzwerkdatenquelle kontaktiert und die abgerufenen Daten in der lokalen Datenquelle speichert. Da das Repository seine Daten mit beobachtbaren Typen bereitstellt, werden Leser über alle Änderungen benachrichtigt.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Bei diesem Ansatz ist die App viel weniger von der Netzwerkdatenquelle abhängig und kann über längere Zeit ohne sie funktionieren. Sie bietet sowohl Lese- als auch Schreibzugriff, wenn sie offline ist, da sie davon ausgeht, dass sie die neuesten Informationen aus der Netzwerkdatenquelle lokal hat.
Die Vor- und Nachteile der Push-basierten Synchronisierung sind in der folgenden Tabelle zusammengefasst:
| Vorteile | Nachteile |
|---|---|
| Die App kann auf unbestimmte Zeit offline bleiben. | Die Versionsverwaltung von Daten zur Konfliktlösung ist nicht trivial. |
| Geringe Datennutzung. Die App ruft nur Daten ab, die sich geändert haben. | Sie müssen bei der Synchronisierung Schreibanforderungen berücksichtigen. |
| Gut geeignet für relationale Daten. Jedes Repository ist dafür verantwortlich, Daten nur für das Modell abzurufen, das es unterstützt. | Die Netzwerkdatenquelle muss die Synchronisierung unterstützen. |
Hybridsynchronisierung
Einige Apps verwenden einen hybriden Ansatz, der je nach Daten Pull- oder Push-basiert ist. Eine Social-Media-App kann beispielsweise die Pull-basierte Synchronisierung verwenden, um den Feed der Nutzer auf Anfrage abzurufen, da der Feed sehr häufig aktualisiert wird. Dieselbe App kann sich dafür entscheiden, die Push-basierte Synchronisierung für Daten über den angemeldeten Nutzer zu verwenden, einschließlich seines Nutzernamens, Profilbilds usw.
Letztendlich hängt die Entscheidung für die Offline-First-Synchronisierung von den Produktanforderungen und der verfügbaren technischen Infrastruktur ab.
Konfliktlösung
Wenn die App im Offlinemodus Daten lokal schreibt, die nicht mit der Netzwerkdatenquelle übereinstimmen, müssen Sie den Konflikt beheben, bevor die Synchronisierung erfolgen kann.
Für die Konfliktlösung ist häufig die Versionsverwaltung erforderlich. Die App muss einige Verwaltungsaufgaben ausführen, um nachzuverfolgen, wann Änderungen aufgetreten sind, damit sie die Metadaten an die Netzwerkdatenquelle übergeben kann. Die Netzwerkdatenquelle ist dann für die Bereitstellung der absoluten Source of Truth verantwortlich. Je nach den Anforderungen der Anwendung gibt es viele Strategien zur Konfliktlösung. Bei mobilen Apps ist der Ansatz „last write wins“ (letzter Schreibvorgang gewinnt) üblich.
Last Write Wins
Bei diesem Ansatz fügen Geräte den Daten, die sie ins Netzwerk schreiben, Zeitstempel-Metadaten hinzu. Wenn die Netzwerkdatenquelle sie empfängt, werden alle Daten verworfen, die älter als der aktuelle Status sind. Daten, die neuer als der aktuelle Status sind, werden akzeptiert.
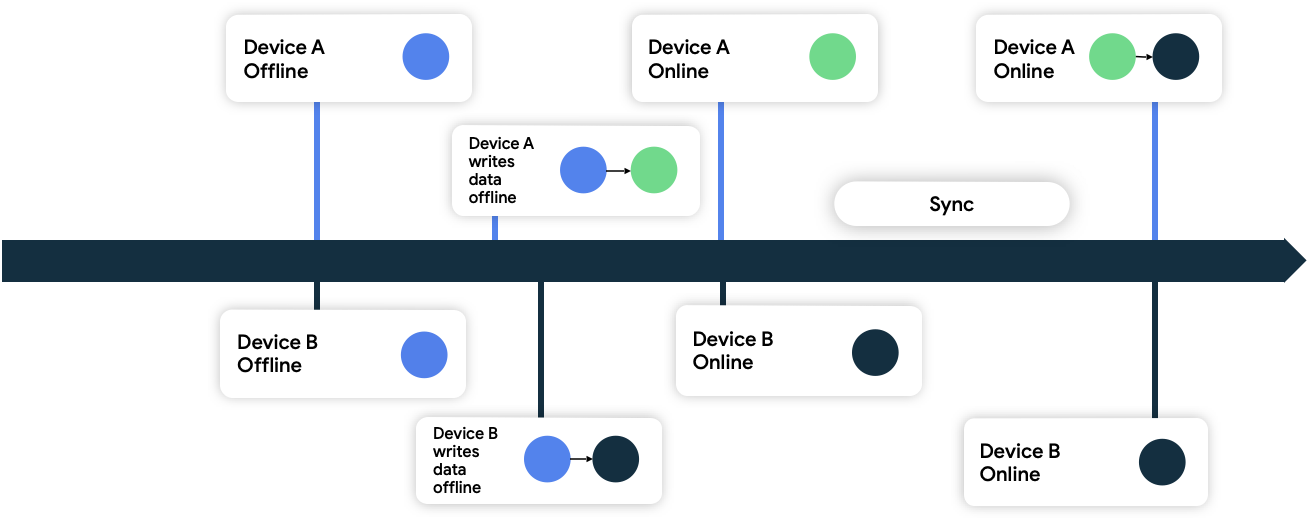
In Abbildung 9 sind beide Geräte offline und anfangs mit der Netzwerkdatenquelle synchronisiert. Im Offlinemodus schreiben beide Daten lokal und erfassen, wann sie ihre Daten geschrieben haben. Wenn beide wieder online sind und mit der Netzwerkdatenquelle synchronisiert werden, löst das Netzwerk den Konflikt, indem es die Daten von Gerät B beibehält, da diese später geschrieben wurden.
WorkManager in Offline-First-Apps
Sowohl bei den zuvor behandelten Lese- als auch bei den Schreibstrategien gibt es zwei gängige Dienstprogramme:
- Warteschlangen
- Lesevorgänge: Werden verwendet, um Lesevorgänge aufzuschieben, bis eine Netzwerkverbindung verfügbar ist.
- Schreibvorgänge: Werden verwendet, um Schreibvorgänge aufzuschieben, bis eine Netzwerkverbindung verfügbar ist, und um Schreibvorgänge für Wiederholungsversuche neu in die Warteschlange zu stellen.
- Monitore für Netzwerkverbindungen
- Lesen: Wird als Signal zum Leeren der Lesewarteschlange verwendet, wenn die App verbunden ist, und zur Synchronisierung.
- Schreibvorgänge: Wird als Signal zum Leeren der Schreibwarteschlange verwendet, wenn die App verbunden ist, und für die Synchronisierung.
Beide Fälle sind Beispiele für die dauerhafte Arbeit, für die WorkManager hervorragend geeignet ist. In der Beispiel-App Now in Android wird WorkManager beispielsweise sowohl als Lese-Warteschlange als auch als Netzwerkmonitor verwendet, wenn die lokale Datenquelle synchronisiert wird. Beim Start führt die App Folgendes aus:
- Stellt die Arbeit zur Lesesynchronisierung in die Warteschlange, um sicherzustellen, dass die lokale Datenquelle und die Netzwerkdatenquelle übereinstimmen.
- Leert die Lesesynchronisierungswarteschlange und beginnt mit der Synchronisierung, wenn die App online ist.
- Führt einen Lesevorgang aus der Netzwerkdatenquelle mit exponentiellem Backoff aus.
- Die Ergebnisse des Lesevorgangs werden in der lokalen Datenquelle gespeichert und alle auftretenden Konflikte werden behoben.
- Macht die Daten aus der lokalen Datenquelle für andere Ebenen der App verfügbar.
Diese Aktionen werden im folgenden Diagramm veranschaulicht:
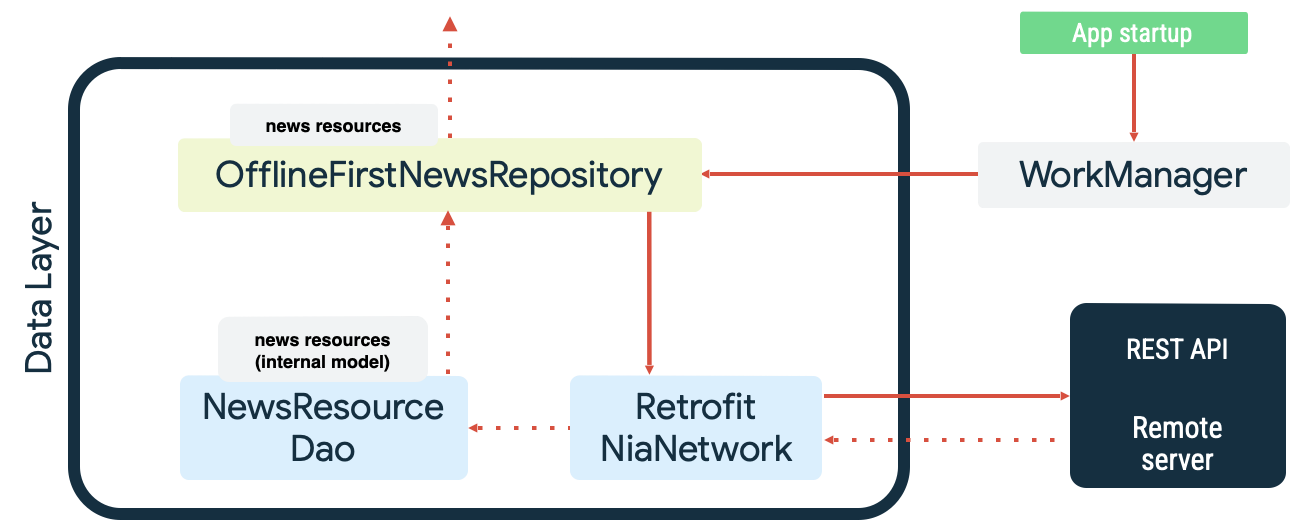
Die Synchronisierungsaufgabe wird mit WorkManager in die Warteschlange gestellt, indem sie mit dem KEEP ExistingWorkPolicy als eindeutige Aufgabe angegeben wird:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() ist so definiert:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Insbesondere erfordert die von SyncConstraints definierte Constraints, dass die NetworkType NetworkType.CONNECTED ist. Das bedeutet, dass es wartet, bis das Netzwerk verfügbar ist, bevor es ausgeführt wird.
Sobald das Netzwerk verfügbar ist, leert der Worker die eindeutige Arbeitswarteschlange, die durch SyncWorkName angegeben wird, indem er die Aufgaben an die entsprechenden Repository-Instanzen delegiert. Wenn die Synchronisierung fehlschlägt, gibt die Methode doWork() Result.retry() zurück. WorkManager wiederholt die Synchronisierung automatisch mit exponentiellem Backoff. Andernfalls wird Result.success() zurückgegeben und die Synchronisierung wird abgeschlossen.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Beispiele
Die folgenden Google-Beispiele veranschaulichen Offline-First-Apps. Sehen Sie sich die Beispiele an, um zu sehen, wie die Richtlinien in der Praxis aussehen:
Empfehlungen für Sie
- Hinweis: Linktext wird angezeigt, wenn JavaScript deaktiviert ist.
- Zustandsproduktion in der Benutzeroberfläche
- UI-Ebene
- Datenschicht