
離線優先應用程式是指不必存取網際網路,就能執行所有或部分關鍵核心功能的應用程式。也就是說,這類應用程式可以離線執行部分或所有商業邏輯。
建構離線優先應用程式時,首先要考慮用於存取應用程式資料和商業邏輯的資料層。應用程式可能需要不時從裝置外部來源重新整理資料。執行此操作時,應用程式可能需要呼叫網路資源來保持最新狀態。
然而,我們無法保證隨時都能使用網路。裝置難免會遇到網路連線不穩或緩慢的問題,使用者也可能遇到以下情況:
- 網際網路頻寬受限。
- 連線暫時中斷,例如搭乘電梯或經過隧道時
- 偶爾才能存取資料,例如僅支援 Wi-Fi 上網的平板電腦
不管原因為何,應用程式通常都能在上述情況下妥善運作。為確保應用程式可在離線狀態下正確運作,應用程式必須符合以下條件:
- 即使沒有穩定的網路連線也能使用
- 會立即向使用者顯示店面資料,而非靜靜等待第一個網路呼叫完成或失敗
- 擷取資料的方式應將電池和資料狀態納入考量,例如只在充電或連上 Wi-Fi 等理想情況下要求擷取資料
符合這些條件的應用程式通常稱為離線優先應用程式。
設計離線優先應用程式
設計離線優先應用程式時,請先從資料層著手,然後考量您可對應用程式資料執行的以下兩項主要作業:
- 讀取:擷取資料供應用程式其他部分使用,例如向使用者顯示資訊。在 Compose 中,您通常會透過觀察狀態來完成這項作業。當 UI 將店面資料來源視為狀態進行觀察時,畫面會自動反映最新的店面資料。
- 寫入:保留使用者輸入內容,供日後擷取。在 Compose 中,您通常會使用從 UI 傳送至 ViewModel 的事件和動作來達成此目的。
資料層中的存放區會負責合併資料來源,提供應用程式資料。在離線優先應用程式中,須至少有一個資料來源不必存取網路,就能執行最關鍵的工作,比如讀取資料。
在離線優先應用程式中建立模型資料
在離線優先應用程式中,每個會用到網路資源的存放區都至少有 2 個資料來源:
- 本機資料來源
- 網路資料來源
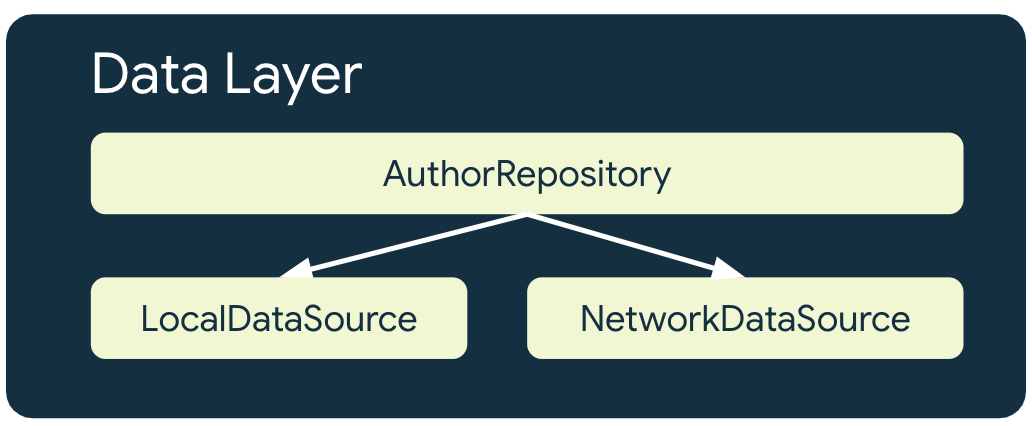
本機資料來源
本機資料來源是應用程式標準化的可靠資料來源。當應用程式中的較高層讀取任何資料時,都應將此做為專屬來源。這種做法可確保連線狀態之間的資料維持一致。一般來說,本機資料來源是由保存在磁碟中的儲存空間負責備份。以下列舉將資料保留至磁碟的一些常見方式:
- 結構化資料來源,例如 Room 等關聯資料庫
- 非結構化資料來源,例如帶有 DataStore 的通訊協定緩衝區
- 簡易檔案。
網路資料來源
網路資料來源是應用程式的實際狀態。店面資料來源最好能與網路資料來源同步,店面資料來源也可能落後於網路資料來源,如果落後了,應用程式需要在恢復連線時更新。相反地,在連線能力恢復且應用程式可以更新網路資料來源前,網路資料來源也可能落後於店面資料。應用程式的網域和 UI 層一律不得直接與網路層通訊,代管的 repository 應負責通訊,並將該網路層用於更新店面資料。
公開資源
應用程式讀取及寫入本機和網路資料來源時,採取的方式存在根本差異。查詢本機資料來源既快速又有彈性,使用 SQL 查詢時便是如此。反之,網路資料來源可能較慢且受限。透過 ID 以漸進方式存取符合 REST 樣式的資源時,就屬於這種情況。因此,每種資料來源通常需要對自身提供的資料採用專屬的表示法,因此,店面資料來源和網路資料來源可能有自己的模型。
下方目錄結構以視覺化方式呈現這個概念。AuthorEntity 代表從應用程式本機資料庫讀取的作者,而 NetworkAuthor 代表透過網路序列化的作者:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
下方則是 AuthorEntity 和 NetworkAuthor 的詳細資料:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
建議您同時將 AuthorEntity 和 NetworkAuthor 保留在資料層,並公開第三種類型供外部層使用。假如本機和網路資料來源中的細微變更並未徹底改變應用程式行為,上述做法可確保外部層不受這些變更影響。詳情請參閱以下程式碼片段:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
網路模型可定義擴充功能方法,並將其轉換成本機模型,而本機模型同樣可定義擴充功能方法,並將其轉換為外部表示法,如下列程式碼片段所示:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
讀取
「讀取」是在離線優先應用程式中對應用程式資料執行的基本作業。因此,請務必確保應用程式能讀取資料,並在一有新資料時就能加以顯示。能這麼做的就是回應式應用程式,因為這類應用程式會公開具有可觀察類型的讀取 API。
在以下程式碼片段中,OfflineFirstTopicRepository 會為自身的所有讀取 API 傳回 Flow。如此一來,當它收到來自網路資料來源的更新內容時,就能更新自己的讀取器。換句話說,如果本機店面資料來源無效,讀取器就會讓 OfflineFirstTopicRepository 推送變更。因此,您必須備妥 OfflineFirstTopicRepository 的所有讀取器,在應用程式恢復網路連線時,處理可能觸發的資料變更。此外,OfflineFirstTopicRepository 還會直接從本機資料來源讀取資料,但它只能先更新本機資料來源,進而將資料變更的消息告知讀取器。
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
在 Jetpack Compose 應用程式中,請使用 ViewModel 連結資料層和 UI。在 ViewModel 中,使用 stateIn 運算子將 Flow 轉換為 StateFlow。然後,可組合函式會使用 collectAsStateWithLifecycle() 收集這些狀態,並以生命週期感知的方式自動管理訂閱項目。
如要進一步瞭解 collectAsStateWithLifecycle(),請參閱「狀態和 Jetpack Compose」。
錯誤處理的策略
離線優先應用程式中處理錯誤的方式各不相同,具體取決於可能發生錯誤的資料來源。以下各小節將概略說明這些策略。
本機資料來源
請盡量減少從店面資料來源讀取資料時發生的錯誤。為防止讀取器出錯,請在讀取器收集資料時所用的 Flow 上使用 catch 運算子。
在 ViewModel 中使用 catch 運算子的步驟如下:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
如要採取更具彈性的做法,請考慮使用 LCE (載入內容錯誤) 解決方案。 在 LCE 中,如果讀取時發生失敗,您會顯示錯誤狀態。通常,您會將 UI 狀態模擬為 Kotlin 密封類別,藉此達成 LCE。
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
網路資料來源
如果從網路資料來源讀取資料時發生錯誤,應用程式需運用經驗法則,重新嘗試擷取資料。常見的經驗法則包括:
指數輪詢
在指數輪詢中,應用程式會不斷嘗試從網路資料來源讀取資料,每次嘗試的時間間隔會持續增加,直到讀取成功或其他條件指示應停止讀取為止。
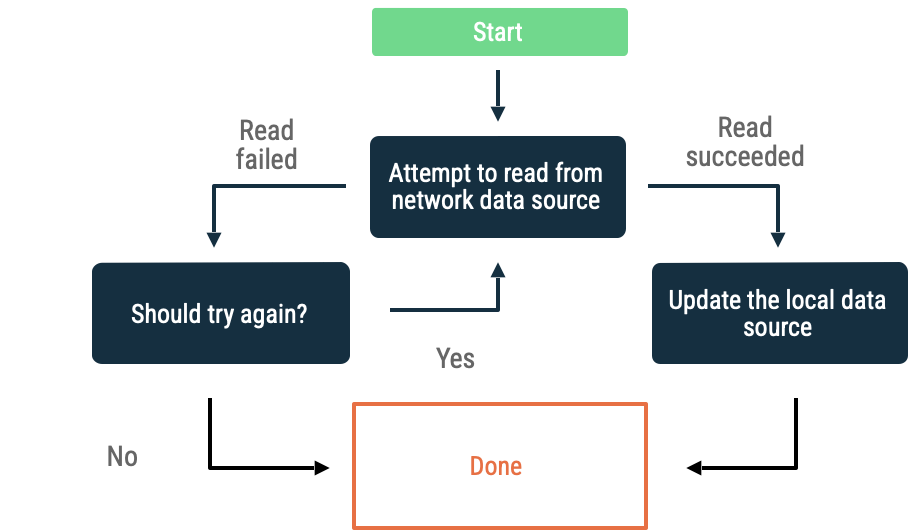
以下條件可用來評估應用程式是否應繼續延遲作業:
- 網路資料來源指出的錯誤類型。舉例來說,如果網路呼叫傳回的錯誤指出沒有連線,就應重試網路呼叫。如果 HTTP 要求未獲得授權,那麼在取得適當憑證前,便不該重試 HTTP 要求。
- 重試次數上限。
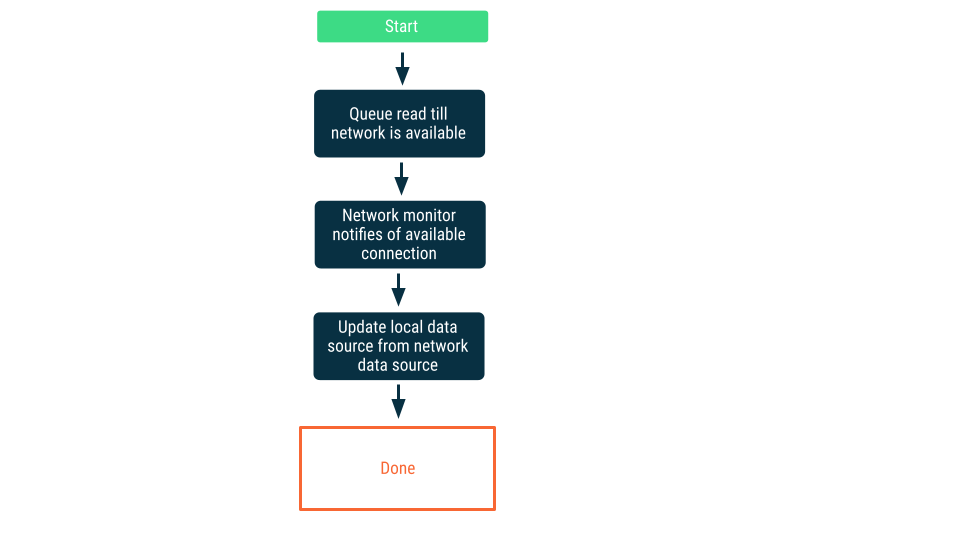
網路連線監控
在這個做法中,讀取要求會排入佇列,直到應用程式確定可連線至網路資料來源為止。建立連線後,系統會將讀取要求移出佇列,然後讀取資料並更新店面資料來源。在 Android 上,系統可能會透過 Room 資料庫來維護這個佇列,並以持續性工作的形式,運用 WorkManager 清空佇列。
寫入
我們建議在離線優先應用程式中讀取資料時使用可觀察的類型,不過對寫入 API 來說,則建議使用暫停函式等非同步 API。這可避免阻斷 UI 執行緒,並協助處理錯誤,因為在跨越網路邊界時,離線優先應用程式中的寫入作業可能會失敗。
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
在上述程式碼片段中,由於方法會暫停,選用的非同步 API 為協同程式。
寫入策略
在離線優先應用程式中寫入資料時,可以考慮採用以下三種策略,具體選擇的策略取決於寫入的資料類型和應用程式需求:
僅限線上寫入
嘗試橫跨網路邊界寫入資料。如果成功,請更新本機資料來源;否則請擲回例外狀況,交由呼叫端妥善回覆。
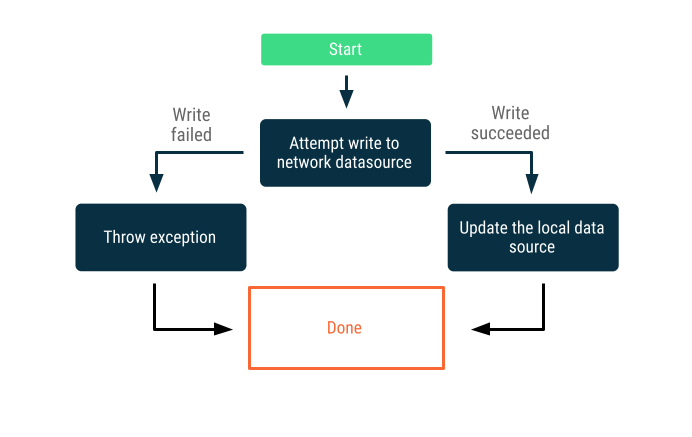
這項策略通常用於必須近乎即時地在線上執行的寫入交易,例如銀行轉帳。由於寫入可能失敗,因此通常必須告知使用者無法寫入,或事先禁止使用者嘗試寫入資料。在這些情況下,您或許可使用以下策略:
- 如果應用程式需要具備網際網路存取權才能寫入資料,您可以選擇不向使用者顯示可寫入資料的 UI,或者至少停用這項功能。
- 您可以採用使用者無法關閉的
AlertDialog,或透過Snackbar,通知使用者目前處於離線狀態。
已加入佇列的寫入
如有要寫入的物件,請將該物件插入佇列。應用程式恢復連線後,請以指數輪詢方式清空佇列。在 Android 上,清空離線佇列屬於持續性工作,通常會委派給 WorkManager。
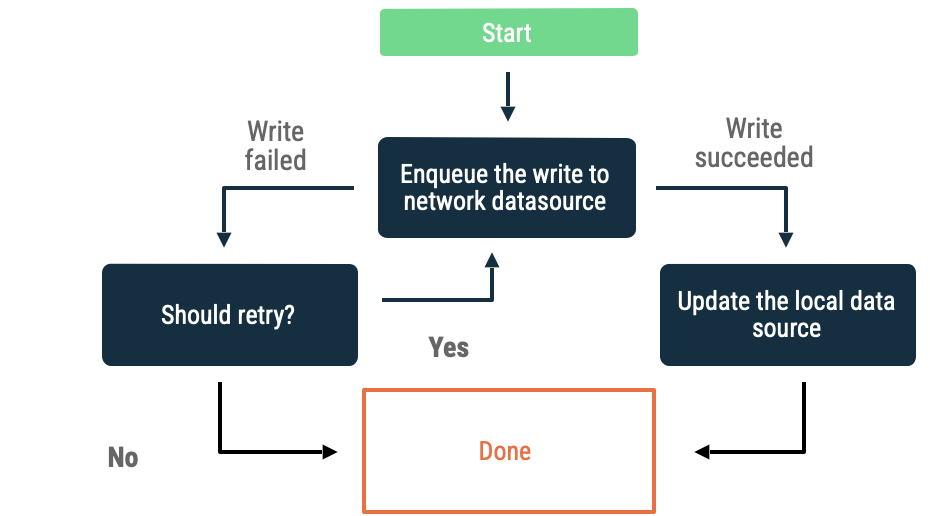
此做法適合下列情況:
- 不一定要將資料寫入網路。
- 交易不具時效性。
- 作業失敗時,不一定要告知使用者。
此做法的用途包括分析事件和記錄。
延遲寫入
請先寫入本機資料來源,然後將寫入作業排入佇列,方便盡快通知網路。這一點非常重要,因為當應用程式恢復網路連線後,網路資料來源和本機資料來源可能會發生衝突。下一節將詳細說明如何解決衝突。
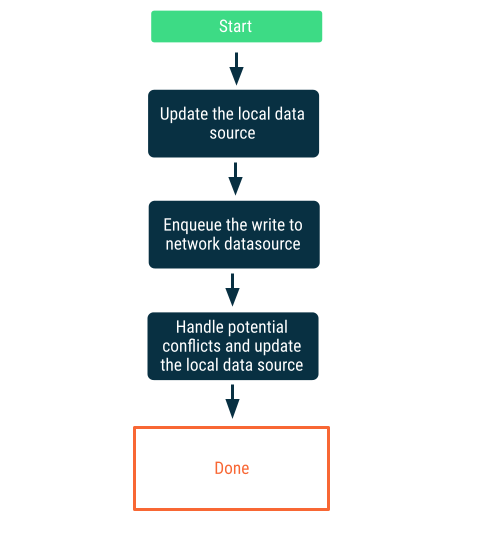
如果資料對應用程式而言非常重要,此做法就是不二之選。舉例來說,在待辦事項清單的離線優先應用程式中,使用者離線新增的所有工作都必須儲存在本機,避免資料遺失。
同步處理及衝突解決
離線優先應用程式恢復連線時,需要核對本機與網路資料來源中的資料。這項程序稱為同步處理。應用程式主要是透過兩種方式與網路資料來源保持同步:
- 提取式同步處理
- 推送式同步處理
提取式同步處理
在提取式同步處理作業中,應用程式會連上網路,按需求讀取最新的應用程式資料。這種做法的常見經驗法則是以導覽為基礎,採用此做法時,應用程式只會在向使用者顯示資料前擷取資料。
如果應用程式預計在短期到中期內都沒有網路連線,這個做法就非常實用。這是因為重新整理資料需要見機行事,在長期沒有連線的情況下,使用者越有可能利用過時或空白的快取,嘗試前往應用程式目的地。
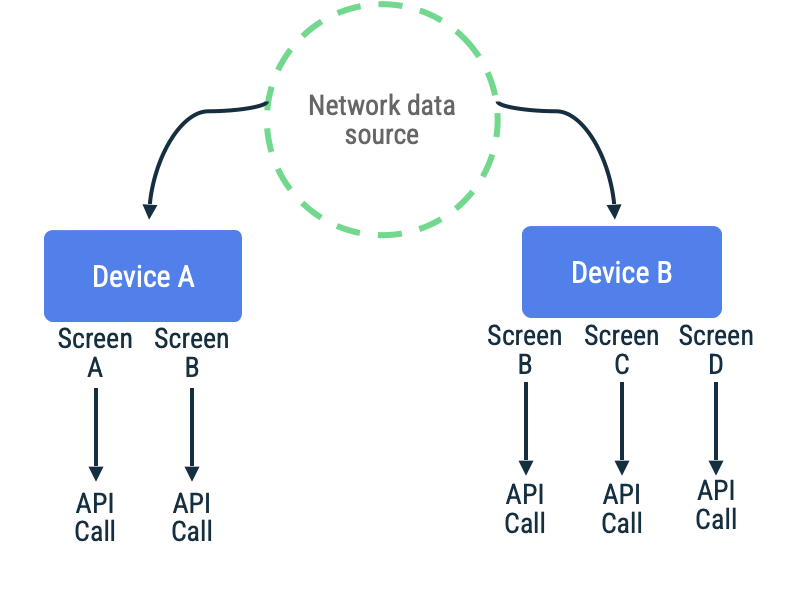
假設在某個應用程式中,網頁權杖的用途是針對特定畫面擷取無盡捲動清單內的項目。這個實作方法可能會延遲連上網路、將資料保存至本機資料來源,然後從本機資料來源讀取資料,將資訊傳回給使用者。如果沒有網路連線,存放區可能只會從本機資料來源要求資料。這是 Jetpack Paging 程式庫搭配 RemoteMediator API 使用的模式。
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
下表摘要說明提取式同步處理的優點和缺點:
| 優點 | 缺點 |
|---|---|
| 實作方式相對簡單。 | 容易大量使用資料。這是因為重複造訪導覽目的地會觸發不必要的擷取作業,重新擷取未變更的資訊。您可以透過適當的快取緩解這個問題,比如在 UI 層使用 cachedIn 運算子,或在網路層使用 HTTP 快取。 |
| 系統一律不會擷取不需要的資料。 | 使用關聯資料時無法正確擴充,因為提取的模型必須自給自足。如果正在同步處理的模型仰賴其他待擷取的模型來填入內容,前述大量使用資料的問題會更加嚴重。此外,這也可能導致父項模型與巢狀模型的存放區彼此依賴。 |
推送式同步處理
在推送式同步處理作業中,本機資料來源會盡可能嘗試模仿網路資料來源的備用資源組合。首次啟動時,本機資料來源會主動擷取適量資料來設定基準。之後便會運用來自伺服器的通知,在資料過時當下發出快訊。
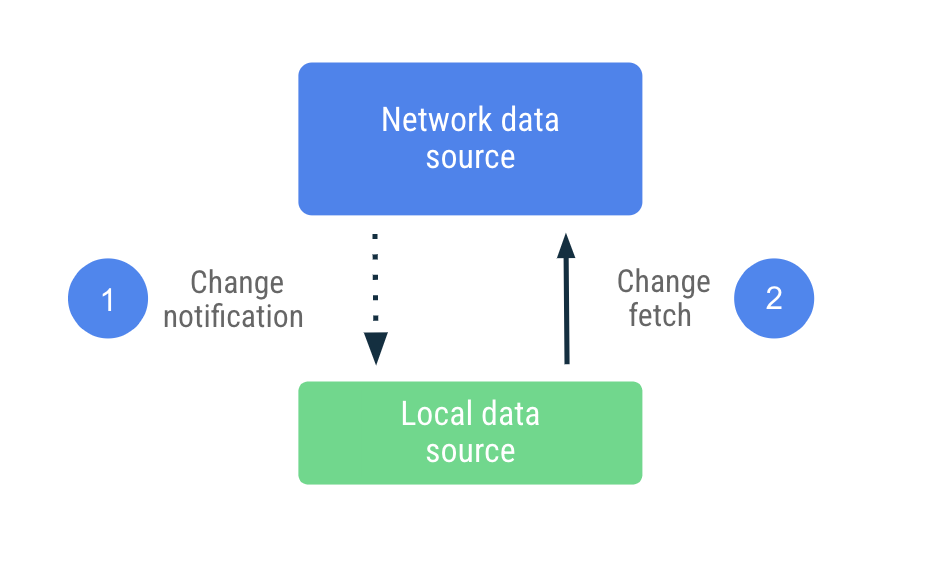
收到過時通知後,應用程式會連線至網路,只更新標示為過時的資料。這項工作會委派給 Repository,由其負責連線至網路資料來源,並保留擷取到店面資料的資料。由於存放區會經由可觀察的類型公開資料,因此一旦有任何變更,讀取器就會收到通知。
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
在這個做法中,應用程式會大幅減少對網路資料來源的依賴,即使長時間沒有這類資料來源也能運作。這會在離線時一併提供讀取及寫入存取權,因為系統假設本機存有來自網路資料來源的最新資訊。
下表摘要說明推送式同步處理的優點和缺點:
| 優點 | 缺點 |
|---|---|
| 應用程式可無限期離線使用。 | 透過資料版本管理來解決衝突並不容易。 |
| 能盡量減少使用資料。應用程式只會擷取已變更的資料。 | 需考慮同步處理期間的寫入問題。 |
| 適合用於關聯資料。每個存放區只負責為自己支援的模型擷取資料。 | 網路資料來源需支援同步處理作業。 |
混合式同步處理
部分應用程式會採用混合做法,依資料選擇提取式或推送式做法。舉例來說,由於動態消息的更新頻率較高,社群媒體應用程式可能會採用提取式同步處理做法,按需求擷取使用者追蹤的動態消息。但這個社群媒體應用程式在處理使用者名稱、個人資料相片等已登入使用者的資料時,也可能選擇採用推送式同步處理做法。
歸根究底,在為離線優先應用程式選擇同步處理方式時,需考量產品需求和現有的技術基礎架構。
衝突解決
如果應用程式在離線期間寫入本機的資料與網路資料來源不相符,就表示發生衝突,而您必須先解決衝突,才能執行同步處理作業。
如要解決衝突,通常需要藉助版本管理。應用程式需要執行一些簿記工作,記錄發生變更的時間,以便將中繼資料傳遞給網路資料來源。接著,網路資料來源會負責提供絕對可靠的資料來源。視應用程式需求而定,可以考慮的衝突解決策略十分多樣。對行動應用程式而言,常見做法是「以最後寫入者為準」。
以最後寫入者為準
在這個做法中,裝置會在寫入網路的資料中附加時間戳記中繼資料。網路資料來源收到這些資料時,會捨棄比目前狀態舊的所有資料,同時接受比目前狀態新的資料。
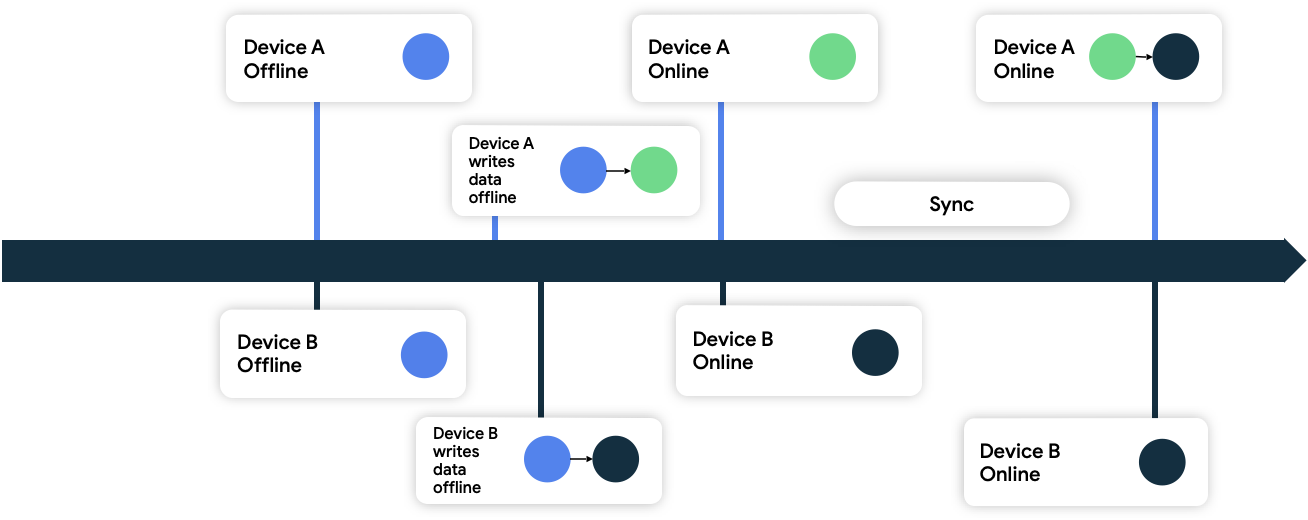
在圖 9 中,兩部裝置都處於離線狀態,而且最初都與網路資料來源保持同步。離線時,兩者都會在本機寫入資料,並記錄寫入資料的時間。如果兩者皆再次連上網路並與網路資料來源同步,為解決衝突問題,網路會保留裝置 B 的資料,因為該裝置寫入資料的時間較晚。
在離線優先應用程式中使用 WorkManager
在先前介紹的讀取和寫入策略中,有兩種常見的公用程式:
- 佇列
- 讀取:用來將讀取作業延遲到有網路連線為止。
- 寫入:用來將寫入作業延遲到有網路連線為止,並將寫入作業重新排入佇列,方便重試。
- 網路連線監控器
- 讀取:當做信號,指示在應用程式連線時清空讀取佇列,並用於同步處理。
- 寫入:當做信號,指示在應用程式連線時清空寫入佇列,並用於同步處理。
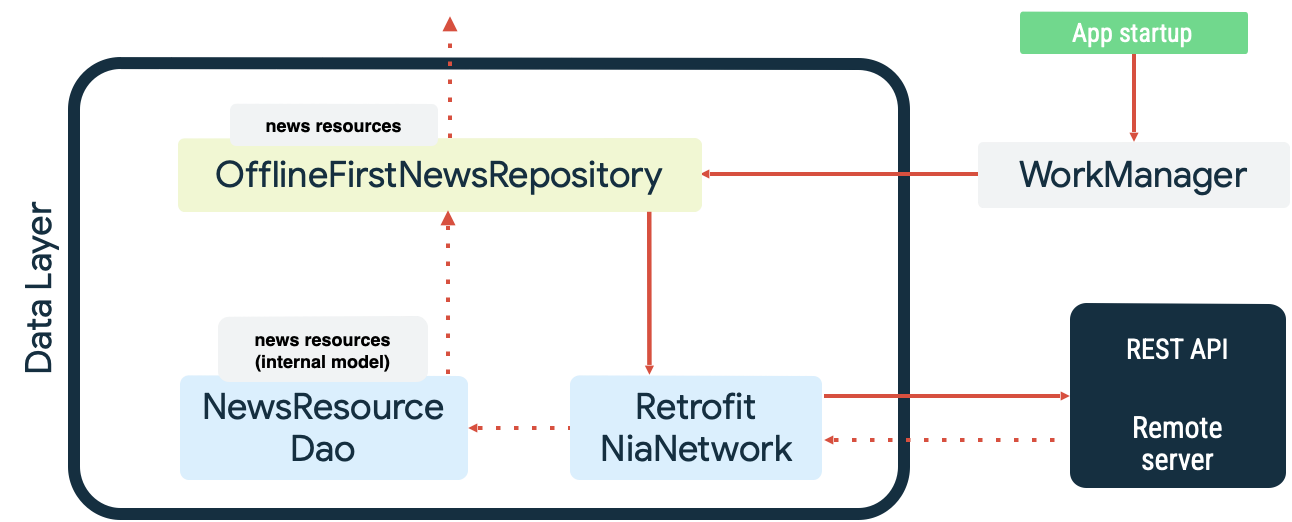
這兩種情況都是說明 WorkManager 擅長處理持續性作業的例子。舉例來說,在 Now in Android 範例應用程式中,同步處理店面資料來源時,WorkManager 可用做讀取佇列和網路監控器。應用程式啟動時會執行下列操作:
- 將讀取同步處理工作排入佇列,確保店面資料與網路資料來源維持一致。
- 清空讀取同步處理佇列,在應用程式連上網路時開始同步。
- 使用指數輪詢功能從網路資料來源執行讀取作業。
- 將讀取結果保留在本機店面資料,並解決任何衝突。
- 公開來自店面資料來源的資料,供應用程式的其他層取用。
下圖說明這些動作:
透過 WorkManager 將同步處理工作加入佇列後,請使用 KEEP ExistingWorkPolicy 將其指定為不重複工作:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() 定義如下:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
具體來說,SyncConstraints 定義的 Constraints 會規定 NetworkType 須為 NetworkType.CONNECTED。也就是說,系統會等到可使用網路後再執行。
可使用網路後,worker 會委派適當的 Repository 例項,清空 SyncWorkName 指定的不重複工作佇列。如果同步處理作業失敗,doWork() 方法會傳回 Result.retry()。WorkManager 會以指數輪詢方式自動重試同步處理作業。否則,則會傳回 Result.success(),完成同步處理。
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
範例
以下 Google 範例為離線優先應用程式。 歡迎查看這些範例,瞭解實務做法: