
オフラインファースト アプリとは、インターネットにアクセスしなくても、コア機能の一部または全部を実行できるアプリのことです。つまり、こうしたアプリはビジネス ロジックの一部またはすべてをオフラインで実行できます。
オフラインファースト アプリを作成するにあたり、まずアプリデータとビジネス ロジックへのアクセスを提供するデータレイヤについて検討する必要があります。場合によっては、アプリがこのデータをデバイスの外部にあるソースから随時更新する必要が生じます。その際、最新の状態を維持するために、ネットワーク リソースへの呼び出しが必要になることもあります。
ネットワークの可用性は常に保証されているわけではありません。デバイスの接続が不安定である場合や、ネットワークの接続速度が遅い場合がよくあります。ユーザーは次のような問題に遭遇する可能性があります。
- インターネット帯域幅が制限を受ける。
- エレベーターやトンネルの中にいるときなど、接続が一時的に切断される
- データアクセスが途切れる(Wi-Fi 専用タブレットなど)
理由はどうであれ、こうした状況でもアプリが適切に機能することはよくあります。オフラインでもアプリを適切に機能させるには、次のことが可能である必要があります。
- 安定したネットワーク接続がない状態で引き続き使用可能である
- 最初のネットワーク呼び出しの完了や失敗を待たずに、すぐにローカルデータをユーザーに表示する
- バッテリーとデータの状態を考慮した方法でデータを取得する(たとえば、最適な状況(充電中や Wi-Fi 接続時など)でのみデータ取得をリクエストする)
これらの条件を満たすアプリは多くの場合、オフラインファースト アプリと呼ばれます。
オフラインファースト アプリの設計
オフラインファースト アプリを設計する際は、データレイヤ、そしてアプリデータに対して実行できる次の 2 つの主要な操作から始める必要があります。
- 読み取り: アプリの他の部分(ユーザーへの情報の表示など)で使用するデータを取得します。Compose では、通常、状態を監視することでこれを実現します。UI がローカル データソースを状態として監視している場合、画面には最新のローカル データが自動的に反映されます。
- 書き込み: 後で取得できるようにユーザー入力を永続化します。Compose では、通常、UI から ViewModel に送信されるイベントとアクションを使用してこれを実現します。
データレイヤのリポジトリは、データソースを組み合わせてアプリデータを提供する役割を担います。オフラインファースト アプリでは、最も重要なタスクを実行するために、ネットワーク アクセスを必要としないデータソースが少なくとも 1 つ必要です。こうした重要なタスクのひとつは、データの読み取りです。
オフラインファースト アプリでのモデルデータ
オフラインファースト アプリには、ネットワーク リソースを利用するリポジトリごとに少なくとも次の 2 つのデータソースがあります。
- ローカル データソース
- ネットワーク データソース
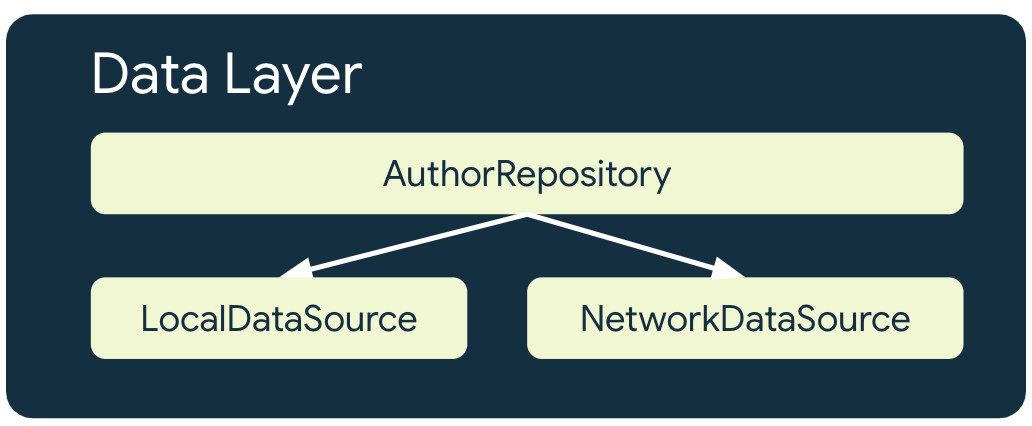
ローカル データソース
ローカル データソースは、アプリの正規の信頼できるソースです。アプリの上位レイヤによって読み取られるすべてのデータの中で唯一のソースである必要があります。これにより、接続状態間のデータの一貫性が確保されます。多くの場合、ローカル データソースは、ディスクに永続化されたストレージを基盤としています。データをディスクに永続化するための一般的な方法には、次のようなものがあります。
- 構造化データソース(Room のようなリレーショナル データベースなど)
- 非構造化データソース(DataStore を使用したプロトコル バッファなど)
- シンプルなファイル
ネットワーク データソース
ネットワーク データソースは、アプリの実際の状態です。ローカル データソースは、ネットワーク データソースと同期させることをおすすめします。ローカル データソースがネットワーク データソースより遅延することもあります。その場合は、オンラインに戻ったときにアプリを更新する必要があります。反対に、接続が回復してアプリがデータソースを更新できるようになるまで、ネットワーク データソースがローカル データソースより遅延することもあります。アプリのドメインレイヤと UI レイヤがネットワーク層と直接通信しないようにする必要があります。ネットワーク レイヤと通信し、それを使用してローカル データソースを更新する役割は、ホストする repository が担います。
リソースの公開
アプリがローカル データソースとネットワーク データソースに対して読み取り操作と書き込み操作を実行する方法に関して、両データソースには根本的な違いがあります。SQL クエリを使用する場合など、ローカル データソースのクエリは高速かつ柔軟に行うことができます。反対に、ID によって RESTful リソースに段階的にアクセスする場合など、ネットワーク データソースは低速になり、制約を受けることがあります。その結果、データソースごとに、提供するデータの独自の表現が必要になることがよくあり、ローカル データソースとネットワーク データソースがそれぞれ独自のモデルを持っている場合があります。
以下のディレクトリ構造は、このコンセプトを視覚化したものです。AuthorEntity はアプリのローカル データベースから読み取られた著者を表し、NetworkAuthor はネットワーク上にシリアル化された著者を表します。
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity と NetworkAuthor の詳細は次のとおりです。
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
AuthorEntity と NetworkAuthor の両方をデータレイヤの内部に保持し、外部レイヤで使用するための第 3 のタイプを公開することをおすすめします。これにより、アプリの動作を根本的に変更しないローカル データソースとネットワーク データソースの軽微な変更から外部レイヤが保護されます。これは、以下のスニペットに示すように行われます。
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
次に、ネットワーク モデルは、それ自体をローカルモデルに変換するための拡張メソッドを定義できます。同様に、ローカルモデルにも、それ自体を外部表現に変換するための拡張メソッドがあります。以下のスニペットをご覧ください。
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
読み取り
読み取りは、オフラインファースト アプリのアプリデータに対する基本的な操作です。したがって、アプリがデータを読み取ることができること、および新しいデータが利用可能になったらすぐに、アプリがこれらのデータを表示できることが必要とされます。こうした操作が可能なアプリは、リアクティブ アプリです。これらは、オブザーバブルな型で読み取り API を公開するためです。
次のスニペットでは、OfflineFirstTopicRepository はそのすべての読み取り API に対して Flow を返します。これにより、このクラスは、ネットワーク データソースから最新情報を受け取ったときにそのリーダーを更新できます。つまり、ローカル データソースが無効な場合に OfflineFirstTopicRepository が変更を push できるようにします。したがって、OfflineFirstTopicRepository の各リーダーは、アプリへのネットワーク接続が回復したときに、トリガーされる可能性のあるデータ変更に対処できるよう準備する必要があります。さらに、OfflineFirstTopicRepository はローカル データソースからデータを直接読み取ります。最初にローカル データソースを更新するだけで、データの変更がリーダーに通知されます。
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
Jetpack Compose アプリでは、ViewModel を使用してデータレイヤと UI を橋渡しします。ViewModel で、stateIn 演算子を使用して Flow を StateFlow に変換します。コンポーザブルは collectAsStateWithLifecycle() を使用してこれらの状態を収集し、ライフサイクルを認識した方法でサブスクリプションを自動的に管理します。
collectAsStateWithLifecycle() の詳細については、状態と Jetpack Compose をご覧ください。
エラー処理の方式
オフラインファースト アプリでエラーを処理する方法は、発生する可能性のあるデータソースに応じてそれぞれ異なります。以降のサブセクションでは、これらの手段の概要を説明します。
ローカル データソース
ローカル データソースからの読み取り時のエラーを最小限に抑えるようにしてください。エラーからリーダーを保護するには、リーダーがデータを収集する Flow に対して catch 演算子を使用します。
ViewModel で catch 演算子を使用する例は、次のとおりです。
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
より復元力の高いアプローチとしては、LCE(Loading Content Error)ソリューションを検討してください。LCE では、読み取り中にエラーが発生すると、エラー状態が表示されます。通常、UI 状態を Kotlin のシールクラスとしてモデル化することで、LCE を実現します。
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
ネットワーク データソース
ネットワーク データソースからデータを読み取る際にエラーが発生した場合、アプリでヒューリスティックを使用してデータの取得を再試行する必要があります。一般的なヒューリスティックは、次のとおりです。
指数バックオフ
指数バックオフでは、アプリはネットワーク データソースからの読み取りを試行し続けます。読み取りが成功するか、他の条件によって読み取りを停止する必要があると判断されるまで続行され、試行間の時間間隔は増加し続けます。
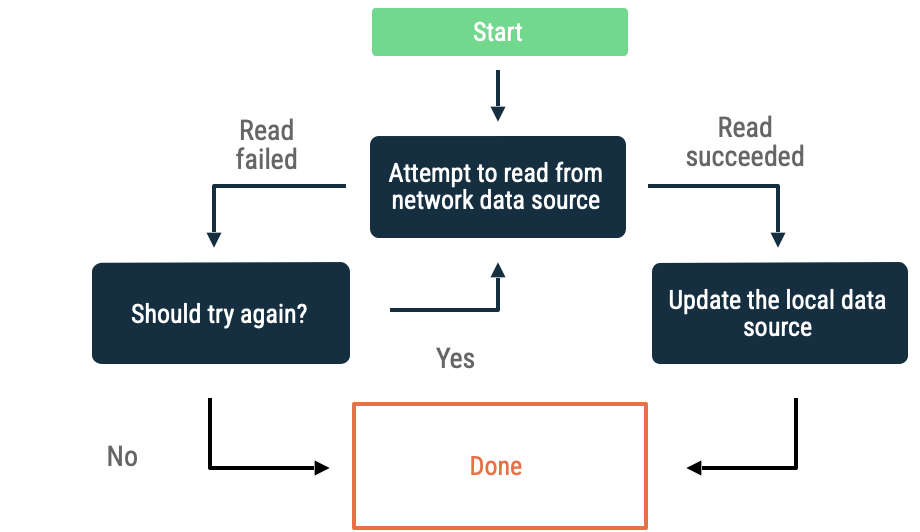
アプリで引き続きバックオフすべきかどうかを評価する基準には、次のようなものがあります。
- ネットワーク データソースが示したエラーの種類。たとえば、接続がないことを示すエラーが返された場合、ネットワーク呼び出しを再試行します。HTTP リクエストが承認されていない場合は、適切な認証情報が利用できるまでリクエストを再試行しないでください。
- 最大許容再試行回数。
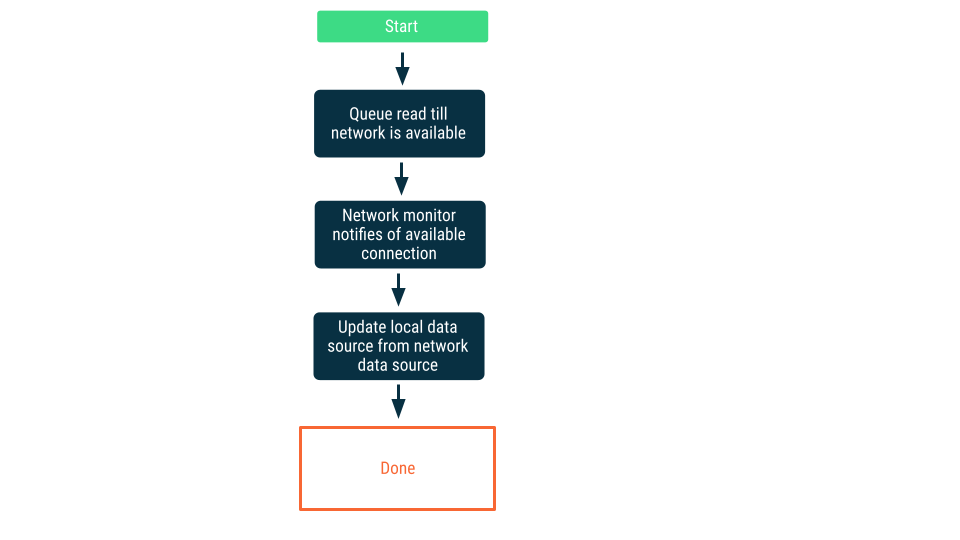
ネットワーク接続のモニタリング
この方法では、アプリがネットワーク データソースに接続できると確認されるまで、読み取りリクエストはキューに追加されます。接続が確立されると、読み取りリクエストはキューから除外され、データの読み取りとローカル データソースの更新が行われます。Android では、このキューは Room データベースで維持され、WorkManager を使用して永続処理としてドレインされる場合があります。
書き込み
オフラインファースト アプリでデータを読み取るには、オブザーバブルな型を使用することが推奨されますが、これらの読み取り方法に対応する書き込み API は、suspend 関数などの非同期 API です。オフラインファースト アプリでの書き込みはネットワーク境界を越えるときに失敗する可能性があるため、非同期 API を使用すると、UI スレッドはブロックされず、エラー処理に役立ちます。
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
上記のスニペットでは、メソッドが一時停止するため、非同期 API としてコルーチンが選択されています。
書き込み手段
オフラインファースト アプリにデータを書き込む際に検討すべき手段が 3 つあります。選択する手段は、書き込まれるデータの種類とアプリの要件によって異なります。
オンラインのみの書き込み
ネットワーク境界を越えてデータを書き込もうとします。成功した場合は、ローカル データソースを更新します。それ以外の場合は、例外をスローし、呼び出し元に適切な応答を任せます。
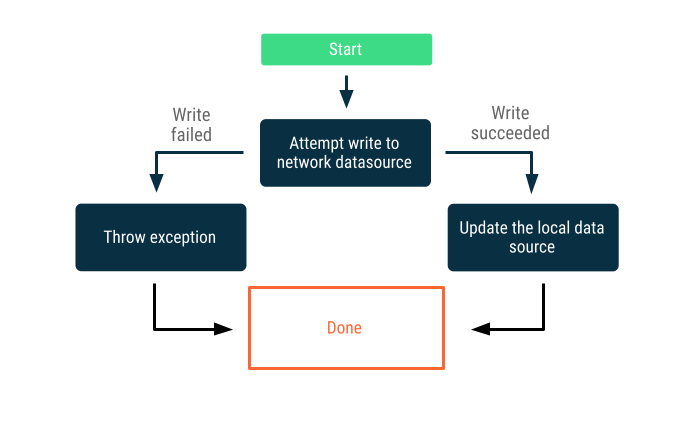
この戦略は多くの場合、ほぼリアルタイムでオンラインで実行する必要がある書き込みトランザクション(銀行振込など)に使用されます。書き込みが失敗する可能性があるため、書き込みが失敗したことをユーザーに伝えるか、ユーザーが最初からデータを書き込まないようにする必要が頻繁に生じます。このような場合にとることができる手段には、次のようなものがあります。
- データの書き込みにインターネット アクセスを必要とするアプリでは、データの書き込みを許可する UI をユーザーに表示しないようにするか、少なくともその UI を無効にすることができます。
- ユーザーが閉じられない
AlertDialogまたはSnackbarを使用して、オフラインであることをユーザーに通知できます。
書き込みのキューへの追加
書き込むオブジェクトがある場合は、それをキューに追加します。アプリがオンラインに戻ったら、指数バックオフを使用してキューをドレインします。Android では、オフライン キューのドレインは永続処理であり、多くの場合 WorkManager に委任されます。
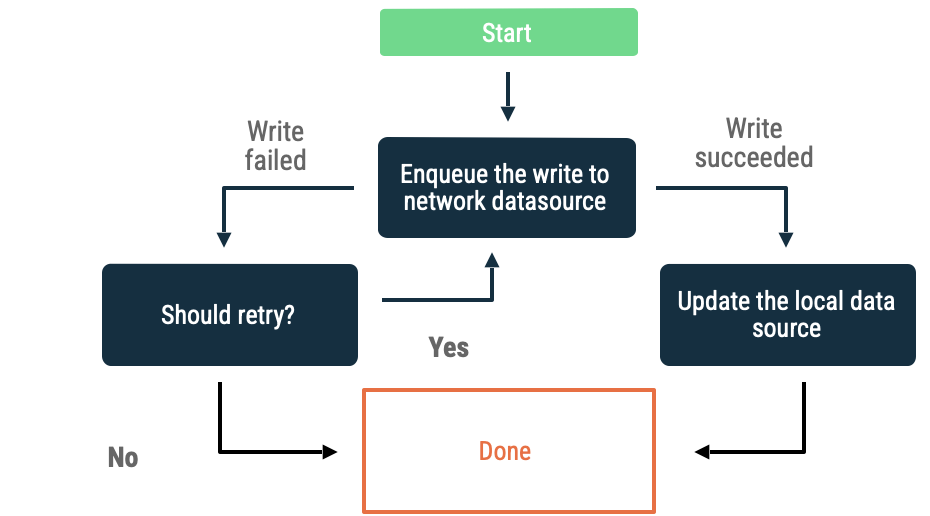
この方法は、次のようなシナリオに適しています。
- データをネットワークに書き込む必要がない。
- トランザクションに時間的制約がない。
- 操作に失敗した場合、ユーザーに通知する必要がない。
この方法の使用例としては、分析イベントやロギングがあります。
遅延書き込み
ローカル データソースに書き込みを行ってから、その書き込みをキューに追加し、できるだけ早くネットワークに通知します。アプリがオンラインに戻ったとき、ネットワークとローカル データソースの間に競合が生じる可能性があるため、これは簡単な作業ではありません。競合の解決について詳しくは、次のセクションをご覧ください。
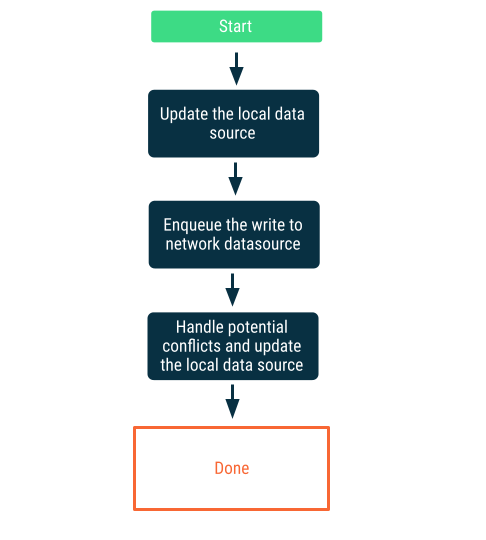
この方法は、データがアプリにとって不可欠な場合に適しています。たとえば、オフラインファーストの ToDo リストアプリでは、ユーザーがオフラインで追加したタスクはすべて、ローカルに保存してデータ損失のリスクを回避する必要があります。
同期と競合の解決
オフラインファースト アプリが接続を回復するとき、ローカル データソースのデータをネットワーク データソースのデータと一致させる必要があります。このプロセスは同期と呼ばれます。アプリがそのネットワーク データソースと同期するには、主に次の 2 つの方法があります。
- pull ベースの同期
- push ベースの同期
pull ベースの同期
pull ベースの同期では、アプリがネットワークにアクセスして、最新のアプリデータをオンデマンドで読み取ります。この方法の一般的なヒューリスティックは、ナビゲーション ベースです。この場合、アプリはユーザーにデータを表示する直前にのみデータを取得します。
この方法は、アプリがネットワークに接続できない期間が短期間から中程度の期間であると予想される場合に最適です。データの更新は日和見的であり、接続できない期間が長い場合、ユーザーが古いキャッシュや空のキャッシュを使用してアプリのデスティネーションにアクセスしようとする可能性が高くなるためです。
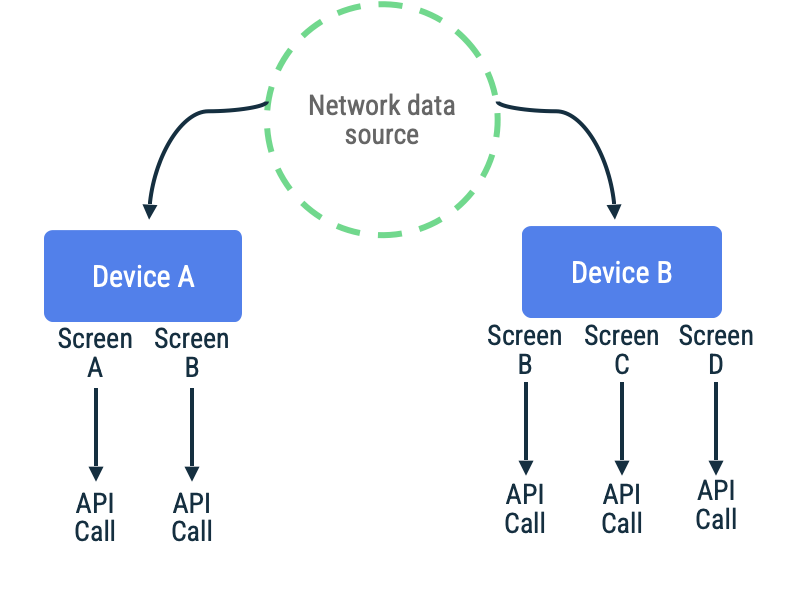
アプリでページトークンを使用して、特定の画面の無限スクロール リスト内のアイテムを取得する場合について考えてみましょう。この実装では、ネットワークへの接続を遅延させ、データをローカル データソースに永続化してから、ローカル データソースからデータを読み取ってユーザーに情報を表示できます。ネットワーク接続がない場合、リポジトリは、ローカル データソースのみからデータをリクエストできます。以下は、Jetpack Paging ライブラリとその RemoteMediator API で使用されるパターンです。
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
pull ベースの同期のメリットとデメリットを次の表にまとめています。
| メリット | デメリット |
|---|---|
| 比較的簡単に実装できます。 | データ使用量が多くなる傾向があります。ナビゲーション デスティネーションに繰り返しアクセスすると、変更されていない情報を再取得するための不要な操作がトリガーされるためです。この問題は、適切なキャッシュの使用で軽減できます。これを行うには、UI レイヤで cachedIn 演算子を使用するか、ネットワーク層で HTTP キャッシュを使用します。 |
| 不要なデータは取得されなくなります。 | pull されたモデルではそれ自体で十分である必要があるため、リレーショナル データでの使用には適していません。同期対象のモデルがそれ自体を取り込むために取得される他のモデルに依存している場合、前述の大量のデータを使用する問題はさらに深刻化します。親モデルのリポジトリとネストされたモデルのリポジトリの間に依存関係が生じる可能性もあります。 |
push ベースの同期
push ベースの同期では、ローカル データソースがネットワーク データソースのレプリカセットを可能な限り模倣しようとします。初回起動時に適切な量のデータを事前に取得してベースラインを設定します。その後、サーバーからの通知に基づいて、データが古くなったときに警告を発します。
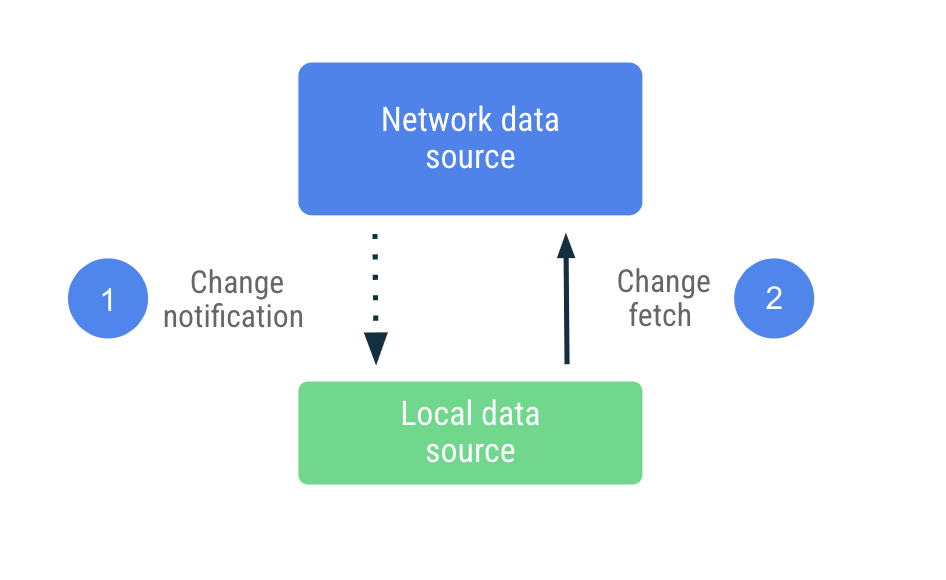
古くなった通知を受信すると、アプリはネットワークに接続し、古くなったとマークされたデータのみを更新します。この処理は Repository に委任されます。委任されると、ネットワーク データソースに接続し、ローカル データソースに取得されたデータを永続化します。このリポジトリはオブザーバブルな型を使用してデータを公開するため、変更があればリーダーに通知されます。
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
この方法では、アプリは、ネットワーク データソースへの依存度が大幅に低下し、ネットワーク データソースがなくても長期間動作できます。この場合、ネットワーク データソースからの最新情報がローカルに存在すると想定されているため、オフライン時には読み取りと書き込みの両方のアクセスが提供されます。
push ベースの同期のメリットとデメリットを次の表にまとめています。
| メリット | デメリット |
|---|---|
| アプリは無期限にオフラインで使用できます。 | 競合を解決するためのデータのバージョニングは容易ではありません。 |
| データ使用量を最小限に抑えることができます。アプリは変更されたデータのみを取得します。 | 同期中は書き込みの問題を考慮する必要があります。 |
| リレーショナル データに適しています。各リポジトリは、サポートするモデルのデータの取得のみを行います。 | ネットワーク データソースは同期をサポートしている必要があります。 |
ハイブリッド同期
アプリによっては、データに応じて pull ベースまたは push ベースのハイブリッドな方法が使用されます。たとえば、ソーシャル メディア アプリは、フィードの更新頻度が高いため、pull ベースの同期を使用して、ユーザーのフォロー フィードをオンデマンドで取得する場合があります。同じアプリで push ベースの同期を使用して、ログインしているユーザーに関するデータ(ユーザー名、プロフィール写真など)を処理することもできます。
最終的には、オフラインファーストの同期に関する選択は、プロダクトの要件と利用可能な技術インフラストラクチャに応じて行うことになります。
競合解決
アプリがオフラインのときにローカルに書き込んだデータがネットワーク データソース内のデータと一致しない場合は、同期の前に競合を解決する必要があります。
競合を解決するには、バージョニングが必要になる場合がよくあります。アプリでは、変更が発生した時間を追跡するために、ブックキーピングを行う必要があります。これにより、メタデータをネットワーク データソースに渡すことができます。ネットワーク データソースには、絶対的な信頼できるソースを提供する責任があります。アプリのニーズに応じて、競合の解決のために検討すべきさまざまな手段があります。モバイルアプリの場合、一般的な方法は「最後の書き込み優先」です。
最後の書き込み優先
この方法では、デバイスは、ネットワークに書き込むデータにタイムスタンプ メタデータを追加します。これらのデータを受信すると、ネットワーク データソースは、現在の状態より古いデータをすべて破棄し、より新しいデータを受け入れます。
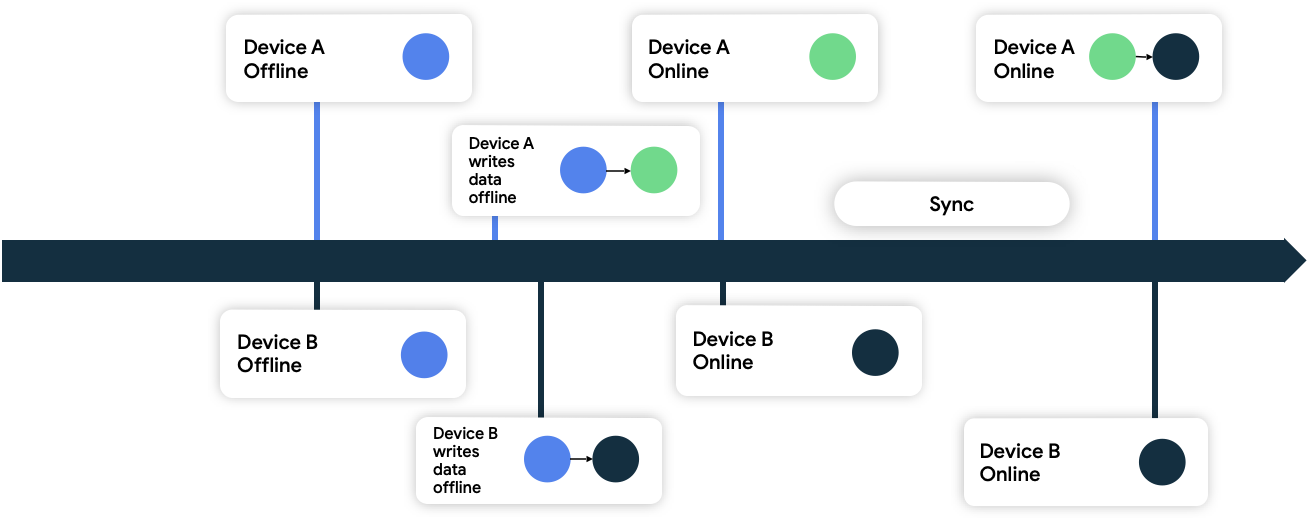
図 9 では、両方のデバイスがオフラインであり、最初はネットワーク データソースと同期しています。オフライン時は、どちらもデータをローカルに書き込み、データを書き込んだ時刻を追跡します。両方ともオンラインに戻ってネットワーク データソースと同期すると、ネットワークがデバイス B のデータを永続化することで競合を解決します。デバイス B が後からデータを書き込んだためです。
オフラインファースト アプリの WorkManager
上記の読み取り手段と書き込み手段のどちらにも、次の 2 つの一般的なユーティリティがあります。
- キュー
- 読み取り: ネットワーク接続が利用可能になるまで読み取りを延期するために使用されます。
- 書き込み: ネットワーク接続が利用可能になるまで書き込みを延期し、再試行のために書き込みを再度キューに追加するために使用します。
- ネットワーク接続モニター
- 読み取り: アプリが接続されているときに読み取りキューをドレインするための信号として使用され、同期にも使用されます。
- 書き込み: アプリが接続されているときに書き込みキューをドレインするための信号として使用され、同期にも使用されます。
いずれのケースも、WorkManager が優れている永続処理の例です。たとえば、Now in Android サンプルアプリでは、WorkManager がローカル データソースとの同期時に読み取りキューとネットワーク モニターの両方として使用されます。起動時に、アプリは次の処理を行います。
- 読み取り同期処理をキューに登録し、ローカル データソースとネットワーク データソースが同等であることを確認します。
- 読み取り同期キューをドレインし、アプリがオンラインになったときに同期を開始します。
- 指数バックオフを使用して、ネットワーク データソースからの読み取りを実行します。
- ローカル データソースに読み込みの結果を永続化し、発生する可能性がある競合を解決します。
- アプリの他のレイヤが使用できるように、ローカル データソースからのデータを公開します。
これらのアクションを次の図に示します。
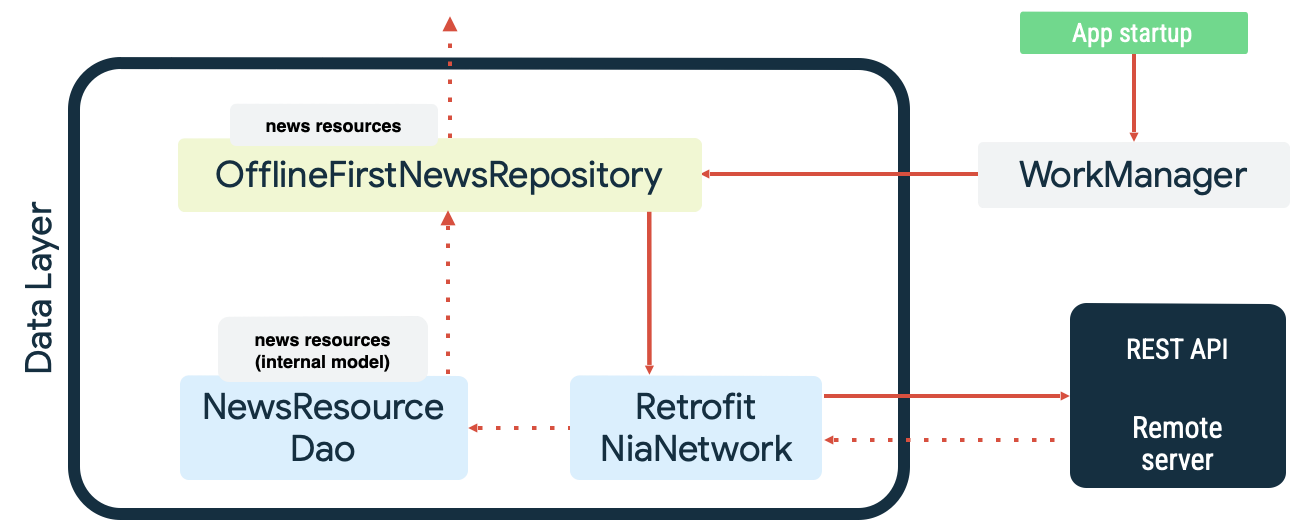
WorkManager を使用して同期処理をキューに登録するには、KEEP ExistingWorkPolicy を使用して同期処理を一意の処理として指定します。
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() は次のように定義されます。
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
具体的には、SyncConstraints で定義された Constraints では、NetworkType が NetworkType.CONNECTED である必要があります。つまり、ネットワークが使用可能になるまで待機してから実行されます。
ネットワークが使用可能になると、ワーカーは SyncWorkName で指定された一意の作業キューを適切な Repository インスタンスに委任してドレインします。同期が失敗した場合、doWork() メソッドは Result.retry() を返します。WorkManager は、指数バックオフを使用して同期を自動的に再試行します。同期が成功した場合は、Result.success() を返して同期を完了します。
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
サンプル
以下の Google サンプルは、オフラインファースト アプリを示しています。このガイダンスを実践するためにご利用ください。