
La visualizzazione delle tracce nel Profiler CPU offre diversi modi per visualizzare le informazioni delle tracce registrate.
Per le tracce del metodo e delle funzioni, puoi visualizzare il Grafico chiamate direttamente nella sequenza temporale Thread e nelle schede Grafico a fiamme, Top giù, In basso verso l'alto ed Eventi dal riquadro Analisi. Per i frame di calltack, puoi visualizzare la parte di codice che è stata eseguita e il motivo per cui è stata richiamata. Per le tracce di sistema, puoi visualizzare gli eventi di traccia direttamente nella sequenza temporale Thread, mentre le schede Grafico a fiamme, In alto in basso, Dal basso verso l'alto ed Eventi dal riquadro Analisi.
Per semplificare la navigazione nei grafici delle chiamate o negli eventi di traccia, sono disponibili le scorciatoie del mouse e della tastiera.
Ispeziona le tracce utilizzando il grafico chiamate
Il grafico chiamate fornisce una rappresentazione grafica della traccia di un metodo o di una funzione, in cui il periodo e la tempistica di una chiamata sono rappresentati sull'asse orizzontale e le chiamate sull'asse verticale. Le chiamate alle API di sistema sono visualizzate in arancione, le chiamate ai metodi dell'app sono mostrate in verde e le chiamate alle API di terze parti (incluse le API di linguaggio Java) sono mostrate in blu. La Figura 4 mostra un grafico delle chiamate di esempio e illustra il concetto di tempo personale, tempo dei figli e tempo totale per un determinato metodo o funzione. Puoi scoprire di più su questi concetti nella sezione su come controllare le tracce utilizzando l'opzione Dall'alto verso il basso e dal basso verso l'alto.
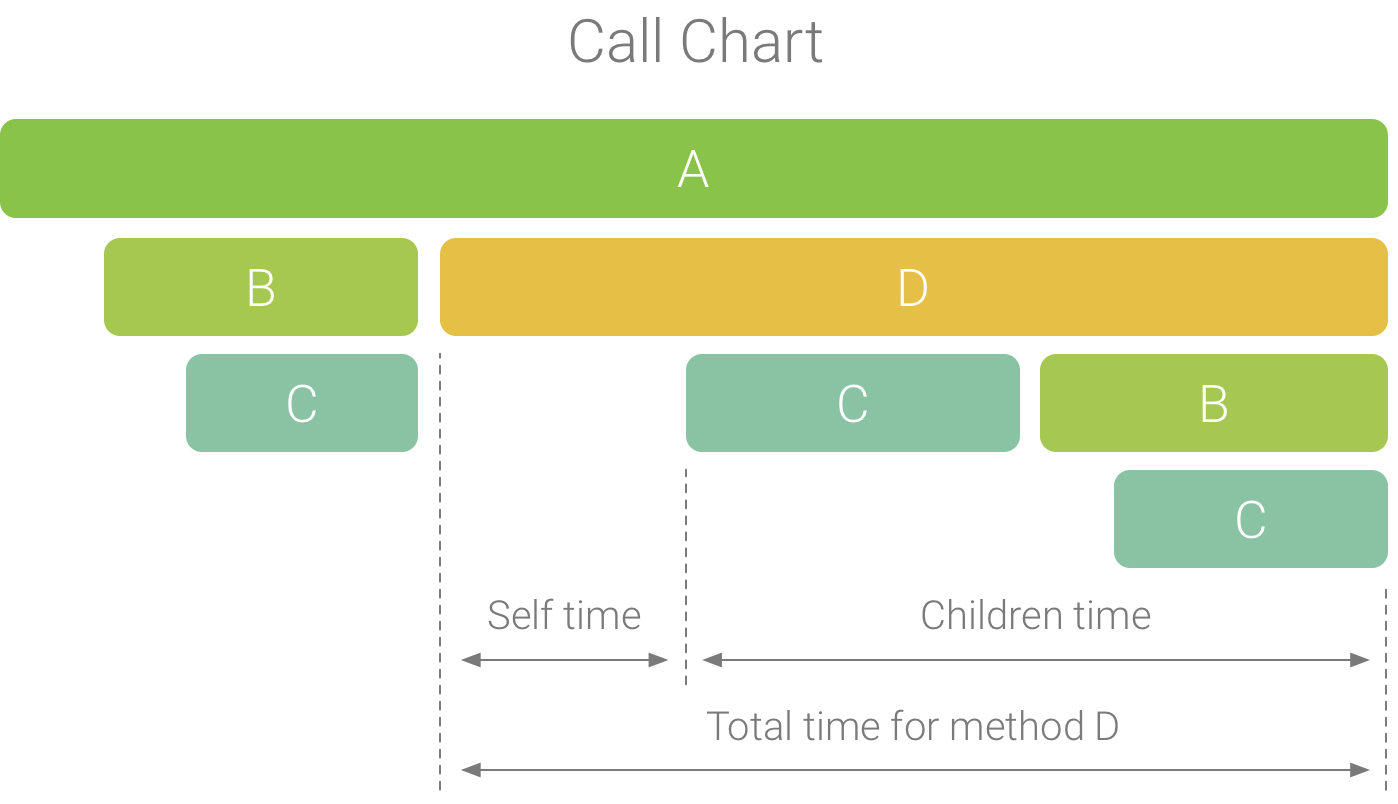
Figura 1. Un esempio di grafico delle chiamate che illustra sé stesso, i figli e il tempo totale per il metodo D.
Suggerimento: per saltare il codice sorgente di un metodo o di una funzione, fai clic con il tasto destro del mouse e seleziona Vai al codice sorgente. Questa operazione funziona da qualsiasi scheda del riquadro Analisi.
Ispeziona le tracce utilizzando la scheda Grafico a fiamme
La scheda Grafico a fiamme fornisce un grafico delle chiamate invertito che aggrega stack di chiamate identici. In altre parole, vengono raccolti metodi o funzioni identici che condividono la stessa sequenza di chiamanti e rappresentati come un'unica barra più lunga in un grafico a fiamme (invece di visualizzarli come più barre più corte, come mostrato in un grafico delle chiamate). In questo modo è più facile vedere quali metodi o funzioni utilizzano più tempo. Tuttavia, ciò significa anche che l'asse orizzontale non rappresenta una sequenza temporale, ma indica il tempo relativo impiegato da ogni metodo o funzione per essere eseguito.
Per illustrare questo concetto, considera il grafico delle chiamate nella Figura 2. Tieni presente che il metodo D effettua più chiamate a B (B1, B2 e B3) e alcune di queste chiamate a B effettuano una chiamata a C (C1 e C3).
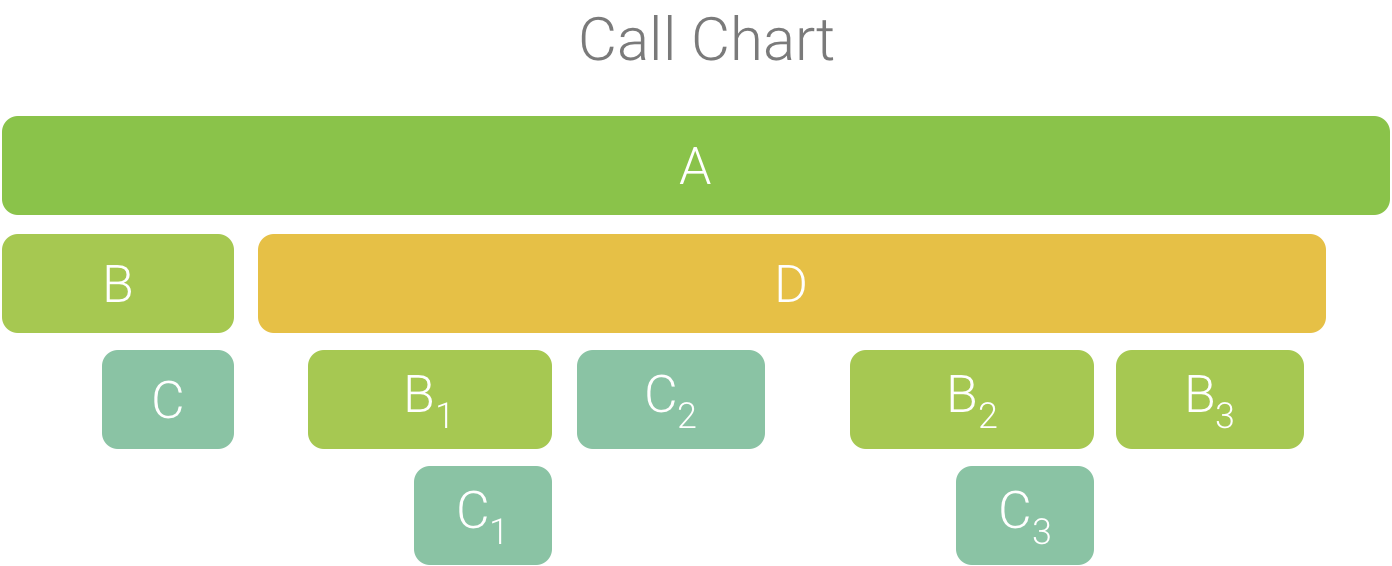
Figura 2. Un grafico delle chiamate con più chiamate di metodi che condividono una sequenza comune di chiamanti.
Poiché B1, B2 e B3 condividono la stessa sequenza di chiamanti (A → D → B), vengono aggregati, come mostrato nella Figura 3. Allo stesso modo, C1 e C3 vengono aggregati perché condividono la stessa sequenza di chiamanti (A → D → B → C). Tieni presente che C2 non è incluso perché ha una sequenza diversa di chiamanti (A → D → C).
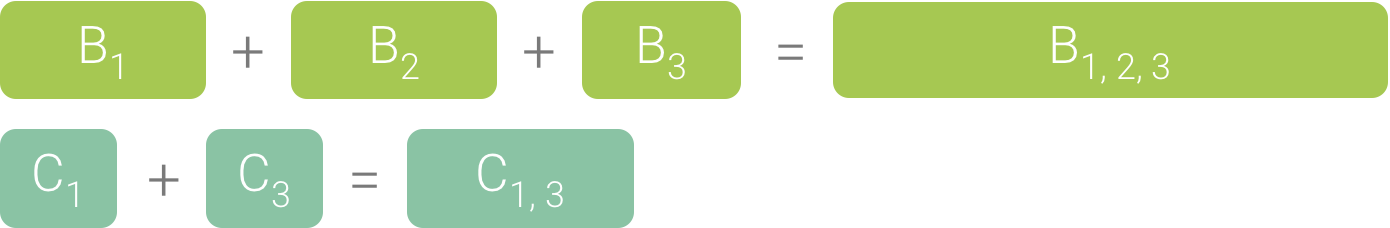
Figura 3. Aggregare metodi identici che condividono lo stesso stack di chiamate.
Le chiamate aggregate vengono utilizzate per creare il grafico a fiamme, come mostrato nella Figura 4. Tieni presente che, per ogni chiamata in un grafico a fiamme, vengono visualizzate per prime le chiamate che consumano più tempo di CPU.
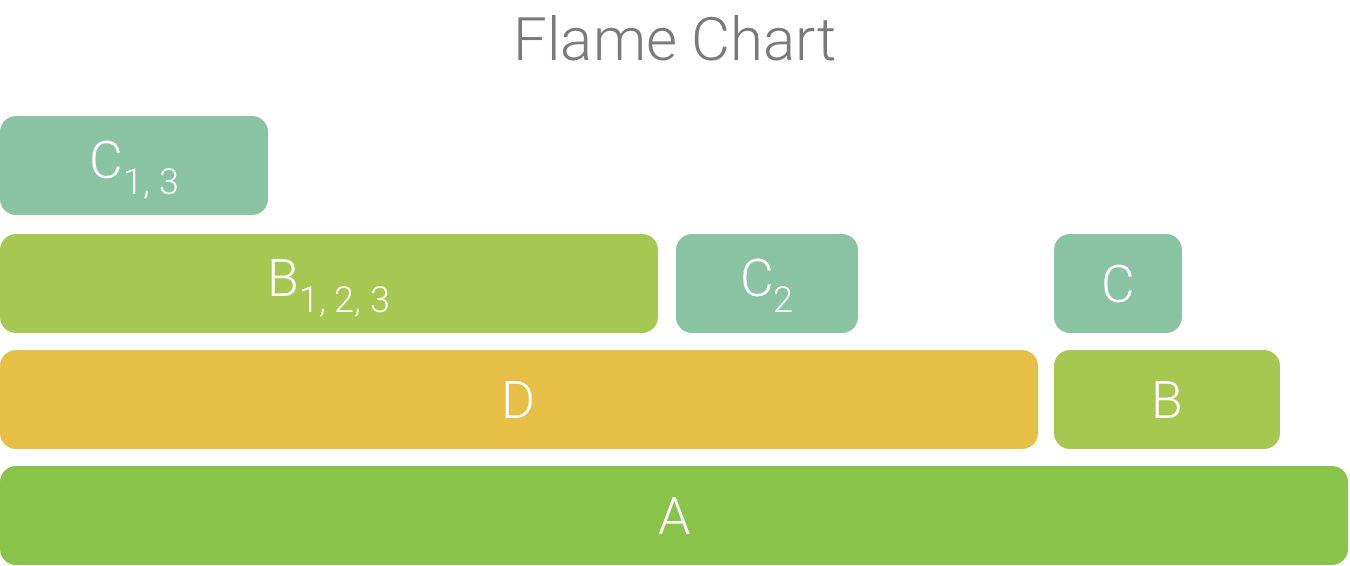
Figura 4. Rappresentazione del grafico a fiamme del grafico delle chiamate in Figura 5.
Ispeziona le tracce utilizzando dall'alto verso il basso e dal basso verso l'alto
La scheda Top-down mostra un elenco di chiamate in cui l'espansione di un nodo di metodo o funzione visualizza le relative chiamate. La Figura 5 mostra un grafico dall'alto verso il basso per il grafico delle chiamate nella Figura 1. Ogni freccia nel grafico punta da un chiamante a una persona chiamata.
Come mostrato nella Figura 5, l'espansione del nodo per il metodo A nella scheda Top Down mostra le chiamate, i metodi B e D. Dopodiché, l'espansione del nodo per il metodo D espone le chiamate, i metodi B e C e così via. Analogamente alla scheda Grafico a fiamme, la struttura ad albero dall'alto verso il basso aggrega informazioni di traccia relative a metodi identici che condividono lo stesso stack di chiamate. In altre parole, la scheda Grafico a fiamme fornisce una rappresentazione grafica della scheda dall'alto verso il basso.
La scheda Dall'alto verso il basso fornisce le seguenti informazioni per descrivere il tempo di CPU impiegato per ogni chiamata (le volte sono rappresentate anche come percentuale del tempo totale del thread nell'intervallo selezionato):
- Self: il tempo trascorso dal metodo o dalla chiamata di funzione nell'esecuzione del proprio codice e non di quello delle chiamate, come illustrato nella Figura 1 per il metodo D.
- Figli: il tempo trascorso dal metodo o dalla chiamata di funzione nell'esecuzione delle proprie chiamate e non il proprio codice, come illustrato nella Figura 1 per il metodo D.
- Totale: la somma del tempo di Auto e Figli del metodo. Questo rappresenta il tempo totale che l'app ha trascorso per eseguire una chiamata, come illustrato nella Figura 1 per il metodo D.
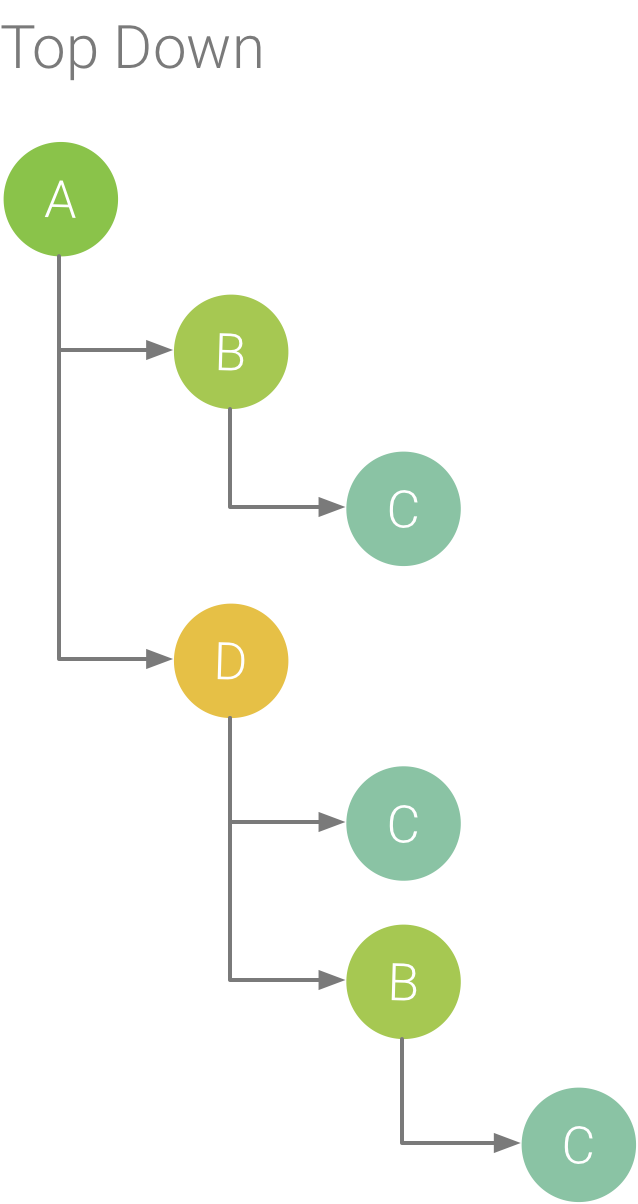
Figura 5. Un albero dall'alto verso il basso.
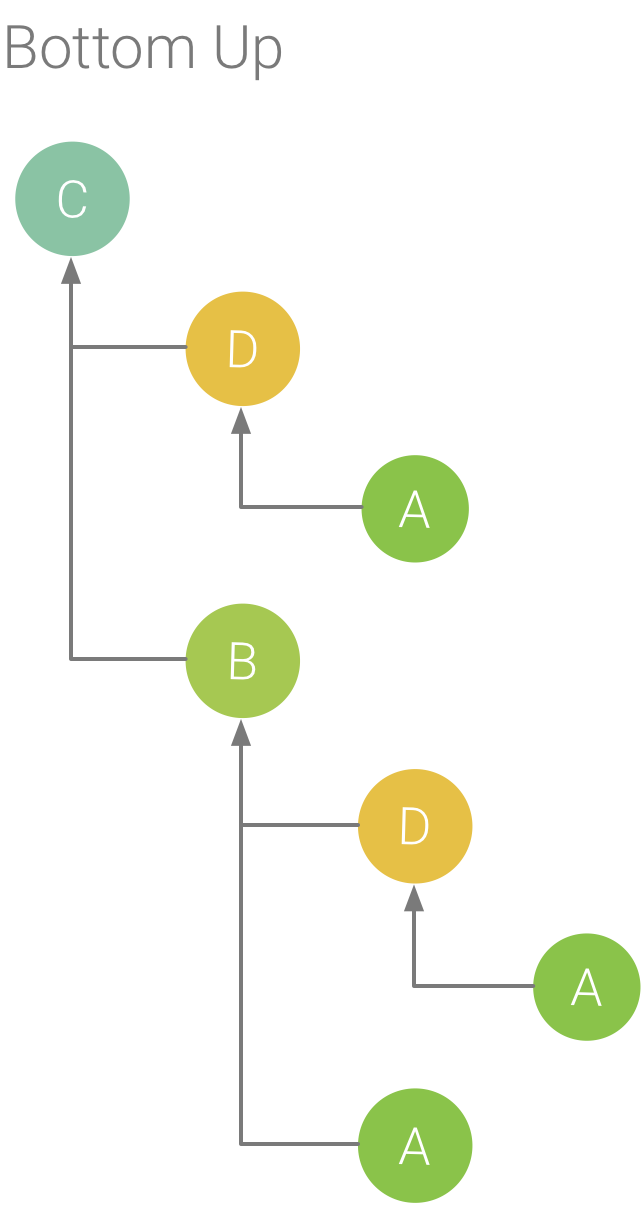
Figura 6. Un albero dal basso verso l'alto per il metodo C della Figura 5.
La scheda Bottom su mostra un elenco di chiamate in cui l'espansione del nodo di una funzione o di un metodo mostra i chiamanti. Usando la traccia di esempio mostrata nella Figura 5, la figura 6 fornisce una struttura ad albero dal basso verso l'alto per il metodo C. Se apri il nodo per il metodo C nell'albero inferiore verso l'alto, viene visualizzato ciascuno dei suoi chiamanti univoci, i metodi B e D. Tieni presente che, sebbene B chiami C due volte, B appare solo una volta quando espandi il nodo per il metodo C nell'albero inferiore. In seguito, l'espansione del nodo per B mostra il chiamante e i metodi A e D.
La scheda Dal basso verso l'alto è utile per ordinare metodi o funzioni in base a quelli che consumano la maggior parte (o meno) tempo di CPU. Puoi esaminare ciascun nodo per determinare quali chiamanti impiegano più tempo di CPU per richiamare questi metodi o funzioni. Rispetto all'albero top-down, le informazioni di temporizzazione per ogni metodo o funzione in un albero top-down fanno riferimento al metodo nella parte superiore di ogni albero (nodo superiore). Il tempo di CPU è anche rappresentato come percentuale del tempo totale del thread durante quella registrazione. La seguente tabella aiuta a spiegare come interpretare le informazioni di temporizzazione per il nodo superiore e i relativi chiamanti (sottonodi).
| Me stesso | Bambini | Totale | |
|---|---|---|---|
| Metodo o funzione nella parte superiore dell'albero in basso verso l'alto (nodo superiore) | Rappresenta il tempo totale trascorso dal metodo o dalla funzione per eseguire il proprio codice e non quello delle chiamate. Rispetto all'albero top-down, queste informazioni di temporizzazione rappresentano la somma di tutte le chiamate a questo metodo o funzione nel corso della durata della registrazione. | Rappresenta il tempo totale trascorso dal metodo o dalla funzione durante l'esecuzione delle chiamate e non il proprio codice. Rispetto all'albero top-down, queste informazioni di temporizzazione rappresentano la somma di tutte le chiamate a questo metodo o a quelle di funzione nel corso della durata della registrazione. | La somma del tempo dedicato a te e dei tuoi figli. |
| Chiamanti (sottonodi) | Rappresenta il tempo totale autonomo della chiamata quando il chiamante viene chiamato. Utilizzando come esempio l'albero dal basso verso l'alto nella Figura 6, il tempo autonomo per il metodo B equivarrà alla somma dei tempi self-service per ogni esecuzione del metodo C quando chiamato da B. | Rappresenta il tempo totale dei figli da parte del chiamante quando viene richiamato. Utilizzando come esempio l'albero dal basso verso l'alto nella Figura 6, il tempo dei figli per il metodo B corrisponde alla somma dei tempi figlio per ogni esecuzione del metodo C quando viene chiamato da B. | La somma del tempo dedicato a te e dei tuoi figli. |
Nota: per una determinata registrazione, Android Studio smette di raccogliere nuovi dati quando il profiler raggiunge il limite delle dimensioni del file (ma la registrazione non viene interrotta). In genere questo avviene molto più rapidamente quando si eseguono le tracce strumentali, perché questo tipo di tracciamento raccoglie più dati in un tempo più breve rispetto a una traccia campionata. Se estendi il tempo di ispezione in un periodo della registrazione che si è verificato dopo aver raggiunto il limite, i dati di temporizzazione nel riquadro di traccia non cambiano (perché non sono disponibili nuovi dati). Inoltre, il riquadro di traccia visualizza NaN per le informazioni di sincronizzazione quando selezioni solo la parte di una registrazione in cui non sono disponibili dati.
Ispeziona le tracce utilizzando la tabella Eventi
La tabella Eventi elenca tutte le chiamate nel thread attualmente selezionato. Per ordinarli, fai clic sulle intestazioni di colonna. Selezionando una riga nella tabella, puoi spostarti nella sequenza temporale fino all'ora di inizio e di fine della chiamata selezionata. Ciò ti consente di individuare con precisione gli eventi sulla sequenza temporale.
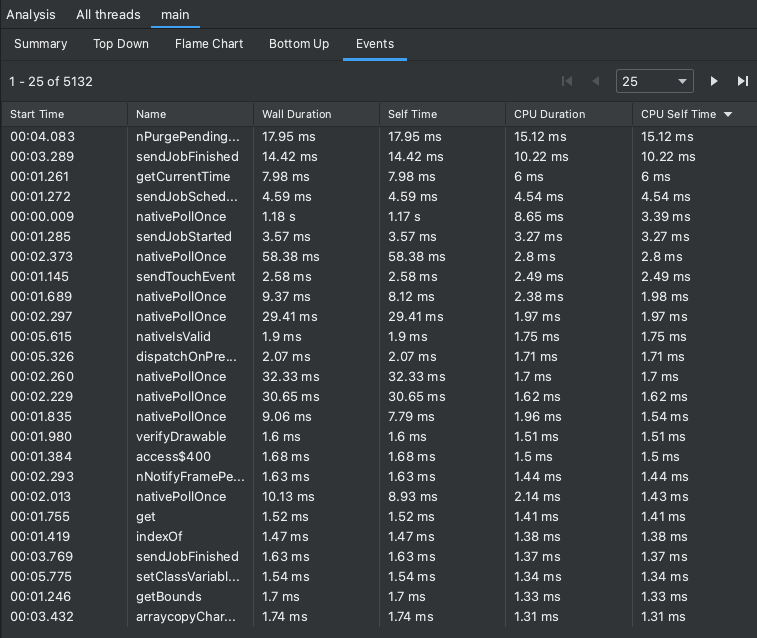
Figura 7. Visualizzazione della scheda Eventi nel riquadro Analisi.
Ispeziona frame sequenza di chiamate
Gli stack di chiamate sono utili per capire quale parte del codice è stata eseguita e perché è stata richiamata. Se una registrazione di esempio di Callstack viene raccolta per un programma Java/Kotlin, di solito il callback include non solo il codice Java/Kotlin, ma anche i frame del codice nativo JNI, della Java Virtual Machine (ad es.
android::AndroidRuntime::start) e il kernel di sistema ([kernel.kallsyms]+offset). Questo perché un programma Java/Kotlin solitamente viene eseguito tramite una macchina virtuale Java. Per eseguire il programma è necessario codice nativo
e consentire al programma di comunicare con il sistema e l'hardware. Profiler presenta questi frame per la massima precisione; tuttavia, a seconda dell'indagine, questi frame di chiamata aggiuntivi potrebbero non essere utili o meno. Profiler consente di comprimere i frame che non ti interessano in modo da poter nascondere le informazioni non pertinenti all'indagine.
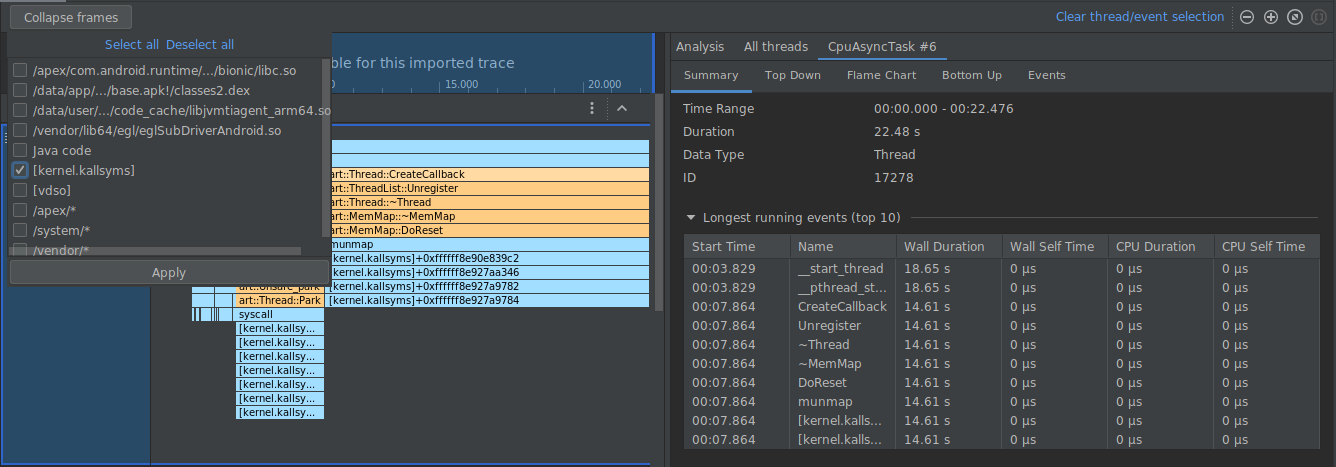
Nell'esempio seguente, la traccia seguente ha molti frame etichettati [kernel.kallsyms]+offset, che al momento non sono utili per lo sviluppo.
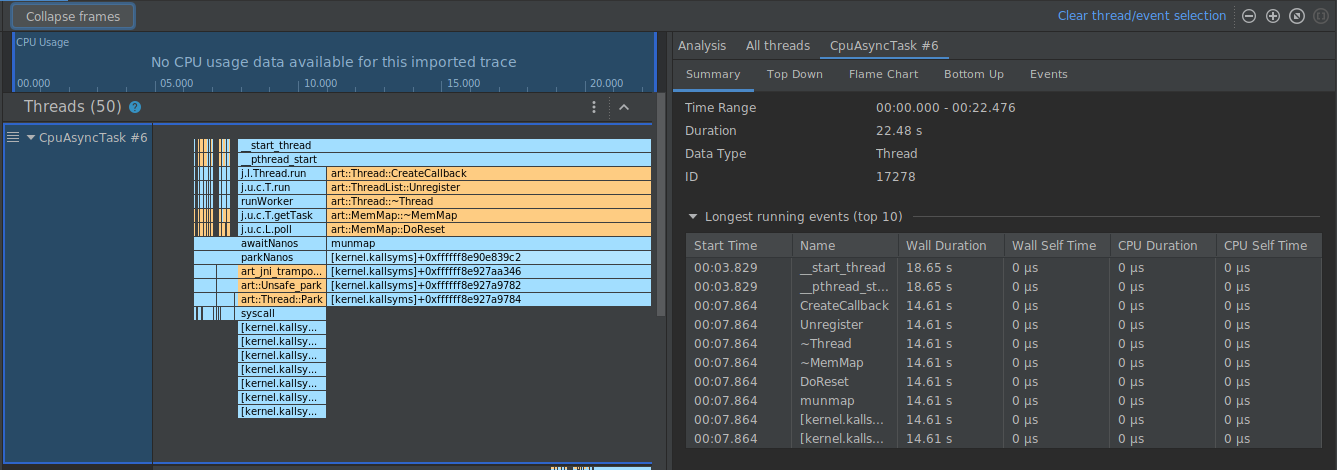
Per comprimere questi frame in uno solo, devi selezionare il pulsante Comprimi frame
dalla barra degli strumenti, scegliere i percorsi da comprimere e poi il pulsante Applica
per applicare le modifiche. In questo esempio, il percorso è [kernel.kallsyms].
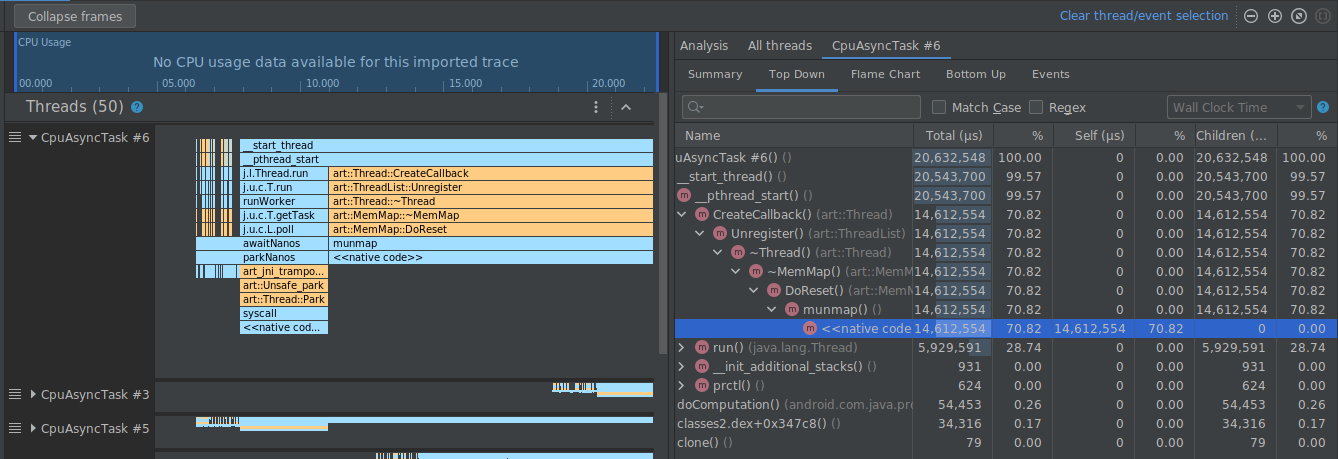
In questo modo, i frame corrispondenti al percorso selezionato vengono compressi nei riquadri sinistro e destro, come mostrato di seguito.
Ispeziona le tracce di sistema
Quando esamini una traccia di sistema, puoi esaminare Trace Events (Eventi di traccia) nella sequenza temporale Thread per visualizzare i dettagli degli eventi che si verificano in ogni thread. Passa il mouse sopra un evento per visualizzarne il nome e il tempo trascorso in ogni stato. Fai clic su un evento per visualizzare ulteriori informazioni nel riquadro Analisi.
Ispeziona tracce di sistema: core della CPU
Oltre ai dati di pianificazione della CPU, le tracce di sistema includono anche la frequenza della CPU per core. Mostra la quantità di attività su ciascun core e può darti un'idea di quali sono i "big" o i "piccoli" core nei moderni processori per dispositivi mobili.
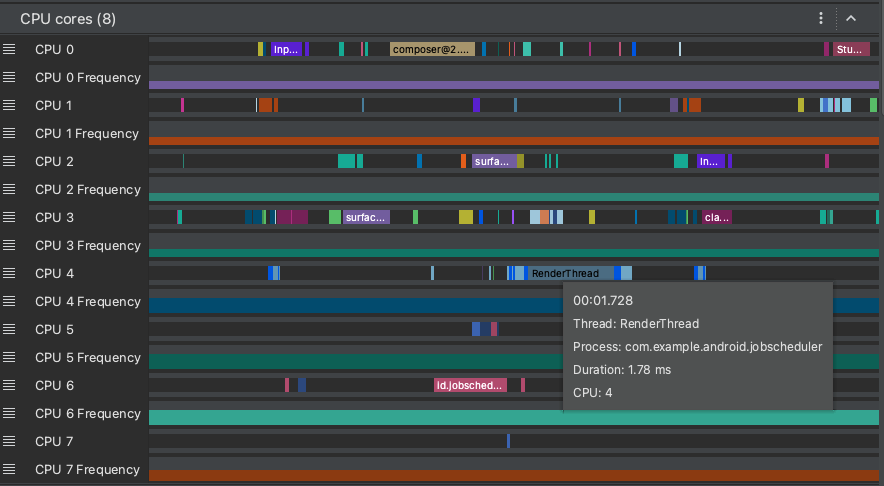
Figura 8. Visualizzazione dell'attività della CPU ed eventi di traccia per il thread di rendering.
Il riquadro Core CPU (come mostrato nella Figura 8) mostra l'attività thread pianificata su ogni core. Passa il puntatore del mouse sopra un'attività thread per vedere su quale thread è in esecuzione questo core in quel momento specifico.
Per ulteriori informazioni sull'ispezione delle informazioni sulla traccia del sistema, consulta la sezione Esaminare i problemi di prestazioni dell'interfaccia utente nella documentazione di systrace.
Ispeziona le tracce di sistema: sequenza temporale di rendering dei frame
Puoi controllare quanto tempo impiega la tua app per eseguire il rendering di ogni frame nel thread principale e RenderThread per esaminare i colli di bottiglia che causano il jank della UI e le basse frequenze dei frame. Per scoprire come utilizzare le tracce di sistema per esaminare e ridurre il jank dell'interfaccia utente, vedi Rilevamento dei jank dell'interfaccia utente.
Ispeziona tracce di sistema: memoria di processo (RSS)
Per le app distribuite su dispositivi con Android 9 o versioni successive, la sezione Memoria di processo (RSS) mostra la quantità di memoria fisica attualmente in uso dall'app.

Figura 9. È visualizzata la memoria fisica nel profiler.
Totale
Si tratta della quantità totale di memoria fisica attualmente in uso nel processo. Nei sistemi basati su Unix, questa metrica è nota come "Dimensione del set residente" ed è la combinazione di tutta la memoria utilizzata da allocazioni anonime, mappature di file e allocazioni di memoria condivisa.
Per gli sviluppatori Windows, le dimensioni del set residente sono analoghe alle dimensioni del set di lavoro.
Assegnata
Questo contatore tiene traccia della quantità di memoria fisica attualmente utilizzata dalle normali allocazioni di memoria del processo. Si tratta di allocazioni anonime (non supportate da un file specifico) e private (non condivise). Nella maggior parte delle
applicazioni, sono composte da allocazioni heap (con malloc o
new) e memoria dello stack. Se scambiate dalla memoria fisica, queste allocazioni vengono scritte nel file di scambio di sistema.
Mappature di file
Questo contatore tiene traccia della quantità di memoria fisica utilizzata dal processo per le mappature dei file, ovvero la memoria mappata dai file in un'area di memoria da parte del gestore della memoria.
Condiviso
Questo contatore tiene traccia della quantità di memoria fisica utilizzata per condividere la memoria tra il processo e altri processi nel sistema.