
Mentre il livello UI contiene lo stato e la logica dell'UI, il livello dati contiene dati dell'applicazione e logica di business. La logica di business è ciò che dà valore alla tua app. È costituita da regole aziendali reali che determinano come devono essere creati, archiviati e modificati i dati dell'applicazione.
Questa separazione delle responsabilità consente di utilizzare il livello dati su più schermate, condividere informazioni tra diverse parti dell'app e riprodurre la logica di business al di fuori della UI per i test delle unità. Per saperne di più sui vantaggi del data layer, consulta la pagina Panoramica dell'architettura.
Architettura del livello dati
Il livello dati è costituito da repository che possono contenere da zero a molte origini dati. Devi creare una classe repository per ogni tipo di dati gestiti nella tua app. Ad esempio, potresti creare una classe MoviesRepository per i dati relativi ai film o una classe PaymentsRepository per i dati relativi ai pagamenti.
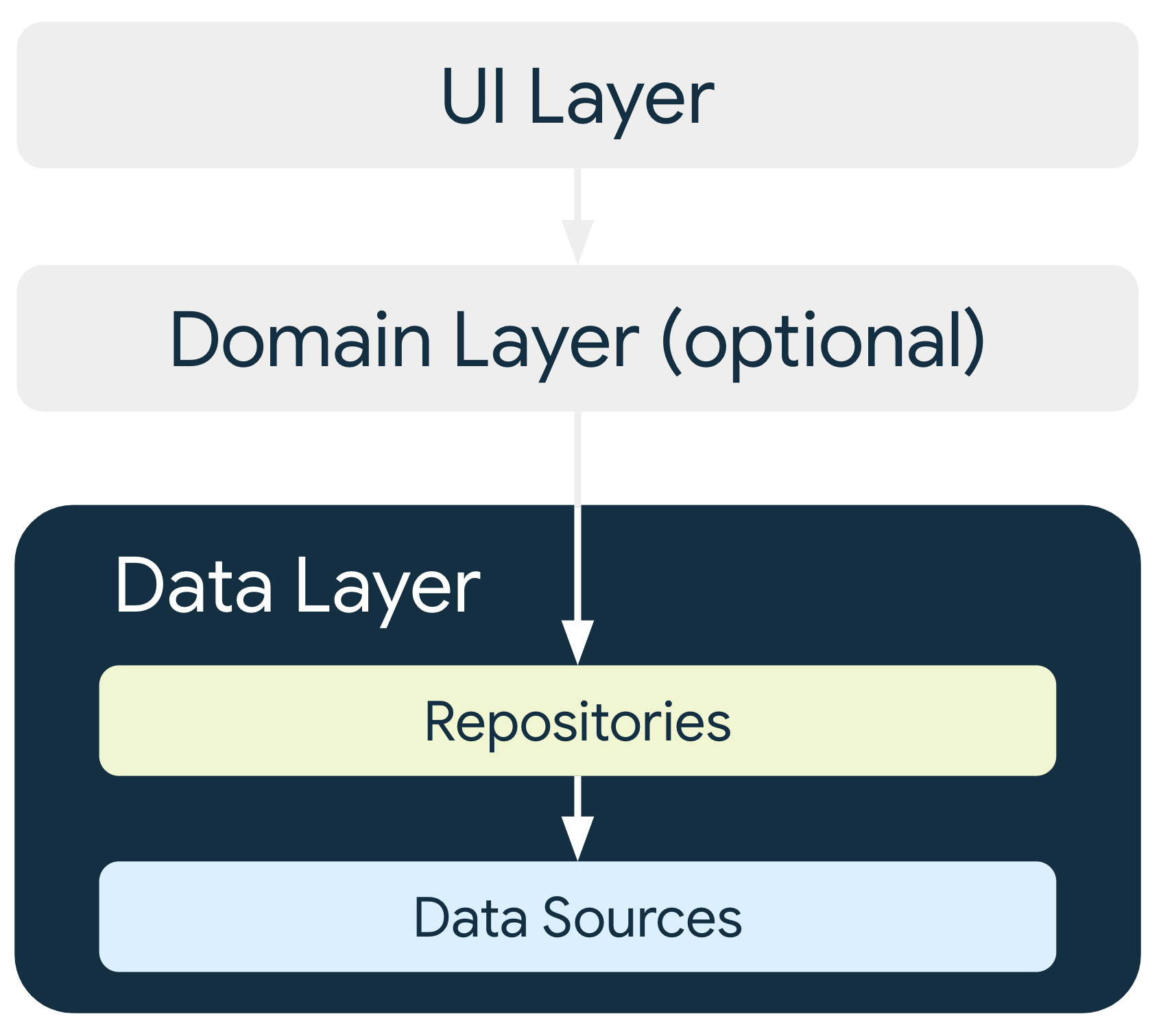
Le classi del repository sono responsabili delle seguenti attività:
- Esposizione dei dati al resto dell'app.
- Centralizzare le modifiche ai dati.
- Risoluzione dei conflitti tra più origini dati.
- Estrazione delle origini dati dal resto dell'app.
- Contenente la logica di business.
Ogni classe di origine dati deve essere responsabile della gestione di una sola origine dati, che può essere un file, un'origine di rete o un database locale. Le classi dell'origine dati sono il ponte tra l'applicazione e il sistema per le operazioni sui dati.
Gli altri livelli della gerarchia non devono mai accedere direttamente alle origini dati; i punti di accesso al livello dati sono sempre le classi del repository. Le classi contenitore di stato (consulta la guida al livello UI) o le classi di casi d'uso (consulta la guida al livello di dominio) non devono mai avere un'origine dati come dipendenza diretta. L'utilizzo delle classi del repository come punti di ingresso consente alle diverse architetture di scalare in modo indipendente.
I dati esposti da questo livello devono essere immutabili, in modo che non possano essere manomessi da altre classi, il che rischierebbe di mettere i suoi valori in uno stato incoerente. I dati immutabili possono essere gestiti in modo sicuro anche da più thread. Per ulteriori dettagli, consulta la sezione relativa all'organizzazione in thread.
Seguendo le best practice per l'iniezione delle dipendenze, il repository accetta le origini dati come dipendenze nel suo costruttore:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Esporre le API
Le classi nel data layer in genere espongono funzioni per eseguire chiamate di creazione, lettura, aggiornamento ed eliminazione (CRUD) una tantum o per ricevere notifiche delle modifiche ai dati nel tempo. Il data layer deve esporre quanto segue per ciascuno di questi casi:
- Per le operazioni una tantum, esponi le funzioni di sospensione.
- Per ricevere notifiche sulle modifiche ai dati nel tempo, mostra i flussi.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Convenzioni di denominazione in questa guida
In questa guida, le classi del repository prendono il nome dai dati di cui sono responsabili. La convenzione è la seguente:
tipo di dati + repository.
Ad esempio: NewsRepository, MoviesRepository o PaymentsRepository.
Le classi di origini dati prendono il nome dai dati di cui sono responsabili e dall'origine che utilizzano. La convenzione è la seguente:
tipo di dati + tipo di origine + DataSource.
Per il tipo di dati, utilizza Remoto o Locale per essere più generico perché
le implementazioni possono cambiare. Ad esempio, NewsRemoteDataSource o NewsLocalDataSource. Per essere più specifici nel caso in cui la sorgente sia importante, utilizza
il tipo di sorgente. Ad esempio, NewsNetworkDataSource o NewsDiskDataSource.
Non assegnare all'origine dati un nome basato su un dettaglio di implementazione, ad esempio
UserSharedPreferencesDataSource, perché i repository che utilizzano questa origine dati
non devono sapere come vengono salvati i dati. Se segui questa regola, puoi modificare l'implementazione dell'origine dati (ad esempio, eseguire la migrazione da SharedPreferences a DataStore) senza influire sul livello che chiama l'origine.
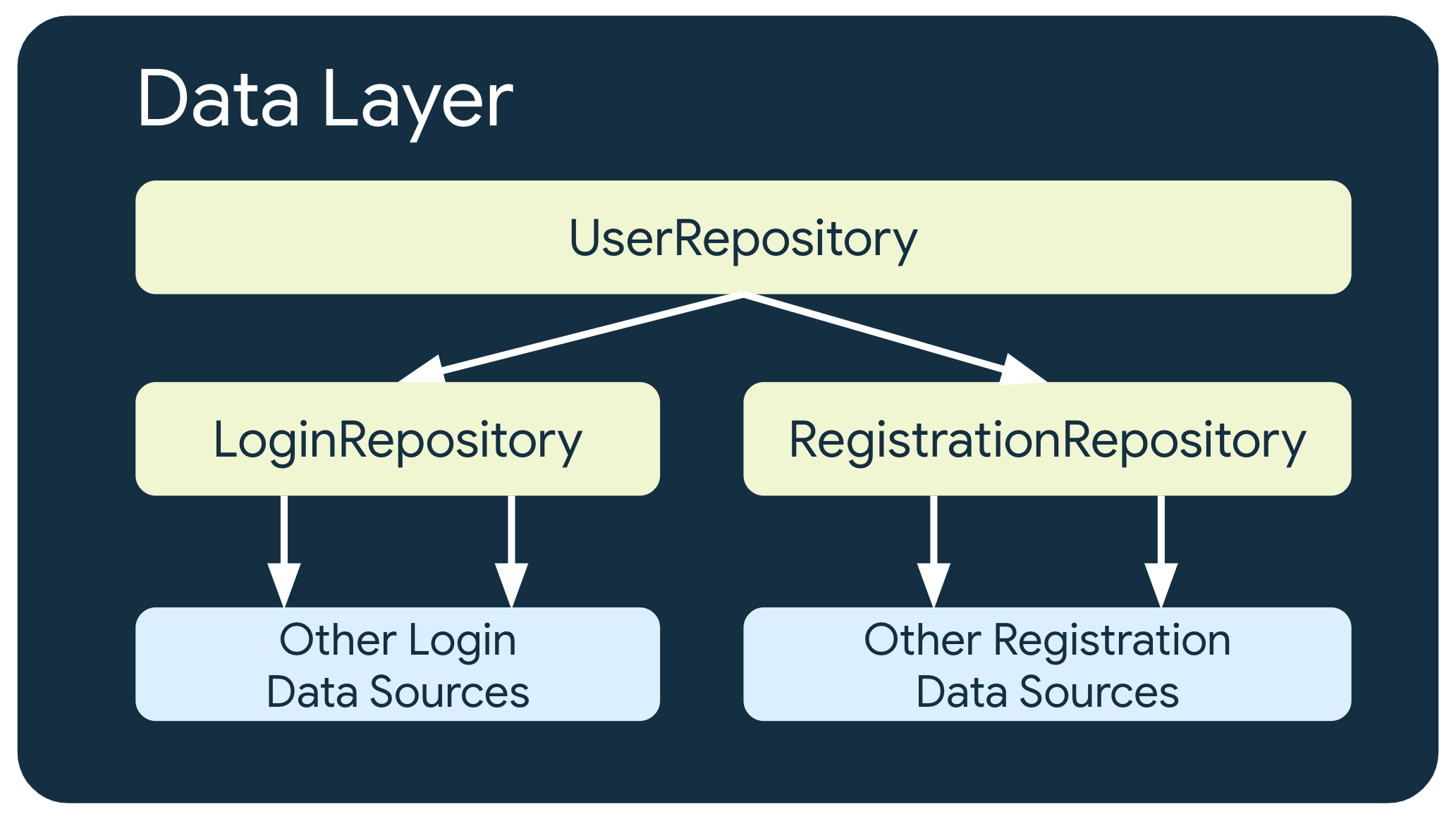
Più livelli di repository
In alcuni casi che riguardano requisiti aziendali più complessi, un repository potrebbe dover dipendere da altri repository. Ciò potrebbe essere dovuto al fatto che i dati coinvolti sono un'aggregazione di più origini dati o perché la responsabilità deve essere incapsulata in un'altra classe di repository.
Ad esempio, un repository che gestisce i dati di autenticazione utente,
UserRepository, potrebbe dipendere da altri repository come LoginRepository
e RegistrationRepository per soddisfare i suoi requisiti.
Fonte attendibile
È importante che ogni repository definisca un'unica fonte di riferimento. L'origine di riferimento contiene sempre dati coerenti, corretti e aggiornati. Infatti, i dati esposti dal repository devono sempre essere quelli provenienti direttamente dall'origine attendibile.
L'origine attendibile può essere un'origine dati, ad esempio il database, o anche una cache in memoria che il repository potrebbe contenere. I repository combinano diverse origini dati e risolvono eventuali conflitti tra le origini dati per aggiornare regolarmente l'unica fonte attendibile o a seguito di un evento di input dell'utente.
Repository diversi nella tua app potrebbero avere fonti di verità diverse. Ad esempio, la classe LoginRepository potrebbe utilizzare la cache come fonte attendibile e la classe PaymentsRepository potrebbe utilizzare l'origine dati di rete.
Per fornire assistenza offline, un'origine dati locale, ad esempio un database, è la fonte di riferimento consigliata.
Filettatura
Le origini e i repository di dati chiamati devono essere sicuri per il thread principale, ovvero sicuri da chiamare dal thread principale. Queste classi sono responsabili dello spostamento dell'esecuzione della loro logica nel thread appropriato durante l'esecuzione di operazioni di blocco a lunga esecuzione. Ad esempio, deve essere main-safe per un'origine dati leggere da un file o per un repository eseguire un filtraggio costoso su un elenco di grandi dimensioni.
Tieni presente che la maggior parte delle origini dati fornisce già API main-safe come le chiamate al metodo suspend fornite da Room, Retrofit o Ktor. Il tuo repository può sfruttare queste API quando sono disponibili.
Per saperne di più sui thread, consulta la guida all'elaborazione in background. Per gli utenti Kotlin, le coroutine sono l'opzione consigliata.
Ciclo di vita
Le istanze delle classi nel data layer rimangono in memoria finché sono raggiungibili da una radice di garbage collection, in genere facendo riferimento ad altri oggetti nella tua app.
Se una classe contiene dati in memoria, ad esempio una cache, potresti voler riutilizzare la stessa istanza della classe per un periodo di tempo specifico. Questo è anche chiamato ciclo di vita dell'istanza della classe.
Se la responsabilità della classe è fondamentale per l'intera applicazione, puoi
definire l'ambito di un'istanza di quella classe nella classe Application. In questo modo
l'istanza segue il ciclo di vita dell'applicazione. In alternativa, se devi riutilizzare la stessa istanza in un particolare flusso della tua app, ad esempio il flusso di registrazione o accesso, devi limitare l'ambito dell'istanza alla classe che possiede il ciclo di vita di quel flusso. Ad esempio, puoi definire l'ambito di un
RegistrationRepository che contiene dati in memoria per l'RegistrationActivity o per uno stack precedente utilizzando un NavEntryDecorator.
Il ciclo di vita di ogni istanza è un fattore fondamentale per decidere come fornire le dipendenze all'interno dell'app. Ti consigliamo di seguire le best practice per l'inserimento delle dipendenze, in cui le dipendenze vengono gestite e possono essere limitate ai contenitori delle dipendenze. Per scoprire di più sull'ambito in Android, consulta il post del blog Ambito in Android e Hilt.
Rappresentare i modelli di business
I modelli di dati che vuoi esporre dal data layer potrebbero essere un sottoinsieme delle informazioni che ottieni dalle diverse origini dati. Idealmente, le diverse origini dati, sia di rete che locali, dovrebbero restituire solo le informazioni necessarie all'applicazione, ma spesso non è così.
Ad esempio, immagina un server API News che restituisce non solo le informazioni sull'articolo, ma anche la cronologia delle modifiche, i commenti degli utenti e alcuni metadati:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
L'app non ha bisogno di molte informazioni sull'articolo perché mostra solo il contenuto dell'articolo sullo schermo, insieme a informazioni di base sull'autore. È buona norma separare le classi di modelli e fare in modo che i repository espongano solo i dati richiesti dagli altri livelli della gerarchia. Ad esempio, ecco come potresti ridurre ArticleApiModel dalla rete per esporre una classe di modello Article ai livelli di dominio e UI:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
La separazione delle classi di modelli è vantaggiosa nei seguenti modi:
- Conserva la memoria dell'app riducendo i dati solo a quelli necessari.
- Adatta i tipi di dati esterni ai tipi di dati utilizzati dalla tua app. Ad esempio, la tua app potrebbe utilizzare un tipo di dati diverso per rappresentare le date.
- Offre una migliore separazione delle competenze. Ad esempio, i membri di un team di grandi dimensioni potrebbero lavorare individualmente sui livelli di rete e UI di una funzionalità se la classe del modello è definita in anticipo.
Puoi estendere questa pratica e definire classi di modelli separate anche in altre parti dell'architettura dell'app, ad esempio nelle classi di origine dati e nei ViewModel. Tuttavia, ciò richiede di definire classi e logica aggiuntive che devi documentare e testare correttamente. Ti consigliamo di creare nuovi modelli almeno ogni volta che un'origine dati riceve dati che non corrispondono a quelli previsti dal resto dell'app.
Tipi di operazioni sui dati
Il data layer può gestire tipi di operazioni che variano in base alla loro criticità: operazioni orientate all'interfaccia utente, all'app e all'attività.
Operazioni orientate alla UI
Le operazioni orientate all'interfaccia utente sono pertinenti solo quando l'utente si trova su una schermata specifica e vengono annullate quando l'utente esce da quella schermata. Un esempio è la visualizzazione di alcuni dati ottenuti dal database.
Le operazioni orientate alla UI vengono in genere attivate dal livello UI e seguono il ciclo di vita del chiamante, ad esempio il ciclo di vita del ViewModel. Consulta la sezione Eseguire una richiesta di rete per un esempio di operazione orientata alla UI.
Operazioni orientate alle app
Le operazioni orientate alle app sono pertinenti finché l'app è aperta. Se l'app viene chiusa o il processo viene interrotto, queste operazioni vengono annullate. Un esempio è la memorizzazione nella cache del risultato di una richiesta di rete in modo che possa essere utilizzato in un secondo momento, se necessario. Per saperne di più, consulta la sezione Implementare la memorizzazione nella cache dei dati in memoria.
Queste operazioni in genere seguono il ciclo di vita della classe Application o
del livello dati. Per un esempio, consulta la sezione Prolungare la durata di un'operazione oltre la durata dello schermo.
Operazioni orientate all'attività
Le operazioni orientate all'attività non possono essere annullate. Devono sopravvivere alla chiusura del processo. Un esempio è il completamento del caricamento di una foto che l'utente vuole pubblicare sul suo profilo.
Per le operazioni orientate al business, ti consigliamo di utilizzare WorkManager. Per saperne di più, consulta la sezione Pianificare le attività utilizzando WorkManager.
Mostrare gli errori
Le interazioni con i repository e le origini dati possono riuscire o generare
un'eccezione quando si verifica un errore. Per le coroutine e i flussi, devi utilizzare il meccanismo di gestione degli errori integrato di Kotlin. Per gli errori che potrebbero essere
attivati dalle funzioni di sospensione, utilizza i blocchi try/catch quando appropriato; e nei
flussi, utilizza l'operatore catch. Con questo approccio, il livello UI
deve gestire le eccezioni quando chiama il livello dati.
Il data layer può comprendere e gestire diversi tipi di errori ed esporli
utilizzando eccezioni personalizzate, ad esempio un UserNotAuthenticatedException.
Per saperne di più sugli errori nelle coroutine, consulta il post del blog Eccezioni nelle coroutine.
Attività comuni
Le sezioni seguenti presentano esempi di come utilizzare e progettare il livello dati per eseguire determinate attività comuni nelle app per Android. Gli esempi si basano sulla tipica app di notizie menzionata in precedenza nella guida.
Inviare una richiesta di rete
L'invio di una richiesta di rete è una delle attività più comuni che un'app per Android potrebbe
eseguire. L'app News deve presentare all'utente le ultime notizie recuperate dalla rete. Pertanto, l'app ha bisogno di una classe di origine dati per gestire
le operazioni di rete: NewsRemoteDataSource. Per esporre le informazioni al
resto dell'app, viene creato un nuovo repository che gestisce le operazioni sui dati delle notizie: NewsRepository.
Il requisito è che le ultime notizie devono essere sempre aggiornate quando l'utente apre la schermata. Pertanto, si tratta di un'operazione orientata alla UI.
Crea l'origine dati
L'origine dati deve esporre una funzione che restituisce le ultime notizie: un elenco
di istanze ArticleHeadline. L'origine dati deve fornire un modo sicuro per i bambini
per ottenere le ultime notizie dal network. Per farlo, deve dipendere da CoroutineDispatcher o Executor per eseguire l'attività.
L'invio di una richiesta di rete è una chiamata one-shot gestita da un nuovo metodo fetchLatestNews():
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
L'interfaccia NewsApi nasconde l'implementazione del client API di rete; non fa differenza se l'interfaccia è supportata da Retrofit o HttpURLConnection. L'utilizzo delle interfacce rende le implementazioni dell'API
intercambiabili nella tua app.
Crea il repository
Poiché per questa attività non è necessaria alcuna logica aggiuntiva nella classe del repository,
NewsRepository funge da proxy per l'origine dati di rete. I vantaggi dell'aggiunta di questo livello di astrazione extra sono spiegati nella sezione Memorizzazione nella cache in memoria.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Per scoprire come utilizzare la classe del repository direttamente dal livello UI, consulta la guida al livello UI.
Implementa la memorizzazione nella cache dei dati in memoria
Supponiamo che venga introdotto un nuovo requisito per l'app News: quando l'utente apre la schermata, le notizie memorizzate nella cache devono essere presentate all'utente se è stata effettuata una richiesta in precedenza. In caso contrario, l'app deve effettuare una richiesta di rete per recuperare le ultime notizie.
In base al nuovo requisito, l'app deve conservare in memoria le ultime notizie mentre l'utente ha l'app aperta. Pertanto, si tratta di un'operazione orientata alle app.
Cache
Puoi conservare i dati mentre l'utente si trova nella tua app aggiungendo la memorizzazione nella cache dei dati in memoria. Le cache sono pensate per salvare alcune informazioni in memoria per un periodo di tempo specifico, in questo caso, finché l'utente rimane nell'app. Le implementazioni della cache possono assumere forme diverse. Possono variare da semplici variabili mutabili a classi più sofisticate che proteggono dalle operazioni di lettura/scrittura su più thread. A seconda del caso d'uso, la memorizzazione nella cache può essere implementata nel repository o nelle classi di origini dati.
Memorizza nella cache il risultato della richiesta di rete
Per semplicità, NewsRepository utilizza una variabile modificabile per memorizzare nella cache le ultime
notizie. Per proteggere le letture e le scritture da thread diversi, viene utilizzato un Mutex. Per scoprire di più sullo stato mutabile condiviso e sulla concorrenza, consulta la documentazione di
Kotlin.
La seguente implementazione memorizza nella cache le informazioni sulle ultime notizie in una variabile del repository protetta da scrittura con un Mutex. Se la richiesta di rete ha esito positivo, i dati vengono assegnati alla variabile latestNews.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Far durare un'operazione più a lungo dello schermo
Se l'utente esce dalla schermata mentre la richiesta di rete è in
corso, verrà annullata e il risultato non verrà memorizzato nella cache. NewsRepository
non deve utilizzare il CoroutineScope del chiamante per eseguire questa logica. NewsRepository deve invece utilizzare un CoroutineScope collegato al suo ciclo di vita.
Il recupero delle ultime notizie deve essere un'operazione orientata alle app.
Per seguire le best practice per l'inserimento delle dipendenze, NewsRepository deve ricevere un
ambito come parametro nel suo costruttore anziché creare il proprio
CoroutineScope. Poiché i repository devono svolgere la maggior parte del lavoro nei
thread in background, devi configurare CoroutineScope con Dispatchers.Default o con il tuo pool di thread.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Poiché NewsRepository è pronto per eseguire operazioni orientate alle app con
CoroutineScope esterno, deve eseguire la chiamata all'origine dati e salvare
il risultato con una nuova coroutine avviata da questo ambito:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async viene utilizzato per avviare la coroutine nell'ambito esterno. await viene chiamato
nella nuova coroutine per sospendere l'esecuzione finché non viene restituita la richiesta di rete e il
risultato viene salvato nella cache. Se a quel punto l'utente è ancora sullo schermo,
vedrà le ultime notizie; se l'utente si allontana dallo schermo,
await viene annullato, ma la logica all'interno di async continua a essere eseguita.
Scopri di più sui pattern per CoroutineScope.
Salva e recupera i dati dal disco
Supponiamo che tu voglia salvare dati come notizie aggiunte ai preferiti e preferenze dell'utente. Questo tipo di dati deve sopravvivere all'interruzione del processo ed essere accessibile anche se l'utente non è connesso alla rete.
Se i dati con cui stai lavorando devono sopravvivere all'interruzione del processo, devi memorizzarli su disco in uno dei seguenti modi:
- Per set di dati di grandi dimensioni che devono essere interrogati, richiedono l'integrità referenziale o richiedono aggiornamenti parziali, salva i dati in un database Room. Nell'esempio dell'app News, gli articoli di notizie o gli autori potrebbero essere salvati nel database.
- Per i set di dati di piccole dimensioni che devono solo essere recuperati e impostati (non sottoposti a query o aggiornati parzialmente), utilizza DataStore. Nell'esempio dell'app News, il formato della data preferito dall'utente o altre preferenze di visualizzazione potrebbero essere salvate in DataStore.
- Per blocchi di dati come un oggetto JSON, utilizza un file.
Come indicato nella sezione Origine attendibile, ogni origine dati funziona con
una sola origine e corrisponde a un tipo di dati specifico (ad esempio News,
Authors, NewsAndAuthors o UserPreferences). Le classi che utilizzano l'origine dati non devono sapere come vengono salvati i dati, ad esempio in un database o in un file.
Stanza come origine dati
Poiché ogni origine dati deve avere la responsabilità di interagire con una sola origine per un tipo specifico di dati, un'origine dati Room riceverebbe un Data Access Object (DAO) o il database stesso come parametro. Ad esempio, NewsLocalDataSource potrebbe utilizzare un'istanza di NewsDao come
parametro e AuthorsLocalDataSource potrebbe utilizzare un'istanza di AuthorsDao.
In alcuni casi, se non è necessaria una logica aggiuntiva, puoi inserire direttamente il DAO nel repository, perché il DAO è un'interfaccia che puoi sostituire facilmente nei test.
Per saperne di più sull'utilizzo delle API Room, consulta le guide di Room.
DataStore come origine dati
DataStore è perfetto per memorizzare coppie chiave-valore come le impostazioni utente. Gli esempi potrebbero includere il formato dell'ora, le preferenze di notifica e se mostrare o nascondere le notizie dopo che l'utente le ha lette. DataStore può anche archiviare oggetti digitati con protocol buffer.
Come per qualsiasi altro oggetto, un'origine dati supportata da DataStore deve contenere dati corrispondenti a un determinato tipo o a una determinata parte dell'app. Questo è ancora più vero con DataStore, perché le letture di DataStore vengono esposte come flusso che viene emesso ogni volta che un valore viene aggiornato. Per questo motivo, devi memorizzare le preferenze correlate nello stesso DataStore.
Ad esempio, potresti avere un NotificationsDataStore che gestisce solo le preferenze relative alle notifiche e un NewsPreferencesDataStore che gestisce solo le preferenze relative alla schermata delle notizie. In questo modo, puoi definire meglio l'ambito
degli aggiornamenti, perché il flusso newsScreenPreferencesDataStore.data viene emesso solo
quando viene modificata una preferenza relativa a quella schermata. Significa anche che
il ciclo di vita dell'oggetto può essere più breve perché può esistere solo per il periodo di tempo in cui
viene visualizzata la schermata delle notizie.
Per scoprire di più sull'utilizzo delle API DataStore, consulta le guide di DataStore.
Un file come origine dati
Quando lavori con oggetti di grandi dimensioni come un oggetto JSON o una bitmap, devi
lavorare con un oggetto File e gestire il cambio di thread.
Per saperne di più sull'utilizzo dell'archiviazione di file, consulta la pagina Panoramica dell'archiviazione.
Pianificare attività utilizzando WorkManager
Supponiamo che venga introdotto un altro nuovo requisito per l'app News: l'app deve dare all'utente la possibilità di recuperare le ultime notizie regolarmente e automaticamente finché il dispositivo è in carica e connesso a una rete non a consumo. Ciò rende questa operazione orientata al business. Questo requisito fa sì che, anche se il dispositivo non ha connettività quando l'utente apre l'app, l'utente possa comunque vedere le notizie recenti.
WorkManager semplifica la pianificazione di attività asincrone e affidabili e
può occuparsi della gestione dei vincoli. È la libreria consigliata per
il lavoro persistente. Per eseguire l'attività definita sopra, viene creata una classe Worker: RefreshLatestNewsWorker. Questa classe utilizza NewsRepository come
dipendenza per recuperare le ultime notizie e memorizzarle nella cache sul disco.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
La logica di business per questo tipo di attività deve essere incapsulata nella propria classe e trattata come un'origine dati separata. WorkManager sarà quindi responsabile solo di garantire che il lavoro venga eseguito su un thread in background quando tutti i vincoli sono soddisfatti. Se rispetti questo pattern, puoi scambiare rapidamente le implementazioni su ambienti diversi in base alle necessità.
In questo esempio, questa attività correlata alle notizie deve essere chiamata da NewsRepository,
che accetta una nuova origine dati come dipendenza, NewsTasksDataSource,
implementata come segue:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Questi tipi di classi prendono il nome dai dati di cui sono responsabili, ad esempio NewsTasksDataSource o PaymentsTasksDataSource. Tutte le attività correlate
a un particolare tipo di dati devono essere incapsulate nella stessa classe.
Se l'attività deve essere attivata all'avvio dell'app, è consigliabile attivare
la richiesta WorkManager utilizzando la libreria Avvio app che chiama il
repository da un Initializer.
Per saperne di più sull'utilizzo delle API WorkManager, consulta le guide di WorkManager.
Test
Le best practice per l'iniezione delle dipendenze sono utili per testare l'app. È anche utile fare affidamento sulle interfacce per le classi che comunicano con risorse esterne. Quando testi un'unità, puoi inserire versioni false delle sue dipendenze per rendere il test deterministico e affidabile.
Test delle unità
Quando testi il data layer, si applicano le linee guida generali per i test. Per i test unitari, utilizza oggetti reali quando necessario e simula le dipendenze che raggiungono origini esterne, ad esempio la lettura da un file o dalla rete.
Test di integrazione
I test di integrazione che accedono a fonti esterne tendono a essere meno deterministici perché devono essere eseguiti su un dispositivo reale. Ti consigliamo di eseguire questi test in un ambiente controllato per renderli più affidabili.
Per i database, Room consente di creare un database in memoria che puoi controllare completamente nei test. Per scoprire di più, consulta la pagina Testare ed eseguire il debug del database.
Per il networking, esistono librerie popolari come WireMock o MockWebServer che consentono di simulare chiamate HTTP e HTTPS e verificare che le richieste siano state effettuate come previsto.
Risorse aggiuntive
Esempi
- Jetcaster
- Modello iniziale di architettura (multimodulo)
- Architettura
- Modello iniziale di architettura (modulo singolo)
- Now in Android
Consigliati per te
- Nota: il testo del link viene visualizzato quando JavaScript è disattivato
- Livello di dominio
- Creare un'app offline-first
- Produzione stato UI