
Nelle coroutine, un flusso è un tipo che può emettere più valori in sequenza, a differenza delle funzioni di sospensione che restituiscono solo un singolo valore. Ad esempio, puoi utilizzare un flusso per ricevere aggiornamenti in tempo reale da un database.
I flussi si basano sulle coroutine e possono fornire più valori.
Un flusso è concettualmente uno stream di dati che può essere calcolato
in modo asincrono. I valori emessi devono essere dello stesso tipo. Ad
esempio, un Flow<Int> è un flusso che emette valori interi.
Un flusso è molto simile a un Iterator che produce una sequenza di valori, ma utilizza funzioni di sospensione per produrre e consumare valori in modo asincrono. Ciò significa, ad esempio, che il flusso può effettuare in sicurezza una
richiesta di rete per produrre il valore successivo senza bloccare il thread
principale.
Sono coinvolte tre entità nei flussi di dati:
- Un produttore produce dati che vengono aggiunti allo stream. Grazie alle coroutine, i flussi possono anche produrre dati in modo asincrono.
- (Facoltativo) Gli intermediari possono modificare ogni valore emesso nel flusso o il flusso stesso.
- Un consumer utilizza i valori del flusso.
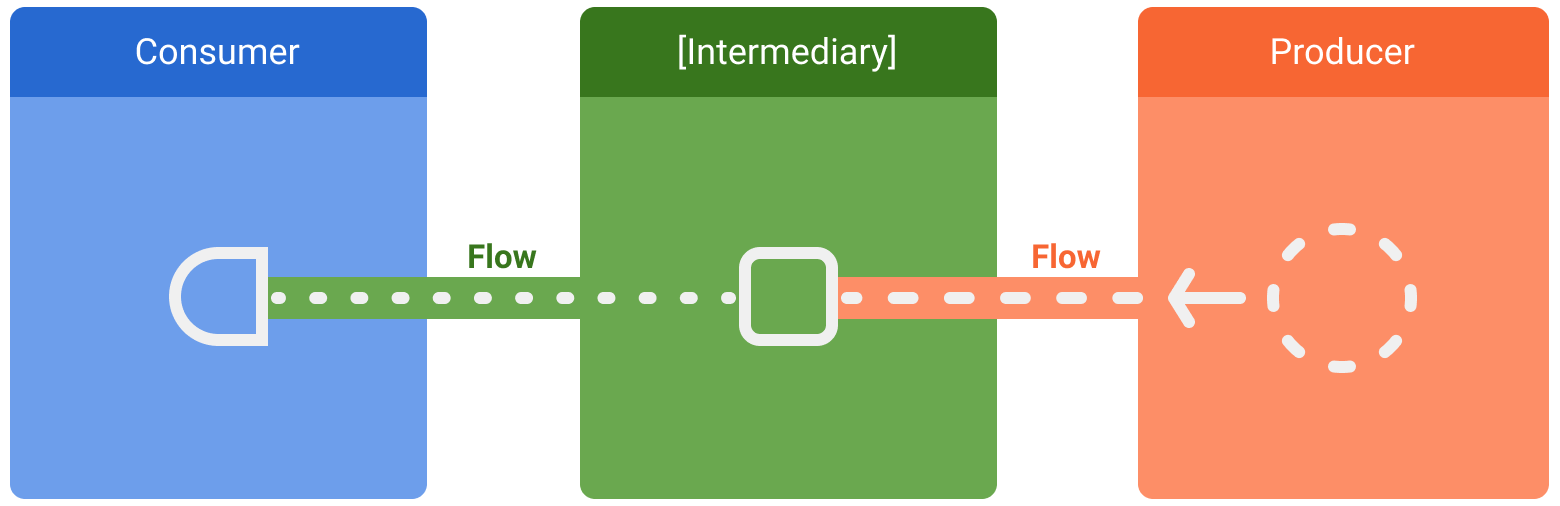
In Android, un repository è in genere un produttore di dati della UI che ha l'interfaccia utente (UI) come consumatore che alla fine visualizza i dati. Altre volte, il livello UI è un produttore di eventi di input dell'utente e altri livelli della gerarchia li utilizzano. I livelli intermedi tra il produttore e il consumatore fungono in genere da intermediari che modificano il flusso di dati per adattarlo ai requisiti del livello successivo.
Creare un flusso
Per creare flussi, utilizza le API Flow Builder. La funzione di creazione flow crea un nuovo flusso in cui puoi emettere manualmente nuovi valori nel flusso di dati utilizzando la funzione emit.
Nell'esempio seguente, un'origine dati recupera automaticamente le ultime notizie a un intervallo fisso. Poiché una funzione di sospensione non può restituire più valori consecutivi, l'origine dati crea e restituisce un flusso per soddisfare questo requisito. In questo caso, l'origine dati funge da produttore.
class NewsRemoteDataSource( private val newsApi: NewsApi, private val refreshIntervalMs: Long = 5000 ) { val latestNews: Flow<List<ArticleHeadline>> = flow { while (true) { val latestNews = newsApi.fetchLatestNews() emit(latestNews) // Emits the result of the request to the flow delay(refreshIntervalMs) // Suspends the coroutine for some time } } } // Interface that provides a way to make network requests with suspend functions interface NewsApi { suspend fun fetchLatestNews(): List<ArticleHeadline> }
Il generatore flow viene eseguito all'interno di una coroutine. Pertanto, beneficia
delle stesse API asincrone, ma si applicano alcune limitazioni:
- I flussi sono sequenziali. Poiché il produttore si trova in una coroutine, quando chiama
una funzione di sospensione, il produttore si sospende finché la funzione di sospensione
non restituisce un valore. Nell'esempio, il producer viene sospeso fino al completamento della richiesta di rete
fetchLatestNews. Solo a questo punto il risultato viene emesso nel flusso. - Con il generatore
flow, il produttore non puòemitvalori da unCoroutineContextdiverso. Pertanto, non chiamareemitin unCoroutineContextdiverso creando nuove coroutine o utilizzando blocchi di codicewithContext. In questi casi, puoi utilizzare altri strumenti di creazione dei flussi, ad esempiocallbackFlow.
Modifica dello stream
Gli intermediari possono utilizzare gli operatori intermedi per modificare il flusso di dati senza consumare i valori. Questi operatori sono funzioni che, se applicate a un flusso di dati, configurano una catena di operazioni che non vengono eseguite finché i valori non vengono utilizzati in futuro. Scopri di più sugli operatori intermedi nella documentazione di riferimento di Flow.
Nell'esempio seguente, il livello del repository utilizza l'operatore intermedio
map
per trasformare i dati da visualizzare in View:
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData ) { /** * Returns the favorite latest news applying transformations on the flow. * These operations are lazy and don't trigger the flow. They just transform * the current value emitted by the flow at that point in time. */ val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews // Intermediate operation to filter the list of favorite topics .map { news -> news.filter { userData.isFavoriteTopic(it) } } // Intermediate operation to save the latest news in the cache .onEach { news -> saveInCache(news) } }
Gli operatori intermedi possono essere applicati uno dopo l'altro, formando una catena di operazioni che vengono eseguite in modo differito quando un elemento viene emesso nel flusso. Tieni presente che la semplice applicazione di un operatore intermedio a uno stream non avvia la raccolta del flusso.
Raccolta da un flusso
Utilizza un operatore terminale per attivare il flusso e iniziare ad ascoltare i valori. Per ottenere tutti i valori nel flusso man mano che vengono emessi, utilizza
collect.
Per scoprire di più sugli operatori terminali, consulta la
documentazione ufficiale sul flusso.
Poiché collect è una funzione di sospensione, deve essere eseguita all'interno di una coroutine. Accetta una funzione lambda come parametro che viene chiamata per
ogni nuovo valore. Poiché si tratta di una funzione di sospensione, la coroutine che chiama collect potrebbe sospendersi fino alla chiusura del flusso.
Continuando l'esempio precedente, ecco una semplice implementazione di
un ViewModel che utilizza i dati del livello repository:
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { // Trigger the flow and consume its elements using collect newsRepository.favoriteLatestNews.collect { favoriteNews -> // Update UI with the latest favorite news } } } }
La raccolta del flusso attiva il producer che aggiorna le ultime notizie
ed emette il risultato della richiesta di rete a intervalli fissi. Poiché il
produttore rimane sempre attivo con il ciclo while(true), il flusso
di dati verrà chiuso quando il ViewModel viene cancellato e
viewModelScope viene annullato.
La raccolta del flusso può interrompersi per i seguenti motivi:
- La coroutine che raccoglie viene annullata, come mostrato nell'esempio precedente. Viene interrotto anche il produttore sottostante.
- Il produttore termina l'emissione degli elementi. In questo caso, il flusso di dati
viene chiuso e la coroutine che ha chiamato
collectriprende l'esecuzione.
I flussi sono freddi e pigri, a meno che non vengano specificati con altri operatori
intermedi. Ciò significa che il codice del producer viene eseguito ogni volta che viene chiamato un operatore terminale nel flusso. Nell'esempio precedente,
la presenza di più raccoglitori di flussi fa sì che l'origine dati recuperi
le ultime notizie più volte a intervalli fissi diversi. Per ottimizzare e
condividere un flusso quando più consumatori raccolgono contemporaneamente, utilizza l'operatore
shareIn.
Rilevamento di eccezioni impreviste
L'implementazione del produttore può provenire da una libreria di terze parti.
Ciò significa che può generare eccezioni impreviste. Per gestire queste eccezioni, utilizza l'operatore intermedio catch.
class LatestNewsViewModel( private val newsRepository: NewsRepository ) : ViewModel() { init { viewModelScope.launch { newsRepository.favoriteLatestNews // Intermediate catch operator. If an exception is thrown, // catch and update the UI .catch { exception -> notifyError(exception) } .collect { favoriteNews -> // Update UI with the latest favorite news } } } }
Nell'esempio precedente, quando si verifica un'eccezione, la lambda collect
non viene chiamata, in quanto non è stato ricevuto un nuovo elemento.
catch può anche emit elementi al flusso. Il livello del repository di esempio
potrebbe emit i valori memorizzati nella cache:
class NewsRepository( // ... ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> saveInCache(news) } // If an error happens, emit the last cached values .catch { exception -> emit(lastCachedNews()) } }
In questo esempio, quando si verifica un'eccezione, viene chiamata la lambda collect, poiché è stato emesso un nuovo elemento nel flusso a causa dell'eccezione.
Esecuzione in un CoroutineContext diverso
Per impostazione predefinita, il produttore di un builder flow viene eseguito in CoroutineContext della coroutine che raccoglie i dati, e come accennato in precedenza, non può emit valori da un CoroutineContext diverso. Questo comportamento potrebbe non essere auspicabile in alcuni casi.
Ad esempio, negli esempi utilizzati in questo argomento, il livello del repository non deve eseguire operazioni su Dispatchers.Main utilizzato da viewModelScope.
Per modificare il CoroutineContext di un flusso, utilizza l'operatore intermedio
flowOn.
flowOn modifica il CoroutineContext del flusso upstream, ovvero
il produttore e gli eventuali operatori intermedi applicati prima (o sopra)
flowOn. Il flusso downstream (gli operatori intermedi dopo flowOn
insieme al consumer) non è interessato e viene eseguito sul
CoroutineContext utilizzato per collect dal flusso. Se sono presenti
più operatori flowOn, ognuno modifica l'upstream dalla sua
posizione attuale.
class NewsRepository( private val newsRemoteDataSource: NewsRemoteDataSource, private val userData: UserData, private val defaultDispatcher: CoroutineDispatcher ) { val favoriteLatestNews: Flow<List<ArticleHeadline>> = newsRemoteDataSource.latestNews .map { news -> // Executes on the default dispatcher news.filter { userData.isFavoriteTopic(it) } } .onEach { news -> // Executes on the default dispatcher saveInCache(news) } // flowOn affects the upstream flow ↑ .flowOn(defaultDispatcher) // the downstream flow ↓ is not affected .catch { exception -> // Executes in the consumer's context emit(lastCachedNews()) } }
Con questo codice, gli operatori onEach e map utilizzano defaultDispatcher,
mentre l'operatore catch e il consumatore vengono eseguiti su
Dispatchers.Main utilizzato da viewModelScope.
Poiché il livello dell'origine dati esegue operazioni di I/O, devi utilizzare un dispatcher ottimizzato per le operazioni di I/O:
class NewsRemoteDataSource( // ... private val ioDispatcher: CoroutineDispatcher ) { val latestNews: Flow<List<ArticleHeadline>> = flow { // Executes on the IO dispatcher // ... } .flowOn(ioDispatcher) }
Flussi nelle librerie Jetpack
Flow è integrato in molte librerie Jetpack ed è popolare tra le librerie di terze parti per Android. Flow è ideale per gli aggiornamenti dei dati in tempo reale e per i flussi di dati continui.
Puoi utilizzare
Flow con Room
per ricevere notifiche delle modifiche apportate a un database. Quando utilizzi
Data Access Object (DAO),
restituisci un tipo Flow per ricevere aggiornamenti in tempo reale.
@Dao abstract class ExampleDao { @Query("SELECT * FROM Example") abstract fun getExamples(): Flow<List<Example>> }
Ogni volta che viene apportata una modifica alla tabella Example, viene emesso un nuovo elenco
con i nuovi elementi nel database.
Convertire le API basate su callback in flussi
callbackFlow
è uno strumento di creazione di flussi che ti consente di convertire le API basate su callback in flussi.
Ad esempio, le API Android di Firebase Firestore utilizzano i callback.
Per convertire queste API in flussi e ascoltare gli aggiornamenti del database Firestore, puoi utilizzare il seguente codice:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
trySend(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
A differenza del builder flow, callbackFlow
consente di emettere valori da un CoroutineContext diverso con la funzione
send o al di fuori di una coroutine con la funzione
trySend.
Internamente, callbackFlow utilizza un
canale,
che è concettualmente molto simile a una
coda di blocco.
Un canale è configurato con una capacità, ovvero il numero massimo di elementi
che possono essere memorizzati nel buffer. Il canale creato in callbackFlow ha una capacità
predefinita di 64 elementi. Quando provi ad aggiungere un nuovo elemento a un canale completo, send sospende il produttore finché non c'è spazio per il nuovo elemento, mentre trySend non aggiunge l'elemento al canale e restituisce false immediatamente.
trySend aggiunge immediatamente l'elemento specificato al canale,
solo se ciò non viola le limitazioni di capacità, quindi restituisce il
risultato positivo.
Risorse aggiuntive per i flussi
- Testare i flussi Kotlin su Android
StateFloweSharedFlow- Risorse aggiuntive per le coroutine e i flussi Kotlin