
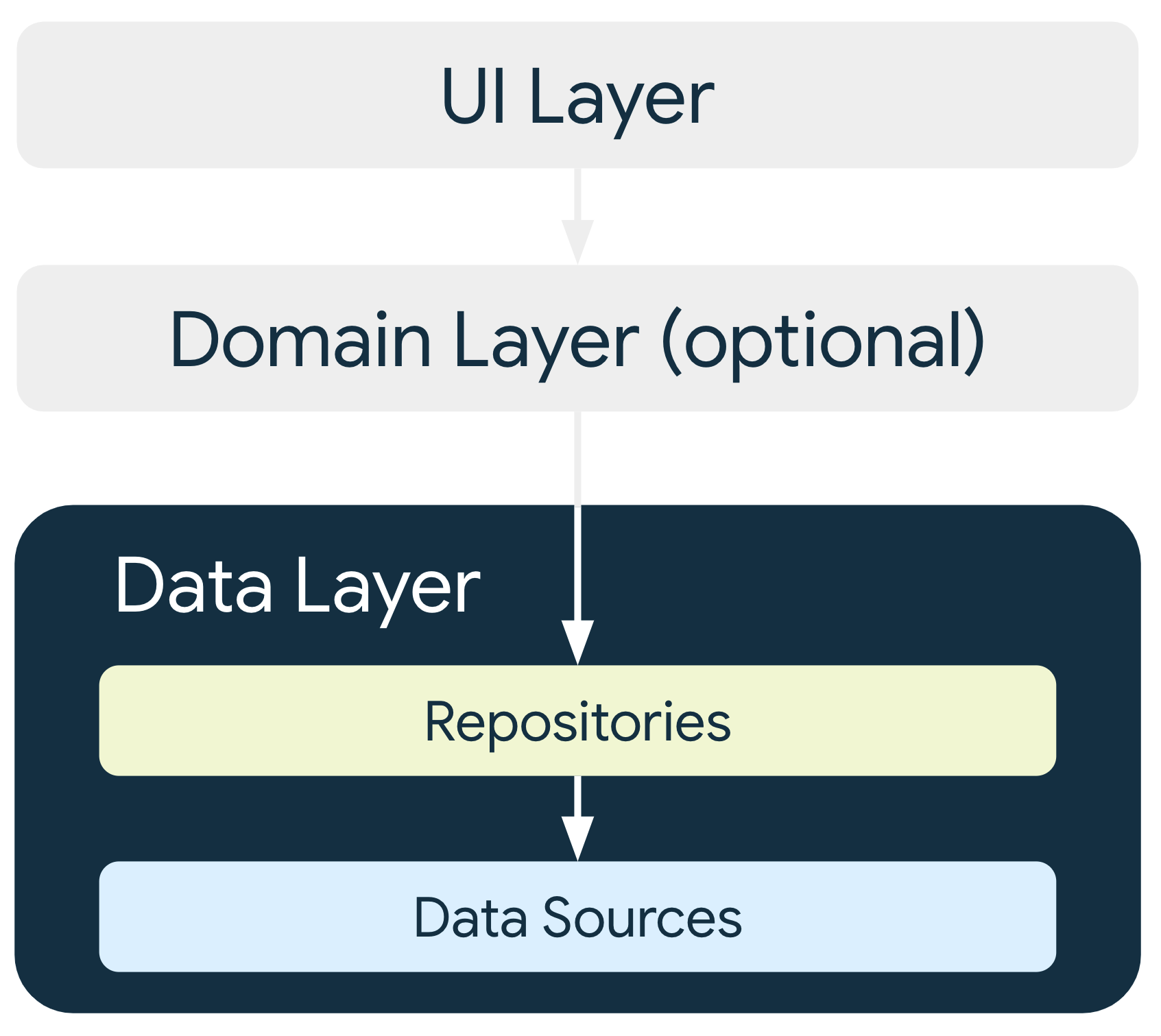
Warstwa interfejsu zawiera stan związany z interfejsem i logikę interfejsu, a warstwa danych zawiera dane aplikacji i logikę biznesową. Logika biznesowa nadaje aplikacji wartość – składa się z rzeczywistych reguł biznesowych, które określają, jak dane aplikacji mają być tworzone, przechowywane i zmieniane.
Ten podział obowiązków umożliwia używanie warstwy danych na wielu ekranach, udostępnianie informacji między różnymi częściami aplikacji i odtwarzanie logiki biznesowej poza interfejsem użytkownika na potrzeby testów jednostkowych. Więcej informacji o zaletach warstwy danych znajdziesz na stronie z omówieniem architektury.
Architektura warstwy danych
Warstwa danych składa się z repozytoriów, z których każde może zawierać od zera do wielu źródeł danych. Utwórz klasę repozytorium dla każdego typu danych, z którymi Twoja aplikacja ma do czynienia. Możesz na przykład utworzyć klasę MoviesRepository dla danych związanych z filmami lub klasę PaymentsRepository dla danych związanych z płatnościami.
Klasy repozytorium odpowiadają za te zadania:
- udostępnianie danych pozostałej części aplikacji;
- centralizowanie zmian w danych,
- rozwiązywanie konfliktów między wieloma źródłami danych;
- oddzielanie źródeł danych od reszty aplikacji;
- zawierające logikę biznesową.
Każda klasa źródła danych powinna być odpowiedzialna za pracę tylko z jednym źródłem danych, którym może być plik, źródło sieciowe lub lokalna baza danych. Klasy źródeł danych stanowią pomost między aplikacją a systemem w przypadku operacji na danych.
Inne warstwy w hierarchii nigdy nie powinny uzyskiwać dostępu do źródeł danych bezpośrednio. Punktami wejścia do warstwy danych są zawsze klasy repozytorium. Klasy przechowujące stan (patrz przewodnik po warstwie interfejsu) lub klasy przypadków użycia (patrz przewodnik po warstwie domeny) nigdy nie powinny mieć źródła danych jako bezpośredniej zależności. Używanie klas repozytorium jako punktów wejścia umożliwia niezależne skalowanie różnych warstw architektury.
Dane udostępniane przez tę warstwę powinny być niezmienne, aby inne klasy nie mogły ich modyfikować, co mogłoby spowodować niespójność ich wartości. Dane niezmienne mogą być też bezpiecznie obsługiwane przez wiele wątków. Więcej informacji znajdziesz w sekcji o wątkach.
Zgodnie ze sprawdzonymi metodami wstrzykiwania zależności repozytorium przyjmuje źródła danych jako zależności w konstruktorze:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Udostępnianie interfejsów API
Klasy w warstwie danych zwykle udostępniają funkcje do wykonywania jednorazowych wywołań operacji tworzenia, odczytywania, aktualizowania i usuwania (CRUD) lub do otrzymywania powiadomień o zmianach danych w czasie. W każdym z tych przypadków warstwa danych powinna udostępniać te informacje:
- W przypadku operacji jednorazowych udostępniaj funkcje zawieszania.
- Aby otrzymywać powiadomienia o zmianach danych w czasie, udostępnij przepływy.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Konwencje nazewnictwa w tym przewodniku
W tym przewodniku klasy repozytorium są nazwane zgodnie z danymi, za które są odpowiedzialne. Obowiązuje następująca konwencja:
typ danych + Repozytorium.
Na przykład: NewsRepository, MoviesRepository lub PaymentsRepository.
Klasy źródeł danych są nazwane na podstawie danych, za które są odpowiedzialne, oraz źródła, z którego korzystają. Obowiązuje następująca konwencja:
typ danych + typ źródła + DataSource.
W przypadku typu danych użyj wartości Remote lub Local, aby zachować większą ogólność, ponieważ implementacje mogą się zmieniać. Na przykład: NewsRemoteDataSource lub NewsLocalDataSource. Jeśli źródło jest ważne, podaj jego typ. Na przykład: NewsNetworkDataSource lub NewsDiskDataSource.
Nie nadawaj źródłu danych nazwy na podstawie szczegółów implementacji, np. UserSharedPreferencesDataSource, ponieważ repozytoria, które korzystają z tego źródła danych, nie powinny wiedzieć, jak dane są zapisywane. Jeśli będziesz przestrzegać tej zasady, możesz zmienić implementację źródła danych (np. przenieść dane z SharedPreferences do DataStore) bez wpływu na warstwę, która wywołuje to źródło.
Wiele poziomów repozytoriów
W niektórych przypadkach, gdy wymagania biznesowe są bardziej złożone, repozytorium może być zależne od innych repozytoriów. Może to być spowodowane tym, że dane są agregacją z wielu źródeł danych lub że odpowiedzialność musi być zamknięta w innej klasie repozytorium.
Na przykład repozytorium, które obsługuje dane uwierzytelniania użytkowników,UserRepositorymoże zależeć od innych repozytoriów, takich jak LoginRepositoryi RegistrationRepository, aby spełnić swoje wymagania.
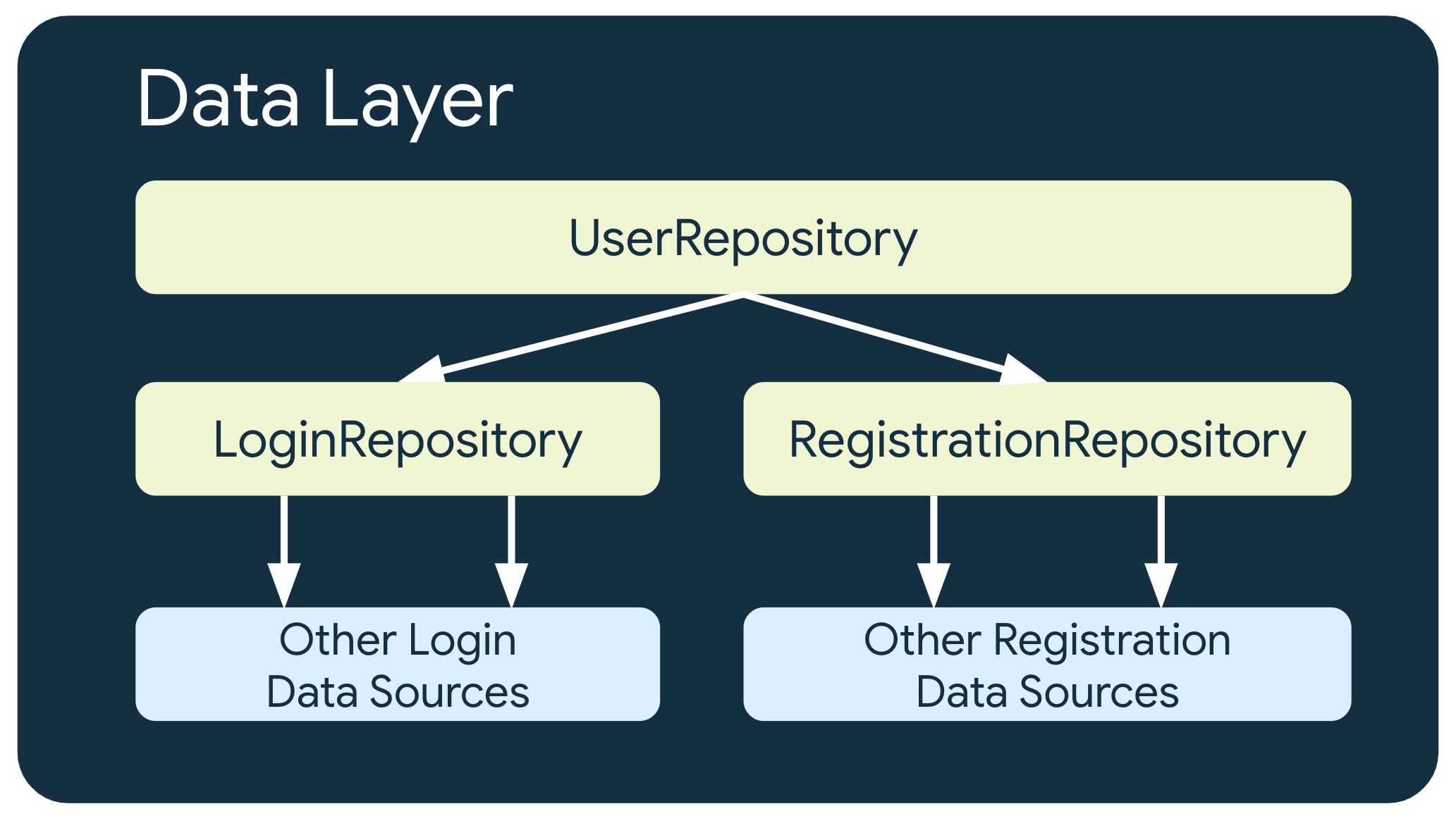
Nadrzędne źródło danych
Ważne jest, aby każde repozytorium definiowało jedno źródło informacji. Źródło informacji zawsze zawiera spójne, prawidłowe i aktualne dane. W rzeczywistości dane udostępniane z repozytorium powinny zawsze pochodzić bezpośrednio ze źródła informacji.
Źródłem informacji może być źródło danych, np. baza danych, a nawet pamięć podręczna, którą może zawierać repozytorium. Repozytoria łączą różne źródła danych i rozwiązują wszelkie potencjalne konflikty między nimi, aby regularnie aktualizować jedno źródło wiarygodnych danych lub w odpowiedzi na dane wejściowe użytkownika.
Różne repozytoria w aplikacji mogą mieć różne źródła informacji. Na przykład klasa LoginRepository może używać pamięci podręcznej jako źródła danych, a klasa PaymentsRepository może używać sieciowego źródła danych.
Aby zapewnić obsługę w trybie offline, zalecamy używanie lokalnego źródła danych, takiego jak baza danych, jako źródła informacji.
Regulacja brwi nitką
Wywoływanie źródeł danych i repozytoriów powinno być bezpieczne w wątku głównym, czyli bezpieczne do wywoływania z wątku głównego. Te klasy odpowiadają za przenoszenie wykonywania logiki do odpowiedniego wątku podczas wykonywania długotrwałych operacji blokujących. Na przykład źródło danych powinno być bezpieczne dla wątku głównego, gdy odczytuje dane z pliku, a repozytorium – gdy wykonuje kosztowne filtrowanie na dużej liście.
Pamiętaj, że większość źródeł danych udostępnia już główne interfejsy API bezpieczne dla wątków, takie jak wywołania metody suspend udostępniane przez Room, Retrofit lub Ktor. Twoje repozytorium może korzystać z tych interfejsów API, gdy są dostępne.
Więcej informacji o wątkach znajdziesz w przewodniku po przetwarzaniu w tle. Użytkownikom języka Kotlin zalecamy korzystanie z korutyn.
Cykl życia
Instancje klas w warstwie danych pozostają w pamięci tak długo, jak długo są dostępne z poziomu głównego elementu czyszczenia pamięci – zwykle przez odwoływanie się do innych obiektów w aplikacji.
Jeśli klasa zawiera dane w pamięci, np. pamięć podręczną, możesz chcieć ponownie użyć tej samej instancji klasy przez określony czas. Nazywa się to też cyklem życia instancji klasy.
Jeśli klasa jest kluczowa dla całej aplikacji, możesz określić zakres instancji tej klasy na klasę Application. Dzięki temu instancja będzie zgodna z cyklem życia aplikacji. Jeśli chcesz ponownie użyć tej samej instancji w określonym procesie w aplikacji, np. w procesie rejestracji lub logowania, ogranicz jej zakres do klasy, która jest właścicielem cyklu życia tego procesu. Możesz na przykład określić zakres RegistrationRepository zawierającego dane w pamięci jako RegistrationActivity lub jako stos wsteczny za pomocą NavEntryDecorator.
Cykl życia każdej instancji jest kluczowym czynnikiem przy podejmowaniu decyzji o tym, jak udostępniać zależności w aplikacji. Zalecamy stosowanie sprawdzonych metod wstrzykiwania zależności, w których zależności są zarządzane i mogą być ograniczone do kontenerów zależności. Więcej informacji o zakresach w Androidzie znajdziesz w tym poście na blogu: Scoping in Android and Hilt (Zakresy w Androidzie i Hilt).
Reprezentowanie modeli biznesowych
Modele danych, które chcesz udostępnić z warstwy danych, mogą być podzbiorem informacji pochodzących z różnych źródeł danych. W idealnej sytuacji różne źródła danych – zarówno sieciowe, jak i lokalne – powinny zwracać tylko informacje potrzebne aplikacji, ale często tak nie jest.
Wyobraź sobie na przykład serwer interfejsu News API, który zwraca nie tylko informacje o artykule, ale też historię zmian, komentarze użytkowników i niektóre metadane:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
Aplikacja nie potrzebuje tak wielu informacji o artykule, ponieważ wyświetla na ekranie tylko jego treść wraz z podstawowymi informacjami o autorze. Sprawdzoną metodą jest oddzielenie klas modeli i udostępnianie przez repozytoria tylko tych danych, które są wymagane przez inne warstwy hierarchii. Oto przykład, jak można skrócić ArticleApiModel z sieci, aby udostępnić klasę modelu Article warstwom domeny i interfejsu:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Rozdzielanie klas modeli jest korzystne z tych powodów:
- Zmniejsza zużycie pamięci aplikacji, ograniczając dane do niezbędnego minimum.
- Dostosowuje zewnętrzne typy danych do typów danych używanych przez aplikację. Na przykład aplikacja może używać innego typu danych do reprezentowania dat.
- Zapewnia lepsze rozdzielenie zadań – na przykład członkowie dużego zespołu mogą pracować indywidualnie nad warstwami sieci i interfejsu funkcji, jeśli klasa modelu jest zdefiniowana z wyprzedzeniem.
Możesz rozszerzyć tę praktykę i zdefiniować osobne klasy modeli w innych częściach architektury aplikacji, np. w klasach źródeł danych i w klasach ViewModel. Wymaga to jednak zdefiniowania dodatkowych klas i logiki, które należy odpowiednio udokumentować i przetestować. Zalecamy tworzenie nowych modeli w każdym przypadku, gdy źródło danych otrzymuje dane, które nie pasują do oczekiwań reszty aplikacji.
Rodzaje operacji na danych
Warstwa danych może obsługiwać różne typy operacji w zależności od ich znaczenia: operacje związane z interfejsem, aplikacją i biznesem.
Operacje zorientowane na interfejs
Operacje związane z interfejsem użytkownika są istotne tylko wtedy, gdy użytkownik znajduje się na określonym ekranie, i są anulowane, gdy użytkownik opuści ten ekran. Przykładem może być wyświetlanie danych uzyskanych z bazy danych.
Operacje zorientowane na interfejs użytkownika są zwykle wywoływane przez warstwę interfejsu użytkownika i podążają za cyklem życia wywołującego, np. cyklem życia ViewModel. Przykład operacji zorientowanej na interfejs znajdziesz w sekcji Wysyłanie żądania sieciowego.
Działania związane z aplikacjami
Operacje związane z aplikacją są istotne, dopóki aplikacja jest otwarta. Jeśli aplikacja zostanie zamknięta lub proces zostanie zakończony, te operacje zostaną anulowane. Przykładem jest buforowanie wyniku żądania sieciowego, aby można go było użyć później w razie potrzeby. Więcej informacji znajdziesz w sekcji Implementowanie buforowania danych w pamięci.
Operacje te zwykle są wykonywane w ramach cyklu życia klasy Application lub warstwy danych. Przykład znajdziesz w sekcji Wydłużanie czasu działania operacji poza ekranem.
Operacje biznesowe
Operacji zorientowanych na biznes nie można anulować. Powinny przetrwać zakończenie procesu. Może to być na przykład zakończenie przesyłania zdjęcia, które użytkownik chce opublikować w swoim profilu.
W przypadku operacji biznesowych zalecamy używanie WorkManagera. Więcej informacji znajdziesz w sekcji Planowanie zadań za pomocą WorkManagera.
Ujawnianie błędów
Interakcje z repozytoriami i źródłami danych mogą się zakończyć powodzeniem lub zgłosić wyjątek w przypadku niepowodzenia. W przypadku korutyn i przepływów należy używać wbudowanego mechanizmu obsługi błędów w Kotlinie. W przypadku błędów, które mogą być wywoływane przez funkcje zawieszania, w odpowiednich przypadkach używaj bloków try/catch, a w przepływach – operatora catch. W tym podejściu warstwa interfejsu powinna obsługiwać wyjątki podczas wywoływania warstwy danych.
Warstwa danych może rozpoznawać i obsługiwać różne typy błędów oraz udostępniać je za pomocą niestandardowych wyjątków, np. UserNotAuthenticatedException.
Więcej informacji o błędach w korutynach znajdziesz w poście na blogu Wyjątki w korutynach.
Częste zadania
W sekcjach poniżej znajdziesz przykłady użycia i projektowania warstwy danych do wykonywania określonych zadań, które są typowe w przypadku aplikacji na Androida. Przykłady są oparte na typowej aplikacji Wiadomości, o której wspomnieliśmy wcześniej w tym przewodniku.
Wysyłanie żądania sieciowego
Wysyłanie żądania sieciowego to jedno z najczęstszych zadań, jakie może wykonywać aplikacja na Androida. Aplikacja Wiadomości musi wyświetlać użytkownikowi najnowsze wiadomości pobrane z sieci. Dlatego aplikacja potrzebuje klasy źródła danych do zarządzania operacjami sieciowymi: NewsRemoteDataSource. Aby udostępnić informacje pozostałej części aplikacji, tworzone jest nowe repozytorium, które obsługuje operacje na danych wiadomości: NewsRepository.
Wymaganie jest takie, że najnowsze wiadomości muszą być zawsze aktualizowane, gdy użytkownik otworzy ekran. Jest to więc operacja zorientowana na interfejs.
Utwórz źródło danych
Źródło danych musi udostępniać funkcję, która zwraca najnowsze wiadomości: listę instancji ArticleHeadline. Źródło danych musi zapewniać bezpieczny sposób uzyskiwania najnowszych wiadomości z sieci. W tym celu musi być zależna od CoroutineDispatcher lub Executor, aby móc wykonać zadanie.
Wysyłanie żądania sieciowego to jednorazowe wywołanie obsługiwane przez nową metodę fetchLatestNews():
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
Interfejs NewsApi ukrywa implementację klienta interfejsu API sieciowego. Nie ma znaczenia, czy interfejs jest obsługiwany przez Retrofit czy HttpURLConnection. Korzystanie z interfejsów umożliwia zamienne stosowanie implementacji interfejsu API w aplikacji.
Tworzenie repozytorium
W klasie repozytorium nie jest potrzebna żadna dodatkowa logika do wykonania tego zadania, więc NewsRepository działa jako serwer proxy dla sieciowego źródła danych. Korzyści z dodania tej dodatkowej warstwy abstrakcji opisano w sekcji pamięć podręczna.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Więcej informacji o korzystaniu z klasy repozytorium bezpośrednio z warstwy interfejsu znajdziesz w przewodniku po warstwie interfejsu.
Wdrożenie buforowania danych w pamięci
Załóżmy, że w przypadku aplikacji Wiadomości wprowadzono nowe wymaganie: gdy użytkownik otworzy ekran, należy mu wyświetlić wiadomości z pamięci podręcznej, jeśli wcześniej wysłano żądanie. W przeciwnym razie aplikacja powinna wysłać żądanie sieciowe, aby pobrać najnowsze wiadomości.
Zgodnie z nowym wymaganiem aplikacja musi zachowywać w pamięci najnowsze wiadomości, gdy użytkownik ma ją otwartą. Jest to więc operacja zorientowana na aplikację.
Pamięci podręczne
Aby zachować dane, gdy użytkownik korzysta z aplikacji, możesz dodać buforowanie danych w pamięci. Pamięć podręczna służy do zapisywania niektórych informacji w pamięci na określony czas – w tym przypadku tak długo, jak użytkownik korzysta z aplikacji. Implementacje pamięci podręcznej mogą przyjmować różne formy. Mogą to być proste zmienne modyfikowalne lub bardziej zaawansowane klasy, które chronią przed operacjami odczytu i zapisu w wielu wątkach. W zależności od przypadku użycia buforowanie można zaimplementować w repozytorium lub w klasach źródła danych.
Zapisywanie w pamięci podręcznej wyniku żądania sieciowego
Dla uproszczenia NewsRepository używa zmiennej modyfikowalnej do buforowania najnowszych wiadomości. Aby chronić odczyty i zapisy z różnych wątków, używany jest Mutex. Więcej informacji o współdzielonym stanie modyfikowalnym i współbieżności znajdziesz w dokumentacji Kotlin.
Poniższa implementacja zapisuje w pamięci podręcznej najnowsze informacje o wiadomościach w zmiennej w repozytorium, która jest chroniona przed zapisem za pomocą znaku Mutex. Jeśli żądanie sieciowe zakończy się powodzeniem, dane zostaną przypisane do zmiennej latestNews.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Wydłużanie działania poza czas wyświetlania ekranu
Jeśli użytkownik opuści ekran, gdy żądanie sieciowe jest w trakcie realizacji, zostanie ono anulowane, a wynik nie zostanie zapisany w pamięci podręcznej. NewsRepository
nie powinna używać CoroutineScope dzwoniącego do wykonania tej logiki. Zamiast tego NewsRepository powinien używać CoroutineScope, który jest powiązany z jego cyklem życia.
Pobieranie najnowszych wiadomości musi być operacją zorientowaną na aplikację.
Aby zachować zgodność ze sprawdzonymi metodami dotyczącymi wstrzykiwania zależności, NewsRepository powinien otrzymywać zakres jako parametr w konstruktorze zamiast tworzyć własny CoroutineScope. Ponieważ repozytoria powinny wykonywać większość pracy w wątkach w tle, należy skonfigurować CoroutineScope za pomocą Dispatchers.Default lub własnej puli wątków.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Ponieważ NewsRepository jest gotowy do wykonywania operacji zorientowanych na aplikację za pomocą zewnętrznego CoroutineScope, musi wywołać źródło danych i zapisać wynik w nowej współprogramie uruchomionej w tym zakresie:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async służy do uruchamiania współprogramu w zakresie zewnętrznym. await jest wywoływana w nowym współprogramie, aby zawiesić działanie do czasu powrotu żądania sieciowego i zapisania wyniku w pamięci podręcznej. Jeśli w tym czasie użytkownik nadal będzie patrzeć na ekran, zobaczy najnowsze wiadomości. Jeśli odwróci wzrok, await zostanie anulowane, ale logika w async będzie nadal wykonywana.
Dowiedz się więcej o wzorcach dla CoroutineScope.
Zapisywanie i pobieranie danych z dysku
Załóżmy, że chcesz zapisać dane, takie jak wiadomości dodane do zakładek i preferencje użytkownika. Ten typ danych musi przetrwać śmierć procesu i być dostępny nawet wtedy, gdy użytkownik nie jest połączony z siecią.
Jeśli dane, z którymi pracujesz, muszą przetrwać śmierć procesu, musisz zapisać je na dysku w jeden z tych sposobów:
- W przypadku dużych zbiorów danych, które wymagają wykonywania zapytań, zachowania integralności referencyjnej lub częściowych aktualizacji, zapisz dane w bazie danych Room. W przykładzie aplikacji Wiadomości w bazie danych można zapisać artykuły lub autorów.
- W przypadku małych zbiorów danych, które wymagają tylko pobrania i ustawienia (nie są częściowo aktualizowane ani nie są do nich wysyłane zapytania), użyj DataStore. W przykładzie aplikacji News preferowany format daty użytkownika lub inne preferencje wyświetlania mogą być zapisane w DataStore.
- W przypadku fragmentów danych, takich jak obiekt JSON, użyj pliku.
Jak wspomnieliśmy w sekcji Źródło informacji, każde źródło danych współpracuje tylko z jednym źródłem i odpowiada konkretnemu typowi danych (np. News, Authors, NewsAndAuthors lub UserPreferences). Klasy, które korzystają ze źródła danych, nie powinny wiedzieć, jak dane są zapisywane – np. w bazie danych lub w pliku.
Pomieszczenie jako źródło danych
Każde źródło danych powinno być odpowiedzialne za współpracę tylko z 1 źródłem określonego typu danych, dlatego źródło danych Room otrzymuje jako parametr obiekt umożliwiający dostęp do danych (DAO) lub samą bazę danych. Na przykład funkcja NewsLocalDataSource może przyjmować instancję funkcji NewsDao jako parametr, a funkcja AuthorsLocalDataSource może przyjmować instancję funkcji AuthorsDao.
W niektórych przypadkach, jeśli nie jest potrzebna dodatkowa logika, możesz wstrzyknąć DAO bezpośrednio do repozytorium, ponieważ DAO to interfejs, który można łatwo zastąpić w testach.
Więcej informacji o korzystaniu z interfejsów Room API znajdziesz w przewodnikach dotyczących Room.
DataStore jako źródło danych
DataStore doskonale nadaje się do przechowywania par klucz-wartość, takich jak ustawienia użytkownika. Mogą to być np. format czasu, ustawienia powiadomień oraz to, czy po przeczytaniu przez użytkownika artykułu ma on być widoczny czy ukryty. Usługa DataStore może też przechowywać obiekty z określonym typem za pomocą buforów protokołu.
Podobnie jak w przypadku innych obiektów, źródło danych obsługiwane przez DataStore powinno zawierać dane odpowiadające określonemu typowi lub określonej części aplikacji. Jest to jeszcze bardziej istotne w przypadku DataStore, ponieważ odczyty z DataStore są udostępniane jako przepływ, który emituje dane za każdym razem, gdy wartość jest aktualizowana. Z tego powodu powiązane preferencje należy przechowywać w tym samym magazynie danych.
Możesz na przykład mieć NotificationsDataStore, który obsługuje tylko ustawienia związane z powiadomieniami, i NewsPreferencesDataStore, który obsługuje tylko ustawienia związane z ekranem wiadomości. Dzięki temu możesz lepiej określić zakres aktualizacji, ponieważ przepływ newsScreenPreferencesDataStore.data emituje tylko wtedy, gdy zmieni się ustawienie związane z tym ekranem. Oznacza to również, że cykl życia obiektu może być krótszy, ponieważ może on istnieć tylko tak długo, jak długo wyświetlany jest ekran wiadomości.
Więcej informacji o korzystaniu z interfejsów DataStore API znajdziesz w przewodnikach po DataStore.
Plik jako źródło danych
Podczas pracy z dużymi obiektami, takimi jak obiekt JSON lub bitmapa, musisz używać obiektu File i obsługiwać przełączanie wątków.
Więcej informacji o korzystaniu z miejsca na pliki znajdziesz na stronie Miejsce na dane.
Planowanie zadań za pomocą biblioteki WorkManager
Załóżmy, że w przypadku aplikacji Wiadomości wprowadzono nowe wymaganie: aplikacja musi dawać użytkownikowi możliwość regularnego i automatycznego pobierania najnowszych wiadomości, o ile urządzenie jest ładowane i połączone z siecią bez limitu danych. Dlatego jest to operacja biznesowa. Dzięki temu wymaganiu nawet jeśli urządzenie nie ma połączenia z internetem, gdy użytkownik otworzy aplikację, będzie mógł zobaczyć najnowsze wiadomości.
WorkManager ułatwia planowanie asynchronicznej i niezawodnej pracy oraz może zarządzać ograniczeniami. Jest to zalecana biblioteka do
pracy ciągłej. Aby wykonać zadanie zdefiniowane powyżej, tworzona jest klasa Worker: RefreshLatestNewsWorker. Ta klasa przyjmuje NewsRepository jako zależność, aby pobierać najnowsze wiadomości i zapisywać je w pamięci podręcznej na dysku.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
Logika biznesowa tego typu zadań powinna być zamknięta w osobnej klasie i traktowana jako oddzielne źródło danych. Biblioteka WorkManager będzie wtedy odpowiadać tylko za zapewnienie, że zadanie zostanie wykonane w wątku w tle, gdy zostaną spełnione wszystkie ograniczenia. Stosując ten wzorzec, możesz w razie potrzeby szybko zamieniać implementacje w różnych środowiskach.
W tym przykładzie zadanie związane z wiadomościami musi być wywoływane z NewsRepository, co spowoduje, że nowe źródło danych będzie zależne od NewsTasksDataSource, co zostanie zaimplementowane w ten sposób:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Nazwy tych klas pochodzą od danych, za które są odpowiedzialne, np. NewsTasksDataSource lub PaymentsTasksDataSource. Wszystkie zadania związane z określonym typem danych powinny być umieszczone w tej samej klasie.
Jeśli zadanie ma być wywoływane przy uruchamianiu aplikacji, zalecamy wywoływanie żądania WorkManagera za pomocą biblioteki App Startup, która wywołuje repozytorium z Initializer.
Więcej informacji o korzystaniu z interfejsów API biblioteki WorkManager znajdziesz w przewodnikach po WorkManager.
Testowanie
Podczas testowania aplikacji przydają się sprawdzone metody wstrzykiwania zależności. Warto też korzystać z interfejsów w przypadku klas, które komunikują się z zasobami zewnętrznymi. Podczas testowania jednostki możesz wstrzykiwać fałszywe wersje jej zależności, aby test był deterministyczny i niezawodny.
Testy jednostkowe
Podczas testowania warstwy danych obowiązują ogólne wskazówki dotyczące testowania. W przypadku testów jednostkowych używaj w razie potrzeby rzeczywistych obiektów i symuluj wszystkie zależności, które sięgają do zewnętrznych źródeł, np. odczytują dane z pliku lub sieci.
Testy integracji
Testy integracyjne, które uzyskują dostęp do źródeł zewnętrznych, są zwykle mniej deterministyczne, ponieważ muszą być uruchamiane na rzeczywistym urządzeniu. Zalecamy przeprowadzanie tych testów w kontrolowanym środowisku, aby zwiększyć ich wiarygodność.
W przypadku baz danych biblioteka Room umożliwia utworzenie bazy danych w pamięci, którą możesz w pełni kontrolować w testach. Więcej informacji znajdziesz na stronie Testowanie i debugowanie bazy danych.
W przypadku sieci istnieją popularne biblioteki, takie jak WireMock lub MockWebServer, które umożliwiają symulowanie wywołań HTTP i HTTPS oraz sprawdzanie, czy żądania zostały wysłane zgodnie z oczekiwaniami.
Dodatkowe materiały
Przykłady
- Jetcaster
- Szablon początkowy architektury (wielomodułowy)
- Architektura
- Szablon początkowy architektury (jeden moduł)
- Aplikacja Now in Android
Polecane dla Ciebie
- Uwaga: tekst linku jest wyświetlany, gdy język JavaScript jest wyłączony.
- Warstwa domeny
- Tworzenie aplikacji działającej w trybie offline
- Produkcja stanu interfejsu