
В то время как слой пользовательского интерфейса содержит состояние и логику, связанные с пользовательским интерфейсом, слой данных содержит данные приложения и бизнес-логику . Бизнес-логика — это то, что придает ценность вашему приложению: она состоит из реальных бизнес-правил, определяющих, как данные приложения должны создаваться, храниться и изменяться.
Такое разделение задач позволяет использовать слой данных на нескольких экранах, обмениваться информацией между различными частями приложения и воспроизводить бизнес-логику вне пользовательского интерфейса для модульного тестирования. Более подробную информацию о преимуществах слоя данных можно найти на странице «Обзор архитектуры» .
архитектура уровня данных
Слой данных состоит из репозиториев , каждый из которых может содержать от нуля до множества источников данных . Для каждого типа данных, обрабатываемых в вашем приложении, следует создать отдельный класс репозитория. Например, можно создать класс MoviesRepository для данных, связанных с фильмами, или класс PaymentsRepository для данных, связанных с платежами.
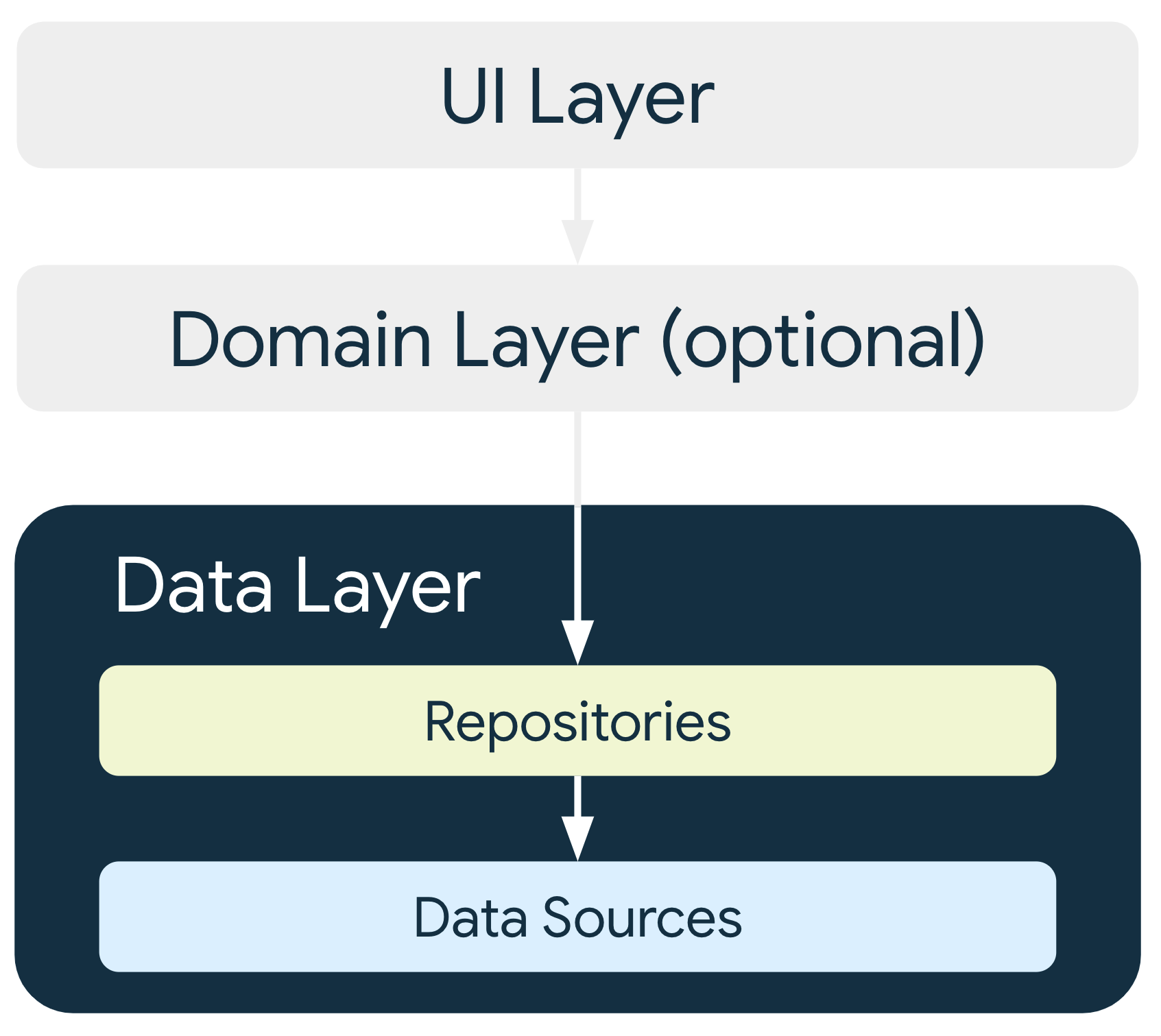
Классы репозитория отвечают за выполнение следующих задач:
- Предоставление доступа к данным остальной части приложения.
- Централизация изменений в данных.
- Разрешение конфликтов между несколькими источниками данных.
- Абстрагирование источников данных от остальной части приложения.
- Содержит бизнес-логику.
Каждый класс источника данных должен отвечать за работу только с одним источником данных, которым может быть файл, сетевой источник или локальная база данных. Классы источников данных выступают связующим звеном между приложением и системой для операций с данными.
Другие уровни иерархии никогда не должны обращаться к источникам данных напрямую; точками входа в слой данных всегда являются классы репозитория. Классы-держатели состояний (см. руководство по слою пользовательского интерфейса ) или классы вариантов использования (см. руководство по доменному слою ) никогда не должны иметь источник данных в качестве прямой зависимости. Использование классов репозитория в качестве точек входа позволяет различным уровням архитектуры масштабироваться независимо.
Данные, предоставляемые этим слоем, должны быть неизменяемыми, чтобы другие классы не могли их изменить, что может привести к несогласованности их значений. Неизменяемые данные также могут безопасно обрабатываться несколькими потоками. Подробнее см. раздел о многопоточности .
В соответствии с передовыми методами внедрения зависимостей , репозиторий принимает источники данных в качестве зависимостей в своем конструкторе:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Предоставлять доступ к API
Классы на уровне данных обычно предоставляют функции для выполнения одноразовых операций создания, чтения, обновления и удаления (CRUD) или для получения уведомлений об изменениях данных с течением времени. Для каждого из этих случаев уровень данных должен предоставлять следующие возможности:
- Для одноразовых операций предоставьте доступ к функциям приостановки.
- Чтобы получать уведомления об изменениях данных с течением времени , отобразите потоки данных .
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Правила именования в этом руководстве
В этом руководстве классы репозитория именуются в соответствии с данными, за которые они отвечают. Принятая договоренность следующая:
тип данных + Репозиторий .
Например: NewsRepository , MoviesRepository или PaymentsRepository .
Классы источников данных именуются в соответствии с данными, за которые они отвечают, и источником, который они используют. Применяется следующая система обозначений:
тип данных + тип источника + DataSource .
Для указания типа данных используйте Remote или Local , чтобы быть более универсальными, поскольку реализации могут меняться. Например: NewsRemoteDataSource или NewsLocalDataSource . Для большей конкретности, если важен источник данных, используйте его тип. Например: NewsNetworkDataSource или NewsDiskDataSource .
Не следует называть источник данных, основываясь на деталях реализации — например, UserSharedPreferencesDataSource , — поскольку репозитории, использующие этот источник данных, не должны знать, как сохраняются данные. Если вы будете следовать этому правилу, вы сможете изменить реализацию источника данных (например, перейти с SharedPreferences на DataStore ), не затрагивая слой, который вызывает этот источник.
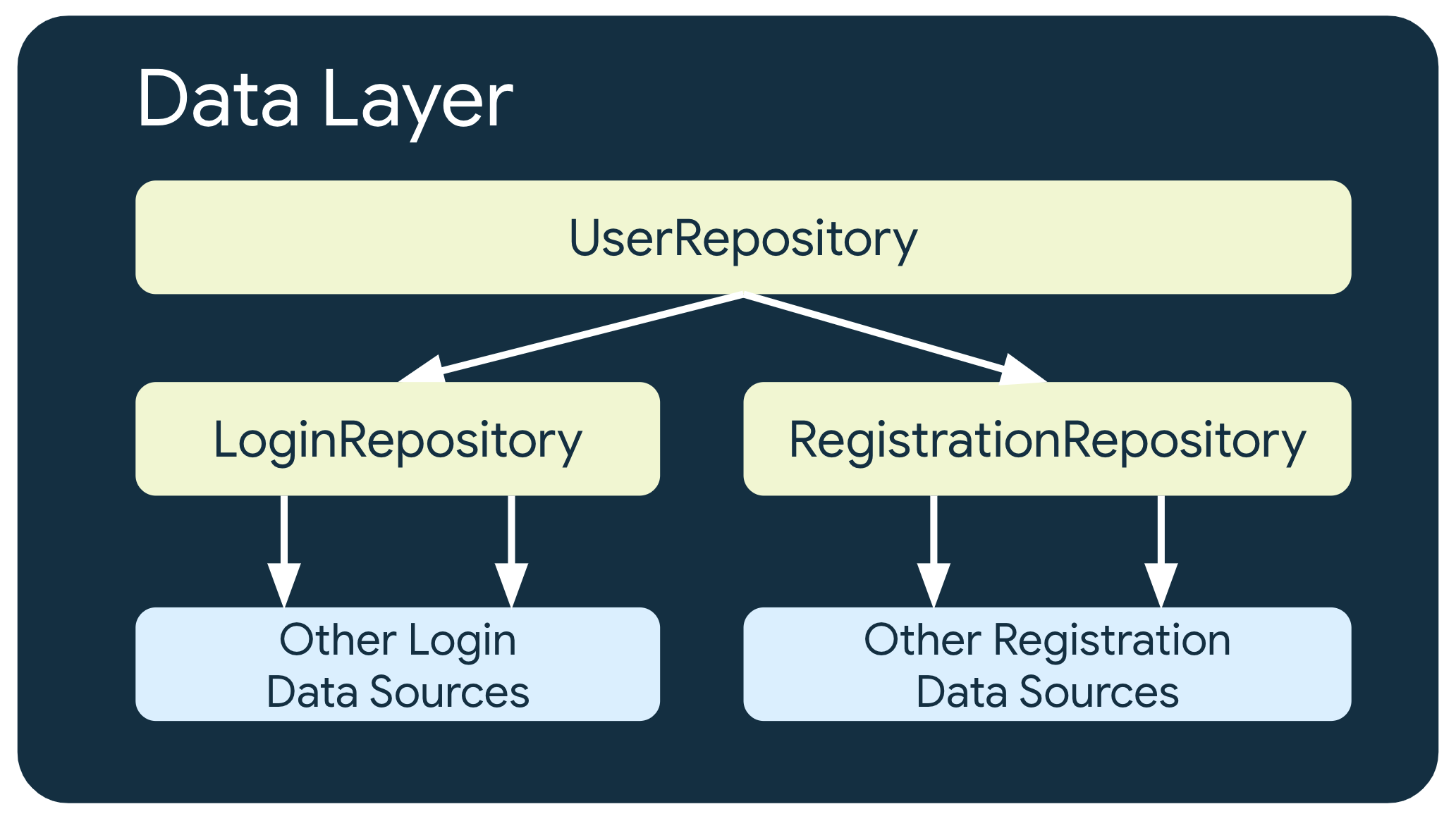
Многоуровневые репозитории
В некоторых случаях, когда требуются более сложные бизнес-задачи, репозиторий может зависеть от других репозиториев. Это может быть связано с тем, что обрабатываемые данные представляют собой агрегацию из нескольких источников данных, или с тем, что ответственность должна быть инкапсулирована в другом классе репозитория.
Например, репозиторий UserRepository , обрабатывающий данные аутентификации пользователей, может зависеть от других репозиториев, таких как LoginRepository и RegistrationRepository для выполнения своих задач.
Источник истины
Важно, чтобы каждый репозиторий определял единый источник достоверной информации. Источник достоверной информации всегда содержит согласованные, корректные и актуальные данные. Фактически, данные, предоставляемые из репозитория, всегда должны поступать непосредственно из источника достоверной информации.
Источником достоверной информации может быть источник данных — например, база данных — или даже кэш в оперативной памяти, который может содержать репозиторий. Репозитории объединяют различные источники данных и разрешают любые потенциальные конфликты между ними, чтобы регулярно обновлять единый источник достоверной информации или в ответ на событие ввода данных пользователем.
В разных репозиториях вашего приложения могут использоваться разные источники достоверной информации. Например, класс LoginRepository может использовать свой кэш в качестве источника данных, а класс PaymentsRepository — сетевой источник данных.
Для обеспечения поддержки в автономном режиме рекомендуется использовать локальный источник данных, например, базу данных, в качестве источника достоверной информации .
Резьба
Вызовы источников данных и репозиториев должны быть безопасными для основного потока — то есть безопасными для вызова из основного потока. Эти классы отвечают за перенос выполнения своей логики в соответствующий поток при выполнении длительных блокирующих операций. Например, чтение данных из файла из источника данных или выполнение ресурсоемкой фильтрации большого списка из репозитория должны быть безопасными для основного потока.
Обратите внимание, что большинство источников данных уже предоставляют безопасные для работы с основной частью API, такие как вызовы метода suspend, предоставляемые Room , Retrofit или Ktor . Ваш репозиторий может использовать эти API, когда они станут доступны.
Чтобы узнать больше о многопоточности, см. руководство по фоновой обработке . Пользователям Kotlin рекомендуется использовать сопрограммы .
Жизненный цикл
Экземпляры классов в слое данных остаются в памяти до тех пор, пока к ним можно получить доступ из корневого каталога сборки мусора — обычно путем ссылок из других объектов в вашем приложении.
Если класс содержит данные, хранящиеся в оперативной памяти, например, кэш, то может возникнуть необходимость повторно использовать один и тот же экземпляр этого класса в течение определенного периода времени. Это также называется жизненным циклом экземпляра класса.
Если функции класса имеют решающее значение для всего приложения, вы можете ограничить область действия экземпляра этого класса классом Application . Это позволит экземпляру следовать жизненному циклу приложения. В качестве альтернативы, если вам нужно повторно использовать один и тот же экземпляр только в определенном потоке вашего приложения — например, в процессе регистрации или входа в систему — то вам следует ограничить область действия экземпляра классом, который отвечает за жизненный цикл этого потока. Например, вы можете ограничить область RegistrationRepository , содержащего данные в памяти, классом RegistrationActivity или стеком возврата, используя NavEntryDecorator .
Жизненный цикл каждого экземпляра является критически важным фактором при определении способа предоставления зависимостей в вашем приложении. Рекомендуется следовать лучшим практикам внедрения зависимостей , где зависимости управляются и могут быть ограничены контейнерами зависимостей. Чтобы узнать больше об ограничении области видимости в Android, см. статью в блоге Hilt «Ограничение области видимости в Android» .
Представлять бизнес-модели
Модели данных, которые вы хотите предоставить из уровня данных, могут представлять собой подмножество информации, получаемой из различных источников данных. В идеале, различные источники данных — как сетевые, так и локальные — должны возвращать только ту информацию, которая необходима вашему приложению; но это не всегда так.
Например, представьте себе сервер News API, который возвращает не только информацию о статье, но и историю изменений, комментарии пользователей и некоторые метаданные:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
Приложению не требуется много информации о статье, поскольку оно отображает на экране только ее содержимое, а также основную информацию об авторе. Хорошей практикой является разделение классов моделей и предоставление репозиториям доступа только к тем данным, которые необходимы другим уровням иерархии. Например, вот как можно сократить класс ArticleApiModel из сети, чтобы предоставить класс модели Article для предметной области и пользовательского интерфейса:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Разделение классов моделей выгодно по следующим причинам:
- Это позволяет экономить память приложения, сокращая объем данных до только необходимых.
- Она адаптирует внешние типы данных к типам данных, используемым вашим приложением — например, ваше приложение может использовать другой тип данных для представления дат.
- Это обеспечивает лучшее разделение задач — например, члены большой команды могут работать индивидуально над сетевым и пользовательским интерфейсом функции, если класс модели определен заранее.
Вы можете расширить эту практику и определить отдельные классы моделей и в других частях архитектуры вашего приложения — например, в классах источников данных и ViewModel. Однако это потребует определения дополнительных классов и логики, которые следует должным образом документировать и тестировать. Как минимум, рекомендуется создавать новые модели в любом случае, когда источник данных получает данные, которые не соответствуют ожиданиям остальной части вашего приложения.
Типы операций с данными
Слой данных может обрабатывать операции различных типов в зависимости от их критичности: операции, ориентированные на пользовательский интерфейс, операции, ориентированные на приложение, и операции, ориентированные на бизнес.
Операции, ориентированные на пользовательский интерфейс
Операции, ориентированные на пользовательский интерфейс, актуальны только тогда, когда пользователь находится на определенном экране, и отменяются, когда пользователь покидает этот экран. Примером может служить отображение данных, полученных из базы данных.
Операции, ориентированные на пользовательский интерфейс, обычно запускаются уровнем пользовательского интерфейса и следуют жизненному циклу вызывающей стороны — например, жизненному циклу ViewModel. Пример операции, ориентированной на пользовательский интерфейс, см. в разделе «Выполнение сетевого запроса» .
Операции, ориентированные на приложения
Операции, ориентированные на приложение, остаются актуальными, пока приложение открыто. Если приложение закрыто или процесс завершен, эти операции отменяются. Примером может служить кэширование результата сетевого запроса для последующего использования при необходимости. Подробнее см. раздел «Реализация кэширования данных в памяти» .
Эти операции, как правило, следуют жизненному циклу класса Application или уровня данных. Например, см. раздел «Как сделать так, чтобы операция выполнялась дольше, чем время, отведенное на просмотр экрана» .
Операции, ориентированные на бизнес
Операции, ориентированные на бизнес, нельзя отменить. Они должны сохраняться после завершения процесса. Примером может служить завершение загрузки фотографии, которую пользователь хочет разместить в своем профиле.
Для бизнес-ориентированных операций рекомендуется использовать WorkManager. Более подробную информацию см. в разделе «Планирование задач с помощью WorkManager» .
Выявлять ошибки
Взаимодействие с репозиториями и источниками данных может либо завершиться успешно, либо вызвать исключение при возникновении ошибки. Для сопрограмм и потоков следует использовать встроенный в Kotlin механизм обработки ошибок . Для ошибок, которые могут быть вызваны функциями приостановки, используйте блоки try/catch где это уместно; а в потоках используйте оператор catch . При таком подходе ожидается, что слой пользовательского интерфейса будет обрабатывать исключения при вызове слоя данных.
Слой данных может понимать и обрабатывать различные типы ошибок и предоставлять к ним доступ с помощью пользовательских исключений — например, UserNotAuthenticatedException .
Чтобы узнать больше об ошибках в сопрограммах, ознакомьтесь с записью в блоге «Исключения в сопрограммах» .
Общие задачи
В следующих разделах представлены примеры использования и архитектуры слоя данных для выполнения определенных задач, часто встречающихся в приложениях Android. Примеры основаны на типичном новостном приложении, упомянутом ранее в руководстве.
Отправить сетевой запрос
Выполнение сетевого запроса — одна из наиболее распространенных задач, которые может выполнять Android-приложение. Новостному приложению необходимо отображать пользователю последние новости, полученные из сети. Поэтому приложению необходим класс источника данных для управления сетевыми операциями: NewsRemoteDataSource . Для предоставления доступа к информации остальной части приложения создается новый репозиторий, обрабатывающий операции с новостными данными: NewsRepository .
Требование заключается в том, что последние новости должны обновляться каждый раз, когда пользователь открывает экран. Таким образом, это операция, ориентированная на пользовательский интерфейс .
Создайте источник данных
Источник данных должен предоставлять функцию, возвращающую последние новости: список экземпляров ArticleHeadline . Источник данных должен обеспечивать безопасный для основного процесса способ получения последних новостей из сети. Для этого он должен зависеть от CoroutineDispatcher или Executor , на котором будет выполняться задача.
Выполнение сетевого запроса — это одноразовый вызов, обрабатываемый новым методом fetchLatestNews() :
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
Интерфейс NewsApi скрывает реализацию клиента сетевого API; не имеет значения, используется ли для поддержки интерфейса Retrofit или HttpURLConnection . Использование интерфейсов позволяет заменять реализации API в вашем приложении.
Создайте репозиторий
Поскольку для этой задачи в классе репозитория не требуется дополнительная логика, NewsRepository выступает в качестве прокси для сетевого источника данных. Преимущества добавления этого дополнительного уровня абстракции объясняются в разделе , посвященном кэшированию в оперативной памяти .
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Чтобы узнать, как напрямую использовать класс репозитория из пользовательского интерфейса, см. руководство по пользовательскому интерфейсу .
Реализовать кэширование данных в оперативной памяти.
Предположим, для новостного приложения появилось новое требование: при открытии пользователем экрана необходимо отображать кэшированные новости, если запрос был сделан ранее. В противном случае приложение должно отправить сетевой запрос для получения последних новостей.
В соответствии с новым требованием, приложение должно сохранять последние новости в памяти, пока пользователь держит его открытым. Таким образом, это операция, ориентированная на приложение .
Кэши
Вы можете сохранять данные, пока пользователь находится в вашем приложении, добавив кэширование данных в памяти. Кэши предназначены для сохранения некоторой информации в памяти в течение определенного времени — в данном случае, пока пользователь находится в приложении. Реализации кэша могут принимать различные формы. Они могут варьироваться от простых изменяемых переменных до более сложных классов, защищающих от операций чтения/записи в нескольких потоках. В зависимости от сценария использования, кэширование может быть реализовано в репозитории или в классах источников данных.
Кэшировать результат сетевого запроса
Для простоты NewsRepository использует изменяемую переменную для кэширования последних новостей. Для защиты операций чтения и записи от разных потоков используется Mutex . Более подробную информацию о совместно используемом изменяемом состоянии и параллельном выполнении см. в документации Kotlin .
Приведенная ниже реализация кэширует последние новости в переменную в репозитории, защищенную от записи с помощью Mutex . Если сетевой запрос проходит успешно, данные присваиваются переменной latestNews .
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Продлите время работы операции до того, как она отобразится на экране.
Если пользователь покинет экран во время выполнения сетевого запроса, он будет отменен, и результат не будет кэширован. NewsRepository не должен использовать CoroutineScope вызывающего объекта для выполнения этой логики. Вместо этого NewsRepository должен использовать CoroutineScope , привязанный к его жизненному циклу. Получение последних новостей должно быть операцией, ориентированной на приложение.
В соответствии с лучшими практиками внедрения зависимостей, NewsRepository должен получать область видимости в качестве параметра в своем конструкторе, а не создавать собственную область видимости CoroutineScope . Поскольку репозитории должны выполнять большую часть своей работы в фоновых потоках, следует настраивать CoroutineScope либо с помощью Dispatchers.Default , либо с помощью собственного пула потоков.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Поскольку NewsRepository готов выполнять операции, ориентированные на приложение, с использованием внешнего CoroutineScope , он должен выполнить вызов к источнику данных и сохранить результат с помощью новой сопрограммы, запущенной в рамках этого CoroutineScope:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async используется для запуска сопрограммы во внешней области видимости. Функция await вызывается для новой сопрограммы, чтобы приостановить выполнение до получения ответа на сетевой запрос, после чего результат сохраняется в кэше. Если к этому моменту пользователь все еще находится на экране, он увидит последние новости; если пользователь отойдет от экрана, await будет отменена, но логика внутри async продолжит выполняться.
Подробнее о шаблонах для CoroutineScope можно прочитать здесь.
Сохранение и извлечение данных с диска
Предположим, вы хотите сохранить такие данные, как закладки новостей и пользовательские настройки. Данные такого типа должны сохраняться после завершения процесса и быть доступными, даже если пользователь не подключен к сети.
Если данные, с которыми вы работаете, должны сохраняться после завершения процесса, то их необходимо хранить на диске одним из следующих способов:
- Для больших наборов данных , требующих запросов, обеспечения ссылочной целостности или частичного обновления, сохраняйте данные в базе данных Room . В примере с новостным приложением новостные статьи или авторы могут быть сохранены в базе данных.
- Для небольших наборов данных , которые нужно только получить и установить (без частичных запросов или обновлений), используйте DataStore . В примере с новостным приложением предпочтительный формат даты пользователя или другие параметры отображения можно сохранить в DataStore.
- Для обработки больших объемов данных, например, объекта JSON, используйте файл .
Как упоминалось в разделе «Источник истины» , каждый источник данных работает только с одним источником и соответствует определенному типу данных (например, News , Authors , NewsAndAuthors или UserPreferences ). Классы, использующие источник данных, не должны знать, как данные сохраняются — например, в базе данных или в файле.
Комната как источник данных
Поскольку каждый источник данных должен отвечать за работу только с одним источником для определенного типа данных, источник данных Room будет получать в качестве параметра либо объект доступа к данным (DAO) , либо саму базу данных. Например, NewsLocalDataSource может принимать в качестве параметра экземпляр NewsDao , а AuthorsLocalDataSource — экземпляр AuthorsDao .
В некоторых случаях, если дополнительная логика не требуется, можно внедрить DAO непосредственно в репозиторий, поскольку DAO представляет собой интерфейс, который легко заменить в тестах.
Чтобы узнать больше о работе с API Room, см. руководства по Room .
DataStore как источник данных
DataStore идеально подходит для хранения пар ключ-значение, например, пользовательских настроек. Примерами могут служить формат времени, настройки уведомлений и возможность отображения или скрытия новостных статей после прочтения пользователем. DataStore также может хранить типизированные объекты с использованием протокола Protocol Buffers .
Как и любой другой объект, источник данных, поддерживаемый DataStore, должен содержать данные, соответствующие определенному типу или определенной части приложения. Это особенно важно для DataStore, поскольку чтение из DataStore осуществляется в виде потока, который генерируется каждый раз при обновлении значения. По этой причине следует хранить связанные настройки в одном и том же DataStore.
Например, можно создать NotificationsDataStore , который будет обрабатывать только настройки, связанные с уведомлениями, и NewsPreferencesDataStore , который будет обрабатывать только настройки, связанные с новостным экраном. Таким образом, можно лучше контролировать область действия обновлений, поскольку поток newsScreenPreferencesDataStore.data генерируется только при изменении настройки, связанной с этим экраном. Это также означает, что жизненный цикл объекта может быть короче, поскольку он может существовать только до тех пор, пока отображается новостной экран.
Чтобы узнать больше о работе с API DataStore, см. руководства DataStore .
Файл как источник данных
При работе с большими объектами, такими как JSON-объект или растровое изображение, вам потребуется использовать объект File и управлять переключением потоков.
Чтобы узнать больше о работе с файловым хранилищем, см. страницу «Обзор хранилища» .
Планируйте задачи с помощью WorkManager
Предположим, для новостного приложения вводится еще одно новое требование: приложение должно предоставлять пользователю возможность регулярно и автоматически получать последние новости, пока устройство заряжается и подключено к сети без ограничений трафика. Это делает его ориентированным на бизнес- задачи. Это требование гарантирует, что даже если устройство не подключено к сети, когда пользователь открывает приложение, он все равно сможет видеть последние новости.
WorkManager упрощает планирование асинхронных и надежных задач и может управлять ограничениями. Это рекомендуемая библиотека для постоянной работы. Для выполнения описанной выше задачи создается класс Worker : RefreshLatestNewsWorker . Этот класс принимает NewsRepository в качестве зависимости для получения последних новостей и их кэширования на диск.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
Бизнес-логика для задач такого типа должна быть инкапсулирована в отдельный класс и рассматриваться как отдельный источник данных. В этом случае WorkManager будет отвечать только за обеспечение выполнения работы в фоновом потоке при соблюдении всех ограничений. Следуя этому шаблону, вы сможете быстро менять реализации в разных средах по мере необходимости.
В этом примере задача, связанная с новостями, должна вызываться из NewsRepository , который принимает в качестве зависимости новый источник данных, NewsTasksDataSource , реализованный следующим образом:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Классы такого типа называются в соответствии с данными, за которые они отвечают — например, NewsTasksDataSource или PaymentsTasksDataSource . Все задачи, связанные с определенным типом данных, должны быть инкапсулированы в одном классе.
Если задачу необходимо запускать при запуске приложения, рекомендуется инициировать запрос WorkManager с помощью библиотеки App Startup , которая вызывает репозиторий из Initializer .
Чтобы узнать больше о работе с API WorkManager, см. руководства WorkManager .
Тестирование
Внедрение зависимостей — это передовая практика, которая помогает при тестировании приложения. Также полезно использовать интерфейсы для классов, взаимодействующих с внешними ресурсами. При тестировании модульного приложения можно внедрять фиктивные версии его зависимостей, чтобы сделать тест детерминированным и надежным.
модульные тесты
Общие рекомендации по тестированию применяются при тестировании уровня данных. Для модульных тестов используйте реальные объекты, когда это необходимо, и имитируйте любые зависимости, которые обращаются к внешним источникам, например, чтение из файла или чтение из сети.
Интеграционные тесты
Интеграционные тесты, обращающиеся к внешним источникам, как правило, менее детерминированы, поскольку они должны выполняться на реальном устройстве. Рекомендуется выполнять такие тесты в контролируемой среде, чтобы повысить их надежность.
В Room для работы с базами данных предусмотрена возможность создания базы данных в оперативной памяти, которую вы можете полностью контролировать в своих тестах. Для получения дополнительной информации см. страницу «Тестирование и отладка базы данных» .
Для работы с сетью существуют популярные библиотеки, такие как WireMock или MockWebServer , которые позволяют имитировать HTTP- и HTTPS-запросы и проверять, были ли запросы выполнены должным образом.
Дополнительные ресурсы
Образцы
- Джеткастер
- Шаблон для создания архитектуры (многомодульный)
- Архитектура
- Шаблон для создания архитектуры (один модуль)
- Теперь в приложении для Android.
Рекомендуем вам
- Примечание: текст ссылки отображается, когда JavaScript отключен.
- Уровень предметной области
- Создайте приложение, ориентированное на работу в офлайн-режиме.
- Производство состояния пользовательского интерфейса