
Un'app offline-first è un'app in grado di eseguire tutte le sue funzionalità di base o un sottoinsieme critico senza accesso a internet. ovvero può eseguire una parte o tutta la sua logica di business offline.
Le considerazioni per la creazione di un'app offline-first iniziano dal livello dati, che offre l'accesso ai dati dell'applicazione e alla logica di business. Di tanto in tanto, l'app potrebbe dover aggiornare questi dati da fonti esterne al dispositivo. In questo modo, potrebbe essere necessario utilizzare risorse di rete per rimanere aggiornato.
La disponibilità della rete non è sempre garantita. I dispositivi hanno comunemente periodi di connessione di rete instabile o lenta. Gli utenti potrebbero riscontrare quanto segue:
- Larghezza di banda internet limitata
- Interruzioni temporanee della connessione, ad esempio quando ci si trova in un ascensore o in una galleria
- Accesso occasionale ai dati, ad esempio tablet solo Wi-Fi
Indipendentemente dal motivo, spesso è possibile che un'app funzioni in modo adeguato in queste circostanze. Per garantire il corretto funzionamento offline della tua app, questa deve essere in grado di:
- Rimanere utilizzabile senza una connessione di rete affidabile
- Mostra immediatamente agli utenti i dati locali anziché attendere il completamento o l'esito negativo della prima chiamata di rete
- Recuperare i dati in modo da tenere conto dello stato della batteria e dei dati, ad esempio richiedendo il recupero dei dati solo in condizioni ottimali, ad esempio durante la ricarica o quando è disponibile una rete Wi-Fi
Un'app che soddisfa questi criteri viene spesso chiamata app offline-first.
Progettare un'app offline-first
Quando progetti un'app offline-first, inizia dal livello dati e dalle due operazioni principali che puoi eseguire sui dati dell'app:
- Letture: recupero dei dati da utilizzare in altre parti dell'app, ad esempio per visualizzare informazioni per l'utente. In Compose, in genere lo fai osservando lo stato. Quando la tua UI osserva l'origine dati locale come stato, lo schermo riflette automaticamente gli ultimi dati locali.
- Scritture: memorizzazione dell'input dell'utente per il recupero successivo. In Compose, in genere si ottiene questo risultato utilizzando eventi e azioni inviati dall'interfaccia utente al ViewModel.
I repository nel data layer sono responsabili della combinazione delle origini dati per fornire i dati delle app. In un'app offline-first, deve essere presente almeno un'origine dati che non necessita dell'accesso alla rete per eseguire le attività più importanti. Una di queste attività critiche è la lettura dei dati.
Modellare i dati in un'app offline-first
Un'app offline-first ha un minimo di due origini dati per ogni repository che utilizza risorse di rete:
- L'origine dati locale
- L'origine dati di rete
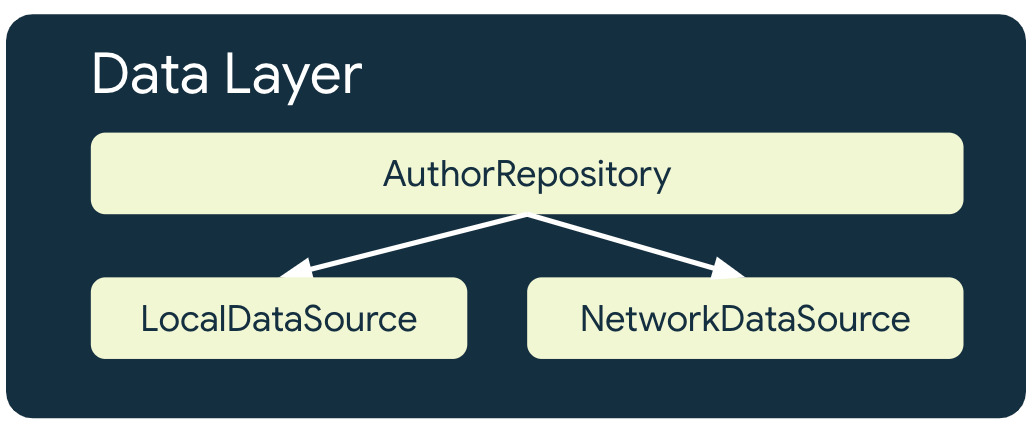
L'origine dati locale
L'origine dati locale è la fonte di riferimento canonica per l'app. Deve essere l'unica origine di tutti i dati letti dai livelli superiori dell'app. Ciò garantisce la coerenza dei dati tra gli stati di connessione. L'origine dati locale è spesso supportata da uno spazio di archiviazione persistente su disco. Alcuni mezzi comuni per rendere persistenti i dati su disco sono i seguenti:
- Origini dati strutturate, come database relazionali come Room
- Origini dati non strutturate, ad esempio buffer di protocollo con DataStore
- File semplici
L'origine dati di rete
L'origine dati di rete è lo stato effettivo dell'applicazione. Nel migliore dei casi, l'origine dati locale viene sincronizzata con l'origine dati di rete. L'origine dati locale può anche essere in ritardo rispetto all'origine dati di rete, nel qual caso l'app deve essere aggiornata quando torna online. Al contrario, l'origine dati di rete potrebbe essere in ritardo
rispetto all'origine dati locale finché l'app non può aggiornarla quando la connettività
viene ripristinata. I livelli di dominio e UI dell'app non devono mai comunicare direttamente
con il livello di rete. È responsabilità dell'repository di hosting
comunicare con esso e utilizzarlo per aggiornare l'origine dati locale.
Esposizione delle risorse
Le origini dati locali e di rete possono differire fondamentalmente nel modo in cui la tua app può leggerle e scriverle. L'esecuzione di query su un'origine dati locale può essere rapida e flessibile, ad esempio quando si utilizzano query SQL. Al contrario, le origini dati di rete possono essere lente e vincolate, ad esempio quando si accede in modo incrementale alle risorse RESTful per ID. Di conseguenza, ogni origine dati spesso ha bisogno di una propria rappresentazione dei dati che fornisce. Pertanto, l'origine dati locale e l'origine dati di rete potrebbero avere modelli propri.
La seguente struttura di directory aiuta a visualizzare questo concetto. AuthorEntity rappresenta un autore letto dal database locale dell'app, mentre
NetworkAuthor rappresenta un autore serializzato sulla rete:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Di seguito sono riportati i dettagli di AuthorEntity e NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
È buona norma mantenere sia AuthorEntity sia NetworkAuthor
interni al data layer ed esporre un terzo tipo per i livelli esterni da
utilizzare. In questo modo, i livelli esterni sono protetti da modifiche minori nelle origini dati locali e di rete che non cambiano in modo sostanziale il comportamento dell'app. Ciò è dimostrato nel seguente snippet:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Il modello di rete può quindi definire un metodo di estensione per convertirlo nel modello locale e il modello locale ne ha uno simile per convertirlo nella rappresentazione esterna, come mostrato nel seguente snippet:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Letture
Le letture sono l'operazione fondamentale sui dati delle app in un'app offline-first. Devi pertanto assicurarti che la tua app possa leggere i dati e che, non appena sono disponibili nuovi dati, l'app possa visualizzarli. Un'app in grado di farlo è un'app reattiva perché espone API di lettura con tipi osservabili.
Nel seguente snippet, OfflineFirstTopicRepository restituisce Flow per
tutte le relative API di lettura. In questo modo, può aggiornare i lettori quando riceve aggiornamenti
dall'origine dati di rete. In altre parole, consente a
OfflineFirstTopicRepository di eseguire il push delle modifiche quando l'origine dati locale
viene invalidata. Pertanto, ogni lettore di OfflineFirstTopicRepository deve essere
preparato a gestire le modifiche ai dati che possono essere attivate quando la connettività di rete
viene ripristinata nell'app. Inoltre, OfflineFirstTopicRepository legge i dati
direttamente dall'origine dati locale. Può notificare ai lettori le modifiche
ai dati solo dopo aver aggiornato la sua origine dati locale.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
In un'app Jetpack Compose, utilizza un ViewModel per collegare il livello dati e la UI.
Nel ViewModel, converti Flow in StateFlow utilizzando l'operatore stateIn. I composable raccolgono quindi questi stati utilizzando
collectAsStateWithLifecycle() e gestiscono automaticamente gli abbonamenti in modo
consapevole del ciclo di vita.
Per saperne di più su collectAsStateWithLifecycle(), consulta
Stato e Jetpack Compose.
Strategie di gestione degli errori
Esistono modi unici di gestire gli errori nelle app offline-first, a seconda delle origini dati in cui potrebbero verificarsi. Le seguenti sottosezioni descrivono queste strategie.
Origine dati locale
Cerca di ridurre al minimo gli errori durante la lettura dall'origine dati locale. Per proteggere
i lettori dagli errori, utilizza l'operatore catch sui Flow da cui
il lettore raccoglie i dati.
Puoi utilizzare l'operatore catch in un ViewModel nel seguente modo:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Per un approccio più resiliente, valuta una soluzione LCE (Loading Content Error). In LCE, quando si verifica un errore durante la lettura, viene visualizzato uno stato di errore. In genere, si ottiene LCE modellando gli stati dell'interfaccia utente come classi sigillate Kotlin.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Origine dati di rete
Se si verificano errori durante la lettura dei dati da un'origine dati di rete, l'app deve utilizzare un'euristica per riprovare a recuperare i dati. Le euristiche comuni includono quanto segue:
Backoff esponenziale
Nel backoff esponenziale, l'app continua a tentare di leggere dall'origine dati di rete con intervalli di tempo crescenti finché non riesce o finché altre condizioni non impongono l'interruzione.
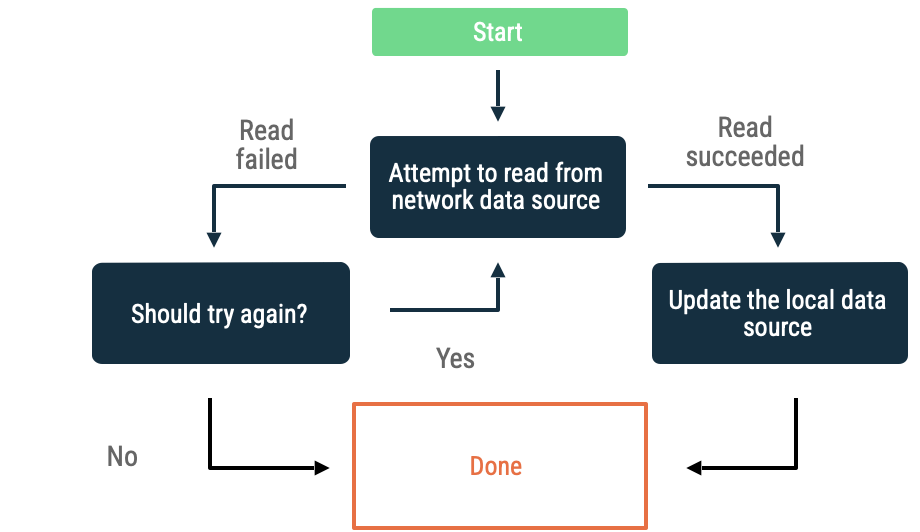
I criteri per valutare se l'app continua a riprovare includono:
- Il tipo di errore indicato dall'origine dati di rete. Ad esempio, esegui nuovi tentativi di chiamate di rete che restituiscono un errore che indica una mancanza di connettività. Non riprovare le richieste HTTP non autorizzate finché non sono disponibili le credenziali corrette.
- Numero massimo di tentativi consentiti.
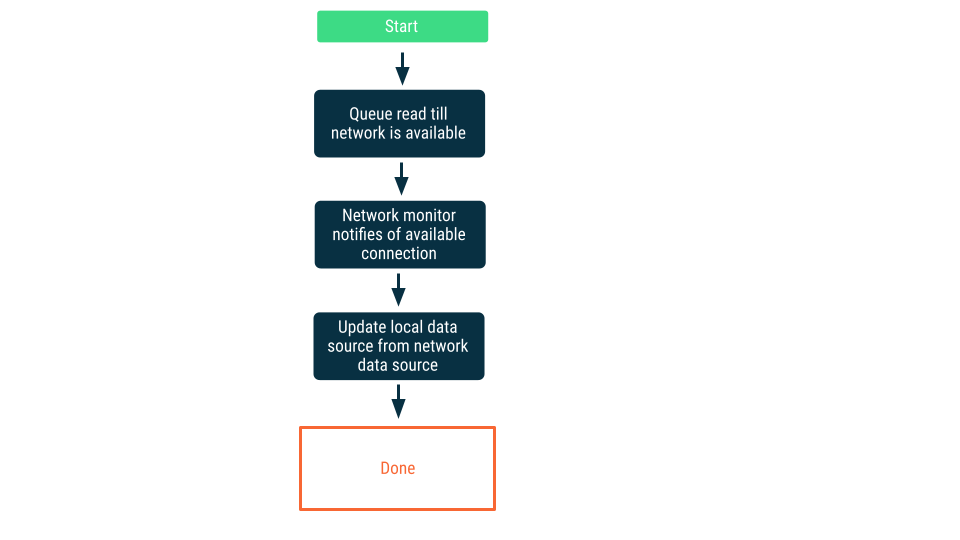
Monitoraggio della connettività di rete
Con questo approccio, le richieste di lettura vengono accodate finché l'app non è certa di potersi connettere all'origine dati di rete. Una volta stabilita una connessione, la richiesta di lettura viene rimossa dalla coda, i dati vengono letti e l'origine dati locale viene aggiornata. Su Android, questa coda potrebbe essere gestita con un database Room e svuotata come attività persistente utilizzando WorkManager.
Scritture
Sebbene il modo consigliato per leggere i dati in un'app offline-first sia l'utilizzo di tipi osservabili, l'equivalente per le API di scrittura sono le API asincrone, come le funzioni di sospensione. In questo modo si evita di bloccare il thread dell'interfaccia utente e si semplifica la gestione degli errori, perché le scritture nelle app offline-first possono non riuscire quando si attraversa un limite di rete.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
Nello snippet precedente, l'API asincrona scelta è Coroutines perché il metodo viene sospeso.
Scrivere strategie
Quando scrivi dati in app offline-first, ci sono tre strategie da considerare. La scelta dipende dal tipo di dati scritti e dai requisiti dell'app:
Scritture solo online
Tentativo di scrivere i dati oltre il limite di rete. In caso di esito positivo, aggiorna l'origine dati locale; in caso contrario, genera un'eccezione e lascia al chiamante il compito di rispondere in modo appropriato.

Questa strategia viene spesso utilizzata per le transazioni di scrittura che devono avvenire online in quasi tempo reale, ad esempio un bonifico bancario. Poiché le scritture possono non riuscire, spesso è necessario comunicare all'utente che la scrittura non è riuscita o impedirgli di tentare di scrivere dati. Ecco alcune strategie che puoi utilizzare in questi scenari:
- Se un'app richiede l'accesso a internet per scrivere dati, puoi scegliere di non presentare un'interfaccia utente che consenta all'utente di scrivere dati o, come minimo, puoi disattivarla.
- Puoi utilizzare un
AlertDialogche l'utente non può chiudere o unSnackbarper comunicare all'utente che è offline.
Scritture in coda
Quando hai un oggetto che vuoi scrivere, inseriscilo in una coda. Quando l'app
torna online, svuota la coda con backoff esponenziale. Su
Android, lo svuotamento di una coda offline è un'attività persistente che viene spesso delegata a
WorkManager.

Questo approccio è una buona scelta nei seguenti scenari:
- Non è essenziale che i dati vengano mai scritti sulla rete.
- La transazione non è urgente.
- Non è essenziale che l'utente venga informato se l'operazione non va a buon fine.
I casi d'uso di questo approccio includono eventi di analisi e logging.
Scritture lazy
Scrivi prima nell'origine dati locale, quindi metti in coda la scrittura per notificare alla rete non appena possibile. Questa operazione non è banale perché possono verificarsi conflitti tra le origini dati di rete e locali quando l'app torna online. La sezione successiva sulla risoluzione dei conflitti fornisce maggiori dettagli.
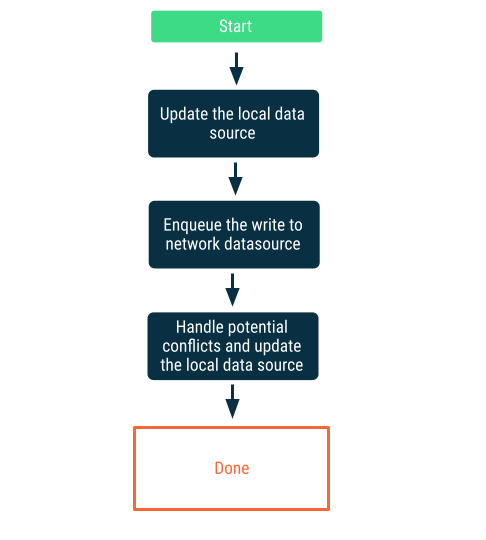
Questo approccio è la scelta giusta quando i dati sono fondamentali per l'app. Ad esempio, in un'app di elenchi di cose da fare offline, è essenziale che tutte le attività che l'utente aggiunge offline vengano archiviate localmente per evitare il rischio di perdita di dati.
Sincronizzazione e risoluzione dei conflitti
Quando un'app offline-first ripristina la connettività, deve riconciliare i dati nell'origine dati locale con quelli nell'origine dati di rete. Questo processo è chiamato sincronizzazione. Esistono due modi principali in cui un'app può sincronizzarsi con la sua origine dati di rete:
- Sincronizzazione basata sul pull
- Sincronizzazione basata sul push
Sincronizzazione basata sul pull
Nella sincronizzazione basata sul pull, l'app contatta la rete per leggere i dati dell'applicazione più recenti su richiesta. Un'euristica comune per questo approccio è la navigazione basata sui dati, in cui l'app recupera i dati solo prima di presentarli all'utente.
Questo approccio funziona meglio quando l'app prevede periodi brevi o intermedi di assenza di connettività di rete. Questo perché l'aggiornamento dei dati è opportunistico e lunghi periodi di assenza di connettività aumentano la probabilità che l'utente tenti di visitare le destinazioni delle app con una cache obsoleta o vuota.
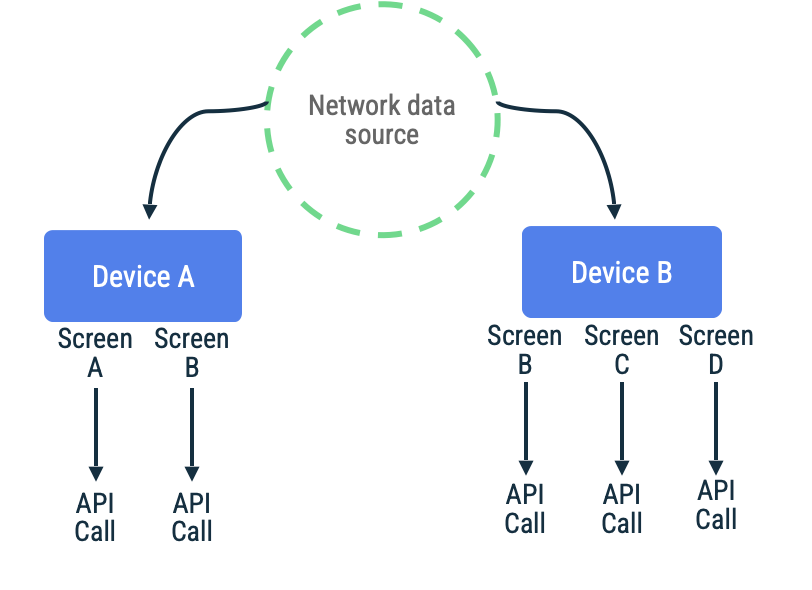
Prendi in considerazione un'app in cui i token di pagina vengono utilizzati per recuperare elementi in un elenco a scorrimento continuo per una schermata specifica. L'implementazione potrebbe raggiungere
la rete in modo differito, persistere i dati nell'origine dati locale e quindi leggere
dall'origine dati locale per presentare le informazioni all'utente. Nel caso in cui
non sia presente connettività di rete, il repository potrebbe richiedere i dati
solo dall'origine dati locale. Questo è il pattern utilizzato dalla
libreria Paging di Jetpack con la relativa API RemoteMediator.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
I vantaggi e gli svantaggi della sincronizzazione basata sul pull sono riassunti nella tabella seguente:
| Vantaggi | Svantaggi |
|---|---|
| Relativamente facile da implementare. | Soggetto a un utilizzo intensivo di dati. Questo perché le visite ripetute a una destinazione di navigazione attivano un recupero non necessario di informazioni invariate. Puoi mitigare questo problema tramite una corretta memorizzazione nella cache. Questa operazione può essere eseguita nel livello UI con l'operatore cachedIn o nel livello di rete con una cache HTTP. |
| I dati non necessari non vengono mai recuperati. | Non è scalabile con i dati relazionali perché il modello estratto deve essere autosufficiente. Se il modello in fase di sincronizzazione dipende da altri modelli da recuperare per essere compilato, il problema dell'utilizzo elevato di dati menzionato in precedenza diventa ancora più significativo. Inoltre, può causare dipendenze tra i repository del modello principale e quelli del modello nidificato. |
Sincronizzazione basata sul push
Nella sincronizzazione basata sul push, l'origine dati locale tenta di imitare un set di repliche dell'origine dati di rete al meglio delle sue capacità. Recupera in modo proattivo una quantità adeguata di dati al primo avvio per impostare una base di riferimento. Dopodiché, si basa sulle notifiche del server per avvisare quando i dati non sono aggiornati.

Al ricevimento della notifica di dati obsoleti, l'app contatta la rete per
aggiornare solo i dati contrassegnati come obsoleti. Questo lavoro viene delegato al
Repository, che contatta l'origine dati di rete e archivia i dati
recuperati nell'origine dati locale. Poiché il repository espone i suoi dati con tipi osservabili, i lettori vengono informati di eventuali modifiche.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Con questo approccio, l'app dipende molto meno dall'origine dati di rete e può funzionare senza per periodi prolungati. Offre l'accesso in lettura e scrittura quando è offline perché presuppone di avere localmente le informazioni più recenti dall'origine dati di rete.
I vantaggi e gli svantaggi della sincronizzazione basata sul push sono riassunti nella tabella seguente:
| Vantaggi | Svantaggi |
|---|---|
| L'app può rimanere offline a tempo indeterminato. | I dati di controllo delle versioni per la risoluzione dei conflitti non sono banali. |
| Utilizzo minimo dei dati. L'app recupera solo i dati modificati. | Durante la sincronizzazione, devi prendere in considerazione i problemi di scrittura. |
| Funziona bene per i dati relazionali. Ogni repository è responsabile del recupero dei dati solo per il modello che supporta. | L'origine dati di rete deve supportare la sincronizzazione. |
Sincronizzazione ibrida
Alcune app utilizzano un approccio ibrido basato su pull o push a seconda dei dati. Ad esempio, un'app di social media potrebbe utilizzare la sincronizzazione basata sul pull per recuperare il feed degli utenti su richiesta a causa dell'elevata frequenza di aggiornamento del feed. La stessa app potrebbe scegliere di utilizzare la sincronizzazione basata sul push per i dati relativi all'utente che ha eseguito l'accesso, inclusi nome utente, immagine del profilo e così via.
In definitiva, la scelta della sincronizzazione offline-first dipende dai requisiti del prodotto e dall'infrastruttura tecnica disponibile.
Risoluzione dei conflitti
Se, quando è offline, l'app scrive localmente dati non allineati all'origine dati di rete, devi risolvere il conflitto prima che possa avvenire la sincronizzazione.
La risoluzione dei conflitti spesso richiede il controllo delle versioni. L'app deve eseguire alcune operazioni di contabilità per tenere traccia di quando si sono verificate le modifiche, in modo da poter trasferire i metadati all'origine dati di rete. L'origine dati di rete ha quindi la responsabilità di fornire l'origine assoluta della verità. Esistono molte strategie da considerare per la risoluzione dei conflitti, a seconda delle esigenze dell'applicazione. Per le app mobile, un approccio comune è "last write wins".
L'ultima scrittura ha la precedenza
In questo approccio, i dispositivi alleggano metadati timestamp ai dati che scrivono nella rete. Quando l'origine dati di rete li riceve, scarta i dati più vecchi del suo stato attuale, accettando quelli più recenti.

Nella figura 9, entrambi i dispositivi sono offline e inizialmente sincronizzati con l'origine dati di rete. Quando sono offline, entrambi scrivono i dati in locale e tengono traccia dell'ora in cui li hanno scritti. Quando entrambi tornano online e si sincronizzano con l'origine dati di rete, la rete risolve il conflitto mantenendo i dati del dispositivo B perché sono stati scritti successivamente.
WorkManager nelle app offline-first
Nelle strategie di lettura e scrittura trattate in precedenza, esistono due utilità comuni:
- Code
- Letture: utilizzato per rimandare le letture fino a quando non è disponibile la connettività di rete.
- Scritture: utilizzato per rimandare le scritture finché la connettività di rete non è disponibile e per rimettere in coda le scritture per i tentativi.
- Monitor della connettività di rete
- Letture: utilizzato come indicatore per svuotare la coda di lettura quando l'app è connessa e per la sincronizzazione.
- Scritture: utilizzato come indicatore per svuotare la coda di scrittura quando l'app è connessa e per la sincronizzazione.
Entrambi i casi sono esempi di lavoro persistente in cui WorkManager eccelle. Ad esempio, nell'app di esempio Now in Android, WorkManager viene utilizzato sia come coda di lettura sia come monitor di rete durante la sincronizzazione dell'origine dati locale. All'avvio, l'app esegue le seguenti operazioni:
- Mette in coda il lavoro di sincronizzazione della lettura per garantire la parità tra l'origine dati locale e l'origine dati di rete.
- Svuota la coda di sincronizzazione della lettura e inizia la sincronizzazione quando l'app è online.
- Esegue una lettura dall'origine dati di rete utilizzando il backoff esponenziale.
- Conserva i risultati della lettura nell'origine dati locale e risolve eventuali conflitti.
- Espone i dati dell'origine dati locale per consentire ad altri livelli dell'app di utilizzarli.
Queste azioni sono illustrate nel seguente diagramma:

L'accodamento del lavoro di sincronizzazione con WorkManager segue specificandolo come lavoro unico con KEEP ExistingWorkPolicy:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() è definito come segue:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Nello specifico, Constraints definito da SyncConstraints richiede che
NetworkType sia NetworkType.CONNECTED. ovvero attende che la rete sia disponibile prima di essere eseguito.
Una volta che la rete è disponibile, il worker svuota la coda di lavoro univoca
specificata da SyncWorkName delegando alle istanze Repository appropriate. Se la sincronizzazione non va a buon fine, il metodo doWork() restituisce
Result.retry(). WorkManager riproverà automaticamente la sincronizzazione con
backoff esponenziale. In caso contrario, restituisce Result.success(), completando
la sincronizzazione.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Esempi
I seguenti esempi di Google mostrano app offline-first. Esplorali per vedere queste indicazioni in pratica:
Consigliati per te
- Nota: il testo del link viene visualizzato quando JavaScript è disattivato
- Produzione stato UI
- Livello UI
- Livello dati