
Автономное приложение — это приложение, которое способно выполнять все или критический подмножество своих основных функций без доступа к Интернету. То есть он может выполнять часть или всю свою бизнес-логику в автономном режиме.
Рекомендации по созданию автономного приложения начинаются с уровня данных , который обеспечивает доступ к данным приложения и бизнес-логике. Приложению может потребоваться время от времени обновлять эти данные из источников, внешних по отношению к устройству. При этом ему может потребоваться обратиться к сетевым ресурсам, чтобы оставаться в курсе событий.
Доступность сети не всегда гарантируется. У устройств обычно бывают периоды нестабильного или медленного сетевого подключения. Пользователи могут столкнуться со следующим:
- Ограниченная пропускная способность Интернета
- Временные прерывания соединения, например, в лифте или туннеле.
- Периодический доступ к данным. Например, планшеты только с Wi-Fi.
Независимо от причины, приложение часто может работать адекватно в таких обстоятельствах. Чтобы обеспечить правильную работу вашего приложения в автономном режиме, оно должно иметь возможность выполнять следующие действия:
- Оставайтесь работоспособными без надежного сетевого подключения.
- Немедленно предоставляйте пользователям локальные данные, не дожидаясь завершения или сбоя первого сетевого вызова.
- Получайте данные таким образом, чтобы учитывать состояние батареи и данных. Например, запрашивая выборку данных только в оптимальных условиях, например, во время зарядки или по Wi-Fi.
Приложение, которое может удовлетворять вышеуказанным критериям, часто называют офлайн-приложением.
Создайте оффлайн-приложение
При разработке автономного приложения вам следует начать с уровня данных и двух основных операций, которые вы можете выполнять с данными приложения:
- Чтение : получение данных для использования другими частями приложения, например отображение информации пользователю.
- Пишет : Сохранение пользовательского ввода для последующего извлечения.
Репозитории на уровне данных отвечают за объединение источников данных для предоставления данных приложения. В автономном приложении должен быть хотя бы один источник данных, которому не требуется доступ к сети для выполнения наиболее важных задач. Одной из таких важнейших задач является чтение данных.
Данные модели в автономном приложении
Автономное приложение имеет как минимум два источника данных для каждого репозитория, использующего сетевые ресурсы:
- Локальный источник данных
- Сетевой источник данных
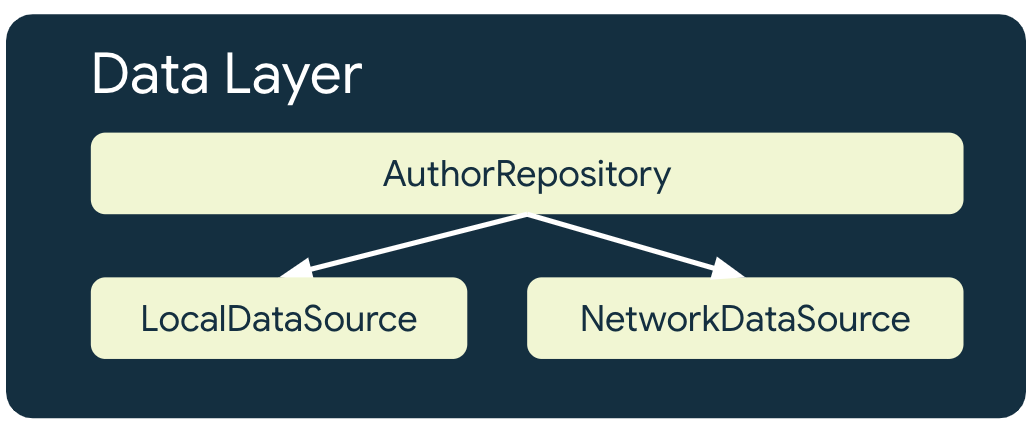
Локальный источник данных
Локальный источник данных является каноническим источником истины для приложения. Он должен быть эксклюзивным источником любых данных, которые считывают более высокие уровни приложения. Это обеспечивает согласованность данных между состояниями соединения. Локальный источник данных часто поддерживается хранилищем, сохраняемым на диске. Некоторые распространенные способы сохранения данных на диск:
- Структурированные источники данных, такие как реляционные базы данных, такие как Room .
- Неструктурированные источники данных. Например, буферы протоколов с Datastore.
- Простые файлы
Сетевой источник данных
Источник сетевых данных — это фактическое состояние приложения. Локальный источник данных в лучшем случае синхронизируется с сетевым источником данных. Оно также может отставать от него, и в этом случае приложение необходимо обновить, когда оно снова будет подключено к сети. И наоборот, сетевой источник данных может отставать от локального источника данных до тех пор, пока приложение не обновит его после восстановления подключения. Уровни домена и пользовательского интерфейса приложения никогда не должны напрямую взаимодействовать с сетевым уровнем. Ответственность за связь с ним и использование его для обновления локального источника данных лежит на хост- repository .
Раскрытие ресурсов
Локальные и сетевые источники данных могут существенно различаться в том, как ваше приложение может их читать и записывать. Запрос к локальному источнику данных может быть быстрым и гибким, например, при использовании запросов SQL. И наоборот, сетевые источники данных могут быть медленными и ограниченными, например, при постепенном доступе к ресурсам RESTful по идентификатору. В результате каждому источнику данных часто требуется собственное представление предоставляемых им данных. Таким образом, локальный источник данных и сетевой источник данных могут иметь свои собственные модели.
Структура каталогов ниже визуализирует эту концепцию. AuthorEntity — это представление автора, считываемое из локальной базы данных приложения, а NetworkAuthor представление автора, сериализованное по сети:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Ниже приведены сведения об AuthorEntity и NetworkAuthor :
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Рекомендуется хранить как AuthorEntity , так и NetworkAuthor внутри уровня данных и предоставлять третий тип для использования внешними уровнями. Это защищает внешние уровни от незначительных изменений в локальных и сетевых источниках данных, которые не меняют фундаментально поведение приложения. Это продемонстрировано в следующем фрагменте:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Затем сетевая модель может определить метод расширения для преобразования ее в локальную модель, а у локальной модели аналогичным образом есть метод для преобразования ее во внешнее представление, как показано ниже:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Читает
Чтение — это фундаментальная операция над данными приложения в автономном приложении. Поэтому вы должны убедиться, что ваше приложение может читать данные и что как только новые данные станут доступны, приложение сможет их отобразить. Приложение, которое может это сделать, является реактивным приложением , поскольку оно предоставляет API-интерфейсы чтения с наблюдаемыми типами.
В приведенном ниже фрагменте OfflineFirstTopicRepository возвращает Flows для всех своих API-интерфейсов чтения. Это позволяет ему обновлять свои считыватели при получении обновлений из сетевого источника данных. Другими словами, он позволяет OfflineFirstTopicRepository отправлять изменения, когда его локальный источник данных становится недействительным. Таким образом, каждый читатель OfflineFirstTopicRepository должен быть готов обрабатывать изменения данных, которые могут быть вызваны при восстановлении сетевого подключения к приложению. Более того, OfflineFirstTopicRepository считывает данные непосредственно из локального источника данных. Он может уведомлять своих читателей об изменениях данных только путем предварительного обновления локального источника данных.
class OfflineFirstTopicsRepository(
private val topicDao: TopicDao,
private val network: NiaNetworkDataSource,
) : TopicsRepository {
override fun getTopicsStream(): Flow<List<Topic>> =
topicDao.getTopicEntitiesStream()
.map { it.map(TopicEntity::asExternalModel) }
}
Стратегии обработки ошибок
Существуют уникальные способы обработки ошибок в автономных приложениях, в зависимости от источников данных, в которых они могут возникнуть. В следующих подразделах описываются эти стратегии.
Локальный источник данных
Ошибки при чтении из локального источника данных должны быть редкими. Чтобы защитить средства чтения от ошибок, используйте оператор catch в Flows , из которых средство чтения собирает данные.
Использование оператора catch в ViewModel выглядит следующим образом:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Сетевой источник данных
Если при чтении данных из сетевого источника данных возникают ошибки, приложению потребуется использовать эвристику, чтобы повторить попытку получения данных. Общие эвристики включают в себя:
Экспоненциальный откат
При экспоненциальной отсрочке приложение продолжает попытки чтения из сетевого источника данных с увеличивающимися интервалами времени до тех пор, пока оно не достигнет успеха или пока другие условия не заставят его остановиться.
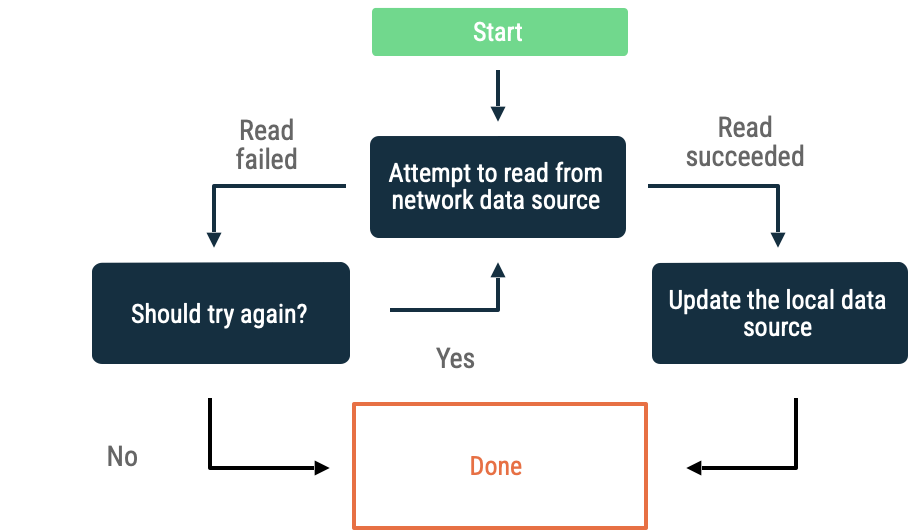
Критерии оценки того, должно ли приложение продолжать отключаться, включают в себя:
- Тип ошибки, указанный источником сетевых данных. Например, вам следует повторить сетевые вызовы, которые возвращают ошибку, указывающую на отсутствие подключения. И наоборот, не следует повторять несанкционированные HTTP-запросы, пока не будут доступны соответствующие учетные данные.
- Максимально допустимое количество повторов.
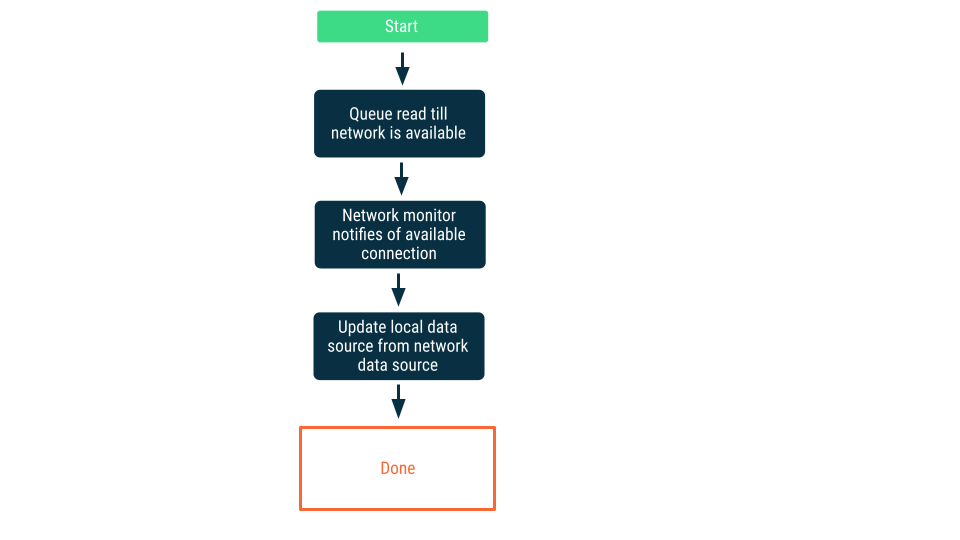
Мониторинг сетевого подключения
При таком подходе запросы на чтение ставятся в очередь до тех пор, пока приложение не убедится, что оно может подключиться к сетевому источнику данных. После установления соединения запрос на чтение выводится из очереди, данные считываются и локальный источник данных обновляется. В Android эта очередь может поддерживаться с помощью базы данных комнаты и очищаться как постоянная работа с помощью WorkManager.
Пишет
Хотя рекомендуемый способ чтения данных в автономном приложении — это использование наблюдаемых типов, эквивалентом API записи являются асинхронные API, такие как функции приостановки. Это позволяет избежать блокировки потока пользовательского интерфейса и помогает обрабатывать ошибки, поскольку запись в автономных приложениях может завершиться неудачно при пересечении границы сети.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
В приведенном выше фрагменте в качестве асинхронного API выбраны Coroutines, поскольку описанный выше метод приостанавливает работу.
Написание стратегий
При записи данных в автономных приложениях следует учитывать три стратегии. Какой выбор вы выберете, зависит от типа записываемых данных и требований приложения:
Пишет только онлайн
Попытайтесь записать данные через границу сети. В случае успеха обновите локальный источник данных, в противном случае создайте исключение и оставьте вызывающему объекту возможность отреагировать соответствующим образом.
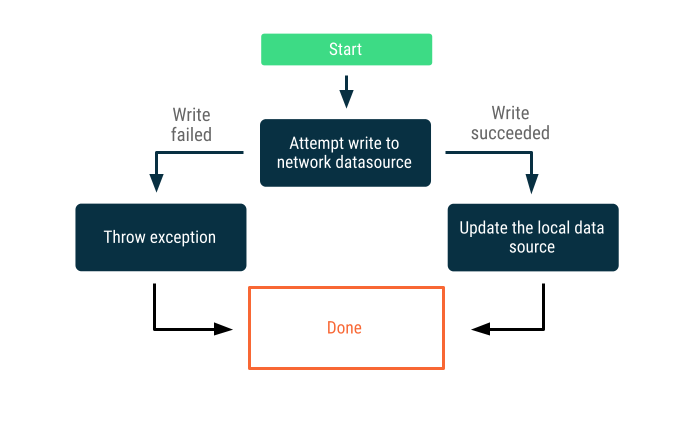
Эта стратегия часто используется для транзакций записи, которые должны происходить онлайн практически в реальном времени. Например, банковский перевод. Поскольку запись может завершиться неудачей, часто необходимо сообщить пользователю, что запись не удалась, или вообще запретить пользователю пытаться записать данные. Некоторые стратегии, которые вы можете использовать в этих сценариях, могут включать:
- Если приложению требуется доступ к Интернету для записи данных, оно может отказаться предоставлять пользователю пользовательский интерфейс, который позволяет пользователю записывать данные, или, по крайней мере, отключить его.
- Вы можете использовать всплывающее сообщение, которое пользователь не может закрыть, или временное приглашение, чтобы уведомить пользователя о том, что он находится в автономном режиме.
В очереди пишет
Если у вас есть объект, который вы хотите записать, вставьте его в очередь. Приступите к очистке очереди с экспоненциальным отключением, когда приложение снова подключится к сети. В Android очистка автономной очереди — это постоянная работа, которую часто делегируют WorkManager .
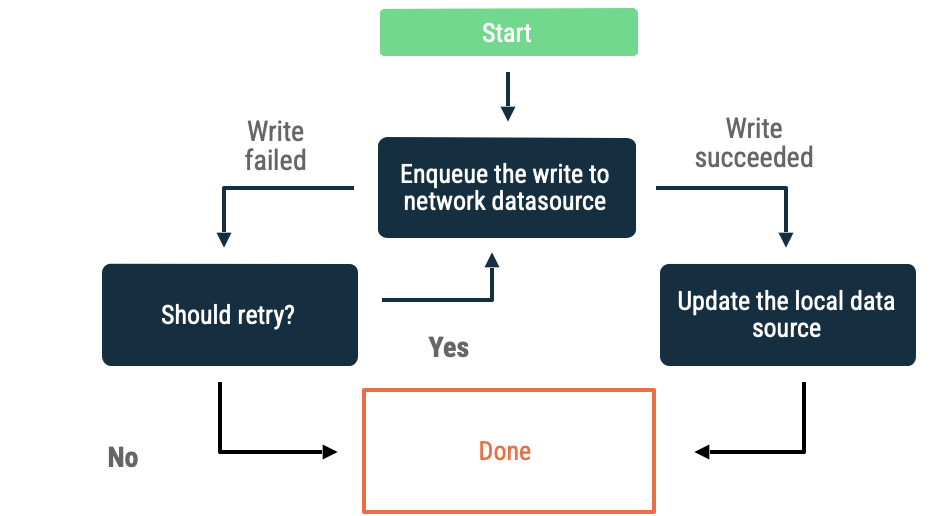
Этот подход является хорошим выбором, если:
- Не обязательно, чтобы данные когда-либо записывались в сеть.
- Транзакция не зависит от времени.
- Необязательно информировать пользователя в случае сбоя операции.
Варианты использования этого подхода включают события аналитики и ведение журналов.
Ленивый пишет
Сначала запишите в локальный источник данных, а затем поставьте запись в очередь, чтобы уведомить сеть при первой же возможности. Это нетривиально, поскольку могут возникнуть конфликты между сетью и локальными источниками данных, когда приложение снова подключается к сети. В следующем разделе, посвященном разрешению конфликтов, представлена более подробная информация.
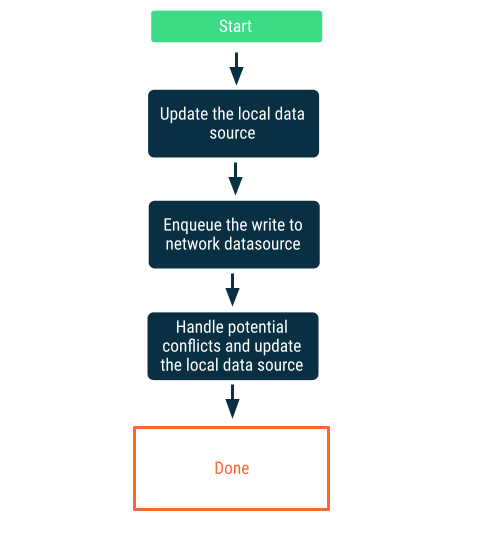
Этот подход является правильным выбором, когда данные имеют решающее значение для приложения. Например, в приложении со списком дел, ориентированном на офлайн-режим, важно, чтобы любые задачи, добавляемые пользователем в автономном режиме, сохранялись локально, чтобы избежать риска потери данных.
Синхронизация и разрешение конфликтов
Когда автономное приложение восстанавливает подключение, ему необходимо согласовать данные в своем локальном источнике данных с данными в сетевом источнике данных. Этот процесс называется синхронизацией . Существует два основных способа синхронизации приложения со своим сетевым источником данных:
- Синхронизация по запросу
- Push-синхронизация
Синхронизация по запросу
При синхронизации по запросу приложение подключается к сети для чтения последних данных приложения по требованию. Обычная эвристика для этого подхода основана на навигации, когда приложение извлекает данные только непосредственно перед их представлением пользователю.
Этот подход работает лучше всего, когда приложение ожидает короткие или промежуточные периоды отсутствия подключения к сети. Это связано с тем, что обновление данных является оппортунистическим, а длительные периоды отсутствия подключения увеличивают вероятность того, что пользователь попытается посетить целевые приложения приложения с устаревшим или пустым кешем.

Рассмотрим приложение, в котором токены страниц используются для извлечения элементов в бесконечном прокручиваемом списке для определенного экрана. Реализация может лениво подключаться к сети, сохранять данные в локальном источнике данных, а затем считывать их из локального источника данных, чтобы представить информацию обратно пользователю. В случае отсутствия сетевого подключения репозиторий может запрашивать данные только из локального источника данных. Это шаблон, используемый библиотекой подкачки Jetpack с ее API RemoteMediator .
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Преимущества и недостатки синхронизации по запросу приведены в таблице ниже:
| Преимущества | Недостатки |
|---|---|
| Относительно легко реализовать. | Склонен к интенсивному использованию данных. Это связано с тем, что повторные посещения пункта назначения навигации вызывают ненужную повторную выборку неизмененной информации. Вы можете смягчить это за счет правильного кэширования. Это можно сделать на уровне пользовательского интерфейса с помощью оператора cachedIn или на сетевом уровне с помощью HTTP-кэша. |
| Данные, которые не нужны, никогда не будут получены. | Плохо масштабируется с реляционными данными, поскольку полученная модель должна быть самодостаточной. Если синхронизируемая модель зависит от других моделей, которые необходимо выбрать для заполнения, упомянутая ранее проблема интенсивного использования данных станет еще более серьезной. Кроме того, это может вызвать зависимости между репозиториями родительской модели и репозиториями вложенной модели. |
Push-синхронизация
При принудительной синхронизации локальный источник данных пытается максимально имитировать набор реплик сетевого источника данных. Он заранее извлекает соответствующий объем данных при первом запуске, чтобы установить базовый уровень, после чего он полагается на уведомления с сервера, чтобы предупредить его, когда эти данные устарели.
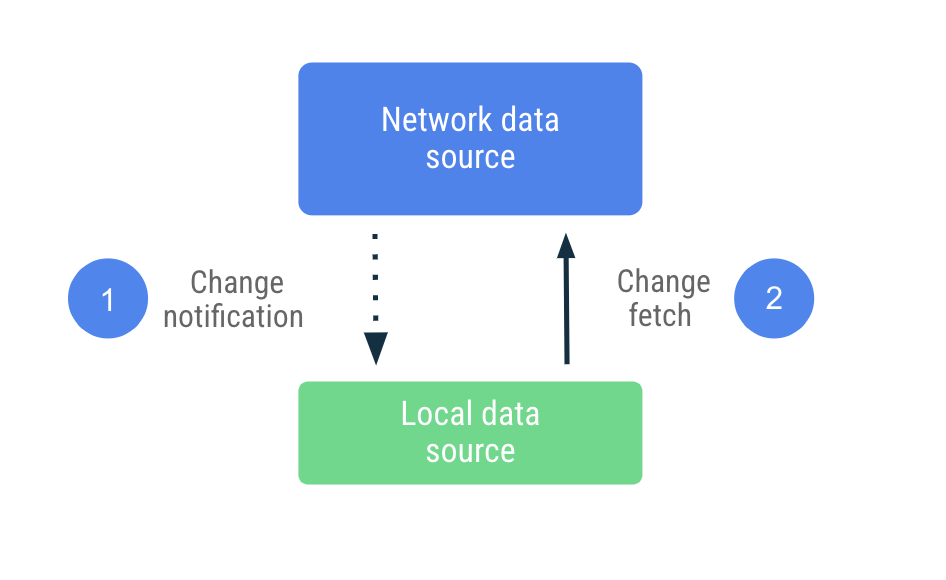
После получения уведомления об устаревании приложение обращается к сети, чтобы обновить только те данные, которые были помечены как устаревшие. Эта работа делегируется Repository , который обращается к сетевому источнику данных и сохраняет данные, полученные в локальном источнике данных. Поскольку репозиторий предоставляет свои данные наблюдаемым типам, читатели будут уведомлены о любых изменениях.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
При таком подходе приложение гораздо меньше зависит от источника сетевых данных и может работать без него в течение продолжительных периодов времени. Он предлагает доступ как для чтения, так и для записи в автономном режиме, поскольку предполагается, что он имеет самую свежую информацию из локального сетевого источника данных.
Преимущества и недостатки принудительной синхронизации приведены в таблице ниже:
| Преимущества | Недостатки |
|---|---|
| Приложение может оставаться офлайн на неопределенный срок. | Управление версиями данных для разрешения конфликтов нетривиально. |
| Минимальное использование данных. Приложение извлекает только изменившиеся данные. | Во время синхронизации необходимо учитывать проблемы записи. |
| Хорошо работает для реляционных данных. Каждый репозиторий отвечает только за выборку данных для модели, которую он поддерживает. | Источник сетевых данных должен поддерживать синхронизацию. |
Гибридная синхронизация
Некоторые приложения используют гибридный подход, основанный на извлечении или отправке в зависимости от данных. Например, приложение для социальных сетей может использовать синхронизацию по запросу для получения следующего канала пользователя по требованию из-за высокой частоты обновлений канала. То же приложение может использовать push-синхронизацию для данных о вошедшем в систему пользователе, включая его имя пользователя, изображение профиля и т. д.
В конечном итоге выбор синхронизации в автономном режиме зависит от требований к продукту и доступной технической инфраструктуры.
Разрешение конфликтов
Если приложение записывает данные локально в автономном режиме, которые не совпадают с сетевым источником данных, это означает, что произошел конфликт, который необходимо разрешить, прежде чем можно будет выполнить синхронизацию.
Разрешение конфликтов часто требует управления версиями. Приложению потребуется вести учет, чтобы отслеживать, когда происходили изменения. Это позволяет ему передавать метаданные в сетевой источник данных. В этом случае сетевой источник данных несет ответственность за предоставление абсолютного источника истины. Существует широкий спектр стратегий разрешения конфликтов, в зависимости от потребностей приложения. Для мобильных приложений распространен подход «побеждает последняя запись».
Последняя запись побеждает
При таком подходе устройства присоединяют метаданные метки времени к данным, которые они записывают в сеть. Когда сетевой источник данных получает их, он отбрасывает все данные старше текущего состояния и принимает данные, более новые, чем его текущее состояние.
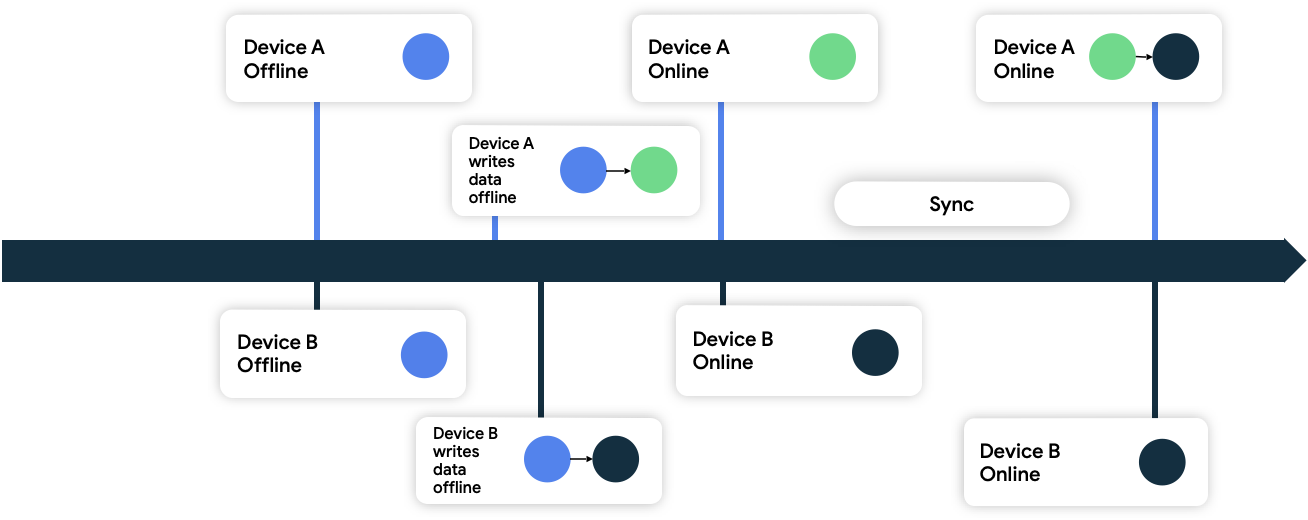
В приведенном выше примере оба устройства находятся в автономном режиме и изначально синхронизированы с сетевым источником данных. В автономном режиме они записывают данные локально и отслеживают время записи данных. Когда они оба снова подключаются к сети и синхронизируются с сетевым источником данных, сеть разрешает конфликт, сохраняя данные с устройства B, поскольку оно записало свои данные позже.
WorkManager в автономных приложениях
В описанных выше стратегиях чтения и записи использовались две общие утилиты:
- Очереди
- Чтение: используется для отсрочки чтения до тех пор, пока не станет доступно сетевое подключение.
- Запись: используется для отсрочки записи до тех пор, пока не станет доступно сетевое подключение, а также для запроса записи для повторных попыток.
- Мониторы сетевого подключения
- Чтение: используется в качестве сигнала для очистки очереди чтения при подключении приложения и для синхронизации.
- Запись: используется в качестве сигнала для очистки очереди записи при подключении приложения и для синхронизации.
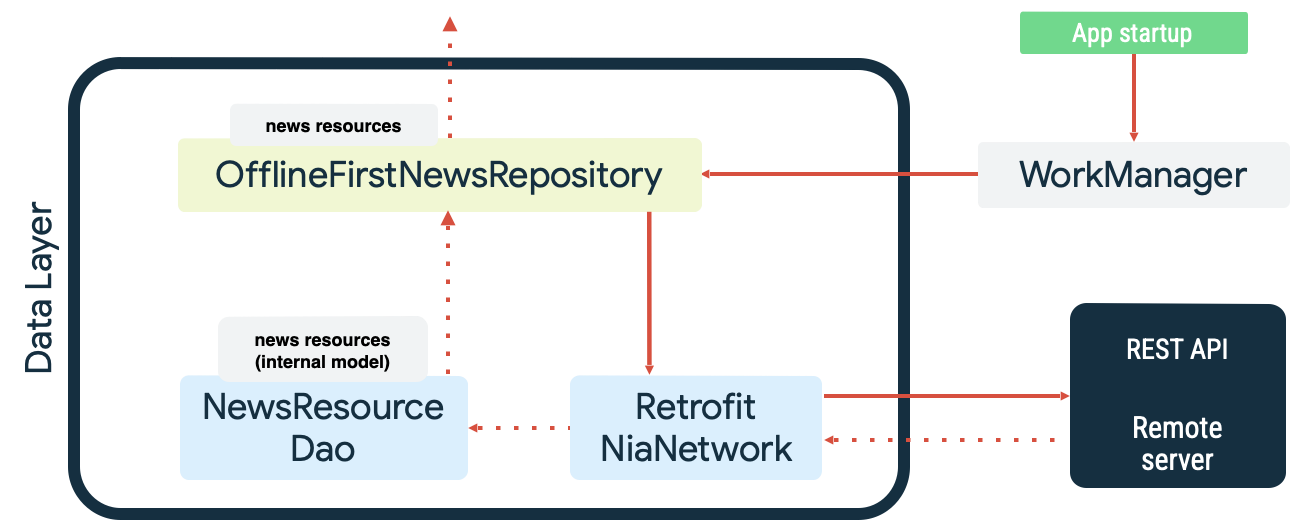
Оба случая являются примерами упорной работы , в которой WorkManager превосходно справляется. Например, в примере приложения «Сейчас в Android» WorkManager используется как очередь чтения и сетевой монитор при синхронизации локального источника данных. При запуске приложение выполняет следующие действия:
- Поставьте в очередь синхронизацию чтения, чтобы убедиться в наличии четности между локальным источником данных и сетевым источником данных.
- Очистите очередь синхронизации чтения и начните синхронизацию, когда приложение находится в сети.
- Выполните чтение из сетевого источника данных, используя экспоненциальную задержку.
- Сохраняйте результаты чтения в локальном источнике данных, разрешая любые конфликты, которые могут возникнуть.
- Предоставьте данные из локального источника данных для использования другими уровнями приложения.
Вышеизложенное проиллюстрировано на схеме ниже:
За этим следует постановка работы синхронизации с WorkManager путем указания ее как уникальной работы с помощью KEEP ExistingWorkPolicy :
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
Где SyncWorker.startupSyncWork() определяется следующим образом:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
В частности, Constraints , определенные SyncConstraints требуют, чтобы NetworkType был NetworkType.CONNECTED . То есть он ждет, пока сеть станет доступной, прежде чем запуститься.
Как только сеть становится доступной, Worker очищает уникальную рабочую очередь, указанную в SyncWorkName путем делегирования ее соответствующим экземплярам Repository . Если синхронизация не удалась, метод doWork() возвращает Result.retry() . WorkManager автоматически повторит попытку синхронизации с экспоненциальной задержкой. В противном случае он возвращает Result.success() завершая синхронизацию.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Образцы
Следующие примеры Google демонстрируют приложения, ориентированные на офлайн-режим. Изучите их, чтобы увидеть это руководство на практике:
Рекомендуется для вас
- Примечание: текст ссылки отображается, когда JavaScript отключен.
- Создание состояния пользовательского интерфейса
- Уровень пользовательского интерфейса
- Уровень данных