
Une application orientée hors connexion est capable d'exécuter l'intégralité ou un sous-ensemble de ses fonctionnalités de base sans accès à Internet. Autrement dit, elle peut réaliser tout ou partie de sa logique métier hors connexion.
Les considérations liées à la création d'une application orientée hors connexion commencent dans la couche de données, qui permet d'accéder aux données d'application et à la logique métier. De temps en temps, l'application peut avoir besoin d'actualiser ces données à partir de sources externes à l'appareil. Ce faisant, elle est amenée à appeler des ressources réseau pour assurer sa mise à jour.
La disponibilité du réseau n'est pas toujours garantie. Les appareils présentent généralement des périodes de connexion réseau irrégulières ou lentes. Les utilisateurs peuvent rencontrer les problèmes suivants :
- Bande passante Internet limitée
- Interruptions de connexion transitoires (par exemple, dans un ascenseur ou un tunnel)
- Accès occasionnel aux données (par exemple, les tablettes équipées uniquement du Wi-Fi)
Quelle qu'en soit la raison, il est souvent possible qu'une application fonctionne de manière adéquate dans ces circonstances. Pour garantir son fonctionnement hors connexion, l'application doit pouvoir effectuer les opérations suivantes :
- Rester utilisable en l'absence d'une connexion réseau fiable
- Présenter immédiatement aux utilisateurs les données locales au lieu d'attendre que le premier appel réseau se termine ou échoue
- Récupérer les données en tenant compte de la batterie et de l'état des données (par exemple, en ne demandant des récupérations de données que des conditions optimales lors de la recharge ou d'une connexion à un réseau Wi-Fi)
Lorsqu'une application répond à ces critères, on la qualifie souvent d'« application orientée hors connexion ».
Créer une application orientée hors connexion
Lorsque vous concevez une application orientée hors connexion, commencez dans la couche de données et tenez compte des deux principales opérations réalisables sur les données de l'application :
- Lecture : récupération de données à utiliser par d'autres parties de l'application, par exemple pour afficher des informations à l'utilisateur. Dans Compose, vous y parvenez généralement en observant l'état. Lorsque votre UI observe la source de données locale en tant qu'état, l'écran reflète automatiquement les dernières données locales.
- Écriture : enregistrement persistant des entrées utilisateur pour une récupération ultérieure. Dans Compose, vous y parvenez généralement à l'aide d'événements et d'actions envoyés depuis l'UI vers le ViewModel.
Les dépôts de la couche de données combinent les sources d'informations pour fournir des données d'application. Une application orientée hors connexion doit disposer d'au moins une source de données qui n'a pas besoin d'un accès réseau pour effectuer ses tâches les plus critiques. L'une de ces tâches essentielles consiste à lire des données.
Modéliser les données d'une application orientée hors connexion
Une application orientée hors connexion dispose d'au moins deux sources de données pour chaque dépôt qui utilise des ressources réseau :
- La source de données locale
- La source de données réseau
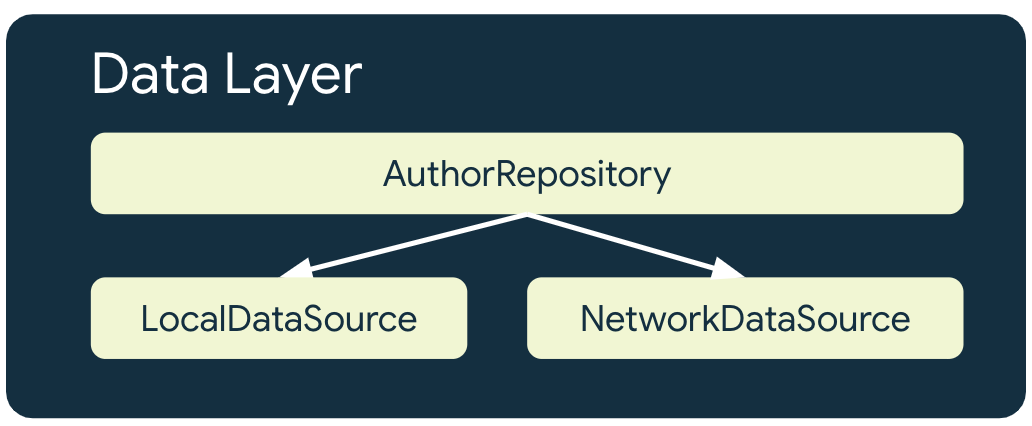
La source de données locale
La source de données locale constitue la source fiable de l'application. Il doit s'agir de la source exclusive de toutes les données lues par les couches supérieures de l'application. Cela garantit la cohérence des données entre les états de connexion. La source de données locale est souvent sauvegardée sur disque. Voici quelques méthodes couramment utilisées à cet effet :
- Sources de données structurées (par exemple, des bases de données relationnelles comme Room)
- Sources de données non structurées (par exemple, des tampons de protocole avec DataStore)
- Fichiers simples
La source de données réseau
La source de données réseau correspond à l'état réel de l'application. Au mieux, la source de données locale est synchronisée avec la source de données réseau. La source de données locale peut également être en retard par rapport à la source de données réseau, auquel cas l'application doit être mise à jour une fois de nouveau en ligne. Inversement, la source de données réseau peut être en retard par rapport à la source de données locale jusqu'à ce que l'application puisse la mettre à jour lorsque la connectivité est restaurée. Les couches de domaine et d'UI de l'application ne doivent jamais communiquer directement avec la couche réseau. Il appartient au repository d'hébergement de communiquer avec elle et de l'utiliser pour mettre à jour la source de données locale.
Exposer des ressources
Les sources de données locale et réseau peuvent présenter des différences fondamentales dans la manière dont votre application les lit et les écrit. L'interrogation d'une source de données locale peut être rapide et flexible, par exemple lors de l'utilisation de requêtes SQL. À l'inverse, les sources de données réseau peuvent être lentes et limitées, par exemple lors de l'accès incrémentiel aux ressources RESTful par ID. Par conséquent, chaque source de données a souvent besoin de sa propre représentation des données qu'elle fournit. La source de données locale et la source de données réseau peuvent donc avoir leurs propres modèles.
La structure de répertoire suivante permet de visualiser ce concept. L'AuthorEntity représente un auteur lu à partir de la base de données locale de l'application, tandis que le NetworkAuthor représente un auteur sérialisé sur le réseau :
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
Voici les détails d'AuthorEntity et de NetworkAuthor :
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Il est recommandé de garder l'AuthorEntity et l'NetworkAuthor internes dans la couche de données, et d'exposer un troisième type de données pour que les couches externes soient utilisées. Cette approche protège les couches externes contre les modifications mineures des sources de données locale et réseau qui ne modifient pas fondamentalement le comportement de l'application. En voici une illustration :
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Le modèle réseau peut ensuite définir une méthode d'extension pour le convertir en modèle local. De même, le modèle local en possède une pour le convertir en représentation externe, comme indiqué dans l'extrait suivant :
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Lecture
Les lectures forment l'opération fondamentale des données d'une application orientée hors connexion. Vous devez donc vous assurer que votre application peut lire les données et qu'elle est en mesure de les afficher dès que de nouvelles informations sont disponibles. Vous pouvez utiliser à cet effet une application réactive, qui expose des API de lecture avec des types observables.
Dans l'extrait suivant, OfflineFirstTopicRepository renvoie les Flow pour toutes ses API de lecture. Cela lui permet de mettre à jour ses lecteurs lorsqu'elle reçoit des mises à jour de la source de données réseau. En d'autres termes, l'envoi de modifications OfflineFirstTopicRepository est autorisé lorsque sa source de données locale est invalidée. Par conséquent, chaque lecteur de OfflineFirstTopicRepository doit être prêt à gérer les modifications de données pouvant être déclenchées lorsque la connectivité réseau est restaurée dans l'application. De plus, OfflineFirstTopicRepository lit les données directement à partir de la source de données locale. Pour que les lecteurs puissent être informés des modifications de données, une mise à jour de la source de données locale est nécessaire en amont.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
Dans une application Jetpack Compose, utilisez un ViewModel pour faire le lien entre la couche de données et l'UI.
Dans le ViewModel, convertissez le Flow en StateFlow à l'aide de l'opérateur stateIn. Les composables collectent ensuite ces états à l'aide de collectAsStateWithLifecycle() et gèrent automatiquement les abonnements de manière à tenir compte du cycle de vie.
Pour en savoir plus sur collectAsStateWithLifecycle(), consultez États et Jetpack Compose.
Stratégies de traitement des erreurs
Il existe des méthodes uniques pour gérer les exceptions dans les applications orientées hors connexion, en fonction des sources de données où elles se produisent. Les sous-sections suivantes décrivent ces stratégies.
Source de données locale
Essayez de minimiser les erreurs lors de la lecture à partir de la source de données locale. Pour en prémunir les lecteurs, utilisez l'opérateur catch sur les Flow à partir desquels ils collectent des données.
Voici comment utiliser l'opérateur catch dans un ViewModel :
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Pour une approche plus résiliente, envisagez une solution LCE (Loading Content Error). Dans LCE, lorsqu'une erreur se produit lors de la lecture, vous affichez un état d'erreur. En général, vous obtenez LCE en modélisant les états de l'UI sous forme de classes scellées Kotlin.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Source de données réseau
Si des erreurs se produisent lors de la lecture de données à partir d'une source réseau, l'application doit utiliser une heuristique pour essayer de récupérer à nouveau les données. Voici quelques exemples d'heuristiques courantes :
Intervalle exponentiel entre les tentatives
En mode d'intervalle exponentiel entre les tentatives, l'application continue de lire la source de données réseau avec des intervalles de temps croissants jusqu'à ce qu'elle aboutisse ou jusqu'à ce que d'autres conditions imposent son arrêt.
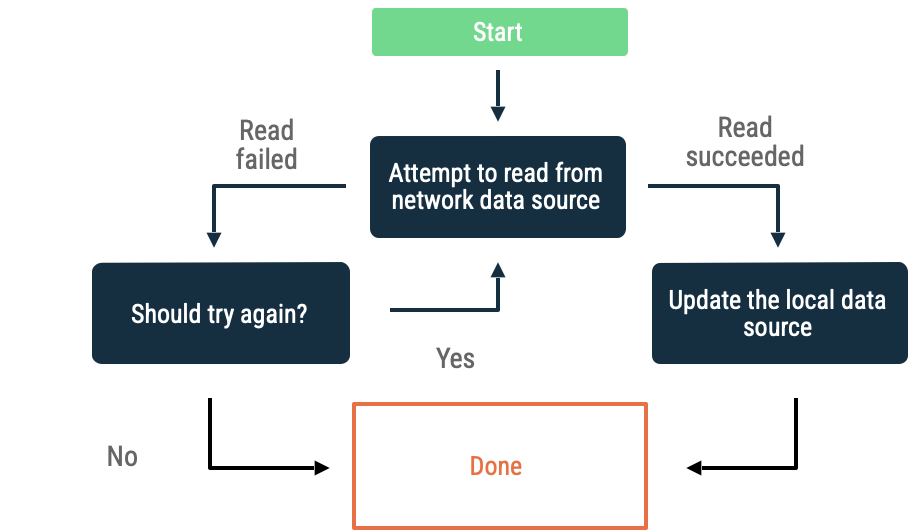
Pour évaluer si l'application doit poursuivre ses tentatives, voici les critères à respecter :
- Le type d'erreur indiqué par la source de données réseau. Par exemple, relancez les appels réseau qui renvoient une erreur indiquant un manque de connectivité. Ne relancez pas les requêtes HTTP sans autorisation tant que les identifiants appropriés ne sont pas disponibles.
- Le nombre maximal de tentatives autorisé.
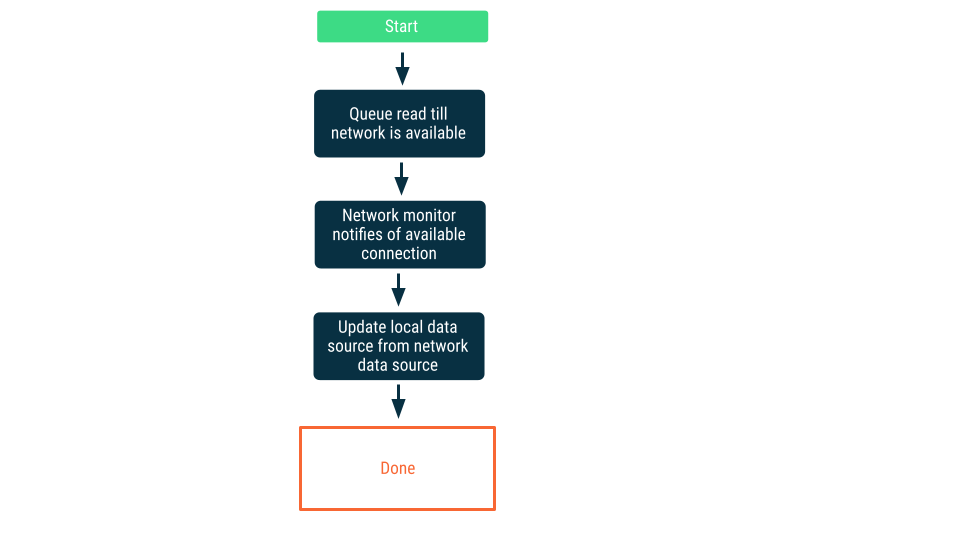
Surveillance de la connectivité réseau
Cette approche place les requêtes de lecture en file d'attente jusqu'à ce que l'application soit certaine de pouvoir se connecter à la source de données réseau. Une fois la connexion établie, la requête de lecture est retirée de la file d'attente, les données sont lues et la source de données locale est mise à jour. Sur Android, cette file d'attente peut être gérée avec une base de données Room et déchargée en tant que tâche persistante à l'aide de WorkManager.
Écritures
Bien que la méthode recommandée pour lire des données dans une application orientée hors connexion consiste à utiliser des types observables, l'équivalent des API d'écriture est l'utilisation d'API asynchrones, telles que les fonctions de suspension. Cela évite le blocage du thread UI et facilite la gestion des exceptions, car les écritures dans les applications hors connexion peuvent échouer en cas de dépassement d'une limite du réseau.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
Dans l'extrait de code précédent, l'API asynchrone choisie est Coroutines, puisque cette méthode suspend.
Écrire des stratégies
Trois stratégies sont à prendre en compte lorsque vous écrivez des données dans des applications orientées hors connexion. L'option que vous choisissez dépend du type de données en cours d'écriture et des exigences de l'application :
Écritures en ligne uniquement
Tentative d'écriture de données au-delà des limites du réseau. Si l'opération réussit, elle met à jour la source de données locale. Sinon, elle génère une exception et laisse à l'appelant le soin de répondre correctement.
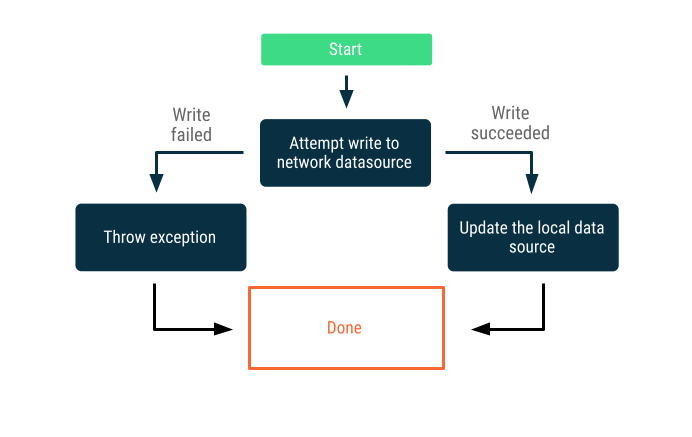
Cette stratégie est souvent utilisée pour les transactions d'écriture qui doivent se produire en ligne en temps quasi réel, par exemple un virement bancaire. Étant donné que les écritures peuvent échouer, il est souvent nécessaire de communiquer cet échec à l'utilisateur ou d'empêcher celui-ci d'essayer d'écrire des données. Voici quelques stratégies que vous pouvez adopter dans ces scénarios :
- Si une application nécessite un accès à Internet pour écrire des données, vous pouvez choisir de ne pas présenter à l'utilisateur l'UI d'écriture de données, ou tout au moins de la désactiver.
- Vous pouvez utiliser un
AlertDialogque l'utilisateur ne peut pas ignorer ou unSnackbarpour avertir l'utilisateur qu'il est hors connexion.
Opérations d'écriture en file d'attente
Si vous avez un objet à écrire, insérez-le dans une file d'attente. Lorsque l'application est de nouveau en ligne, videz la file d'attente en appliquant un intervalle exponentiel entre les tentatives. Sur Android, le déchargement d'une file d'attente hors connexion est une tâche persistante, souvent déléguée à WorkManager.
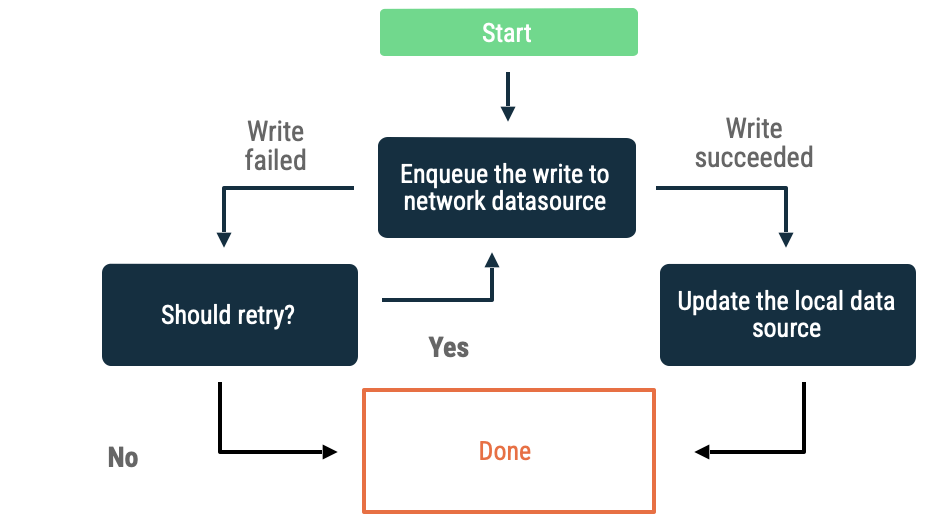
Cette approche est pertinente dans les cas suivants :
- Il n'est pas indispensable que les données soient écrites sur le réseau.
- La transaction n'est pas urgente.
- Il n'est pas indispensable d'informer l'utilisateur si l'opération échoue.
Cette méthode peut être utilisée, entre autres, pour les événements d'analyse et la journalisation.
Opérations d'écriture différées
Écrivez d'abord sur la source de données locale, puis mettez l'écriture en file d'attente pour avertir le réseau dès que possible. Cette situation n'est pas simple, car il existe des conflits entre le réseau et les sources de données locales lorsque l'application est de nouveau en ligne. La section suivante sur la résolution des conflits fournit plus de détails à cet égard.
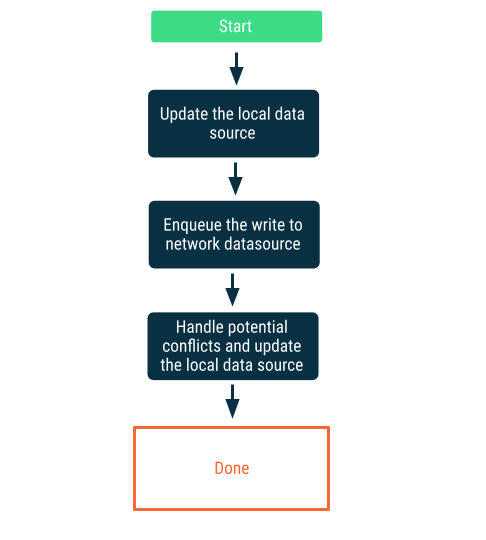
Cette approche est pertinente lorsque les données sont essentielles à l'application. Par exemple, dans une application de liste de tâches orientée hors connexion, il est indispensable que toutes les tâches que l'utilisateur ajoute hors connexion soient stockées localement pour éviter tout risque de perte de données.
Synchronisation et résolution des conflits
Lorsqu'une application orientée hors connexion rétablit sa connectivité, elle doit veiller au rapprochement entre les données de sa source locale et celles de sa source réseau. Ce processus est appelé synchronisation. Une application peut se synchroniser avec sa source de données réseau de deux manières :
- Synchronisation pull
- Synchronisation push
Synchronisation pull
Lors d'une synchronisation pull, l'application contacte le réseau pour lire les dernières données d'application à la demande. Une heuristique courante pour cette approche est basée sur la navigation, où l'application récupère les données juste avant de les présenter à l'utilisateur.
Cette méthode fonctionne mieux lorsque l'application prévoit des périodes courtes à intermédiaires sans connexion réseau. En effet, l'actualisation des données est opportuniste, et de longues périodes d'absence de connectivité augmentent les chances que l'utilisateur tente d'accéder aux destinations des applications avec un cache obsolète ou vide.
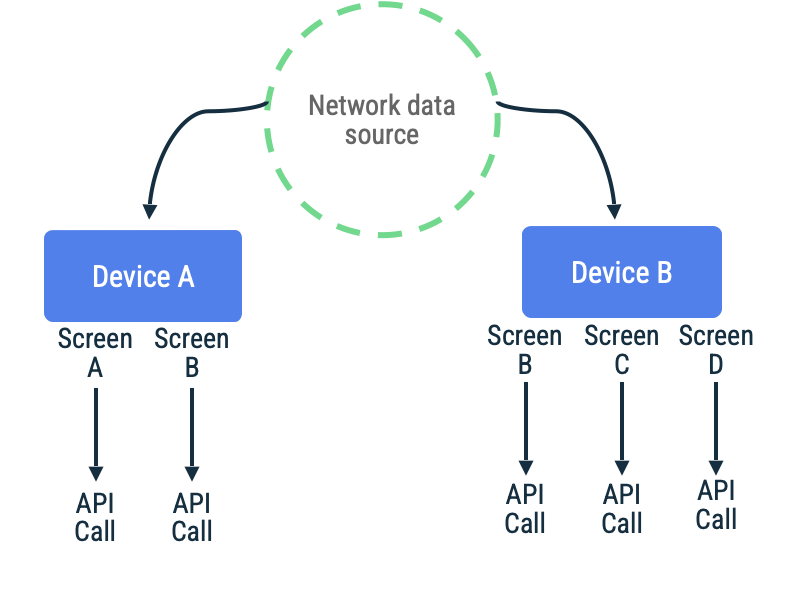
Prenons l'exemple d'une application qui utilise des jetons de page pour extraire des éléments d'une liste à défilement infini pour un écran particulier. L'implémentation peut contacter le réseau de manière différée, conserver les données dans la source de données locale, puis les lire à partir de la source de données locale pour présenter des informations à l'utilisateur. En l'absence de connectivité réseau, le dépôt peut uniquement demander des données à la source de données locale. Il s'agit du modèle utilisé par la bibliothèque Jetpack Paging avec son API RemoteMediator.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Le tableau suivant récapitule les avantages et les inconvénients de la synchronisation pull :
| Avantages | Inconvénients |
|---|---|
| Relativement simple à mettre en œuvre. | Méthode sujette à une utilisation intensive des données. En effet, les visites répétées vers une destination de navigation déclenchent la récupération inutile d'informations inchangées. Pour y remédier, utilisez une mise en cache adéquate. Vous pouvez le faire dans la couche de l'UI avec l'opérateur cachedIn ou dans la couche réseau à l'aide d'un cache HTTP. |
| Les données inutiles ne sont jamais récupérées. | Se prête mal aux données relationnelles, car le modèle extrait doit être suffisamment autonome. Si le modèle en cours de synchronisation dépend d'autres modèles devant être récupérés pour se remplir, le problème d'utilisation intensive des données mentionné précédemment devient encore plus important. En outre, cela peut entraîner des dépendances entre les dépôts du modèle parent et ceux du modèle imbriqué. |
Synchronisation push
Lors d'une synchronisation push, la source de données locale tente d'imiter au mieux un ensemble d'instances dupliquées de la source de données réseau. Elle extrait de manière proactive une quantité appropriée de données au premier démarrage pour définir une référence. Ensuite, elle s'appuie sur les notifications du serveur pour l'avertir lorsque ces données sont obsolètes.
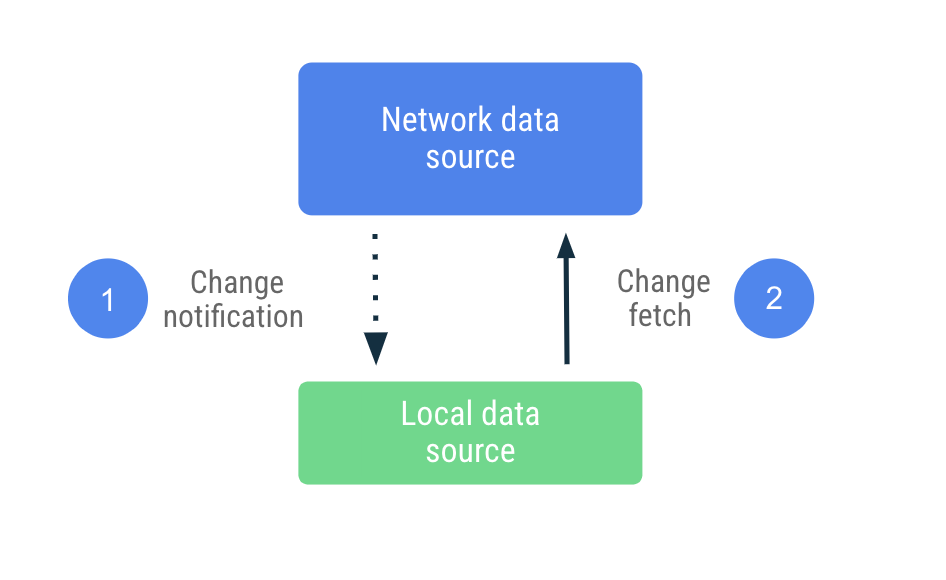
À réception de la notification, l'application contacte le réseau pour ne mettre à jour que les données marquées comme non actualisées. Cette tâche est déléguée au Repository, qui contacte la source de données réseau et conserve les données extraites vers la source de données locale. Comme le dépôt expose ses données avec des types observables, les lecteurs sont avertis de toute modification.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
Grâce à cette approche, l'application est beaucoup moins dépendante de la source de données réseau et peut fonctionner sans elle pendant de longues périodes. Cette méthode offre un accès en lecture et en écriture hors connexion, car elle suppose que les informations les plus récentes proviennent localement de la source de données réseau.
Le tableau suivant récapitule les avantages et les inconvénients de la synchronisation push :
| Avantages | Inconvénients |
|---|---|
| L'application peut rester hors connexion indéfiniment. | Les données de gestion des versions pour la résolution des conflits sont complexes. |
| Consommation de données minimale. L'application ne récupère que les données qui ont changé. | Vous devez prendre en compte les éventuels problèmes d'écriture lors de la synchronisation. |
| Parfaitement adapté aux données relationnelles. Chaque dépôt est responsable de la récupération des données uniquement pour le modèle qu'il accepte. | La source de données réseau doit être compatible avec la synchronisation. |
Synchronisation hybride
Certaines applications utilisent une approche hybride pull ou push en fonction des données. Par exemple, une application de réseaux sociaux peut utiliser la synchronisation pull pour récupérer à la demande le flux des suivis de l'utilisateur en raison de la fréquence élevée des mises à jour. La même application peut choisir d'utiliser la synchronisation push pour les données concernant l'utilisateur connecté, y compris son nom d'utilisateur, sa photo de profil, etc.
Enfin, le choix de la synchronisation hors connexion dépend des exigences du produit et de l'infrastructure technique disponible.
Résolution de conflit
Si, en mode hors connexion, l'application écrit des données localement qui ne correspondent pas à la source de données réseau, vous devez résoudre le conflit pour que la synchronisation puisse avoir lieu.
La résolution des conflits nécessite souvent une gestion des versions. L'application doit effectuer des archivages pour savoir quand des modifications se sont produites, afin de pouvoir transmettre les métadonnées à la source de données réseau. Il incombe alors à la source de données réseau de fournir la source absolue de vérité. Vous pouvez envisager de nombreuses stratégies pour résoudre les conflits, en fonction des besoins de l'application. Pour les applications mobiles, une approche courante consiste à juger que "la dernière écriture l'emporte".
La dernière écriture l'emporte
Dans cette approche, les appareils associent des métadonnées d'horodatage aux données qu'ils écrivent sur le réseau. Lorsque la source de données réseau les reçoit, elle élimine toutes les données antérieures à son état actuel, tout en acceptant celles qui sont plus récentes.
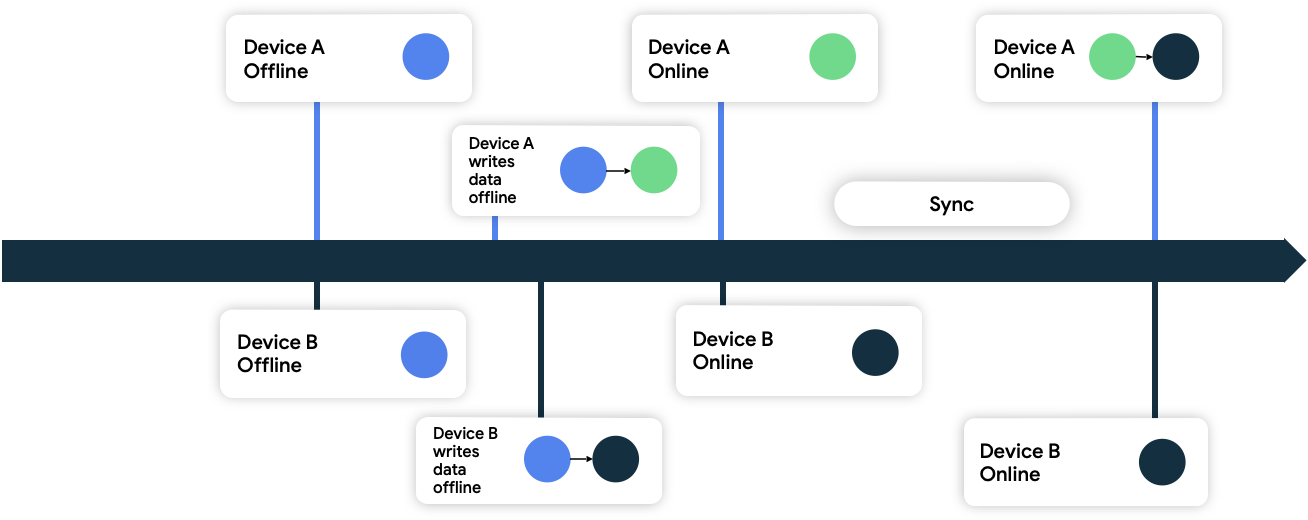
Dans la figure 9, les deux appareils sont hors connexion et sont initialement synchronisés avec la source de données réseau. En mode hors connexion, ils écrivent les données localement et suivent l'heure à laquelle ils ont écrit leurs données. Lorsqu'ils se reconnectent et se synchronisent avec la source de données réseau, le réseau résout le conflit en conservant les données de l'appareil B, car il a écrit ses données en dernier.
WorkManager dans les applications orientées hors connexion
Les stratégies de lecture et d'écriture décrites précédemment comportent deux utilitaires courants :
- Files d'attente
- Lecture : permet de différer les lectures jusqu'à ce que la connectivité réseau soit disponible.
- Écriture : permet de différer les écritures jusqu'à ce que la connectivité réseau soit disponible, ainsi que de remettre les écritures en file d'attente en cas de nouvelles tentatives.
- Surveillance de la connectivité réseau
- Lecture : utilisée pour signaler le déchargement de la file d'attente de lecture lorsque l'application est connectée, ainsi que pour la synchronisation.
- Écritures : utilisées pour signaler le déchargement de la file d'attente d'écriture lorsque l'application est connectée, ainsi que pour la synchronisation.
Les deux cas sont des exemples de tâche persistante dans lesquels WorkManager excelle. Ainsi, dans l'application exemple Now in Android, WorkManager est utilisé à la fois comme file d'attente de lecture et comme dispositif de surveillance réseau lors de la synchronisation de la source de données locale. Au démarrage, l'application effectue les opérations suivantes :
- Mise en file d'attente des tâches de synchronisation de lecture pour confirmer la parité entre la source de données locale et la source de données réseau.
- Décharge la file d'attente de synchronisation de lecture et lance la synchronisation lorsque l'application est en ligne.
- Lecture à partir de la source de données réseau en utilisant un intervalle exponentiel entre les tentatives.
- Conservation des résultats de la lecture dans la source de données locale et résolution des éventuels conflits.
- Exposition des données de la source de données locale pour que les autres couches de l'application les consomment.
Ces actions sont illustrées dans le diagramme suivant :
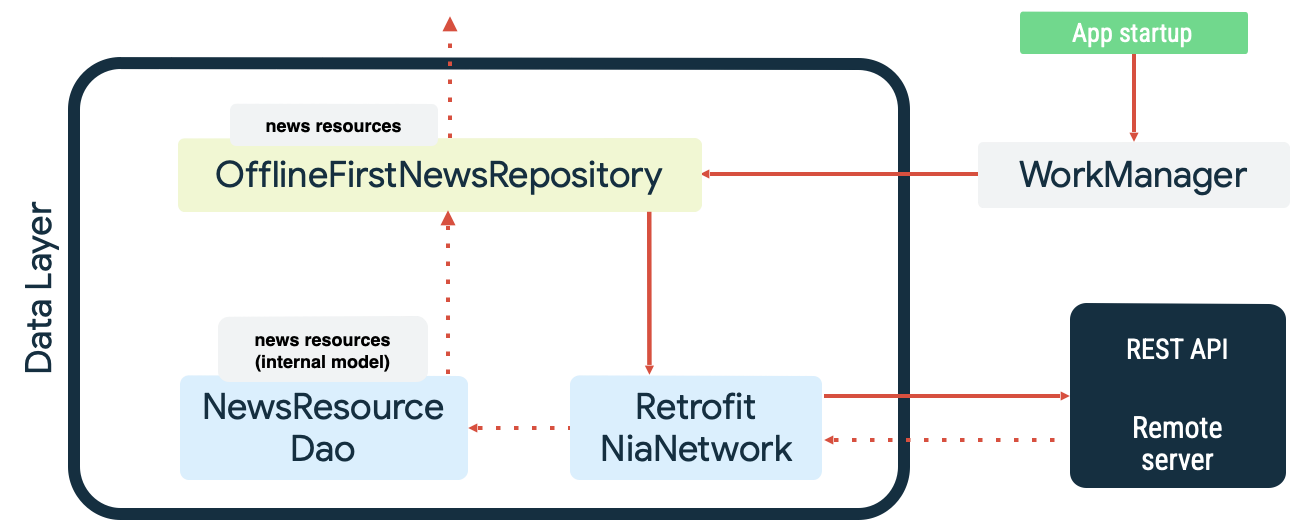
La mise en file d'attente de la tâche de synchronisation avec WorkManager se définit comme une tâche unique avec la ExistingWorkPolicy KEEP :
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() est défini comme suit :
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Plus précisément, les Constraints définies par SyncConstraints exigent que le NetworkType soit NetworkType.CONNECTED. Autrement dit, elles attendent que le réseau soit disponible avant de s'exécuter.
Une fois le réseau disponible, le nœud de calcul décharge la file d'attente de tâche unique spécifiée par le SyncWorkName en déléguant l'accès aux instances Repository appropriées. Si la synchronisation échoue, la méthode doWork() renvoie Result.retry(). WorkManager relance automatiquement la synchronisation avec un intervalle exponentiel entre les tentatives. Sinon, il renvoie Result.success() pour terminer la synchronisation.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Exemples
Les exemples Google suivants illustrent des applications orientées hors connexion. Parcourez-les pour voir ces conseils en pratique :
Recommandations personnalisées
- Remarque : Le texte du lien s'affiche lorsque JavaScript est désactivé
- Production de l'état de l'interface utilisateur
- Couche d'interface utilisateur
- Couche de données