
A arquitetura de apps é a base de um app Android de alta qualidade. Uma arquitetura bem definida permite criar um app escalonável e fácil de manter que pode se adaptar ao ecossistema cada vez maior de dispositivos Android, incluindo smartphones, tablets, dobráveis, dispositivos ChromeOS, telas de carro e XR.
Composição de apps
Um app Android típico é composto por vários componentes de app, como serviços, provedores de conteúdo e broadcast receivers. Esses componentes são declarados no manifesto do app.
A interface do usuário de um app também é um componente. Historicamente, as UIs eram criadas usando várias atividades. No entanto, os apps modernos usam uma arquitetura de atividade única. Um único Activity serve como um contêiner para
telas ou destinos do Jetpack Compose.
Vários formatos
Os apps podem ser executados em vários formatos, incluindo não apenas smartphones, mas também tablets, dispositivos dobráveis, dispositivos ChromeOS e muito mais. Não presuma que o app sempre vai ficar fixo na orientação retrato ou paisagem. Mudanças de configuração, como rotação do dispositivo ou dobrar e desdobrar um dispositivo dobrável, forçam o app a recompor a interface, o que afeta o estado do app.
Restrições de recursos
Os dispositivos móveis, mesmo os de tela grande, têm recursos limitados. Por isso, o sistema operacional pode interromper o processo do app a qualquer momento para dar os recursos dele a outros processos.
Condições de lançamento de variáveis
Em um ambiente com poucos recursos, os componentes do app podem ser iniciados individualmente e fora de ordem. Além disso, o sistema operacional ou o usuário podem destruí-los a qualquer momento. Por isso, não armazene dados ou estados de aplicativos nos componentes do app. Faça com que os componentes do app sejam independentes uns dos outros.
Princípios arquitetônicos comuns
Se não é recomendável usar componentes do app para armazenar dados e estados, qual é a melhor forma de criar um app?
Conforme os apps para Android aumentam de tamanho, é importante definir uma arquitetura que permita o escalonamento. Uma arquitetura de app bem projetada define os limites entre as partes do app e as responsabilidades de cada uma.
Separação de conceitos
Crie a arquitetura do app para seguir alguns princípios específicos.
O princípio mais importante é a separação de conceitos: separar o app em métodos, classes, arquivos, pacotes, módulos e camadas que têm responsabilidades e limites claramente definidos.
É um erro comum escrever todo o código em um Activity.
A função principal de um Activity é hospedar a interface do usuário do app. O SO Android controla o ciclo de vida delas, destruindo e recriando com frequência em resposta a ações do usuário, como rotação da tela, ou eventos do sistema, como pouca memória.
Essa natureza efêmera os torna inadequados para armazenar dados ou estados de aplicativos. Se você armazenar dados em um Activity, eles serão perdidos quando
o componente for recriado. Para garantir a persistência dos dados e oferecer uma experiência de usuário estável, não confie o estado a esses componentes de UI.
Layouts adaptáveis
Crie apps que processem corretamente mudanças de configuração, como mudanças na orientação do dispositivo ou no tamanho da janela do app. Implemente os layouts canônicos adaptáveis para oferecer uma experiência do usuário ideal em vários formatos.
interface do Drive com base em modelos de dados
Outro princípio importante é basear sua interface em modelos de dados, de preferência, modelos persistentes. Os modelos de dados representam os dados de um app. Eles são independentes dos elementos da interface e outros componentes do app. Isso significa que eles não estão vinculados ao ciclo de vida do componente da interface e do app, mas ainda vão ser destruídos quando o SO remover o processo do app da memória.
Os modelos persistentes são ideais por estes motivos:
Seus usuários não perdem dados se o SO Android destruir o app para liberar recursos.
Seu app continua funcionando quando uma conexão de rede está intermitente ou indisponível.
Baseie a arquitetura do app em classes de modelo de dados para torná-lo robusto e testável.
Fonte única da verdade
Quando um novo tipo de dado é definido no seu app, atribua uma única fonte de informações (SSOT, na sigla em inglês) a ele. A SSOT é a proprietária desses dados, e apenas ela pode fazer mudanças neles. Para isso, ela expõe os dados usando um tipo imutável. Para fazer mudanças, ela expõe funções ou recebe eventos que outros tipos podem chamar.
Esse padrão tem vários benefícios:
- Centraliza todas as mudanças de um tipo específico de dados em um só lugar
- Protege os dados para que outros tipos não possam fazer adulterações neles
- Torna as mudanças nos dados mais rastreáveis, facilitando a detecção de bugs
Em um aplicativo que prioriza o modo off-line, a fonte da verdade para os dados do aplicativo
geralmente é um banco de dados. Em alguns outros casos, ela pode ser um
ViewModel.
Fluxo de dados unidirecional
O princípio da única fonte de verdade é usado com frequência com o padrão de fluxo de dados unidirecional (UDF). No UDF, o estado flui em apenas uma direção, geralmente do componente pai para o componente filho. São os eventos que modificam o fluxo de dados na direção oposta.
No Android, o estado ou os dados geralmente fluem dos tipos de escopo mais altos da hierarquia para os mais baixos. Os eventos geralmente são acionados pelos tipos de escopo mais baixos até alcançarem a SSOT para o tipo de dados correspondente. Por exemplo, os dados do app geralmente fluem das fontes de dados para a interface. Já os eventos do usuário, como pressionamento de botões, fluem da interface para a SSOT, em que os dados do aplicativo são modificados e expostos em um tipo imutável.
Esse padrão mantém melhor a consistência dos dados, é menos propenso a erros, é mais fácil de depurar e oferece todos os benefícios do padrão SSOT.
Para mais informações sobre o UDF, consulte Fluxo de dados unidirecional no Jetpack Compose.
Arquitetura de app recomendada
Considerando os princípios de arquitetura comuns, projete cada aplicativo com pelo menos duas camadas:
- Camada de interface:mostra os dados do aplicativo na tela.
- Camada de dados:contém a lógica de negócios do app e expõe os dados do aplicativo.
É possível adicionar uma camada extra conhecida como camada de domínios para simplificar e reutilizar as interações entre a IU e as camadas de dados.
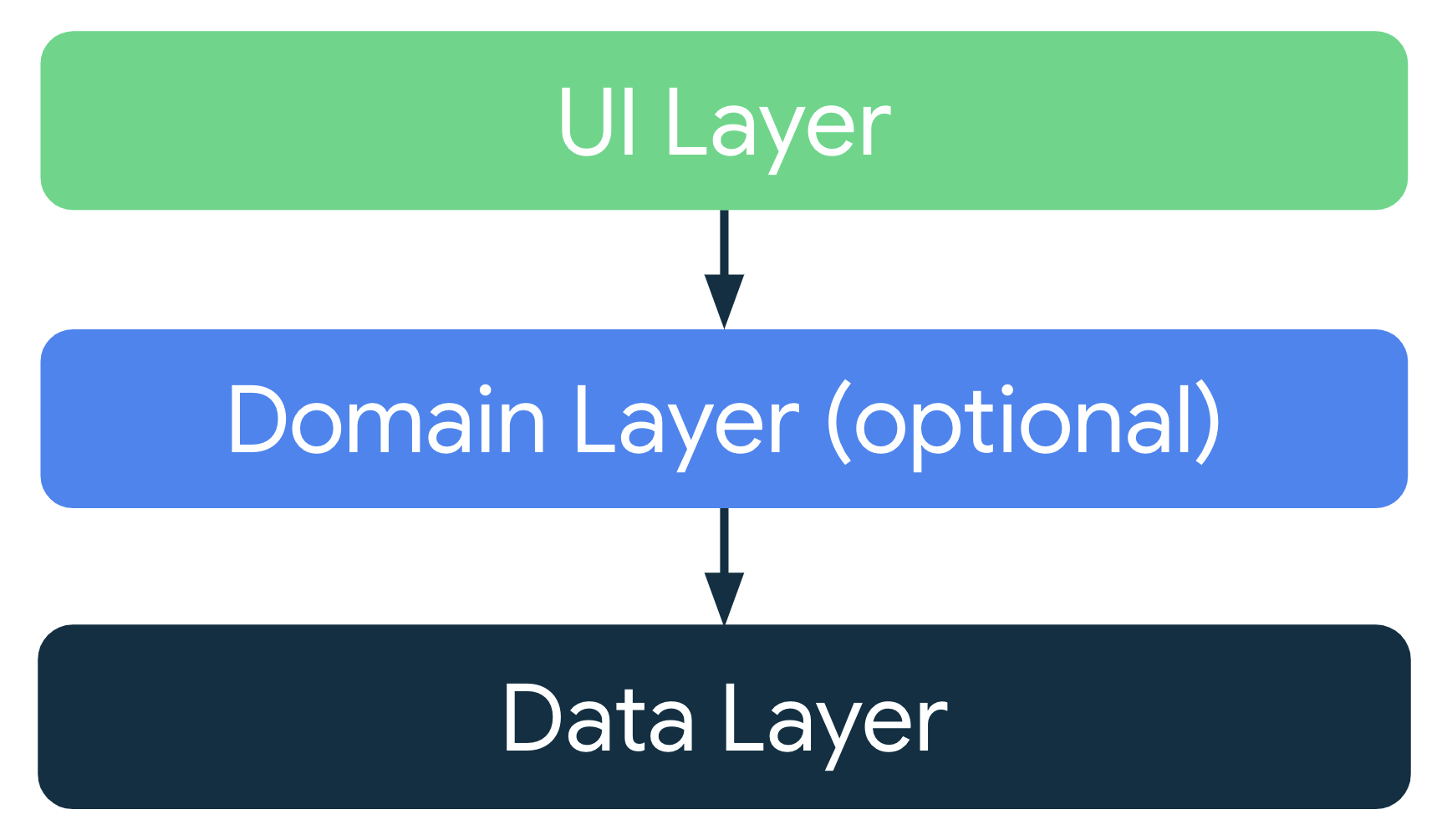
Arquitetura moderna de apps
Uma arquitetura moderna de apps Android usa as seguintes técnicas (entre outras):
- Arquitetura adaptativa e em camadas
- Fluxo de dados unidirecional (UDF) em todas as camadas do app
- Camada da interface com detentores de estado para gerenciar a complexidade dela
- Corrotinas e fluxos
- Práticas recomendadas para injeção de dependência
Para mais informações, consulte Recomendações para a arquitetura do Android.
Camada de IU
A função da camada de IU (ou camada de apresentação) é exibir os dados do aplicativo na tela. Sempre que os dados mudam, seja devido à interação do usuário, como o pressionamento de um botão, ou a uma entrada externa, como uma resposta de rede, a interface é atualizada para refletir as mudanças.
A camada de UI compreende dois tipos de construções:
- Elementos da IU que renderizam os dados na tela. Esses elementos são criados usando funções do Jetpack Compose para oferecer suporte a layouts adaptáveis.
- Detentores de estado, como
ViewModel, que armazenam dados, os expõem à interface e processam a lógica. Os detentores de estado precisam durar o mesmo tempo que o elemento da interface para o qual eles fornecem estado. Por exemplo, um ViewModel de uma tela precisa ser mantido na memória até que ela seja removida da backstack de navegação do app. Para mais informações, consulte Ciclos de vida do estado.
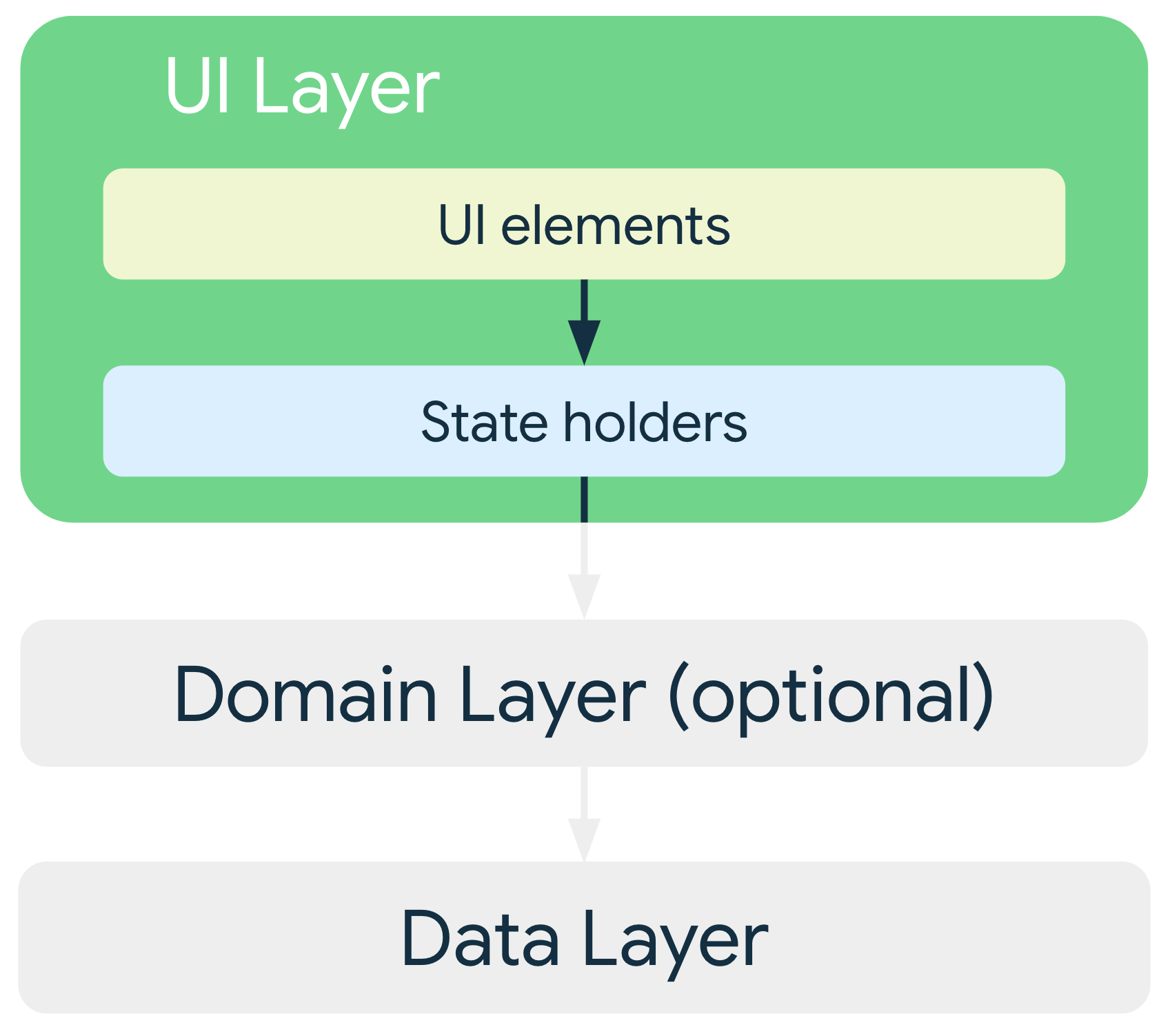
Para UIs adaptáveis, detentores de estado, como objetos ViewModel, expõem o estado da interface que
se adapta a diferentes classes de tamanho de janela. Você pode usar
currentWindowAdaptiveInfo() para derivar esse estado da UI. Componentes como
NavigationSuiteScaffold podem usar essas informações para alternar automaticamente
entre diferentes padrões de navegação (por exemplo, NavigationBar,
NavigationRail ou NavigationDrawer) com base no espaço disponível na tela.
Para saber mais, consulte Camada de UI e Arquitetura de UI do Compose.
Para mais informações sobre apps e navegação adaptáveis, consulte Criar apps adaptáveis e Criar navegação adaptável.
Camada de dados
A camada de dados de um app contém a lógica de negócios. A lógica de negócios é o que agrega valor ao app. Ela é composta por regras que determinam como o app cria, armazena e muda dados.
A camada de dados é composta por repositórios, cada um deles podendo conter de zero a muitas fontes de dados. Crie uma classe de repositório para cada tipo diferente de
dados processados no seu app. Por exemplo, você pode criar uma classe MoviesRepository
para dados relacionados a filmes ou uma classe PaymentsRepository para dados
relacionados a pagamentos.
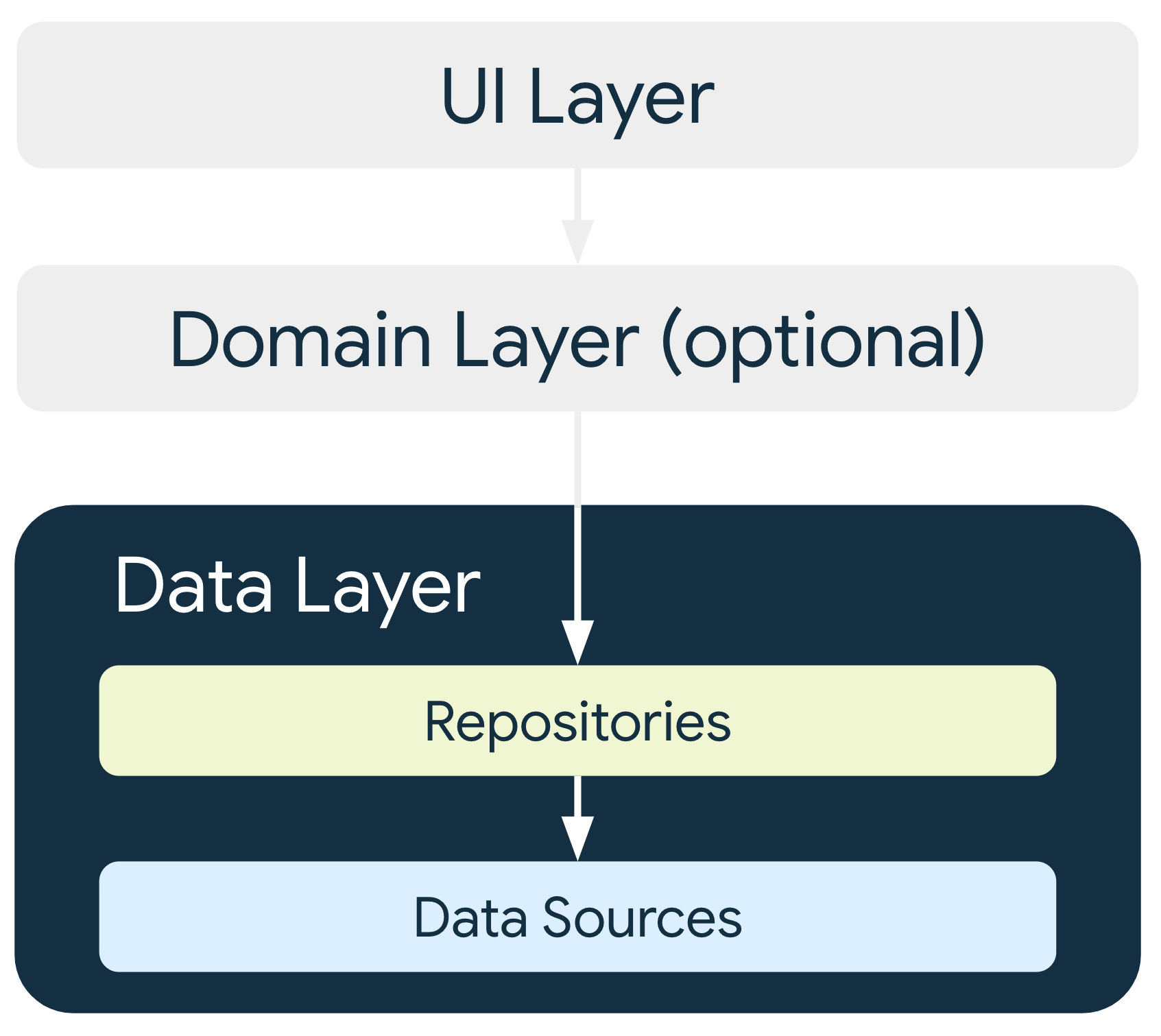
As classes de repositório são responsáveis pelo seguinte:
- Expor dados ao restante do app
- Centralizar mudanças nos dados
- Resolver conflitos entre várias fontes de dados
- Abstrair fontes de dados do restante do app
- Conter uma lógica de negócios
Cada classe de fonte de dados é responsável por trabalhar com apenas uma origem, que pode ser um arquivo, uma rede ou um banco de dados local. As classes de fonte de dados são a ponte entre o aplicativo e o sistema para operações de dados.
Para saber mais, consulte a página sobre a camada de dados.
Camada de domínios
A camada de domínios é opcional e fica entre a interface e as camadas de dados.
A camada de domínio é responsável por encapsular a lógica de negócios complexa ou mais simples que é reutilizada por vários ViewModels. A camada de domínio é opcional porque nem todos os apps têm esses requisitos. Use-a apenas quando necessário, por exemplo, para lidar com a complexidade ou favorecer a reutilização.
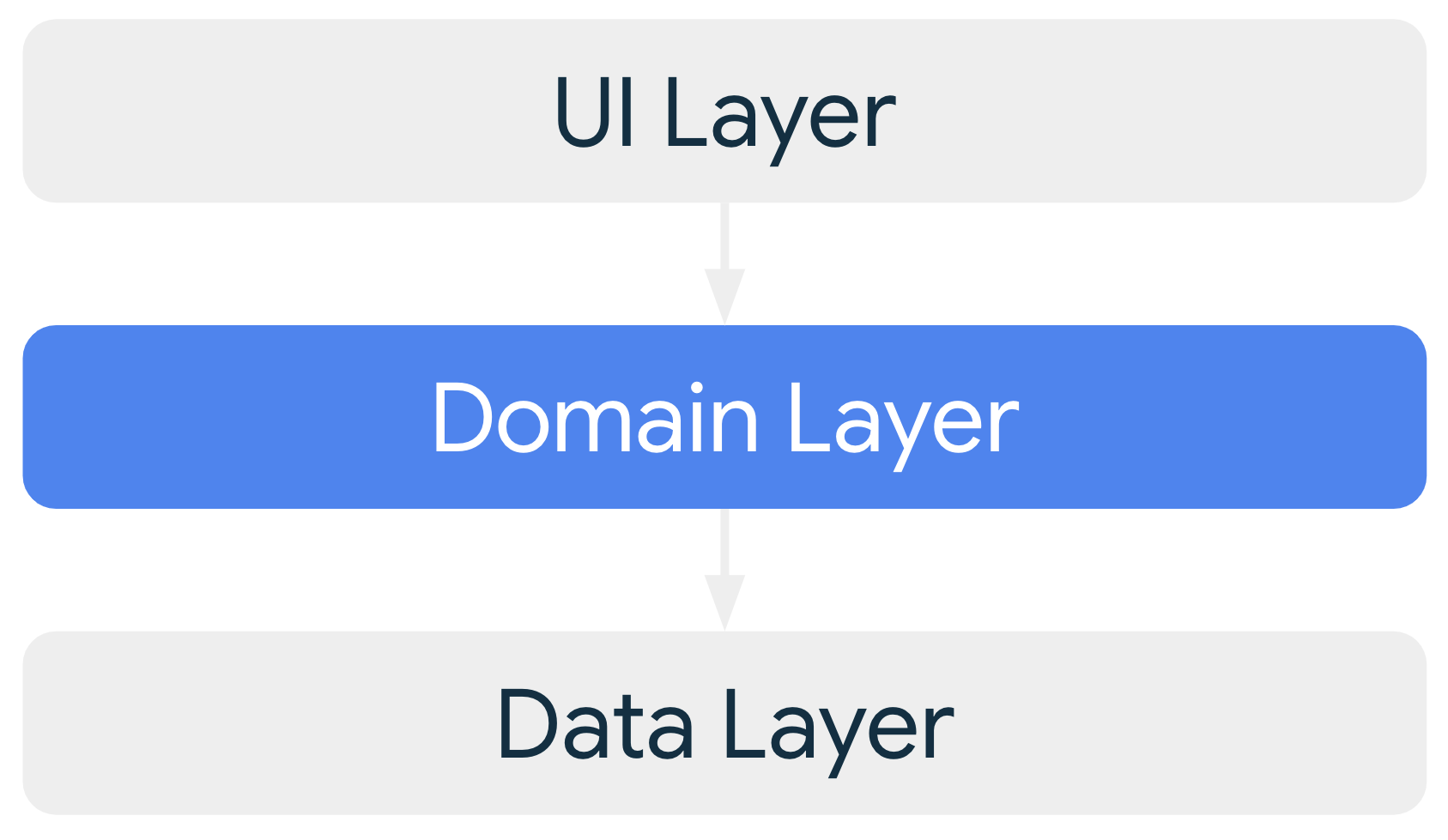
As classes na camada de domínio são normalmente chamadas de casos de uso ou interagentes.
Cada caso de uso é responsável por uma única funcionalidade. Por
exemplo, o app pode ter uma classe GetTimeZoneUseCase se vários modelos de
visualização dependerem de fusos horários para mostrar a mensagem adequada na tela.
Para saber mais, consulte a página da camada de domínios.
Gerenciar dependências entre componentes
As classes no app dependem de outras para funcionar corretamente. É possível usar um dos padrões de design abaixo para reunir as dependências de uma classe específica:
- Injeção de dependência (DI, na sigla em inglês): permite que as classes definam as próprias dependências sem construí-las. No tempo de execução, outra classe é responsável por fornecer essas dependências.
- Localizador de serviço: esse padrão fornece um registro de onde as classes podem buscar as próprias dependências em vez de construí-las.
Esses padrões permitem dimensionar o código, porque fornecem padrões claros para gerenciar dependências sem duplicar o código ou elevar a complexidade dele. Os padrões também permitem alternar rapidamente entre implementações de teste e de produção.
Práticas recomendadas gerais
A programação é um campo criativo, e a criação de apps Android não é uma exceção. Há muitas maneiras de resolver um problema: é possível comunicar dados entre várias atividades ou fragmentos, extrair dados remotos e os armazenar localmente no modo off-line ou lidar com qualquer outro cenário comum que apps não triviais encontrem.
Embora as recomendações abaixo não sejam obrigatórias, na maioria dos casos a observação delas torna sua base de código mais robusta, testável e de fácil manutenção.
Não armazene dados em componentes do app.
Evite designar os pontos de entrada do seu app, como atividades, serviços e broadcast receivers, como fontes de dados. Faça com que os pontos de entrada se coordenem com outros componentes para recuperar apenas o subconjunto de dados relevante para esse ponto de entrada. Cada componente do app tem vida curta, dependendo da interação do usuário com o dispositivo e da capacidade do sistema.
Reduza as dependências nas classes do Android.
Faça com que os componentes do app sejam as únicas classes que dependem das APIs do SDK
do framework do Android, como Context ou Toast. Abstrair outras classes do seu
app dos componentes dele ajuda na capacidade de teste e reduz o
acoplamento no app.
Defina limites de responsabilidade claros entre os módulos do seu app.
Não divulgue o código que carrega dados da rede em várias classes ou pacotes na sua base de código. Da mesma forma, não defina várias responsabilidades não relacionadas, como armazenamento de dados em cache e vinculação de dados, na mesma classe. Siga a arquitetura de apps recomendada.
Exponha o mínimo possível de cada módulo.
Não crie atalhos que exponham detalhes de implementação interna. Você pode ganhar um pouco de tempo a curto prazo, mas provavelmente vai pagar caro por isso tecnicamente à medida que sua base de código evoluir.
Concentre-se no núcleo exclusivo do seu app para que ele se destaque de outros apps.
Não reinvente a roda escrevendo o mesmo código clichê várias vezes. Em vez disso, concentre seu tempo e energia no que torna seu app único. Deixe que as bibliotecas do Jetpack e outras bibliotecas recomendadas processem o boilerplate repetitivo.
Use layouts canônicos e padrões de design de apps.
As bibliotecas do Jetpack Compose oferecem APIs robustas para criar interfaces de usuário adaptáveis. Use os layouts canônicos no app para otimizar a experiência do usuário em vários formatos e tamanhos de tela. Consulte a galeria de padrões de design de apps para selecionar os layouts que funcionam melhor para seus casos de uso.
Preserve o estado da interface em todas as mudanças de configuração.
Ao projetar layouts adaptáveis, preserve o estado da interface em todas as mudanças de configuração, como redimensionamento, dobra e mudanças de orientação da tela. Sua arquitetura precisa verificar se o estado atual do usuário é mantido, proporcionando uma experiência perfeita.
Projete componentes de interface reutilizáveis e combináveis.
Crie componentes de UI reutilizáveis e combináveis para oferecer suporte ao design adaptável. Isso permite combinar e reorganizar componentes para se adequar a vários tamanhos de tela e posturas sem refatoração significativa.
Considere como tornar cada parte do app testável de forma isolada.
Uma API bem definida para buscar dados da rede facilita o teste do módulo que mantém esses dados em um banco de dados local. Se, em vez disso, você mesclar a lógica dessas duas funções em um só lugar ou distribuir seu código de rede por toda a base de código, será muito mais difícil, se não impossível, testá-los.
Os tipos são responsáveis pela própria política de simultaneidade.
Se um tipo estiver executando um trabalho de bloqueio de longa duração, ele precisará ser responsável por mover esse cálculo para a linha de execução correta. O tipo sabe o tipo de cálculo que está sendo feito e em qual linha de execução ele precisa ser executado. Os tipos precisam ser protegidos, ou seja, podem ser chamados com segurança da linha de execução principal sem que ela seja bloqueada.
Aplique o máximo de persistência possível em dados relevantes e atualizados.
Dessa forma, os usuários podem aproveitar a funcionalidade do app mesmo quando o dispositivo estiver no modo off-line. Lembre-se de que nem todos os usuários têm conectividade constante e de alta velocidade e, mesmo se tiverem, eles podem ter sinal ruim em alguns lugares lotados.
Benefícios da arquitetura
Ter uma boa arquitetura implementada no app oferece muitos benefícios para as equipes de projetos e engenharia:
- Melhora a capacidade de manutenção, a qualidade e a robustez do app em geral.
- Permite que o app seja escalonado. Mais pessoas e equipes podem contribuir para a mesma base de código com conflitos mínimos.
- Ajuda na integração. Como a arquitetura traz consistência ao projeto, os novos membros da equipe podem começar a trabalhar mais rápido e ser mais eficientes em menos tempo.
- É mais fácil de testar. Uma boa arquitetura incentiva tipos mais simples, que geralmente são mais fáceis de testar.
- Permite investigar bugs metodicamente com processos bem definidos.
Embora uma boa arquitetura exija um investimento inicial de tempo, ela também tem um impacto direto nos usuários. Eles se beneficiam de um aplicativo mais estável e com mais recursos graças a uma equipe de engenharia mais produtiva.
Amostras
Os exemplos a seguir demonstram uma boa arquitetura de apps: