
AppSearch ist eine leistungsstarke On-Device-Suchlösung zur Verwaltung lokal gespeicherter strukturierter Daten. Sie enthält APIs zum Indexieren von Daten und zum Abrufen von Daten mithilfe der Volltextsuche. Mit AppSearch können Apps benutzerdefinierte In-App-Suchfunktionen anbieten, mit denen Nutzer auch offline nach Inhalten suchen können.
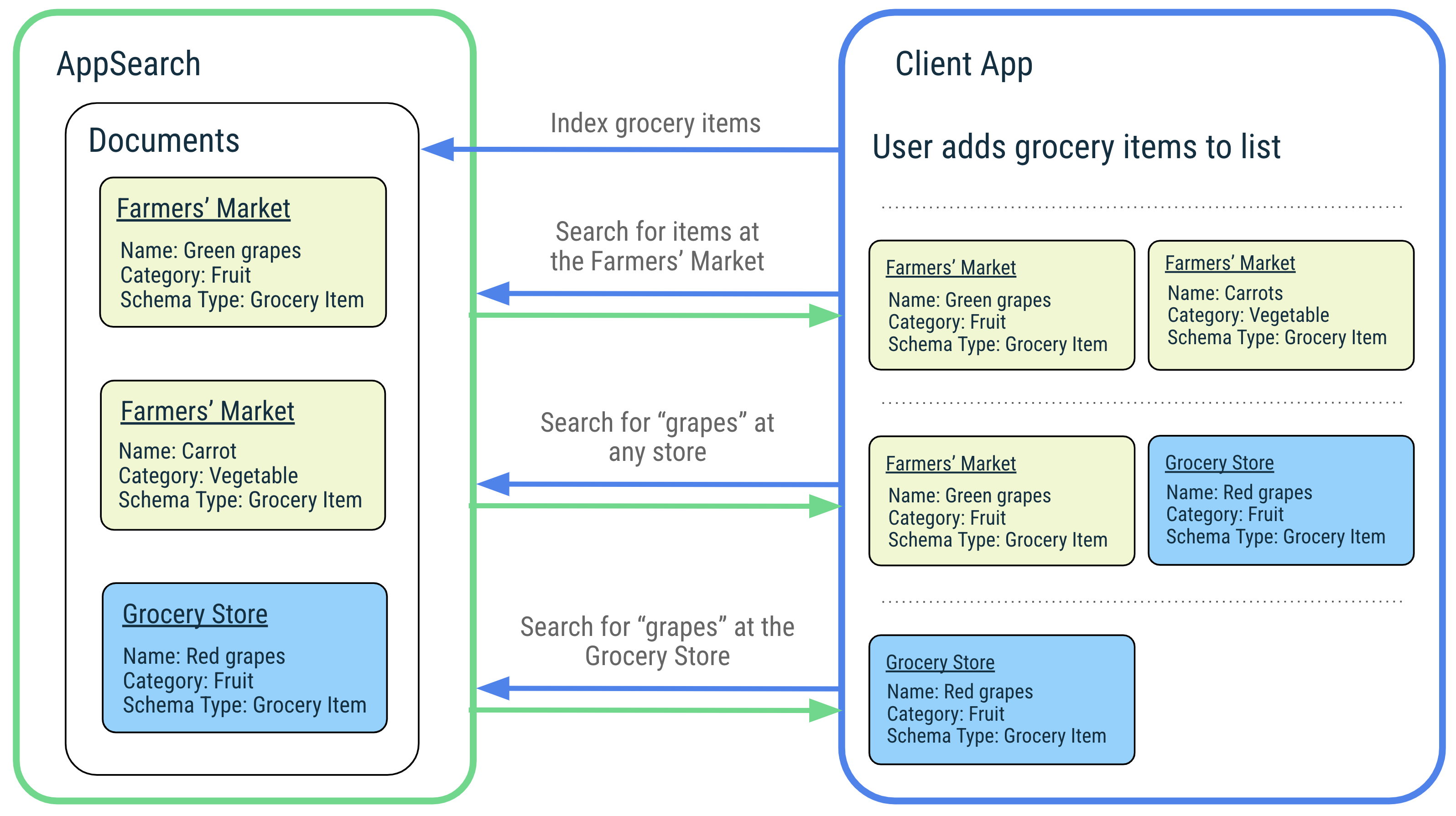
AppSearch bietet folgende Funktionen:
- Eine schnelle, mobilfreundliche Speicherimplementierung mit geringer I/O-Nutzung
- Hocheffiziente Indexierung und Abfrage großer Datenmengen
- Mehrsprachiger Support, z. B. auf Englisch und Spanisch
- Relevanzrangfolge und Nutzungsbewertung
Aufgrund der geringeren E/A-Nutzung bietet AppSearch im Vergleich zu SQLite eine geringere Latenz bei der Indexierung und Suche in großen Datenmengen. AppSearch vereinfacht abfrageübergreifende Abfragen, da einzelne Abfragen unterstützt werden, während SQLite Ergebnisse aus mehreren Tabellen zusammenführt.
Zur Veranschaulichung der Funktionen von AppSearch nehmen wir als Beispiel eine Musik-App, mit der Nutzer ihre Lieblingssongs verwalten und ganz einfach danach suchen können. Nutzer können Musik aus aller Welt mit Titeln in verschiedenen Sprachen hören. AppSearch unterstützt die Indexierung und Abfrage dieser Titel nativ. Wenn der Nutzer nach einem Titel oder Künstler sucht, leitet die Anwendung die Anfrage einfach an AppSearch weiter, um passende Titel schnell und effizient abzurufen. Die Anwendung zeigt die Ergebnisse an, sodass Nutzer ihre Lieblingssongs schnell abspielen können.
Einrichten
Wenn Sie AppSearch in Ihrer Anwendung verwenden möchten, fügen Sie der Datei build.gradle Ihrer Anwendung die folgenden Abhängigkeiten hinzu:
Cool
dependencies { def appsearch_version = "1.2.0-alpha01" implementation "androidx.appsearch:appsearch:$appsearch_version" // Use kapt instead of annotationProcessor if writing Kotlin classes annotationProcessor "androidx.appsearch:appsearch-compiler:$appsearch_version" implementation "androidx.appsearch:appsearch-local-storage:$appsearch_version" // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation "androidx.appsearch:appsearch-platform-storage:$appsearch_version" // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation "androidx.appsearch:appsearch-play-services-storage:$appsearch_version" }
Kotlin
dependencies { val appsearch_version = "1.2.0-alpha01" implementation("androidx.appsearch:appsearch:$appsearch_version") // Use annotationProcessor instead of kapt if writing Java classes kapt("androidx.appsearch:appsearch-compiler:$appsearch_version") implementation("androidx.appsearch:appsearch-local-storage:$appsearch_version") // PlatformStorage is compatible with Android 12+ devices, and offers additional features // to LocalStorage. implementation("androidx.appsearch:appsearch-platform-storage:$appsearch_version") // PlayServicesStorage is compatible with all devices that support Google Play Services on // all API levels. It offers the same features as PlatformStorage and is the recommended // solution for lower API levels on which PlatformStorage is not supported. implementation("androidx.appsearch:appsearch-play-services-storage:$appsearch_version") }
AppSearch-Konzepte
Das folgende Diagramm veranschaulicht die AppSearch-Konzepte und ihre Interaktionen.
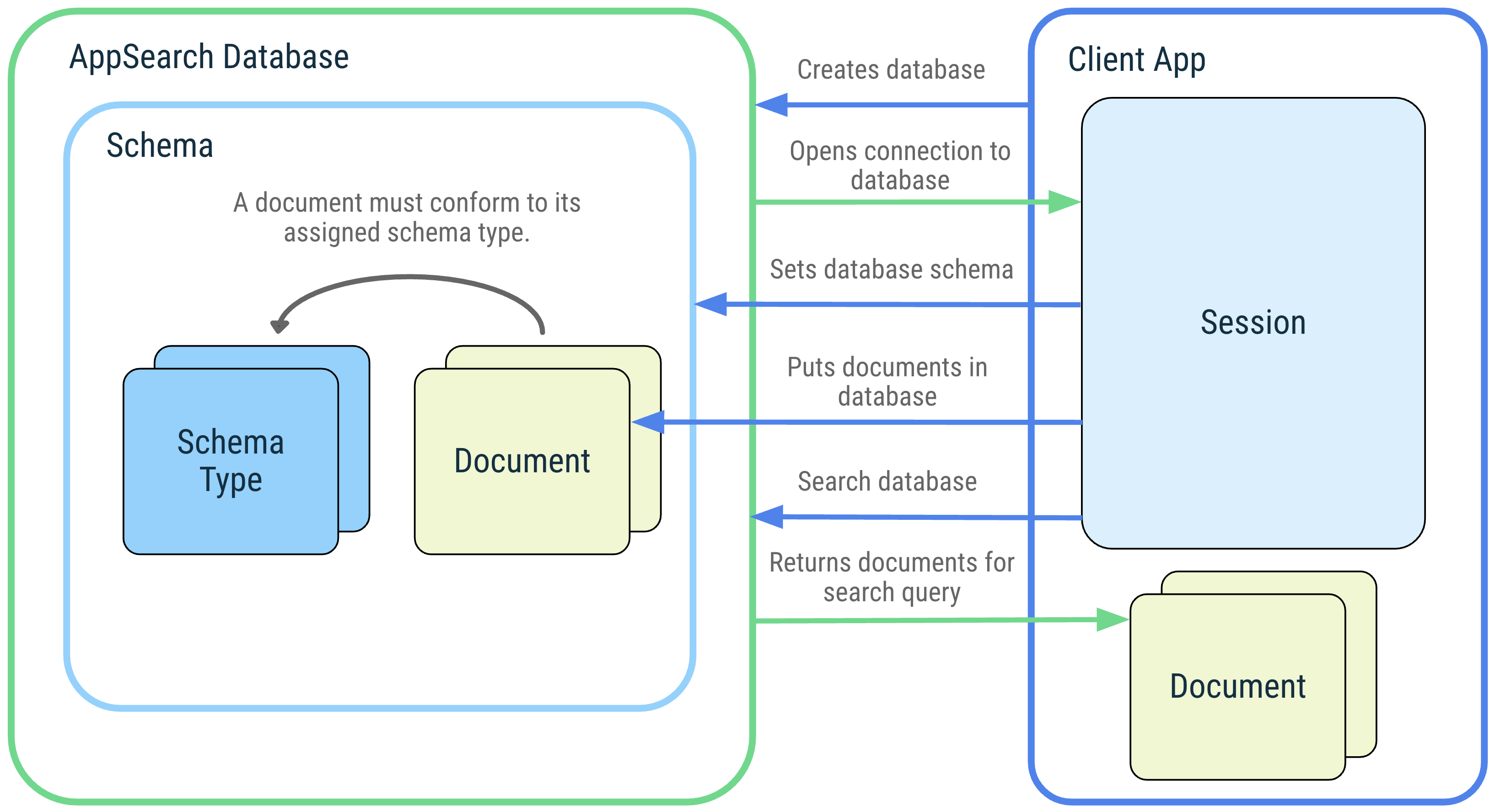 Abbildung 1 Diagramm der AppSearch-Konzepte: AppSearch-Datenbank, Schema, Schematypen, Dokumente, Sitzung und Suche.
Abbildung 1 Diagramm der AppSearch-Konzepte: AppSearch-Datenbank, Schema, Schematypen, Dokumente, Sitzung und Suche.
Datenbank und Sitzung
Eine AppSearch-Datenbank ist eine Sammlung von Dokumenten, die dem Datenbankschema entsprechen. Clientanwendungen erstellen eine Datenbank, indem sie ihren Anwendungskontext und einen Datenbanknamen angeben. Datenbanken können nur von der Anwendung geöffnet werden, mit der sie erstellt wurden. Wenn eine Datenbank geöffnet wird, wird eine Sitzung zurückgegeben, um mit der Datenbank zu interagieren. Die Sitzung ist der Einstiegspunkt für den Aufruf der AppSearch APIs und bleibt geöffnet, bis sie von der Clientanwendung geschlossen wird.
Schema und Schematypen
Ein Schema stellt die Organisationsstruktur der Daten in einer AppSearch-Datenbank dar.
Das Schema besteht aus Schematypen, die eindeutige Datentypen darstellen. Schematypen bestehen aus Properties mit einem Namen, einem Datentyp und einer Kardinalität. Sobald dem Datenbankschema ein Schematyp hinzugefügt wurde, können Dokumente dieses Schematyps erstellt und der Datenbank hinzugefügt werden.
Dokumente
In AppSearch wird eine Dateneinheit als Dokument dargestellt. Jedes Dokument in einer AppSearch-Datenbank wird eindeutig durch seinen Namespace und seine ID identifiziert. Namespaces werden verwendet, um Daten aus verschiedenen Quellen zu trennen, wenn nur eine Quelle abgefragt werden muss, z. B. Nutzerkonten.
Dokumente enthalten einen Erstellungszeitstempel, eine Gültigkeitsdauer (Time-to-Live, TTL) und eine Bewertung, die beim Abrufen zum Ranking verwendet werden kann. Jedem Dokument wird außerdem ein Schematyp zugewiesen, der zusätzliche Dateneigenschaften beschreibt, die das Dokument haben muss.
Eine Dokumentklasse ist eine Abstraktion eines Dokuments. Es enthält annotierte Felder, die den Inhalt eines Dokuments darstellen. Standardmäßig wird der Name des Schematyps durch den Namen der Dokumentklasse festgelegt.
Suchen
Dokumente werden indexiert und können durch Eingabe einer Suchanfrage durchsucht werden. Ein Dokument wird abgeglichen und in die Suchergebnisse aufgenommen, wenn es die Begriffe in der Abfrage enthält oder mit einer anderen Suchanfrage übereinstimmt. Die Ergebnisse werden anhand ihres Werts und der Ranking-Strategie sortiert. Die Suchergebnisse werden durch Seiten dargestellt, die Sie nacheinander abrufen können.
AppSearch bietet Anpassungen für die Suche, z. B. Filter, Seitengrößenkonfiguration und Snippets.
Plattformspeicher, lokaler Speicher oder Play-Dienste-Speicher
AppSearch bietet drei Speicherlösungen: LocalStorage, PlatformStorage und PlayServicesStorage. Mit LocalStorage verwaltet Ihre Anwendung einen app-spezifischen Index, der sich im Anwendungsdatenverzeichnis befindet. Sowohl mit PlatformStorage als auch mit PlayServicesStorage trägt Ihre Anwendung zu einem systemweiten zentralen Index bei. Der Index von PlatformStorage wird auf dem Systemserver gehostet und der Index von PlayServicesStorage wird im Speicher der Google Play-Dienste gehostet. Der Datenzugriff in diesen zentralen Indexen ist auf Daten beschränkt, die von Ihrer Anwendung stammen, und auf Daten, die von einer anderen Anwendung ausdrücklich für Sie freigegeben wurden. Alle diese Speicheroptionen verwenden dieselbe API und können je nach Geräteversion ausgetauscht werden:
Kotlin
if (BuildCompat.isAtLeastS()) { appSearchSessionFuture.setFuture( PlatformStorage.createSearchSession( PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { if (usePlayServicesStorageBelowS) { appSearchSessionFuture.setFuture( PlayServicesStorage.createSearchSession( PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } else { appSearchSessionFuture.setFuture( LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build() ) ) } }
Java
if (BuildCompat.isAtLeastS()) { mAppSearchSessionFuture.setFuture(PlatformStorage.createSearchSession( new PlatformStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { if (usePlayServicesStorageBelowS) { mAppSearchSessionFuture.setFuture(PlayServicesStorage.createSearchSession( new PlayServicesStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } else { mAppSearchSessionFuture.setFuture(LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(mContext, DATABASE_NAME) .build())); } }
Mit PlatformStorage und PlayServicesStorage kann Ihre Anwendung Daten sicher für andere Anwendungen freigeben, damit diese auch in den Daten Ihrer App suchen können. Die Freigabe von Anwendungsdaten im Lesemodus erfolgt über einen Zertifikats-Handshake, um sicherzustellen, dass die andere Anwendung die Berechtigung zum Lesen der Daten hat. Weitere Informationen zu dieser API finden Sie in der Dokumentation zu setSchemaTypeVisibilityForPackage().
Mit PlatformStorage können außerdem indexierte Daten auf System-UI-Oberflächen angezeigt werden. Anwendungen können festlegen, dass einige oder alle Daten nicht in der Systemoberfläche angezeigt werden. Weitere Informationen zu dieser API findest du in der Dokumentation für setSchemaTypeDisplayedBySystem().
| Funktionen | LocalStorage (kompatibel mit Android 5.0 und höher) |
PlatformStorage (kompatibel mit Android 12 und höher) |
PlayServicesStorage (kompatibel mit Android 5.0 und höher) |
|---|---|---|---|
| Effiziente Volltextsuche | |||
| Mehrsprachiger Support | |||
| Verringerte Binärgröße | |||
| Datenfreigabe zwischen Anwendungen | |||
| Möglichkeit, Daten auf Oberflächen der System-UI anzuzeigen | |||
| Unbegrenzte Anzahl und Größe von Dokumenten kann indexiert werden | |||
| Schnellere Vorgänge ohne zusätzliche Binderlatenz |
Bei der Auswahl zwischen LocalStorage und PlatformStorage müssen weitere Vor- und Nachteile berücksichtigt werden. Da PlatformStorage Jetpack APIs über den AppSearch-Systemdienst umschließt, ist die Auswirkung auf die APK-Größe im Vergleich zur Verwendung von LocalStorage minimal. Dies bedeutet jedoch auch, dass bei AppSearch-Vorgängen beim Aufrufen des AppSearch-Systemdienstes eine zusätzliche Bindunglatenz entsteht. Mit PlatformStorage begrenzt AppSearch die Anzahl und Größe der Dokumente, die eine Anwendung indexieren kann, um ein effizientes zentrales Index zu gewährleisten. PlayServicesStorage unterliegt außerdem denselben Einschränkungen wie PlatformStorage und wird nur auf Geräten mit Google Play-Diensten unterstützt.
Erste Schritte mit AppSearch
Im Beispiel in diesem Abschnitt wird gezeigt, wie Sie AppSearch APIs verwenden, um eine hypothetische Notiz-App zu integrieren.
Dokumentenklasse schreiben
Der erste Schritt zur Integration mit AppSearch besteht darin, eine Dokumentklasse zu schreiben, um die Daten zu beschreiben, die in die Datenbank eingefügt werden sollen. Markieren Sie eine Klasse mit der Anmerkung @Document als Dokumentklasse.Mithilfe von Instanzen der Dokumentklasse können Sie Dokumente in die Datenbank einfügen und daraus abrufen.
Im folgenden Code wird eine Notizdokumentklasse mit einem mit @Document.StringProperty annotierten Feld zum Indexieren des Texts eines Notizobjekts definiert.
Kotlin
@Document public data class Note( // Required field for a document class. All documents MUST have a namespace. @Document.Namespace val namespace: String, // Required field for a document class. All documents MUST have an Id. @Document.Id val id: String, // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score val score: Int, // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = AppSearchSchema.StringPropertyConfig.INDEXING_TYPE_PREFIXES) val text: String )
Java
@Document public class Note { // Required field for a document class. All documents MUST have a namespace. @Document.Namespace private final String namespace; // Required field for a document class. All documents MUST have an Id. @Document.Id private final String id; // Optional field for a document class, used to set the score of the // document. If this is not included in a document class, the score is set // to a default of 0. @Document.Score private final int score; // Optional field for a document class, used to index a note's text for this // document class. @Document.StringProperty(indexingType = StringPropertyConfig.INDEXING_TYPE_PREFIXES) private final String text; Note(@NonNull String id, @NonNull String namespace, int score, @NonNull String text) { this.id = Objects.requireNonNull(id); this.namespace = Objects.requireNonNull(namespace); this.score = score; this.text = Objects.requireNonNull(text); } @NonNull public String getNamespace() { return namespace; } @NonNull public String getId() { return id; } public int getScore() { return score; } @NonNull public String getText() { return text; } }
Datenbank öffnen
Sie müssen eine Datenbank erstellen, bevor Sie mit Dokumenten arbeiten können. Im folgenden Code wird eine neue Datenbank mit dem Namen notes_app erstellt und eine ListenableFuture für eine AppSearchSession abgerufen. Letztere stellt die Verbindung zur Datenbank dar und bietet die APIs für Datenbankvorgänge.
Kotlin
val context: Context = getApplicationContext() val sessionFuture = LocalStorage.createSearchSession( LocalStorage.SearchContext.Builder(context, /*databaseName=*/"notes_app") .build() )
Java
Context context = getApplicationContext(); ListenableFuture<AppSearchSession> sessionFuture = LocalStorage.createSearchSession( new LocalStorage.SearchContext.Builder(context, /*databaseName=*/ "notes_app") .build() );
Schema festlegen
Sie müssen ein Schema festlegen, bevor Sie Dokumente in die Datenbank einfügen und daraus abrufen können. Das Datenbankschema besteht aus verschiedenen Arten von strukturierten Daten, die als „Schematypen“ bezeichnet werden. Im folgenden Code wird das Schema festgelegt, indem die Dokumentklasse als Schematyp angegeben wird.
Kotlin
val setSchemaRequest = SetSchemaRequest.Builder().addDocumentClasses(Note::class.java) .build() val setSchemaFuture = Futures.transformAsync( sessionFuture, { session -> session?.setSchema(setSchemaRequest) }, mExecutor )
Java
SetSchemaRequest setSchemaRequest = new SetSchemaRequest.Builder().addDocumentClasses(Note.class) .build(); ListenableFuture<SetSchemaResponse> setSchemaFuture = Futures.transformAsync(sessionFuture, session -> session.setSchema(setSchemaRequest), mExecutor);
Dokument in die Datenbank einfügen
Nachdem ein Schematyp hinzugefügt wurde, können Sie der Datenbank Dokumente dieses Typs hinzufügen.
Im folgenden Code wird ein Dokument vom Schematyp Note mit dem Note-Dokumentklassen-Builder erstellt. Der Dokument-Namespace user1 wird so festgelegt, dass er einen beliebigen Nutzer dieses Beispiels darstellt. Das Dokument wird dann in die Datenbank eingefügt und ein Listener wird angehängt, um das Ergebnis des Put-Vorgangs zu verarbeiten.
Kotlin
val note = Note( namespace="user1", id="noteId", score=10, text="Buy fresh fruit" ) val putRequest = PutDocumentsRequest.Builder().addDocuments(note).build() val putFuture = Futures.transformAsync( sessionFuture, { session -> session?.put(putRequest) }, mExecutor ) Futures.addCallback( putFuture, object : FutureCallback<AppSearchBatchResult<String, Void>?> { override fun onSuccess(result: AppSearchBatchResult<String, Void>?) { // Gets map of successful results from Id to Void val successfulResults = result?.successes // Gets map of failed results from Id to AppSearchResult val failedResults = result?.failures } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to put documents.", t) } }, mExecutor )
Java
Note note = new Note(/*namespace=*/"user1", /*id=*/ "noteId", /*score=*/ 10, /*text=*/ "Buy fresh fruit!"); PutDocumentsRequest putRequest = new PutDocumentsRequest.Builder().addDocuments(note) .build(); ListenableFuture<AppSearchBatchResult<String, Void>> putFuture = Futures.transformAsync(sessionFuture, session -> session.put(putRequest), mExecutor); Futures.addCallback(putFuture, new FutureCallback<AppSearchBatchResult<String, Void>>() { @Override public void onSuccess(@Nullable AppSearchBatchResult<String, Void> result) { // Gets map of successful results from Id to Void Map<String, Void> successfulResults = result.getSuccesses(); // Gets map of failed results from Id to AppSearchResult Map<String, AppSearchResult<Void>> failedResults = result.getFailures(); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to put documents.", t); } }, mExecutor);
Suchen
Sie können mit den in diesem Abschnitt beschriebenen Suchvorgängen in indexierten Dokumenten suchen. Im folgenden Code werden Abfragen für den Begriff „Obst“ in der Datenbank für Dokumente ausgeführt, die zum Namespace user1 gehören.
Kotlin
val searchSpec = SearchSpec.Builder() .addFilterNamespaces("user1") .build(); val searchFuture = Futures.transform( sessionFuture, { session -> session?.search("fruit", searchSpec) }, mExecutor ) Futures.addCallback( searchFuture, object : FutureCallback<SearchResults> { override fun onSuccess(searchResults: SearchResults?) { iterateSearchResults(searchResults) } override fun onFailure(t: Throwable?) { Log.e("TAG", "Failed to search notes in AppSearch.", t) } }, mExecutor )
Java
SearchSpec searchSpec = new SearchSpec.Builder() .addFilterNamespaces("user1") .build(); ListenableFuture<SearchResults> searchFuture = Futures.transform(sessionFuture, session -> session.search("fruit", searchSpec), mExecutor); Futures.addCallback(searchFuture, new FutureCallback<SearchResults>() { @Override public void onSuccess(@Nullable SearchResults searchResults) { iterateSearchResults(searchResults); } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to search notes in AppSearch.", t); } }, mExecutor);
SearchResults durchlaufen
Suchanfragen geben eine SearchResults-Instanz zurück, die Zugriff auf die Seiten von SearchResult-Objekten gewährt. Jeder SearchResult enthält das zugehörige GenericDocument, das allgemeine Dokumentformat, in das alle Dokumente konvertiert werden. Der folgende Code ruft die erste Seite der Suchergebnisse ab und konvertiert das Ergebnis wieder in ein Note-Dokument.
Kotlin
Futures.transform( searchResults?.nextPage, { page: List<SearchResult>? -> // Gets GenericDocument from SearchResult. val genericDocument: GenericDocument = page!![0].genericDocument val schemaType = genericDocument.schemaType val note: Note? = try { if (schemaType == "Note") { // Converts GenericDocument object to Note object. genericDocument.toDocumentClass(Note::class.java) } else null } catch (e: AppSearchException) { Log.e( TAG, "Failed to convert GenericDocument to Note", e ) null } note }, mExecutor )
Java
Futures.transform(searchResults.getNextPage(), page -> { // Gets GenericDocument from SearchResult. GenericDocument genericDocument = page.get(0).getGenericDocument(); String schemaType = genericDocument.getSchemaType(); Note note = null; if (schemaType.equals("Note")) { try { // Converts GenericDocument object to Note object. note = genericDocument.toDocumentClass(Note.class); } catch (AppSearchException e) { Log.e(TAG, "Failed to convert GenericDocument to Note", e); } } return note; }, mExecutor);
Dokument entfernen
Wenn der Nutzer eine Notiz löscht, löscht die Anwendung das entsprechende Note-Dokument aus der Datenbank. Dadurch wird sichergestellt, dass die Notiz nicht mehr in Suchanfragen angezeigt wird. Im folgenden Code wird explizit angefordert, das Note-Dokument anhand der ID aus der Datenbank zu entfernen.
Kotlin
val removeRequest = RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build() val removeFuture = Futures.transformAsync( sessionFuture, { session -> session?.remove(removeRequest) }, mExecutor )
Java
RemoveByDocumentIdRequest removeRequest = new RemoveByDocumentIdRequest.Builder("user1") .addIds("noteId") .build(); ListenableFuture<AppSearchBatchResult<String, Void>> removeFuture = Futures.transformAsync(sessionFuture, session -> session.remove(removeRequest), mExecutor);
Auf dem Laufwerk speichern
Aktualisierungen an einer Datenbank sollten regelmäßig auf dem Laufwerk gespeichert werden, indem requestFlush() aufgerufen wird. Im folgenden Code wird requestFlush() mit einem Listener aufgerufen, um festzustellen, ob der Aufruf erfolgreich war.
Kotlin
val requestFlushFuture = Futures.transformAsync( sessionFuture, { session -> session?.requestFlush() }, mExecutor ) Futures.addCallback(requestFlushFuture, object : FutureCallback<Void?> { override fun onSuccess(result: Void?) { // Success! Database updates have been persisted to disk. } override fun onFailure(t: Throwable) { Log.e(TAG, "Failed to flush database updates.", t) } }, mExecutor)
Java
ListenableFuture<Void> requestFlushFuture = Futures.transformAsync(sessionFuture, session -> session.requestFlush(), mExecutor); Futures.addCallback(requestFlushFuture, new FutureCallback<Void>() { @Override public void onSuccess(@Nullable Void result) { // Success! Database updates have been persisted to disk. } @Override public void onFailure(@NonNull Throwable t) { Log.e(TAG, "Failed to flush database updates.", t); } }, mExecutor);
Sitzung schließen
Ein AppSearchSession sollte geschlossen werden, wenn eine Anwendung keine Datenbankvorgänge mehr aufruft. Der folgende Code schließt die zuvor geöffnete AppSearch-Sitzung und speichert alle Updates auf dem Laufwerk.
Kotlin
val closeFuture = Futures.transform<AppSearchSession, Unit>(sessionFuture, { session -> session?.close() Unit }, mExecutor )
Java
ListenableFuture<Void> closeFuture = Futures.transform(sessionFuture, session -> { session.close(); return null; }, mExecutor);
Weitere Informationen
Weitere Informationen zu AppSearch finden Sie in den folgenden Ressourcen:
Produktproben
- Android AppSearch Sample (Kotlin): Eine Notiz-App, die die AppSearch verwendet, um die Notizen eines Nutzers zu indexieren und Nutzern die Suche in ihren Notizen zu ermöglichen.
Feedback geben
Du kannst uns dein Feedback und deine Ideen über die folgenden Ressourcen mitteilen:
Melden Sie Fehler, damit wir sie beheben können.