
L'architecture d'application est le fondement d'une application Android de haute qualité. Une architecture bien définie vous permet de créer une application évolutive et facile à gérer, qui peut s'adapter à l'écosystème en constante expansion des appareils Android, y compris les téléphones, les tablettes, les appareils pliables, les appareils ChromeOS, les écrans de voiture et la réalité étendue.
Composition de l'application
Une application Android type est composée de plusieurs composants d'application, tels que les services, les fournisseurs de contenu et les broadcast receivers. Vous déclarez ces composants dans le fichier manifeste de votre application.
L'interface utilisateur d'une application est également un composant. Historiquement, les UI étaient créées à l'aide de plusieurs activités. Cependant, les applications modernes utilisent une architecture à activité unique. Un seul Activity sert de conteneur pour les écrans ou les destinations Jetpack Compose.
Différents formats disponibles
Les applications peuvent s'exécuter sur plusieurs facteurs de forme, y compris les téléphones, mais aussi les tablettes, les appareils pliables, les appareils ChromeOS, etc. Ne partez pas du principe que votre application reste toujours fixe en orientation portrait ou paysage. Les changements de configuration, tels que la rotation de l'appareil ou le pliage et le dépliage d'un appareil pliable, forcent votre application à recomposer son interface utilisateur, ce qui affecte l'état de l'application.
Contraintes liées aux ressources
Les appareils mobiles, même ceux à grand écran, sont limités en ressources. Par conséquent, le système d'exploitation peut à tout moment arrêter le processus de votre application pour allouer ses ressources à d'autres processus.
Conditions de lancement variables
Dans un environnement aux ressources limitées, les composants de votre application peuvent être lancés individuellement et dans le désordre. De plus, le système d'exploitation ou l'utilisateur peuvent les détruire à tout moment. Par conséquent, ne stockez aucune donnée ni aucun état d'application dans vos composants d'application. Rendez les composants de votre application autonomes et indépendants les uns des autres.
Principes architecturaux courants
Si vous ne pouvez pas utiliser les composants d'application pour stocker les données et l'état de l'application, comment devez-vous concevoir votre application ?
À mesure que la taille des applications Android augmente, il est important de définir une architecture qui leur permet d'évoluer. Une architecture d'application bien conçue définit les limites entre les parties de l'application et les responsabilités de chaque partie.
Séparation des préoccupations
Concevez l'architecture de votre application en suivant quelques principes spécifiques.
Le principe le plus important est la séparation des préoccupations : il s'agit de diviser votre application en méthodes, classes, fichiers, packages, modules et couches qui ont des responsabilités et des limites clairement définies.
Une erreur courante consiste à écrire tout votre code dans une Activity.
Le rôle principal d'un Activity est d'héberger l'UI de votre application. Le système d'exploitation Android contrôle leur cycle de vie, en les détruisant et en les recréant fréquemment en réponse à des actions de l'utilisateur, comme la rotation de l'écran, ou à des événements système, comme une mémoire insuffisante.
Cette nature éphémère les rend inadaptés au stockage des données ou de l'état des applications. Si vous stockez des données dans un Activity, elles sont perdues lorsque le composant est recréé. Pour assurer la persistance des données et offrir une expérience utilisateur stable, n'attribuez pas d'état à ces composants d'UI.
Mises en page adaptatives
Créez des applications qui gèrent correctement les changements de configuration, tels que les changements d'orientation de l'appareil ou de la taille de la fenêtre de l'application. Implémentez les mises en page standards adaptatives pour offrir une expérience utilisateur optimale sur différents facteurs de forme.
Contrôle de l'UI à partir de modèles de données
Un autre principe important est de contrôler votre UI à partir de modèles de données, de préférence des modèles persistants. Les modèles de données représentent les données d'une application. Ils sont indépendants des éléments de l'UI et des autres composants de votre application. Cela signifie qu'ils ne sont pas liés au cycle de vie de l'UI et des composants de l'application, mais qu'ils seront quand même détruits lorsque l'OS supprimera le processus de l'application de la mémoire.
Les modèles persistants sont parfaitement adaptés pour les raisons suivantes :
Les utilisateurs ne perdent pas de données si l'OS Android détruit votre application pour libérer des ressources.
Votre application continue de fonctionner même lorsque la connexion réseau est intermittente ou indisponible.
Basez l'architecture de votre application sur des classes de modèle de données pour la rendre robuste et facile à tester.
Single Source of Truth (référence unique)
Lorsqu'un nouveau type de données est défini dans votre application, attribuez-lui une source unique de vérité (SSOT). La SSOT est le propriétaire de ces données, et elle seule peut les modifier ou les muter. Pour ce faire, la SSOT expose les données avec un type immuable. Pour les modifier, elle expose des fonctions ou reçoit des événements que d'autres types peuvent appeler.
Ce modèle présente plusieurs avantages :
- Centralise toutes les modifications apportées à un type de données particulier
- Protège les données contre d'autres types qui tentent d'y accéder
- Les modifications apportées aux données sont ainsi plus faciles à tracer, ce qui permet de repérer plus facilement les bugs.
Dans une application axée sur une utilisation hors connexion, la référence des données de l'application est généralement une base de données. Dans d'autres cas, la source de vérité peut être un ViewModel.
Flux de données unidirectionnel
Le principe de référence unique est souvent utilisé avec le modèle de flux de données unidirectionnel (UDF, Unidirectional Data Flow). Dans l'UDF, l'état est transmis dans une seule direction, généralement du composant parent au composant enfant. Les événements qui modifient les données sont transmis dans la direction opposée.
Dans Android, l'état ou les données sont généralement transmis depuis les niveaux supérieurs de la hiérarchie vers les niveaux inférieurs. Les événements sont généralement déclenchés à partir des types de niveau inférieur jusqu'à ce qu'ils atteignent la SSOT pour le type de données correspondant. Par exemple, les données d'application sont généralement transmises depuis des sources de données vers l'UI. Les événements utilisateur (quand un utilisateur appuie sur un bouton, par exemple) sont transmis depuis l'UI vers la SSOT où les données de l'application sont modifiées et exposées dans un type immuable.
Ce modèle permet de mieux maintenir la cohérence des données, est moins sujet aux erreurs et plus facile à déboguer, et offre tous les avantages du modèle SSOT.
Pour en savoir plus sur le flux de données unidirectionnel, consultez Flux de données unidirectionnel dans Jetpack Compose.
Architecture d'application recommandée
Compte tenu des principes architecturaux courants, concevez chaque application avec au moins deux couches :
- Couche d'interface utilisateur : affiche les données de l'application à l'écran.
- Couche de données : contient la logique métier de votre application et expose les données de l'application.
Vous pouvez ajouter une couche, appelée couche de domaine, pour simplifier et réutiliser les interactions entre l'interface utilisateur et les couches de données.
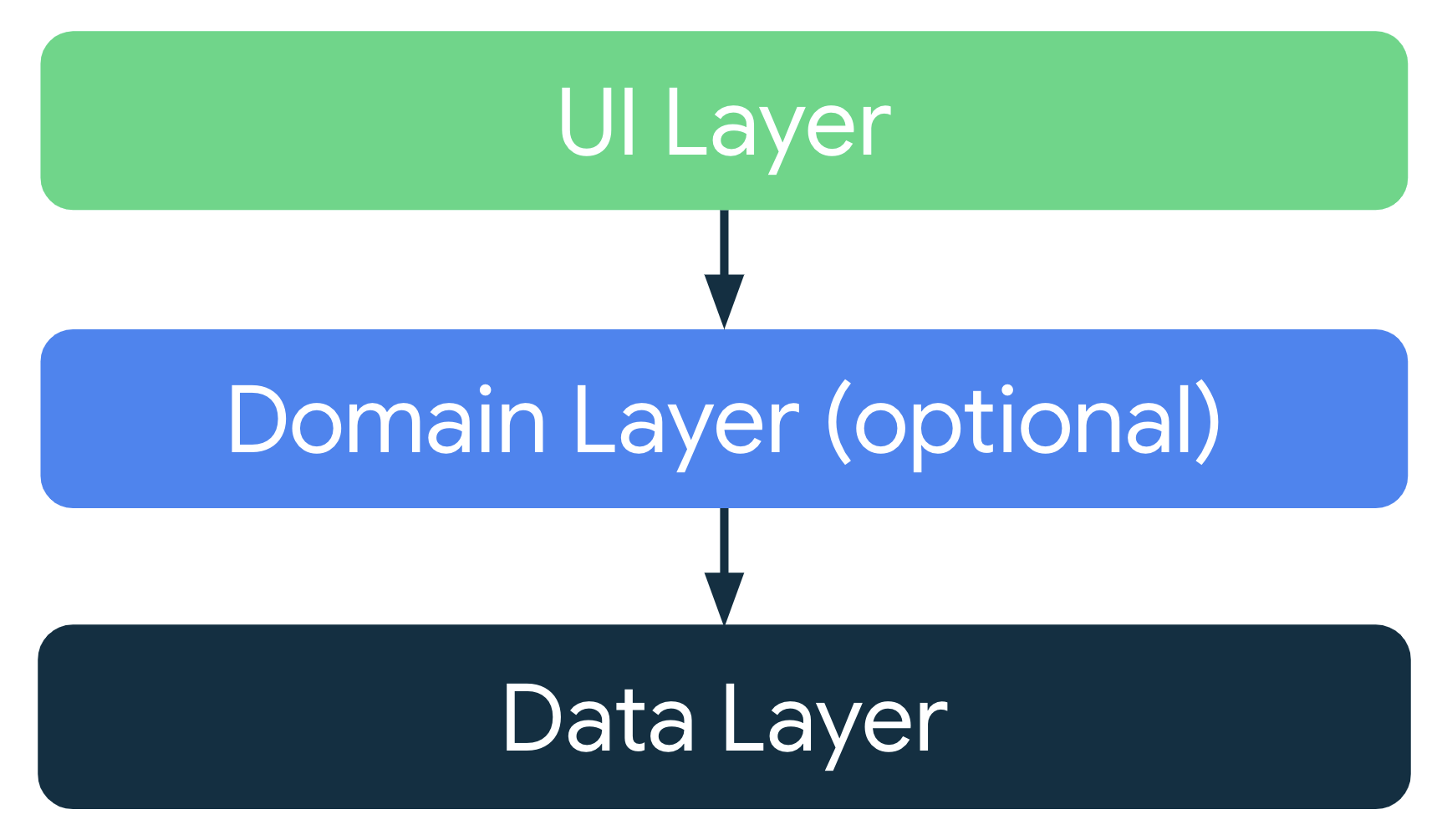
Architecture d'application moderne
Une architecture d'application Android moderne utilise les techniques suivantes (entre autres) :
- Architecture adaptative et multicouche
- Flux de données unidirectionnel dans toutes les couches de l'application
- Couche d'UI avec des conteneurs d'état pour gérer la complexité de l'UI
- Coroutines et flux
- Bonnes pratiques pour l'injection de dépendances
Pour en savoir plus, consultez Recommandations pour l'architecture Android.
Couche d'interface utilisateur
Le rôle de la couche de l'interface utilisateur (ou couche de présentation) consiste à afficher les données de l'application à l'écran. Chaque fois que les données changent, soit à la suite d'une interaction de l'utilisateur (par exemple, si celui-ci appuie sur un bouton) ou d'une entrée externe (telle qu'une réponse du réseau), l'UI est mise à jour pour refléter les modifications.
La couche UI comprend deux types de constructions :
- Éléments d'interface utilisateur qui affichent les données à l'écran. Ces éléments sont créés à l'aide des fonctions Jetpack Compose pour prendre en charge les mises en page adaptatives.
- Les conteneurs d'état (tels que
ViewModel) qui contiennent des données les exposent à l'UI et gèrent la logique. Les conteneurs d'état doivent exister pendant la même durée que l'élément d'UI pour lequel ils fournissent l'état. Par exemple, un ViewModel pour un écran doit être conservé en mémoire jusqu'à ce que l'écran soit supprimé de la pile "Retour" de l'application. Pour en savoir plus, consultez Durée de vie des états.
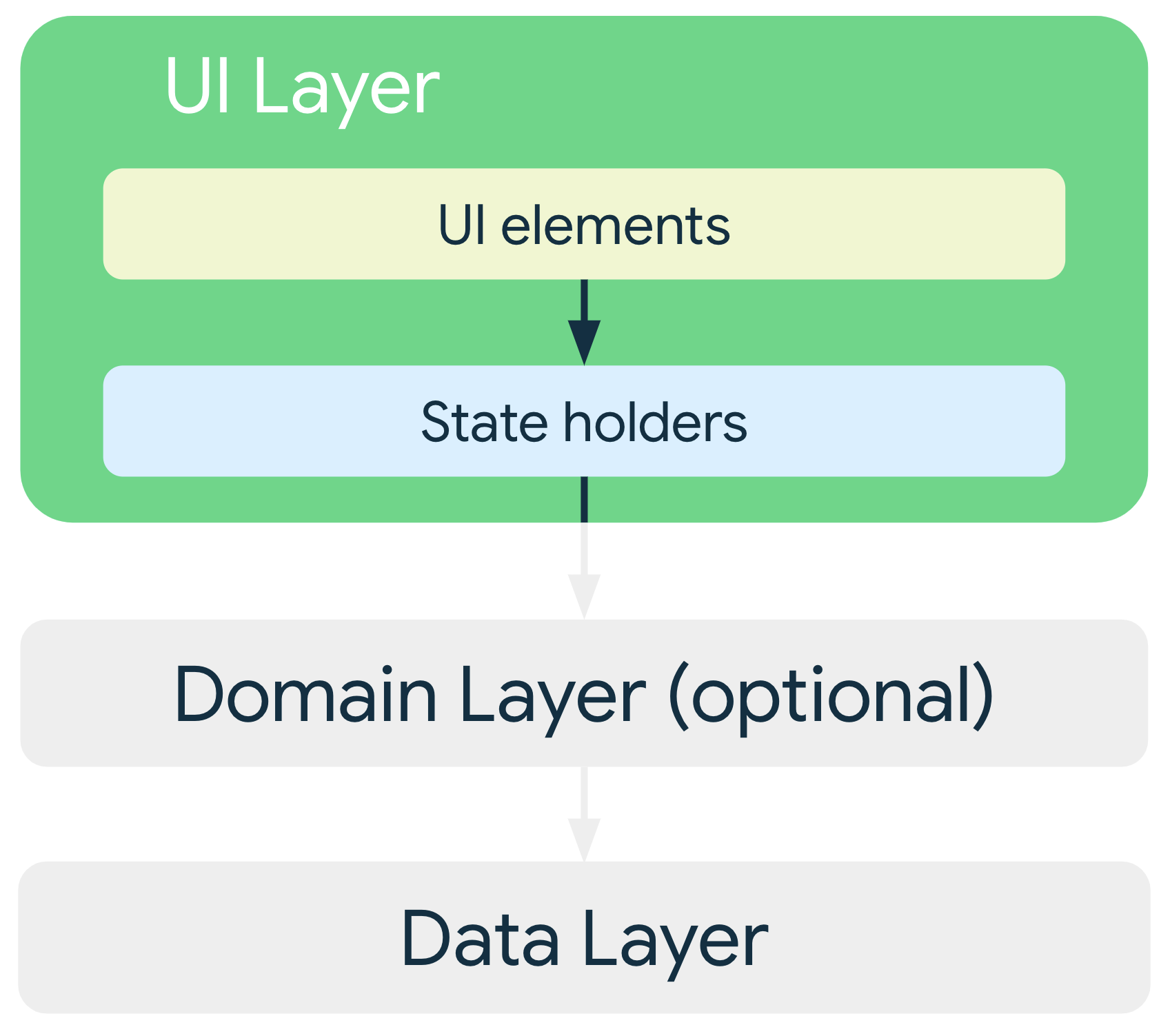
Pour les UI adaptatives, les détenteurs d'état tels que les objets ViewModel exposent l'état de l'UI qui s'adapte à différentes classes de taille de fenêtre. Vous pouvez utiliser currentWindowAdaptiveInfo() pour dériver cet état de l'UI. Les composants tels que NavigationSuiteScaffold peuvent ensuite utiliser ces informations pour basculer automatiquement entre différents modèles de navigation (par exemple, NavigationBar, NavigationRail ou NavigationDrawer) en fonction de l'espace disponible à l'écran.
Pour en savoir plus, consultez Couche d'interface utilisateur et Architecture de l'UI Compose.
Pour en savoir plus sur les applications et la navigation adaptatives, consultez Créer des applications adaptatives et Créer une navigation adaptative.
Couche de données
La couche de données d'une application contient la logique métier. La logique métier donne de la valeur à votre application. Elle repose sur des règles qui déterminent la manière dont votre application crée, stocke et modifie les données.
La couche de données est constituée de dépôts, chacun pouvant contenir de zéro à plusieurs sources de données. Créez une classe de dépôt pour chaque type de données que vous gérez dans votre application. Par exemple, vous pouvez créer une classe MoviesRepository pour les données liées aux films ou une classe PaymentsRepository pour les données liées aux paiements.
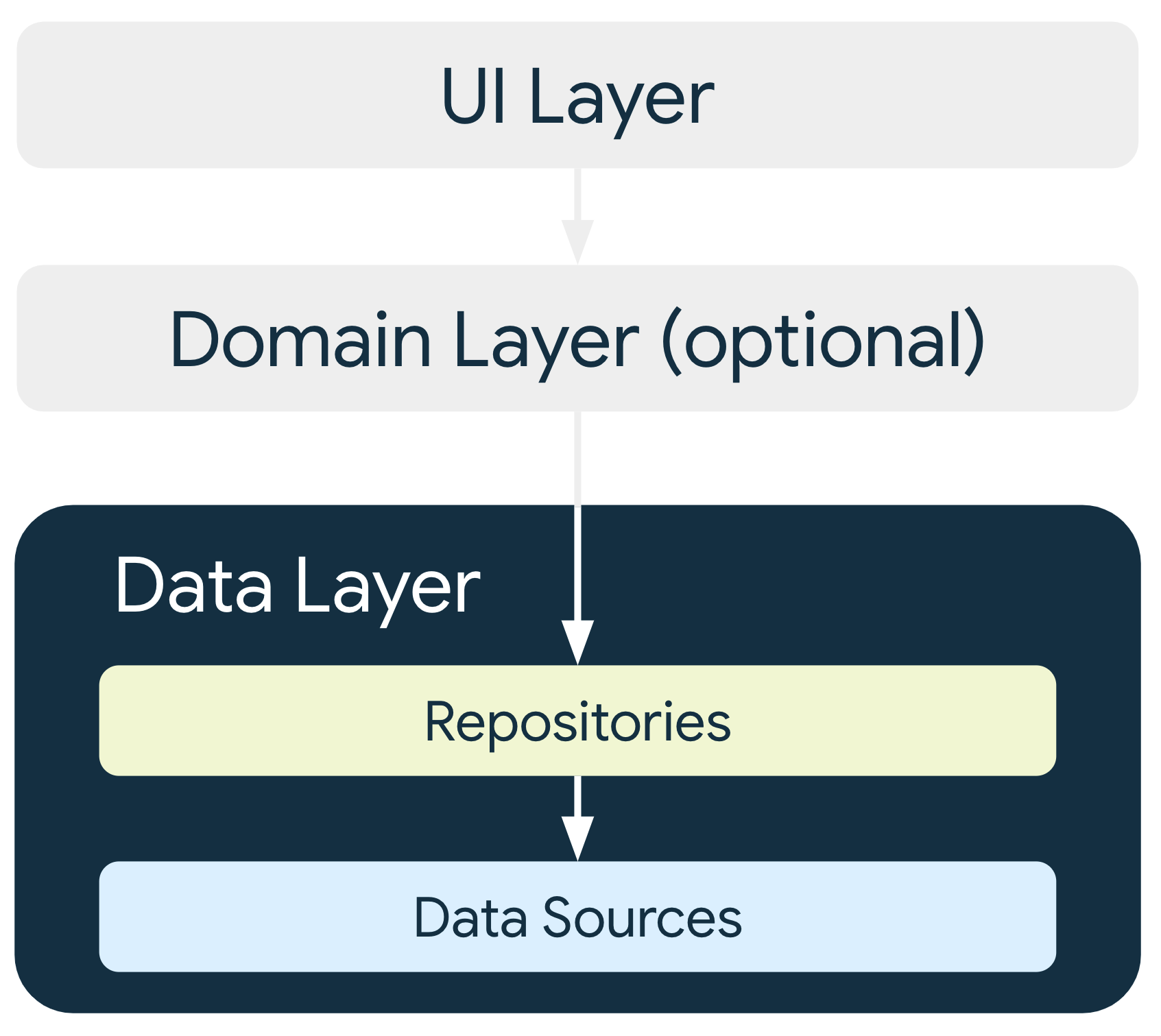
Les classes de dépôt sont responsables des éléments suivants :
- Présenter les données au reste de l'application
- Centraliser les modifications apportées aux données
- Résoudre les conflits entre plusieurs sources de données
- Extraire des sources de données du reste de l'application
- Contenir la logique métier
Chaque classe de source de données a la responsabilité de travailler avec une seule source de données, à savoir un fichier, une source réseau ou une base de données locale. Les classes de sources de données font le lien entre l'application et le système pour les opérations de données.
Pour en savoir plus, consultez la page sur la couche de données.
Couche de domaine
La couche de domaine est une couche facultative située entre les couches d'UI et de données.
La couche de domaine est chargée d'encapsuler une logique métier complexe, ou une logique métier simple qui est réutilisée par plusieurs ViewModels. La couche de domaine est facultative, car ces exigences ne s'appliquent pas à toutes les applications. Vous ne devez l'utiliser que lorsque cela est nécessaire, par exemple pour gérer la complexité ou favoriser la réutilisation.
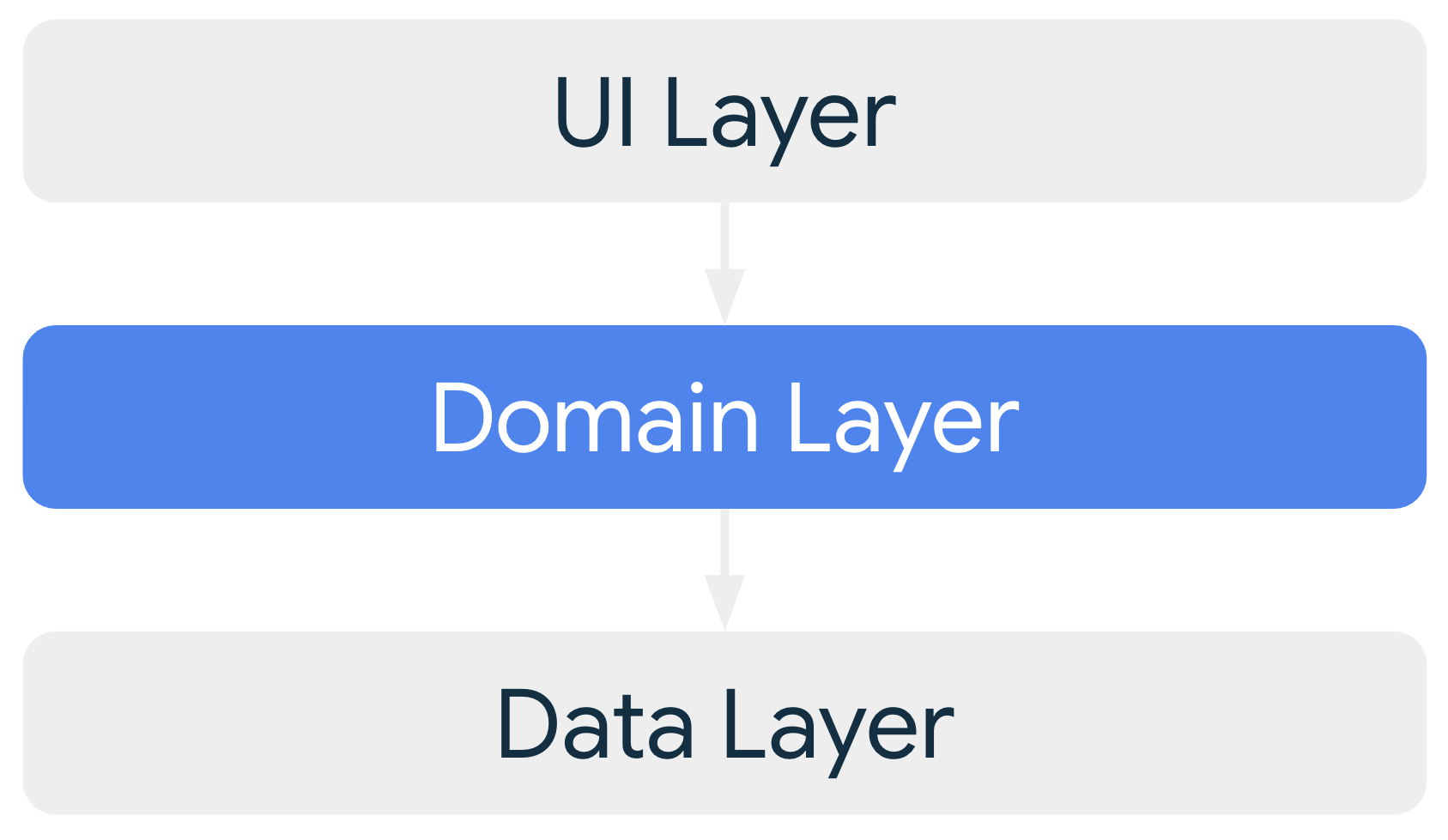
Les classes de la couche de domaine sont communément appelées use cases (cas d'utilisation) ou interactors (interacteurs).
Chaque cas d'utilisation est responsable d'une seule fonctionnalité. Par exemple, votre application peut avoir une classe GetTimeZoneUseCase si plusieurs modèles de vue utilisent les fuseaux horaires pour afficher le bon message à l'écran.
Pour en savoir plus, consultez la page sur la couche de domaine.
Gérer les dépendances entre les composants
Les classes de votre application dépendent d'autres classes pour fonctionner correctement. Vous pouvez utiliser l'un des modèles de conception suivants pour rassembler les dépendances d'une classe particulière :
- Injection de dépendances : l'injection de dépendances permet aux classes de définir leurs dépendances sans les créer. Au moment de l'exécution, une autre classe est chargée de fournir ces dépendances.
- Localisateur de services : le modèle de localisateur de services fournit un registre dans lequel les classes peuvent obtenir leurs dépendances au lieu de les construire.
Ces modèles vous permettent de faire évoluer votre code, car ils fournissent des modèles clairs qui permettent de gérer les dépendances sans dupliquer le code ni le complexifier. Les modèles vous permettent également de basculer rapidement entre les implémentations de test et de production.
Bonnes pratiques générales
La programmation est un domaine créatif, et le développement d'applications Android ne fait pas exception. Il existe de nombreuses façons de résoudre un problème. Vous pouvez communiquer des données entre plusieurs activités ou fragments, récupérer des données distantes et les conserver en local en mode hors connexion, ou gérer d'autres scénarios courants rencontrés par des applications complexes.
Bien que les recommandations suivantes ne soient pas obligatoires, dans la plupart des cas, elles rendent votre codebase plus solide, plus facile à tester et à gérer.
Ne stockez pas de données dans les composants d'une application.
Évitez de désigner les points d'entrée de votre application, tels que les activités, les services et les broadcast receivers comme sources de données. Faites en sorte que les points d'entrée se coordonnent avec d'autres composants pour récupérer uniquement le sous-ensemble de données correspondant à ce point d'entrée. Chaque composant d'application a une durée de vie courte, en fonction de l'interaction de l'utilisateur avec son appareil et de la capacité du système.
Réduisez les dépendances aux classes Android.
Faites en sorte que vos composants d'application soient les seules classes qui s'appuient sur les API SDK du framework Android telles que Context ou Toast. Extraire les autres classes de votre application des composants de l'application facilite les tests et réduit le couplage dans votre application.
Définissez des limites de responsabilité claires entre les modules de votre application.
Ne répartissez pas le code qui charge les données du réseau entre plusieurs classes ou packages de votre code base. De même, ne définissez pas plusieurs responsabilités non liées, comme la mise en cache et la liaison de données, dans la même classe. Suivez l'architecture d'application recommandée.
Exposez le moins d'éléments possible dans chaque module.
Ne créez pas de raccourcis qui exposent les informations détaillées sur une implémentation interne. Cela vous ferait peut-être gagner un peu de temps à court terme, mais vous risqueriez d'être confronté à de nombreuses contraintes techniques à mesure que votre codebase évolue.
Concentrez-vous sur le principe unique de votre application pour qu'elle se démarque des autres.
Ne réinventez pas la roue en écrivant le même code récurrent. Au lieu de cela, consacrez votre temps et votre énergie à ce qui rend votre application unique. Laissez les bibliothèques Jetpack et les autres bibliothèques recommandées gérer le code récurrent.
Utilisez des mises en page canoniques et des modèles de conception d'applications.
Les bibliothèques Jetpack Compose fournissent des API robustes pour créer des interfaces utilisateur adaptatives. Utilisez les mises en page standards dans votre application pour optimiser l'expérience utilisateur sur plusieurs facteurs de forme et tailles d'écran. Consultez la galerie de modèles de conception d'applications pour sélectionner les mises en page qui conviennent le mieux à vos cas d'utilisation.
Conservez l'état de l'UI en cas de modifications de configuration.
Lorsque vous concevez des mises en page adaptatives, conservez l'état de l'UI lors des changements de configuration, tels que le redimensionnement de l'écran, le pliage et les changements d'orientation. Votre architecture doit vérifier que l'état actuel de l'utilisateur est conservé, ce qui permet d'offrir une expérience fluide.
Concevez des composants d'UI réutilisables et composables.
Créez des composants d'UI réutilisables et composables pour prendre en charge la conception adaptative. Cela vous permet de combiner et de réorganiser les composants pour les adapter à différentes tailles d'écran et orientations sans refactorisation importante.
Réfléchissez à la façon dont chaque partie de votre application pourrait être testée de manière isolée.
Une API bien définie pour récupérer les données du réseau facilite le test du module qui conserve ces données dans une base de données locale. Si vous mélangez la logique de ces deux fonctions au même endroit ou que vous répartissez votre code réseau sur l'ensemble de votre code base, il devient beaucoup plus difficile, voire impossible, d'effectuer un test.
Les types sont responsables de leur règlement de simultanéité.
Si un type effectue un travail de blocage sur le long terme, il doit être chargé de déplacer ce calcul vers le thread approprié. Le type sait quel type de calcul il effectue et dans quel thread exécuter le calcul. Les types doivent être sécurisés, c'est-à-dire qu'ils peuvent être appelés en toute sécurité depuis le thread principal sans le bloquer.
Conservez des données aussi pertinentes et récentes que possible.
De cette façon, les utilisateurs peuvent profiter des fonctionnalités de votre application même lorsque leur appareil est en mode hors connexion. N'oubliez pas que tous vos utilisateurs ne bénéficient pas d'une connectivité constante et rapide, et que même dans ce cas, ils peuvent rencontrer des problèmes de réception dans les lieux très fréquentés.
Avantages de l'architecture
Une architecture de bonne qualité implémentée dans votre application présente de nombreux avantages pour les équipes de projet et d'ingénierie :
- Elle améliore la gestion, la qualité et la robustesse de l'application dans son ensemble.
- Permet à l'application de s'adapter. Davantage de personnes et d'équipes peuvent contribuer au même codebase sans se heurter à des conflits de code.
- Elle facilite l'intégration. À mesure que l'architecture apporte de la cohérence à votre projet, les nouveaux membres de l'équipe peuvent devenir rapidement opérationnels et plus efficaces en moins de temps.
- Les tests sont facilités. Une bonne architecture favorise des types plus simples, qui sont généralement plus faciles à tester.
- Vous permet d'examiner les bugs de manière méthodique avec des processus bien définis.
Bien qu'une bonne architecture nécessite un investissement en temps préliminaire, elle a également un impact direct sur les utilisateurs. Ils bénéficient d'une application plus stable et de plus de fonctionnalités grâce à une équipe d'ingénierie plus productive.
Exemples
Les exemples suivants montrent ce qui constitue une bonne architecture d'application :