
La couche de domaine est une couche facultative située entre la couche de l'interface utilisateur et la couche de données.
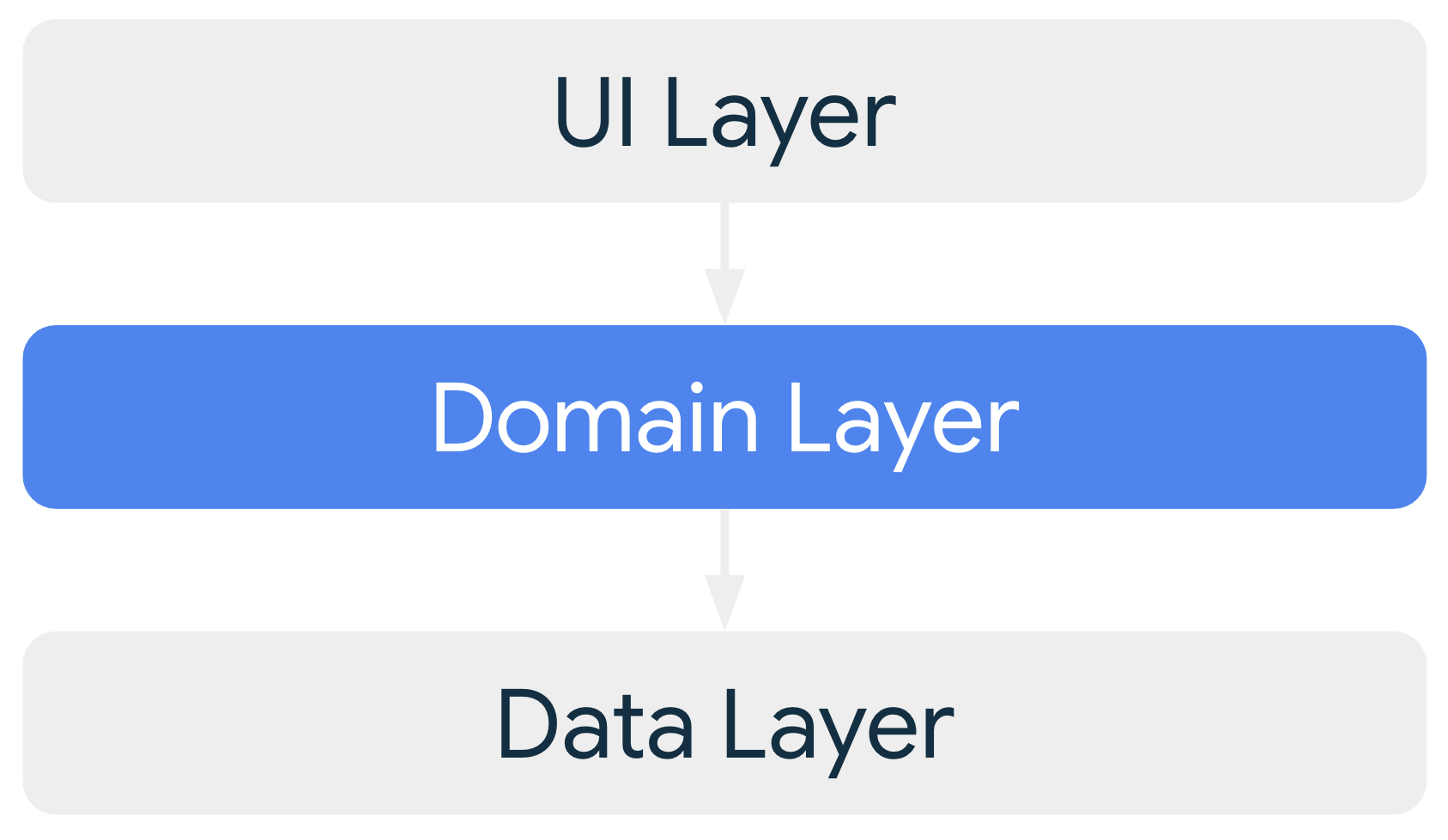
La couche de domaine est chargée d'encapsuler une logique métier complexe, ou une logique métier simple qui est réutilisée par plusieurs ViewModels. Cette couche est facultative, car ces exigences ne s'appliquent pas à toutes les applications. Vous ne devez l'utiliser que lorsque cela est nécessaire, par exemple pour gérer la complexité ou favoriser la réutilisation.
Une couche de domaine offre les avantages suivants :
- Elle évite la duplication de code.
- Elle améliore la lisibilité des classes qui utilisent des classes de couche de domaine.
- Elle améliore la testabilité de l'application.
- Elle évite les classes volumineuses en vous permettant de partager les responsabilités.
Pour que ces classes soient simples et légères, chaque cas d'utilisation ne doit être responsable que d'une seule fonctionnalité et ne doit pas contenir de données modifiables. Vous devez gérer les données modifiables dans l'interface utilisateur ou les couches de données.
Conventions d'attribution de noms dans ce guide
Dans ce guide, les cas d'utilisation portent le nom de l'action unique dont ils sont responsables. La convention est la suivante :
verbe au présent + nom/quoi (facultatif) + UseCase
Par exemple : FormatDateUseCase, LogOutUserUseCase,
GetLatestNewsWithAuthorsUseCase ou MakeLoginRequestUseCase.
Dépendances
Dans une architecture d'application classique, les classes de cas d'utilisation se situent entre les ViewModels de la couche d'UI et les dépôts de la couche de données. Cela signifie que les classes de cas d'utilisation dépendent généralement des classes de dépôt et qu'elles communiquent avec la couche d'interface utilisateur de la même manière que les dépôts, à l'aide de rappels (Java) ou de coroutines (Kotlin). Pour en savoir plus à ce sujet, consultez la page sur la couche de données.
Par exemple, dans votre application, vous pouvez avoir une classe de cas d'utilisation qui extrait des données d'un dépôt d'actualités et d'un dépôt d'auteurs, puis les combine :
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository
) { /* ... */ }
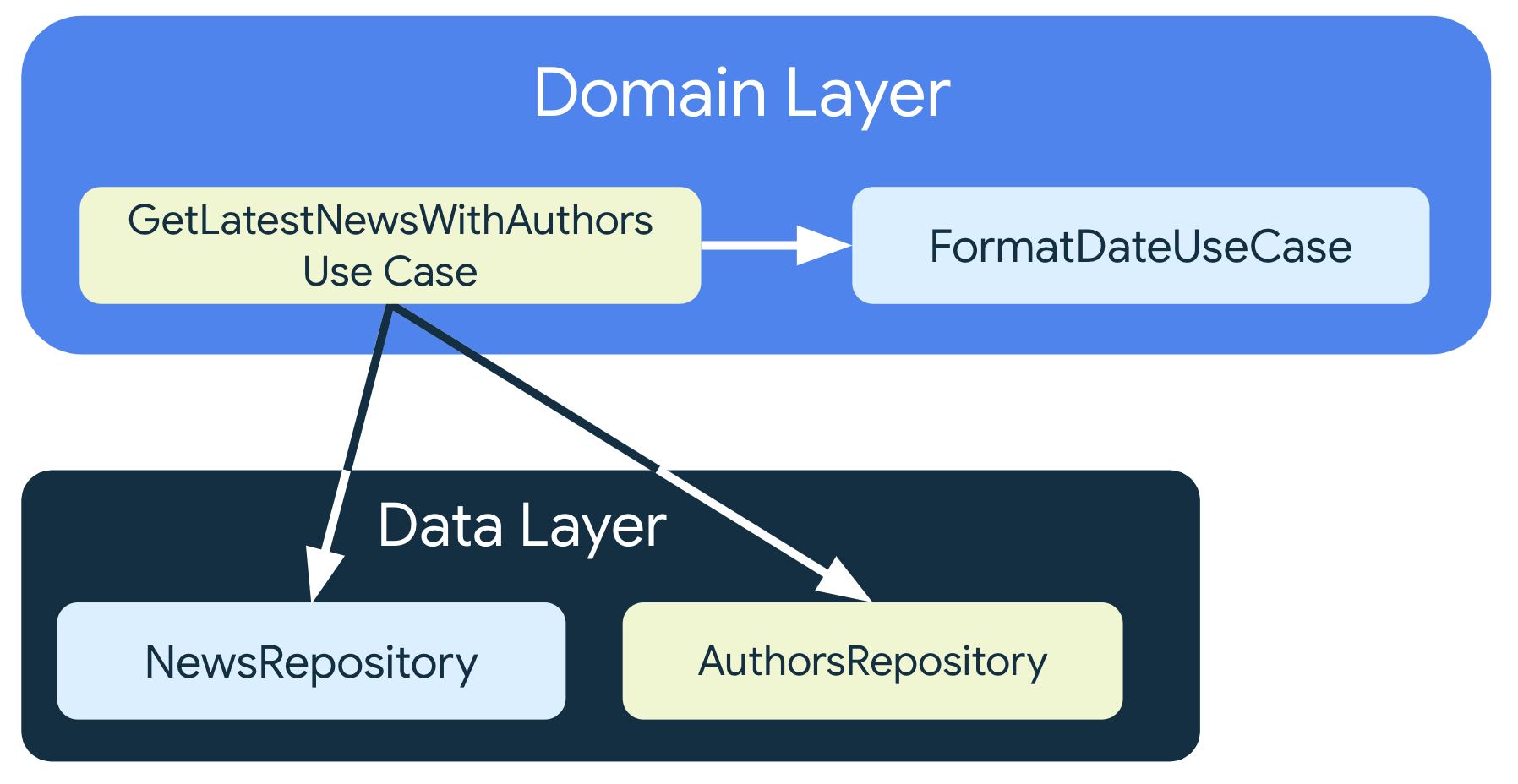
Étant donné que les cas d'utilisation contiennent une logique réutilisable, ils peuvent également être utilisés par d'autres cas d'utilisation. Il est normal d'avoir plusieurs niveaux de cas d'utilisation dans la couche de domaine. Par exemple, le cas d'utilisation défini dans l'exemple ci-dessous peut s'appuyer sur FormatDateUseCase si plusieurs classes de la couche de l'interface utilisateur reposent sur les fuseaux horaires pour afficher le bon message à l'écran.
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository,
private val formatDateUseCase: FormatDateUseCase
) { /* ... */ }
Cas d'utilisation des appels dans Kotlin
Dans Kotlin, vous pouvez faire en sorte que les instances de cas d'utilisation puissent être appelées en tant que fonctions en définissant invoke() avec le modificateur operator. Consultez l'exemple suivant :
class FormatDateUseCase(userRepository: UserRepository) {
private val formatter = SimpleDateFormat(
userRepository.getPreferredDateFormat(),
userRepository.getPreferredLocale()
)
operator fun invoke(date: Date): String {
return formatter.format(date)
}
}
Dans cet exemple, la méthode invoke() dans FormatDateUseCase vous permet d'appeler des instances de la classe comme s'il s'agissait de fonctions. La méthode invoke() n'est limitée à aucune signature spécifique. Elle peut accepter un nombre illimité de paramètres et renvoyer n'importe quel type. Vous pouvez également surcharger invoke() avec différentes signatures dans votre classe. Vous pouvez appeler le cas d'utilisation de l'exemple ci-dessus comme suit :
class MyViewModel(formatDateUseCase: FormatDateUseCase) : ViewModel() {
init {
val today = Calendar.getInstance()
val todaysDate = formatDateUseCase(today)
/* ... */
}
}
Pour en savoir plus sur l'opérateur invoke(), consultez la documentation Kotlin.
Cycle de vie
Les cas d'utilisation ne disposent pas de leur propre cycle de vie. Ils se limitent à la classe qui les utilise. Cela signifie que vous pouvez appeler des cas d'utilisation depuis les classes de la couche de l'interface utilisateur, les services ou la classe Application. Étant donné que les cas d'utilisation ne doivent pas contenir de données modifiables, vous devez créer une instance d'une classe de cas d'utilisation chaque fois que vous la transmettez en tant que dépendance.
Exécution de threads
Les cas d'utilisation de la couche de domaine doivent être sécurisés. En d'autres termes, ils doivent pouvoir être appelés en toute sécurité depuis le thread principal. Si les classes de cas d'utilisation effectuent des opérations de blocage de longue durée, elles sont chargées de déplacer cette logique vers le thread approprié. Toutefois, vérifiez en amont s'il est préférable de placer ces opérations de blocage dans d'autres couches de la hiérarchie. En règle générale, des calculs complexes sont effectués dans la couche de données pour encourager la réutilisation ou la mise en cache. Par exemple, mieux vaut placer une opération nécessitant beaucoup de ressources sur une longue liste dans la couche de données que dans la couche de domaine si le résultat doit être mis en cache pour une réutilisation sur plusieurs écrans de l'application.
L'exemple suivant montre un cas d'utilisation qui effectue sa tâche sur un thread d'arrière-plan :
class MyUseCase(
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend operator fun invoke(...) = withContext(defaultDispatcher) {
// Long-running blocking operations happen on a background thread.
}
}
Tâches courantes
Cette section explique comment effectuer des tâches de couche de domaine courantes.
Logique métier simple et réutilisable
Vous devez encapsuler la logique métier reproductible présente dans la couche de l'interface utilisateur dans une classe de cas d'utilisation. Cela permet d'appliquer plus facilement les modifications partout où la logique est utilisée. Cette méthode vous permet également de tester la logique de manière isolée.
Prenons l'exemple FormatDateUseCase décrit précédemment. Si vos exigences métiers concernant le formatage des dates évoluent, vous n'aurez qu'à modifier le code à un seul endroit.
Combiner des dépôts
Dans une application d'actualités, vous pouvez avoir des classes NewsRepository et AuthorsRepository qui traitent respectivement les opérations de données liées aux actualités et aux auteurs. La classe Article exposée par NewsRepository ne contient que le nom de l'auteur, mais vous souhaitez afficher plus d'informations sur celui-ci à l'écran. Vous pouvez obtenir des informations sur l'auteur à partir de AuthorsRepository.
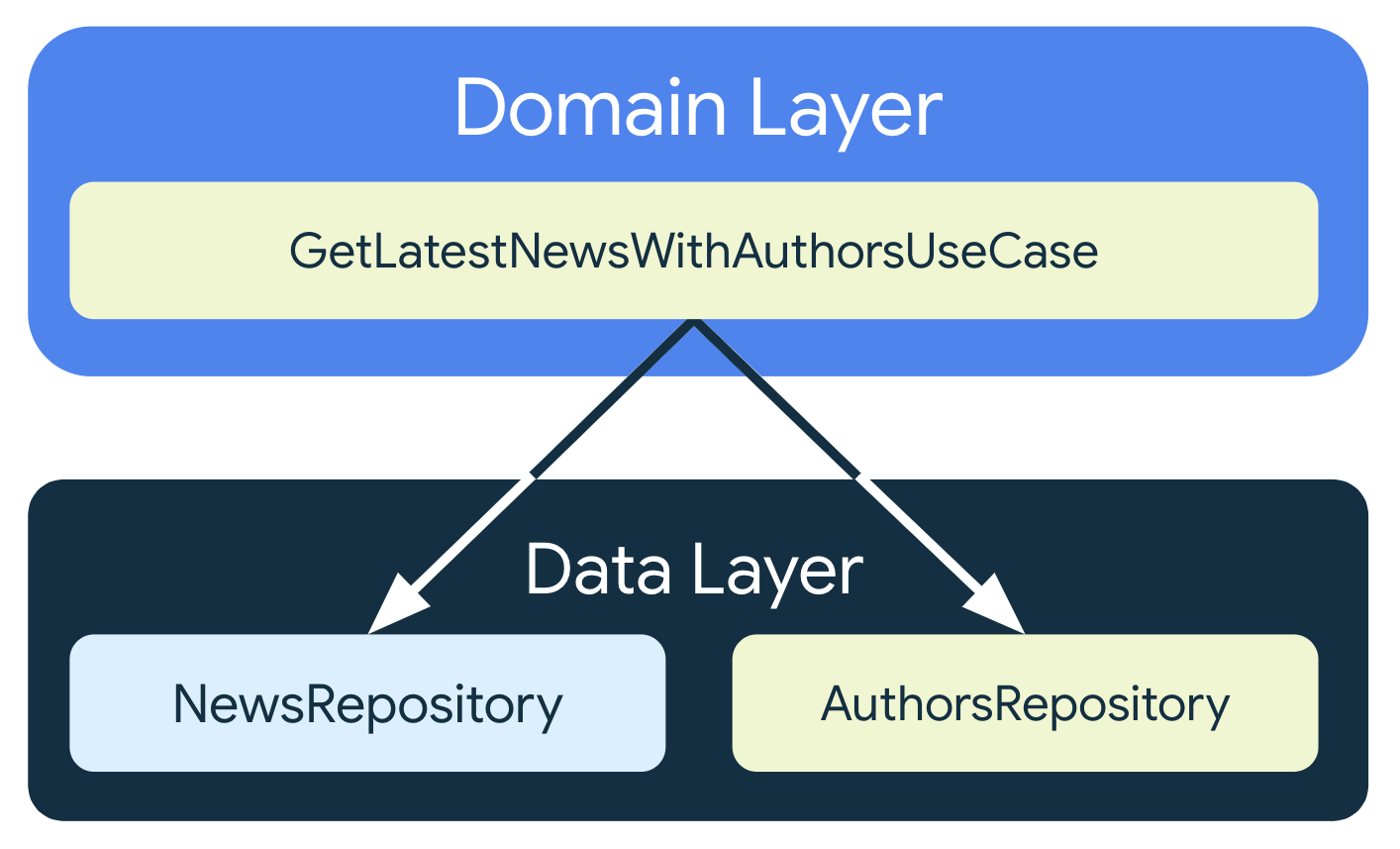
Comme la logique implique plusieurs dépôts et peut devenir complexe, vous devez créer une classe GetLatestNewsWithAuthorsUseCase pour extraire la logique du ViewModel et la rendre plus lisible. Cela facilite également les tests isolés et la réutilisation dans différentes parties de l'application.
/**
* This use case fetches the latest news and the associated author.
*/
class GetLatestNewsWithAuthorsUseCase(
private val newsRepository: NewsRepository,
private val authorsRepository: AuthorsRepository,
private val defaultDispatcher: CoroutineDispatcher = Dispatchers.Default
) {
suspend operator fun invoke(): List<ArticleWithAuthor> =
withContext(defaultDispatcher) {
val news = newsRepository.fetchLatestNews()
val result: MutableList<ArticleWithAuthor> = mutableListOf()
// This is not parallelized, the use case is linearly slow.
for (article in news) {
// The repository exposes suspend functions
val author = authorsRepository.getAuthor(article.authorId)
result.add(ArticleWithAuthor(article, author))
}
result
}
}
La logique mappe tous les éléments de la liste news. Ainsi, même si la couche de données est sécurisée, ce thread ne doit pas bloquer le thread principal, car vous ne connaissez pas le nombre d'éléments traités. C'est pourquoi le cas d'utilisation déplace la tâche vers un thread d'arrière-plan à l'aide du coordinateur par défaut.
Autres consommateurs
Outre la couche de l'interface utilisateur, la couche de domaine peut être réutilisée par d'autres classes, telles que les services et la classe Application. De plus, si d'autres plates-formes telles que TV ou Wear partagent le codebase de l'application mobile, leur couche d'interface utilisateur peut également réutiliser des cas d'utilisation pour bénéficier de tous les avantages mentionnés ci-dessus.
Restriction d'accès à la couche de données
Un autre élément à prendre en compte lors de l'implémentation de la couche du domaine est de savoir si vous devez toujours autoriser l'accès direct à la couche de données depuis la couche d'UI ou forcer l'accès via la couche du domaine.
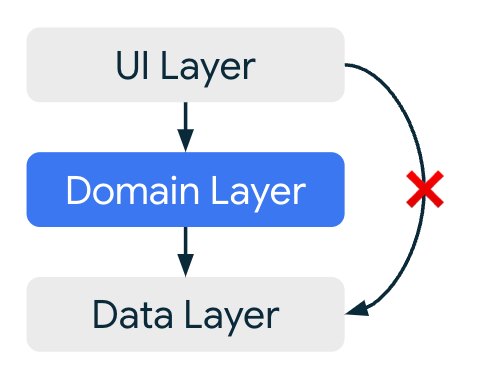
Cette restriction présente l'avantage d'empêcher votre UI de contourner la logique de la couche de domaine ; par exemple, si vous effectuez une journalisation analytique sur chaque demande d'accès à la couche de données.
Cependant, cela peut éventuellement présenter un inconvénient majeur, à savoir qu'elle vous oblige à ajouter des cas d'utilisation, même s'il s'agit d'appels de fonction simples vers la couche de données, ce qui peut compliquer les choses sans apporter beaucoup d'avantages.
Une bonne approche consiste à n'ajouter des cas d'utilisation que lorsque cela s'avère nécessaire. Si vous constatez que votre couche d'UI accède presque exclusivement aux données par le biais de cas d'utilisation, il peut être judicieux de n'y accéder que de cette manière.
En fin de compte, la décision de restreindre l'accès à la couche de données dépend de deux facteurs : votre codebase individuel et si vous préférez des règles strictes ou une approche plus flexible.
Test
Les consignes générales relatives aux tests s'appliquent lors du test de la couche de domaine. Pour les autres tests d'UI, les développeurs utilisent généralement de faux dépôts. Il est également recommandé d'utiliser des faux dépôts lorsque vous testez la couche de domaine.
Exemples
Les exemples Google suivants illustrent l'utilisation de la couche de domaine. Parcourez-les pour voir ces conseils en pratique :
Recommandations personnalisées
- Remarque : Le texte du lien s'affiche lorsque JavaScript est désactivé
- Couche de données
- Production de l'état de l'interface utilisateur