
A camada de interface contém o estado relacionado à interface e a lógica da interface, enquanto a camada de dados contém dados do aplicativo e lógica de negócios. A lógica de negócios é o que agrega valor ao seu app. Ela é composta por regras de negócios reais que determinam como os dados do aplicativo precisam ser criados, armazenados e alterados.
Essa separação de problemas permite que a camada de dados seja usada em várias telas, compartilhe informações entre diferentes partes do aplicativo e reproduza a lógica de negócios fora da interface para testes de unidade. Para saber mais sobre os benefícios da camada de dados, consulte a Página de visão geral da arquitetura.
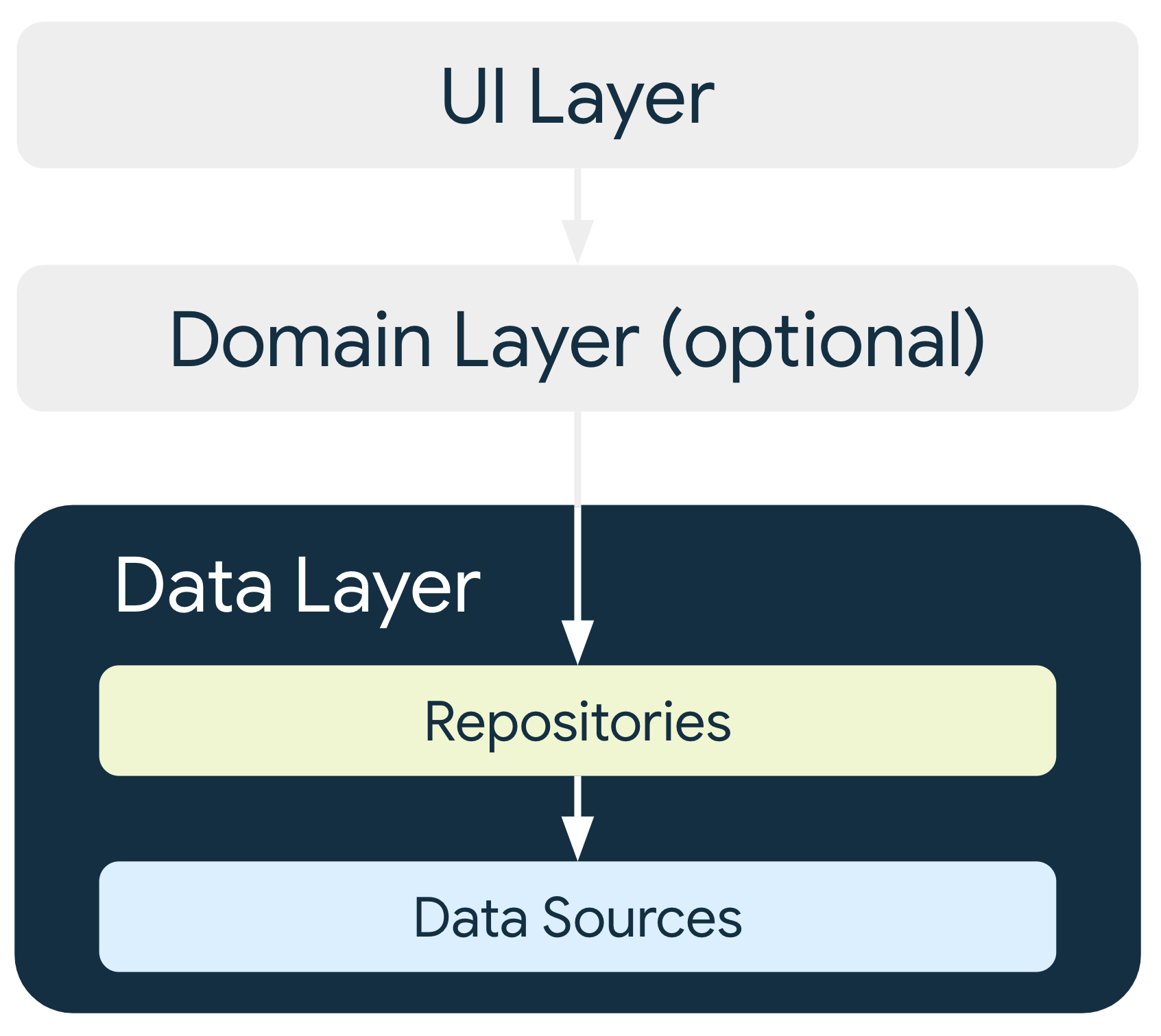
Arquitetura da camada de dados
A camada de dados é composta por repositórios que podem conter de zero a muitas
fontes de dados. Crie uma classe de repositório para cada tipo diferente de
dados processados no seu app. Por exemplo, você pode criar uma classe MoviesRepository
para dados relacionados a filmes ou uma classe PaymentsRepository para dados
relacionados a pagamentos.
As classes de repositório são responsáveis por estas tarefas:
- Expor dados ao restante do app.
- Centralizar mudanças nos dados.
- Resolver conflitos entre várias fontes de dados.
- Abstrair fontes de dados do restante do app.
- Conter uma lógica de negócios.
Cada classe de fonte de dados deve ser responsável por trabalhar com apenas uma origem, que pode ser um arquivo, uma rede ou um banco de dados local. As classes de fonte de dados são a ponte entre o aplicativo e o sistema para operações de dados.
Outras camadas na hierarquia não podem acessar diretamente as fontes de dados. Os pontos de entrada para a camada de dados são sempre as classes de repositório. As classes do detentor de estado (consulte o Guia da camada da interface) ou as classes de caso de uso (consulte o Guia da camada do domínio) não devem ter uma fonte de dados como uma dependência direta. O uso de classes de repositório como pontos de entrada permite que as diferentes camadas da arquitetura sejam escalonadas de forma independente.
Os dados expostos por essa camada precisam ser imutáveis para que não possam ser adulterados por outras classes, o que arriscaria colocar os valores em um estado inconsistente. Dados imutáveis também podem ser processados com segurança por várias linhas de execução. Consulte a seção de linhas de execução para saber mais.
Seguindo as práticas recomendadas de injeção de dependência, o repositório usa fontes de dados como dependências no construtor:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Expor APIs
As classes na camada de dados geralmente expõem funções para realizar chamadas únicas de criação, leitura, atualização e exclusão (CRUD, na sigla em inglês) ou para serem notificadas sobre mudanças de dados ao longo do tempo. A camada de dados precisa expor os seguintes itens para cada um desses casos:
- Para operações únicas, exponha funções de suspensão.
- Para receber notificações sobre mudanças de dados ao longo do tempo, exponha fluxos.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Convenções de nomenclatura neste guia
Neste guia, as classes de repositório são nomeadas com base nos dados pelos quais são responsáveis. A convenção é a seguinte:
tipo de dados + repositório.
Por exemplo: NewsRepository, MoviesRepository ou PaymentsRepository.
As classes da fonte de dados têm o nome dos dados pelos quais são responsáveis e da fonte que usam. A convenção é a seguinte:
tipo de dados + tipo de fonte + DataSource.
Para o tipo de dados, use Remote ou Local para ser mais genérico, porque
as implementações podem mudar. Por exemplo: NewsRemoteDataSource ou
NewsLocalDataSource. Para ser mais específico caso a fonte seja importante, use
o tipo dela. Por exemplo: NewsNetworkDataSource ou
NewsDiskDataSource.
Não nomeie a fonte de dados com base em um detalhe de implementação, por exemplo,
UserSharedPreferencesDataSource, porque os repositórios que usam essa fonte
não devem saber como os dados são salvos. Se você seguir essa regra, poderá mudar
a implementação da fonte de dados (por exemplo, migrar de
SharedPreferences para DataStore) sem afetar a camada que chama
essa fonte.
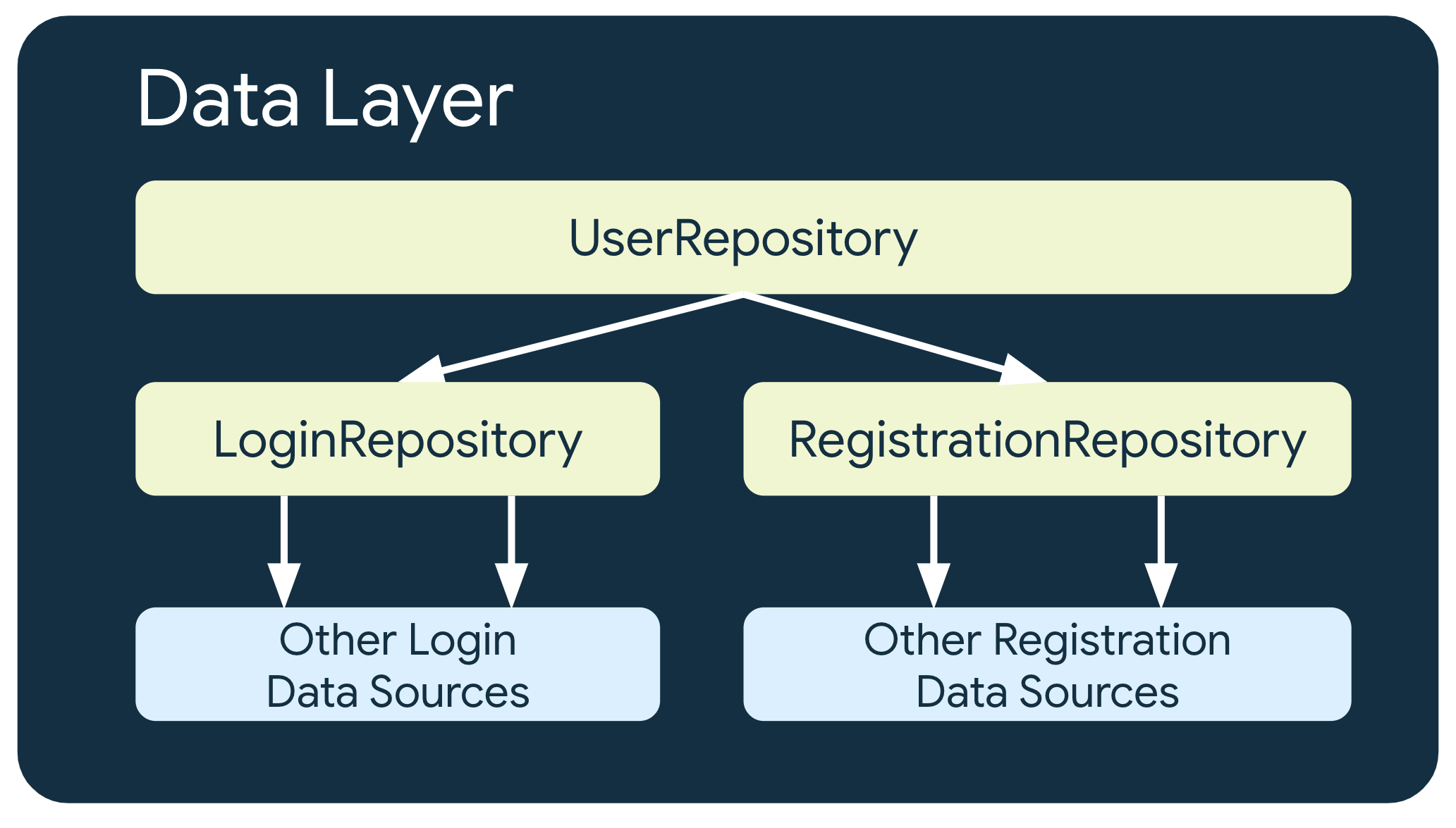
Vários níveis de repositórios
Em alguns casos que envolvem requisitos de negócios mais complexos, um repositório talvez precise depender de outros repositórios. Isso pode acontecer porque os dados envolvidos são uma agregação de várias fontes de dados ou porque a responsabilidade precisa ser encapsulada em outra classe de repositório.
Por exemplo, um repositório que processa dados de autenticação do usuário,
UserRepository, pode depender de outros repositórios, por exemplo, LoginRepository
e RegistrationRepository, para atender aos requisitos.
Fonte de verdade
É importante que cada repositório defina uma única fonte de verdade. A fonte de verdade sempre contém dados consistentes, corretos e atualizados. Na realidade, os dados expostos do repositório precisam ser sempre aqueles que provêm diretamente da fonte de verdade.
A fonte de verdade pode ser uma fonte de dados, por exemplo, um banco de dados, ou até mesmo um cache na memória que o repositório pode conter. Os repositórios combinam fontes de dados diferentes e resolvem possíveis conflitos entre elas para atualizar regularmente a única fonte de verdade ou devido a um evento de entrada do usuário.
Repositórios diferentes no app podem ter fontes de verdade distintas. Por
exemplo, a classe LoginRepository pode usar o próprio cache como fonte de verdade,
e a classe PaymentsRepository pode usar a fonte de dados da rede.
Para oferecer compatibilidade que prioriza o modo off-line, uma fonte de dados local, por exemplo, um banco de dados, é a fonte de verdade recomendada.
Linhas de execução
A chamada de fontes de dados e repositórios precisa ser protegida, ou seja, segura para chamadas pela linha de execução principal. Essas classes são responsáveis por mover a execução da lógica para a linha de execução adequada ao realizar operações de bloqueio de longa duração. Por exemplo, precisa ser seguro para uma fonte de dados ler de um arquivo ou para um repositório executar filtros dispendiosos em uma lista grande.
Observe que a maioria das fontes de dados já oferece APIs seguras para o encadeamento principal, como as chamadas de método de suspensão fornecidas pelo Room, Retrofit ou Ktor. Seu repositório pode aproveitar essas APIs quando elas estiverem disponíveis.
Para saber mais sobre linhas de execução, consulte o guia para processamento em segundo plano. Para usuários do Kotlin, as corrotinas são a opção recomendada.
Ciclo de vida
As instâncias de classes na camada de dados permanecerão na memória enquanto puderem ser acessadas de uma raiz de coleta de lixo, geralmente com referência em outros objetos do app.
Se uma classe contiver dados na memória (por exemplo, um cache), convém reutilizar a mesma instância dessa classe por um período específico. Isso também é chamado de ciclo de vida da instância da classe.
Se a responsabilidade da classe é essencial para todo o aplicativo, é possível
definir o escopo de uma instância dessa classe para a classe Application. Isso faz com que
a instância siga o ciclo de vida do aplicativo. Como alternativa, se você só
precisa reutilizar a mesma instância em um fluxo específico no app (por exemplo,
o fluxo de cadastro ou login), provavelmente é o caso de definir o escopo da instância para a classe
que contém o ciclo de vida desse fluxo. Por exemplo, é possível definir o escopo de um
RegistrationRepository que contém dados na memória para o
RegistrationActivity ou para uma pilha de retorno usando um NavEntryDecorator.
O ciclo de vida de cada instância é um fator essencial para decidir como fornecer dependências no app. É recomendável seguir as práticas recomendadas de injeção de dependência em que elas são gerenciadas e podem ter o escopo definido para contêineres de dependência. Para saber mais sobre o escopo no Android, consulte a postagem do blog Escopo no Android e no Hilt (em inglês).
Representar modelos de negócios
Os modelos de dados que você quer expor da camada de dados podem ser um subconjunto das informações recebidas de diferentes fontes. O ideal é que as diferentes fontes, tanto de rede quanto locais, retornem apenas as informações de que o aplicativo precisa. Porém, geralmente, esse não é o caso.
Por exemplo, imagine um servidor da API Google Notícias que retorna não só as informações do artigo, mas também o histórico de edições, os comentários dos usuários e alguns metadados:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
Esse app não precisa de muitas informações sobre o artigo porque
ele exibe apenas o conteúdo da matéria na tela, além de informações básicas
sobre o autor. Uma prática recomendada é separar as classes de modelo e fazer com que os
repositórios exponham apenas os dados exigidos pelas outras camadas da
hierarquia. Por exemplo, veja como reduzir o ArticleApiModel da
rede para expor uma classe de modelo Article às camadas de domínio
e IU:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
A separação de classes de modelo é benéfica das seguintes maneiras:
- Ela economiza memória do app reduzindo os dados apenas para o que é necessário.
- Ela adapta os tipos de dados externos aos tipos usados pelo app. Por exemplo, o app pode usar um tipo de dados diferente para representar datas.
- Ela oferece uma separação melhor de problemas. Por exemplo, membros de uma equipe grande podem trabalhar individualmente nas camadas de rede e UI de um recurso se a classe de modelo é definida com antecedência.
Também é possível ampliar essa prática e definir classes de modelo separadas em outras partes da arquitetura do app, por exemplo, em classes de fonte de dados e ViewModels. No entanto, isso exige que você defina classes e lógicas extras que precisam ser documentadas e testadas corretamente. No mínimo, recomendamos que você crie novos modelos quando uma fonte de dados receber dados que não correspondem ao que o restante do app espera.
Tipos de operações de dados
A camada de dados pode lidar com tipos de operações que variam de acordo com a importância delas: orientadas a IU, a apps e a negócios.
Operações para IU
As operações para interface são relevantes apenas quando o usuário está em uma tela específica e são canceladas quando o usuário sai da tela. Um exemplo é a exibição de alguns dados recebidos do banco de dados.
Operações para interface geralmente são acionadas pela camada de interface e seguem o ciclo de vida do autor da chamada, por exemplo, o ciclo de vida do ViewModel. Consulte a seção Fazer uma solicitação de rede para um exemplo de operação para IU.
Operações para apps
Operações para apps são relevantes enquanto o app está aberto. Se o app for fechado ou o processo for encerrado, essas operações serão canceladas. Um exemplo é armazenar em cache o resultado de uma solicitação de rede para que ele possa ser usado mais tarde, se necessário. Consulte a seção Implementar o armazenamento em cache de dados na memória para saber mais.
Essas operações normalmente seguem o ciclo de vida da classe Application ou
da camada de dados. Consulte a seção Tornar uma operação ativa por mais tempo do que a
tela para ver um exemplo.
Operações para negócios
Operações para negócios não podem ser canceladas. Elas precisam sobreviver ao encerramento do processo. Veja um exemplo de conclusão do upload de uma foto que o usuário quer postar no perfil.
A recomendação para esse tipo de operação é usar o WorkManager. Consulte a seção Programar tarefas usando o WorkManager para saber mais.
Expor erros
As interações com repositórios e fontes de dados podem ser bem-sucedidas ou gerar
uma exceção quando ocorre uma falha. Para corrotinas e fluxos, use
o mecanismo integrado de tratamento de erros do Kotlin. Para erros que podem ser
acionados por funções de suspensão, use blocos try/catch quando adequado e, em
fluxos, use o operador catch. Com essa abordagem, espera-se que a camada de UI processe as exceções ao chamar a camada de dados.
A camada de dados pode entender e processar diferentes tipos de erros que podem ser expostos
usando exceções personalizadas, como UserNotAuthenticatedException.
Para saber mais sobre erros em corrotinas, consulte a postagem do blog Exceções em corrotinas (link em inglês).
Tarefas comuns
As próximas seções apresentam exemplos de como usar e arquitetar a camada de dados para realizar determinadas tarefas comuns em apps Android. Os exemplos são baseados no app normal do Google Notícias mencionado anteriormente no guia.
Fazer uma solicitação de rede
Fazer uma solicitação de rede é uma das tarefas mais comuns que um app para Android pode
realizar. O app Google Notícias precisa apresentar ao usuário as últimas notícias encontradas na rede. Portanto, o app precisa de uma classe de fonte de dados para gerenciar
operações de rede: NewsRemoteDataSource. Para expor as informações no restante do app, será criado um novo repositório que processa operações em dados de
notícias: NewsRepository.
O requisito é que as notícias mais recentes sempre precisam ser atualizadas quando o usuário abre a tela. Portanto, esta é uma operação para IU.
Criar a fonte de dados
A fonte de dados precisa expor uma função que retorne as notícias mais recentes: uma lista
de instâncias de ArticleHeadline. A fonte de dados precisa fornecer uma maneira segura
de receber as notícias mais recentes da rede. Para isso, ela precisa de uma
dependência de CoroutineDispatcher ou Executor para executar a tarefa.
Fazer uma solicitação de rede é uma chamada única processada por um novo método
fetchLatestNews():
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
A interface NewsApi oculta a implementação do cliente da API de rede. Não
faz diferença se a interface é apoiada pela Retrofit ou
HttpURLConnection. Confiar em interfaces torna as implementações da API alternáveis no seu app.
Criar o repositório
Como nenhuma lógica extra é necessária na classe do repositório para essa tarefa,
NewsRepository atua como um proxy para a fonte de dados da rede. Os benefícios de
adicionar essa camada extra de abstração são explicados na seção Armazenamento em
cache na memória.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
Para saber como consumir a classe do repositório diretamente da camada da IU, consulte o guia Camada da IU.
Implementar o armazenamento em cache de dados na memória
Imagine que um novo requisito seja introduzido para o app Google Notícias: quando o usuário abrir a tela, as notícias em cache precisarão ser apresentadas a ele, se uma solicitação tiver sido feita. Caso contrário, o app precisará fazer uma solicitação de rede para buscar as notícias mais recentes.
Considerando o novo requisito, o app precisa preservar as notícias mais recentes na memória enquanto o usuário estiver com o app aberto. Portanto, esta é uma operação para apps.
Caches
É possível preservar os dados enquanto o usuário está no app, adicionando armazenamento em cache na memória. O objetivo do armazenamento em cache é salvar algumas informações na memória por um período específico. Nesse caso, elas são salvas enquanto o usuário está no app. As implementações de cache podem assumir diferentes formas. Elas podem variar de variáveis mutáveis simples a classes mais sofisticadas que protegem contra operações de leitura/gravação em várias linhas de execução. Dependendo do caso de uso, o armazenamento em cache pode ser implementado no repositório ou em classes de fonte de dados.
Armazenar em cache o resultado da solicitação de rede
Para simplificar, NewsRepository usa uma variável mutável para armazenar em cache as notícias mais
recentes. Para proteger leituras e gravações de linhas de execução diferentes, é usado um Mutex. Para saber mais sobre o estado mutável compartilhado e simultaneidade, consulte a documentação do
Kotlin (em inglês).
A implementação a seguir armazena em cache as informações mais recentes de notícias em uma variável no
repositório que é protegido contra gravação com um Mutex. Se o resultado da solicitação de
rede for bem-sucedido, os dados serão atribuídos à variável latestNews.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Tornar uma operação ativa por mais tempo do que a tela
Se o usuário sair da tela enquanto a solicitação de rede estiver em
andamento, ela será cancelada, e o resultado não será armazenado em cache. O NewsRepository
não pode usar o CoroutineScope do autor da chamada para executar essa lógica. Em vez disso,
o NewsRepository precisa usar um CoroutineScope ligado ao ciclo de vida.
A busca pelas últimas notícias precisa ser uma operação para apps.
Para seguir as práticas recomendadas de injeção de dependência, o NewsRepository precisa receber um
escopo como um parâmetro no construtor em vez de criar o próprio
CoroutineScope. Como os repositórios precisam executar a maior parte do trabalho em
linhas de execução em segundo plano, configure o CoroutineScope com
Dispatchers.Default ou com seu próprio pool de linhas de execução.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Como o NewsRepository está pronto para executar operações para apps com o
CoroutineScope externo, ele precisa executar a chamada para a fonte de dados e salvar
o resultado com uma nova corrotina iniciada por esse escopo:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
O recurso async é usado para iniciar a corrotina no escopo externo. O recurso await é chamado
na nova corrotina para suspensão até que a solicitação de rede volte e o
resultado seja salvo no cache. Nesse momento, se o usuário ainda estiver na tela,
ele verá as notícias mais recentes. Se o usuário sair da tela,
await será cancelado, mas a lógica dentro de async continuará sendo executada.
Leia mais sobre padrões para CoroutineScope.
Salvar e recuperar dados do disco
Imagine que você queira salvar dados como notícias favoritas e preferências do usuário. Esse tipo de dados precisa sobreviver ao encerramento do processo e ser acessível mesmo que o usuário não esteja conectado à rede.
Se os dados com os quais você está trabalhando precisam sobreviver ao encerramento do processo, eles precisam ser armazenados no disco de uma das seguintes maneiras:
- Para grandes conjuntos de dados que precisam ser consultados, de integridade referencial ou de atualizações parciais, salve os dados em um banco de dados da Room. No exemplo do app Google Notícias, as matérias ou os autores podem ser salvos no banco de dados.
- Para conjuntos de dados pequenos que só precisam ser recuperados e definidos (não consultados ou atualizados parcialmente), use o DataStore. No exemplo do app Google Notícias, o formato de datas preferido do usuário ou outras preferências de exibição podem ser salvas no DataStore.
- Para blocos de dados, como um objeto JSON, use um arquivo.
Como mencionado na seção Fonte de verdade, cada fonte de dados funciona com
apenas uma fonte e corresponde a um tipo de dados específico (por exemplo, News,
Authors, NewsAndAuthors ou UserPreferences). As classes que usam a fonte de
dados não devem saber como os dados são salvos, por exemplo, em um banco de dados ou em um
arquivo.
Room como fonte de dados
Como cada fonte de dados precisa ser responsável por trabalhar com apenas uma
fonte para um tipo específico de dados, uma fonte de dados Room receberá um
objeto de acesso a dados (DAO, na sigla em inglês) ou o próprio banco de dados como parâmetro. Por
exemplo, NewsLocalDataSource pode usar uma instância de NewsDao como um
parâmetro, e AuthorsLocalDataSource pode usar uma instância de AuthorsDao.
Em alguns casos, se nenhuma lógica extra for necessária, será possível injetar o DAO diretamente no repositório, porque o DAO é uma interface que pode ser facilmente substituída em testes.
Para saber mais sobre como trabalhar com as APIs da Room, consulte os guias da Room.
DataStore como fonte de dados
O DataStore é perfeito para armazenar pares de chave-valor, como configurações do usuário. Exemplos podem incluir o formato de hora, as preferências de notificação e a exibição ou ocultação de itens de notícias depois da leitura do usuário. O DataStore também pode armazenar objetos tipados com buffers de protocolo.
Como acontece com qualquer outro objeto, uma fonte de dados apoiada pelo DataStore precisa conter dados correspondentes a um determinado tipo ou a uma determinada parte do app. Isso é ainda mais verdadeiro no DataStore, porque as leituras do DataStore são expostas como um fluxo que é emitido sempre que um valor é atualizado. Por esse motivo, é preciso armazenar as preferências relacionadas no mesmo DataStore.
Por exemplo, você pode ter um NotificationsDataStore que processa apenas preferências relacionadas a notificações e um NewsPreferencesDataStore que processa somente preferências relacionadas à tela de notícias. Dessa forma, é possível definir
melhor o escopo das atualizações, porque o fluxo newsScreenPreferencesDataStore.data só é
emitido quando uma preferência relacionada a essa tela é alterada. Isso também significa que
o ciclo de vida do objeto pode ser menor, porque ele pode existir somente enquanto
a tela de notícias estiver sendo mostrada.
Para saber mais sobre como trabalhar com as APIs do DataStore, consulte os guias do DataStore.
Um arquivo como fonte de dados
Ao trabalhar com objetos grandes, como um objeto JSON ou um bitmap, você precisará
trabalhar com um objeto File e processar a troca de linhas de execução.
Para saber mais sobre como trabalhar com o armazenamento de arquivos, consulte a página Visão geral do armazenamento.
Programar tarefas usando o WorkManager
Suponha que outro novo requisito seja introduzido para o Google Notícias: o app precisa oferecer ao usuário a opção de buscar as notícias mais recentes de maneira regular e automática, desde que o dispositivo esteja carregando e conectado a uma rede ilimitada. Essa seria uma operação para negócios. Esse requisito faz com que o usuário ainda possa conferir as notícias recentes mesmo se o dispositivo não tiver conectividade quando o app for aberto.
O WorkManager facilita a programação de um trabalho assíncrono e confiável e
pode cuidar do gerenciamento de restrições. É a biblioteca recomendada para
trabalhos persistentes. Para executar a tarefa definida acima, uma classe Worker é
criada: RefreshLatestNewsWorker. Essa classe usa NewsRepository como uma
dependência para buscar as notícias mais recentes e armazená-las em cache no disco.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
A lógica de negócios para esse tipo de tarefa precisa ser encapsulada na própria classe e tratada como uma fonte de dados separada. O WorkManager só vai ser responsável por garantir que o trabalho seja executado em uma linha de execução em segundo plano quando todas as restrições forem atendidas. Ao aderir a esse padrão, é possível trocar rapidamente as implementações em diferentes ambientes, conforme necessário.
Neste exemplo, a tarefa relacionada a notícias precisa ser chamada de NewsRepository,
que precisaria de uma nova fonte de dados como dependência, NewsTasksDataSource,
implementada da seguinte maneira:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
Esses tipos de classes recebem o nome dos dados pelos quais são responsáveis, por
exemplo, NewsTasksDataSource ou PaymentsTasksDataSource. Todas as tarefas relacionadas
a um determinado tipo de dados precisam ser encapsuladas na mesma classe.
Se a tarefa precisa ser acionada na inicialização do app, é recomendável acionar a
solicitação do WorkManager usando a biblioteca App Startup que chama o
repositório de um Initializer.
Para saber mais sobre como trabalhar com as APIs do WorkManager, consulte os guias do WorkManager.
Teste
As práticas recomendadas de injeção de dependência ajudam a testar o app. Também é útil usar interfaces para classes que se comunicam com recursos externos. Quando você testa uma unidade, é possível injetar versões falsas das dependências dela para tornar o teste determinístico e confiável.
Testes de unidade
As diretrizes gerais de teste se aplicam ao testar a camada de dados. Para testes de unidade, use objetos reais quando necessário e falsifique as dependências que se conectam a fontes externas, por exemplo, a leitura de um arquivo ou da rede.
Testes de integração
Os testes de integração que acessam fontes externas tendem a ser menos determinísticos porque precisam ser executados em um dispositivo real. É recomendável executar esses testes em um ambiente controlado para aumentar a confiabilidade.
Para bancos de dados, a Room permite criar um banco de dados na memória que você pode controlar totalmente nos testes. Saiba mais na página Testar e depurar o banco de dados.
Para a rede, temos bibliotecas conhecidas, como WireMock ou MockWebServer (em inglês), que permitem simular chamadas HTTP e HTTPS e verificar se as solicitações foram feitas conforme o esperado.
Outros recursos
Amostras
- Jetcaster
- Modelo inicial de arquitetura (vários módulos)
- Arquitetura
- Modelo inicial de arquitetura (módulo único)
- Now in Android
Recomendados para você
- Observação: o texto do link aparece quando o JavaScript está desativado
- Camada de domínios
- Criar um app que prioriza o modo off-line
- Produção do estado da interface