
یک برنامه آفلاین-اول، برنامهای است که قادر است تمام یا زیرمجموعهای حیاتی از عملکردهای اصلی خود را بدون دسترسی به اینترنت انجام دهد. یعنی میتواند بخشی یا تمام منطق کسبوکار خود را بهصورت آفلاین انجام دهد.
ملاحظات مربوط به ساخت یک برنامه آفلاین از لایه داده شروع میشود، که دسترسی به دادههای برنامه و منطق کسبوکار را فراهم میکند. هر از گاهی، برنامه ممکن است نیاز داشته باشد این دادهها را از منابع خارجی دستگاه بهروزرسانی کند. در انجام این کار، ممکن است برای بهروز ماندن، به منابع شبکه نیاز داشته باشد.
دسترسی به شبکه همیشه تضمین شده نیست. دستگاهها معمولاً دورههایی از اتصال شبکهی پر از مشکل یا کند را تجربه میکنند. کاربران ممکن است موارد زیر را تجربه کنند:
- پهنای باند اینترنت محدود
- قطعیهای گذرای اتصال، مانند زمانی که در آسانسور یا تونل هستید
- دسترسی گاه به گاه به داده - برای مثال، تبلتهای فقط وای فای
صرف نظر از دلیل، اغلب ممکن است یک برنامه در این شرایط به درستی کار کند. برای اطمینان از عملکرد صحیح برنامه شما در حالت آفلاین، باید بتواند موارد زیر را انجام دهد:
- بدون اتصال به شبکه قابل اعتماد قابل استفاده باقی بماند
- به جای انتظار برای تکمیل یا عدم موفقیت اولین فراخوانی شبکه، دادههای محلی را فوراً در اختیار کاربران قرار دهید.
- دادهها را به شیوهای که از وضعیت باتری و دادهها آگاه باشد، دریافت کنید - برای مثال، فقط در شرایط بهینه، مانند هنگام شارژ یا اتصال به Wi-Fi، درخواست دریافت دادهها را بدهید
اپلیکیشنی که این معیارها را برآورده کند، اغلب اپلیکیشن آفلاین-اول نامیده میشود.
یک اپلیکیشن آفلاین طراحی کنید
هنگام طراحی یک برنامه آفلاین، از لایه داده و دو عملیات اصلی که میتوانید روی دادههای برنامه انجام دهید، شروع کنید:
- خواندن : بازیابی دادهها برای استفاده توسط سایر بخشهای برنامه مانند نمایش اطلاعات به کاربر. در Compose، معمولاً این کار را با مشاهده وضعیت انجام میدهید. وقتی رابط کاربری شما منبع داده محلی را به عنوان وضعیت مشاهده میکند، صفحه نمایش آخرین دادههای محلی را به طور خودکار منعکس میکند.
- Writes : ورودی کاربر را برای بازیابی بعدی ذخیره میکند. در Compose، معمولاً با استفاده از رویدادها و اکشنهای ارسالی از رابط کاربری به ViewModel به این هدف دست مییابید.
مخازن در لایه داده مسئول ترکیب منابع داده برای ارائه دادههای برنامه هستند. در یک برنامه آفلاین، باید حداقل یک منبع داده وجود داشته باشد که برای انجام مهمترین وظایف خود نیازی به دسترسی به شبکه نداشته باشد. یکی از این وظایف مهم، خواندن دادهها است.
مدلسازی دادهها در یک برنامه آفلاین
یک برنامهی آفلاین برای هر مخزن داده که از منابع شبکه استفاده میکند، حداقل ۲ منبع داده دارد:
- منبع داده محلی
- منبع داده شبکه
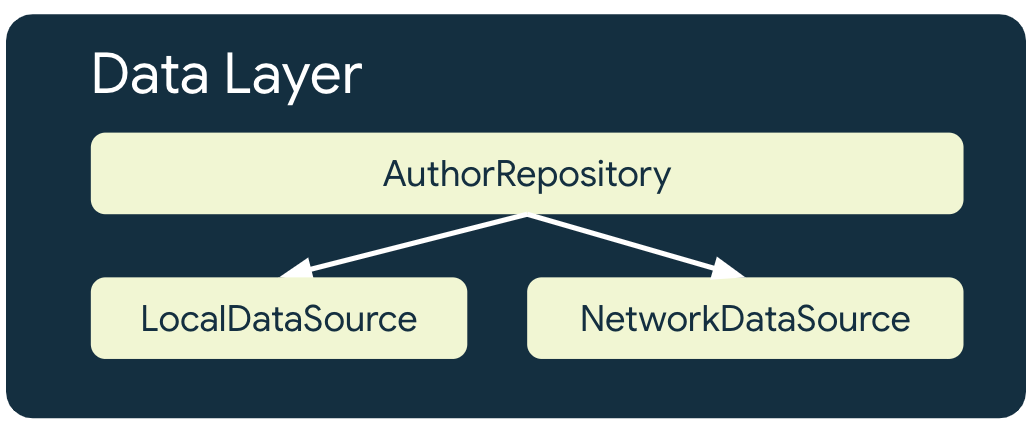
منبع داده محلی
منبع داده محلی، منبع اصلی حقیقت برای برنامه است. این منبع باید منبع انحصاری هر دادهای باشد که لایههای بالاتر برنامه آن را میخوانند. این امر، ثبات دادهها را بین حالتهای اتصال تضمین میکند. منبع داده محلی اغلب توسط فضای ذخیرهسازی که روی دیسک ذخیره میشود، پشتیبانی میشود. برخی از روشهای رایج ذخیره دادهها روی دیسک عبارتند از:
- منابع داده ساختاریافته، مانند پایگاههای داده رابطهای مانند Room
- منابع داده بدون ساختار - برای مثال، بافرهای پروتکل با DataStore
- فایلهای ساده
منبع داده شبکه
منبع داده شبکه، وضعیت واقعی برنامه است. در بهترین حالت، منبع داده محلی با منبع داده شبکه همگامسازی میشود. منبع داده محلی همچنین میتواند از منبع داده شبکه عقب بماند، که در این صورت برنامه هنگام اتصال مجدد نیاز به بهروزرسانی دارد. برعکس، منبع داده شبکه ممکن است از منبع داده محلی عقب بماند تا زمانی که برنامه بتواند هنگام اتصال مجدد، آن را بهروزرسانی کند. لایههای دامنه و رابط کاربری برنامه هرگز نباید مستقیماً با لایه شبکه ارتباط برقرار کنند. این مسئولیت repository میزبان است که با آن ارتباط برقرار کند و از آن برای بهروزرسانی منبع داده محلی استفاده کند.
افشای منابع
منابع داده محلی و شبکه میتوانند اساساً در نحوه خواندن و نوشتن برنامه شما در آنها متفاوت باشند. پرسوجو از یک منبع داده محلی میتواند سریع و انعطافپذیر باشد، مانند استفاده از پرسوجوهای SQL. در مقابل، منابع داده شبکه میتوانند کند و محدود باشند، مانند زمانی که به صورت تدریجی به منابع RESTful از طریق شناسه دسترسی پیدا میکنید. در نتیجه، هر منبع داده اغلب به نمایش خاص خود از دادههایی که ارائه میدهد نیاز دارد. بنابراین، منبع داده محلی و منبع داده شبکه ممکن است مدلهای خاص خود را داشته باشند.
ساختار دایرکتوری زیر به تجسم این مفهوم کمک میکند. AuthorEntity نشان دهنده نویسندهای است که از پایگاه داده محلی برنامه خوانده شده است و NetworkAuthor نشان دهنده نویسندهای است که از طریق شبکه سریالی شده است:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
جزئیات AuthorEntity و NetworkAuthor به شرح زیر است:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
بهتر است که هم AuthorEntity و هم NetworkAuthor را در لایه داده داخلی نگه دارید و نوع سومی را برای استفاده لایههای خارجی در نظر بگیرید. این کار از لایههای خارجی در برابر تغییرات جزئی در منابع داده محلی و شبکه که اساساً رفتار برنامه را تغییر نمیدهند، محافظت میکند. این موضوع در قطعه کد زیر نشان داده شده است:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
سپس مدل شبکه میتواند یک متد الحاقی برای تبدیل آن به مدل محلی تعریف کند، و مدل محلی نیز به طور مشابه متدی برای تبدیل آن به نمایش خارجی دارد، همانطور که در قطعه کد زیر نشان داده شده است:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
خوانده شده
خواندن عملیات اساسی روی دادههای برنامه در یک برنامه آفلاین است. بنابراین باید مطمئن شوید که برنامه شما میتواند دادهها را بخواند و به محض اینکه دادههای جدید در دسترس قرار گیرند، برنامه میتواند آنها را نمایش دهد. برنامهای که بتواند این کار را انجام دهد، یک برنامه واکنشی است زیرا APIهای خواندن را با انواع قابل مشاهده در معرض نمایش قرار میدهد.
در قطعه کد زیر، OfflineFirstTopicRepository برای تمام APIهای خوانده شده خود، Flow s را برمیگرداند. این به آن اجازه میدهد تا خوانندگان خود را هنگام دریافت بهروزرسانیها از منبع داده شبکه بهروزرسانی کند. به عبارت دیگر، به OfflineFirstTopicRepository اجازه میدهد تا تغییرات را هنگام نامعتبر شدن منبع داده محلی خود اعمال کند. بنابراین، هر خواننده OfflineFirstTopicRepository باید برای مدیریت تغییرات دادهای که میتوانند هنگام بازیابی اتصال شبکه به برنامه ایجاد شوند، آماده باشد. علاوه بر این، OfflineFirstTopicRepository دادهها را مستقیماً از منبع داده محلی میخواند. این برنامه فقط میتواند خوانندگان خود را از تغییرات داده با بهروزرسانی اولیه منبع داده محلی خود مطلع کند.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
در یک برنامه Jetpack Compose، از یک ViewModel برای ایجاد پل بین لایه داده و رابط کاربری استفاده کنید. در ViewModel، Flow با استفاده از عملگر stateIn به StateFlow تبدیل کنید. سپس Composableها این حالتها را با استفاده از collectAsStateWithLifecycle() جمعآوری کرده و به طور خودکار اشتراکها را به شیوهای آگاه از چرخه عمر مدیریت میکنند.
برای اطلاعات بیشتر در مورد collectAsStateWithLifecycle() ، به State و Jetpack Compose مراجعه کنید.
استراتژیهای مدیریت خطا
بسته به منابع دادهای که ممکن است در آنها خطاها رخ دهند، روشهای منحصر به فردی برای مدیریت خطاها در برنامههای آفلاین وجود دارد. بخشهای زیر این استراتژیها را شرح میدهند.
منبع داده محلی
سعی کنید هنگام خواندن از منبع داده محلی، خطاها را به حداقل برسانید. برای محافظت از خوانندگان در برابر خطاها، از عملگر catch روی Flow هایی که خواننده از آنها دادهها را جمعآوری میکند، استفاده کنید.
میتوانید از عملگر catch در ViewModel به صورت زیر استفاده کنید:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
برای یک رویکرد مقاومتر، یک راهحل LCE (خطای بارگذاری محتوا) را در نظر بگیرید. در LCE، وقتی هنگام خواندن با شکست مواجه میشوید، یک حالت خطا نمایش داده میشود. معمولاً، با مدلسازی حالتهای رابط کاربری به عنوان کلاسهای مهر و موم شده کاتلین ، به LCE دست مییابید.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
منبع داده شبکه
اگر هنگام خواندن دادهها از منبع داده شبکه خطایی رخ دهد، برنامه باید از یک روش اکتشافی برای تلاش مجدد برای واکشی دادهها استفاده کند. روشهای اکتشافی رایج شامل موارد زیر است:
عقبنشینی نمایی
در backoff نمایی ، برنامه با فواصل زمانی افزایشی به تلاش برای خواندن از منبع داده شبکه ادامه میدهد تا زمانی که موفق شود، یا شرایط دیگری ایجاب کند که متوقف شود.
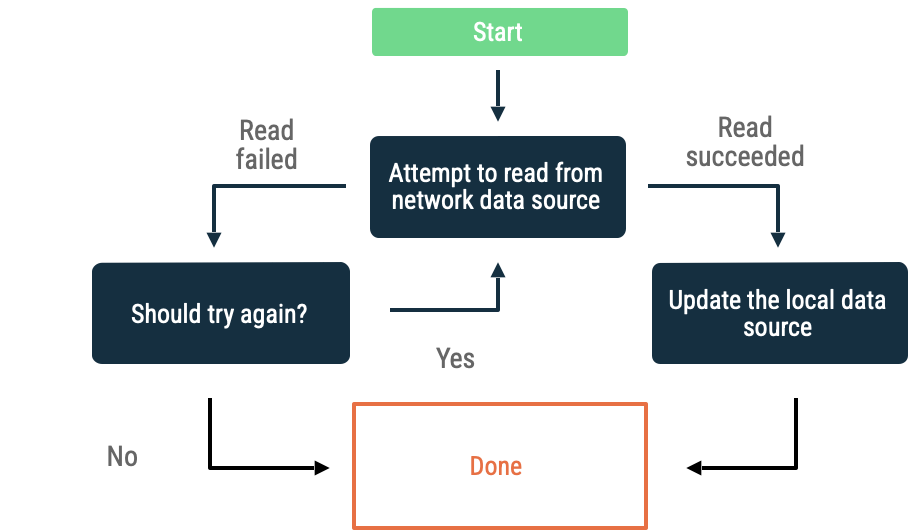
معیارهای ارزیابی اینکه آیا برنامه مرتباً از کار میافتد یا خیر، شامل موارد زیر است:
- نوع خطایی که منبع داده شبکه نشان داده است. برای مثال، فراخوانیهای شبکهای که خطایی را نشان میدهند که نشاندهنده عدم اتصال است را دوباره امتحان کنید. درخواستهای HTTP که مجاز نیستند را تا زمانی که اعتبارنامههای مناسب در دسترس نباشند، دوباره امتحان نکنید.
- حداکثر تعداد مجاز تلاش مجدد
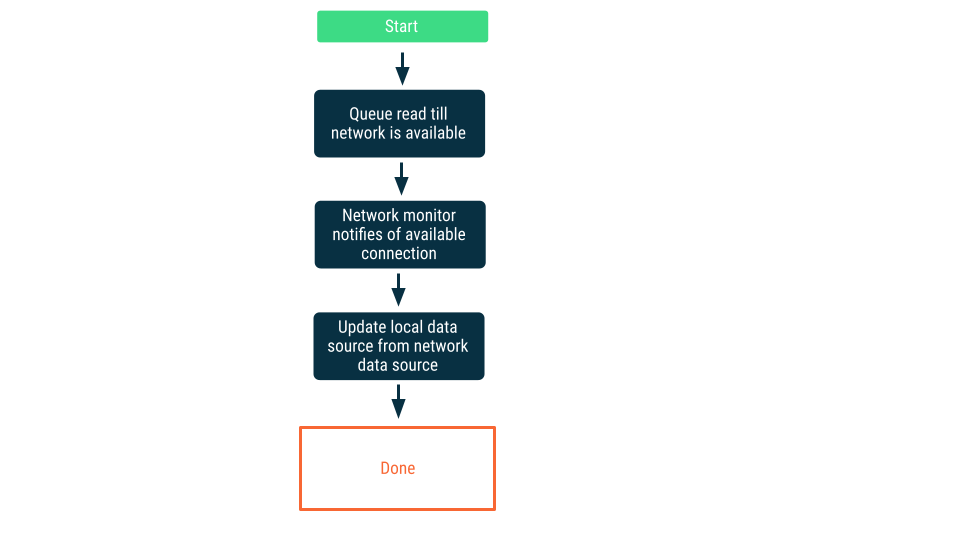
نظارت بر اتصال شبکه
در این رویکرد، درخواستهای خواندن تا زمانی که برنامه مطمئن شود میتواند به منبع داده شبکه متصل شود، در صف قرار میگیرند. پس از برقراری اتصال، درخواست خواندن از صف خارج میشود، دادهها خوانده میشوند و منبع داده محلی بهروزرسانی میشود. در اندروید، این صف ممکن است با یک پایگاه داده Room نگهداری شود و با استفاده از WorkManager به عنوان کار مداوم تخلیه شود.
مینویسد
در حالی که روش توصیه شده برای خواندن دادهها در یک برنامه آفلاین-اول، استفاده از انواع قابل مشاهده است، معادل آن برای APIهای نوشتن، APIهای ناهمزمان مانند توابع تعلیق هستند. این امر از مسدود شدن نخ رابط کاربری جلوگیری میکند و به مدیریت خطا کمک میکند زیرا نوشتن در برنامههای آفلاین-اول میتواند هنگام عبور از مرز شبکه با شکست مواجه شود.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
در قطعه کد قبلی، API ناهمزمان مورد نظر، Coroutines است زیرا متد به حالت تعلیق در میآید.
نوشتن استراتژیها
هنگام نوشتن دادهها در برنامههای آفلاین، سه استراتژی وجود دارد که باید در نظر بگیرید. انتخاب شما به نوع دادهای که نوشته میشود و الزامات برنامه بستگی دارد:
فقط آنلاین مینویسد
تلاش برای نوشتن دادهها در سراسر مرز شبکه. در صورت موفقیت، منبع داده محلی را بهروزرسانی کنید؛ در غیر این صورت، یک استثنا ایجاد کنید و اجازه دهید فراخواننده پاسخ مناسب را بدهد.
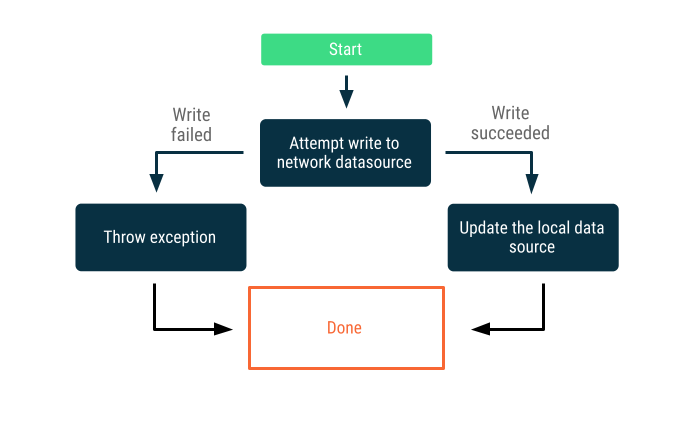
این استراتژی اغلب برای تراکنشهای نوشتن که باید به صورت آنلاین و تقریباً بلادرنگ اتفاق بیفتند - مثلاً انتقال بانکی - استفاده میشود. از آنجایی که نوشتنها ممکن است با شکست مواجه شوند، اغلب لازم است به کاربر اطلاع داده شود که نوشتن ناموفق بوده است، یا از همان ابتدا از تلاش کاربر برای نوشتن دادهها جلوگیری شود. در اینجا چند استراتژی وجود دارد که میتوانید در این سناریوها به کار ببرید:
- اگر یک برنامه برای نوشتن داده به دسترسی به اینترنت نیاز دارد، میتوانید رابط کاربری که به کاربر اجازه نوشتن داده میدهد را نمایش ندهید، یا حداقل میتوانید آن را غیرفعال کنید.
- شما میتوانید از یک
AlertDialogکه کاربر نمیتواند آن را رد کند، یا یکSnackbar، برای اطلاع دادن به کاربر که آفلاین است، استفاده کنید.
نوشتههای صفبندیشده
وقتی میخواهید یک شیء بنویسید، آن را در یک صف قرار دهید. وقتی برنامه دوباره آنلاین شد، صف را با استفاده از backoff نمایی تخلیه کنید. در اندروید، تخلیه یک صف آفلاین یک کار مداوم است که اغلب به WorkManager محول میشود.
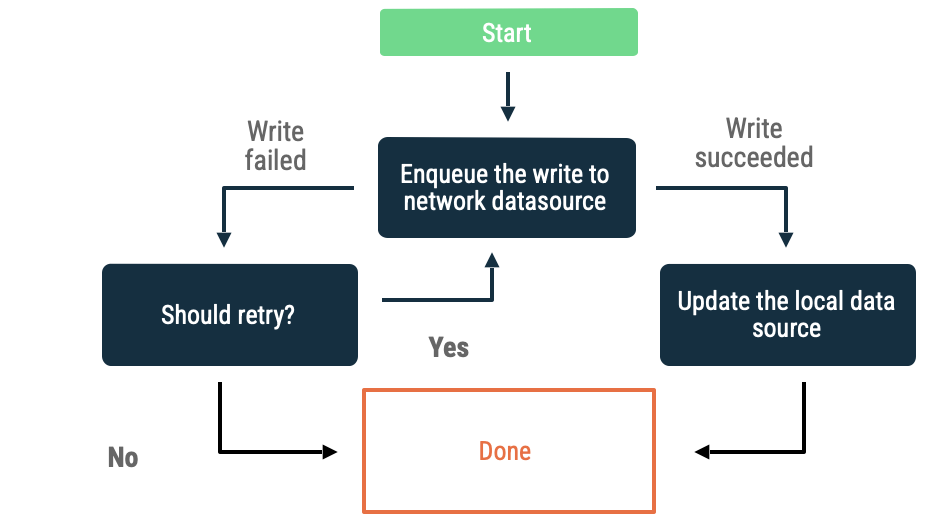
این رویکرد در سناریوهای زیر انتخاب خوبی است:
- ضروری نیست که دادهها حتماً در شبکه نوشته شوند.
- این تراکنش به زمان حساس نیست.
- ضروری نیست که در صورت عدم موفقیت عملیات، به کاربر اطلاع داده شود.
موارد استفاده برای این رویکرد شامل رویدادهای تحلیلی و ثبت وقایع است.
تنبل مینویسد
ابتدا در منبع داده محلی بنویسید، سپس نوشتن را در صف قرار دهید تا در اولین فرصت به شبکه اطلاع دهید. این موضوع بدیهی نیست زیرا وقتی برنامه دوباره آنلاین میشود، ممکن است بین شبکه و منابع داده محلی تداخل ایجاد شود. بخش بعدی در مورد حل تداخل، جزئیات بیشتری را ارائه میدهد.
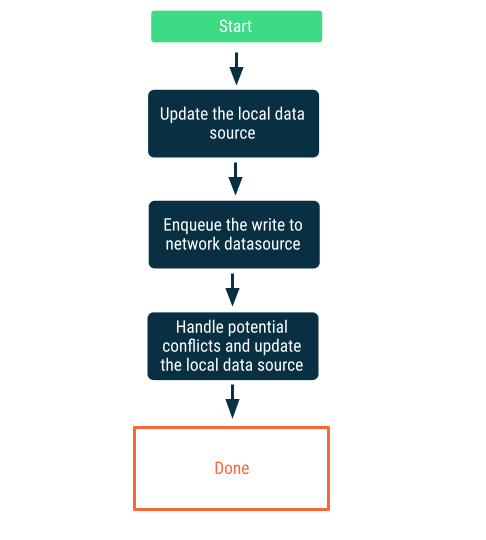
این رویکرد زمانی انتخاب صحیحی است که دادهها برای برنامه حیاتی باشند. به عنوان مثال، در یک برنامه لیست کارهای آفلاین، ضروری است که هر کاری که کاربر به صورت آفلاین اضافه میکند، به صورت محلی ذخیره شود تا از خطر از دست دادن دادهها جلوگیری شود.
هماهنگسازی و حل تعارض
وقتی یک برنامهی آفلاین اتصال خود را بازیابی میکند، باید دادههای منبع دادهی محلی خود را با دادههای منبع دادهی شبکه تطبیق دهد. این فرآیند همگامسازی نامیده میشود. دو روش اصلی وجود دارد که یک برنامه میتواند با منبع دادهی شبکهی خود همگامسازی کند:
- همگامسازی مبتنی بر کشش
- همگامسازی مبتنی بر فشار
همگامسازی مبتنی بر کشش
در همگامسازی مبتنی بر کشش، برنامه برای خواندن آخرین دادههای برنامه در صورت تقاضا به شبکه متصل میشود. یک روش اکتشافی رایج برای این رویکرد، مبتنی بر ناوبری است که در آن برنامه فقط دادهها را درست قبل از ارائه به کاربر دریافت میکند.
این رویکرد زمانی بهترین عملکرد را دارد که برنامه انتظار دورههای کوتاه تا متوسط عدم اتصال به شبکه را داشته باشد. دلیل این امر آن است که بهروزرسانی دادهها فرصتطلبانه است و دورههای طولانی عدم اتصال، احتمال تلاش کاربر برای بازدید از مقاصد برنامه با حافظه پنهان قدیمی یا خالی را افزایش میدهد.
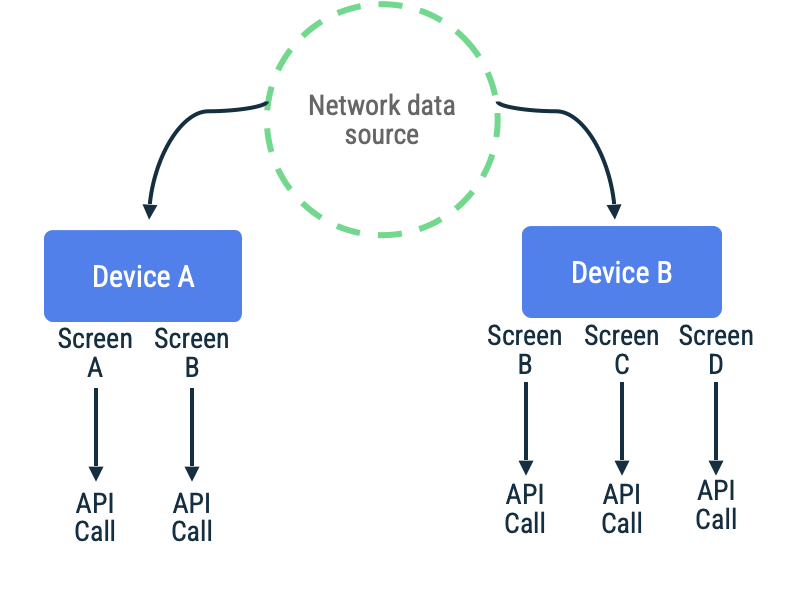
برنامهای را در نظر بگیرید که در آن از توکنهای صفحه برای دریافت آیتمها در یک لیست پیمایش بیپایان برای یک صفحه خاص استفاده میشود. پیادهسازی ممکن است به صورت تنبل به شبکه دسترسی پیدا کند، دادهها را در منبع داده محلی ذخیره کند و سپس از منبع داده محلی بخواند تا اطلاعات را به کاربر ارائه دهد. در صورتی که اتصال شبکه وجود نداشته باشد، مخزن ممکن است دادهها را فقط از منبع داده محلی درخواست کند. این الگویی است که توسط کتابخانه صفحهبندی Jetpack با RemoteMediator API آن استفاده میشود.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
مزایا و معایب همگامسازی مبتنی بر کشش در جدول زیر خلاصه شده است:
| مزایا | معایب |
|---|---|
| اجرای نسبتاً آسان. | مستعد استفاده زیاد از دادهها. دلیل این امر این است که بازدیدهای مکرر از یک مقصد ناوبری، باعث بازیابی غیرضروری اطلاعات بدون تغییر میشود. میتوانید این مشکل را از طریق ذخیرهسازی مناسب کاهش دهید. این کار را میتوان در لایه رابط کاربری با استفاده از عملگر cachedIn یا در لایه شبکه با استفاده از حافظه پنهان HTTP انجام داد. |
| دادههایی که مورد نیاز نیستند، هرگز واکشی نمیشوند. | با دادههای رابطهای به خوبی مقیاسپذیر نیست زیرا مدل استخراجشده باید خودکفا باشد. اگر مدلی که همگامسازی میشود برای پر کردن خود به مدلهای دیگری که باید واکشی شوند وابسته باشد، مشکل استفاده زیاد از دادهها که قبلاً ذکر شد، حتی مهمتر میشود. علاوه بر این، میتواند باعث وابستگی بین مخازن مدل والد و مخازن مدل تودرتو شود. |
همگامسازی مبتنی بر فشار
در همگامسازی مبتنی بر فشار، منبع داده محلی سعی میکند تا حد امکان از یک مجموعه کپی از منبع داده شبکه تقلید کند. این منبع داده به طور فعال مقدار مناسبی از دادهها را در اولین راهاندازی برای تنظیم یک خط پایه دریافت میکند. پس از آن، به اعلانهای سرور متکی است تا در صورت قدیمی بودن آن دادهها به آن هشدار دهد.
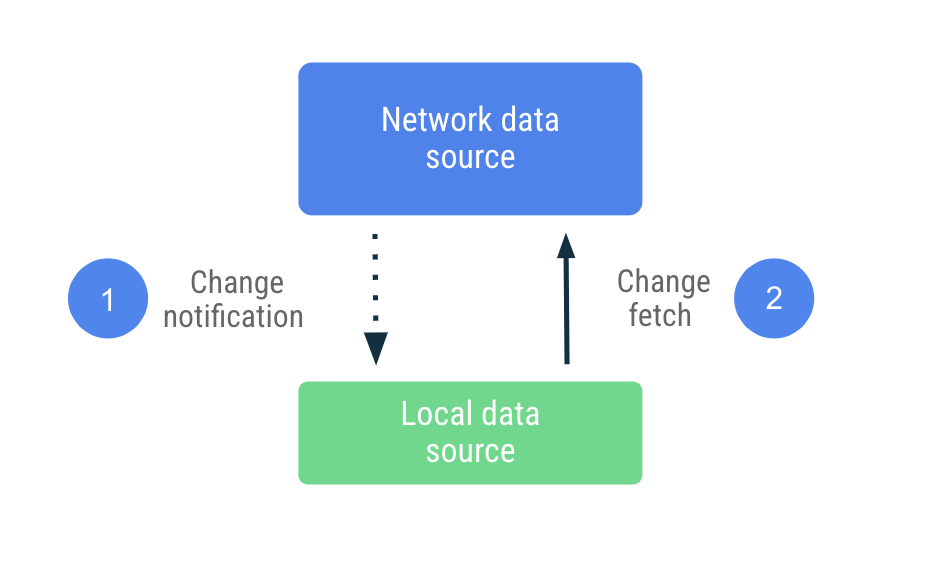
پس از دریافت اعلان قدیمی شدن، برنامه با شبکه تماس میگیرد تا فقط دادههایی را که به عنوان قدیمی علامتگذاری شدهاند، بهروزرسانی کند. این کار به Repository محول میشود که با منبع داده شبکه تماس میگیرد و دادههای واکشی شده را در منبع داده محلی ذخیره میکند. از آنجایی که مخزن دادههای خود را با انواع قابل مشاهده (observable types) در معرض نمایش قرار میدهد، خوانندگان از هرگونه تغییر مطلع میشوند.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
در این رویکرد، برنامه وابستگی بسیار کمتری به منبع داده شبکه دارد و میتواند برای مدت طولانی بدون آن کار کند. این برنامه در حالت آفلاین، دسترسی خواندن و نوشتن را ارائه میدهد زیرا فرض میکند که آخرین اطلاعات را از منبع داده شبکه به صورت محلی دارد.
مزایا و معایب همگامسازی مبتنی بر فشار در جدول زیر خلاصه شده است:
| مزایا | معایب |
|---|---|
| این برنامه میتواند به طور نامحدود آفلاین باقی بماند. | نسخهبندی دادهها برای حل تعارض، کار سادهای است. |
| حداقل مصرف داده. برنامه فقط دادههایی را که تغییر کردهاند، دریافت میکند. | هنگام همگامسازی باید نگرانیهای مربوط به نوشتن را در نظر بگیرید. |
| برای دادههای رابطهای خوب کار میکند. هر مخزن مسئول دریافت دادهها فقط برای مدلی است که از آن پشتیبانی میکند. | منبع داده شبکه باید از همگامسازی پشتیبانی کند. |
هماهنگسازی ترکیبی
برخی از برنامهها از یک رویکرد ترکیبی استفاده میکنند که بسته به دادهها مبتنی بر کشش یا فشار است. به عنوان مثال، یک برنامه رسانه اجتماعی ممکن است به دلیل فرکانس بالای بهروزرسانیهای فید، از همگامسازی مبتنی بر کشش برای دریافت فید زیر کاربر در صورت تقاضا استفاده کند. همین برنامه ممکن است از همگامسازی مبتنی بر فشار برای دادههای مربوط به کاربر وارد شده، از جمله نام کاربری، تصویر پروفایل و غیره، استفاده کند.
در نهایت، انتخاب همگامسازی آفلاین به الزامات محصول و زیرساخت فنی موجود بستگی دارد.
حل اختلاف
اگر در حالت آفلاین، برنامه دادههایی را به صورت محلی مینویسد که با منبع داده شبکه همسو نیستند، قبل از اینکه همگامسازی انجام شود، باید این تداخل را برطرف کنید.
حل تعارض اغلب نیاز به نسخهبندی دارد. برنامه برای پیگیری زمان وقوع تغییرات، نیاز به انجام برخی حسابداریها دارد تا بتواند فرادادهها را به منبع داده شبکه منتقل کند. سپس منبع داده شبکه مسئولیت ارائه منبع مطلق حقیقت را بر عهده دارد. بسته به نیازهای برنامه، استراتژیهای زیادی برای حل تعارض وجود دارد. برای برنامههای تلفن همراه، یک رویکرد رایج «آخرین نوشتن برنده میشود» است.
آخرین نوشته برنده میشود
در این رویکرد، دستگاهها به دادههایی که در شبکه مینویسند، ابردادههای برچسب زمانی (timestamp metadata) اضافه میکنند. وقتی منبع داده شبکه آنها را دریافت میکند، هر داده قدیمیتر از وضعیت فعلی خود را کنار میگذارد و دادههای جدیدتر از وضعیت فعلی خود را میپذیرد.
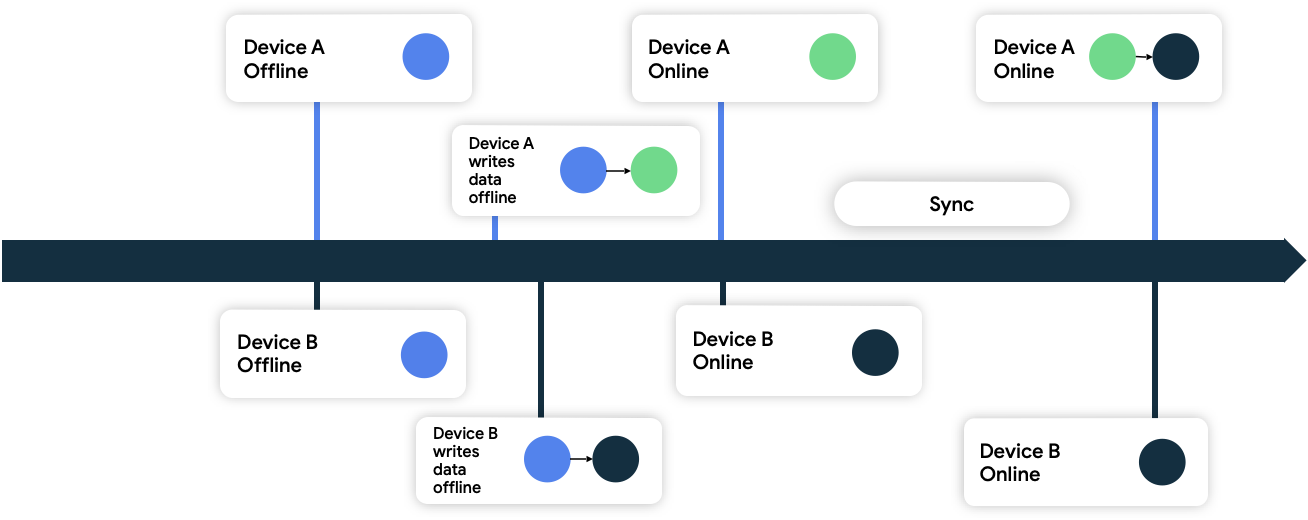
در شکل ۹، هر دو دستگاه آفلاین هستند و در ابتدا با منبع داده شبکه همگامسازی شدهاند. در حالت آفلاین، هر دو دادهها را به صورت محلی مینویسند و زمان نوشتن دادههای خود را پیگیری میکنند. وقتی هر دو دوباره آنلاین میشوند و با منبع داده شبکه همگامسازی میشوند، شبکه با حفظ دادهها از دستگاه B، زیرا دادههای خود را بعداً نوشته است، این تداخل را حل میکند.
WorkManager در برنامههای آفلاین
در هر دو استراتژی خواندن و نوشتن که قبلاً به آنها پرداخته شد، دو ابزار رایج وجود دارد:
- صفها
- خواندن: برای به تعویق انداختن خواندن تا زمان اتصال به شبکه استفاده میشود.
- نوشتنها: برای به تعویق انداختن نوشتنها تا زمان برقراری اتصال شبکه و برای در صف قرار دادن دوباره نوشتنها برای تلاشهای مجدد استفاده میشود.
- مانیتورهای اتصال شبکه
- خواندنها: به عنوان سیگنالی برای تخلیه صف خواندن هنگام اتصال برنامه و برای همگامسازی استفاده میشود.
- نوشتن: به عنوان سیگنالی برای تخلیه صف نوشتن هنگام اتصال برنامه و برای همگامسازی استفاده میشود.
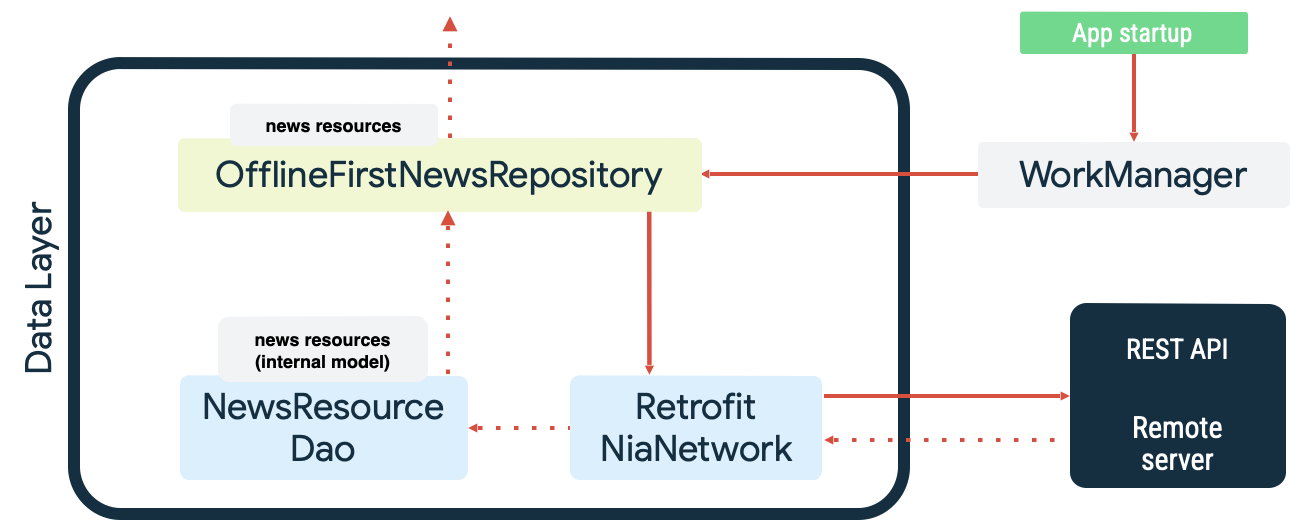
هر دو مورد، نمونههایی از کار مداومی هستند که WorkManager در آن برتری دارد. برای مثال، در برنامه نمونه Now in Android ، WorkManager هنگام همگامسازی منبع داده محلی، هم به عنوان صف خواندن و هم به عنوان مانیتور شبکه استفاده میشود. در هنگام راهاندازی، برنامه موارد زیر را انجام میدهد:
- همگامسازی خواندن در صفها (Enqueues) برای اطمینان از وجود برابری (parity) بین منبع داده محلی و منبع داده شبکه انجام میشود.
- صف همگامسازی خواندن را خالی میکند و وقتی برنامه آنلاین است، همگامسازی را شروع میکند.
- با استفاده از backoff نمایی، خواندن از منبع داده شبکه را انجام میدهد.
- نتایج خواندن را در منبع داده محلی ذخیره میکند و هرگونه تداخلی را که رخ میدهد، برطرف میکند.
- دادهها را از منبع داده محلی برای استفاده سایر لایههای برنامه در معرض نمایش قرار میدهد.
این اقدامات در نمودار زیر نشان داده شده است:
نوبتدهی کار همگامسازی با WorkManager با مشخص کردن آن به عنوان یک کار منحصر به فرد با KEEP ExistingWorkPolicy دنبال میشود:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() به صورت زیر تعریف شده است:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
به طور خاص، Constraints تعریف شده توسط SyncConstraints مستلزم آن است که NetworkType NetworkType.CONNECTED باشد. یعنی، قبل از اجرا منتظر میماند تا شبکه در دسترس قرار گیرد.
زمانی که شبکه در دسترس قرار گرفت، Worker صف کار منحصر به فرد مشخص شده توسط SyncWorkName را با واگذاری به نمونههای Repository مناسب، تخلیه میکند. اگر همگامسازی با شکست مواجه شود، متد doWork() با Result.retry() برمیگرداند. WorkManager به طور خودکار همگامسازی را با backoff نمایی دوباره امتحان میکند. در غیر این صورت، Result.success() را برمیگرداند و همگامسازی را تکمیل میکند.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
نمونهها
نمونههای گوگل زیر، برنامههای آفلاین را نشان میدهند. برای مشاهدهی این راهنمایی در عمل، آنها را بررسی کنید:
برای شما توصیه میشود
- توجه: متن لینک زمانی نمایش داده میشود که جاوا اسکریپت غیرفعال باشد.
- تولید حالت UI
- لایه رابط کاربری
- لایه داده