
La arquitectura de la app es la base de una aplicación para Android de alta calidad. Una arquitectura bien definida te permite crear una app escalable y fácil de mantener que se pueda adaptar al ecosistema en constante expansión de dispositivos Android, incluidos teléfonos, tablets, dispositivos plegables, dispositivos ChromeOS, pantallas de automóviles y XR.
Composición de la app
Una app de Android típica consta de varios componentes de la app, como servicios, proveedores de contenido y receptores de emisión. Estos componentes se declaran en el manifiesto de la app.
La interfaz de usuario de una app también es un componente. Históricamente, las IUs se compilaban
con varias actividades. Sin embargo, las apps modernas usan una arquitectura de una sola actividad. Una sola Activity sirve como contenedor para pantallas o destinos de Jetpack Compose.
Múltiples factores de forma
Las apps se pueden ejecutar en varios factores de forma, incluidos teléfonos, pero también tablets, dispositivos plegables, dispositivos ChromeOS y mucho más. No supongas que tu app siempre permanece fija en orientación vertical u horizontal. Los cambios de configuración, como la rotación del dispositivo o el plegado y desplegado de un dispositivo plegable, obligan a tu app a recomponer su IU, lo que afecta el estado de la app.
Restricciones de recursos
Los dispositivos móviles, incluso los dispositivos con pantalla grande, tienen restricciones de recursos, por lo que, en cualquier momento, el sistema operativo podría detener el proceso de tu app para otorgar sus recursos a otros procesos.
Condiciones de lanzamiento variables
En un entorno con restricciones de recursos, los componentes de tu app se pueden iniciar de manera individual y desordenada. Además, el usuario o el sistema operativo podrían finalizarlos en cualquier momento. Como resultado, no almacenes datos ni estados de la aplicación en los componentes de tu app. Haz que los componentes de tu app sean autónomos e independientes entre sí.
Principios comunes de arquitectura
Si no puedes usar los componentes de la app para almacenar datos y estados de la aplicación, ¿cómo deberías diseñar tu app?
A medida que crece el tamaño de las apps para Android, es importante definir una arquitectura que permita que esta crezca. Una arquitectura de app bien diseñada define los límites entre las partes de la app y las responsabilidades que tiene cada parte.
Separación de problemas
Diseña la arquitectura de tu app para que cumpla con algunos principios específicos.
El principio más importante es la separación de problemas: separar tu app en métodos, clases, archivos, paquetes, módulos y capas que tengan responsabilidades y límites claramente definidos.
Un error común es escribir todo tu código en un Activity.
La función principal de una Activity es alojar la IU de tu app. El SO Android controla su ciclo de vida, y las destruye y las vuelve a crear con frecuencia en respuesta a acciones del usuario, como la rotación de la pantalla, o eventos del sistema, como memoria insuficiente.
Esta naturaleza efímera las hace inadecuadas para contener datos o estados de la aplicación. Si almacenas datos en una Activity, esos datos se pierden cuando se vuelve a crear el componente. Para garantizar la persistencia de los datos y proporcionar una experiencia del usuario estable, no confíes el estado a estos componentes de la IU.
Diseños adaptables
Compila apps que controlen correctamente los cambios de configuración, como los cambios de orientación del dispositivo o los cambios en el tamaño de la ventana de la app. Implementa los diseños canónicos adaptables para proporcionar una experiencia del usuario óptima en una variedad de factores de forma.
Controla la IU a partir de modelos de datos
Otro principio importante es controlar la IU a partir de modelos de datos, preferentemente que sean de persistencia. Los modelos de datos representan los datos de una app. Son independientes de los elementos de la IU y otros componentes de la app. Por lo tanto, no están vinculados a la IU ni al ciclo de vida de esos componentes, pero se destruirán cuando el SO quite el proceso de la app de la memoria.
Los modelos de persistencia son ideales por los siguientes motivos:
Los usuarios no perderán datos si el SO Android destruye tu app para liberar recursos.
Tu app continuará funcionando cuando la conexión de red sea intermitente o no esté disponible.
Basa la arquitectura de tu app en clases de modelos de datos para que tu app sea sólida y se pueda probar.
Fuente de confianza única
Cuando se define un nuevo tipo de datos en tu app, debes asignarle una fuente de confianza única (SSOT, por sus siglas en inglés). La SSOT es la propietaria de esos datos, y solo SSOT puede modificarlos o mutarlos. Con ese fin, la SSOT expone los datos con un tipo inmutable y, para modificarlos, expone funciones o recibe eventos a los que otros tipos pueden llamar.
Este patrón tiene varios beneficios:
- Centraliza todos los cambios en un tipo particular de datos en un solo lugar.
- Protege los datos para que otros tipos no puedan manipularlos.
- Hace que los cambios en los datos sean más rastreables, por lo que los errores son más fáciles de detectar.
En una aplicación que prioriza la condición sin conexión, la fuente de información de los datos de aplicación suele ser una base de datos. En algunos otros casos, la fuente de información puede ser un
ViewModel.
Flujo de datos unidireccional
El principio de fuente de confianza única se suele usar con el patrón de flujo de datos unidireccional (UDF). En este flujo, el estado fluye en una sola dirección, por lo general, del componente superior al componente secundario. Los eventos que modifican los datos fluyen en la dirección opuesta.
En Android, el estado o los datos suelen fluir desde los tipos de jerarquía más altos a los de menor alcance. Por lo general, los eventos se activan desde los tipos de alcance inferior hasta que alcanzan la SSOT para el tipo de datos correspondiente. Por ejemplo, los datos de la aplicación generalmente fluyen desde las fuentes de datos hacia la IU. Los eventos del usuario, como presionar el botón, fluyen desde la IU hasta el SSOT, en donde los datos de la aplicación se modifican y se exponen en un tipo inmutable.
Este patrón mantiene mejor la coherencia de los datos, es menos propenso a errores, es más fácil de depurar y brinda todos los beneficios del patrón de SSOT.
Para obtener más información sobre UDF, consulta Flujo de datos unidireccional en Jetpack Compose.
Arquitectura de app recomendada
Teniendo en cuenta los principios de arquitectura comunes, diseña cada aplicación con al menos dos capas:
- Capa de la IU: Muestra los datos de la aplicación en la pantalla.
- Capa de datos: Contiene la lógica empresarial de tu aplicación y expone sus datos.
Puedes agregar una capa adicional llamada capa de dominio para simplificar y volver a utilizar las interacciones entre la IU y las capas de datos.
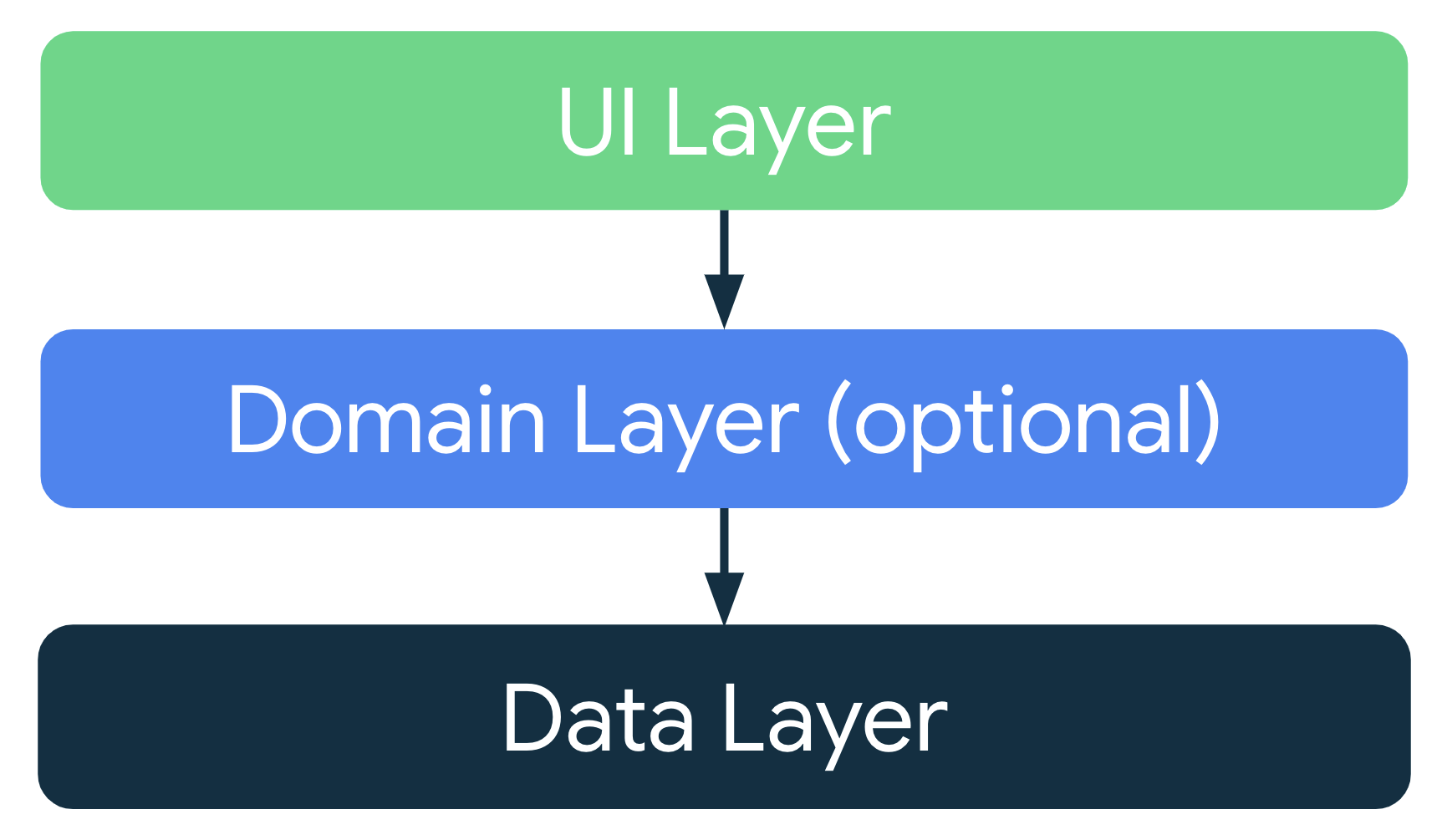
Arquitectura moderna de apps
Una arquitectura moderna de apps para Android usa las siguientes técnicas (entre otras):
- Arquitectura en capas y adaptable
- Flujo unidireccional de datos (UDF) en todas las capas de la app
- Capa de IU con contenedores de estado para administrar la complejidad de la IU
- Corrutinas y flujos
- Prácticas recomendadas para la inserción de dependencias
Para obtener más información, consulta Recomendaciones para la arquitectura de Android.
Capa de la IU
La función de la capa de la IU (o capa de presentación) consiste en mostrar los datos de la aplicación en la pantalla. Cuando los datos cambian, ya sea debido a la interacción del usuario (como cuando presiona un botón) o una entrada externa (como una respuesta de red), la IU se actualiza para reflejar los cambios.
La capa de la IU consta de dos tipos de construcciones:
- Elementos de la IU que renderizan los datos en la pantalla (puedes compilar estos elementos con las funciones de Jetpack Compose para admitir diseños adaptables)
- Contenedores de estados (como
ViewModel) que retienen datos, los exponen a la IU y controlan la lógica (los contenedores de estado deben durar lo mismo que el elemento de la IU para el que proporcionan el estado) (por ejemplo, un ViewModel para una pantalla debe conservarse en la memoria hasta que se quite la pantalla de la pila de actividades de navegación de la app) (para obtener más información, consulta Ciclos de vida de los estados)
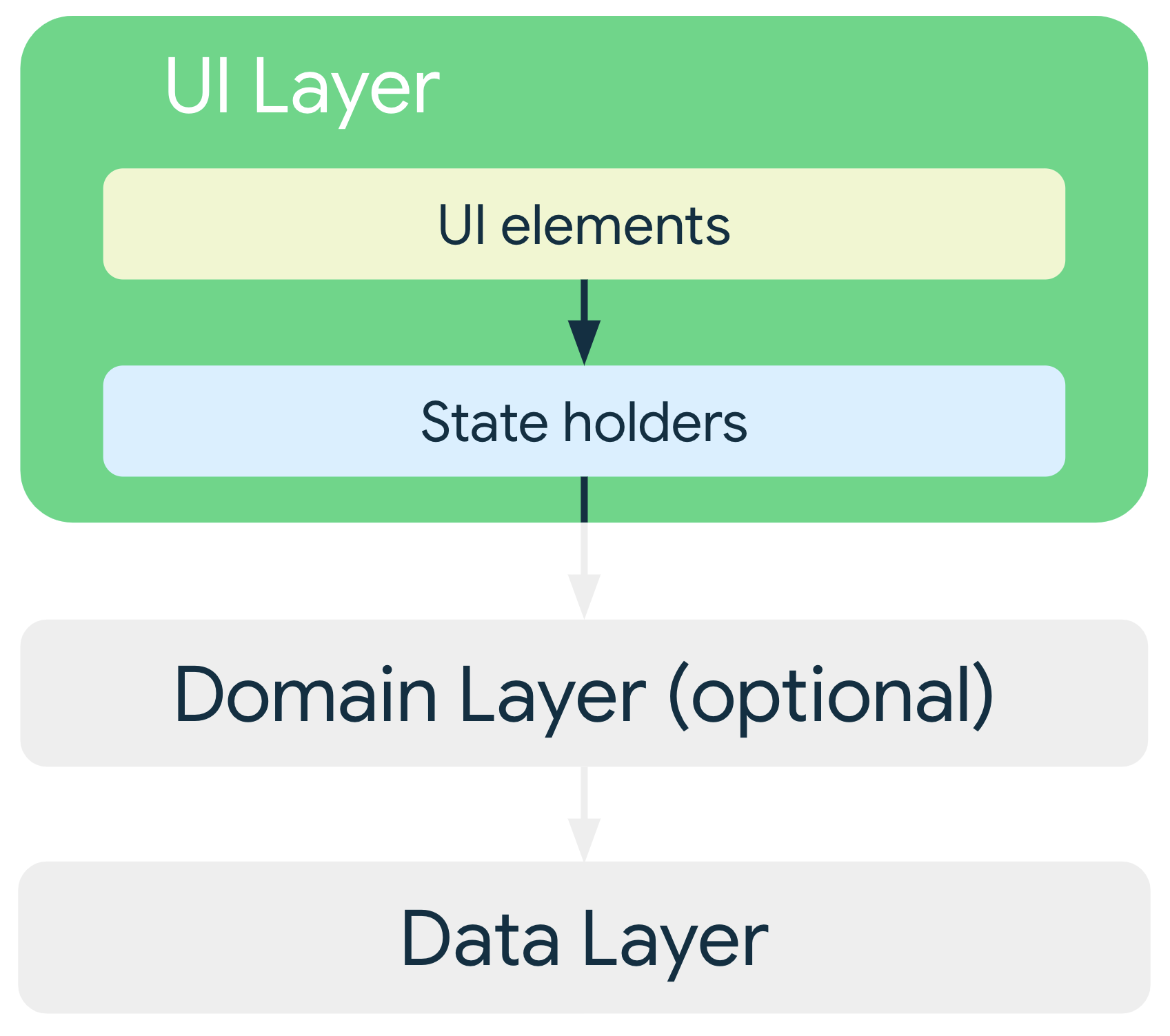
En el caso de las IUs adaptables, los contenedores de estado, como los objetos ViewModel, exponen el estado de la IU que
se adapta a diferentes clases de tamaño de ventana. Puedes usar currentWindowAdaptiveInfo() para derivar este estado de la IU. Luego, los componentes como NavigationSuiteScaffold pueden usar esta información para cambiar automáticamente entre diferentes patrones de navegación (por ejemplo, NavigationBar, NavigationRail o NavigationDrawer) según el espacio de pantalla disponible.
Para obtener más información, consulta Capa de la IU y Arquitectura de la IU de Compose.
Para obtener más información sobre las apps adaptables y la navegación, consulta Cómo compilar apps adaptables y Cómo compilar navegación adaptable.
Capa de datos
La capa de datos de una app contiene la lógica empresarial. Esta lógica es lo que le da valor a tu app. Además, está compuesta por reglas que determinan cómo tu app crea, almacena y cambia datos.
La capa de datos está formada por repositorios que pueden contener de cero a muchas fuentes de datos. Crea una clase de repositorio para cada tipo de datos diferente que administres en tu app. Por ejemplo, puedes crear una clase MoviesRepository para datos relacionados con películas o una clase PaymentsRepository para datos relacionados con pagos.
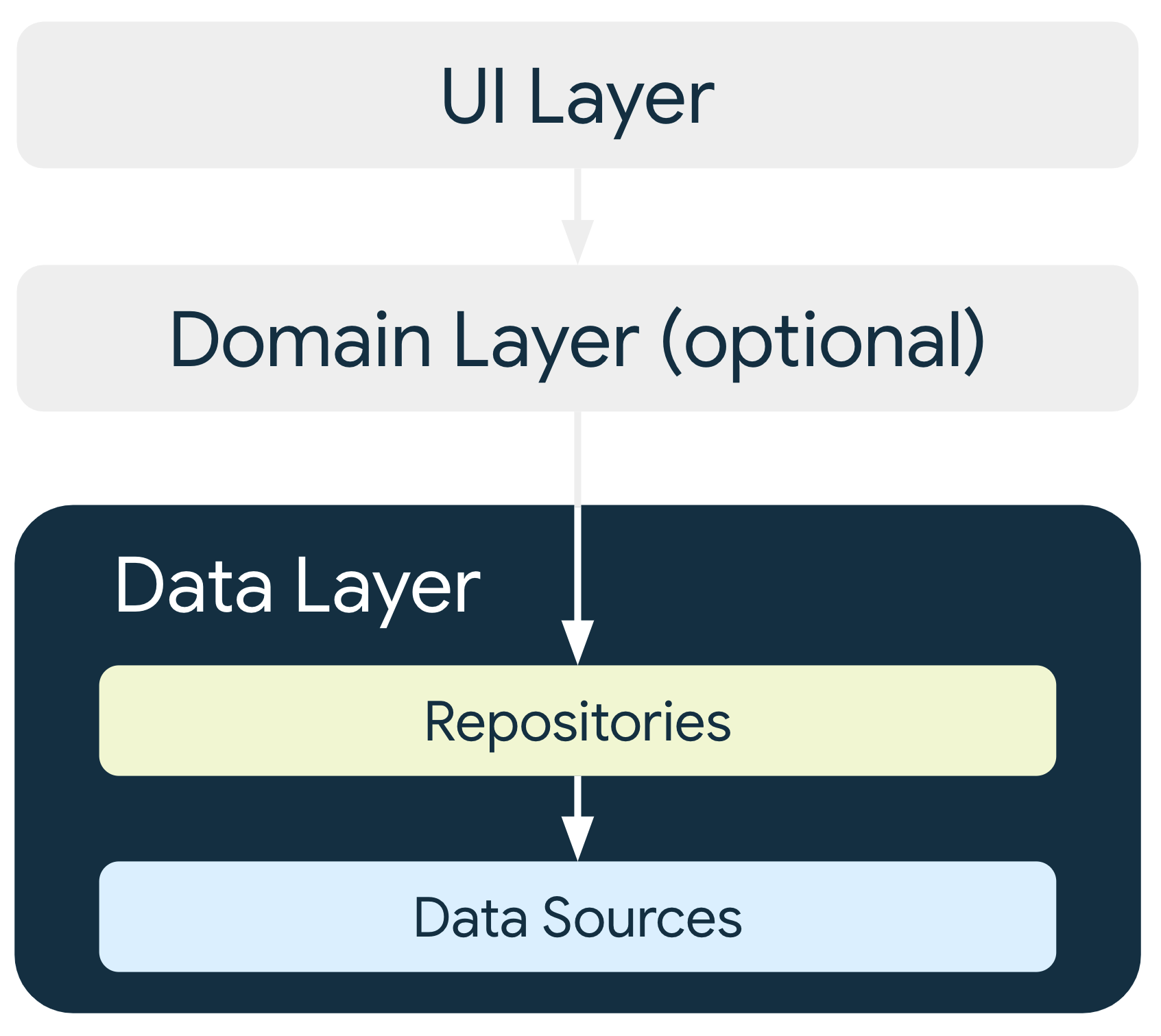
Las clases de repositorio son responsables de lo siguiente:
- Exponer datos al resto de la app
- Centralizar los cambios en los datos
- Resolver conflictos entre múltiples fuentes de datos
- Abstraer fuentes de datos del resto de la app
- Contener la lógica empresarial
Cada clase de fuente de datos debe tener la responsabilidad de trabajar con una sola fuente de datos, que puede ser un archivo, una fuente de red o una base de datos local. Las clases de fuente de datos son el puente entre la aplicación y el sistema para las operaciones de datos.
Para obtener más información, consulta la página sobre la capa de datos.
Capa de dominio
La capa de dominio es una capa opcional que se ubica entre la capa de la IU y la de datos.
La capa de dominio es responsable de encapsular la lógica empresarial compleja o la lógica empresarial simple que varios modelos de vista reutilizan. La capa de dominio es opcional porque no todas las apps tienen estos requisitos. Solo debes usarla cuando sea necesario; por ejemplo, para administrar la complejidad o favorecer la reutilización.
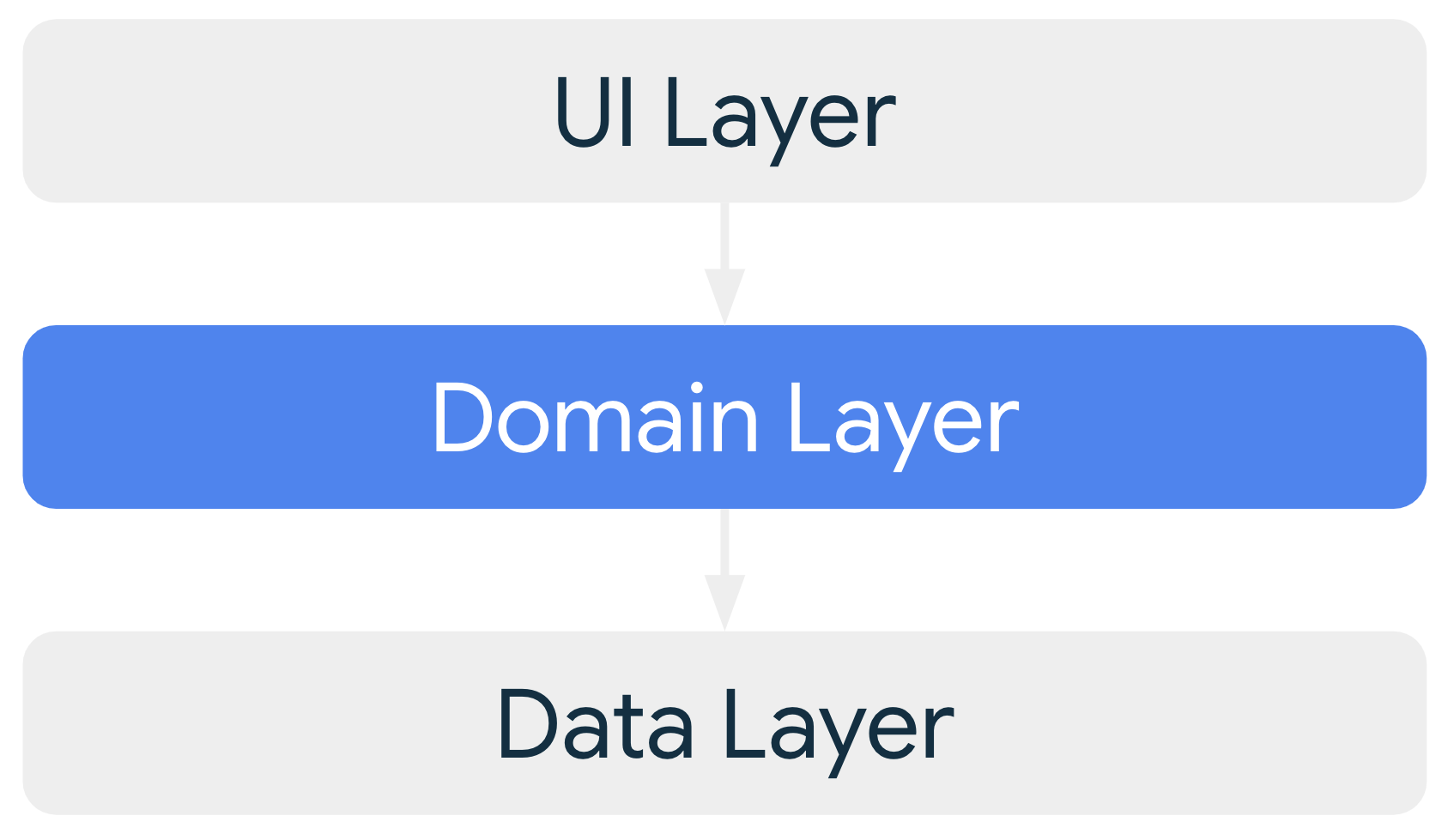
Las clases de la capa de dominio se denominan casos de uso o interactores.
Cada caso de uso tiene responsabilidad sobre una funcionalidad única. Por ejemplo, tu app podría tener una clase GetTimeZoneUseCase si varios modelos de vista dependen de las zonas horarias para mostrar el mensaje adecuado en la pantalla.
Para obtener más información, consulta la página sobre la capa del dominio.
Cómo administrar dependencias entre componentes
Las clases de tu app dependen de otras para funcionar correctamente. Puedes usar cualquiera de los siguientes patrones de diseño para recopilar las dependencias de una clase en particular:
- Inyección de dependencia (DI): Permite que las clases definan sus dependencias sin construirlas. En el tiempo de ejecución, otra clase es responsable de proporcionar estas dependencias.
- Localizador de servicios: El patrón de localizador de servicios proporciona un registro en el que las clases pueden obtener sus dependencias en lugar de construirlas.
Estos patrones te permiten hacer un escalamiento del código, ya que proporcionan patrones claros para administrar dependencias sin duplicar el código ni aumentar la complejidad. Además, te permiten cambiar rápidamente entre las implementaciones de prueba y de producción.
Prácticas recomendadas generales
La programación es una disciplina creativa y crear apps de Android no es una excepción. Hay muchas maneras de resolver un problema: puedes comunicar datos entre varias actividades o fragmentos, recuperar datos remotos y conservarlos a nivel local para el modo sin conexión, o bien controlar cualquier cantidad de situaciones comunes con las que pueden encontrarse las apps no triviales.
Aunque las siguientes recomendaciones no son obligatorias, en la mayoría de los casos, si las sigues, tu código base será más confiable, tendrá mayor capacidad de prueba y será más fácil de mantener.
No almacenes datos en los componentes de la app
Evita designar los puntos de entrada de tu app (receptores de transmisiones, servicios y actividades) como fuentes de datos. Haz que los puntos de entrada se coordinen con otros componentes para recuperar solo el subconjunto de datos relevante para ese punto de entrada. Cada componente de la app tiene una duración relativamente corta, según la interacción que el usuario tenga con su dispositivo y la capacidad del sistema.
Reduce las dependencias de clases de Android
Haz que los componentes de tu app sean las únicas clases que dependan de las APIs del SDK del framework de Android
como Context o Toast. La abstracción de otras clases en tu
app fuera de los componentes de la app ayuda con la capacidad de prueba y reduce
el acoplamiento dentro de la app.
Define límites de responsabilidad claros entre los módulos de tu app.
No extiendas el código que carga datos de la red entre varias clases o paquetes en tu código base. Del mismo modo, no definas varias responsabilidades no relacionadas, como caché de datos y vinculación de datos, en la misma clase. Sigue la arquitectura de la app recomendada.
Expón lo mínimo indispensable de cada módulo
No crees accesos directos que expongan detalles internos de la implementación. Quizás ahorres algo de tiempo a corto plazo, pero tendrás más probabilidades de que se generen problemas técnicos a medida que tu código base evolucione.
Concéntrate en aquello que hace única a tu app para que se destaque del resto
No desperdicies tu tiempo reinventando algo que ya existe ni escribiendo el mismo código estándar una y otra vez. En cambio, enfoca tu tiempo y tu energía en aquello que hace que tu app sea única. Deja que tanto las bibliotecas de Jetpack como las otras recomendadas se ocupen del código estándar repetitivo.
Usa diseños canónicos y patrones de diseño de apps.
Las bibliotecas de Jetpack Compose proporcionan APIs sólidas para compilar interfaces de usuario adaptables. Usa los diseños canónicos en tu app para optimizar la experiencia del usuario en varios factores de forma y tamaños de pantalla. Revisa la galería de patrones de diseño de apps para seleccionar los diseños que mejor se adapten a tus casos de uso.
Preserva el estado de la IU durante los cambios de configuración.
Cuando diseñes diseños adaptables, preserva el estado de la IU durante los cambios de configuración, como el cambio de tamaño de la pantalla, el plegado y los cambios de orientación. Tu arquitectura debe verificar que se mantenga el estado actual del usuario, lo que proporciona una experiencia fluida.
Diseña componentes de IU reutilizables y que admitan composición.
Compila componentes de IU reutilizables y que admitan composición para admitir el diseño adaptable. Esto te permite combinar y reorganizar componentes para que se adapten a varios tamaños y posiciones de pantalla sin una refactorización significativa.
Piensa en cómo lograr que cada parte de tu app se pueda probar por separado
Una API bien definida para recuperar datos de la red facilita las pruebas que realices en el módulo que conserve esa información en la base de datos local. En cambio, si combinas la lógica de estas dos funciones en un solo lugar, o si distribuyes el código de red por todo tu código base, será mucho más difícil (y quizás hasta imposible) ponerlo a prueba.
Los tipos son responsables de su política de simultaneidad
Si un tipo realiza un trabajo de bloqueo de larga duración, debería ser responsable de mover ese cálculo al subproceso correcto. El tipo conoce el tipo de procesamiento que está haciendo y en qué subproceso debe ejecutarse. Los tipos deben ser seguros para el subproceso principal, lo que significa que son seguros llamarlos desde el subproceso principal sin bloquearlo.
Conserva la mayor cantidad posible de datos relevantes y actualizados
De esa manera, los usuarios podrán aprovechar la funcionalidad de tu app, incluso cuando su dispositivo esté en modo sin conexión. Recuerda que no todos tus usuarios cuentan con una conexión de alta velocidad de manera constante y, si lo hacen, pueden tener una mala recepción en lugares muy concurridos.
Beneficios de la arquitectura
Tener una buena arquitectura implementada en tu app trae muchos beneficios a los equipos de proyectos y de ingeniería:
- Mejora la capacidad de mantenimiento, calidad y solidez de la app en general.
- Permite que la aplicación escale. Más personas y más equipos pueden contribuir a la misma base de código con conflictos de código mínimos.
- Ayuda con la integración. A medida que la arquitectura aporta coherencia a tu proyecto, los miembros nuevos del equipo pueden ponerse al día rápidamente y ser más eficientes en menos tiempo.
- Es más fácil probarlo. Una buena arquitectura fomenta tipos más simples que, en general, son más fáciles de probar.
- Te permite investigar errores metódicamente con procesos bien definidos.
Aunque una buena arquitectura requiere una inversión de tiempo inicial, también tiene un impacto directo en los usuarios, ya que se beneficiarán de una aplicación más estable y de más funciones gracias a un equipo de ingeniería más productivo.
Ejemplos
En los siguientes ejemplos, se demuestra una buena arquitectura de la app: