
While the UI layer contains UI-related state and UI logic, the data layer contains application data and business logic. The business logic is what gives value to your app—it's made of real-world business rules that determine how application data must be created, stored, and changed.
This separation of concerns allows the data layer to be used on multiple screens, share information between different parts of the app, and reproduce business logic outside of the UI for unit testing. For more information about the benefits of the data layer, check out the Architecture Overview page.
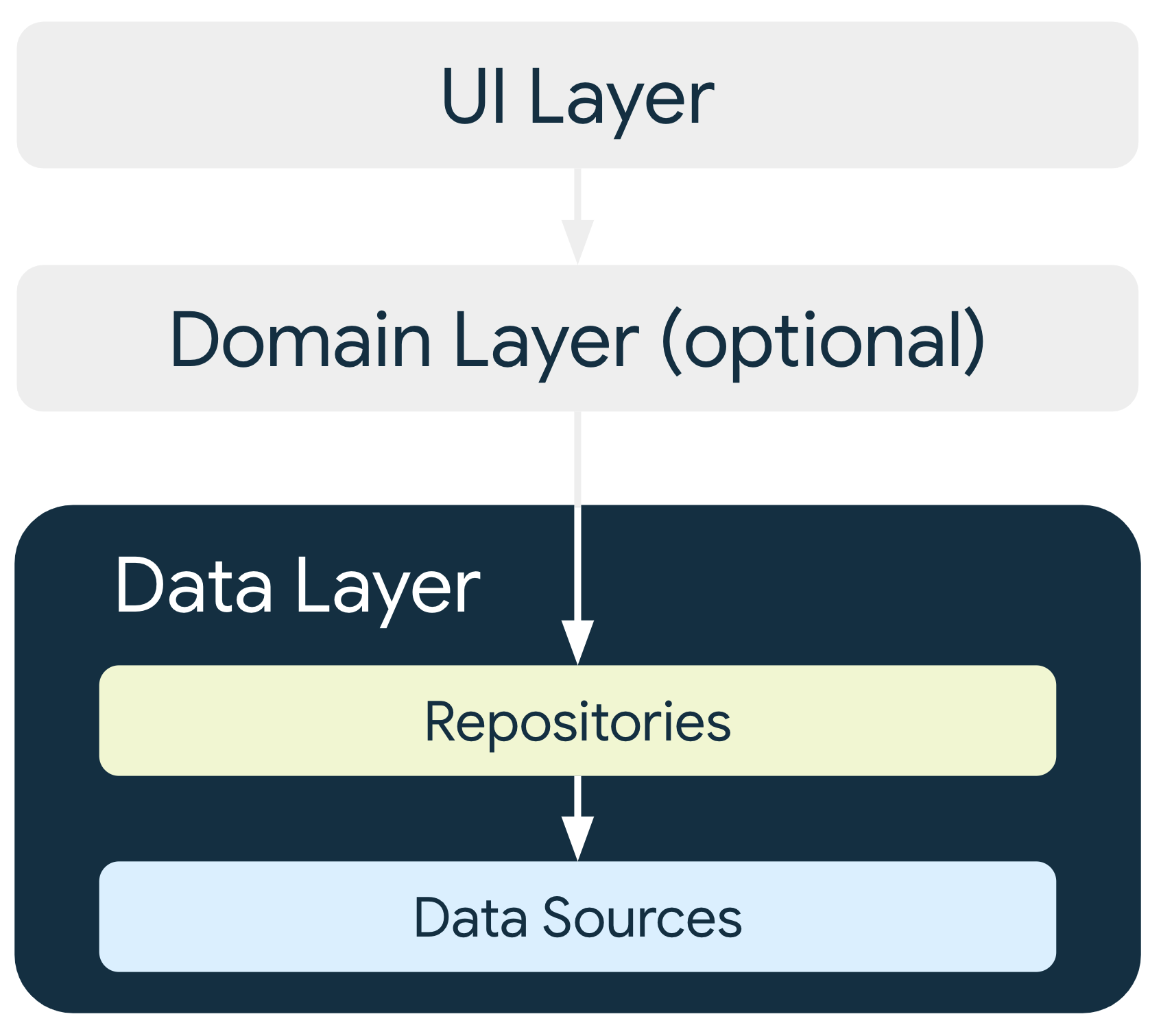
Data layer architecture
The data layer is made of repositories that each can contain zero to many
data sources. You should create a repository class for each different type of
data you handle in your app. For example, you might create a MoviesRepository
class for data related to movies, or a PaymentsRepository class for data
related to payments.
Repository classes are responsible for the following tasks:
- Exposing data to the rest of the app.
- Centralizing changes to the data.
- Resolving conflicts between multiple data sources.
- Abstracting sources of data from the rest of the app.
- Containing business logic.
Each data source class should have the responsibility of working with only one source of data, which can be a file, a network source, or a local database. Data source classes are the bridge between the application and the system for data operations.
Other layers in the hierarchy should never access data sources directly; the entry points to the data layer are always the repository classes. State holder classes (see the UI layer guide) or use case classes (see the domain layer guide) should never have a data source as a direct dependency. Using repository classes as entry points allows the different layers of the architecture to scale independently.
The data exposed by this layer should be immutable so that it cannot be tampered with by other classes, which would risk putting its values in an inconsistent state. Immutable data can also be safely handled by multiple threads. See the threading section for more details.
Following dependency injection best practices, the repository takes data sources as dependencies in its constructor:
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) { /* ... */ }
Expose APIs
Classes in the data layer generally expose functions to perform one-shot Create, Read, Update and Delete (CRUD) calls or to be notified of data changes over time. The data layer should expose the following for each of these cases:
- For one-shot operations, expose suspend functions.
- To be notified of data changes over time, expose flows.
class ExampleRepository(
private val exampleRemoteDataSource: ExampleRemoteDataSource, // network
private val exampleLocalDataSource: ExampleLocalDataSource // database
) {
val data: Flow<Example> = ...
suspend fun modifyData(example: Example) { ... }
}
Naming conventions in this guide
In this guide, repository classes are named after the data that they're responsible for. The convention is as follows:
type of data + Repository.
For example: NewsRepository, MoviesRepository, or PaymentsRepository.
Data source classes are named after the data they're responsible for and the source they use. The convention is as follows:
type of data + type of source + DataSource.
For the type of data, use Remote or Local to be more generic because
implementations can change. For example: NewsRemoteDataSource or
NewsLocalDataSource. To be more specific in case the source is important, use
the type of the source. For example: NewsNetworkDataSource or
NewsDiskDataSource.
Don't name the data source based on an implementation detail—for example,
UserSharedPreferencesDataSource—because repositories that use that data source
shouldn't know how the data is saved. If you follow this rule, you can change
the implementation of the data source (for example, migrating from
SharedPreferences to DataStore) without affecting the layer that calls
that source.
Multiple levels of repositories
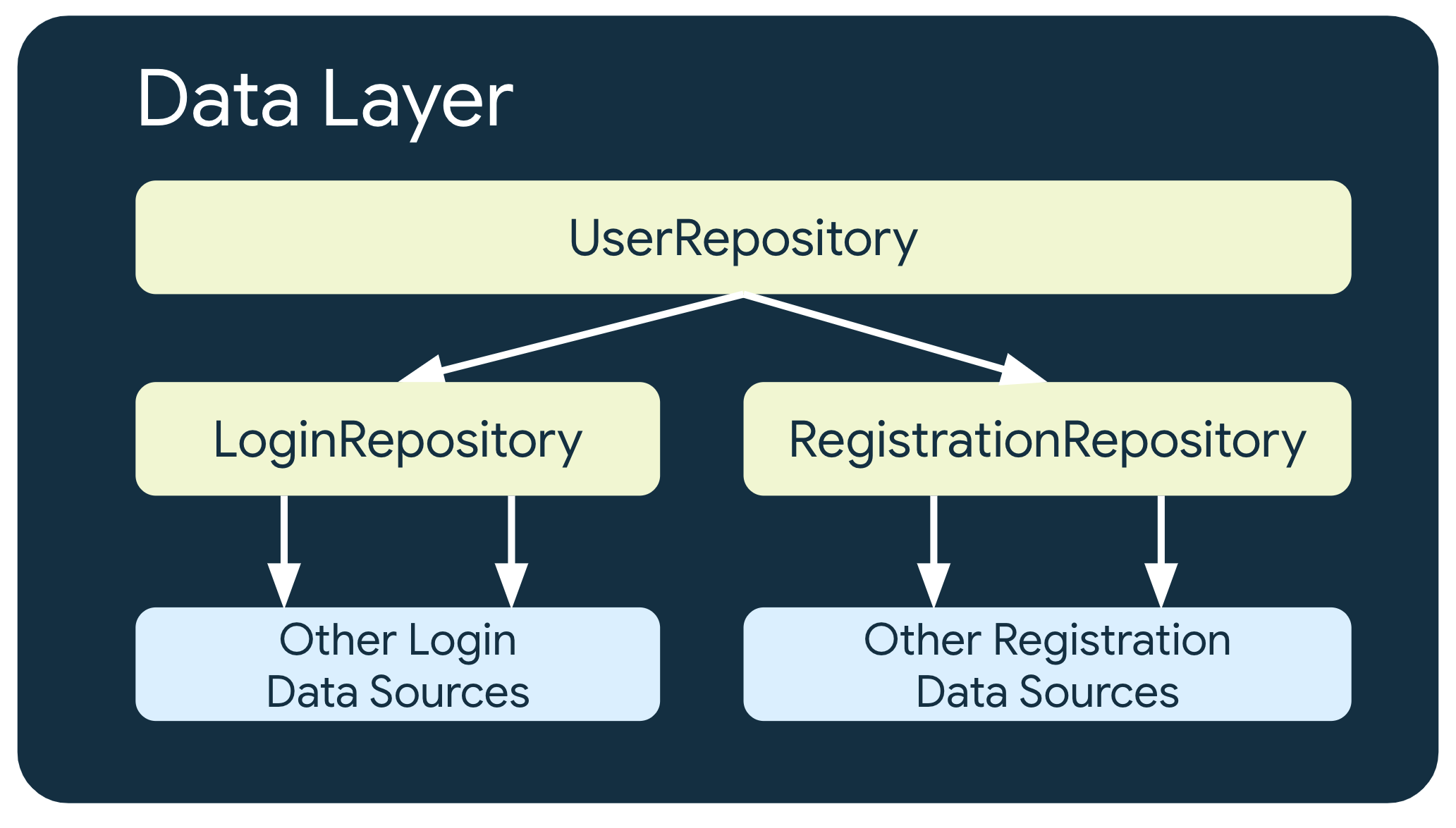
In some cases involving more complex business requirements, a repository might need to depend on other repositories. This could be because the data involved is an aggregation from multiple data sources, or because the responsibility needs to be encapsulated in another repository class.
For example, a repository that handles user authentication data,
UserRepository, could depend on other repositories such as LoginRepository
and RegistrationRepository to fulfill its requirements.
Source of truth
It's important that each repository defines a single source of truth. The source of truth always contains data that is consistent, correct, and up-to-date. In fact, the data exposed from the repository should always be the data coming directly from the source of truth.
The source of truth can be a data source—for example, the database—or even an in-memory cache that the repository might contain. Repositories combine different data sources and solve any potential conflicts between the data sources to update the single source of truth regularly or due to a user input event.
Different repositories in your app might have different sources of truth. For
example, the LoginRepository class might use its cache as the source of truth
and the PaymentsRepository class might use the network data source.
In order to provide offline-first support, a local data source—such as a database—is the recommended source of truth.
Threading
Calling data sources and repositories should be main-safe—safe to call from the main thread. These classes are responsible for moving the execution of their logic to the appropriate thread when performing long-running blocking operations. For example, it should be main-safe for a data source to read from a file, or for a repository to perform expensive filtering on a big list.
Note that most data sources already provide main-safe APIs like the suspend method calls provided by Room, Retrofit or Ktor. Your repository can take advantage of these APIs when they are available.
To learn more about threading, see the guide to background processing. For Kotlin users, coroutines are the recommended option.
Lifecycle
Instances of classes in the data layer remain in memory as long as they are reachable from a garbage collection root—usually by being referenced from other objects in your app.
If a class contains in-memory data—for example, a cache—you might want to reuse the same instance of that class for a specific period of time. This is also referred to as the lifecycle of the class instance.
If the class's responsibility is crucial for the whole application, you can
scope an instance of that class to the Application class. This makes it so
the instance follows the application's lifecycle. Alternatively, if you only
need to reuse the same instance in a particular flow in your app—for example,
the registration or login flow—then you should scope the instance to the class
that owns the lifecycle of that flow. For example, you could scope a
RegistrationRepository that contains in-memory data to the
RegistrationActivity, or to a backstack using a NavEntryDecorator.
The lifecycle of each instance is a critical factor in deciding how to provide dependencies within your app. It's recommended that you follow dependency injection best practices where the dependencies are managed and can be scoped to dependency containers. To learn more about scoping in Android, see the Scoping in Android and Hilt blog post.
Represent business models
The data models that you want to expose from the data layer might be a subset of the information that you get from the different data sources. Ideally, the different data sources—both network and local—should return only the information your application needs; but that's not often the case.
For example, imagine a News API server that returns not only the article information, but also edit history, user comments, and some metadata:
data class ArticleApiModel(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val modifications: Array<ArticleApiModel>,
val comments: Array<CommentApiModel>,
val lastModificationDate: Date,
val authorId: Long,
val authorName: String,
val authorDateOfBirth: Date,
val readTimeMin: Int
)
The app doesn't need that much information about the article because it only
displays the content of the article on the screen, along with basic information
about its author. It's a good practice to separate model classes and have your
repositories expose only the data that the other layers of the hierarchy
require. For example, here is how you might trim down the ArticleApiModel from
the network in order to expose an Article model class to the domain and UI
layers:
data class Article(
val id: Long,
val title: String,
val content: String,
val publicationDate: Date,
val authorName: String,
val readTimeMin: Int
)
Separating model classes is beneficial in the following ways:
- It saves app memory by reducing the data to only what's needed.
- It adapts external data types to data types used by your app—for example, your app might use a different data type to represent dates.
- It provides better separation of concerns—for example, members of a large team could work individually on the network and UI layers of a feature if the model class is defined beforehand.
You can extend this practice and define separate model classes in other parts of your app architecture as well—for example, in data source classes and ViewModels. However, this requires you to define extra classes and logic that you should properly document and test. At minimum, it's recommended that you create new models in any case where a data source receives data that doesn't match with what the rest of your app expects.
Types of data operations
The data layer can deal with types of operations that vary based on how critical they are: UI-oriented, app-oriented, and business-oriented operations.
UI-oriented operations
UI-oriented operations are only relevant when the user is on a specific screen, and they're canceled when the user moves away from that screen. An example is displaying some data obtained from the database.
UI-oriented operations are typically triggered by the UI layer and follow the caller's lifecycle—for example, the lifecycle of the ViewModel. See the Make a network request section for an example of a UI-oriented operation.
App-oriented operations
App-oriented operations are relevant as long as the app is open. If the app is closed or the process is killed, these operations are canceled. An example is caching the result of a network request so that it can be used later if needed. See the Implement in-memory data caching section to learn more.
These operations typically follow the lifecycle of the Application class or
the data layer. For an example, see the Make an operation live longer than the
screen section.
Business-oriented operations
Business-oriented operations cannot be canceled. They should survive process death. An example is finishing the upload of a photo that the user wants to post to their profile.
The recommendation for business-oriented operations is to use WorkManager. See the Schedule tasks using WorkManager section to learn more.
Expose errors
Interactions with repositories and sources of data can either succeed or throw
an exception when a failure occurs. For coroutines and flows, you should use
Kotlin's built-in error-handling mechanism. For errors that could be
triggered by suspend functions, use try/catch blocks when appropriate; and in
flows, use the catch operator. With this approach, the UI layer is
expected to handle exceptions when calling the data layer.
The data layer can understand and handle different types of errors and expose
them using custom exceptions—for example, a UserNotAuthenticatedException.
To learn more about errors in coroutines, see the Exceptions in coroutines blog post.
Common tasks
The following sections present examples of how to use and architect the data layer to perform certain tasks that are common in Android apps. The examples are based on the typical News app mentioned earlier in the guide.
Make a network request
Making a network request is one of the most common tasks an Android app might
perform. The News app needs to present the user with the latest news that is
fetched from the network. Therefore, the app needs a data source class to manage
network operations: NewsRemoteDataSource. To expose the information to the
rest of the app, a new repository that handles operations on news data is
created: NewsRepository.
The requirement is that the latest news always needs to be updated when the user opens the screen. Thus, this is a UI-oriented operation.
Create the data source
The data source needs to expose a function that returns the latest news: a list
of ArticleHeadline instances. The data source needs to provide a main-safe way
to obtain the latest news from the network. For that, it needs to take a
dependency on the CoroutineDispatcher or Executor to run the task on.
Making a network request is a one-shot call handled by a new fetchLatestNews()
method:
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val ioDispatcher: CoroutineDispatcher
) {
/**
* Fetches the latest news from the network and returns the result.
* This executes on an IO-optimized thread pool, the function is main-safe.
*/
suspend fun fetchLatestNews(): List<ArticleHeadline> =
// Move the execution to an IO-optimized thread since the ApiService
// doesn't support coroutines and makes synchronous requests.
withContext(ioDispatcher) {
newsApi.fetchLatestNews()
}
}
// Makes news-related network synchronous requests.
interface NewsApi {
fun fetchLatestNews(): List<ArticleHeadline>
}
The NewsApi interface hides the implementation of the network API client; it
doesn't make a difference whether the interface is backed by Retrofit or
HttpURLConnection. Relying on interfaces makes API implementations
swappable in your app.
Create the repository
Because no extra logic is needed in the repository class for this task,
NewsRepository acts as a proxy for the network data source. The benefits of
adding this extra layer of abstraction are explained in the in-memory
caching section.
// NewsRepository is consumed from other layers of the hierarchy.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
suspend fun fetchLatestNews(): List<ArticleHeadline> =
newsRemoteDataSource.fetchLatestNews()
}
To learn how to consume the repository class directly from the UI layer, see the UI layer guide.
Implement in-memory data caching
Suppose a new requirement is introduced for the News app: when the user opens the screen, cached news must be presented to the user if a request has been made previously. Otherwise, the app should make a network request to fetch the latest news.
Given the new requirement, the app must preserve the latest news in memory while the user has the app open. Thus, this is an app-oriented operation.
Caches
You can preserve data while the user is in your app by adding in-memory data caching. Caches are meant to save some information in memory for a specific amount of time—in this case, as long as the user is in the app. Cache implementations can take different forms. They can vary from simple mutable variables to more sophisticated classes that protect from read/write operations on multiple threads. Depending on the use case, caching can be implemented in the repository or in data source classes.
Cache the result of the network request
For simplicity, NewsRepository uses a mutable variable to cache the latest
news. To protect reads and writes from different threads, a Mutex is
used. To learn more about shared mutable state and concurrency, see the Kotlin
documentation.
The following implementation caches the latest news information to a variable in
the repository that is write-protected with a Mutex. If the result of the
network request succeeds, the data is assigned to the latestNews variable.
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource
) {
// Mutex to make writes to cached values thread-safe.
private val latestNewsMutex = Mutex()
// Cache of the latest news got from the network.
private var latestNews: List<ArticleHeadline> = emptyList()
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
if (refresh || latestNews.isEmpty()) {
val networkResult = newsRemoteDataSource.fetchLatestNews()
// Thread-safe write to latestNews
latestNewsMutex.withLock {
this.latestNews = networkResult
}
}
return latestNewsMutex.withLock { this.latestNews }
}
}
Make an operation live longer than the screen
If the user navigates away from the screen while the network request is in
progress, it'll be canceled and the result won't be cached. NewsRepository
shouldn't use the caller's CoroutineScope to perform this logic. Instead,
NewsRepository should use a CoroutineScope that's attached to its lifecycle.
Fetching the latest news needs to be an app-oriented operation.
To follow dependency injection best practices, NewsRepository should receive a
scope as a parameter in its constructor instead of creating its own
CoroutineScope. Because repositories should do most of their work in
background threads, you should configure the CoroutineScope with either
Dispatchers.Default or with your own thread pool.
class NewsRepository(
...,
// This could be CoroutineScope(SupervisorJob() + Dispatchers.Default).
private val externalScope: CoroutineScope
) { ... }
Because NewsRepository is ready to perform app-oriented operations with the
external CoroutineScope, it must perform the call to the data source and save
its result with a new coroutine started by that scope:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val externalScope: CoroutineScope
) {
/* ... */
suspend fun getLatestNews(refresh: Boolean = false): List<ArticleHeadline> {
return if (refresh) {
externalScope.async {
newsRemoteDataSource.fetchLatestNews().also { networkResult ->
// Thread-safe write to latestNews.
latestNewsMutex.withLock {
latestNews = networkResult
}
}
}.await()
} else {
return latestNewsMutex.withLock { this.latestNews }
}
}
}
async is used to start the coroutine in the external scope. await is called
on the new coroutine to suspend until the network request comes back and the
result is saved to the cache. If by that time the user is still on the screen,
then they will see the latest news; if the user moves away from the screen,
await is canceled but the logic inside async continues to execute.
Read more about patterns for CoroutineScope.
Save and retrieve data from disk
Suppose that you want to save data like bookmarked news and user preferences. This type of data needs to survive process death and be accessible even if the user is not connected to the network.
If the data you're working with needs to survive process death, then you need to store it on disk in one of the following ways:
- For large datasets that need to be queried, need referential integrity, or need partial updates, save the data in a Room database. In the News app example, the news articles or authors could be saved in the database.
- For small datasets that only need to be retrieved and set (not queried or updated partially), use DataStore. In the News app example, the user's preferred date format or other display preferences could be saved in DataStore.
- For chunks of data like a JSON object, use a file.
As mentioned in the Source of truth section, each data source works with
only one source and corresponds to a specific data type (for example, News,
Authors, NewsAndAuthors, or UserPreferences). Classes that use the data
source shouldn't know how the data is saved—for example, in a database or in a
file.
Room as a data source
Because each data source should have the responsibility of working with only one
source for a specific type of data, a Room data source would receive either a
data access object (DAO) or the database itself as a parameter. For
example, NewsLocalDataSource might take an instance of NewsDao as a
parameter, and AuthorsLocalDataSource might take an instance of AuthorsDao.
In some cases, if no extra logic is needed, you could inject the DAO directly into the repository, because the DAO is an interface that you can easily replace in tests.
To learn more about working with the Room APIs, see the Room guides.
DataStore as a data source
DataStore is perfect for storing key-value pairs like user settings. Examples might include time format, notification preferences, and whether to show or hide news items after the user has read them. DataStore can also store typed objects with protocol buffers.
Like with any other object, a data source backed by DataStore should contain data corresponding to a certain type or to a certain part of the app. This is even more true with DataStore, because DataStore reads are exposed as a flow that emits every time a value is updated. For this reason, you should store related preferences in the same DataStore.
For example, you could have a NotificationsDataStore that only handles
notification-related preferences and a NewsPreferencesDataStore that only
handles preferences related to the news screen. That way, you're able to scope
the updates better, because the newsScreenPreferencesDataStore.data flow only
emits when a preference related to that screen is changed. It also means that
the lifecycle of the object can be shorter because it can live only as long as
the news screen is displayed.
To learn more about working with the DataStore APIs, see the DataStore guides.
A file as a data source
When working with large objects like a JSON object or a bitmap, you'll need to
work with a File object and handle switching threads.
To learn more about working with file storage, see the Storage overview page.
Schedule tasks using WorkManager
Suppose another new requirement is introduced for the News app: the app must give the user the option to fetch the latest news regularly and automatically as long as the device is charging and connected to an unmetered network. That makes this a business-oriented operation. This requirement makes it so that even if the device doesn't have connectivity when the user opens the app, the user can still see recent news.
WorkManager makes it easy to schedule asynchronous and reliable work and
can take care of constraint management. It's the recommended library for
persistent work. To perform the task defined above, a Worker class is
created: RefreshLatestNewsWorker. This class takes NewsRepository as a
dependency in order to fetch the latest news and cache it to disk.
class RefreshLatestNewsWorker(
private val newsRepository: NewsRepository,
context: Context,
params: WorkerParameters
) : CoroutineWorker(context, params) {
override suspend fun doWork(): Result = try {
newsRepository.refreshLatestNews()
Result.success()
} catch (error: Throwable) {
Result.failure()
}
}
The business logic for this type of task should be encapsulated in its own class and treated as a separate data source. WorkManager will then only be responsible for ensuring the work is executed on a background thread when all constraints are met. By adhering to this pattern, you can quickly swap implementations on different environments as needed.
In this example, this news-related task must be called from NewsRepository,
which would take a new data source as a dependency, NewsTasksDataSource,
implemented as follows:
private const val REFRESH_RATE_HOURS = 4L
private const val FETCH_LATEST_NEWS_TASK = "FetchLatestNewsTask"
private const val TAG_FETCH_LATEST_NEWS = "FetchLatestNewsTaskTag"
class NewsTasksDataSource(
private val workManager: WorkManager
) {
fun fetchNewsPeriodically() {
val fetchNewsRequest = PeriodicWorkRequestBuilder<RefreshLatestNewsWorker>(
REFRESH_RATE_HOURS, TimeUnit.HOURS
).setConstraints(
Constraints.Builder()
.setRequiredNetworkType(NetworkType.TEMPORARILY_UNMETERED)
.setRequiresCharging(true)
.build()
)
.addTag(TAG_FETCH_LATEST_NEWS)
workManager.enqueueUniquePeriodicWork(
FETCH_LATEST_NEWS_TASK,
ExistingPeriodicWorkPolicy.KEEP,
fetchNewsRequest.build()
)
}
fun cancelFetchingNewsPeriodically() {
workManager.cancelAllWorkByTag(TAG_FETCH_LATEST_NEWS)
}
}
These types of classes are named after the data they're responsible for—for
example, NewsTasksDataSource or PaymentsTasksDataSource. All tasks related
to a particular type of data should be encapsulated in the same class.
If the task needs to be triggered at app startup, it's recommended to trigger
the WorkManager request using the App Startup library that calls the
repository from an Initializer.
To learn more about working with WorkManager APIs, see the WorkManager guides.
Testing
Dependency injection best practices help when testing your app. It's also helpful to rely on interfaces for classes that communicate with external resources. When you test a unit, you can inject fake versions of its dependencies to make the test deterministic and reliable.
Unit tests
General testing guidance applies when testing the data layer. For unit tests, use real objects when needed and fake any dependencies that reach out to external sources such as reading from a file or reading from the network.
Integration tests
Integration tests that access external sources tend to be less deterministic because they need to run on a real device. It's recommended that you execute those tests under a controlled environment to make the integration tests more reliable.
For databases, Room allows creating an in-memory database that you can fully control in your tests. To learn more, see the Test and debug your database page.
For networking, there are popular libraries such as WireMock or MockWebServer that let you fake HTTP and HTTPS calls and verify that the requests were made as expected.
Additional resources
Samples
- Jetcaster
- Architecture starter template (multi-module)
- Architecture
- Architecture starter template (single module)
- Now in Android app
Recommended for you
- Note: link text is displayed when JavaScript is off
- Domain layer
- Build an offline-first app
- UI State production