
Android Neural Networks API (NNAPI) là một API ngôn ngữ C của Android được thiết kế để chạy các phép tính toán chuyên sâu dành cho học máy trên thiết bị Android. NNAPI được thiết kế nhằm cung cấp một lớp chức năng cơ sở cho các khung máy học cao cấp hơn (chẳng hạn như TensorFlow Lite và Caffe2) có tác dụng xây dựng và huấn luyện mạng nơron. API này có sẵn trên tất cả các thiết bị Android chạy Android 8.1 (cấp độ API 27) trở lên, nhưng đã ngừng hoạt động trong Android 15.
NNAPI hỗ trợ khả năng dự đoán bằng cách áp dụng dữ liệu từ thiết bị Android cho các mô hình đã được huấn luyện và được nhà phát triển xác định trước đó. Ví dụ về khả năng dự đoán: phân loại hình ảnh, dự đoán hành vi của người dùng và chọn nội dung phản hồi thích hợp cho một cụm từ tìm kiếm.
Khả năng dự đoán trên thiết bị mang lại nhiều lợi ích:
- Độ trễ: Bạn không cần gửi yêu cầu qua kết nối mạng và chờ phản hồi. Ví dụ: đối với các ứng dụng video xử lý các khung hình liên tiếp từ máy ảnh/máy quay thì độ trễ có thể là yếu tố quan trọng.
- Khả năng hoạt động: Ứng dụng hoạt động ngay cả khi nằm ngoài phạm vi kết nối của mạng.
- Tốc độ: Phần cứng mới dành riêng cho việc xử lý mạng nơron mang lại tốc độ tính toán nhanh hơn đáng kể so với khi chỉ có một CPU nhiều công dụng.
- Quyền riêng tư: Dữ liệu không rời khỏi thiết bị Android.
- Chi phí: Không cần đến cụm máy chủ khi tất cả các phép tính đều được thực hiện trên thiết bị Android.
Nhà phát triển cũng cần lưu ý một số yếu tố đánh đổi:
- Mức sử dụng hệ thống: Việc đánh giá mạng nơron kéo theo nhiều hoạt động tính toán, từ đó có thể làm tăng mức sử dụng pin. Bạn nên cân nhắc theo dõi tình trạng pin nếu đây là vấn đề đáng ngại cho ứng dụng của bạn, đặc biệt là khi có các phép tính diễn ra trong thời gian dài.
- Kích thước ứng dụng: Hãy chú ý đến kích thước của các mô hình mà bạn sử dụng. Các mô hình có thể chiếm nhiều megabyte dung lượng. Nếu việc đóng gói các mô hình lớn trong tệp APK có thể ảnh hưởng quá mức đến người dùng, bạn nên cân nhắc tải các mô hình đó xuống sau khi cài đặt ứng dụng, sử dụng các mô hình nhỏ hơn hoặc chạy các phép tính trên đám mây. NNAPI không cung cấp chức năng chạy các mô hình trên đám mây.
Để tìm hiểu ví dụ về cách sử dụng NNAPI, hãy xem mẫu Android Neural Networks API.
Tìm hiểu về môi trường thời gian chạy của Neural Networks API
NNAPI vốn là dùng theo lệnh gọi của các công cụ, khung và thư viện máy học nhằm cho phép các nhà phát triển huấn luyện mô hình ở ngoài thiết bị rồi triển khai các mô hình đó trên thiết bị Android. Các ứng dụng thường không trực tiếp sử dụng NNAPI mà sẽ dùng các khung máy học cao cấp hơn. Sau đó, các khung này có thể sử dụng NNAPI để thực hiện các phép toán dự đoán có tăng tốc phần cứng trên những thiết bị được hỗ trợ.
Dựa trên các yêu cầu của ứng dụng và khả năng của phần cứng trên thiết bị Android, môi trường thời gian chạy mạng nơron của Android có thể phân phối khối lượng công việc điện toán một cách hiệu quả giữa các bộ xử lý có trên thiết bị, bao gồm phần cứng mạng nơron chuyên dụng, các bộ xử lý đồ hoạ (GPU) và các bộ xử lý tín hiệu kỹ thuật số (DSP).
Đối với các thiết bị Android thiếu trình điều khiển chuyên biệt của nhà cung cấp, môi trường thời gian chạy NNAPI sẽ thực thi các yêu cầu trên CPU.
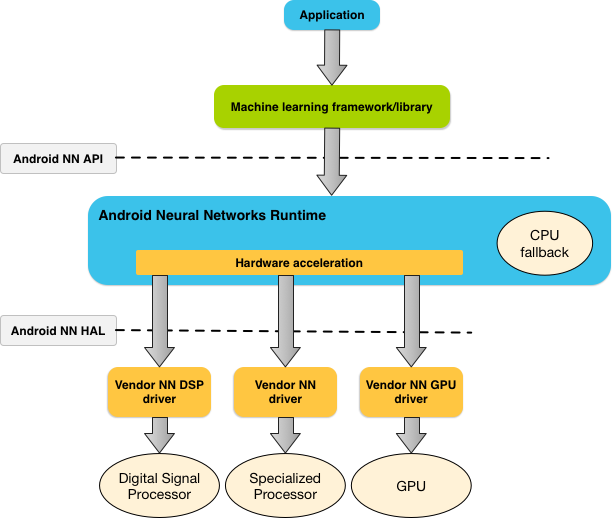
Hình 1 thể hiện kiến trúc hệ thống cấp cao của NNAPI.
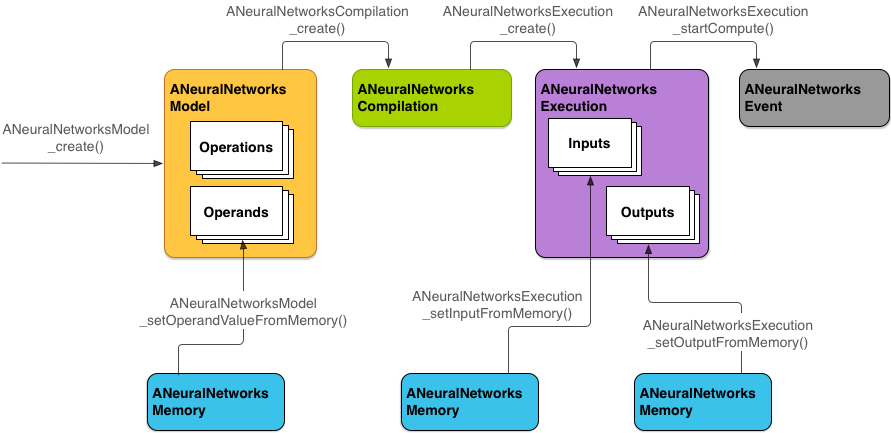
Mô hình lập trình của Neural Networks API
Để thực hiện các phép tính bằng NNAPI, trước tiên bạn cần xây dựng một đồ thị định hướng giúp xác định các phép tính cần thực hiện. Đồ thị tính toán này, kết hợp với dữ liệu đầu vào của bạn (ví dụ: các trọng số và độ chệch được truyền từ một khung máy học), tạo thành mô hình để đánh giá môi trường thời gian chạy NNAPI.
NNAPI sử dụng bốn thành phần trừu tượng chính:
- Mô hình: Đồ thị tính toán gồm các phép tính toán học và giá trị hằng số đã học thông qua một quá trình huấn luyện. Đây là những phép toán dành riêng cho mạng nơron. Các phép toán này bao gồm: tích chập 2 chiều (2D), hàm kích hoạt logic (sigmoid), hàm kích hoạt tuyến tính chỉnh lưu (ReLU), v.v. Việc tạo mô hình là một phép toán đồng bộ.
Sau khi tạo thành công mô hình, bạn có thể sử dụng lại mô hình này trên các luồng và cấu hình biên dịch mã (compilation).
Trong NNAPI, một mô hình được biểu thị dưới dạng một phiên bản (instance)
ANeuralNetworksModel. - Cấu hình biên dịch mã: Biểu thị một cấu hình để biên dịch mô hình NNAPI thành
mã cấp thấp hơn. Việc tạo cấu hình biên dịch mã là một phép toán đồng bộ. Sau khi tạo thành công cấu hình biên dịch mã, bạn có thể sử dụng lại cấu hình này trên các luồng và lượt thực thi. Trong
NNAPI, mỗi cấu hình biên dịch mã được biểu thị dưới dạng một phiên bản
ANeuralNetworksCompilation. - Bộ nhớ: Biểu thị bộ nhớ dùng chung, tệp được ánh xạ trong bộ nhớ và các vùng đệm bộ nhớ tương tự. Việc sử dụng vùng đệm bộ nhớ cho phép môi trường thời gian chạy NNAPI truyền dữ liệu tới các trình điều khiển một cách hiệu quả hơn. Ứng dụng thường tạo một vùng đệm bộ nhớ dùng chung
chứa mọi tensor cần thiết để xác định một mô hình. Bạn cũng có thể sử dụng vùng đệm
bộ nhớ để lưu trữ các dữ liệu đầu vào và đầu ra cho một phiên bản thực thi. Trong NNAPI,
mỗi vùng đệm bộ nhớ được biểu thị dưới dạng một phiên bản
ANeuralNetworksMemory. Lượt thực thi: Giao diện để áp dụng một mô hình NNAPI cho một tập hợp các dữ liệu đầu vào và để thu thập kết quả. Lượt thực thi có thể được thực hiện đồng bộ hoặc không đồng bộ.
Đối với lượt thực thi không đồng bộ, nhiều luồng có thể chờ trên cùng một lượt thực thi. Khi lượt thực thi này hoàn tất, tất cả các luồng sẽ được giải phóng.
Trong NNAPI, mỗi lượt thực thi được biểu thị dưới dạng một phiên bản
ANeuralNetworksExecution.
Hình 2 thể hiện quy trình lập trình cơ bản.
Phần còn lại của nội dung này mô tả các bước thiết lập mô hình NNAPI để thực hiện tính toán, biên dịch mô hình và thực thi mô hình đã biên dịch.
Cấp quyền truy cập vào dữ liệu huấn luyện
Các dữ liệu độ lệch và trọng số đã qua huấn luyện của bạn có thể được lưu trữ trong một tệp. Để cung cấp cho môi trường thời gian chạy NNAPI quyền truy cập hiệu quả vào dữ liệu này, hãy tạo một phiên bản ANeuralNetworksMemory bằng cách gọi hàm ANeuralNetworksMemory_createFromFd() và truyền vào đó chỉ số mô tả tệp của tệp dữ liệu đã mở. Bạn cũng chỉ định các cờ bảo vệ bộ nhớ và một vị trí bù trừ (offset) ở nơi vùng bộ nhớ dùng chung bắt đầu trong tệp.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Chúng tôi chỉ sử dụng một phiên bản ANeuralNetworksMemory cho tất cả các trọng số trong ví dụ này, nhưng bạn có thể sử dụng nhiều phiên bản ANeuralNetworksMemory cho nhiều tệp.
Sử dụng vùng đệm phần cứng gốc
Bạn có thể sử dụng vùng đệm phần cứng gốc cho dữ liệu đầu vào, đầu ra và các giá trị toán hạng hằng của mô hình. Trong một số trường hợp nhất định, trình tăng tốc NNAPI có thể truy cập các đối tượng AHardwareBuffer mà không cần trình điều khiển sao chép dữ liệu. AHardwareBuffer có nhiều cấu hình và không phải trình tăng tốc NNAPI nào cũng có thể hỗ trợ tất cả các cấu hình này. Do sự hạn chế này, hãy tham khảo các điều kiện ràng buộc được nêu trong tài liệu tham khảo về ANeuralNetworksMemory_createFromAHardwareBuffer và kiểm thử trước trên các thiết bị mục tiêu để đảm bảo các cấu hình biên dịch mã và lượt thực thi sử dụng AHardwareBuffer hoạt động đúng như dự kiến, sử dụng tính năng chỉ định thiết bị để chỉ định trình tăng tốc.
Để cho phép môi trường thời gian chạy NNAPI truy cập vào một đối tượng AHardwareBuffer, hãy tạo một phiên bản ANeuralNetworksMemory bằng cách gọi hàm ANeuralNetworksMemory_createFromAHardwareBuffer và truyền vào đó đối tượng AHardwareBuffer, như được minh hoạ trong mã mẫu sau:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Khi NNAPI không cần truy cập vào đối tượng AHardwareBuffer nữa, hãy giải phóng
phiên bản ANeuralNetworksMemory tương ứng:
ANeuralNetworksMemory_free(mem2);
Lưu ý:
- Bạn chỉ có thể sử dụng
AHardwareBuffercho toàn bộ vùng đệm chứ không thể dùng với một tham sốARect. - Môi trường thời gian chạy NNAPI sẽ không đẩy dữ liệu vùng đệm. Bạn cần đảm bảo khả năng truy cập vào các vùng đệm đầu vào và đầu ra trước khi lên lịch cho lượt thực thi.
- Không hỗ trợ chỉ số mô tả tệp của hàng rào đồng bộ hoá (sync fence file descriptor).
- Đối với một
AHardwareBuffercó các định dạng và bit sử dụng đặc thù theo nhà cung cấp, bạn sẽ phải phụ thuộc vào phương thức triển khai của nhà cung cấp để xác định xem ứng dụng khách (client) hoặc trình điều khiển có trách nhiệm đẩy dữ liệu bộ nhớ đệm hay không.
Mô hình
Mô hình là đơn vị tính toán cơ bản trong NNAPI. Mỗi mô hình sẽ do một hoặc nhiều toán hạng và phép tính xác định.
Toán hạng
Toán hạng là các đối tượng dữ liệu dùng khi xác định biểu đồ tính toán. Các đối tượng này bao gồm dữ liệu đầu vào và đầu ra của mô hình, các nút trung gian chứa dữ liệu chuyển giữa các phép toán và các hằng số được truyền đến các phép toán này.
Bạn có thể thêm hai loại toán hạng vào mô hình NNAPI: đại lượng vô hướng (scalar) và tensor.
Một đại lượng vô hướng biểu thị một giá trị duy nhất. NNAPI hỗ trợ các giá trị vô hướng ở các định dạng: boolean, dấu phẩy động 16 bit, dấu phẩy động 32 bit, số nguyên 32 bit và số nguyên 32 bit không dấu.
Hầu hết các phép tính trong NNAPI đều liên quan đến các tensor. Tensor là các mảng n chiều (n-dimensional array). NNAPI hỗ trợ tensor ở các định dạng giá trị: dấu phẩy động 16 bit, dấu phẩy động 32 bit, lượng tử hoá (quantized) 8 bit, lượng tử hoá 16 bit, số nguyên 32 bit và boolean 8 bit.
Ví dụ: Hình 3 thể hiện một mô hình có hai phép toán, trước tiên là phép tính cộng và theo sau là phép tính nhân. Mô hình này sẽ sử dụng một tensor đầu vào và tạo ra một tensor đầu ra.
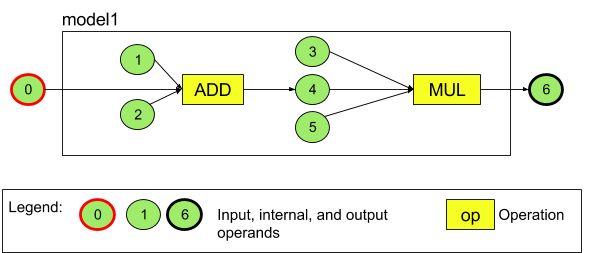
Mô hình trên có 7 toán hạng. Các toán hạng này được xác định ngầm theo chỉ mục tương ứng với thứ tự mà các toán hạng đó được thêm vào mô hình. Toán hạng đầu tiên được thêm có chỉ mục là 0, toán hạng thứ hai có chỉ mục là 1, và cứ thế tiếp tục. Toán hạng 1, 2, 3 và 5 là các toán hạng hằng.
Thứ tự mà thêm toán hạng không quan trọng. Ví dụ: Toán hạng đầu ra của mô hình có thể là toán hạng đầu tiên được thêm. Phần quan trọng là sử dụng giá trị chỉ mục chính xác khi tham chiếu đến toán hạng.
Toán hạng có nhiều loại. Loại toán hạng được chỉ định khi thêm vào mô hình.
Bạn không thể dùng một toán hạng làm cả đầu vào và đầu ra của mô hình.
Mỗi toán hạng phải là một giá trị đầu vào của mô hình, một hằng số hoặc toán hạng đầu ra của đúng một toán tử.
Để biết thêm thông tin về cách sử dụng toán hạng, hãy xem phần Tìm hiểu thêm về toán hạng.
Toán tử
Toán tử sẽ chỉ định các phép tính cần thực hiện. Mỗi toán tử bao gồm các yếu tố sau:
- loại toán tử (ví dụ: cộng, nhân, tích chập),
- danh sách chỉ mục của toán hạng mà toán tử sử dụng cho đầu vào, và
- danh sách chỉ mục của toán hạng mà toán tử sử dụng cho đầu ra.
Thứ tự trong các danh sách này rất quan trọng; hãy xem tài liệu tham khảo API NNAPI để biết dữ liệu đầu vào và đầu ra dự kiến của từng loại toán tử.
Bạn phải thêm toán hạng mà một toán tử sử dụng hoặc tạo ra vào mô hình trước khi thêm toán tử.
Thứ tự thêm toán tử không quan trọng. NNAPI dựa vào các phần phụ thuộc được thiết lập bằng đồ thị tính toán về các toán hạng và toán tử để xác định thứ tự thực hiện toán tử.
Các toán tử mà NNAPI hỗ trợ được tóm tắt trong bảng dưới đây:
Vấn đề đã biết trong API cấp 28: Khi truyền tensor ANEURALNETWORKS_TENSOR_QUANT8_ASYMM vào toán tử ANEURALNETWORKS_PAD, có trên Android 9 (API cấp 28) trở lên, đầu ra từ NNAPI có thể không khớp với đầu ra từ các khung máy học cao cấp hơn, chẳng hạn như TensorFlow Lite. Thay vào đó, bạn chỉ nên truyền ANEURALNETWORKS_TENSOR_FLOAT32.
Vấn đề này đã được giải quyết trong Android 10 (API cấp 29) trở lên.
Xây dựng các mô hình
Trong ví dụ sau, chúng tôi tạo mô hình hai phép toán bạn đã thấy trong hình 3.
Các bước xây dựng mô hình này như sau:
Gọi hàm
ANeuralNetworksModel_create()để xác định một mô hình trống.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Thêm các toán hạng vào mô hình bằng cách gọi
ANeuralNetworks_addOperand(). Các loại dữ liệu của toán hạng được xác định bằng cấu trúc dữ liệuANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Đối với các toán hạng có giá trị hằng số, chẳng hạn như trọng số và độ chệch mà ứng dụng của bạn nhận được từ một quá trình huấn luyện, hãy sử dụng hàm
ANeuralNetworksModel_setOperandValue()vàANeuralNetworksModel_setOperandValueFromMemory().Trong ví dụ sau, chúng tôi thiết lập các giá trị hằng số từ tệp dữ liệu huấn luyện tương ứng với vùng đệm bộ nhớ mà chúng tôi đã tạo trong Cung cấp quyền truy cập vào dữ liệu huấn luyện.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Đối với mỗi toán tử trong biểu đồ định hướng mà bạn muốn tính toán, hãy thêm toán tử đó vào mô hình bằng cách gọi hàm
ANeuralNetworksModel_addOperation().Là tham số cho lệnh gọi này, ứng dụng của bạn phải cung cấp:
- loại toán tử
- số lượng giá trị đầu vào
- mảng chỉ mục cho các toán hạng đầu vào
- số lượng giá trị đầu ra
- mảng chỉ mục cho các toán hạng đầu ra
Lưu ý: Bạn không thể sử dụng một toán hạng cho cả đầu vào và đầu ra của cùng một toán tử.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Hãy xác định các toán hạng mà mô hình sẽ coi là dữ liệu đầu vào và đầu ra bằng cách gọi hàm
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Không bắt buộc: Bạn có thể chỉ định việc có cho phép tính toán
ANEURALNETWORKS_TENSOR_FLOAT32với phạm vi hoặc độ chính xác thấp như của định dạng dấu phẩy động IEEE 754 16 bit hay không bằng cách gọiANeuralNetworksModel_relaxComputationFloat32toFloat16().Hãy gọi
ANeuralNetworksModel_finish()để hoàn tất định nghĩa mô hình. Nếu không có lỗi, hàm này sẽ trả về mã kết quả làANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Sau khi tạo một mô hình, bạn có thể biên dịch mô hình đó với số lần bất kỳ và thực thi từng lần biên dịch với số lần bất kỳ.
Luồng điều khiển
Để kết hợp luồng điều khiển trong mô hình NNAPI, hãy làm như sau:
Dựng các đồ thị con thực thi tương ứng (các đồ thị con
thenvàelsecho một câu lệnhIF, đồ thị conconditionvàbodycho một vòng lặpWHILE) làm mô hìnhANeuralNetworksModel*độc lập:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Tạo toán hạng tham chiếu đến các mô hình đó trong mô hình có chứa luồng điều khiển:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Thêm toán tử luồng điều khiển:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Biên dịch
Bước biên dịch xác định bộ xử lý mà mô hình của bạn sẽ được thực thi và yêu cầu các trình điều khiển tương ứng chuẩn bị cho việc thực thi. Quá trình này có thể bao gồm việc tạo mã máy dành riêng cho các bộ xử lý nơi mô hình của bạn sẽ chạy.
Các bước biên dịch một mô hình như sau:
Gọi hàm
ANeuralNetworksCompilation_create()để tạo một phiên bản biên dịch mới.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Không bắt buộc: Bạn có thể sử dụng tính năng chỉ định thiết bị để lựa chọn rõ ràng những thiết bị nơi quá trình thực thi sẽ diễn ra.
Bạn có thể tuỳ ý tác động đến cách môi trường thời gian chạy cân bằng giữa mức sử dụng pin và tốc độ thực thi. Bạn có thể thực hiện việc này bằng cách gọi
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Các lựa chọn ưu tiên bạn có thể chỉ định bao gồm:
ANEURALNETWORKS_PREFER_LOW_POWER: Ưu tiên thực thi theo cách giảm thiểu mức tiêu hao pin. Đây là điều đáng mong muốn đối với những quá trình biên dịch được thực thi thường xuyên.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Ưu tiên trả về câu trả lời duy nhất nhanh nhất có thể, ngay cả khi tốn nhiều pin hơn. Đây là lựa chọn mặc định.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Ưu tiên tối đa hoá công suất của các khung liên tiếp, chẳng hạn như khi xử lý các khung hình liên tiếp từ máy ảnh/máy quay.
Bạn có thể tuỳ ý thiết lập việc lưu kết quả biên dịch bằng cách gọi
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Sử dụng
getCodeCacheDir()chocacheDir.tokenđược chỉ định phải là duy nhất cho từng mô hình trong ứng dụng.Hãy hoàn tất định nghĩa biên dịch bằng cách gọi
ANeuralNetworksCompilation_finish(). Nếu không có lỗi, hàm này sẽ trả về mã kết quả làANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Khám phá và chỉ định thiết bị
Trên các thiết bị Android chạy Android 10 (API cấp 29) trở lên, NNAPI cung cấp các hàm cho phép các ứng dụng và thư viện của khung máy học có được thông tin về các thiết bị có sẵn và chỉ định các thiết bị sẽ dùng để thực thi. Việc cung cấp thông tin về các thiết bị có sẵn cho phép các ứng dụng biết được phiên bản chính xác của các trình điều khiển có trên thiết bị để tránh các trường hợp không tương thích đã biết. Nhờ được phép chỉ định những thiết bị sẽ thực thi những phần khác nhau của một mô hình, các ứng dụng có thể được tối ưu hoá cho thiết bị Android mà ứng dụng được triển khai.
Khám phá thiết bị
Sử dụng ANeuralNetworks_getDeviceCount để biết số lượng thiết bị có sẵn. Đối với mỗi thiết bị, hãy sử dụng ANeuralNetworks_getDevice để đặt một phiên bản ANeuralNetworksDevice làm tham chiếu đến thiết bị đó.
Khi đã có tham chiếu đến thiết bị, bạn có thể tìm hiểu thêm thông tin về thiết bị đó bằng các hàm sau:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Chỉ định thiết bị
Sử dụng ANeuralNetworksModel_getSupportedOperationsForDevices để khám phá các toán tử của một mô hình có thể chạy trên các thiết bị cụ thể.
Để điều khiển việc dùng những trình tăng tốc nào khi thực thi, hãy gọi ANeuralNetworksCompilation_createForDevices thay vì ANeuralNetworksCompilation_create.
Sử dụng đối tượng ANeuralNetworksCompilation thu được, như bình thường.
Hàm trả về một lỗi nếu mô hình đã cho chứa các toán tử không được thiết bị đã chọn hỗ trợ.
Nếu bạn chỉ định nhiều thiết bị, thì môi trường thời gian chạy sẽ chịu trách nhiệm phân phối công việc giữa các thiết bị đó.
Tương tự các thiết bị khác, quá trình triển khai CPU NNAPI được biểu thị bằng một ANeuralNetworksDevice kèm theo tên nnapi-reference và loại ANEURALNETWORKS_DEVICE_TYPE_CPU. Khi gọi ANeuralNetworksCompilation_createForDevices, quá trình triển khai CPU không được dùng để xử lý các trường hợp lỗi liên quan đến việc biên dịch và thực thi mô hình.
Ứng dụng có trách nhiệm phân chia một mô hình thành các mô hình phụ có thể chạy trên các thiết bị được chỉ định. Các ứng dụng không cần phân chia thủ công nên tiếp tục gọi ANeuralNetworksCompilation_create đơn giản hơn để sử dụng tất cả các thiết bị có sẵn (bao gồm cả CPU) để tăng tốc mô hình. Nếu thiết bị mà bạn chỉ định bằng ANeuralNetworksCompilation_createForDevices không thể hỗ trợ đầy đủ cho mô hình, thì kết quả trả về sẽ là ANEURALNETWORKS_BAD_DATA.
Phân chia mô hình
Khi mô hình có thể sử dụng nhiều thiết bị, môi trường thời gian chạy NNAPI sẽ phân phối công việc giữa các thiết bị đó. Ví dụ: Nếu nhiều thiết bị được cung cấp cho ANeuralNetworksCompilation_createForDevices, tất cả thiết bị được chỉ định sẽ được xem xét khi phân bổ công việc. Lưu ý: Nếu thiết bị CPU không có trong danh sách, quá trình thực thi bằng CPU sẽ bị tắt. Khi sử dụng ANeuralNetworksCompilation_create, tất cả các thiết bị có sẵn sẽ được tính đến, bao gồm cả CPU.
Việc phân phối được thực hiện như sau: đối với mỗi toán tử trong mô hình, thiết bị hỗ trợ toán tử và khai báo hiệu suất tốt nhất sẽ được chọn từ các thiết bị hiện có. Hiệu suất tốt nhất được hiểu là có thời gian thực thi nhanh nhất hoặc mức tiêu thụ năng lượng thấp nhất, tuỳ theo lựa chọn thực thi do ứng dụng chỉ định. Thuật toán phân vùng này không tính đến các yếu tố không hiệu quả có thể xảy ra do IO giữa các bộ xử lý khác nhau. Do đó, khi chỉ định nhiều bộ xử lý (tức là rõ ràng khi sử dụng ANeuralNetworksCompilation_createForDevices hoặc chạy ngầm khi sử dụng ANeuralNetworksCompilation_create) thì bạn cần phân tích tài nguyên của ứng dụng thu được.
Để hiểu cách mô hình được phân chia theo NNAPI, hãy kiểm tra thông báo trong nhật ký Android (ở cấp INFO (thông tin) có thẻ ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name là tên mô tả của toán tử trong đồ thị và device-index là chỉ mục của thiết bị ứng viên trong danh sách thiết bị.
Danh sách này là dữ liệu đầu vào được cung cấp cho ANeuralNetworksCompilation_createForDevices hoặc nếu sử dụng ANeuralNetworksCompilation_createForDevices, thì là danh sách thiết bị được trả về khi lặp lại trên tất cả các thiết bị bằng ANeuralNetworks_getDeviceCount và ANeuralNetworks_getDevice.
Thông báo (ở cấp INFO có thẻ ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Thông báo này cho biết toàn bộ đồ thị đã được tăng tốc trên thiết bị device-name.
Thực thi
Bước thực thi sẽ áp dụng mô hình cho một tập hợp các dữ liệu đầu vào và lưu trữ các kết quả đầu ra của quá trình tính toán trên một hoặc nhiều vùng đệm người dùng hay dung lượng bộ nhớ mà ứng dụng của bạn đã phân bổ.
Để thực thi mô hình đã biên dịch, hãy làm theo các bước sau:
Gọi hàm
ANeuralNetworksExecution_create()để tạo một phiên bản thực thi mới.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Chỉ định nơi ứng dụng đọc giá trị đầu vào để tính toán. Ứng dụng có thể đọc các giá trị đầu vào từ vùng đệm người dùng hoặc dung lượng bộ nhớ được phân bổ bằng cách gọi
ANeuralNetworksExecution_setInput()hoặcANeuralNetworksExecution_setInputFromMemory()tương ứng.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Chỉ định vị trí mà ứng dụng ghi giá trị đầu ra. Ứng dụng có thể ghi các giá trị đầu ra vào vùng đệm người dùng hoặc dung lượng bộ nhớ được phân bổ, bằng cách gọi
ANeuralNetworksExecution_setOutput()hoặcANeuralNetworksExecution_setOutputFromMemory()tương ứng.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Đặt lịch bắt đầu thực thi bằng cách gọi hàm
ANeuralNetworksExecution_startCompute(). Nếu không có lỗi, hàm này sẽ trả về mã kết quả làANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Gọi hàm
ANeuralNetworksEvent_wait()để chờ thực thi xong. Nếu thực thi thành công, hàm này sẽ trả về một mã kết quả làANEURALNETWORKS_NO_ERROR. Chương trình có thể chờ trên một luồng khác với luồng bắt đầu quá trình thực thi.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Bạn có thể tuỳ ý áp dụng một tập hợp dữ liệu đầu vào khác cho mô hình đã biên dịch bằng cách sử dụng cùng một phiên bản biên dịch để tạo một phiên bản
ANeuralNetworksExecutionmới.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Thực thi đồng bộ
Quá trình thực thi không đồng bộ cần thời gian để tạo (spawn) và đồng bộ hoá các chuỗi. Hơn nữa, độ trễ có thể thay đổi rất nhiều, với độ trễ lâu nhất lên tới 500 micrô giây giữa thời điểm luồng được thông báo hoặc đánh thức và thời điểm mà cuối cùng luồng cũng liên kết với lõi CPU.
Để cải thiện độ trễ, bạn có thể lệnh cho một ứng dụng thực hiện lệnh gọi dự đoán đồng bộ đến môi trường thời gian chạy. Lệnh gọi đó sẽ chỉ trả về khi dự đoán xong thay vì trả về sau khi bắt đầu dự đoán. Thay vì gọi ANeuralNetworksExecution_startCompute cho một lệnh gọi dự đoán không đồng bộ đến môi trường thời gian chạy, ứng dụng gọi ANeuralNetworksExecution_compute để thực hiện lệnh gọi đồng bộ đến môi trường thời gian chạy. Lệnh gọi đến ANeuralNetworksExecution_compute không cần đến ANeuralNetworksEvent và không ghép nối với lệnh gọi đến ANeuralNetworksEvent_wait.
Thực thi hàng loạt
Trên các thiết bị Android chạy Android 10 (API cấp 29) trở lên, NNAPI hỗ trợ các quy trình thực thi hàng loạt thông qua đối tượng ANeuralNetworksBurst. Thực thi hàng loạt là một chuỗi quá trình thực thi cùng một hoạt động biên dịch diễn ra liên tiếp và nhanh chóng, chẳng hạn như quá trình thực thi hoạt động trên các khung hình của một lần thu nạp máy ảnh/máy quay hoặc mẫu âm thanh liên tiếp. Việc sử dụng các đối tượng ANeuralNetworksBurst có thể dẫn đến quá trình thực thi nhanh hơn, vì các đối tượng đó chỉ báo cho các trình tăng tốc biết rằng có thể sử dụng lại các tài nguyên giữa các quá trình thực thi và rằng các trình tăng tốc cần duy trì trạng thái hiệu suất cao trong thời gian thực hiện hàng loạt.
ANeuralNetworksBurst chỉ đưa ra một thay đổi nhỏ trên đường dẫn thực thi thông thường. Bạn tạo một đối tượng hàng loạt bằng cách sử dụng ANeuralNetworksBurst_create, như minh hoạ trong đoạn mã sau đây:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Các quá trình thực thi hàng loạt có tính chất đồng bộ. Tuy nhiên, thay vì sử dụng ANeuralNetworksExecution_compute để thực hiện mỗi lần dự đoán, bạn ghép nối nhiều đối tượng ANeuralNetworksExecution khác nhau với cùng một ANeuralNetworksBurst trong các lệnh gọi hàm ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Giải phóng đối tượng ANeuralNetworksBurst bằng ANeuralNetworksBurst_free khi không còn cần đến đối tượng đó.
// Cleanup ANeuralNetworksBurst_free(burst);
Hàng đợi lệnh không đồng bộ và quá trình thực thi có hàng rào
Trên Android 11 trở lên, NNAPI hỗ trợ một cách khác để lên lịch thực thi không đồng bộ thông qua phương thức ANeuralNetworksExecution_startComputeWithDependencies(). Khi bạn sử dụng phương thức này, quá trình thực thi sẽ chờ tất cả các sự kiện phụ thuộc được báo hiệu trước khi bắt đầu đánh giá. Sau khi quá trình thực thi hoàn tất và dữ liệu đầu ra đã sẵn sàng được đưa vào sử dụng, sự kiện trả về sẽ được báo hiệu.
Tuỳ thuộc vào thiết bị xử lý quá trình thực thi, sự kiện có thể được hàng rào đồng bộ hoá hỗ trợ. Bạn phải gọi ANeuralNetworksEvent_wait() để chờ sự kiện và truy hồi các tài nguyên mà quá trình thực thi đã sử dụng. Bạn có thể nhập hàng rào đồng bộ hoá vào một đối tượng sự kiện bằng cách sử dụng ANeuralNetworksEvent_createFromSyncFenceFd(), và có thể xuất hàng rào đồng bộ hoá từ một đối tượng sự kiện bằng cách sử dụng ANeuralNetworksEvent_getSyncFenceFd().
Đầu ra được định kích thước một cách linh hoạt
Để hỗ trợ các mô hình mà kích thước của đầu ra phụ thuộc vào dữ liệu đầu vào, nghĩa là khi không thể xác định kích thước tại thời điểm thực thi mô hình, hãy sử dụng ANeuralNetworksExecution_getOutputOperandRank và ANeuralNetworksExecution_getOutputOperandDimensions.
Mã mẫu sau đây cho biết cách thực hiện việc này:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Dọn dẹp
Bước dọn dẹp xử lý việc giải phóng tài nguyên nội bộ dùng để tính toán.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Quản lý lỗi và dùng CPU làm thiết bị dự phòng
Nếu xảy ra lỗi trong quá trình phân chia, nếu trình điều khiển không thể biên dịch (một phần) mô hình, hoặc nếu trình điều khiển không thể thực thi (một phần) mô hình đã biên dịch, NNAPI có thể quay lại triển khai một hoặc nhiều toán tử bằng chính CPU của mình.
Nếu ứng dụng NNAPI chứa các phiên bản được tối ưu hoá của toán tử (ví dụ: TFLite), thì việc vô hiệu hoá tính năng dùng CPU làm thiết bị dự phòng và xử lý các lỗi khi triển khai toán tử được tối ưu hoá của ứng dụng có thể là một lợi thế.
Trên Android 10, nếu bạn biên dịch bằng ANeuralNetworksCompilation_createForDevices, tính năng dùng CPU làm thiết bị dự phòng sẽ bị tắt.
Trong Android P, quá trình thực thi NNAPI sẽ quay lại sử dụng CPU nếu quá trình thực thi trên trình điều khiển không thành công.
Điều này cũng đúng trên Android 10 khi sử dụng ANeuralNetworksCompilation_create thay vì ANeuralNetworksCompilation_createForDevices.
Lần thực thi đầu tiên sẽ quay lại sử dụng CPU cho một mình phân đoạn đó, và nếu vẫn không thành công thì sẽ thử lại toàn bộ mô hình trên CPU.
Nếu phân chia hoặc biên dịch không thành công, toàn bộ mô hình sẽ được thử trên CPU.
Có những trường hợp một số toán tử không được hỗ trợ trên CPU và khi đó, việc biên dịch hoặc thực thi sẽ không thành công thay vì quay lại sử dụng.
Ngay cả sau khi vô hiệu hoá tính năng dùng CPU làm thiết bị dự phòng, thì có thể vẫn có một số toán tử trong mô hình được lên lịch trên CPU. Nếu CPU nằm trong danh sách các bộ xử lý được cung cấp cho ANeuralNetworksCompilation_createForDevices và là bộ xử lý duy nhất hỗ trợ các toán tử đó hoặc là bộ xử lý có hiệu suất tốt nhất cho các toán tử đó, thì CPU đó sẽ được chọn làm trình thực thi chính (không phải dự phòng).
Để đảm bảo không có quá trình thực thi bằng CPU, hãy sử dụng ANeuralNetworksCompilation_createForDevices trong khi loại trừ nnapi-reference khỏi danh sách thiết bị.
Kể từ Android P, bạn có thể tắt tính năng dự phòng tại thời điểm thực thi trên các bản gỡ lỗi (DEBUG) bằng cách đặt thuộc tính debug.nn.partition thành 2.
Miền bộ nhớ
Trong Android 11 trở lên, NNAPI hỗ trợ các miền bộ nhớ cung cấp giao diện bộ phân bổ (allocator) cho các bộ nhớ mờ (opaque). Điều này cho phép các ứng dụng truyền các bộ nhớ gốc của thiết bị giữa các quá trình thực thi, nhờ đó NNAPI không sao chép hoặc chuyển đổi dữ liệu một cách không cần thiết khi thực hiện các quá trình thực thi liên tiếp trên cùng một trình điều khiển.
Tính năng miền bộ nhớ dành cho các tensor sử dụng chủ yếu trong nội bộ cho trình điều khiển và không cần thường xuyên truy cập vào phía máy khách. Ví dụ về tensor đó bao gồm các tensor trạng thái trong mô hình chuỗi. Đối với các tensor cần truy cập CPU thường xuyên ở phía máy khách, hãy sử dụng các nhóm bộ nhớ dùng chung.
Để phân bổ bộ nhớ mờ, hãy thực hiện các bước sau:
Gọi hàm
ANeuralNetworksMemoryDesc_create()để tạo một chỉ số mô tả bộ nhớ mới:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Hãy chỉ định tất cả các vai trò đầu vào và đầu ra dự kiến bằng cách gọi
ANeuralNetworksMemoryDesc_addInputRole()vàANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Nếu muốn, hãy chỉ định kích thước bộ nhớ bằng cách gọi
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Hoàn tất định nghĩa của chỉ số mô tả bằng cách gọi
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Phân bổ lượng bộ nhớ theo nhu cầu bằng cách truyền chỉ số mô tả cho
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Hãy giải phóng chỉ số mô tả bộ nhớ khi không cần nữa.
ANeuralNetworksMemoryDesc_free(desc);
Ứng dụng chỉ có thể sử dụng đối tượng ANeuralNetworksMemory đã tạo với ANeuralNetworksExecution_setInputFromMemory() hoặc ANeuralNetworksExecution_setOutputFromMemory() theo các vai trò đã chỉ định trong đối tượng ANeuralNetworksMemoryDesc. Đối số chênh lệch và độ dài phải được đặt thành 0, cho biết rằng toàn bộ bộ nhớ sẽ được sử dụng. Ứng dụng cũng có thể đặt hoặc trích xuất nội dung của bộ nhớ một cách rõ ràng bằng cách sử dụng ANeuralNetworksMemory_copy().
Bạn có thể tạo các bộ nhớ mờ với vai trò có các kích thước hoặc thứ hạng không xác định.
Trong trường hợp đó, việc tạo bộ nhớ có thể không thành công với trạng thái ANEURALNETWORKS_OP_FAILED nếu không được trình điều khiển cơ bản hỗ trợ. Ứng dụng nên triển khai logic dự phòng bằng cách phân bổ một vùng đệm đủ lớn do AHardwareBuffer của Ashmem hoặc BLOB-mode hỗ trợ.
Khi NNAPI không còn cần truy cập vào đối tượng bộ nhớ mờ, bạn hãy giải phóng phiên bản ANeuralNetworksMemory tương ứng:
ANeuralNetworksMemory_free(opaqueMem);
Đo lường hiệu suất
Bạn có thể đánh giá hiệu suất của ứng dụng bằng cách đo lường thời gian thực thi hoặc bằng cách phân tích tài nguyên.
Thời gian thực thi
Khi muốn xác định tổng thời gian thực thi thông qua môi trường thời gian chạy, bạn có thể sử dụng API thực thi đồng bộ và đo lường thời gian mà lệnh gọi sử dụng. Khi muốn xác định tổng thời gian thực thi thông qua một cấp độ thấp hơn trong ngăn xếp phần mềm, bạn có thể sử dụng ANeuralNetworksExecution_setMeasureTiming và ANeuralNetworksExecution_getDuration để biết:
- thời gian thực thi trên một trình tăng tốc (không phải trong trình điều khiển chạy trên bộ xử lý máy chủ).
- thời gian thực thi trong trình điều khiển, kể cả thời gian trên trình tăng tốc.
Thời gian thực thi trong trình điều khiển không bao gồm mức hao tổn, chẳng hạn như chính môi trường thời gian chạy và IPC cần thiết để môi trường thời gian chạy giao tiếp với trình điều khiển.
Các API này đo lường khoảng thời gian từ sự kiện gửi công việc đến sự kiện hoàn thành công việc, thay vì thời gian mà trình điều khiển hoặc trình tăng tốc thực hiện dự đoán mà có thể bị gián đoạn do ngữ cảnh chuyển đổi.
Ví dụ: Nếu dự đoán 1 bắt đầu, thì trình điều khiển sẽ dừng công việc để thực hiện dự đoán 2, sau đó tiếp tục và hoàn thành dự đoán 1, thời gian thực thi cho dự đoán 1 sẽ bao gồm thời gian dừng công việc để thực hiện dự đoán 2.
Thông tin về thời gian này có thể hữu ích khi triển khai phiên bản chính thức của ứng dụng để thu thập dữ liệu đo từ xa cho trường hợp sử dụng ngoại tuyến. Bạn có thể sử dụng dữ liệu về thời gian để sửa đổi ứng dụng nhằm đạt được hiệu suất cao hơn.
Khi sử dụng chức năng này, hãy ghi nhớ những điều sau:
- Việc thu thập thông tin về thời gian có thể ảnh hưởng đến hiệu suất.
- Chỉ trình điều khiển mới có thể tính toán thời gian thực thi trong chính trình điều khiển hoặc trên trình tăng tốc, không bao gồm thời gian dùng trong môi trường thời gian chạy NNAPI và IPC.
- Bạn chỉ có thể sử dụng các API này với một
ANeuralNetworksExecutionđược tạo bằngANeuralNetworksCompilation_createForDevicesvớinumDevices = 1. - Việc báo cáo thông tin về thời gian không cần có trình điều khiển.
Phân tích tài nguyên cho ứng dụng của bạn bằng Android Systrace
Bắt đầu từ Android 10, NNAPI sẽ tự động tạo các sự kiện systrace mà bạn có thể sử dụng để phân tích tài nguyên cho ứng dụng.
Nguồn NNAPI đi kèm với một phần mềm tiện ích parse_systrace để xử lý các sự kiện systrace do ứng dụng tạo ra và tạo một chế độ xem theo bảng cho biết thời gian dành cho các giai đoạn khác nhau trong vòng đời của mô hình (Tạo thực thể, Chuẩn bị, Thực thi biên dịch và Chấm dứt) và các lớp (layer) của ứng dụng. Các lớp trong đó ứng dụng của bạn được chia là:
Application: mã xử lý ứng dụng chínhRuntime: Môi trường thời gian chạy NNAPIIPC: Cơ chế giao tiếp liên tiến trình giữa Môi trường thời gian chạy NNAPI và mã Trình điều khiểnDriver: quy trình trình điểu khiển của trình tăng tốc.
Tạo dữ liệu phân tích tài nguyên
Giả sử bạn đã kiểm tra cây nguồn AOSP (Dự án nguồn mở Android) tại $ANDROID_BUILD_TOP và sử dụng ví dụ về phân loại hình ảnh TFLite làm ứng dụng mục tiêu, bạn có thể tạo dữ liệu phân tích tài nguyên của NNAPI bằng các bước sau:
- Khởi động Android systrace bằng lệnh sau:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Tham số -o trace.html cho biết rằng các dấu vết sẽ được ghi trong trace.html. Khi phân tích tài nguyên cho ứng dụng riêng, bạn cần thay thế org.tensorflow.lite.examples.classification bằng tên quy trình được chỉ định trong tệp kê khai ứng dụng.
Thao tác này sẽ khiến một trong các bảng điều khiển (console) shell bận rộn, không chạy lệnh trong nền vì lệnh sẽ chờ (có tính tương tác) một thao tác nhấn enter để chấm dứt.
- Sau khi khởi động bộ thu thập systrace, hãy khởi động ứng dụng và chạy kiểm thử điểm chuẩn.
Trong trường hợp của chúng tôi, bạn có thể khởi động ứng dụng Phân loại hình ảnh từ Android Studio hoặc ngay từ giao diện người dùng điện thoại kiểm thử nếu ứng dụng đã được cài đặt. Để tạo một số dữ liệu NNAPI, bạn cần định cấu hình cho ứng dụng sử dụng NNAPI bằng cách chọn NNAPI làm thiết bị mục tiêu trong hộp thoại cấu hình ứng dụng.
Khi quá trình kiểm thử hoàn tất, hãy chấm dứt systrace bằng cách nhấn
entertrên dòng lệnh của bảng điều khiển (console) đang hoạt động kể từ bước 1.Chạy phần mềm tiện ích
systrace_parsertạo số liệu thống kê tích luỹ:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Trình phân tích cú pháp chấp nhận các tham số sau:
– --total-times: cho biết tổng thời gian đã dùng trong một lớp (layer), bao gồm cả thời gian chờ thực thi trong một lệnh gọi đến một lớp cơ bản
– --print-detail: in tất cả các sự kiện đã được thu thập từ systrace
– --per-execution: chỉ in dữ liệu thực thi và giai đoạn phụ (dưới dạng số lần trong mỗi quá trình thực thi) thay vì số liệu thống kê cho tất cả các giai đoạn
– --json: cho ra kết quả ở định dạng JSON
Dưới đây là ví dụ về dữ liệu đầu ra:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Trình phân tích cú pháp có thể không thành công nếu các sự kiện đã thu thập không phản ánh một dấu vết ứng dụng hoàn chỉnh. Cụ thể, trình phân tích cú pháp có thể không thành công nếu các sự kiện systrace được tạo để đánh dấu sự kết thúc của một phần hiện diện trong dấu vết mà không có một sự kiện bắt đầu phần đi kèm. Việc này thường xảy ra nếu một số sự kiện từ phiên phân tích tài nguyên trước đó được tạo khi bạn khởi động bộ thu thập systrace. Trong trường hợp này, bạn sẽ phải chạy lại quá trình phân tích tài nguyên.
Thêm số liệu thống kê cho mã xử lý ứng dụng vào dữ liệu đầu ra systrace_parser
Ứng dụng parse_systrace dựa trên chức năng systrace tích hợp sẵn của Android. Bạn có thể thêm dấu vết cho các hoạt động cụ thể trong ứng dụng của mình bằng cách sử dụng API systrace (dành cho Java, dành cho các ứng dụng gốc) với tên sự kiện tuỳ chỉnh.
Để liên kết sự kiện tuỳ chỉnh với các giai đoạn trong Vòng đời ứng dụng, hãy thêm một trong các chuỗi sau vào đầu tên sự kiện:
[NN_LA_PI]: Sự kiện cấp ứng dụng để Khởi động[NN_LA_PP]: Sự kiện cấp ứng dụng để Chuẩn bị[NN_LA_PC]: Sự kiện cấp ứng dụng để Biên dịch[NN_LA_PE]: Sự kiện cấp ứng dụng để Thực thi
Dưới đây là ví dụ về cách thay đổi mã ví dụ về phân loại hình ảnh TFLite nhờ thêm phần runInferenceModel cho giai đoạn Execution và lớp Application chứa các phần preprocessBitmap khác sẽ không được xem xét trong dấu vết NNAPI. Phần runInferenceModel sẽ nằm trong các sự kiện systrace do trình phân tích cú pháp nnapi systrace xử lý:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Chất lượng dịch vụ
Trên Android 11 trở lên, NNAPI giúp nâng cao chất lượng dịch vụ (QoS) bằng cách cho phép ứng dụng cho biết các mức độ ưu tiên tương đối của các mô hình, khoảng thời gian tối đa dự kiến cần để chuẩn bị một mô hình nhất định và thời lượng tối đa dự kiến cần để hoàn tất một phép tính nhất định. Android 11 cũng giới thiệu thêm các mã kết quả NNAPI cho phép các ứng dụng hiểu được các lỗi như thời hạn thực thi bị lỡ.
Đặt mức độ ưu tiên trong khối lượng công việc
Để đặt mức độ ưu tiên trong khối lượng công việc của NNAPI, hãy gọi ANeuralNetworksCompilation_setPriority() trước khi gọi ANeuralNetworksCompilation_finish().
Đặt thời hạn
Các ứng dụng có thể đưa ra thời hạn cho cả việc biên dịch mô hình và dự đoán.
- Để đặt thời gian chờ biên dịch, hãy gọi
ANeuralNetworksCompilation_setTimeout()trước khi gọiANeuralNetworksCompilation_finish(). - Để đặt thời gian chờ dự đoán, hãy gọi
ANeuralNetworksExecution_setTimeout()trước khi bắt đầu biên dịch.
Tìm hiểu thêm về toán hạng
Phần sau đây đề cập đến các chủ đề nâng cao về việc sử dụng toán hạng.
Tensor lượng tử hoá
Tensor lượng tử hoá là một cách gọn nhẹ để biểu thị một mảng n chiều (n-dimensional array) của các giá trị dấu phẩy động.
NNAPI hỗ trợ các tensor lượng tử hoá bất đối xứng 8 bit. Đối với các tensor này, giá trị của mỗi ô được biểu thị bằng một số nguyên 8 bit. Đi kèm tensor là một số tỷ lệ và giá trị điểm không. Số tỷ lệ và giá trị điểm không được dùng để chuyển đổi số nguyên 8 bit thành giá trị dấu phẩy động đang được biểu thị.
Công thức như sau:
(cellValue - zeroPoint) * scale
trong đó giá trị zeroPoint là số nguyên 32 bit và số tỷ lệ là giá trị dấu phẩy động 32 bit.
So với tensor của các giá trị dấu phẩy động 32 bit, tensor lượng tử hoá 8 bit có hai ưu điểm:
- Ứng dụng nhỏ hơn vì trọng số được huấn luyện chiếm một phần tư kích thước của tensor 32-bit.
- Việc tính toán thường có thể được thực thi nhanh hơn. Ưu điểm này là nhờ lượng dữ liệu nhỏ hơn cần tìm nạp từ bộ nhớ và tính hiệu quả của các bộ xử lý, chẳng hạn như DSP (Bộ xử lý tín hiệu kỹ thuật số), trong việc thực hiện phép toán số nguyên.
Mặc dù có thể chuyển đổi mô hình dấu phẩy động sang mô hình lượng tử hoá nhưng kinh nghiệm chúng tôi có được cho thấy rằng kết quả tốt hơn là do huấn luyện trực tiếp mô hình lượng tử hoá. Kết quả là mạng nơron sẽ học được cách bù lại mức độ chi tiết cao hơn của mỗi giá trị. Đối với mỗi tensor lượng tử hoá, các giá trị số tỷ lệ và zeroPoint được xác định trong quá trình huấn luyện.
Trong NNAPI, bạn xác định các loại tensor lượng tử hoá bằng cách đặt trường loại của cấu trúc dữ liệu ANeuralNetworksOperandType thành ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
Bạn cũng chỉ định số tỷ lệ và giá trị zeroPoint của tensor trong cấu trúc dữ liệu đó.
Ngoài tensor lượng tử hoá bất đối xứng 8 bit, NNAPI hỗ trợ các tensor sau:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELmà bạn có thể dùng để biểu thị trọng số cho các toán tửCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMmà bạn có thể sử dụng cho trạng thái nội bộ củaQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMMcó thể là dữ liệu đầu vào choANEURALNETWORKS_DEQUANTIZE.
Toán hạng tuỳ chọn
Một vài toán tử, chẳng hạn như ANEURALNETWORKS_LSH_PROJECTION, sẽ áp dụng toán hạng tuỳ chọn. Để chỉ báo trong mô hình rằng toán hạng tuỳ chọn bị bỏ qua, hãy gọi hàm ANeuralNetworksModel_setOperandValue(), truyền NULL cho vùng đệm và 0 cho độ dài.
Nếu quyết định về việc toán hạng hiện diện hay không là khác nhau đối với mỗi quá trình thực thi, bạn sẽ chỉ báo rằng toán hạng bị bỏ qua bằng cách sử dụng hàm ANeuralNetworksExecution_setInput() hoặc ANeuralNetworksExecution_setOutput(), truyền NULL cho vùng đệm và 0 cho độ dài.
Tensor có hạng không xác định
Android 9 (API cấp 28) đã giới thiệu toán hạng mô hình chưa biết chiều nhưng đã biết hạng (số chiều). Android 10 (API cấp 29) giới thiệu các tensor đã biết hạng, như thể hiện trong ANeuralNetworksOperandType.
Điểm chuẩn NNAPI
Điểm chuẩn NNAPI hiện có trên AOSP (Dự án nguồn mở Android) ở platform/test/mlts/benchmark (ứng dụng điểm chuẩn) và platform/test/mlts/models (mô hình và tập dữ liệu).
Điểm chuẩn này đánh giá độ trễ và độ chính xác, đồng thời so sánh các trình điều khiển với cùng một công việc thực hiện bằng Tensorflow Lite chạy trên CPU, cho các mô hình và tập dữ liệu giống nhau.
Để sử dụng điểm chuẩn, hãy làm như sau:
Kết nối thiết bị Android mục tiêu với máy tính, mở cửa sổ dòng lệnh và đảm bảo thiết bị có thể truy cập được qua adb.
Nếu có nhiều thiết bị Android được kết nối, hãy xuất biến môi trường
ANDROID_SERIALcủa thiết bị mục tiêu.Chuyển đến thư mục nguồn cấp cao nhất của Android.
Chạy các lệnh sau:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Khi kết thúc quá trình chạy điểm chuẩn, kết quả sẽ được trình bày dưới dạng một trang HTML được truyền đến
xdg-open.
Nhật ký NNAPI
NNAPI tạo thông tin chẩn đoán hữu ích trong nhật ký hệ thống. Để phân tích nhật ký, hãy sử dụng phần mềm tiện ích logcat.
Bật tính năng ghi nhật ký NNAPI chi tiết cho các giai đoạn hoặc thành phần cụ thể bằng cách đặt thuộc tính debug.nn.vlog (sử dụng adb shell) thành danh sách các giá trị sau (phân tách bằng dấu cách, dấu hai chấm hoặc dấu phẩy):
model: Xây dựng mô hìnhcompilation: Tạo kế hoạch thực thi mô hình và biên dịchexecution: Thực thi mô hìnhcpuexe: Thực thi các toán tử bằng cách triển khai bằng CPU của NNAPImanager: Thông tin liên quan đến các phần mở rộng NNAPI, giao diện có sẵn và khả năngallhoặc1: Tất cả các phần tử ở trên
Ví dụ: Để bật tính năng ghi nhật ký chi tiết đầy đủ, hãy sử dụng lệnh adb shell setprop debug.nn.vlog all. Để tắt tính năng ghi nhật ký chi tiết, hãy sử dụng lệnh adb shell setprop debug.nn.vlog '""'.
Sau khi được bật, tính năng ghi nhật ký chi tiết sẽ tạo các mục nhập nhật ký ở cấp INFO với thẻ được đặt thành tên giai đoạn hoặc tên thành phần.
Ngoài các thông điệp được kiểm soát của debug.nn.vlog, các thành phần NNAPI API còn cung cấp các mục nhập nhật ký khác ở các cấp độ khác nhau, mỗi cấp độ sử dụng một thẻ nhật ký cụ thể.
Để xem danh sách các thành phần, hãy tìm cây nguồn bằng cách sử dụng biểu thức sau:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Biểu thức này hiện trả về các thẻ sau:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Toán tử
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Để kiểm soát cấp độ thông điệp nhật ký do logcat hiển thị, hãy sử dụng biến môi trường ANDROID_LOG_TAGS.
Để hiển thị tập hợp đầy đủ thông điệp nhật ký NNAPI và vô hiệu hoá các thông điệp khác, hãy đặt ANDROID_LOG_TAGS thành các giá trị sau:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Bạn có thể đặt ANDROID_LOG_TAGS bằng lệnh sau đây:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Lưu ý rằng đây chỉ là một bộ lọc áp dụng cho logcat. Bạn vẫn cần đặt thuộc tính debug.nn.vlog thành all để tạo thông tin nhật ký chi tiết.