
Android Neural Networks API(NNAPI)は、Android デバイス上で演算負荷の高い機械学習処理を実行するために設計された Android C API です。NNAPI は、ニューラル ネットワークの構築とトレーニングを行うハイレベルの機械学習フレームワーク(TensorFlow Lite、Caffe2 など)に機能ベースレイヤを提供することを目的としています。この API は Android 8.1(API レベル 27)以上を搭載したすべての Android デバイスで利用できますが、Android 15 で非推奨になりました。
NNAPI は、デベロッパーが定義したトレーニング済みのモデルに Android デバイスのデータを適用することで、推論処理をサポートします。この推論処理には、画像の分類、ユーザー行動の予測、検索クエリに対する最適な回答の選択などが含まれます。
デバイス上で推論を実行することには、次のような多くのメリットがあります。
- レイテンシ: ネットワーク経由でリクエストを送信して応答を待つ必要がありません。これはカメラからの連続フレームを処理する動画アプリにおいて、非常に重要な点です。
- 可用性: ネットワークがつながらない状況でもアプリを実行できます。
- 速度: ニューラル ネットワーク処理に特化した新しいハードウェアによって、汎用 CPU のみを使う場合に比べて計算速度が格段に速くなります。
- プライバシー: データが Android デバイスの外に送信されません。
- 費用: Android デバイス上ですべての計算が実行される場合、サーバー ファームは必要ありません。
デベロッパーが留意すべきデメリットもあります。
- システムの使用率: ニューラル ネットワークの評価時は計算量が多くなるため、電池の消費量が増えます。特に計算が長時間におよぶアプリなどで、この点が懸念される場合は、バッテリー ヘルスをモニタリングすることをおすすめします。
- アプリのサイズ: モデルのサイズに注意してください。モデルは何メガバイトもの容量を占有する場合があります。APK に含まれるモデルの容量が大きく、ユーザーに悪影響がおよぶ可能性がある場合は、アプリのインストール後にモデルをダウンロードする、より小さなモデルを使用する、クラウド上で計算を実行するなどの対策を検討してください。NNAPI には、クラウド内でモデルを実行する機能はありません。
Android Neural Networks API のサンプルで、NNAPI の使用方法の一例をご覧ください。
Neural Networks API ランタイムについて
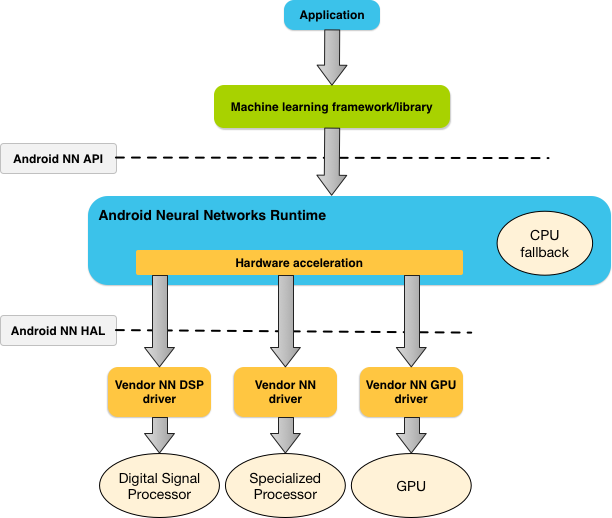
NNAPI は機械学習のライブラリ、フレームワーク、ツール(デベロッパーによるデバイス外でのモデルのトレーニング、Android デバイスへのモデルのデプロイに使用するツール)によって呼び出されることを想定して設計されています。通常、アプリが直接使用するのは NNAPI ではなく、高レベルの機械学習フレームワークです。そのフレームワークが NNAPI を使用することで、ハードウェア アクセラレーションによる推論処理がサポート デバイス上で実行されます。
Android のニューラル ネットワーク ランタイムは、アプリの要件や Android デバイスのハードウェア性能に応じて、そのデバイスで利用可能なプロセッサに効率的に計算負荷を分散させます。具体的には、専用のニューラル ネットワーク ハードウェア、グラフィックス プロセッシング ユニット(GPU)、デジタル シグナル プロセッサ(DSP)などに分散させます。
専用のベンダー ドライバがないデバイスの場合、NNAPI ランタイムは CPU 上でリクエストを実行します。
図 1 に NNAPI の上位レベル システム アーキテクチャを示します。
Neural Networks API プログラミング モデル
NNAPI を使用して計算を実行するには、まずその計算を定義する有向グラフを作成する必要があります。この計算グラフと入力データ(機械学習フレームワークから渡される重みやバイアスなど)とが組み合わされて、NNAPI ランタイム評価のモデルが形成されます。
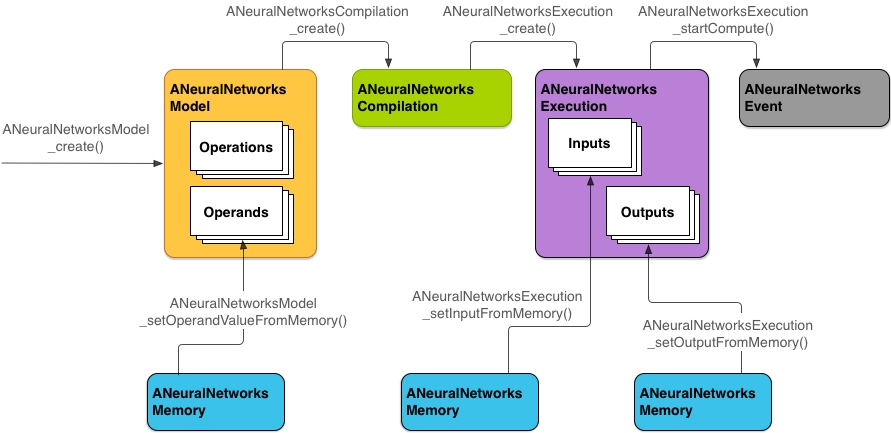
NNAPI には 4 つの主な抽象概念があります。
- モデル: 算術演算の計算グラフと、トレーニング プロセスで学習した定数値です。これらの演算はニューラル ネットワークごとに固有です。たとえば 2 次元(2D)の畳み込み、ロジスティック(シグモイド)活性化関数、正規化線形(ReLU)活性化関数などが含まれます。モデルの作成は同期演算です。
いったん正常に作成できると、さまざまなスレッドやコンパイルで再利用できます。
NNAPI では、モデルは
ANeuralNetworksModelインスタンスとして表されます。 - コンパイル: NNAPI モデルを下位レベルのコードにコンパイルするための設定を表します。コンパイルの作成は同期演算です。いったん正常に作成できると、さまざまなスレッドや実行で再利用できます。NNAPI では、各コンパイルは
ANeuralNetworksCompilationインスタンスとして表されます。 - メモリ: 共有メモリ、メモリマップ ファイル、および同様のメモリバッファを表します。メモリバッファを使うと、NNAPI ランタイムはデータをより効率的にドライバへ転送できます。一般的にアプリは、モデルの定義に必要なテンソルをすべて含む共有メモリバッファを 1 つ作成します。メモリバッファを使用して、実行インスタンスの入出力データを保存することもできます。NNAPI では、各メモリバッファは
ANeuralNetworksMemoryインスタンスとして表されます。 実行: NNAPI モデルを入力データのセットに適用して結果を収集するインターフェースです。実行は同期的にも非同期的にも行えます。
1 件の実行において複数のスレッドが待機できます。この実行が完了すると、すべてのスレッドが解放されます。
NNAPI では、各実行は
ANeuralNetworksExecutionインスタンスとして表されます。
図 2 に基本的なプログラミング フローを示します。
このセクションの残りのパートでは、NNAPI モデルをセットアップして、モデルの計算とコンパイルを行い、コンパイルしたモデルを実行する手順について説明します。
トレーニング データへのアクセスを可能にする
通常、トレーニング済みの重みやバイアスのデータはファイルに保存してあります。このデータに NNAPI ランタイムが効率よくアクセスできるようにするには、ANeuralNetworksMemory インスタンスを作成します。そのためには、ANeuralNetworksMemory_createFromFd() 関数を呼び出して、開いているデータファイルのファイル記述子を渡します。メモリ保護フラグや、ファイル内の共有メモリ領域の開始点となるオフセットも指定します。
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
この例では、すべての重みに対して 1 つの ANeuralNetworksMemory インスタンスのみ使用していますが、複数のファイルの複数の ANeuralNetworksMemory インスタンスを使用することもできます。
ネイティブ ハードウェア バッファを使用する
モデル入力、モデル出力、定数オペランド値に対してネイティブ ハードウェア バッファを使用できます。場合によっては、ドライバでデータをコピーすることなく、NNAPI アクセラレータが AHardwareBuffer オブジェクトにアクセスできます。AHardwareBuffer には多数の設定があり、すべての NNAPI アクセラレータがこれらの設定のすべてをサポートしているわけではありません。この制限があるので、ANeuralNetworksMemory_createFromAHardwareBuffer リファレンス ドキュメントに記載されている制約をご確認ください。さらに、デバイスの割り当てを行ってアクセラレータを指定し、ターゲット デバイスで事前にテストして、AHardwareBuffer を使用するコンパイルと実行が期待どおり動作するかどうかご確認ください。
NNAPI ランタイムが AHardwareBuffer オブジェクトにアクセスできるようにするには、次のコードサンプルに示すように、ANeuralNetworksMemory_createFromAHardwareBuffer 関数を呼び出して AHardwareBuffer オブジェクトを渡し、ANeuralNetworksMemory インスタンスを作成します。
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
NNAPI が AHardwareBuffer オブジェクトにアクセスする必要がなくなったら、対応する ANeuralNetworksMemory インスタンスを解放してください。
ANeuralNetworksMemory_free(mem2);
注:
AHardwareBufferはバッファ全体に対してのみ使用できます。ARectパラメータと併用することはできません。- NNAPI ランタイムはバッファをフラッシュしません。実行をスケジューリングする前に、入力バッファと出力バッファにアクセスできることを確認する必要があります。
- ファイル記述子の sync fence には対応していません。
AHardwareBufferにベンダー固有の形式と使用ビットがある場合、クライアントとドライバのどちらにキャッシュのフラッシュを担わせるかはベンダーの実装次第です。
モデル
NNAPI の計算において、モデルは基本構成要素です。各モデルは 1 つ以上のオペランドと演算で定義されます。
オペランド
オペランドはグラフの定義に使われるデータ オブジェクトです。オペランドには、モデルの入力データと出力データ、ある演算から別の演算に渡されるデータを含む中間ノード、それらの演算に渡される定数が含まれます。
NNAPI モデルに追加できるオペランドのタイプは、「スカラー」と「テンソル」の 2 種類です。
スカラーは単一の値を表します。NNAPI ではスカラー値として、ブール値、16 ビット浮動小数点数、32 ビット浮動小数点数、32 ビット整数、符号なし 32 ビット整数の各形式をサポートしています。
NNAPI での演算の多くには、テンソルが含まれます。テンソルとは N 次元の配列です。 NNAPI では 16 ビット浮動小数点テンソル、32 ビット浮動小数点テンソル、8 ビット量子化テンソル、16 ビット量子化テンソル、32 ビット整数テンソル、8 ビット ブール値テンソルをサポートしています。
たとえば図 3 は、2 つの演算(加算の後に乗算)からなるモデルを表しています。このモデルは 1 つの入力テンソルを取り込み、1 つの出力テンソルを算出します。
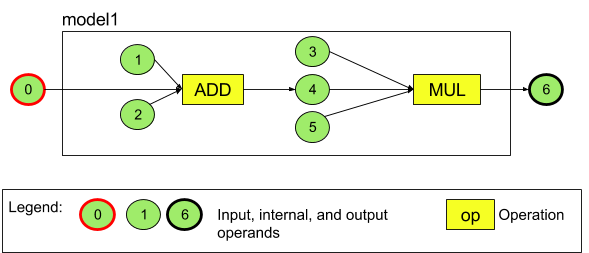
上記のモデルには 7 つのオペランドがあります。これらのオペランドは、モデルに追加する順番を示したインデックスにより、間接的に特定されます。最初に追加するオペランドのインデックスは 0、2 番目のオペランドのインデックスは 1 となり、それ以降も同様にインデックスが付けられます。オペランド 1、2、3、5 は定数オペランドです。
オペランドを追加する順序に意味はありません。たとえば、モデルの出力オペランドを最初に追加してもかまいません。重要なのは、オペランドを参照するときに正しいインデックスを使用することです。
オペランドにはタイプがあり、モデルに追加されるときに指定されます。
1 つのオペランドをモデルの入力と出力の両方に使用することはできません。
どのオペランドも、モデル入力、定数、1 つの演算の出力オペランドのいずれかです。
オペランドの使用方法について詳しくは、オペランドの詳細をご覧ください。
演算
演算は実行する計算を指定するもので、次の 3 つの要素で構成されます。
- 演算タイプ(加算、乗算、畳み込みなど)
- 演算の入力に使用するオペランドのインデックス リスト
- 演算の出力に使用するオペランドのインデックス リスト
これらのリスト内の順番には意味があります。各演算タイプで想定される入力と出力については、NNAPI API リファレンスをご覧ください。
演算を追加する前に、演算で使用または生成するオペランドをモデルに追加する必要があります。
演算の追加順には意味がありません。NNAPI は、オペランドと演算の計算グラフに規定された依存関係に基づいて演算の実行順序を決定します。
下記の表に、NNAPI がサポートする演算をまとめます。
API レベル 28 での既知の問題: ANEURALNETWORKS_TENSOR_QUANT8_ASYMM テンソルを ANEURALNETWORKS_PAD 演算(Android 9、API レベル 28 以上で利用可能)に渡す場合、NNAPI を使用した場合の出力と、それより上位の機械学習フレームワーク(TensorFlow Lite など)を使用した場合の出力が一致しない場合があります。代わりに ANEURALNETWORKS_TENSOR_FLOAT32 のみを渡す必要があります。この問題は、Android 10(API レベル 29)以上で解決されています。
モデルの作成
以下の例では、図 3 に示した 2 つの演算を含むモデルを作成します。
モデルの作成手順は次のとおりです。
ANeuralNetworksModel_create()関数を呼び出して空のモデルを定義します。ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
ANeuralNetworks_addOperand()を呼び出して、オペランドをモデルに追加します。オペランドのデータタイプは、ANeuralNetworksOperandTypeデータ構造を使用して定義します。// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6トレーニング プロセスでアプリが取得する重みやバイアスなどの定数を含むオペランドには、
ANeuralNetworksModel_setOperandValue()関数とANeuralNetworksModel_setOperandValueFromMemory()関数を使用します。以下の例では、トレーニング データへのアクセスを可能にするセクションで作成したメモリバッファに対応するトレーニング データ ファイルにある定数値を設定します。
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));計算する有向グラフ内の各演算について、
ANeuralNetworksModel_addOperation()関数を呼び出してその演算をモデルに追加します。この呼び出しの際に、アプリは次のパラメータを指定する必要があります。
- 演算タイプ
- 入力値の総数
- 入力オペランドのインデックス配列
- 出力値の総数
- 出力オペランドのインデックス配列
1 つのオペランドを同じ演算の入力と出力の両方に使用することはできません。
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);ANeuralNetworksModel_identifyInputsAndOutputs()関数を呼び出して、モデルで入力データとして扱うオペランドと出力データとして扱うオペランドを指定します。// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
必要に応じて
ANeuralNetworksModel_relaxComputationFloat32toFloat16()を呼び出し、IEEE 754 16 ビット浮動小数点形式と同程度の範囲あるいは精度でANEURALNETWORKS_TENSOR_FLOAT32を計算することが許容されるかどうかを指定します。ANeuralNetworksModel_finish()を呼び出して、モデルの定義を確定します。エラーがなければ、この関数は結果コードANEURALNETWORKS_NO_ERRORを返します。ANeuralNetworksModel_finish(model);
作成したモデルは何度でもコンパイルでき、コンパイルしたモデルは何度でも実行できます。
制御フロー
NNAPI モデルに制御フローを組み込む手順は次のとおりです。
対応する実行サブグラフ(
IFステートメントのthenおよびelseサブグラフ、WHILEループのconditionとbodyサブグラフ)をスタンドアロンのANeuralNetworksModel*モデルとして以下のように構築します。ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
コントロール フローを含むモデルで、これらのモデルを参照するオペランドを作成します。
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
コントロール フロー オペレーションを追加します。
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
コンパイル
コンパイルの手順では、モデルを実行するプロセッサを決定し、対応するドライバで実行の準備をします。この手順には、モデルを実行するプロセッサに固有のマシンコードの生成が含まれる場合があります。
モデルをコンパイルする手順は次のとおりです。
ANeuralNetworksCompilation_create()関数を呼び出して、コンパイル インスタンスを新規作成します。// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
必要に応じて、デバイスの割り当てを行って、どのデバイスで実行するかを明示的に選択できます。
必要に応じて、ランタイムに電池消費量の節約と実行速度のどちらを優先するかを指定できます。指定するには
ANeuralNetworksCompilation_setPreference()を呼び出します。// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
以下の設定を指定できます。
ANEURALNETWORKS_PREFER_LOW_POWER: 電池の消耗を最小限に抑えて実行することを優先します。実行頻度の高いコンパイルにはこの設定をおすすめします。ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: 電池を多く消費しても、最速で単一の回答を返すことを優先します。これがデフォルトです。ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: 連続フレームのスループットを最大にすることを優先します(カメラから送られる連続フレームを処理する場合など)。
必要に応じて、
ANeuralNetworksCompilation_setCachingを呼び出してコンパイルのキャッシュへの保存をセットアップできます。// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
cacheDirにはgetCodeCacheDir()を使用します。指定するtokenは、アプリ内の各モデルに固有である必要があります。ANeuralNetworksCompilation_finish()を呼び出してコンパイルの定義を完了します。エラーがなければ、この関数は結果コードANEURALNETWORKS_NO_ERRORを返します。ANeuralNetworksCompilation_finish(compilation);
デバイスの検出と割り当て
Android 10(API レベル 29)以降を搭載した Android デバイスでは、機械学習フレームワーク ライブラリとアプリで NNAPI の関数を使うことにより、使用可能なデバイスに関する情報を取得して、実行に使用するデバイスを指定できます。アプリは、使用可能なデバイスに関する情報を得ることにより、デバイスで見つかったドライバの正確なバージョンから、既知の非互換性の問題を回避できるようになります。アプリは、実行するデバイスをモデルのセクションごとに指定できるようになるため、デプロイする Android デバイス用に最適化できます。
デバイス検出
ANeuralNetworks_getDeviceCount を使用して使用可能なデバイスの数を取得します。各デバイスに対して、ANeuralNetworks_getDevice を使用して、ANeuralNetworksDevice インスタンスをそのデバイスへの参照に設定します。
デバイス参照を取得したら、次の関数を使用してそのデバイスに関する追加情報を入手できます。
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
デバイス割り当て
ANeuralNetworksModel_getSupportedOperationsForDevices を使用して、特定のデバイスで実行できるモデルの演算を調べます。
実行に使用するアクセラレータを制御するには、ANeuralNetworksCompilation_create の代わりに、ANeuralNetworksCompilation_createForDevices を呼び出します。結果の ANeuralNetworksCompilation オブジェクトを通常どおり使用します。
指定されたモデルが選択されたデバイスでサポートされていない演算を含んでいる場合、この関数はエラーを返します。
複数のデバイスが指定されている場合、デバイス間で処理を分散する責任はランタイムにあります。
他のデバイスと同様に、NNAPI CPU 実装は、名前が nnapi-reference でタイプが ANEURALNETWORKS_DEVICE_TYPE_CPU の ANeuralNetworksDevice で表されます。ANeuralNetworksCompilation_createForDevices を呼び出すとき、モデルのコンパイルと実行が失敗した場合の処理に CPU 実装は使用されません。
モデルを特定のデバイスで実行できるようにサブモデルにパーティショニングするのはアプリの責任です。手動のパーティショニングが不要なアプリは、引き続きより単純な ANeuralNetworksCompilation_create を呼び出し、使用可能なすべてのデバイス(CPU を含む)を使ってモデルのアクセラレーションを行う必要があります。ANeuralNetworksCompilation_createForDevices を使用して指定したデバイスがモデルを十分にサポートできない場合、ANEURALNETWORKS_BAD_DATA が返されます。
モデルのパーティショニング
モデルに複数のデバイスを使用できる場合、NNAPI ランタイムはその複数のデバイスに作業を分散します。たとえば、複数のデバイスが ANeuralNetworksCompilation_createForDevices に指定された場合、作業の割り当て対象はそれら指定デバイスすべてになります。CPU デバイスがそのリストにない場合、CPU の実行は無効になります。ANeuralNetworksCompilation_create を使用する場合は、CPU など、使用可能なすべてのデバイスが対象になります。
この分散は、使用可能なデバイスのリストから、モデル内の演算ごとに、デバイスを選択することによって行われます。選択されるのは、その演算をサポートし、最高のパフォーマンスを宣言しているデバイスです。ここでの「最高のパフォーマンス」とは、最短の実行時間または最小の電池消費量(クライアントが指定した実行の優先設定に応じて決まる)を指します。このパーティショニング アルゴリズムでは、異なるプロセッサ間での入出力によって生じる可能性のある非効率は考慮されません。そのため、複数のプロセッサを指定する(ANeuralNetworksCompilation_createForDevices を使って明示するか、ANeuralNetworksCompilation_create を使って暗黙的に指定する)場合、最終的なアプリの特性を明確にすることが重要です。
NNAPI でモデルがどのようにパーティショニングされたかを把握するには、Android のログでメッセージ(タグ ExecutionPlan の付いた情報レベルのメッセージ)をご確認ください。
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name はグラフ内での演算を説明する名前であり、device-index はデバイスリストにある候補のデバイスのインデックスです。このデバイスリストは、ANeuralNetworksCompilation_createForDevices に指定する入力であり、ANeuralNetworksCompilation_createForDevices を使用する場合は、ANeuralNetworks_getDeviceCount と ANeuralNetworks_getDevice を使ってすべてのデバイスについて繰り返して返されるデバイスのリストです。
メッセージ(タグ ExecutionPlan の付いた情報レベルのメッセージ)の例:
ModelBuilder::partitionTheWork: only one best device: device-name
このメッセージは、デバイス device-name 上でグラフ全体にアクセラレーションを行ったことを示しています。
実行
実行の手順では、モデルを入力データのセットに適用し、計算結果を 1 つ以上のユーザー バッファまたはアプリが割り当てたメモリ領域に保存します。
コンパイル済みのモデルを実行する手順は次のとおりです。
ANeuralNetworksExecution_create()関数を呼び出して、実行インスタンスを新規作成します。// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
計算の入力値をアプリが読み取る場所を指定します。アプリは、
ANeuralNetworksExecution_setInput()またはANeuralNetworksExecution_setInputFromMemory()を呼び出すことによって、それぞれユーザー バッファまたは割り当てられたメモリ領域から入力値を読み取ることができます。// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
出力値をアプリが書き出す場所を指定します。アプリは、
ANeuralNetworksExecution_setOutput()またはANeuralNetworksExecution_setOutputFromMemory()を呼び出すことによって、それぞれユーザー バッファまたは割り当てられたメモリ領域に出力値を書き出すことができます。// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
ANeuralNetworksExecution_startCompute()関数を呼び出して、実行を開始するようにスケジューリングします。エラーがなければ、この関数は結果コードANEURALNETWORKS_NO_ERRORを返します。// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
ANeuralNetworksEvent_wait()関数を呼び出して、実行が完了するのを待ちます。実行が正常に完了すると、この関数は結果コードANEURALNETWORKS_NO_ERRORを返します。実行を開始したスレッドとは別のスレッドで完了を待つことができます。// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
必要であれば、同じコンパイル インスタンスを使用して
ANeuralNetworksExecutionインスタンスを新規作成し、コンパイル済みモデルに異なる入力セットを適用できます。// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
同期実行
非同期実行では、スレッドの生成と同期に時間がかかります。 さらに、レイテンシに非常に大きなばらつきが生じる可能性があり、スレッドが通知または起動されてから最終的に CPU コアにバインドされるまでに最長 500 マイクロ秒かかる場合があります。
遅延を改善するため、ランタイムへの同期推論呼び出しを行うように、アプリに指示できます。この呼び出しは、推論の開始時ではなく、完了時にだけ戻ります。ランタイムへの非同期推論呼び出しのために ANeuralNetworksExecution_startCompute を呼び出す代わりに、アプリは ANeuralNetworksExecution_compute を呼び出してランタイムへの同期呼び出しを行います。ANeuralNetworksExecution_compute への呼び出しは ANeuralNetworksEvent を受け取らず、ANeuralNetworksEvent_wait への呼び出しと対になりません。
バースト実行
Android 10(API レベル 29)以上を搭載する Android デバイスで、NNAPI は ANeuralNetworksBurst オブジェクトを介したバースト実行をサポートしています。バースト実行とは、カメラ キャプチャのフレームや連続するオーディオ サンプルなど、同じコンパイルが途切れずに発生する実行シーケンスです。ANeuralNetworksBurst オブジェクトは、実行をまたいでリソースを再利用できることと、バースト中に高パフォーマンス状態を維持する必要があることをアクセラレータに伝えます。そのため、このオブジェクトを使用すると実行が高速になる可能性があります。
ANeuralNetworksBurst では、通常の実行パスを少し変更するだけです。次のコード スニペットに示すように、ANeuralNetworksBurst_create を使用してバースト オブジェクトを作成します。
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
バースト実行は同期します。ただし、ANeuralNetworksExecution_compute を使用して各推論を実行する代わりに、ANeuralNetworksExecution_burstCompute 関数への呼び出しの中でさまざまな ANeuralNetworksExecution オブジェクトを同じ ANeuralNetworksBurst と対にします。
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
ANeuralNetworksBurst オブジェクトが不要になったら、ANeuralNetworksBurst_free を使って解放します。
// Cleanup ANeuralNetworksBurst_free(burst);
非同期のコマンドキューとフェンスを使用した実行
Android 11 以上では、NNAPI は ANeuralNetworksExecution_startComputeWithDependencies() メソッドにより、非同期実行をスケジュールする追加の方法をサポートしています。このメソッドを使用すると、依存するすべてのイベントが通知されるまで実行を待機してから、評価を開始します。実行が完了し、出力の準備ができたら、イベントが返されたことが通知されます。
実行デバイスの種類によっては、イベントが同期フェンスによってバックアップされる場合があります。ANeuralNetworksEvent_wait() を呼び出してイベントを待ち、実行したリソースを回復する必要があります。ANeuralNetworksEvent_createFromSyncFenceFd() を使用して、同期フェンスをイベント オブジェクトにインポートできます。また、ANeuralNetworksEvent_getSyncFenceFd() を使用して、イベント オブジェクトから同期フェンスをエクスポートできます。
動的にサイズ変更される出力
出力のサイズが入力データに依存するモデル、つまり、サイズがモデルの実行時に決定できないモデルをサポートするには、ANeuralNetworksExecution_getOutputOperandRank と ANeuralNetworksExecution_getOutputOperandDimensions を使用します。
次のコードサンプルは、これを行う方法を示しています。
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
クリーンアップ
クリーンアップのステップでは、計算に使用した内部リソースを解放します。
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
エラー管理と CPU のフォールバック
パーティショニング中にエラーが発生した場合、ドライバがモデル(の一部)のコンパイルに失敗した場合、またはドライバがコンパイルされたモデル(の一部)の実行に失敗した場合、NNAPI は自身の演算の CPU 実装にフォールバックすることがあります。
NNAPI クライアントに演算の最適化されたバージョン(たとえば TFLite)がある場合、CPU のフォールバックを無効にして、クライアントの最適化演算の実装でエラーを処理するほうがよい可能性があります。
Android 10 では、ANeuralNetworksCompilation_createForDevices を使用してコンパイルされるので、CPU フォールバックは無効になります。
Android P では、ドライバでの実行が失敗した場合、NNAPI の実行は CPU にフォールバックします。
ANeuralNetworksCompilation_createForDevices ではなく、ANeuralNetworksCompilation_create が使用される場合、これは Android 10 でも同様です。
最初の実行は、その単一のパーティションについてフォールバックし、それも失敗する場合は、CPU でモデル全体が再試行されます。
パーティショニングまたはコンパイルが失敗すると、CPU でモデル全体が再試行されます。
一部の演算が CPU でサポートされていない場合は、コンパイルや実行はフォールバックではなく、失敗となります。
CPU フォールバックを無効にした後も、CPU でスケジューリングされる演算がモデルに残っていることがあります。CPU が ANeuralNetworksCompilation_createForDevices に供給されるプロセッサのリストに含まれており、それらの演算をサポートする唯一のプロセッサであるか、それらの演算に対して最適なパフォーマンスを提示するプロセッサである場合、その CPU がプライマリの(フォールバックではない)実行 CPU として選択されます。
CPU での実行が発生するのを確実に防ぐには、ANeuralNetworksCompilation_createForDevices を使用し、なおかつデバイスのリストから nnapi-reference を除外します。Android P 以降は、デバッグビルドでの実行時のフォールバックを無効にすることが可能であり、それには debug.nn.partition プロパティを 2 に設定します。
メモリドメイン
Android 11 以降では、NNAPI は不透明なメモリ用のアロケータ インターフェースを提供するメモリドメインをサポートしています。これを使用すると、アプリケーションは実行間でデバイスのネイティブ メモリを受け渡しできるようになり、同じドライバでの連続した実行間で NNAPI が不要にデータをコピーまたは変換しないようにできます。
メモリドメイン機能は、主にクライアント側への頻繁なアクセスを必要としないドライバ内部のテンソル向けです。このようなテンソルの例には、シーケンス モデル内の状態テンソルがあります。クライアント側での CPU アクセスを頻繁に必要とするテンソルの場合は、代わりに共有メモリプールを使用します。
不透明メモリを割り当てるには、次の手順に従います。
ANeuralNetworksMemoryDesc_create()関数を呼び出して、新しいメモリ記述子を作成します。// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
ANeuralNetworksMemoryDesc_addInputRole()とANeuralNetworksMemoryDesc_addOutputRole()を呼び出して、すべての入力ロールと出力ロールを指定します。// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
必要に応じて、
ANeuralNetworksMemoryDesc_setDimensions()を呼び出してメモリの寸法を指定します。// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
ANeuralNetworksMemoryDesc_finish()を呼び出して、記述子の定義を完了します。ANeuralNetworksMemoryDesc_finish(desc);
記述子を
ANeuralNetworksMemory_createFromDesc()に渡して、必要なだけメモリを割り当てます。// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
不要になったメモリ記述子を解放します。
ANeuralNetworksMemoryDesc_free(desc);
クライアントは、ANeuralNetworksMemoryDesc オブジェクトで指定されたロールに従って、ANeuralNetworksExecution_setInputFromMemory() または ANeuralNetworksExecution_setOutputFromMemory() を使用して作成された ANeuralNetworksMemory オブジェクトのみを使用できます。offset 引数と length 引数を 0 に設定して、メモリ全体が使用されていることを示す必要があります。また、クライアントは ANeuralNetworksMemory_copy() を使用してメモリの内容を明示的に設定または抽出することもできます。
不特定の要素またはランクのロールを持つ不透明なメモリを作成できます。この場合、基盤となるドライバでサポートされていない場合、メモリの作成は ANEURALNETWORKS_OP_FAILED ステータスで失敗することがあります。Ashmem または BLOB モードの AHardwareBuffer に基づく十分なバッファを割り当てて、クライアントにフォールバック ロジックを実装することをおすすめします。
NNAPI が不透明なメモリ オブジェクトにアクセスする必要がなくなったら、対応する ANeuralNetworksMemory インスタンスを解放します。
ANeuralNetworksMemory_free(opaqueMem);
パフォーマンスの測定
アプリのパフォーマンスを評価するには、実行時間を測定するか、プロファイリングを行います。
実行時間
ランタイム全体を通した合計実行時間を調べるには、同期実行 API を使用して、呼び出しにかかった時間を測定します。下位レベルのソフトウェア スタック全体の合計実行時間を調べるには、ANeuralNetworksExecution_setMeasureTiming と ANeuralNetworksExecution_getDuration を使用して以下を取得します。
- アクセラレータでの実行時間(ホスト プロセッサで実行されるドライバでの時間は含まない)
- ドライバでの実行時間(アクセラレータでの時間を含む)
ドライバでの実行時間には、ランタイム自体のオーバーヘッドや、ランタイムがドライバと通信するために必要な IPC のオーバーヘッドなどは含まれません。
これらの API は、処理の送信から完了までの時間を測定します。これは、ドライバまたはアクセラレータが推論を実行していた時間だけを測定すると、コンテキストの切り替えによって阻害される可能性があるためです。
たとえば、推論 1 が始まってから、ドライバが推論 2 を実行するために処理を停止して、その後で推論 1 を再開して完了した場合、推論 1 の実行時間には、推論 2 を実行するために処理が停止していた時間が含まれます。
このタイミング情報は、オフラインでの使用のためにテレメトリーを収集するアプリケーションを本番環境にデプロイするときに役立つ場合があります。タイミング データを使用して、アプリにパフォーマンス改善のための修正を加えることが可能です。
この機能を使用する際は、以下にご注意ださい。
- タイミング情報の収集によってパフォーマンスが低下することがあります。
- NNAPI ランタイムと IPC にかかった時間を除いて、ドライバ自身あるいはアクセラレータでかかった時間を算出できるのは、ドライバだけです。
- この API で使用できるのは、
numDevices = 1としてANeuralNetworksCompilation_createForDevicesで作成されたANeuralNetworksExecutionだけです。 - 時間情報をレポートするためにドライバは必要ありません。
Android Systrace を使用してアプリをプロファイリングする
Android 10 以降では、NNAPI によって自動的に systrace イベントが生成され、これを使用してアプリをプロファイリングできます。
NNAPI ソースに付属している parse_systrace ユーティリティは、アプリによって生成された systrace イベントを処理し、モデル ライフサイクルの各フェーズ(インスタンス化、準備、コンパイル実行、終了)とアプリの各レイヤで費やされた時間を示す表形式のビューを生成します。アプリは次のレイヤに分割されます。
Application: メインのアプリコードRuntime: NNAPI ランタイムIPC: NNAPI ランタイムとドライバコード間のプロセス間通信Driver: アクセラレータ ドライバ プロセス
プロファイリング分析データを生成する
$ANDROID_BUILD_TOP で AOSP ソースツリーをチェックアウトし、ターゲット アプリとしてTFLite 画像分類サンプルを使用する場合、次の手順で NNAPI プロファイリング データを生成できます。
- 次のコマンドで Android systrace を起動します。
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
-o trace.html パラメータは、トレースが trace.html に書き込まれることを示します。実際のアプリをプロファイリングする場合は、org.tensorflow.lite.examples.classification をアプリ マニフェストで指定したプロセス名に置き換えてください。
これにより、いずれかのシェル コンソールがビジー状態になります。終了時に enter を押すことを求められるので、コマンドをバックグラウンドで実行しないでください。
- systrace コレクタが開始されたら、アプリを起動してベンチマーク テストを実行します。
この例では、Android Studio から、またはアプリがすでにインストールされている場合はテスト用のスマートフォン向け UI から直接に、画像分類アプリを起動できます。 一部の NNAPI データを生成するには、アプリが NNAPI を使用するように設定するために、アプリ設定ダイアログで NNAPI をターゲット デバイスとして選択する必要があります。
テストが完了したら、ステップ 1 でアクティブになったコンソール ターミナルで
enterを押して systrace を終了します。systrace_parserユーティリティを実行して累積統計を生成します。
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
パーサーが受け取るパラメータは次のとおりです。--total-times: レイヤで費やされた合計時間(基礎となるレイヤへの呼び出しでの実行待機時間を含む)を表示します。--print-detail: systrace で収集されたすべてのイベントを出力します。--per-execution: すべてのフェーズの統計情報ではなく、実行とそのサブフェーズ(実行時間ごと)のみを出力します。--json: JSON 形式で出力を生成します。
出力の例を以下に示します。
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
収集されたイベントが完全なアプリトレースを表していない場合、パーサーが失敗する可能性があります。失敗が特に多いのは、セクションの終了を示すために生成された systrace イベントがトレース内に存在するにもかかわらず、関連するセクション開始イベントがない場合です。これは、通常、systrace コレクタを起動したときに、前回のプロファイリング セッションのイベントの一部が生成中である場合に発生します。 この場合、プロファイリングを再度実行する必要があります。
アプリコードの統計情報を systrace_parser の出力に追加する
parse_systrace アプリは、組み込みの Android systrace 機能をベースにしています。カスタム イベント名に systrace API(Java 用、ネイティブ アプリ用)を使用して、アプリ内の特定のオペレーションのトレースを追加できます。
カスタム イベントをアプリ ライフサイクルのフェーズに関連付けるには、イベント名の前に次のいずれかの文字列を付加します。
[NN_LA_PI]: アプリレベルの初期化イベント[NN_LA_PP]: アプリレベルの準備イベント[NN_LA_PC]: アプリレベルのコンパイル イベント[NN_LA_PE]: アプリレベルの実行イベント
TFLite 画像分類サンプルのコードを変更して、Execution フェーズの runInferenceModel セクションと、NNAPI トレースでは考慮されない別のセクションである preprocessBitmap を含む Application レイヤを追加する方法の例を次に示します。runInferenceModel セクションは、NNAPI systrace パーサーによって処理される systrace イベントの一部になります。
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
サービス品質
Android 11 以降の NNAPI では、モデルの相対的な優先度、モデルの準備に要することが想定される最大時間、実行の完了までにかかると想定される最大時間をアプリが示すようにすることで、サービス品質(QoS)を改善しています。また、Android 11 では、NNAPI 結果コードが追加されています。これは、実行期限の遅れなどのエラーを理解できるようにするものです。
ワークロードの優先度を設定する
NNAPI ワークロードの優先度を設定するには、ANeuralNetworksCompilation_setPriority()、ANeuralNetworksCompilation_finish() の順に呼び出します。
期限の設定
アプリケーションでは、モデルのコンパイルと推論の両方の期限を設定できます。
- コンパイルのタイムアウトを設定するには、
ANeuralNetworksCompilation_finish()を呼び出す前にANeuralNetworksCompilation_setTimeout()を呼び出します。 - 推論タイムアウトを設定するには、コンパイルの開始前に
ANeuralNetworksExecution_setTimeout()を呼び出します。
オペランドの詳細
以下のセクションでは、オペランドの使用に関する高度なトピックを扱います。
量子化テンソル
量子化テンソルは、浮動小数点数値の N 次元配列を簡潔に表現する方法です。
NNAPI は 8 ビットの非対称な量子化テンソルをサポートします。このテンソルでは、各セルの値は 8 ビットの整数で表現されます。テンソルと関連づけられているのがスケールと零点値で、これらは 8 ビットの整数を浮動小数点数値に変換して表現するために使用されます。
式は次のとおりです。
(cellValue - zeroPoint) * scale
ここで、zeroPoint 値は 32 ビット整数で、scale は 32 ビット浮動小数点数値です。
32 ビット浮動小数点数値のテンソルと比較して、8 ビットの量子化テンソルには次の 2 つのメリットがあります。
- トレーニング済みの重みのサイズが 32 ビットテンソルの 4 分の 1 になるので、アプリケーションのサイズが小さくなります。
- 一般的に計算の実行速度が上がります。これは、メモリから取得する必要があるデータ量が減り、整数値の計算中に DSP などのプロセッサ効率が上がるためです。
浮動小数点数モデルを量子化モデルに変換することは可能ですが、量子化モデルを直接トレーニングしたほうが良い結果が得られることがこれまでの経験からわかっています。実際にニューラル ネットワークは、各値の粒度の粗さを補うように学習します。各量子化テンソルの scale と zeroPoint 値はトレーニング プロセスで決定されます。
NNAPI では、ANeuralNetworksOperandType データ構造のタイプ フィールドを ANEURALNETWORKS_TENSOR_QUANT8_ASYMM に設定することで、量子化テンソルのタイプを定義します。そのデータ構造内でテンソルの scale と zeroPoint 値も指定できます。
NNAPI は、8 ビットの非対称な量子化テンソルに加えて、次をサポートします。
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL:CONV/DEPTHWISE_CONV/TRANSPOSED_CONV演算に対する重みを表すために使用します。ANEURALNETWORKS_TENSOR_QUANT16_ASYMM:QUANTIZED_16BIT_LSTMの内部状態を表すために使用します。ANEURALNETWORKS_TENSOR_QUANT8_SYMM:ANEURALNETWORKS_DEQUANTIZEへの入力として使用できます。
オプションのオペランド
ANEURALNETWORKS_LSH_PROJECTION のようないくつかの演算は、オプションのオペランドを取ります。モデル内でオプションのオペランドが省略されていることを示すには、ANeuralNetworksModel_setOperandValue() 関数を呼び出して、バッファに NULL を、長さに 0 を渡します。
オペランドが存在するかどうかの決定が実行のたびに異なる場合は、ANeuralNetworksExecution_setInput() 関数または ANeuralNetworksExecution_setOutput() 関数を使用し、バッファに NULL を、長さに 0 を指定して、そのオペランドが省略されていることを示します。
階数が未知のテンソル
Android 9(API レベル 28)では、次元は未知ですが、階数(次元数)が既知であるモデル演算が導入されました。Android 10(API レベル 29)では、ANeuralNetworksOperandType に記載されているように、階数が未知のテンソルを導入しました。
NNAPI ベンチマーク
NNAPI ベンチマークは、AOSP の platform/test/mlts/benchmark(ベンチマーク アプリ)と platform/test/mlts/models(モデルとデータセット)とから入手可能です。
ベンチマークでは、レイテンシと精度を評価し、ドライバごとに CPU 上で Tensorflow Lite を実行し、同じモデルとデータセットに対して同じ処理を行って比較します。
ベンチマークは次の手順で使用します。
Android ターゲット デバイスをパソコンに接続し、ターミナル ウィンドウを開いて、adb でデバイスにアクセスできることを確認します。
複数の Android デバイスが接続されている場合、ターゲット デバイスの
ANDROID_SERIAL環境変数をエクスポートします。Android のソース ディレクトリの最上位に移動します。
次のコマンドを実行します。
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
ベンチマークが終了すると、
xdg-openに渡される HTML ページとして結果が表示されます。
NNAPI ログ
NNAPI は有用な診断情報をシステムログに生成します。 ログを分析するには、logcat ユーティリティを使用します。
特定のフェーズまたはコンポーネントについて詳細 NNAPI ログを有効にするには、以下の値をスペース、コロン、またはカンマで区切ったリストをプロパティ debug.nn.vlog に設定します(adb shell を使用)。
model: モデルのビルドcompilation: モデルの実行計画の生成とコンパイルexecution: モデルの実行cpuexe: NNAPI CPU 実装を使用した演算の実行manager: NNAPI 拡張機能、利用可能なインターフェース、および機能に関する情報allまたは1: 上記の要素すべて
たとえば、完全な詳細ログを有効にするには、コマンド adb shell setprop debug.nn.vlog all を使用します。詳細ログを無効にするには、コマンド adb shell setprop debug.nn.vlog '""' を使用します。
有効になると、詳細ログは情報レベルにログエントリを生成し、そのフェーズまたはコンポーネント名に設定したタグを付けます。
debug.nn.vlog が制御するメッセージのほか、NNAPI API コンポーネントがそれぞれ固有のログタグを使用して、さまざまなレベルで他のログエントリを提供します。
コンポーネントのリストを取得するには、次の式を使用してソースツリーを検索します。
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
現在、この式は以下のタグを返します。
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operations
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
logcat で表示されるログメッセージのレベルを制御するには、環境変数 ANDROID_LOG_TAGS を使用します。
NNAPI ログメッセージの全セットを表示し、他のログメッセージを無効にするには、ANDROID_LOG_TAGS に以下を設定します。
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
ANDROID_LOG_TAGS を設定するには、次のコマンドを使用します。
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
これは、logcat に適用する単なるフィルタです。詳細ログ情報を生成するには、結局はプロパティ debug.nn.vlog を all に設定する必要があります。