
Architektura aplikacji to podstawa wysokiej jakości aplikacji na Androida. Dobrze zdefiniowana architektura umożliwia tworzenie skalowalnych aplikacji, które można łatwo utrzymywać i dostosowywać do stale rozwijającego się ekosystemu urządzeń z Androidem, w tym telefonów, tabletów, urządzeń składanych, urządzeń z ChromeOS, wyświetlaczy samochodowych i XR.
Kompozycja aplikacji
Typowa aplikacja na Androida składa się z wielu komponentów, takich jak usługi, dostawcy treści i odbiorniki transmisji. Te komponenty deklarujesz w manifeście aplikacji.
Interfejs aplikacji jest również komponentem. W przeszłości interfejsy użytkownika były tworzone przy użyciu wielu aktywności. Nowoczesne aplikacje korzystają jednak z architektury z jednym działaniem. Pojedynczy Activity służy jako kontener ekranów lub miejsc docelowych Jetpack Compose.
Kilka formatów
Aplikacje mogą działać na wielu różnych urządzeniach, w tym nie tylko na telefonach, ale też na tabletach, urządzeniach składanych, urządzeniach z ChromeOS i innych. Nie zakładaj, że aplikacja zawsze pozostaje w orientacji pionowej lub poziomej. Zmiany konfiguracji, takie jak obrócenie urządzenia lub złożenie i rozłożenie urządzenia składanego, wymuszają ponowne skomponowanie interfejsu aplikacji, co wpływa na jej stan.
Ograniczone zasoby
Urządzenia mobilne – nawet te z dużym ekranem – mają ograniczone zasoby, dlatego w każdej chwili system operacyjny może zatrzymać proces aplikacji, aby przekazać zasoby innym procesom.
Zmienne warunki uruchamiania
W środowisku o ograniczonych zasobach komponenty aplikacji mogą być uruchamiane pojedynczo i w dowolnej kolejności. Ponadto system operacyjny lub użytkownik mogą je w każdej chwili zniszczyć. Dlatego nie przechowuj w komponentach aplikacji żadnych danych aplikacji ani stanu. Spraw, aby komponenty aplikacji były samodzielne i niezależne od siebie.
Typowe zasady architektury
Jeśli nie możesz używać komponentów aplikacji do przechowywania danych i stanu aplikacji, jak powinna być zaprojektowana Twoja aplikacja?
Wraz ze wzrostem rozmiaru aplikacji na Androida ważne jest zdefiniowanie architektury, która umożliwi jej skalowanie. Dobrze zaprojektowana architektura aplikacji określa granice między poszczególnymi częściami aplikacji i odpowiedzialność każdej z nich.
Rozdzielenie obowiązków
Zaprojektuj architekturę aplikacji zgodnie z kilkoma konkretnymi zasadami.
Najważniejsza zasada to rozdzielenie odpowiedzialności: podzielenie aplikacji na metody, klasy, pliki, pakiety, moduły i warstwy, które mają jasno określone obowiązki i granice.
Częstym błędem jest pisanie całego kodu w Activity.
Głównym zadaniem Activity jest hostowanie interfejsu aplikacji. System operacyjny Android kontroluje ich cykl życia, często je niszcząc i odtwarzając w odpowiedzi na działania użytkownika, takie jak obracanie ekranu, lub zdarzenia systemowe, takie jak niski poziom pamięci.
Ze względu na ich ulotny charakter nie nadają się one do przechowywania danych aplikacji ani stanu. Jeśli przechowujesz dane w Activity, zostaną one utracone, gdy komponent zostanie ponownie utworzony. Aby zapewnić trwałość danych i stabilność działania aplikacji, nie powierzaj stanu tym komponentom interfejsu.
Układy adaptacyjne
Twórz aplikacje, które dobrze radzą sobie ze zmianami konfiguracji, takimi jak zmiana orientacji urządzenia lub rozmiaru okna aplikacji. Wdróż adaptacyjne układy kanoniczne, aby zapewnić optymalne wrażenia użytkownikom na różnych formatach.
Tworzenie interfejsu Dysku na podstawie modeli danych
Kolejną ważną zasadą jest tworzenie interfejsu na podstawie modeli danych, najlepiej trwałych. Modele danych reprezentują dane aplikacji. Są one niezależne od elementów interfejsu i innych komponentów aplikacji. Oznacza to, że nie są powiązane z cyklem życia interfejsu i komponentów aplikacji, ale zostaną zniszczone, gdy system operacyjny usunie proces aplikacji z pamięci.
Modele trwałe są idealne z tych powodów:
Użytkownicy nie tracą danych, jeśli system operacyjny Android zniszczy Twoją aplikację, aby zwolnić zasoby.
Aplikacja nadal działa, gdy połączenie sieciowe jest przerywane lub niedostępne.
Oprzyj architekturę aplikacji na klasach modelu danych, aby była niezawodna i łatwa do testowania.
Jedno źródło wiarygodnych danych
Gdy w aplikacji zdefiniujesz nowy typ danych, przypisz do niego jedno źródło danych. SSOT jest właścicielem tych danych i tylko SSOT może je modyfikować lub zmieniać. Aby to osiągnąć, SSOT udostępnia dane za pomocą typu niezmiennego. Aby zmodyfikować dane, SSOT udostępnia funkcje lub odbiera zdarzenia, które mogą wywoływać inne typy.
Ten wzorzec ma wiele zalet:
- Centralizuje wszystkie zmiany dotyczące określonego typu danych w jednym miejscu.
- chroni dane przed zmianami przez inne typy,
- Ułatwia śledzenie zmian w danych, dzięki czemu łatwiej jest wykrywać błędy.
W aplikacji działającej w trybie offline źródłem danych aplikacji jest zwykle baza danych. W innych przypadkach źródłem informacji może być ViewModel.
Jednokierunkowy przepływ danych
Zasada jednego źródła danych jest często stosowana w przypadku wzorca jednokierunkowego przepływu danych (UDF). W UDF stan przepływa tylko w jednym kierunku, zwykle od komponentu nadrzędnego do komponentu podrzędnego. zdarzenia, które zmieniają przepływ danych w przeciwnym kierunku.
W Androidzie stan lub dane zwykle przepływają z typów o szerszym zakresie w hierarchii do typów o węższym zakresie. Zdarzenia są zwykle wywoływane z typów o mniejszym zakresie, aż osiągną SSOT dla odpowiedniego typu danych. Na przykład dane aplikacji zwykle przepływają ze źródeł danych do interfejsu. Zdarzenia użytkownika, takie jak naciśnięcia przycisków, przepływają z interfejsu do SSOT, gdzie dane aplikacji są modyfikowane i udostępniane w niezmiennym typie.
Ten wzorzec lepiej zachowuje spójność danych, jest mniej podatny na błędy, łatwiejszy do debugowania i zapewnia wszystkie zalety wzorca SSOT.
Więcej informacji o UDF znajdziesz w artykule Jednokierunkowy przepływ danych w Jetpack Compose.
Zalecana architektura aplikacji
Zgodnie z ogólnymi zasadami architektury zaprojektuj każdą aplikację z co najmniej 2 warstwami:
- Warstwa interfejsu: wyświetla dane aplikacji na ekranie.
- Warstwa danych: zawiera logikę biznesową aplikacji i udostępnia dane aplikacji.
Możesz dodać dodatkową warstwę o nazwie warstwa domeny, aby uprościć i ponownie wykorzystać interakcje między warstwami interfejsu i danych.
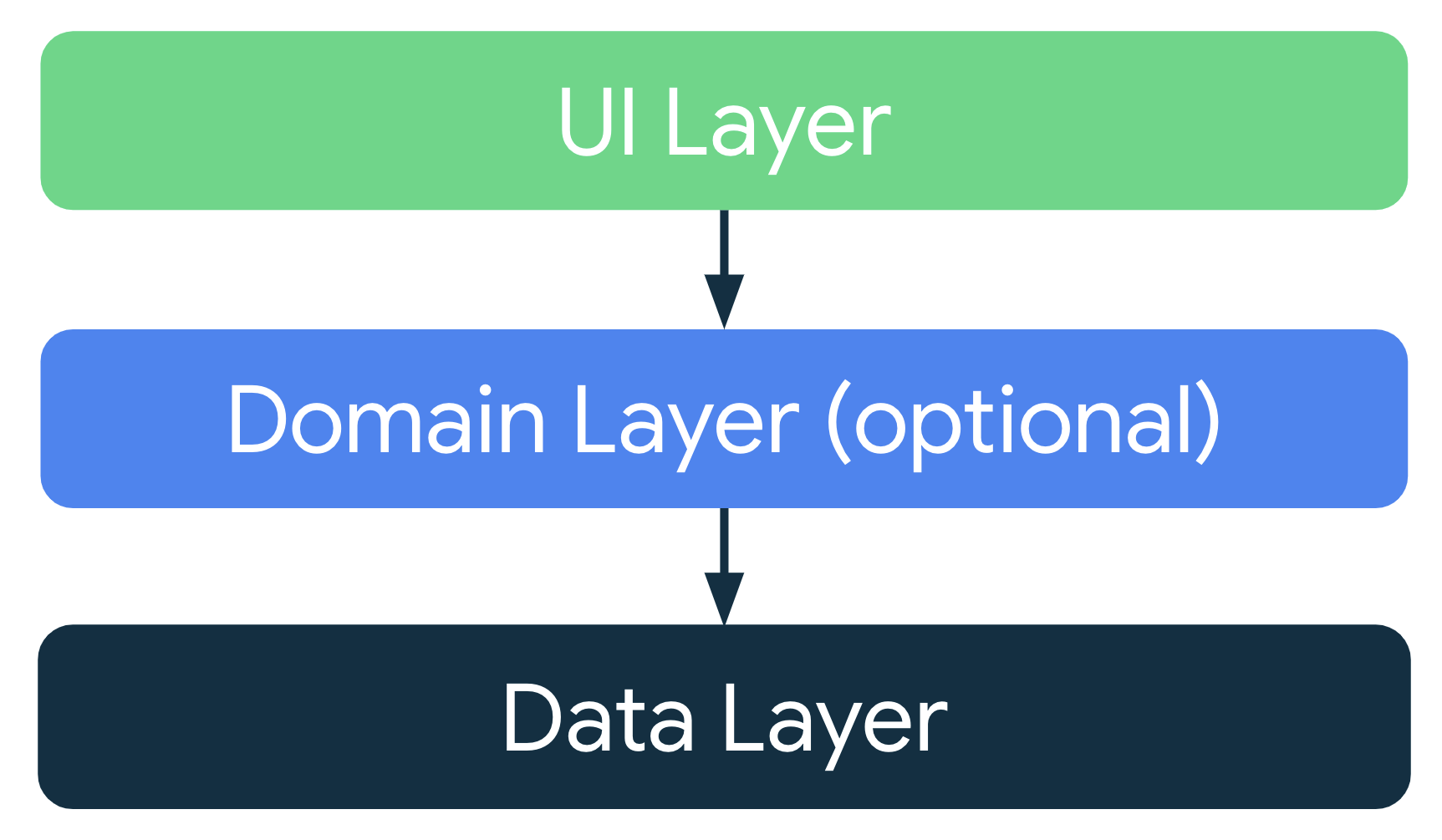
Nowoczesna architektura aplikacji
Nowoczesna architektura aplikacji na Androida wykorzystuje m.in. te techniki:
- Adaptacyjna i warstwowa architektura
- Jednokierunkowy przepływ danych (UDF) we wszystkich warstwach aplikacji
- Warstwa interfejsu z obiektami stanu, która ułatwia zarządzanie złożonością interfejsu.
- Korutyny i przepływy
- Sprawdzone metody wstrzykiwania zależności
Więcej informacji znajdziesz w artykule Rekomendacje dotyczące architektury Androida.
Warstwa interfejsu
Zadaniem warstwy interfejsu (lub warstwy prezentacji) jest wyświetlanie danych aplikacji na ekranie. Gdy dane się zmienią (w wyniku interakcji użytkownika, np. naciśnięcia przycisku, lub danych wejściowych z zewnątrz, np. odpowiedzi sieci), interfejs użytkownika zostanie zaktualizowany, aby odzwierciedlać te zmiany.
Warstwa interfejsu składa się z 2 rodzajów konstrukcji:
- elementy interfejsu, które renderują dane na ekranie; Te elementy tworzysz za pomocą funkcji Jetpack Compose, aby obsługiwać układy adaptacyjne.
- Obiekty stanu (np.
ViewModel), które przechowują dane, udostępniają je w interfejsie i obsługują logikę. Obiekty stanu powinny istnieć tak długo, jak element interfejsu, dla którego dostarczają stan. Na przykład ViewModel ekranu powinien być przechowywany w pamięci, dopóki ekran nie zostanie usunięty ze stosu wstecznego nawigacji aplikacji. Więcej informacji znajdziesz w artykule Okresy istnienia stanów.
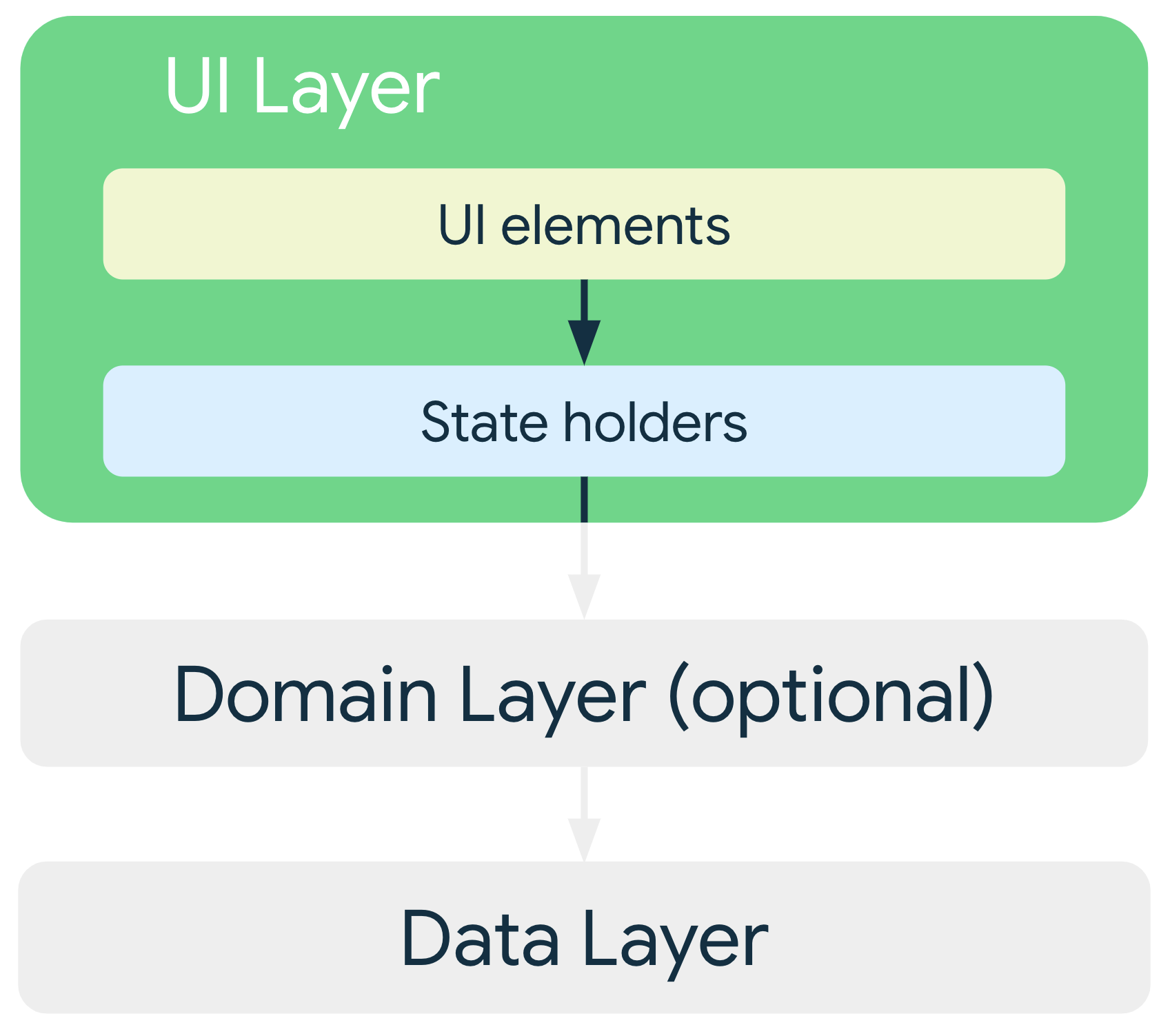
W przypadku adaptacyjnych interfejsów użytkownika obiekty przechowujące stan, takie jak obiekty ViewModel, udostępniają stan interfejsu użytkownika, który dostosowuje się do różnych klas rozmiaru okna. Możesz użyć
currentWindowAdaptiveInfo(), aby uzyskać ten stan interfejsu. Komponenty takie jak NavigationSuiteScaffold mogą następnie używać tych informacji do automatycznego przełączania się między różnymi wzorcami nawigacji (np. NavigationBar, NavigationRail lub NavigationDrawer) w zależności od dostępnej przestrzeni na ekranie.
Więcej informacji znajdziesz w sekcjach Warstwa interfejsu i Architektura interfejsu Compose.
Więcej informacji o aplikacjach adaptacyjnych i nawigacji znajdziesz w artykułach Tworzenie aplikacji adaptacyjnych i Tworzenie adaptacyjnej nawigacji.
Warstwa danych
Warstwa danych aplikacji zawiera logikę biznesową. Logika biznesowa nadaje wartość Twojej aplikacji – obejmuje reguły, które określają, jak aplikacja tworzy, przechowuje i zmienia dane.
Warstwa danych składa się z repozytoriów, z których każde może zawierać od 0 do wielu źródeł danych. Utwórz klasę repozytorium dla każdego typu danych, z którymi Twoja aplikacja ma do czynienia. Możesz na przykład utworzyć klasę MoviesRepositorydla danych związanych z filmami lub klasę PaymentsRepositorydla danych związanych z płatnościami.
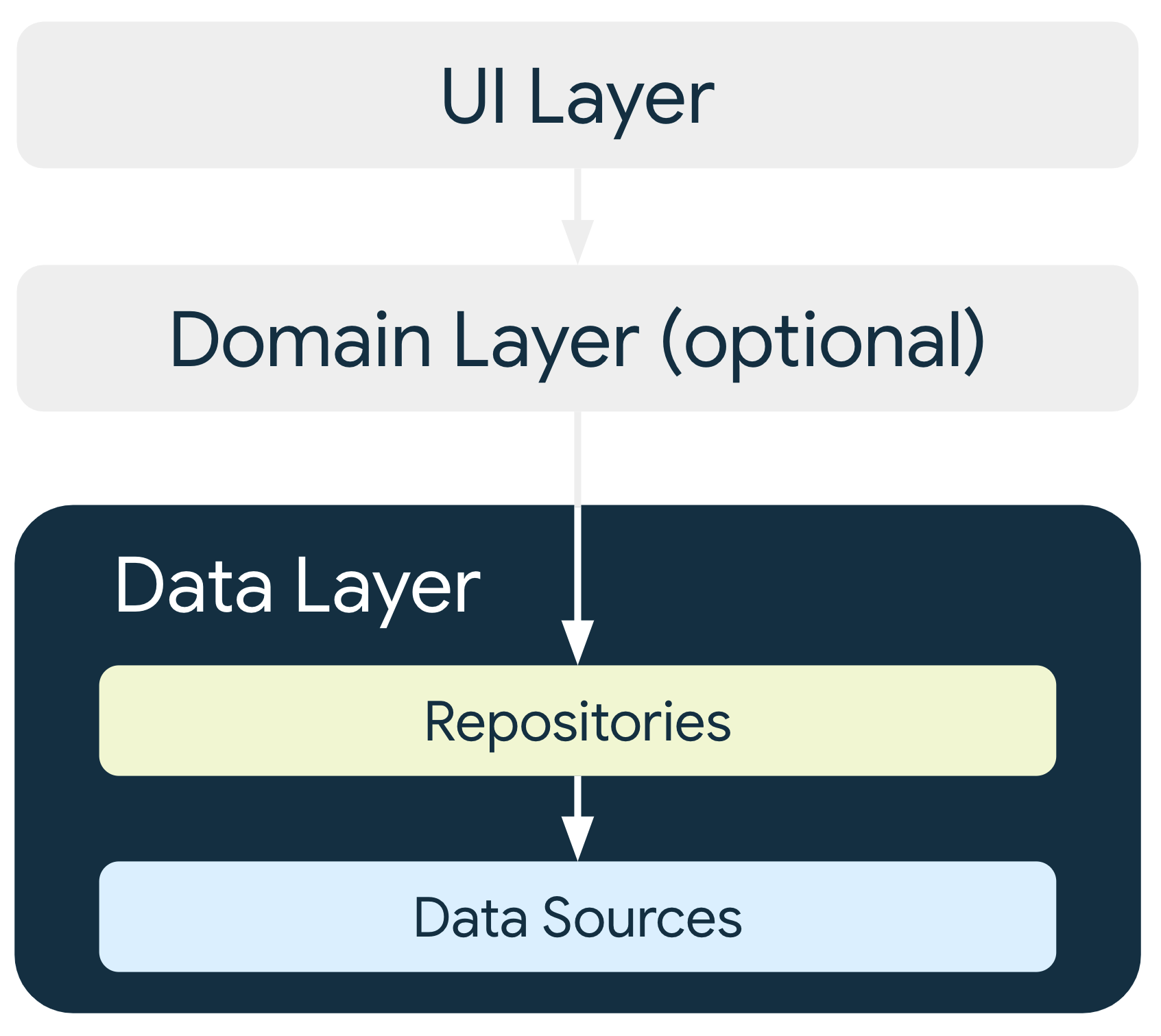
Klasy repozytorium są odpowiedzialne za:
- udostępnianie danych pozostałej części aplikacji,
- Centralizowanie zmian w danych
- Rozwiązywanie konfliktów między wieloma źródłami danych
- oddzielenie źródeł danych od reszty aplikacji;
- zawierające logikę biznesową,
Każda klasa źródła danych jest odpowiedzialna za pracę tylko z jednym źródłem danych, którym może być plik, źródło sieciowe lub lokalna baza danych. Klasy źródeł danych stanowią pomost między aplikacją a systemem w przypadku operacji na danych.
Więcej informacji znajdziesz na stronie warstwy danych.
Warstwa domeny
Warstwa domeny jest opcjonalną warstwą między warstwami interfejsu i danych.
Warstwa domeny odpowiada za hermetyzację złożonej logiki biznesowej lub prostszej logiki biznesowej, która jest ponownie używana przez wiele modeli widoku. Warstwa domeny jest opcjonalna, ponieważ nie wszystkie aplikacje mają takie wymagania. Używaj go tylko wtedy, gdy jest to konieczne, np. aby poradzić sobie ze złożonością lub zwiększyć możliwość ponownego użycia.
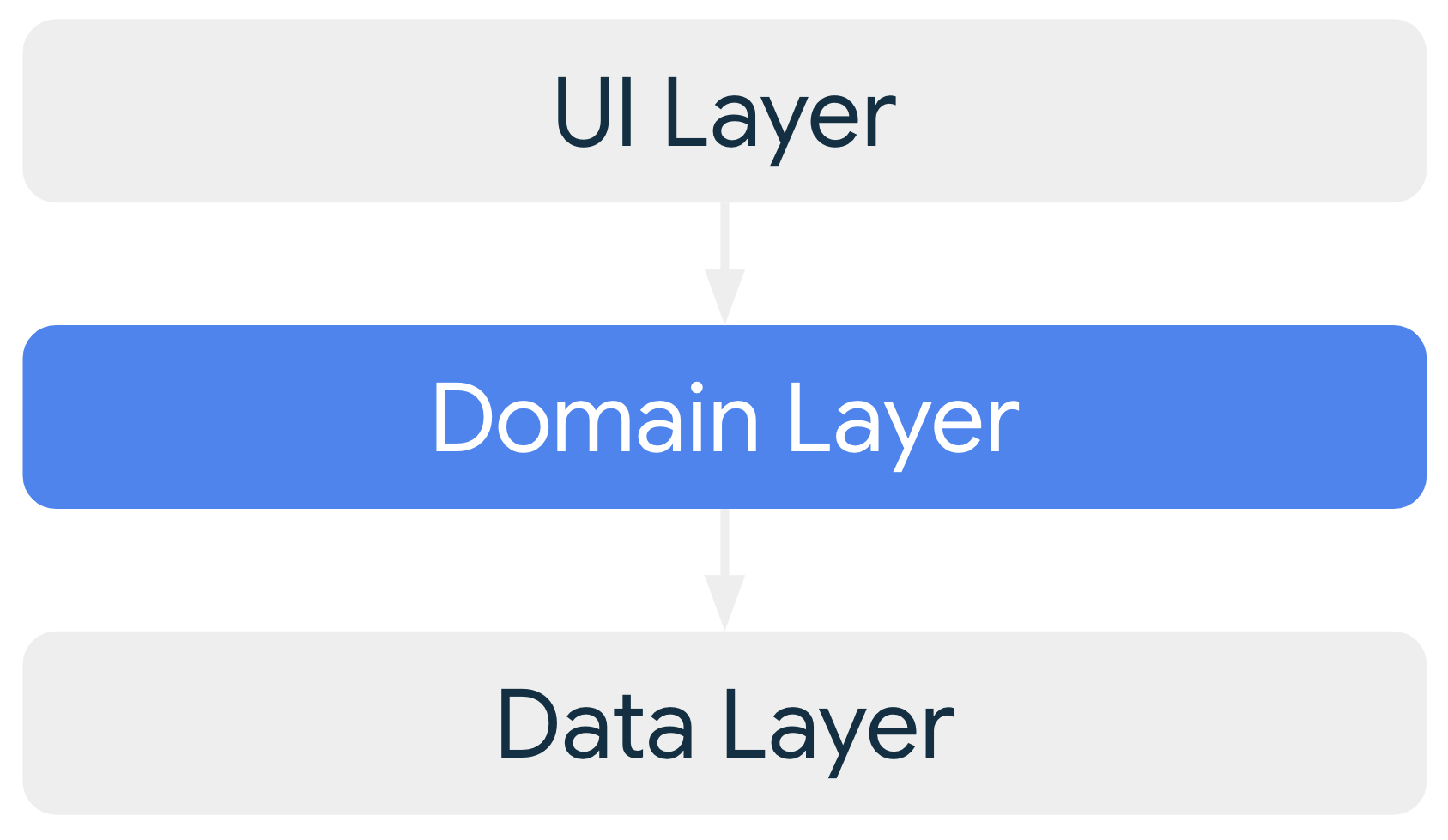
Klasy w warstwie domeny są zwykle nazywane przypadkami użycia lub interaktorami.
Każdy przypadek użycia odpowiada za jedną funkcję. Na przykład aplikacja może mieć klasę GetTimeZoneUseCase, jeśli wiele modeli widoku korzysta ze stref czasowych, aby wyświetlać odpowiednie komunikaty na ekranie.
Więcej informacji znajdziesz na stronie warstwy domeny.
Zarządzanie zależnościami między komponentami
Klasy w aplikacji zależą od innych klas, aby działać prawidłowo. Aby zebrać zależności konkretnej klasy, możesz użyć jednego z tych wzorców projektowych:
- Wstrzykiwanie zależności (DI): wstrzykiwanie zależności umożliwia klasom definiowanie zależności bez ich konstruowania. W czasie działania aplikacji za dostarczanie tych zależności odpowiada inna klasa.
- Lokalizator usług: wzorzec lokalizatora usług udostępnia rejestr, w którym klasy mogą uzyskiwać swoje zależności zamiast je tworzyć.
Te wzorce pozwalają skalować kod, ponieważ zapewniają jasne wzorce zarządzania zależnościami bez powielania kodu ani zwiększania jego złożoności. Wzorce te umożliwiają też szybkie przełączanie się między wdrożeniami testowymi i produkcyjnymi.
Ogólne sprawdzone metody
Programowanie to dziedzina kreatywna, a tworzenie aplikacji na Androida nie jest tu wyjątkiem. Istnieje wiele sposobów rozwiązania problemu. Możesz przesyłać dane między wieloma aktywnościami lub fragmentami, pobierać dane zdalne i przechowywać je lokalnie w trybie offline lub obsługiwać dowolną liczbę innych typowych scenariuszy, z którymi spotykają się nietrywialne aplikacje.
Poniższe zalecenia nie są obowiązkowe, ale w większości przypadków ich stosowanie sprawia, że baza kodu jest bardziej niezawodna, łatwiejsza do testowania i utrzymania.
Nie przechowuj danych w komponentach aplikacji.
Nie wyznaczaj punktów wejścia do aplikacji, takich jak aktywności, usługi i odbiorniki transmisji, jako źródeł danych. Spraw, aby punkty wejścia współdziałały z innymi komponentami, aby pobierać tylko podzbiór danych, który jest istotny dla danego punktu wejścia. Każdy komponent aplikacji działa krótko, w zależności od interakcji użytkownika z urządzeniem i wydajności systemu.
Ogranicz zależności od klas Androida.
Zadbaj o to, aby tylko komponenty aplikacji korzystały z interfejsów API pakietu SDK platformy Android, takich jak Context czy Toast. Odseparowanie innych klas w aplikacji od jej komponentów ułatwia testowanie i zmniejsza powiązania w aplikacji.
Określ wyraźne granice odpowiedzialności między modułami w aplikacji.
Nie rozdzielaj kodu, który wczytuje dane z sieci, na wiele klas ani pakietów w bazie kodu. Podobnie nie definiuj w tej samej klasie wielu niezwiązanych ze sobą zadań, takich jak buforowanie danych i wiązanie danych. Postępuj zgodnie z zalecaną architekturą aplikacji.
Udostępniaj jak najmniej informacji z każdego modułu.
Nie twórz skrótów, które ujawniają wewnętrzne szczegóły implementacji. Możesz zyskać trochę czasu w krótkim okresie, ale w miarę rozwoju bazy kodu prawdopodobnie wielokrotnie zwiększysz dług techniczny.
Skup się na unikalnych funkcjach aplikacji, aby wyróżnić ją na tle innych.
Nie musisz pisać tego samego powtarzalnego kodu wielokrotnie. Zamiast tego skup się na tym, co wyróżnia Twoją aplikację. Pozwól bibliotekom Jetpack i innym polecanym bibliotekom obsługiwać powtarzalne fragmenty kodu.
Korzystaj z kanonicznych układów i wzorców projektowania aplikacji.
Biblioteki Jetpack Compose udostępniają zaawansowane interfejsy API do tworzenia adaptacyjnych interfejsów użytkownika. Używaj w aplikacji kanonicznych układów, aby zoptymalizować wrażenia użytkowników na różnych urządzeniach i wyświetlaczach. Przejrzyj galerię wzorców projektowania aplikacji, aby wybrać układy, które najlepiej pasują do Twoich przypadków użycia.
Zachowaj stan interfejsu po zmianach konfiguracji.
Projektując układy adaptacyjne, zachowuj stan interfejsu w przypadku zmian konfiguracji, takich jak zmiana rozmiaru wyświetlacza, składanie i zmiana orientacji. Twoja architektura powinna sprawdzać, czy bieżący stan użytkownika jest zachowany, aby zapewnić mu wygodę.
Projektowanie komponentów interfejsu do wielokrotnego użycia i komponowania.
Twórz komponenty interfejsu, które można ponownie wykorzystywać i łączyć, aby obsługiwać projektowanie adaptacyjne. Umożliwia to łączenie i przekształcanie komponentów w celu dopasowania ich do różnych rozmiarów ekranu i orientacji bez konieczności wprowadzania znaczących zmian w kodzie.
Zastanów się, jak sprawić, aby każdą część aplikacji można było testować osobno.
Dobrze zdefiniowany interfejs API do pobierania danych z sieci ułatwia testowanie modułu, który zapisuje te dane w lokalnej bazie danych. Jeśli jednak połączysz logikę tych 2 funkcji w jednym miejscu lub rozprowadzisz kod sieciowy w całej bazie kodu, testowanie stanie się znacznie trudniejsze, a nawet niemożliwe.
Typy są odpowiedzialne za swoje zasady współbieżności.
Jeśli typ wykonuje długotrwałą pracę blokującą, powinien przenieść obliczenia do odpowiedniego wątku. Typ wie, jakiego rodzaju obliczenia wykonuje i w którym wątku ma je przeprowadzić. Typy powinny być bezpieczne dla wątku głównego, co oznacza, że można je wywoływać z wątku głównego bez blokowania go.
Przechowuj jak najwięcej istotnych i aktualnych danych.
Dzięki temu użytkownicy będą mogli korzystać z funkcji aplikacji nawet wtedy, gdy ich urządzenie jest w trybie offline. Pamiętaj, że nie wszyscy użytkownicy mają stałe połączenie o wysokiej przepustowości, a nawet jeśli tak jest, w zatłoczonych miejscach mogą mieć słaby sygnał.
Korzyści wynikające z architektury
Dobra architektura wdrożona w aplikacji przynosi wiele korzyści projektowi i zespołom inżynieryjnym:
- Poprawia łatwość konserwacji, jakość i niezawodność całej aplikacji.
- Umożliwia skalowanie aplikacji. Więcej osób i zespołów może pracować nad tą samą bazą kodu przy minimalnej liczbie konfliktów.
- Pomaga w procesie wprowadzania. Architektura zapewnia spójność projektu, dzięki czemu nowi członkowie zespołu mogą szybko nadrobić zaległości i w krótszym czasie pracować wydajniej.
- łatwiej je testować, Dobra architektura zachęca do stosowania prostszych typów, które są zwykle łatwiejsze do testowania.
- Umożliwia metodyczne badanie błędów za pomocą dobrze zdefiniowanych procesów.
Dobra architektura wymaga początkowej inwestycji czasu, ale ma też bezpośredni wpływ na użytkowników. Dzięki temu użytkownicy mogą korzystać z bardziej stabilnej aplikacji i większej liczby funkcji.
Próbki
Poniższe przykłady pokazują dobrą architekturę aplikacji: