
অফলাইন-ফার্স্ট অ্যাপ হলো এমন একটি অ্যাপ যা ইন্টারনেট সংযোগ ছাড়াই তার মূল কার্যকারিতার সবটুকু বা একটি গুরুত্বপূর্ণ অংশ সম্পাদন করতে পারে। অর্থাৎ, এটি তার কিছু বা সমস্ত বিজনেস লজিক অফলাইনে সম্পাদন করতে পারে।
একটি অফলাইন-ফার্স্ট অ্যাপ তৈরির বিবেচ্য বিষয়গুলো ডেটা লেয়ার থেকে শুরু হয়, যা অ্যাপ্লিকেশন ডেটা এবং বিজনেস লজিকে অ্যাক্সেস প্রদান করে। সময়ে সময়ে, অ্যাপটির ডিভাইসের বাইরের উৎস থেকে এই ডেটা রিফ্রেশ করার প্রয়োজন হতে পারে। এমনটা করার জন্য, আপ-টু-ডেট থাকতে এটির নেটওয়ার্ক রিসোর্সের সাহায্য নেওয়ার প্রয়োজন হতে পারে।
নেটওয়ার্কের প্রাপ্যতা সবসময় নিশ্চিত নয়। ডিভাইসগুলোতে প্রায়শই মাঝে মাঝে নেটওয়ার্ক সংযোগ দুর্বল বা ধীরগতির হয়ে থাকে। ব্যবহারকারীরা নিম্নলিখিত সমস্যাগুলো অনুভব করতে পারেন:
- সীমিত ইন্টারনেট ব্যান্ডউইথ
- অস্থায়ী সংযোগ বিঘ্ন, যেমন লিফট বা টানেলের ভিতরে থাকাকালীন।
- মাঝেমধ্যে ডেটা অ্যাক্সেস—উদাহরণস্বরূপ, শুধু ওয়াই-ফাই যুক্ত ট্যাবলেট
কারণ যাই হোক না কেন, এই পরিস্থিতিতেও একটি অ্যাপের পক্ষে প্রায়শই যথাযথভাবে কাজ করা সম্ভব। আপনার অ্যাপটি অফলাইনে সঠিকভাবে কাজ করে তা নিশ্চিত করতে, এটিকে নিম্নলিখিত কাজগুলো করতে সক্ষম হতে হবে:
- নির্ভরযোগ্য নেটওয়ার্ক সংযোগ ছাড়াও ব্যবহারযোগ্য থাকে
- প্রথম নেটওয়ার্ক কলটি সম্পূর্ণ বা ব্যর্থ হওয়ার জন্য অপেক্ষা না করে ব্যবহারকারীদের কাছে অবিলম্বে স্থানীয় ডেটা উপস্থাপন করুন।
- ব্যাটারি এবং ডেটার অবস্থার কথা মাথায় রেখে ডেটা সংগ্রহ করুন—উদাহরণস্বরূপ, শুধুমাত্র সর্বোত্তম পরিস্থিতিতে, যেমন চার্জ দেওয়ার সময় বা ওয়াই-ফাই সংযুক্ত থাকাকালীন, ডেটা সংগ্রহের অনুরোধ করুন।
যে অ্যাপ এই মানদণ্ডগুলো পূরণ করে, তাকে প্রায়শই অফলাইন-ফার্স্ট অ্যাপ বলা হয়।
একটি অফলাইন-ফার্স্ট অ্যাপ ডিজাইন করুন
অফলাইন-ফার্স্ট অ্যাপ ডিজাইন করার সময়, ডেটা লেয়ার থেকে শুরু করুন এবং অ্যাপ ডেটার উপর যে দুটি প্রধান অপারেশন করা যায় তা হলো:
- রিডস : অ্যাপের অন্যান্য অংশে ব্যবহারের জন্য ডেটা পুনরুদ্ধার করা, যেমন ব্যবহারকারীকে তথ্য প্রদর্শন করা। কম্পোজে, আপনি সাধারণত স্টেট অবজার্ভ করার মাধ্যমে এটি সম্পন্ন করেন। যখন আপনার UI লোকাল ডেটা সোর্সকে স্টেট হিসেবে অবজার্ভ করে, তখন স্ক্রিনটি স্বয়ংক্রিয়ভাবে সর্বশেষ লোকাল ডেটা প্রতিফলিত করে।
- ব্যবহারকারীর ইনপুট পরবর্তীতে ব্যবহারের জন্য সংরক্ষণ করা । Compose-এ, সাধারণত UI থেকে ViewModel-এ ইভেন্ট এবং অ্যাকশন পাঠানোর মাধ্যমে এটি করা হয়।
ডেটা লেয়ারের রিপোজিটরিগুলো অ্যাপের ডেটা সরবরাহ করার জন্য বিভিন্ন ডেটা সোর্সকে একত্রিত করার দায়িত্বে থাকে। একটি অফলাইন-ফার্স্ট অ্যাপে অবশ্যই অন্তত একটি ডেটা সোর্স থাকতে হবে, যেটির সবচেয়ে গুরুত্বপূর্ণ কাজগুলো করার জন্য নেটওয়ার্ক অ্যাক্সেসের প্রয়োজন হয় না। এই গুরুত্বপূর্ণ কাজগুলোর মধ্যে একটি হলো ডেটা রিড করা।
একটি অফলাইন-ফার্স্ট অ্যাপে মডেল ডেটা
একটি অফলাইন-ফার্স্ট অ্যাপে নেটওয়ার্ক রিসোর্স ব্যবহারকারী প্রতিটি রিপোজিটরির জন্য ন্যূনতম ২টি ডেটা সোর্স থাকে:
- স্থানীয় ডেটা উৎস
- নেটওয়ার্ক ডেটা উৎস
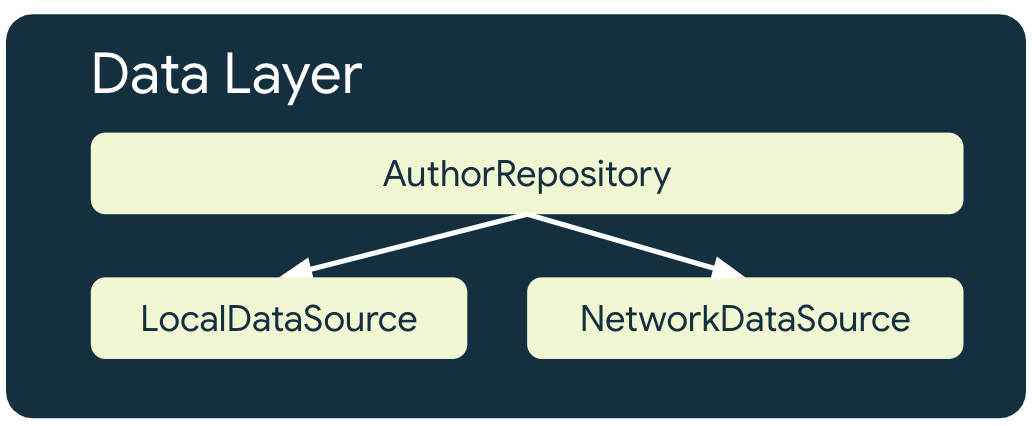
স্থানীয় ডেটা উৎস
স্থানীয় ডেটা সোর্স হলো অ্যাপটির জন্য তথ্যের চূড়ান্ত ও নির্ভরযোগ্য উৎস । অ্যাপের উচ্চতর স্তরগুলো যে কোনো ডেটা পড়ে, তার একমাত্র উৎস এটিই হওয়া উচিত। এটি বিভিন্ন কানেকশন স্টেটের মধ্যে ডেটার সামঞ্জস্য নিশ্চিত করে। স্থানীয় ডেটা সোর্স প্রায়শই এমন স্টোরেজ দ্বারা সমর্থিত হয় যা ডিস্কে সংরক্ষিত থাকে। ডিস্কে ডেটা সংরক্ষণের কিছু সাধারণ উপায় নিচে দেওয়া হলো:
- স্ট্রাকচার্ড ডেটা সোর্স, যেমন Room-এর মতো রিলেশনাল ডেটাবেস
- অসংগঠিত ডেটা উৎস—উদাহরণস্বরূপ, DataStore সহ প্রোটোকল বাফার
- সাধারণ ফাইল
নেটওয়ার্ক ডেটা উৎস
নেটওয়ার্ক ডেটা সোর্স হলো অ্যাপ্লিকেশনটির প্রকৃত অবস্থা। সর্বোত্তম ক্ষেত্রে, লোকাল ডেটা সোর্স নেটওয়ার্ক ডেটা সোর্সের সাথে সিঙ্ক্রোনাইজড থাকে। লোকাল ডেটা সোর্স নেটওয়ার্ক ডেটা সোর্সের চেয়ে পিছিয়েও থাকতে পারে, সেক্ষেত্রে অ্যাপটি পুনরায় অনলাইন হলে আপডেট করার প্রয়োজন হয়। বিপরীতভাবে, কানেক্টিভিটি ফিরে আসার পর অ্যাপটি আপডেট না করা পর্যন্ত নেটওয়ার্ক ডেটা সোর্স লোকাল ডেটা সোর্সের চেয়ে পিছিয়ে থাকতে পারে। অ্যাপের ডোমেইন এবং UI লেয়ার কখনোই সরাসরি নেটওয়ার্ক লেয়ারের সাথে যোগাযোগ করবে না। এর সাথে যোগাযোগ করা এবং লোকাল ডেটা সোর্স আপডেট করার জন্য এটিকে ব্যবহার করা হোস্টিং repository দায়িত্ব।
সম্পদ উন্মোচন করা
আপনার অ্যাপ কীভাবে লোকাল এবং নেটওয়ার্ক ডেটা সোর্স থেকে ডেটা রিড ও রাইট করতে পারে, তার ভিত্তিতে এগুলোর মধ্যে মৌলিক পার্থক্য থাকতে পারে। লোকাল ডেটা সোর্স থেকে ডেটা কোয়েরি করা দ্রুত এবং নমনীয় হতে পারে, যেমন SQL কোয়েরি ব্যবহার করার সময়। এর বিপরীতে, নেটওয়ার্ক ডেটা সোর্স ধীর এবং সীমাবদ্ধ হতে পারে, যেমন ID দ্বারা RESTful রিসোর্স পর্যায়ক্রমে অ্যাক্সেস করার ক্ষেত্রে। ফলস্বরূপ, প্রতিটি ডেটা সোর্সের প্রায়শই তার সরবরাহ করা ডেটার নিজস্ব উপস্থাপনার প্রয়োজন হয়। তাই লোকাল ডেটা সোর্স এবং নেটওয়ার্ক ডেটা সোর্সের নিজস্ব মডেল থাকতে পারে।
নিম্নলিখিত ডিরেক্টরি কাঠামোটি এই ধারণাটি কল্পনা করতে সাহায্য করে। AuthorEntity অ্যাপের স্থানীয় ডেটাবেস থেকে পড়া একজন লেখককে প্রতিনিধিত্ব করে, এবং NetworkAuthor নেটওয়ার্কের মাধ্যমে সিরিয়ালাইজড একজন লেখককে প্রতিনিধিত্ব করে:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
AuthorEntity এবং NetworkAuthor এর বিবরণ নিচে দেওয়া হলো:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
ডেটা লেয়ারের অভ্যন্তরে AuthorEntity এবং NetworkAuthor উভয়কেই রাখা এবং বাহ্যিক লেয়ারগুলোর ব্যবহারের জন্য তৃতীয় একটি প্রকার উন্মুক্ত রাখা একটি উত্তম অভ্যাস। এটি স্থানীয় এবং নেটওয়ার্ক ডেটা উৎসের এমন ছোটখাটো পরিবর্তন থেকে বাহ্যিক লেয়ারগুলোকে সুরক্ষিত রাখে, যা অ্যাপটির আচরণকে মৌলিকভাবে পরিবর্তন করে না। নিম্নলিখিত কোড স্নিপেটে এটি প্রদর্শন করা হয়েছে:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
এরপর নেটওয়ার্ক মডেলটি এটিকে লোকাল মডেলে রূপান্তর করার জন্য একটি এক্সটেনশন মেথড সংজ্ঞায়িত করতে পারে, এবং একইভাবে লোকাল মডেলটিতেও এটিকে এক্সটার্নাল রিপ্রেজেন্টেশনে রূপান্তর করার জন্য একটি মেথড থাকে, যেমনটি নিম্নলিখিত কোড স্নিপেটে দেখানো হয়েছে:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
পড়া
অফলাইন-ফার্স্ট অ্যাপে অ্যাপ ডেটার উপর রিড হলো মৌলিক অপারেশন। তাই আপনাকে অবশ্যই নিশ্চিত করতে হবে যে আপনার অ্যাপ ডেটা রিড করতে পারে এবং নতুন ডেটা উপলব্ধ হওয়ার সাথে সাথেই তা প্রদর্শন করতে পারে। যে অ্যাপ এটি করতে পারে, তাকে রিঅ্যাক্টিভ অ্যাপ বলা হয়, কারণ এটি অবজার্ভেবল টাইপের মাধ্যমে রিড এপিআই (API) উন্মুক্ত করে।
নিম্নলিখিত কোড স্নিপেটে, OfflineFirstTopicRepository তার সমস্ত রিড এপিআই-এর জন্য Flow ) রিটার্ন করে। এটি নেটওয়ার্ক ডেটা সোর্স থেকে আপডেট পেলে তার রিডারদের আপডেট করতে সাহায্য করে। অন্য কথায়, যখন OfflineFirstTopicRepository এর লোকাল ডেটা সোর্স অবৈধ হয়ে যায়, তখন এটি পরিবর্তনগুলো পুশ (push) করতে দেয়। অতএব, OfflineFirstTopicRepository এর প্রতিটি রিডারকে অবশ্যই সেইসব ডেটা পরিবর্তন সামলানোর জন্য প্রস্তুত থাকতে হবে যা অ্যাপে নেটওয়ার্ক সংযোগ পুনরুদ্ধার হলে ঘটতে পারে। এছাড়াও, OfflineFirstTopicRepository সরাসরি লোকাল ডেটা সোর্স থেকে ডেটা রিড করে। এটি শুধুমাত্র প্রথমে তার লোকাল ডেটা সোর্স আপডেট করার মাধ্যমেই তার রিডারদের ডেটা পরিবর্তনের বিষয়ে অবহিত করতে পারে।
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
একটি Jetpack Compose অ্যাপে, ডেটা লেয়ার এবং UI-এর মধ্যে সংযোগ স্থাপন করতে একটি ViewModel ব্যবহার করুন। ViewModel-এর মধ্যে, stateIn অপারেটর ব্যবহার করে Flow একটি StateFlow তে রূপান্তর করুন। এরপর Composable-গুলো collectAsStateWithLifecycle() ব্যবহার করে সেই স্টেটগুলো সংগ্রহ করে এবং লাইফসাইকেল-সচেতন পদ্ধতিতে স্বয়ংক্রিয়ভাবে সাবস্ক্রিপশনগুলো পরিচালনা করে।
collectAsStateWithLifecycle() সম্পর্কে আরও তথ্যের জন্য, State এবং Jetpack Compose দেখুন।
ত্রুটি পরিচালনা কৌশল
অফলাইন-ফার্স্ট অ্যাপে ত্রুটি মোকাবিলার কিছু স্বতন্ত্র উপায় রয়েছে, যা নির্ভর করে ত্রুটিগুলো কোন ডেটা সোর্স থেকে ঘটতে পারে তার উপর। নিম্নলিখিত উপবিভাগগুলোতে এই কৌশলগুলো তুলে ধরা হয়েছে।
স্থানীয় ডেটা উৎস
স্থানীয় ডেটা উৎস থেকে ডেটা পড়ার সময় ত্রুটি কমানোর চেষ্টা করুন। রিডারদের ত্রুটি থেকে রক্ষা করতে, যে Flow ) থেকে রিডার ডেটা সংগ্রহ করছে, সেটিতে catch অপারেটর ব্যবহার করুন।
আপনি একটি ViewModel এ catch অপারেটরটি নিম্নোক্তভাবে ব্যবহার করতে পারেন:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
আরও স্থিতিশীল একটি পদ্ধতির জন্য, একটি LCE (Loading Content Error) সমাধান বিবেচনা করতে পারেন। LCE-তে, পড়ার সময় কোনো ব্যর্থতা ঘটলে একটি এরর স্টেট দেখানো হয়। সাধারণত, UI স্টেটগুলোকে কোটলিন সিলড ক্লাস (Kotlin sealed classes) হিসেবে মডেলিং করার মাধ্যমে LCE অর্জন করা হয়।
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
নেটওয়ার্ক ডেটা উৎস
নেটওয়ার্ক ডেটা সোর্স থেকে ডেটা পড়ার সময় ত্রুটি ঘটলে, অ্যাপটিকে ডেটা পুনরায় আনার চেষ্টা করার জন্য একটি হিউরিস্টিক ব্যবহার করতে হয়। প্রচলিত হিউরিস্টিকগুলোর মধ্যে নিম্নলিখিতগুলো অন্তর্ভুক্ত:
সূচকীয় ব্যাকঅফ
এক্সপোনেনশিয়াল ব্যাকঅফে , অ্যাপটি সফল না হওয়া পর্যন্ত, অথবা অন্য কোনো পরিস্থিতি এটিকে থামতে বাধ্য না করা পর্যন্ত, ক্রমবর্ধমান সময় ব্যবধানে নেটওয়ার্ক ডেটা উৎস থেকে ডেটা পড়ার চেষ্টা চালিয়ে যায়।
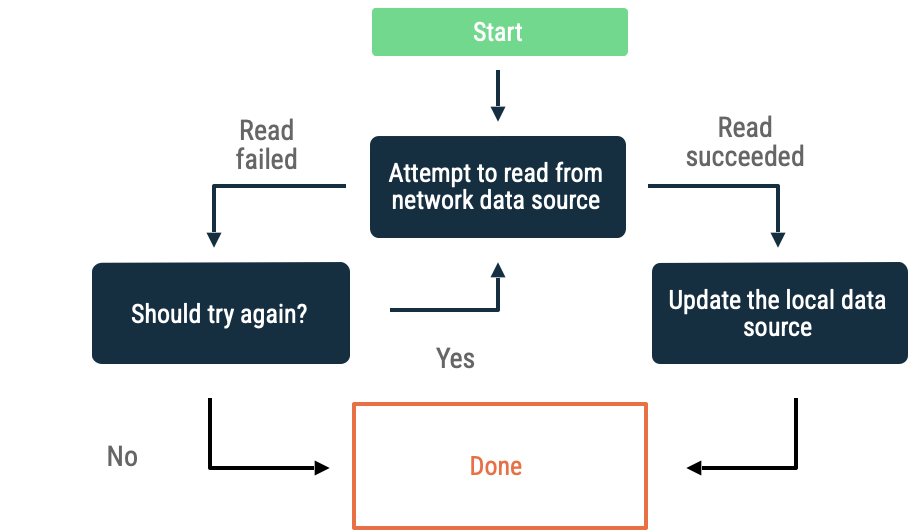
অ্যাপটি বারবার ব্যাক অফ হয়ে যাচ্ছে কিনা তা মূল্যায়ন করার মানদণ্ডগুলোর মধ্যে নিম্নলিখিতগুলো অন্তর্ভুক্ত:
- নেটওয়ার্ক ডেটা সোর্স যে ধরনের ত্রুটি নির্দেশ করেছে। উদাহরণস্বরূপ, যে নেটওয়ার্ক কলগুলো সংযোগের অভাব নির্দেশ করে এমন ত্রুটি ফেরত দেয়, সেগুলো পুনরায় চেষ্টা করুন। সঠিক ক্রেডেনশিয়াল উপলব্ধ না হওয়া পর্যন্ত অননুমোদিত HTTP অনুরোধগুলো পুনরায় চেষ্টা করবেন না।
- সর্বাধিক অনুমোদিত পুনঃচেষ্টা।
নেটওয়ার্ক সংযোগ পর্যবেক্ষণ
এই পদ্ধতিতে, অ্যাপটি নেটওয়ার্ক ডেটা সোর্সের সাথে সংযোগ স্থাপন করতে পারবে বলে নিশ্চিত না হওয়া পর্যন্ত রিড রিকোয়েস্টগুলো কিউতে জমা থাকে। একবার সংযোগ স্থাপিত হলে, রিড রিকোয়েস্টটি কিউ থেকে বের করা হয়, ডেটা পড়া হয় এবং স্থানীয় ডেটা সোর্স আপডেট করা হয়। অ্যান্ড্রয়েডে এই কিউটি একটি Room ডেটাবেস দিয়ে রক্ষণাবেক্ষণ করা হতে পারে এবং WorkManager ব্যবহার করে স্থায়ী কাজ হিসেবে খালি করা হতে পারে।
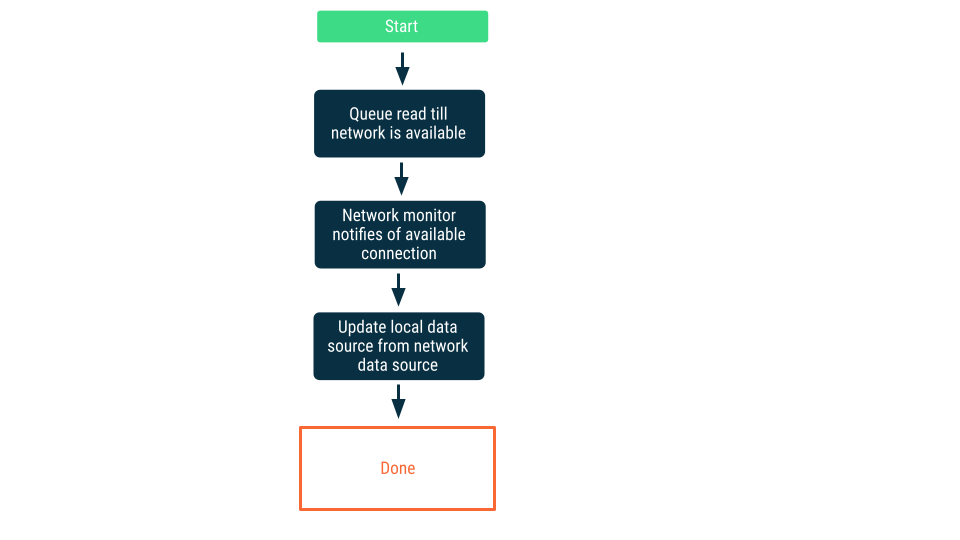
লেখে
অফলাইন-ফার্স্ট অ্যাপে ডেটা পড়ার জন্য অবজার্ভেবল টাইপ ব্যবহার করার পরামর্শ দেওয়া হলেও, রাইট এপিআই-এর ক্ষেত্রে এর সমতুল্য হলো সাসপেন্ড ফাংশনের মতো অ্যাসিঙ্ক্রোনাস এপিআই । এর ফলে UI থ্রেড ব্লক হওয়া এড়ানো যায় এবং এরর হ্যান্ডলিং-এও সাহায্য হয়, কারণ অফলাইন-ফার্স্ট অ্যাপে নেটওয়ার্কের সীমানা অতিক্রম করার সময় রাইট অপারেশন ব্যর্থ হতে পারে।
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
পূর্ববর্তী কোড অংশে, অ্যাসিঙ্ক্রোনাস এপিআই হিসেবে কো-রুটিন ব্যবহার করা হয়েছে, কারণ মেথডটি সাসপেন্ড হয়।
কৌশল লিখুন
অফলাইন-ফার্স্ট অ্যাপে ডেটা লেখার সময় তিনটি কৌশল বিবেচনা করা যেতে পারে। আপনি কোনটি বেছে নেবেন তা নির্ভর করে কী ধরনের ডেটা লেখা হচ্ছে এবং অ্যাপটির প্রয়োজনীয়তার ওপর:
শুধুমাত্র অনলাইনে লেখা
নেটওয়ার্ক সীমানা পেরিয়ে ডেটা লেখার চেষ্টা করুন। সফল হলে, স্থানীয় ডেটা উৎস আপডেট করুন; অন্যথায়, একটি এক্সেপশন থ্রো করুন এবং যথাযথভাবে সাড়া দেওয়ার দায়িত্ব কলারের উপর ছেড়ে দিন।
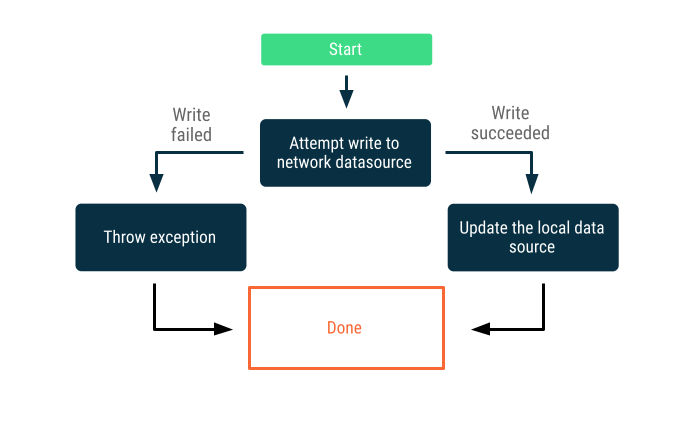
এই কৌশলটি প্রায়শই এমন রাইট ট্রানজ্যাকশনের জন্য ব্যবহৃত হয় যা প্রায় রিয়েল টাইমে অনলাইনে সম্পন্ন হওয়া আবশ্যক—উদাহরণস্বরূপ, একটি ব্যাংক ট্রান্সফার। যেহেতু রাইট ব্যর্থ হতে পারে, তাই প্রায়শই ব্যবহারকারীকে জানানো প্রয়োজন হয় যে রাইটটি ব্যর্থ হয়েছে, অথবা ব্যবহারকারীকে শুরুতেই ডেটা লেখার চেষ্টা করা থেকে বিরত রাখা হয়। এই ধরনের পরিস্থিতিতে আপনি যে কৌশলগুলো অবলম্বন করতে পারেন, তা নিচে দেওয়া হলো:
- যদি কোনো অ্যাপ ডেটা লেখার জন্য ইন্টারনেট অ্যাক্সেসের প্রয়োজন হয়, তাহলে আপনি ব্যবহারকারীকে ডেটা লেখার সুবিধা দেয় এমন কোনো ইউজার ইন্টারফেস (UI) না দেখানোর সিদ্ধান্ত নিতে পারেন, অথবা অন্ততপক্ষে আপনি এটি নিষ্ক্রিয় করে দিতে পারেন।
- ব্যবহারকারীকে তিনি অফলাইনে আছেন তা জানানোর জন্য আপনি একটি
AlertDialogব্যবহার করতে পারেন যা তিনি বন্ধ করতে পারবেন না, অথবা একটিSnackbar) ব্যবহার করতে পারেন।
সারিবদ্ধ লেখা
যখন আপনার লেখার জন্য কোনো অবজেক্ট থাকবে, তখন সেটিকে একটি কিউ-তে প্রবেশ করান। অ্যাপটি আবার অনলাইন হলে, এক্সপোনেনশিয়াল ব্যাকঅফ ব্যবহার করে কিউ-টি খালি করে দিন। অ্যান্ড্রয়েডে, একটি অফলাইন কিউ খালি করা একটি স্থায়ী কাজ, যা প্রায়শই WorkManager এর উপর অর্পণ করা হয়।
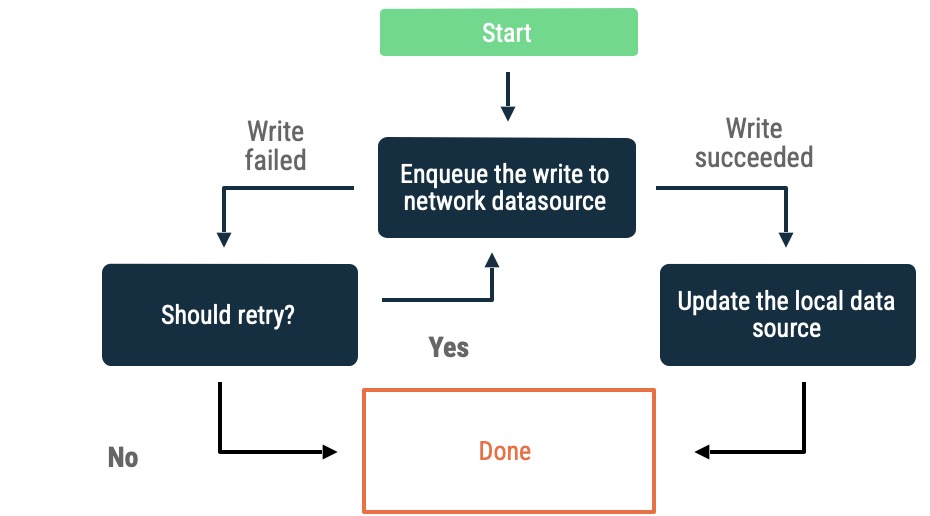
নিম্নলিখিত পরিস্থিতিগুলিতে এই পদ্ধতিটি একটি ভালো পছন্দ:
- ডেটা নেটওয়ার্কে লেখা হওয়াটা অপরিহার্য নয়।
- লেনদেনটি সময়-সংবেদনশীল নয়।
- অপারেশনটি ব্যর্থ হলে ব্যবহারকারীকে জানানো অপরিহার্য নয়।
এই পদ্ধতির ব্যবহারক্ষেত্রগুলোর মধ্যে রয়েছে অ্যানালিটিক্স ইভেন্ট এবং লগিং।
লেজি লেখে
প্রথমে স্থানীয় ডেটা সোর্সে লিখুন, তারপর যত তাড়াতাড়ি সম্ভব নেটওয়ার্ককে জানানোর জন্য লেখাটি কিউতে রাখুন। এই কাজটি সহজ নয়, কারণ অ্যাপটি পুনরায় অনলাইন হলে নেটওয়ার্ক এবং স্থানীয় ডেটা সোর্সের মধ্যে সংঘাত দেখা দিতে পারে। সংঘাত নিরসন সম্পর্কিত পরবর্তী বিভাগে এ বিষয়ে আরও বিস্তারিত আলোচনা করা হয়েছে।
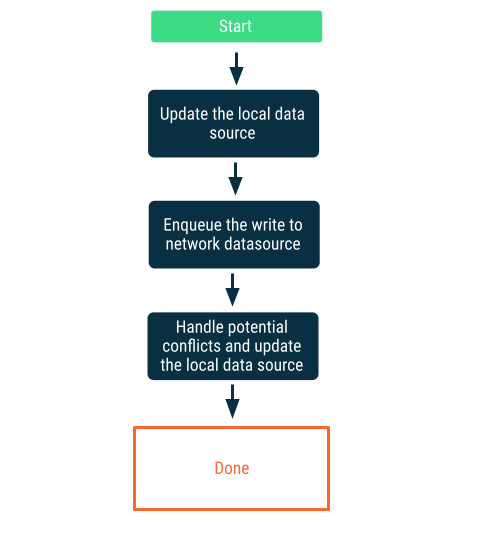
যখন ডেটা অ্যাপটির জন্য অত্যন্ত গুরুত্বপূর্ণ হয়, তখন এই পদ্ধতিটিই সঠিক পছন্দ। উদাহরণস্বরূপ, একটি অফলাইন-ফার্স্ট টু-ডু লিস্ট অ্যাপের ক্ষেত্রে, ডেটা হারানোর ঝুঁকি এড়াতে ব্যবহারকারীর অফলাইনে যোগ করা যেকোনো টাস্ক স্থানীয়ভাবে সংরক্ষণ করা অপরিহার্য।
সমন্বয় এবং সংঘাত সমাধান
যখন একটি অফলাইন-ফার্স্ট অ্যাপ তার কানেক্টিভিটি পুনরুদ্ধার করে, তখন সেটিকে তার লোকাল ডেটা সোর্সের ডেটার সাথে নেটওয়ার্ক ডেটা সোর্সের ডেটা মিলিয়ে নিতে হয়। এই প্রক্রিয়াটিকে সিনক্রোনাইজেশন বলা হয়। একটি অ্যাপ প্রধানত দুটি উপায়ে তার নেটওয়ার্ক ডেটা সোর্সের সাথে সিনক্রোনাইজ করতে পারে:
- টান-ভিত্তিক সিঙ্ক্রোনাইজেশন
- পুশ-ভিত্তিক সিঙ্ক্রোনাইজেশন
টান-ভিত্তিক সিঙ্ক্রোনাইজেশন
পুল-ভিত্তিক সিঙ্ক্রোনাইজেশনে, অ্যাপটি চাহিদা অনুযায়ী সর্বশেষ অ্যাপ্লিকেশন ডেটা পড়ার জন্য নেটওয়ার্কের সাথে যোগাযোগ করে। এই পদ্ধতির একটি সাধারণ কৌশল হলো নেভিগেশন-ভিত্তিক, যেখানে অ্যাপটি ব্যবহারকারীর কাছে ডেটা উপস্থাপন করার ঠিক আগে তা সংগ্রহ করে।
এই পদ্ধতিটি সবচেয়ে ভালোভাবে কাজ করে যখন অ্যাপটি অল্প থেকে মাঝারি সময়ের জন্য নেটওয়ার্ক সংযোগ বিচ্ছিন্ন থাকার আশঙ্কা করে। এর কারণ হলো, ডেটা রিফ্রেশ একটি সুযোগসন্ধানী প্রক্রিয়া, এবং দীর্ঘ সময় ধরে সংযোগ বিচ্ছিন্ন থাকলে ব্যবহারকারীর পক্ষে পুরোনো বা খালি ক্যাশে দিয়ে অ্যাপের গন্তব্যে যাওয়ার চেষ্টা করার সম্ভাবনা বেড়ে যায়।
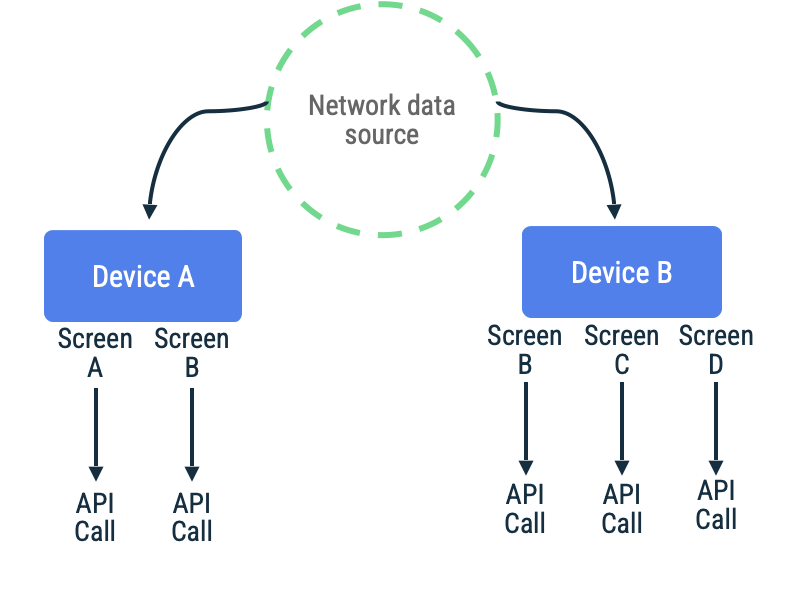
এমন একটি অ্যাপের কথা ভাবুন যেখানে একটি নির্দিষ্ট স্ক্রিনের জন্য একটি অন্তহীন স্ক্রোলিং তালিকা থেকে আইটেম আনার জন্য পেজ টোকেন ব্যবহার করা হয়। এই ইমপ্লিমেন্টেশনটি অলসভাবে নেটওয়ার্কের সাথে সংযোগ স্থাপন করতে পারে, ডেটা স্থানীয় ডেটা সোর্সে সংরক্ষণ করতে পারে এবং তারপর ব্যবহারকারীকে তথ্য ফিরিয়ে দেওয়ার জন্য স্থানীয় ডেটা সোর্স থেকে তা পড়তে পারে। যদি কোনো নেটওয়ার্ক সংযোগ না থাকে, তবে রিপোজিটরিটি শুধুমাত্র স্থানীয় ডেটা সোর্স থেকেই ডেটার জন্য অনুরোধ করতে পারে। জেটপ্যাক পেজিং লাইব্রেরি তার RemoteMediator এপিআই (RemoteMediator API) এর মাধ্যমে এই প্যাটার্নটিই ব্যবহার করে।
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
পুল-ভিত্তিক সিঙ্ক্রোনাইজেশনের সুবিধা ও অসুবিধাগুলো নিম্নলিখিত সারণিতে সংক্ষেপে তুলে ধরা হলো:
| সুবিধাগুলি | অসুবিধা |
|---|---|
| বাস্তবায়ন করা তুলনামূলকভাবে সহজ। | এতে প্রচুর ডেটা ব্যবহারের প্রবণতা থাকে। এর কারণ হলো, কোনো নেভিগেশন গন্তব্যে বারবার গেলে অপরিবর্তিত তথ্য অপ্রয়োজনীয়ভাবে পুনরায় ফেচ করার প্রয়োজন হয়। সঠিক ক্যাশিংয়ের মাধ্যমে আপনি এটি কমাতে পারেন। এটি UI লেয়ারে cachedIn অপারেটরের সাহায্যে, অথবা নেটওয়ার্ক লেয়ারে একটি HTTP ক্যাশের মাধ্যমে করা যেতে পারে। |
| অপ্রয়োজনীয় ডেটা কখনোই সংগ্রহ করা হয় না। | রিলেশনাল ডেটার ক্ষেত্রে এটি ভালোভাবে কাজ করে না, কারণ যে মডেলটি পুল করা হয় তাকে স্বয়ংসম্পূর্ণ হতে হয়। যদি সিঙ্ক্রোনাইজ করা মডেলটি নিজেকে পপুলেট করার জন্য অন্য মডেল ফেচ করার উপর নির্ভর করে, তবে পূর্বে উল্লিখিত অতিরিক্ত ডেটা ব্যবহারের সমস্যাটি আরও গুরুতর হয়ে ওঠে। এছাড়াও, এটি প্যারেন্ট মডেলের রিপোজিটরি এবং নেস্টেড মডেলের রিপোজিটরিগুলোর মধ্যে নির্ভরশীলতা তৈরি করতে পারে। |
পুশ-ভিত্তিক সিঙ্ক্রোনাইজেশন
পুশ-ভিত্তিক সিঙ্ক্রোনাইজেশনে, স্থানীয় ডেটা উৎস তার সাধ্যমতো নেটওয়ার্ক ডেটা উৎসের একটি প্রতিরূপ সেট অনুকরণ করার চেষ্টা করে। এটি একটি বেসলাইন সেট করার জন্য প্রথমবার চালু হওয়ার সময় সক্রিয়ভাবে উপযুক্ত পরিমাণ ডেটা সংগ্রহ করে। এরপর, সেই ডেটা পুরোনো হয়ে গেলে সতর্ক করার জন্য এটি সার্ভার থেকে আসা নোটিফিকেশনের উপর নির্ভর করে।
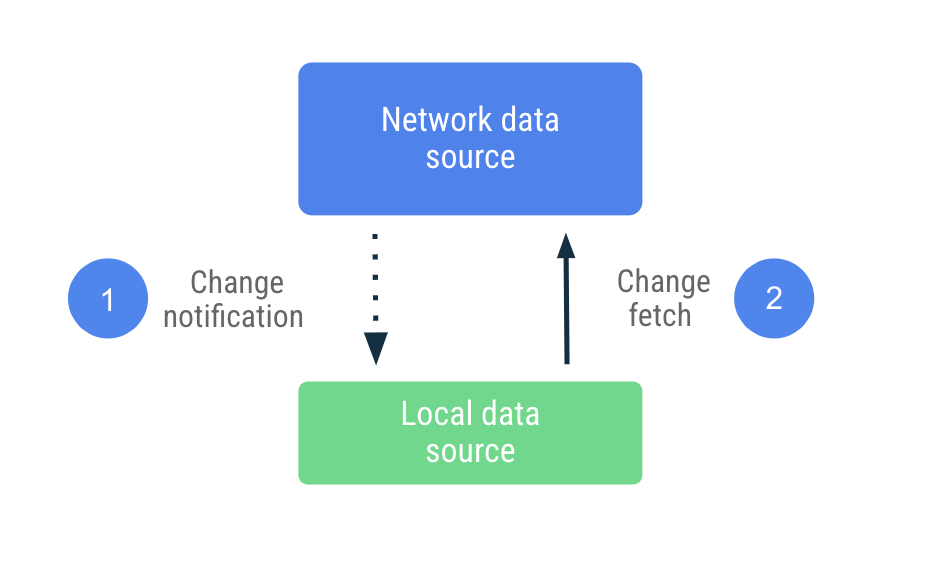
পুরনো বা অপ্রচলিত ডেটার নোটিফিকেশন পাওয়ার পর, অ্যাপটি শুধুমাত্র সেই ডেটা আপডেট করার জন্য নেটওয়ার্কের সাথে যোগাযোগ করে যা পুরনো হিসেবে চিহ্নিত করা হয়েছিল। এই কাজটি Repository কে অর্পণ করা হয়, যা নেটওয়ার্ক ডেটা সোর্সের সাথে যোগাযোগ করে এবং সংগৃহীত ডেটা স্থানীয় ডেটা সোর্সে সংরক্ষণ করে। যেহেতু রিপোজিটরি তার ডেটা অবজার্ভেবল টাইপের মাধ্যমে প্রকাশ করে, তাই যেকোনো পরিবর্তনের বিষয়ে পাঠকদের অবহিত করা হয়।
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
এই পদ্ধতিতে, অ্যাপটি নেটওয়ার্ক ডেটা উৎসের উপর অনেক কম নির্ভরশীল থাকে এবং এটি ছাড়াই দীর্ঘ সময় ধরে কাজ করতে পারে। অফলাইনে থাকাকালীন এটি রিড এবং রাইট উভয় অ্যাক্সেসই প্রদান করে, কারণ এটি ধরে নেয় যে এর কাছে স্থানীয়ভাবে নেটওয়ার্ক ডেটা উৎস থেকে সর্বশেষ তথ্য রয়েছে।
পুশ-ভিত্তিক সিঙ্ক্রোনাইজেশনের সুবিধা ও অসুবিধাগুলো নিম্নলিখিত সারণিতে সংক্ষেপে তুলে ধরা হলো:
| সুবিধাগুলি | অসুবিধা |
|---|---|
| অ্যাপটি অনির্দিষ্টকালের জন্য অফলাইনে থাকতে পারে। | বিরোধ নিষ্পত্তির জন্য ডেটার ভার্সনিং করা একটি গুরুত্বপূর্ণ কাজ। |
| ন্যূনতম ডেটা ব্যবহার। অ্যাপটি শুধুমাত্র পরিবর্তিত ডেটা সংগ্রহ করে। | সিঙ্ক্রোনাইজেশনের সময় আপনাকে রাইট কনসার্নগুলো বিবেচনায় নিতে হবে। |
| রিলেশনাল ডেটার জন্য এটি ভালোভাবে কাজ করে। প্রতিটি রিপোজিটরি শুধুমাত্র তার সমর্থিত মডেলের জন্য ডেটা আনার দায়িত্বে থাকে। | নেটওয়ার্ক ডেটা উৎসকে সিঙ্ক্রোনাইজেশন সমর্থন করতে হবে। |
হাইব্রিড সিঙ্ক্রোনাইজেশন
কিছু অ্যাপ ডেটার উপর নির্ভর করে পুল-ভিত্তিক বা পুশ-ভিত্তিক একটি হাইব্রিড পদ্ধতি ব্যবহার করে। উদাহরণস্বরূপ, একটি সোশ্যাল মিডিয়া অ্যাপ ঘন ঘন ফিড আপডেটের কারণে চাহিদা অনুযায়ী ব্যবহারকারীর ফলোয়িং ফিড আনার জন্য পুল-ভিত্তিক সিনক্রোনাইজেশন ব্যবহার করতে পারে। একই অ্যাপটি সাইন-ইন করা ব্যবহারকারীর ইউজারনেম, প্রোফাইল পিকচার ইত্যাদির ডেটার জন্য পুশ-ভিত্তিক সিনক্রোনাইজেশন ব্যবহার করার সিদ্ধান্ত নিতে পারে।
পরিশেষে, অফলাইন-ফার্স্ট সিঙ্ক্রোনাইজেশনের সিদ্ধান্ত পণ্যের প্রয়োজনীয়তা এবং উপলব্ধ প্রযুক্তিগত অবকাঠামোর উপর নির্ভর করে।
সংঘাত সমাধান
অফলাইনে থাকাকালীন, অ্যাপটি যদি স্থানীয়ভাবে এমন ডেটা লেখে যা নেটওয়ার্ক ডেটা সোর্সের সাথে সামঞ্জস্যপূর্ণ নয়, তাহলে সিঙ্ক্রোনাইজেশন হওয়ার আগে আপনাকে অবশ্যই এই দ্বন্দ্বটির সমাধান করতে হবে।
দ্বন্দ্ব নিরসনের জন্য প্রায়শই ভার্সনিং-এর প্রয়োজন হয়। কখন পরিবর্তন ঘটেছে তার হিসাব রাখার জন্য অ্যাপটিকে কিছু হিসাবরক্ষণ করতে হয়, যাতে এটি মেটাডেটা নেটওয়ার্ক ডেটা সোর্সে পাঠাতে পারে। এরপর নেটওয়ার্ক ডেটা সোর্সের দায়িত্ব হলো তথ্যের চূড়ান্ত নির্ভরযোগ্য উৎস সরবরাহ করা। অ্যাপ্লিকেশনের প্রয়োজনের উপর নির্ভর করে দ্বন্দ্ব নিরসনের জন্য বিবেচনা করার মতো অনেক কৌশল রয়েছে। মোবাইল অ্যাপের ক্ষেত্রে, একটি প্রচলিত পদ্ধতি হলো "সর্বশেষ লেখাই চূড়ান্ত"।
শেষ লেখাটিই জয়ী হয়
এই পদ্ধতিতে, ডিভাইসগুলো নেটওয়ার্কে লেখা ডেটার সাথে টাইমস্ট্যাম্প মেটাডেটা সংযুক্ত করে। নেটওয়ার্ক ডেটা সোর্স যখন সেগুলো গ্রহণ করে, তখন এটি তার বর্তমান অবস্থার চেয়ে পুরোনো ডেটা বাতিল করে দেয় এবং নতুন ডেটা গ্রহণ করে।
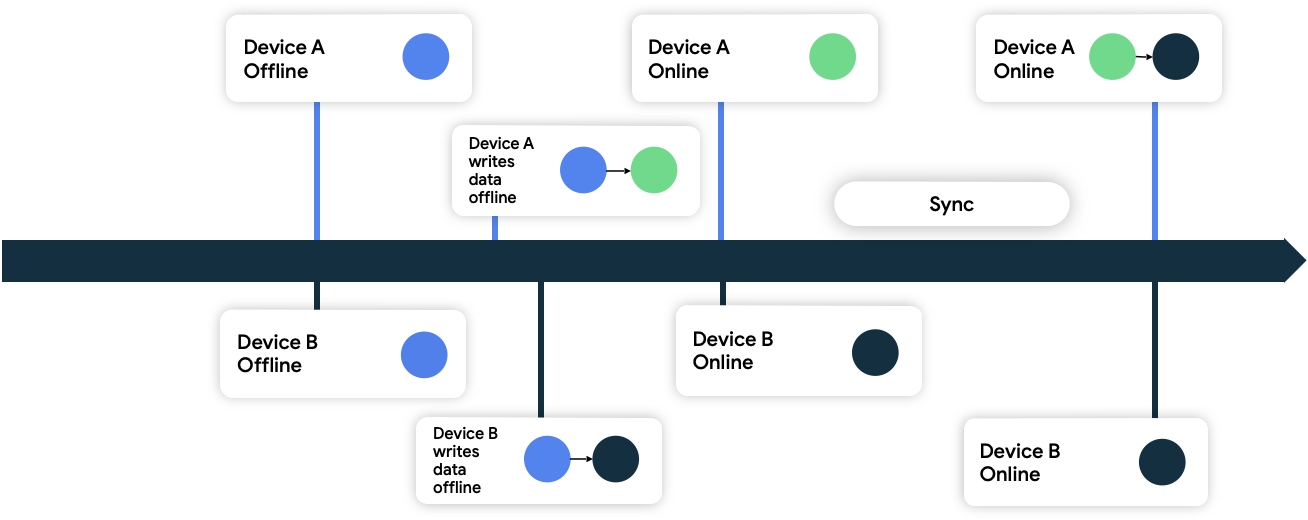
চিত্র ৯-এ, উভয় ডিভাইস অফলাইন এবং প্রাথমিকভাবে নেটওয়ার্ক ডেটা সোর্সের সাথে সিঙ্ক করা আছে। অফলাইন থাকাকালীন, তারা উভয়ই স্থানীয়ভাবে ডেটা লেখে এবং কখন ডেটা লিখেছে তার হিসাব রাখে। যখন তারা উভয়ই আবার অনলাইন হয় এবং নেটওয়ার্ক ডেটা সোর্সের সাথে সিঙ্ক্রোনাইজ করে, তখন নেটওয়ার্কটি ডিভাইস B-এর ডেটা সংরক্ষণ করে দ্বন্দ্বটির সমাধান করে, কারণ ডিভাইস B তার ডেটা পরে লিখেছিল।
অফলাইন-ফার্স্ট অ্যাপে ওয়ার্কম্যানেজার
পূর্বে আলোচিত পঠন ও লিখন উভয় কৌশলেরই দুটি সাধারণ উপযোগিতা রয়েছে:
- সারি
- রিডস: নেটওয়ার্ক সংযোগ পাওয়া না যাওয়া পর্যন্ত রিড স্থগিত রাখতে ব্যবহৃত হয়।
- রাইটস: নেটওয়ার্ক সংযোগ উপলব্ধ না হওয়া পর্যন্ত রাইট স্থগিত রাখতে এবং পুনরায় চেষ্টার জন্য রাইটগুলোকে আবার কিউতে যুক্ত করতে ব্যবহৃত হয়।
- নেটওয়ার্ক সংযোগ মনিটর
- রিডস: অ্যাপটি সংযুক্ত থাকাকালীন রিড কিউ খালি করার সংকেত হিসেবে এবং সিঙ্ক্রোনাইজেশনের জন্য ব্যবহৃত হয়।
- রাইটস: অ্যাপটি সংযুক্ত থাকাকালীন রাইট কিউ খালি করার সংকেত হিসেবে এবং সিনক্রোনাইজেশনের জন্য ব্যবহৃত হয়।
উভয় ক্ষেত্রেই ওয়ার্কম্যানেজার যে ধরনের অবিরাম কাজ করতে পারদর্শী, তার উদাহরণ রয়েছে। উদাহরণস্বরূপ, 'Now in Android' স্যাম্পল অ্যাপটিতে, স্থানীয় ডেটা সোর্স সিঙ্ক্রোনাইজ করার সময় ওয়ার্কম্যানেজারকে রিড কিউ এবং নেটওয়ার্ক মনিটর উভয় হিসেবেই ব্যবহার করা হয়। চালু হওয়ার সময়, অ্যাপটি নিম্নলিখিত কাজগুলো করে:
- স্থানীয় ডেটা উৎস এবং নেটওয়ার্ক ডেটা উৎসের মধ্যে সমতা নিশ্চিত করার জন্য রিড সিনক্রোনাইজেশনের কাজ এনকিউ করা হয়।
- রিড সিনক্রোনাইজেশন কিউ খালি করে এবং অ্যাপটি অনলাইন হলে সিনক্রোনাইজেশন শুরু করে।
- এক্সপোনেনশিয়াল ব্যাকঅফ ব্যবহার করে নেটওয়ার্ক ডেটা সোর্স থেকে ডেটা রিড করা হয়।
- রিডের ফলাফল স্থানীয় ডেটা সোর্সে সংরক্ষণ করে এবং উদ্ভূত যেকোনো দ্বন্দ্বের সমাধান করে।
- অ্যাপের অন্যান্য স্তরগুলোর ব্যবহারের জন্য স্থানীয় ডেটা উৎস থেকে ডেটা উন্মুক্ত করে।
এই ক্রিয়াগুলি নিম্নলিখিত চিত্রে দেখানো হয়েছে:
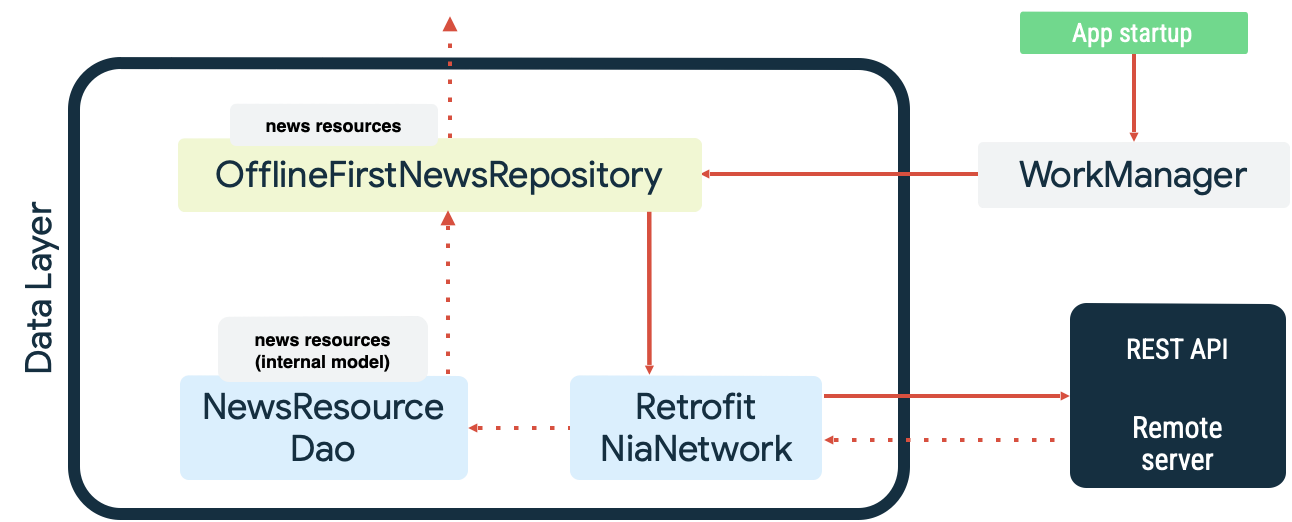
WorkManager-এর সাথে সিঙ্ক্রোনাইজেশন কাজটি কিউতে যুক্ত করার জন্য, KEEP ExistingWorkPolicy ব্যবহার করে এটিকে একটি স্বতন্ত্র কাজ হিসেবে নির্দিষ্ট করতে হয়।
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() কে নিম্নরূপে সংজ্ঞায়িত করা হয়েছে:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
সুনির্দিষ্টভাবে, SyncConstraints দ্বারা সংজ্ঞায়িত Constraints জন্য NetworkType অবশ্যই NetworkType.CONNECTED হতে হয়। অর্থাৎ, এটি চলার আগে নেটওয়ার্ক উপলব্ধ হওয়া পর্যন্ত অপেক্ষা করে।
নেটওয়ার্ক উপলব্ধ হলে, ওয়ার্কার উপযুক্ত Repository ইনস্ট্যান্সগুলিতে দায়িত্ব অর্পণ করে SyncWorkName দ্বারা নির্দিষ্ট অনন্য ওয়ার্ক কিউটি খালি করে। যদি সিঙ্ক্রোনাইজেশন ব্যর্থ হয়, doWork() মেথডটি Result.retry() সহ রিটার্ন করে। WorkManager স্বয়ংক্রিয়ভাবে এক্সপোনেনশিয়াল ব্যাকঅফ সহ সিঙ্ক্রোনাইজেশন পুনরায় চেষ্টা করবে। অন্যথায়, এটি Result.success() রিটার্ন করে, যার মাধ্যমে সিঙ্ক্রোনাইজেশন সম্পন্ন হয়।
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
নমুনা
নিম্নলিখিত গুগল নমুনাগুলি অফলাইন-ফার্স্ট অ্যাপের উদাহরণ। এই নির্দেশনাটি বাস্তবে দেখতে এগুলি ঘুরে দেখুন:
আপনার জন্য প্রস্তাবিত
- দ্রষ্টব্য: জাভাস্ক্রিপ্ট বন্ধ থাকলেও লিঙ্কের লেখা প্রদর্শিত হয়।
- UI রাজ্য উৎপাদন
- UI স্তর
- ডেটা স্তর