
Una app que prioriza el uso sin conexión es aquella que puede realizar toda su funcionalidad principal, o un subconjunto crítico de ella, sin acceso a Internet. Es decir, puede realizar una parte o la totalidad de su lógica empresarial sin conexión.
Las consideraciones para compilar una app que prioriza el uso sin conexión comienzan en la capa de datos, que ofrece acceso a los datos de la aplicación y la lógica empresarial. Es posible que la app deba actualizar estos datos ocasionalmente desde fuentes externas al dispositivo. De esta manera, quizás deba llamar a los recursos de red para estar actualizada.
La disponibilidad de la red no siempre está garantizada. Los dispositivos suelen tener períodos de conexión de red inestable o lenta. Los usuarios pueden experimentar lo siguiente:
- Ancho de banda de Internet limitado
- Interrupciones de conexión transitorias, como en un ascensor o túnel
- Acceso ocasional a los datos (por ejemplo, tablets solo con Wi-Fi)
Sin importar el motivo, a menudo es posible que una app funcione de manera adecuada en estas circunstancias. Para asegurarte de que tu app funcione correctamente sin conexión, esta debe poder hacer lo siguiente:
- Puede seguir usándose sin una conexión de red confiable.
- Presenta a los usuarios datos locales de inmediato en lugar de esperar a que se complete o falle la primera llamada de red.
- Recupera datos de una manera que tenga en cuenta el estado de la batería y los datos (por ejemplo, solicitando la recuperación de datos solo en condiciones óptimas, como cuando se está cargando o con Wi-Fi).
Una app que satisface estos criterios se suele denominar app que prioriza el uso sin conexión.
Cómo diseñar una app que prioriza el uso sin conexión
Cuando diseñes una app que prioriza el uso sin conexión, comienza en la capa de datos y las dos operaciones principales que puedes realizar con los datos de la app:
- Lecturas: Recuperación de datos para que los usen otras partes de la app, como mostrar información al usuario En Compose, por lo general, esto se logra observando el estado. Cuando tu IU observa la fuente de datos local como estado, la pantalla refleja automáticamente los datos locales más recientes.
- Escrituras: Entrada persistente del usuario para su posterior recuperación En Compose, esto se suele lograr con eventos y acciones que se envían desde la IU al ViewModel.
Los repositorios de la capa de datos son responsables de combinar las fuentes de datos para proporcionar datos de la app. En una app que prioriza el uso sin conexión, debe haber al menos una fuente de datos que no necesite acceso a la red para realizar las tareas más importantes. Una de estas tareas es la lectura de datos.
Datos del modelo en una app que prioriza el uso sin conexión
Este tipo de apps tiene un mínimo de 2 fuentes de datos para cada repositorio que usa recursos de red:
- La fuente de datos local
- La fuente de datos de red
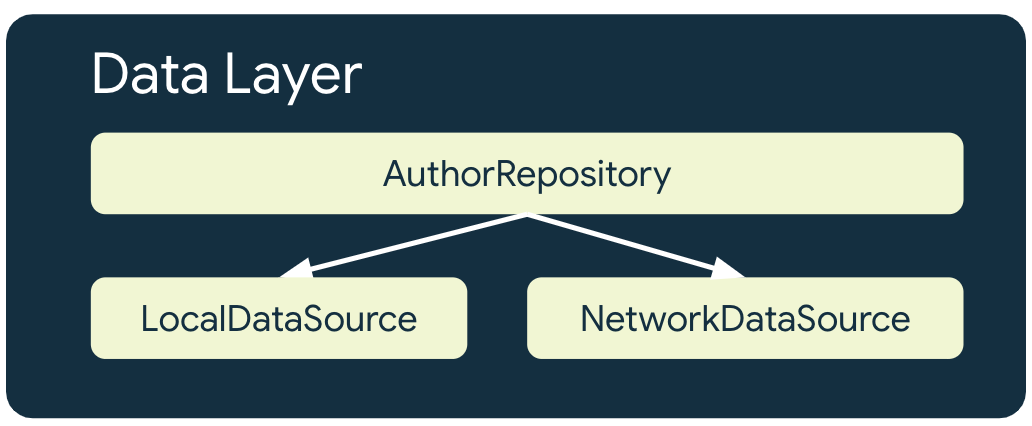
La fuente de datos local
La fuente de datos local es la fuente de confianza canónica de la app. Debe ser la fuente exclusiva de todo dato que lean las capas superiores de la app. Esto garantiza la coherencia de los datos entre los estados de conexión. La fuente de datos local suele estar respaldada por el almacenamiento persistente en el disco. A continuación, se indican algunos medios comunes de persistencia de datos en el disco:
- Fuentes de datos estructurados, como bases de datos relacionales; por ejemplo, Room
- Fuentes de datos no estructurados (por ejemplo, búferes de protocolo con Datastore)
- Archivos simples
La fuente de datos de red
La fuente de datos de red es el estado real de la aplicación. En el mejor de los casos, la fuente de datos local se sincroniza con la fuente de datos de red. La fuente de datos local también puede retrasarse con respecto a la fuente de datos de red, en cuyo caso la app debe actualizarse cuando vuelva a estar en línea. Por el contrario, es posible que la fuente de datos de red se retrase con respecto a la fuente de datos local hasta que la app pueda actualizarla cuando regrese la conectividad. Las capas de dominio y de IU de la app nunca deben comunicarse directamente con la capa de red. Es responsabilidad del host repository comunicarse con ella y usarla para actualizar la fuente de datos local.
Exposición de recursos
La fuente de datos local y la de red pueden diferir fundamentalmente en la forma en que tu app puede leer y escribir en ellas. Consultar una fuente de datos local puede ser rápido y flexible, como cuando se usan consultas en SQL. Por el contrario, las fuentes de datos de red pueden ser lentas y limitadas, como cuando se accede de manera incremental a los recursos RESTful por ID. Como resultado, cada fuente de datos suele necesitar su propia representación de los datos que proporciona. Por lo tanto, la fuente de datos local y la fuente de datos de red pueden tener sus propios modelos.
La siguiente estructura de directorios ayuda a visualizar este concepto. AuthorEntity representa un autor leído desde la base de datos local de la app y NetworkAuthor representa un autor serializado en la red:
data/
├─ local/
│ ├─ entities/
│ │ ├─ AuthorEntity
│ ├─ dao/
│ ├─ NiADatabase
├─ network/
│ ├─ NiANetwork
│ ├─ models/
│ │ ├─ NetworkAuthor
├─ model/
│ ├─ Author
├─ repository/
A continuación, se muestran los detalles de AuthorEntity y NetworkAuthor:
/**
* Network representation of [Author]
*/
@Serializable
data class NetworkAuthor(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
/**
* Defines an author for either an [EpisodeEntity] or [NewsResourceEntity].
* It has a many-to-many relationship with both entities
*/
@Entity(tableName = "authors")
data class AuthorEntity(
@PrimaryKey
val id: String,
val name: String,
@ColumnInfo(name = "image_url")
val imageUrl: String,
@ColumnInfo(defaultValue = "")
val twitter: String,
@ColumnInfo(name = "medium_page", defaultValue = "")
val mediumPage: String,
@ColumnInfo(defaultValue = "")
val bio: String,
)
Se recomienda mantener AuthorEntity y NetworkAuthor de forma interna en la capa de datos y exponer un tercer tipo para que las capas externas lo consuman. Esto protege las capas externas contra cambios menores en las fuentes de datos local y de red que no modifican de manera fundamental el comportamiento de la app. Esto se demuestra en el siguiente fragmento:
/**
* External data layer representation of a "Now in Android" Author
*/
data class Author(
val id: String,
val name: String,
val imageUrl: String,
val twitter: String,
val mediumPage: String,
val bio: String,
)
Luego, el modelo de red puede definir un método de extensión para convertirlo en el modelo local, y el modelo local, de manera similar, tiene uno para convertirlo en la representación externa, como se muestra en el siguiente fragmento:
/**
* Converts the network model to the local model for persisting
* by the local data source
*/
fun NetworkAuthor.asEntity() = AuthorEntity(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
/**
* Converts the local model to the external model for use
* by layers external to the data layer
*/
fun AuthorEntity.asExternalModel() = Author(
id = id,
name = name,
imageUrl = imageUrl,
twitter = twitter,
mediumPage = mediumPage,
bio = bio,
)
Lecturas
Las lecturas son la operación fundamental de los datos de una app que prioriza el uso sin conexión. Por lo tanto, debes asegurarte de que tu app pueda leer los datos y de que, apenas estén disponibles, pueda mostrarlos. Una app que puede hacer esto es una app reactiva porque expone las APIs de lectura con tipos observables.
En el siguiente fragmento, OfflineFirstTopicRepository devuelve Flow para todas sus APIs de lectura. Esto le permite actualizar sus lectores cuando recibe actualizaciones de la fuente de datos de red. En otras palabras, permite que OfflineFirstTopicRepository envíe cambios cuando se invalida su fuente de datos local. Por lo tanto, cada lector de OfflineFirstTopicRepository debe estar preparado para manejar los cambios de datos que se pueden activar cuando se restablece la conectividad de red en la app. Además, OfflineFirstTopicRepository lee los datos directamente desde la fuente de datos local. Solo puede notificar a los lectores sobre los cambios de datos si primero actualiza su fuente de datos local.
class TopicsViewModel(
offlineFirstTopicsRepository: OfflineFirstTopicsRepository
) : ViewModel() {
val topics: StateFlow<List<Topic>> = offlineFirstTopicsRepository.getTopicsStream()
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = emptyList()
)
}
En una app de Jetpack Compose, usa un ViewModel para conectar la capa de datos y la IU.
En el ViewModel, convierte el Flow en un StateFlow con el operador stateIn. Luego, los elementos componibles recopilan esos estados con collectAsStateWithLifecycle() y administran automáticamente las suscripciones de una manera que tiene en cuenta el ciclo de vida.
Para obtener más información sobre collectAsStateWithLifecycle(), consulta El estado y Jetpack Compose.
Estrategias de manejo de errores
Existen formas únicas de manejar los errores en las apps que priorizan el uso sin conexión, según las fuentes de datos en las que pueden ocurrir. Estas estrategias se describen en las siguientes subsecciones.
Fuente de datos locales
Intenta minimizar los errores cuando leas desde la fuente de datos local. Para proteger a los lectores de los errores, usa el operador catch en los Flow de los que recopila datos.
Puedes usar el operador catch en un ViewModel de la siguiente manera:
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information
private val authorStream: Flow<Author> =
authorsRepository.getAuthorStream(
id = authorId
)
.catch { emit(Author.empty()) }
}
Para un enfoque más resistente, considera una solución de LCE (error de carga de contenido). En LCE, cuando hay una falla durante la lectura, se muestra un estado de error. Por lo general, se logra el LCE modelando los estados de la IU como clases selladas de Kotlin.
// Define the LCE UI state
sealed interface AuthorUiState {
data object Loading : AuthorUiState
data class Success(val author: Author) : AuthorUiState
data object Error : AuthorUiState
}
class AuthorViewModel(
authorsRepository: AuthorsRepository,
...
) : ViewModel() {
private val authorId: String = ...
// Observe author information and map to LCE state
val authorUiState: StateFlow<AuthorUiState> =
authorsRepository.getAuthorStream(id = authorId)
.map<Author, AuthorUiState> { author ->
AuthorUiState.Success(author)
}
.catch { emit(AuthorUiState.Error) }
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = AuthorUiState.Loading
)
}
Fuente de datos de red
Si se producen errores cuando se leen datos desde una fuente de datos de red, la app deberá emplear una heurística para reintentar la recuperación de datos. Entre las heurísticas comunes, se incluyen las siguientes:
Retirada exponencial
En la retirada exponencial, la app sigue intentando leer desde la fuente de datos de red con intervalos de tiempo cada vez más altos hasta que tiene éxito o hasta que otras condiciones indiquen que debe detenerse.
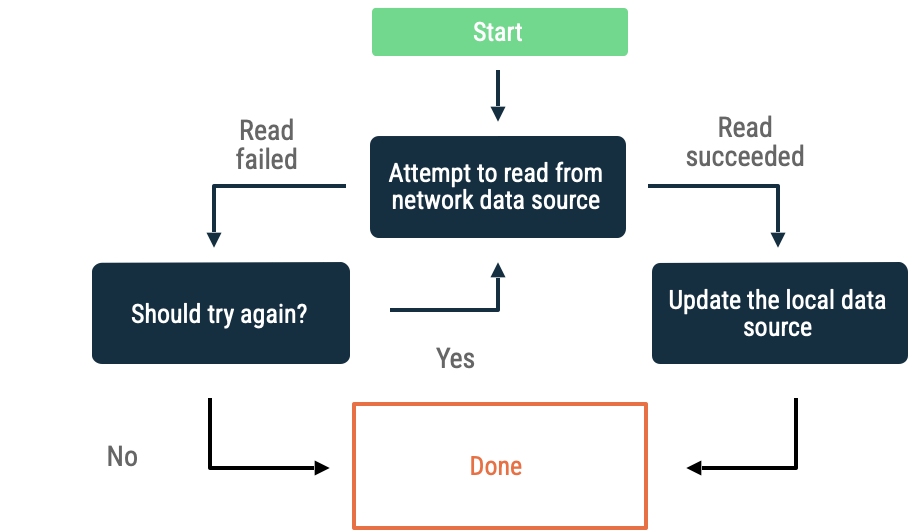
Los criterios para evaluar si la app debe seguir retirándose incluyen los siguientes:
- Es el tipo de error que indicó la fuente de datos de red. Por ejemplo, reintenta las llamadas de red que muestran un error que indica falta de conectividad. No reintentes las solicitudes HTTP que no están autorizadas hasta que las credenciales adecuadas estén disponibles.
- Cantidad máxima de reintentos permitidos
Supervisión de conectividad de red
En este enfoque, las solicitudes de lectura se ponen en cola hasta que la app está segura de que puede conectarse a la fuente de datos de red. Una vez que se establece una conexión, se quita de la cola la solicitud de lectura, se leen los datos y se actualiza la fuente de datos local. En Android, esta cola se puede mantener con una base de datos de Room y se vacía como trabajo persistente con WorkManager.
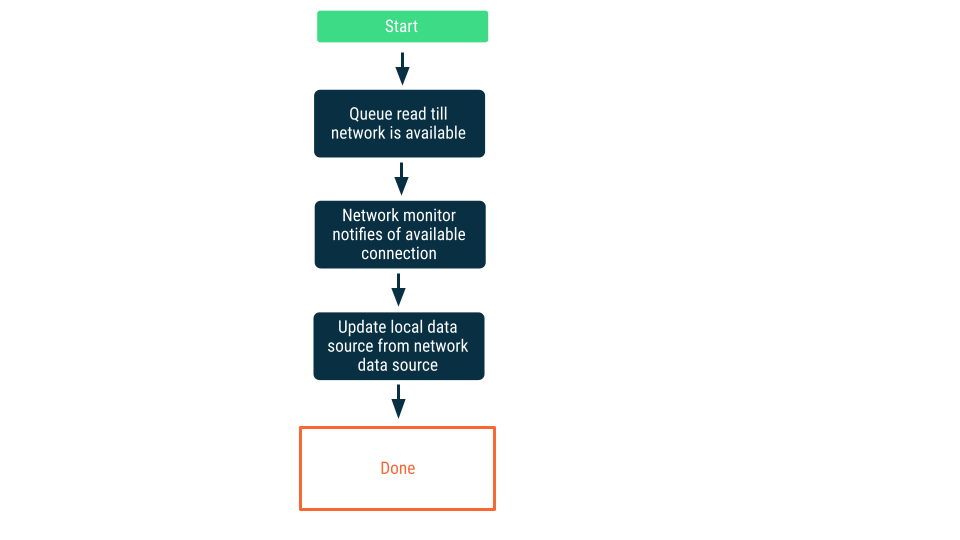
Escrituras
Si bien la forma recomendada de leer datos en una app que prioriza el uso sin conexión es usar tipos observables, el equivalente para las APIs de escritura son las APIs asíncronas, como las funciones de suspensión. Esto evita el bloqueo del subproceso de IU y ayuda con el manejo de errores, ya que las operaciones de escritura en las apps que priorizan el uso sin conexión pueden fallar cuando se cruza un límite de red.
interface UserDataRepository {
/**
* Updates the bookmarked status for a news resource
*/
suspend fun updateNewsResourceBookmark(newsResourceId: String, bookmarked: Boolean)
}
En el fragmento anterior, la API asíncrona elegida es Corrutinas porque se suspende el método.
Estrategias de escritura
Cuando se escriben datos en apps que priorizan el uso sin conexión, se deben considerar tres estrategias. La elección depende del tipo de datos que se escriben y de los requisitos de la app:
Escrituras solo en línea
Intento de escribir los datos a través del límite de la red. Si se ejecuta de forma correcta, actualiza la fuente de datos local; de lo contrario, arroja una excepción y déjala al emisor para que la responda de forma adecuada.
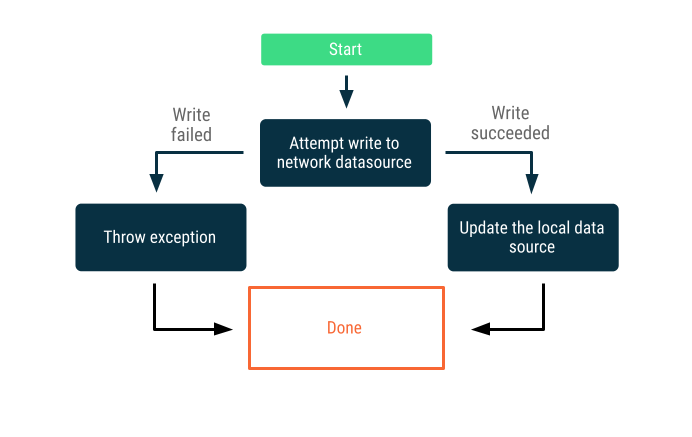
A menudo, esta estrategia se usa para transacciones de escritura que deben realizarse en línea casi en tiempo real, por ejemplo, una transferencia bancaria. Dado que las escrituras pueden fallar, suele ser necesario comunicarle al usuario que la escritura falló o evitar que el usuario intente escribir datos en primer lugar. Estas son algunas estrategias que puedes emplear en estas situaciones:
- Si una app requiere acceso a Internet para escribir datos, puedes optar por no presentarle una IU al usuario que le permita escribir datos o, al menos, puedes inhabilitarla.
- Puedes usar un
AlertDialogque el usuario no pueda descartar o unSnackbarpara notificarle que no tiene conexión.
Escrituras en cola
Cuando tengas un objeto que quieras escribir, inclúyelo en una cola. Cuando la app vuelva a estar en línea, vacía la cola con la retirada exponencial. En Android, el vaciado de una cola sin conexión es un trabajo persistente que, a menudo, se delega a WorkManager.
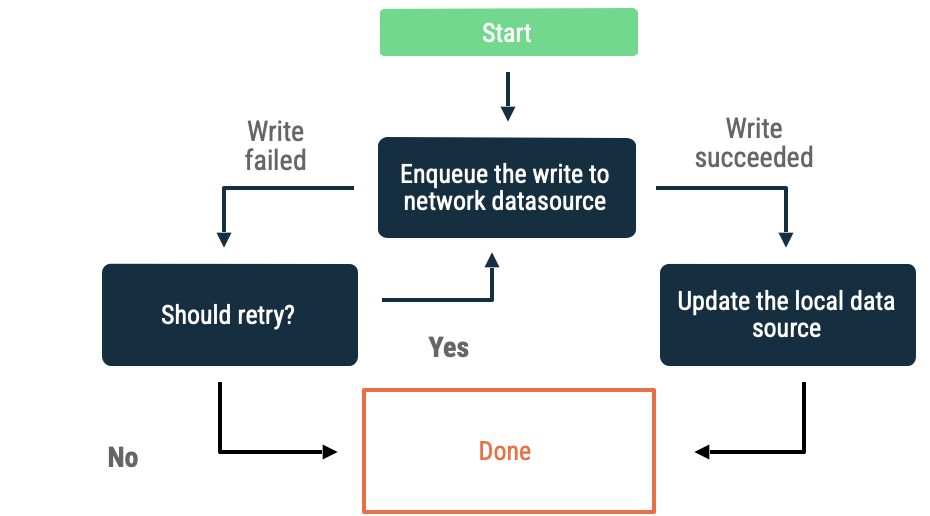
Este enfoque es una buena opción en las siguientes situaciones:
- No es esencial que los datos se escriban en la red.
- La transacción no es urgente.
- No es esencial que se informe al usuario si la operación falla.
Los casos de uso de este enfoque incluyen los eventos de estadísticas y registros.
Escrituras diferidas
Primero, escribe en la fuente de datos local y, luego, pon en cola la escritura para notificar a la red lo antes posible. Esto no es trivial, ya que puede haber conflictos entre las fuentes de datos local y de red cuando la app vuelve a estar en línea. En la siguiente sección sobre resolución de conflictos, se proporcionan más detalles.

Este enfoque es la opción correcta cuando los datos son fundamentales para la app. Por ejemplo, en una app de lista de tareas pendientes que prioriza el uso sin conexión, es esencial que las tareas que agrega el usuario sin conexión se almacenen de forma local para evitar el riesgo de pérdida de datos.
Sincronización y resolución de conflictos
Cuando una app que prioriza el uso sin conexión restablece su conectividad, necesita conciliar los datos de su fuente de datos local con los de la fuente de datos de red. Este proceso se denomina sincronización. Hay dos formas principales en que una app puede sincronizarse con su fuente de datos de red:
- Sincronización basada en extracciones
- Sincronización basada en envíos
Sincronización basada en extracciones
En la sincronización basada en extracciones, la app se comunica con la red para leer los últimos datos de la aplicación a pedido. Una heurística común para este enfoque se basa en la navegación, en la que la app solo recupera datos justo antes de presentárselos al usuario.
Este enfoque funciona mejor cuando la app espera períodos breves o intermedios sin conectividad de red. Esto se debe a que la actualización de datos es oportunista y los períodos largos sin conectividad aumentan las probabilidades de que el usuario intente visitar destinos de la app con una caché inactiva o vacía.
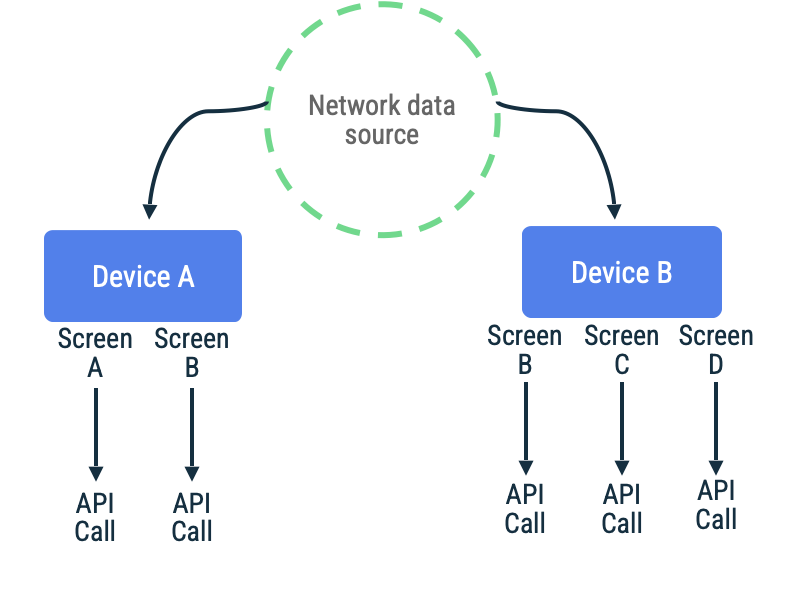
Considera una app en la que los tokens de página se usan para recuperar elementos en una lista de desplazamiento infinito para una pantalla en particular. La implementación puede llegar a la red de forma diferida, conservar los datos en la fuente de datos local y, luego, leer desde esa fuente para presentarle información al usuario. En caso de que no haya conectividad de red, el repositorio puede solicitar datos de la fuente de datos local solamente. Este es el patrón que usa la biblioteca de paginación de Jetpack con su API de RemoteMediator.
class FeedRepository(...) {
fun feedPagingSource(): PagingSource<FeedItem> { ... }
}
class FeedViewModel(
private val repository: FeedRepository
) : ViewModel() {
private val pager = Pager(
config = PagingConfig(
pageSize = NETWORK_PAGE_SIZE,
enablePlaceholders = false
),
remoteMediator = FeedRemoteMediator(...),
pagingSourceFactory = feedRepository::feedPagingSource
)
val feedPagingData = pager.flow
}
Las ventajas y las desventajas de la sincronización basada en extracciones se resumen en la siguiente tabla:
| Ventajas | Desventajas |
|---|---|
| Relativamente fácil de implementar. | Propensa al uso intensivo de datos. Esto se debe a que las visitas repetidas a un destino de navegación activan la recuperación innecesaria de información sin cambios. Puedes mitigar esto a través del almacenamiento en caché adecuado. Esto se puede hacer en la capa de la IU con el operador cachedIn o en la capa de red con una caché HTTP. |
| Los datos que no son necesarios nunca se recuperan. | No se ajusta bien con los datos relacionales, ya que el modelo extraído debe ser autosuficiente. Si el modelo que se sincroniza depende de otros modelos que se deben recuperar para propagarse, el problema del uso intensivo de datos mencionado antes se vuelve aún más significativo. Además, puede causar dependencias entre los repositorios del modelo principal y los repositorios del modelo anidado. |
Sincronización basada en envíos
En la sincronización basada en envíos, la fuente de datos local intenta imitar un conjunto de réplicas de la fuente de datos de red lo mejor que puede. Recupera de forma proactiva una cantidad adecuada de datos en el primer inicio para establecer un modelo de referencia. Después de eso, depende de las notificaciones del servidor para alertarlo cuando esos datos están inactivos.
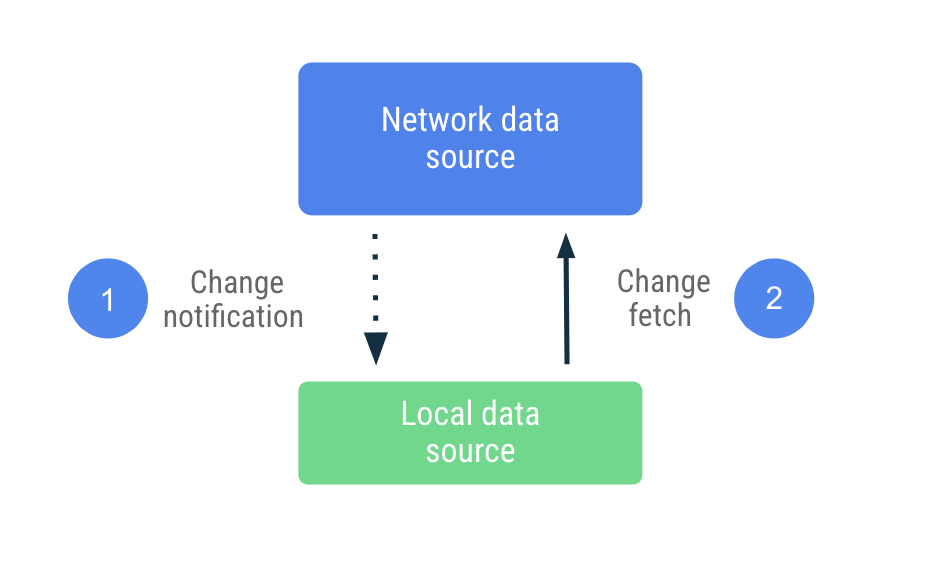
Cuando se recibe la notificación inactiva, la app se comunica con la red para actualizar solo los datos que se marcaron como inactivos. Este trabajo se delega al Repository, que se comunica con la fuente de datos de red y conserva los datos recuperados en la fuente de datos local. Dado que el repositorio expone sus datos con tipos observables, los lectores reciben una notificación sobre cualquier cambio.
class UserDataRepository(...) {
suspend fun synchronize() {
val userData = networkDataSource.fetchUserData()
localDataSource.saveUserData(userData)
}
}
En este enfoque, la app depende mucho menos de la fuente de datos de red y puede funcionar sin ella durante períodos prolongados. Ofrece acceso de lectura y escritura cuando está sin conexión porque se supone que tiene la información más reciente de la fuente de datos de red de manera local.
Las ventajas y las desventajas de la sincronización basada en envíos se resumen en la siguiente tabla:
| Ventajas | Desventajas |
|---|---|
| La app puede permanecer sin conexión indefinidamente. | Los datos del control de versiones para la resolución de conflictos no son triviales. |
| Uso mínimo de datos. La app solo recupera los datos que cambiaron. | Debes tener en cuenta las inquietudes de escritura durante la sincronización. |
| Funciona bien con los datos relacionales. Cada repositorio es responsable de recuperar los datos solo del modelo que admite. | La fuente de datos de red debe ser compatible con la sincronización. |
Sincronización híbrida
Algunas apps usan un enfoque híbrido que se basa en extracciones o envíos según los datos. Por ejemplo, una app de redes sociales puede usar la sincronización basada en extracciones para obtener el siguiente feed del usuario a pedido debido a la alta frecuencia de las actualizaciones del feed. La misma app puede optar por usar la sincronización basada en envíos para los datos sobre el usuario que accedió, lo que incluye su nombre de usuario, la foto de perfil, etc.
En última instancia, la opción de sincronización que prioriza el uso sin conexión depende de los requisitos del producto y de la infraestructura técnica disponible.
Resolución de conflictos
Si, cuando no hay conexión, la app escribe datos de forma local que no están alineados con la fuente de datos de la red, debes resolver el conflicto antes de que se pueda realizar la sincronización.
La resolución de conflictos a menudo requiere control de versiones. La app deberá llevar un registro de cuándo se produjeron los cambios para poder pasar los metadatos a la fuente de datos de red. La fuente de datos de red tiene la responsabilidad de proporcionar la fuente de confianza absoluta. Existen muchas estrategias para resolver los conflictos, según las necesidades de la aplicación. En el caso de las apps para dispositivos móviles, un enfoque común es el de la "prevalencia de la última escritura".
Prevalencia de la última escritura
En este enfoque, los dispositivos adjuntan metadatos de marca de tiempo a los datos que escriben en la red. Cuando la fuente de datos de red los recibe, descarta los datos más antiguos que su estado actual y acepta los más nuevos que su estado actual.
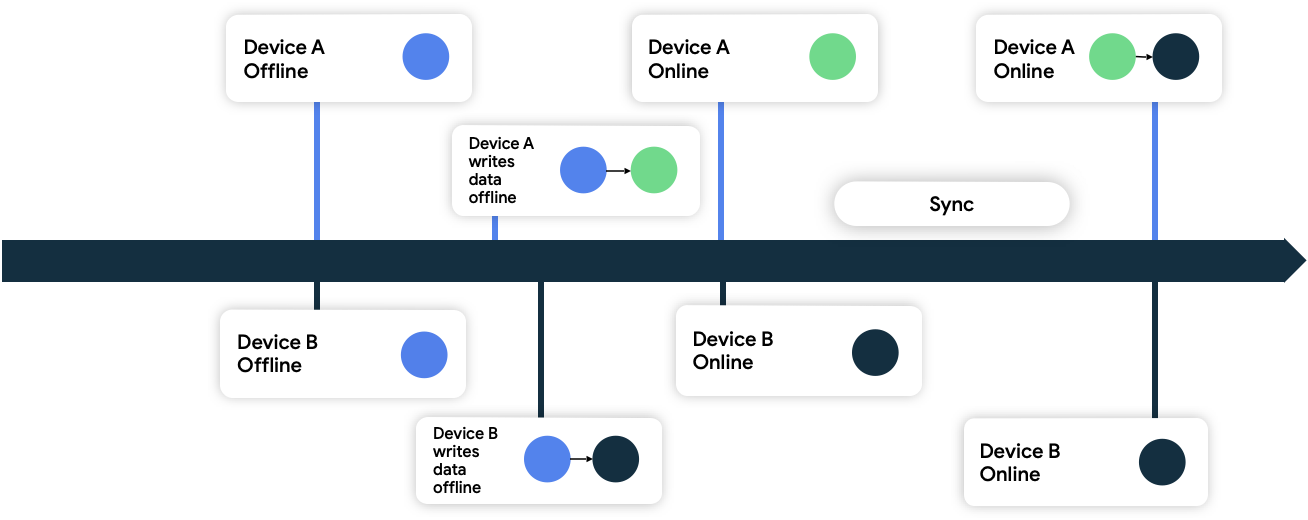
En la figura 9, ambos dispositivos están sin conexión y, al principio, están sincronizados con la fuente de datos de red. Mientras están sin conexión, ambos escriben datos de forma local y realizan un seguimiento del tiempo en el que los escribieron. Cuando ambos vuelven a estar en línea y se sincronizan con la fuente de datos de red, la red resuelve el conflicto mediante la persistencia de los datos del dispositivo B, ya que los escribió más tarde.
WorkManager en apps que priorizan el uso sin conexión
En las estrategias de lectura y escritura que se trataron antes, hay dos utilidades comunes:
- Colas
- Lecturas: Se usan para diferir las lecturas hasta que la conectividad de red esté disponible.
- Escrituras: Se usan para diferir las escrituras hasta que la conectividad de red esté disponible y volver a poner en cola las escrituras para los reintentos.
- Supervisores de conectividad de red
- Lecturas: Se usan como indicador para vaciar la cola de lectura cuando la app está conectada y para la sincronización.
- Escrituras: Se usan como indicador para vaciar la cola de escritura cuando la app está conectada y para la sincronización.
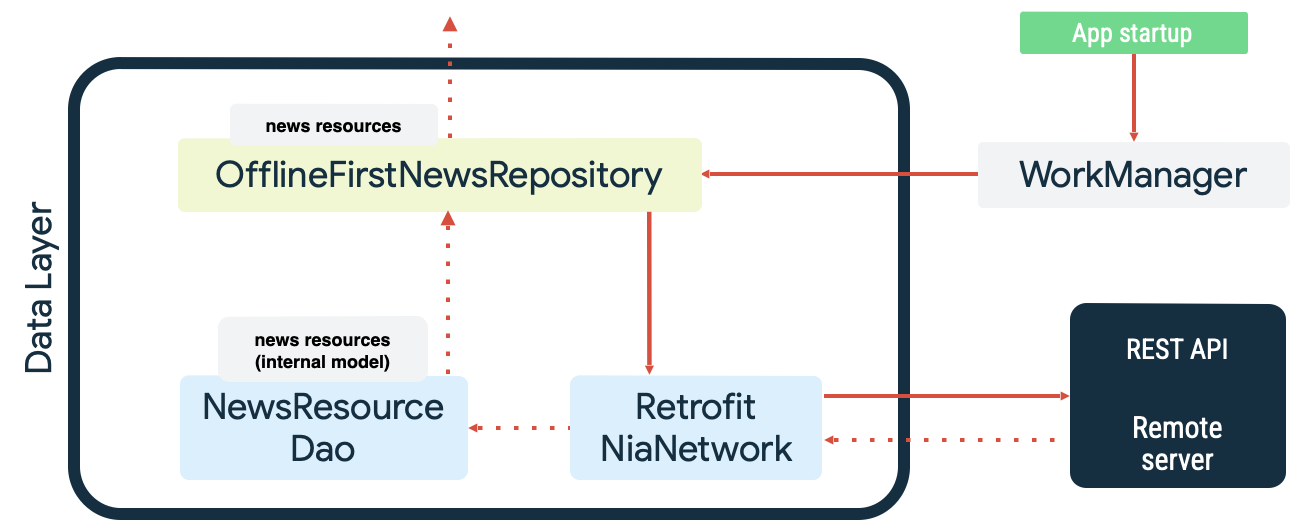
Ambos casos son ejemplos del trabajo persistente en el que WorkManager se destaca. Por ejemplo, en la app de ejemplo Now in Android, WorkManager se usa como supervisor de cola de lectura y como un supervisor de red cuando se sincroniza la fuente de datos local. Durante el inicio, la app hace lo siguiente:
- Pone en cola el trabajo de sincronización de lectura para asegurarse de que haya paridad entre la fuente de datos local y la de red.
- Vacía la cola de sincronización de lectura y comienza a sincronizar cuando la app está en línea.
- Realiza una lectura desde la fuente de datos de red con retirada exponencial.
- Conserva los resultados de la lectura en la fuente de datos local y resuelve cualquier conflicto que ocurra.
- Expone los datos de la fuente de datos local para que los consuman otras capas de la app.
Estas acciones se ilustran en el siguiente diagrama:
Para poner en cola el trabajo de sincronización con WorkManager, debes especificarlo como trabajo único con KEEP ExistingWorkPolicy:
class SyncInitializer : Initializer<Sync> {
override fun create(context: Context): Sync {
WorkManager.getInstance(context).apply {
// Queue sync on app startup and ensure only one
// sync worker runs at any time
enqueueUniqueWork(
SyncWorkName,
ExistingWorkPolicy.KEEP,
SyncWorker.startUpSyncWork()
)
}
return Sync
}
}
SyncWorker.startupSyncWork() se define de la siguiente manera:
/**
Create a WorkRequest to call the SyncWorker using a DelegatingWorker.
This allows for dependency injection into the SyncWorker in a different
module than the app module without having to create a custom WorkManager
configuration.
*/
fun startUpSyncWork() = OneTimeWorkRequestBuilder<DelegatingWorker>()
// Run sync as expedited work if the app is able to.
// If not, it runs as regular work.
.setExpedited(OutOfQuotaPolicy.RUN_AS_NON_EXPEDITED_WORK_REQUEST)
.setConstraints(SyncConstraints)
// Delegate to the SyncWorker.
.setInputData(SyncWorker::class.delegatedData())
.build()
val SyncConstraints
get() = Constraints.Builder()
.setRequiredNetworkType(NetworkType.CONNECTED)
.build()
Específicamente, Constraints definido por SyncConstraints requiere que NetworkType sea NetworkType.CONNECTED. Es decir, espera hasta que la red esté disponible antes de ejecutarse.
Una vez que la red está disponible, Worker vacía la cola de trabajo única especificada por SyncWorkName mediante la delegación de las instancias Repository correspondientes. Si la sincronización falla, el método doWork() se muestra con Result.retry(). WorkManager volverá a intentar la sincronización con la retirada exponencial automáticamente. De lo contrario, muestra Result.success() y completa la sincronización.
class SyncWorker(...) : CoroutineWorker(appContext, workerParams), Synchronizer {
override suspend fun doWork(): Result = withContext(ioDispatcher) {
// First sync the repositories in parallel
val syncedSuccessfully = awaitAll(
async { topicRepository.sync() },
async { authorsRepository.sync() },
async { newsRepository.sync() },
).all { it }
if (syncedSuccessfully) Result.success()
else Result.retry()
}
}
Ejemplos
En los siguientes ejemplos de Google, se muestran las apps que priorizan el uso sin conexión. Explóralos para ver esta guía en práctica:
Recomendaciones para ti
- Nota: El texto del vínculo se muestra cuando JavaScript está desactivado
- Producción del estado de la IU
- Capa de la IU
- Capa de datos