
Android Neural Networks API (NNAPI) to interfejs C API na Androida przeznaczony do uruchamiania na urządzeniach z Androidem operacji wymagających dużej mocy obliczeniowej na potrzeby uczenia maszynowego. NNAPI ma zapewniać podstawową warstwę funkcji dla platform uczenia maszynowego wyższego poziomu, takich jak TensorFlow Lite i Caffe2, które tworzą i trenują sieci neuronowe. Interfejs API jest dostępny na wszystkich urządzeniach z Androidem 8.1 (interfejs API na poziomie 27) lub nowszym, ale został wycofany w Androidzie 15.
NNAPI obsługuje wnioskowanie przez stosowanie danych z urządzeń z Androidem do wcześniej wytrenowanych modeli zdefiniowanych przez dewelopera. Przykłady wnioskowania to klasyfikowanie obrazów, przewidywanie zachowań użytkowników i wybieranie odpowiednich odpowiedzi na zapytanie.
Wnioskowanie na urządzeniu ma wiele zalet:
- Opóźnienie: nie musisz wysyłać żądania przez połączenie sieciowe ani czekać na odpowiedź. Może to być na przykład kluczowe w przypadku aplikacji wideo, które przetwarzają kolejne klatki pochodzące z kamery.
- Dostępność: aplikacja działa nawet poza zasięgiem sieci.
- Szybkość: nowy sprzęt przeznaczony do przetwarzania sieci neuronowych zapewnia znacznie szybsze obliczenia niż sam procesor do zwykłych obciążeń.
- Prywatność: dane nie opuszczają urządzenia z Androidem.
- Koszt: nie jest potrzebna farma serwerów, ponieważ wszystkie obliczenia są wykonywane na urządzeniu z Androidem.
Deweloper powinien też pamiętać o pewnych kompromisach:
- Wykorzystanie systemu: ocena sieci neuronowych wymaga wielu obliczeń, co może zwiększyć zużycie baterii. Jeśli stan baterii jest ważny dla Twojej aplikacji, zwłaszcza w przypadku długotrwałych obliczeń, warto go monitorować.
- Rozmiar aplikacji: zwróć uwagę na rozmiar modeli. Modele mogą zajmować kilka megabajtów miejsca. Jeśli dołączenie dużych modeli do pliku APK miałoby niekorzystny wpływ na użytkowników, możesz rozważyć pobranie modeli po zainstalowaniu aplikacji, użycie mniejszych modeli lub uruchomienie obliczeń w chmurze. NNAPI nie udostępnia funkcji do uruchamiania modeli w chmurze.
Przykład użycia interfejsu NNAPI znajdziesz w przykładowym kodzie interfejsu Android Neural Networks API.
Informacje o środowisku wykonawczym interfejsu Neural Networks API
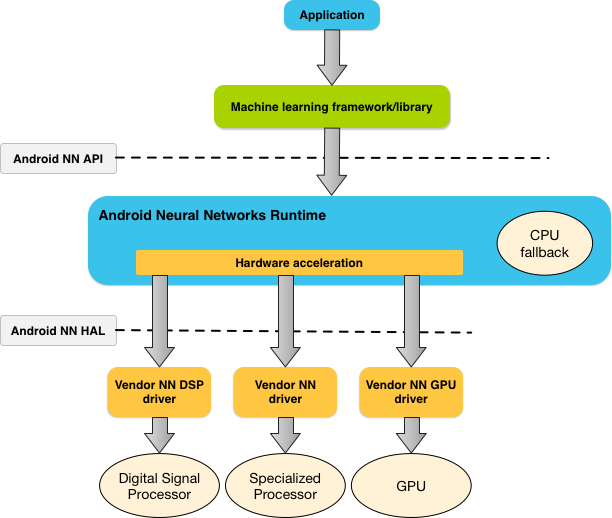
NNAPI jest przeznaczony do wywoływania przez biblioteki, platformy i narzędzia do uczenia maszynowego, które umożliwiają deweloperom trenowanie modeli poza urządzeniem i wdrażanie ich na urządzeniach z Androidem. Aplikacje zwykle nie korzystają bezpośrednio z NNAPI, ale używają platform uczenia maszynowego wyższego poziomu. Te platformy mogą z kolei używać NNAPI do wykonywania operacji wnioskowania z akceleracją sprzętową na obsługiwanych urządzeniach.
Na podstawie wymagań aplikacji i możliwości sprzętowych urządzenia z Androidem środowisko wykonawcze sieci neuronowych Androida może efektywnie rozdzielać obciążenie obliczeniowe między dostępne na urządzeniu procesory, w tym dedykowany sprzęt sieci neuronowych, procesory graficzne (GPU) i procesory sygnałowe (DSP).
W przypadku urządzeń z Androidem, które nie mają specjalistycznego sterownika dostawcy, środowisko wykonawcze NNAPI wykonuje żądania na procesorze.
Rysunek 1 przedstawia architekturę systemu NNAPI.
Model programowania interfejsu Neural Networks API
Aby wykonywać obliczenia za pomocą NNAPI, musisz najpierw utworzyć skierowany graf, który definiuje obliczenia do wykonania. Ten graf obliczeniowy w połączeniu z danymi wejściowymi (np. wagami i odchyleniami przekazywanymi z platformy uczenia maszynowego) tworzy model do oceny środowiska wykonawczego NNAPI.
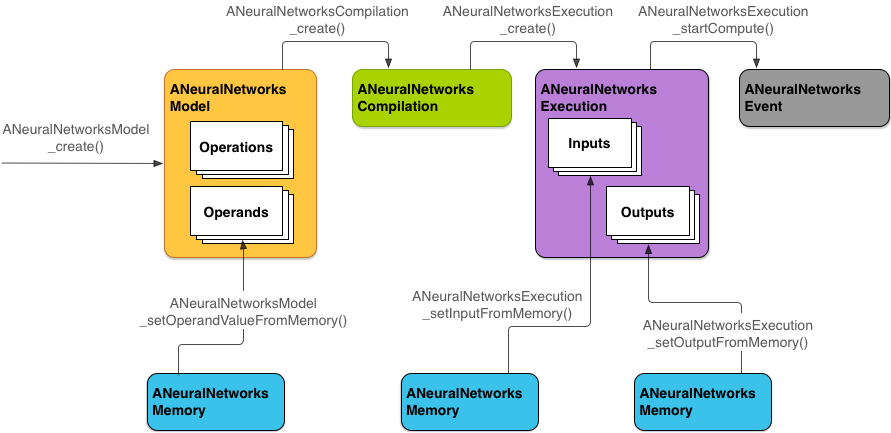
NNAPI korzysta z 4 głównych abstrakcji:
- Model: graf obliczeniowy operacji matematycznych i stałych wartości wyuczonych w procesie trenowania. Te operacje są specyficzne dla sieci neuronowych. Są to m.in. konwolucja 2D, aktywacja logistyczna (sigmoid), aktywacja liniowa z prostownikiem (ReLU) i inne. Tworzenie modelu to operacja synchroniczna.
Po utworzeniu można go używać w różnych wątkach i kompilacjach.
W NNAPI model jest reprezentowany jako instancja
ANeuralNetworksModel. - Kompilacja: reprezentuje konfigurację kompilowania modelu NNAPI do kodu niższego poziomu. Tworzenie kompilacji jest operacją synchroniczną. Po utworzeniu można go używać ponownie w różnych wątkach i wykonaniach. W NNAPI każda kompilacja jest reprezentowana jako instancja
ANeuralNetworksCompilation. - Pamięć: reprezentuje pamięć współdzieloną, pliki mapowane w pamięci i podobne bufory pamięci. Korzystanie z bufora pamięci umożliwia środowisku wykonawczemu NNAPI wydajniejsze przesyłanie danych do sterowników. Aplikacja zwykle tworzy jeden bufor pamięci współdzielonej, który zawiera wszystkie tensory potrzebne do zdefiniowania modelu. Możesz też używać buforów pamięci do przechowywania danych wejściowych i wyjściowych instancji wykonania. W NNAPI każdy bufor pamięci jest reprezentowany jako instancja
ANeuralNetworksMemory. Wykonanie: interfejs do stosowania modelu NNAPI do zestawu danych wejściowych i zbierania wyników. Wykonanie może być synchroniczne lub asynchroniczne.
W przypadku wykonywania asynchronicznego wiele wątków może oczekiwać na to samo wykonanie. Po zakończeniu tego wykonania wszystkie wątki zostaną zwolnione.
W NNAPI każde wykonanie jest reprezentowane jako instancja
ANeuralNetworksExecution.
Rysunek 2 przedstawia podstawowy proces programowania.
W pozostałej części tej sekcji opisujemy, jak skonfigurować model NNAPI do wykonywania obliczeń, skompilować go i uruchomić.
Udostępnianie danych treningowych
Dane wytrenowanych wag i odchyleń są prawdopodobnie przechowywane w pliku. Aby zapewnić środowisku wykonawczemu NNAPI wydajny dostęp do tych danych, utwórz instancję ANeuralNetworksMemory, wywołując funkcję ANeuralNetworksMemory_createFromFd() i przekazując deskryptor pliku otwartego pliku danych. Możesz też określić flagi ochrony pamięci i przesunięcie, od którego zaczyna się w pliku region pamięci współdzielonej.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
W tym przykładzie używamy tylko 1 instancji ANeuralNetworksMemory
dla wszystkich wag, ale można użyć więcej niż 1 instancji ANeuralNetworksMemory w przypadku wielu plików.
Używanie natywnych buforów sprzętowych
W przypadku danych wejściowych i wyjściowych modelu oraz stałych wartości operandów możesz używać natywnych buforów sprzętowych. W niektórych przypadkach akcelerator NNAPI może uzyskiwać dostęp do obiektówAHardwareBuffer bez konieczności kopiowania danych przez sterownik. AHardwareBuffer ma wiele różnych konfiguracji i nie każdy akcelerator NNAPI może obsługiwać wszystkie te konfiguracje. Ze względu na to ograniczenie zapoznaj się z ograniczeniami wymienionymi w ANeuralNetworksMemory_createFromAHardwareBufferdokumentacji i przeprowadź testy na urządzeniach docelowych, aby upewnić się, że kompilacje i wykonania korzystające z AHardwareBuffer działają zgodnie z oczekiwaniami. Użyj przypisywania urządzeń, aby określić akcelerator.
Aby umożliwić środowisku wykonawczemu NNAPI dostęp do obiektu AHardwareBuffer, utwórz instancję ANeuralNetworksMemory, wywołując funkcję ANeuralNetworksMemory_createFromAHardwareBuffer i przekazując obiekt AHardwareBuffer, jak pokazano w tym przykładowym kodzie:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Gdy NNAPI nie potrzebuje już dostępu do obiektu AHardwareBuffer, zwolnij odpowiednią instancję ANeuralNetworksMemory:
ANeuralNetworksMemory_free(mem2);
Uwaga:
- Możesz używać parametru
AHardwareBuffertylko w przypadku całego bufora. Nie możesz go używać z parametremARect. - Środowisko wykonawcze NNAPI nie opróżni bufora. Przed zaplanowaniem wykonania musisz się upewnić, że bufory wejściowe i wyjściowe są dostępne.
- Deskryptory plików bariery synchronizacji nie są obsługiwane.
- W przypadku
AHardwareBufferz formatami i bitami użycia specyficznymi dla dostawcy to implementacja dostawcy określa, czy za opróżnianie pamięci podręcznej odpowiada klient czy sterownik.
Model
Model to podstawowa jednostka obliczeniowa w NNAPI. Każdy model jest definiowany przez co najmniej 1 operand i operację.
Operandy
Operandy to obiekty danych używane do definiowania grafu. Obejmują one dane wejściowe i wyjściowe modelu, węzły pośrednie zawierające dane przepływające z jednej operacji do drugiej oraz stałe przekazywane do tych operacji.
Do modeli NNAPI można dodawać 2 rodzaje operandów: skalary i tensory.
Skalar to pojedyncza wartość. NNAPI obsługuje wartości skalarne w formatach logicznym, 16-bitowym zmiennoprzecinkowym, 32-bitowym zmiennoprzecinkowym, 32-bitowym całkowitym i 32-bitowym całkowitym bez znaku.
Większość operacji w NNAPI obejmuje tensory. Tensory to tablice n-wymiarowe. NNAPI obsługuje tensory z 16-bitowymi wartościami zmiennoprzecinkowymi, 32-bitowymi wartościami zmiennoprzecinkowymi, 8-bitowymi wartościami skwantowanymi, 16-bitowymi wartościami skwantowanymi, 32-bitowymi wartościami całkowitymi i 8-bitowymi wartościami logicznymi.
Na przykład rysunek 3 przedstawia model z 2 operacjami: dodawaniem, a następnie mnożeniem. Model pobiera tensor wejściowy i generuje jeden tensor wyjściowy.
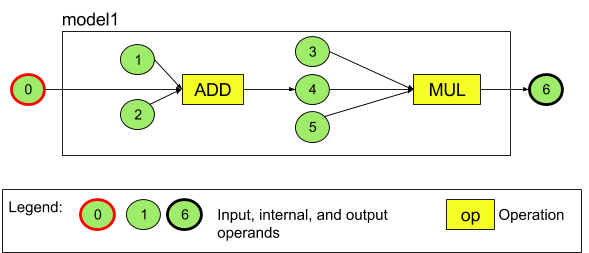
Powyższy model ma 7 operandów. Te operandy są identyfikowane niejawnie przez indeks kolejności, w jakiej są dodawane do modelu. Pierwszy dodany operand ma indeks 0, drugi – 1 itd. Operandy 1, 2, 3 i 5 są operandami stałymi.
Kolejność dodawania operandów nie ma znaczenia. Na przykład operand wyjściowy modelu może być pierwszym dodanym operandem. Ważne jest, aby podczas odwoływania się do operandu używać prawidłowej wartości indeksu.
Operandy mają typy. Są one określane w momencie dodawania ich do modelu.
Operandu nie można używać jednocześnie jako danych wejściowych i wyjściowych modelu.
Każdy operand musi być danymi wejściowymi modelu, stałą lub operandem wyjściowym dokładnie jednej operacji.
Więcej informacji o używaniu operandów znajdziesz w artykule Więcej informacji o operandach.
Operacje
Operacja określa obliczenia, które mają zostać wykonane. Każda operacja składa się z tych elementów:
- typ operacji (np. dodawanie, mnożenie, splot);
- lista indeksów operandów, których operacja używa jako danych wejściowych,
- lista indeksów operandów, których operacja używa do danych wyjściowych.
Kolejność na tych listach ma znaczenie. Oczekiwane dane wejściowe i wyjściowe każdego typu operacji znajdziesz w dokumentacji interfejsu NNAPI.
Przed dodaniem operacji musisz dodać do modelu operandy, które są przez nią używane lub generowane.
Kolejność dodawania operacji nie ma znaczenia. NNAPI opiera się na zależnościach określonych przez graf obliczeniowy operandów i operacji, aby określić kolejność wykonywania operacji.
Operacje obsługiwane przez NNAPI znajdziesz w tabeli poniżej:
Znany problem na poziomie interfejsu API 28: podczas przekazywania tensorów ANEURALNETWORKS_TENSOR_QUANT8_ASYMM do operacji ANEURALNETWORKS_PAD, która jest dostępna w Androidzie 9 (poziom interfejsu API 28) i nowszych wersjach, dane wyjściowe z NNAPI mogą nie pasować do danych wyjściowych z platform uczenia maszynowego wyższego poziomu, takich jak TensorFlow Lite. Zamiast tego przekaż tylko ANEURALNETWORKS_TENSOR_FLOAT32.
Problem został rozwiązany w Androidzie 10 (poziom 29 interfejsu API) i nowszych wersjach.
Tworzenie modeli
W tym przykładzie utworzymy model z 2 operacjami przedstawiony na rysunku 3.
Aby zbudować model, wykonaj te czynności:
Wywołaj funkcję
ANeuralNetworksModel_create(), aby zdefiniować pusty model.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Dodaj operandy do modelu, wywołując funkcję
ANeuralNetworks_addOperand(). Typy danych są zdefiniowane za pomocą struktury danychANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6W przypadku operandów o stałych wartościach, takich jak wagi i odchylenia, które aplikacja uzyskuje w procesie trenowania, użyj funkcji
ANeuralNetworksModel_setOperandValue()iANeuralNetworksModel_setOperandValueFromMemory().W tym przykładzie ustawiamy stałe wartości z pliku danych treningowych odpowiadające buforowi pamięci utworzonemu w sekcji Udzielanie dostępu do danych treningowych.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));W przypadku każdej operacji w grafie skierowanym, którą chcesz obliczyć, dodaj ją do modelu, wywołując funkcję
ANeuralNetworksModel_addOperation().W ramach parametrów tego wywołania aplikacja musi podać:
- typ operacji,
- liczba wartości wejściowych,
- tablica indeksów operandów wejściowych,
- liczba wartości wyjściowych,
- tablica indeksów operandów wyjściowych;
Pamiętaj, że operandu nie można używać zarówno jako danych wejściowych, jak i wyjściowych tej samej operacji.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Określ, które operandy model ma traktować jako dane wejściowe i wyjściowe, wywołując funkcję
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Opcjonalnie możesz określić, czy wartość
ANEURALNETWORKS_TENSOR_FLOAT32może być obliczana z zakresem lub precyzją tak niską jak w przypadku 16-bitowego formatu reprezentacji zmiennoprzecinkowej IEEE 754, wywołując funkcjęANeuralNetworksModel_relaxComputationFloat32toFloat16().Zadzwoń pod numer
ANeuralNetworksModel_finish(), aby dokończyć definiowanie modelu. Jeśli nie ma błędów, ta funkcja zwraca kod wynikuANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Po utworzeniu modelu możesz go kompilować dowolną liczbę razy i wykonywać każdą kompilację dowolną liczbę razy.
Kontrola przepływu
Aby uwzględnić przepływ sterowania w modelu NNAPI:
Utwórz odpowiednie podgrafy wykonania (podgrafy
thenielsedla instrukcjiIF, podgrafyconditionibodydla pętliWHILE) jako samodzielne modeleANeuralNetworksModel*:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Utwórz operandy, które odwołują się do tych modeli w modelu zawierającym przepływ sterowania:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Dodaj operację przepływu sterowania:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Kompilacja
Etap kompilacji określa, na których procesorach będzie wykonywany model, i prosi odpowiednie sterowniki o przygotowanie się do jego wykonania. Może to obejmować generowanie kodu maszynowego dostosowanego do procesorów, na których będzie działać model.
Aby skompilować model, wykonaj te czynności:
Wywołaj funkcję
ANeuralNetworksCompilation_create(), aby utworzyć nową instancję kompilacji.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Opcjonalnie możesz użyć przypisywania urządzeń, aby wyraźnie wybrać urządzenia, na których ma być wykonywane działanie.
Opcjonalnie możesz wpływać na to, jak środowisko wykonawcze równoważy zużycie baterii i szybkość wykonywania. Możesz to zrobić, dzwoniąc pod numer
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Możesz określić m.in. te preferencje:
ANEURALNETWORKS_PREFER_LOW_POWER: prefer executing in a way that minimizes szybkie zużycie baterii. Jest to pożądane w przypadku kompilacji, które są często wykonywane.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: preferuj zwracanie pojedynczej odpowiedzi tak szybko, jak to możliwe, nawet jeśli powoduje to większe zużycie energii. Jest to ustawienie domyślne.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: preferuje maksymalizację przepustowości kolejnych klatek, np. podczas przetwarzania kolejnych klatek pochodzących z kamery.
Opcjonalnie możesz skonfigurować buforowanie kompilacji, wywołując funkcję
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Użyj
getCodeCacheDir()w przypadkucacheDir. Wartośćtokenmusi być unikalna dla każdego modelu w aplikacji.Zakończ definiowanie kompilacji, wywołując
ANeuralNetworksCompilation_finish(). Jeśli nie ma błędów, funkcja zwraca kod wynikuANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Wykrywanie i przypisywanie urządzeń
Na urządzeniach z Androidem 10 (poziom interfejsu API 29) lub nowszym interfejs NNAPI udostępnia funkcje, które umożliwiają bibliotekom i aplikacjom platformy uczenia maszynowego uzyskiwanie informacji o dostępnych urządzeniach i określanie urządzeń, które mają być używane do wykonywania zadań. Podawanie informacji o dostępnych urządzeniach umożliwia aplikacjom uzyskanie dokładnej wersji sterowników znajdujących się na urządzeniu, aby uniknąć znanych niezgodności. Dzięki możliwości określania przez aplikacje, na których urządzeniach mają być wykonywane różne sekcje modelu, można je zoptymalizować pod kątem urządzenia z Androidem, na którym są wdrażane.
Wykrywanie urządzeń
Użyj
ANeuralNetworks_getDeviceCount
aby uzyskać liczbę dostępnych urządzeń. W przypadku każdego urządzenia użyj
ANeuralNetworks_getDevice
aby ustawić instancję ANeuralNetworksDevice jako odwołanie do tego urządzenia.
Gdy uzyskasz odniesienie do urządzenia, możesz znaleźć dodatkowe informacje o tym urządzeniu, korzystając z tych funkcji:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Przypisanie urządzenia
Użyj
ANeuralNetworksModel_getSupportedOperationsForDevices
aby sprawdzić, które operacje modelu można uruchamiać na określonych urządzeniach.
Aby określić, których akceleratorów używać do wykonywania, zamiast ANeuralNetworksCompilation_create wywołaj funkcję ANeuralNetworksCompilation_createForDevices.
Używaj utworzonego obiektu ANeuralNetworksCompilation w normalny sposób.
Funkcja zwraca błąd, jeśli podany model zawiera operacje, które nie są obsługiwane przez wybrane urządzenia.
Jeśli określono kilka urządzeń, środowisko wykonawcze odpowiada za rozdzielenie pracy między nimi.
Podobnie jak w przypadku innych urządzeń, implementacja NNAPI na procesorze jest reprezentowana przez element
ANeuralNetworksDevice o nazwie nnapi-reference i typie
ANEURALNETWORKS_DEVICE_TYPE_CPU. Podczas wywoływania
ANeuralNetworksCompilation_createForDevicesimplementacja procesora nie jest
używana do obsługi przypadków niepowodzenia kompilacji i wykonania modelu.
Obowiązkiem aplikacji jest podzielenie modelu na podmodele, które mogą działać na określonych urządzeniach. Aplikacje, które nie wymagają ręcznego dzielenia na partycje, powinny nadal wywoływać prostszą funkcję ANeuralNetworksCompilation_create, aby używać wszystkich dostępnych urządzeń (w tym procesora) do przyspieszania działania modelu. Jeśli model nie może być w pełni obsługiwany przez urządzenia określone za pomocą ANeuralNetworksCompilation_createForDevices, zwracana jest wartość ANEURALNETWORKS_BAD_DATA.
Podział modelu na partycje
Gdy model jest dostępny na wielu urządzeniach, środowisko wykonawcze NNAPI rozdziela pracę między te urządzenia. Jeśli na przykład ANeuralNetworksCompilation_createForDevices udostępniono więcej niż 1 urządzenie, podczas przydzielania pracy będą brane pod uwagę wszystkie określone urządzenia. Pamiętaj, że jeśli urządzenia CPU nie ma na liście, wykonywanie na procesorze będzie wyłączone. Gdy używasz ANeuralNetworksCompilation_create, brane są pod uwagę wszystkie dostępne urządzenia, w tym procesor.
Dystrybucja odbywa się przez wybranie z listy dostępnych urządzeń dla każdej operacji w modelu urządzenia obsługującego operację i deklarującego najlepszą wydajność, czyli najkrótszy czas wykonania lub najniższe zużycie energii, w zależności od preferencji wykonania określonych przez klienta. Ten algorytm podziału nie uwzględnia możliwych nieefektywności spowodowanych przez operacje wejścia/wyjścia między różnymi procesorami, dlatego podczas określania wielu procesorów (jawnie za pomocą ANeuralNetworksCompilation_createForDevices lub niejawnie za pomocą ANeuralNetworksCompilation_create) ważne jest profilowanie wynikowej aplikacji.
Aby dowiedzieć się, jak model został podzielony przez NNAPI, sprawdź logi Androida pod kątem komunikatu (na poziomie INFO z tagiem ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name to opisowa nazwa operacji na wykresie, a device-index to indeks urządzenia kandydującego na liście urządzeń.
Ta lista jest danymi wejściowymi przekazywanymi do funkcji ANeuralNetworksCompilation_createForDevices lub, jeśli używasz funkcji ANeuralNetworksCompilation_createForDevices, listą urządzeń zwracaną podczas iteracji po wszystkich urządzeniach za pomocą funkcji ANeuralNetworks_getDeviceCount i ANeuralNetworks_getDevice.
Wiadomość (na poziomie INFO z tagiem ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Ten komunikat oznacza, że cały wykres został przyspieszony na urządzeniudevice-name.
Wykonanie
Krok wykonania stosuje model do zestawu danych wejściowych i przechowuje wyniki obliczeń w co najmniej jednym buforze użytkownika lub obszarze pamięci przydzielonym przez aplikację.
Aby wykonać skompilowany model, wykonaj te czynności:
Wywołaj funkcję
ANeuralNetworksExecution_create(), aby utworzyć nową instancję wykonania.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Określ, skąd aplikacja odczytuje wartości wejściowe do obliczeń. Aplikacja może odczytywać wartości wejściowe z bufora użytkownika lub przydzielonego obszaru pamięci, wywołując odpowiednio funkcje
ANeuralNetworksExecution_setInput()lubANeuralNetworksExecution_setInputFromMemory().// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Określ, gdzie aplikacja zapisuje wartości wyjściowe. Aplikacja może zapisywać wartości wyjściowe w buforze użytkownika lub w przydzielonym obszarze pamięci, wywołując odpowiednio funkcje
ANeuralNetworksExecution_setOutput()lubANeuralNetworksExecution_setOutputFromMemory().// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Zaplanuj rozpoczęcie wykonania, wywołując funkcję
ANeuralNetworksExecution_startCompute(). Jeśli nie ma błędów, funkcja zwraca kod wynikuANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Wywołaj funkcję
ANeuralNetworksEvent_wait(), aby poczekać na zakończenie wykonywania. Jeśli wykonanie się powiodło, funkcja zwraca kod wynikuANEURALNETWORKS_NO_ERROR. Oczekiwanie może odbywać się w innym wątku niż ten, który rozpoczyna wykonanie.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Opcjonalnie możesz zastosować do skompilowanego modelu inny zestaw danych wejściowych, używając tej samej instancji kompilacji do utworzenia nowej instancji
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Wykonanie synchroniczne
W przypadku wykonywania asynchronicznego czas jest poświęcany na tworzenie i synchronizowanie wątków. Ponadto opóźnienie może być bardzo zmienne, a najdłuższe opóźnienia sięgają nawet 500 mikrosekund między momentem powiadomienia lub wybudzenia wątku a momentem jego powiązania z rdzeniem procesora.
Aby zmniejszyć opóźnienie, możesz zamiast tego skierować aplikację do wykonania synchronicznego wywołania wnioskowania do środowiska wykonawczego. Wywołanie zostanie zwrócone dopiero po zakończeniu wnioskowania, a nie po jego rozpoczęciu. Zamiast wywoływać
ANeuralNetworksExecution_startCompute
asynchroniczne wywołanie wnioskowania w środowisku wykonawczym, aplikacja wywołuje
ANeuralNetworksExecution_compute
synchroniczne wywołanie w środowisku wykonawczym. Połączenie na numer ANeuralNetworksExecution_compute nie korzysta z ANeuralNetworksEvent i nie jest sparowane z połączeniem na numer ANeuralNetworksEvent_wait.
Uruchomienia seryjne
Na urządzeniach z Androidem 10 (poziom interfejsu API 29) lub nowszym interfejs NNAPI obsługuje wykonywanie pakietowe za pomocą obiektu ANeuralNetworksBurst. Wykonania seryjne to sekwencja wykonań tej samej kompilacji, które następują po sobie w szybkim tempie, np. w przypadku klatek rejestrowanych przez aparat lub kolejnych próbek dźwięku. Używanie obiektów ANeuralNetworksBurst może przyspieszyć wykonywanie, ponieważ wskazuje akceleratorom, że zasoby mogą być ponownie wykorzystywane między wykonaniami i że akceleratory powinny pozostawać w stanie wysokiej wydajności przez cały czas trwania serii.
ANeuralNetworksBurst wprowadza tylko niewielką zmianę w normalnej ścieżce wykonywania. Obiekt burst tworzy się za pomocą metody ANeuralNetworksBurst_create, jak pokazano w tym fragmencie kodu:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Wykonywanie w trybie burst jest synchroniczne. Zamiast jednak używać
ANeuralNetworksExecution_compute
do każdego wnioskowania, łączysz różne obiekty
ANeuralNetworksExecution
z tym samym ANeuralNetworksBurst w wywołaniach funkcji
ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Zwolnij obiekt ANeuralNetworksBurst za pomocą funkcji
ANeuralNetworksBurst_free
gdy nie będzie już potrzebny.
// Cleanup ANeuralNetworksBurst_free(burst);
Asynchroniczne kolejki poleceń i wykonywanie w izolacji
W Androidzie 11 i nowszych interfejs NNAPI obsługuje dodatkowy sposób planowania wykonywania asynchronicznego za pomocą metody ANeuralNetworksExecution_startComputeWithDependencies(). Gdy używasz tej metody, wykonanie czeka na sygnał ze wszystkich zdarzeń zależnych, zanim rozpocznie ocenę. Gdy wykonanie się zakończy i dane wyjściowe będą gotowe do użycia, zwracane zdarzenie zostanie zasygnalizowane.
W zależności od tego, które urządzenia obsługują wykonanie, zdarzenie może być obsługiwane przez barierę synchronizacji. Aby poczekać na zdarzenie i odzyskać zasoby użyte przez wykonanie, musisz wywołać funkcję ANeuralNetworksEvent_wait(). Możesz importować bariery synchronizacji do obiektu zdarzenia za pomocą ANeuralNetworksEvent_createFromSyncFenceFd() i eksportować je z obiektu zdarzenia za pomocą ANeuralNetworksEvent_getSyncFenceFd().
Dane wyjściowe o dynamicznym rozmiarze
Aby obsługiwać modele, w których rozmiar danych wyjściowych zależy od danych wejściowych, czyli w których rozmiaru nie można określić w momencie wykonywania modelu, użyj ANeuralNetworksExecution_getOutputOperandRank i ANeuralNetworksExecution_getOutputOperandDimensions.
Poniższy przykładowy kod pokazuje, jak to zrobić:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Czyszczenie
Krok czyszczenia zajmuje się zwalnianiem zasobów wewnętrznych używanych do obliczeń.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Zarządzanie błędami i przełączanie na procesor
Jeśli podczas dzielenia na partycje wystąpi błąd, sterownik nie skompiluje (fragmentu) modelu lub nie wykona skompilowanego (fragmentu) modelu, NNAPI może wrócić do własnej implementacji na procesorze co najmniej jednej operacji.
Jeśli klient NNAPI zawiera zoptymalizowane wersje operacji (np. TFLite), może być korzystne wyłączenie rezerwowego działania na CPU i obsługa błędów za pomocą zoptymalizowanej implementacji operacji klienta.
W Androidzie 10, jeśli kompilacja jest przeprowadzana za pomocą
ANeuralNetworksCompilation_createForDevices, to rezerwowe użycie procesora będzie wyłączone.
W Androidzie P wykonanie NNAPI jest przywracane do procesora, jeśli wykonanie na sterowniku się nie powiedzie.
Dotyczy to też Androida 10, gdy używana jest wartość ANeuralNetworksCompilation_create zamiast ANeuralNetworksCompilation_createForDevices.
Pierwsze wykonanie w przypadku tej partycji kończy się niepowodzeniem, a jeśli to nadal nie działa, ponawia próbę wykonania całego modelu na procesorze.
Jeśli podział lub kompilacja się nie powiedzie, cały model zostanie wypróbowany na procesorze.
W niektórych przypadkach niektóre operacje nie są obsługiwane na procesorze. W takich sytuacjach kompilacja lub wykonanie nie powiedzie się, zamiast powracać do poprzedniego stanu.
Nawet po wyłączeniu rezerwowego procesora CPU w modelu mogą nadal występować operacje zaplanowane na procesorze CPU. Jeśli procesor znajduje się na liście procesorów dostarczonych do ANeuralNetworksCompilation_createForDevices i jest jedynym procesorem obsługującym te operacje lub procesorem, który zapewnia najlepszą wydajność w przypadku tych operacji, zostanie wybrany jako główny (nieawaryjny) wykonawca.
Aby mieć pewność, że nie będzie wykonywane żadne działanie procesora, użyj ANeuralNetworksCompilation_createForDevices, wykluczając nnapi-reference z listy urządzeń.
Od Androida P w kompilacjach do debugowania można wyłączyć wycofywanie w czasie wykonywania, ustawiając właściwość debug.nn.partition na 2.
Domeny pamięci
W Androidzie 11 i nowszych interfejs NNAPI obsługuje domeny pamięci, które udostępniają interfejsy alokatora dla nieprzezroczystych pamięci. Dzięki temu aplikacje mogą przekazywać pamięci natywne dla urządzenia między wykonaniami, więc NNAPI nie musi niepotrzebnie kopiować ani przekształcać danych podczas kolejnych wykonań na tym samym sterowniku.
Funkcja domeny pamięci jest przeznaczona dla tensorów, które są w większości wewnętrzne dla sterownika i nie wymagają częstego dostępu po stronie klienta. Przykładami takich tensorów są tensory stanu w modelach sekwencyjnych. W przypadku tensorów, które wymagają częstego dostępu do procesora po stronie klienta, używaj zamiast tego pul pamięci współdzielonej.
Aby przydzielić pamięć nieprzezroczystą, wykonaj te czynności:
Wywołaj funkcję
ANeuralNetworksMemoryDesc_create(), aby utworzyć nowy deskryptor pamięci:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Określ wszystkie zamierzone role danych wejściowych i wyjściowych, wywołując
ANeuralNetworksMemoryDesc_addInputRole()iANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Opcjonalnie możesz określić wymiary pamięci, wywołując funkcję
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Zakończ definiowanie deskryptora, wywołując
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Przydziel dowolną liczbę pamięci, przekazując deskryptor do funkcji
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Zwolnij deskryptor pamięci, gdy nie jest już potrzebny.
ANeuralNetworksMemoryDesc_free(desc);
Klient może używać utworzonego obiektu ANeuralNetworksMemory tylko z obiektami ANeuralNetworksExecution_setInputFromMemory() lub ANeuralNetworksExecution_setOutputFromMemory() zgodnie z rolami określonymi w obiekcie ANeuralNetworksMemoryDesc. Argumenty offset i length muszą być ustawione na 0, co oznacza, że używana jest cała pamięć. Klient może też jawnie ustawić lub wyodrębnić zawartość pamięci za pomocą ANeuralNetworksMemory_copy().
Możesz tworzyć nieprzezroczyste wspomnienia z rolami o nieokreślonych wymiarach lub randze.
W takim przypadku utworzenie pamięci może się nie udać i zwrócić stan ANEURALNETWORKS_OP_FAILED, jeśli nie jest ona obsługiwana przez sterownik bazowy. Zalecamy klientowi wdrożenie logiki rezerwowej przez przydzielenie wystarczająco dużego bufora obsługiwanego przez Ashmem lub BLOB-mode AHardwareBuffer.
Gdy interfejs NNAPI nie potrzebuje już dostępu do nieprzezroczystego obiektu pamięci, zwolnij odpowiednią instancję ANeuralNetworksMemory:
ANeuralNetworksMemory_free(opaqueMem);
Pomiar wyników
Skuteczność aplikacji możesz ocenić, mierząc czas wykonania lub profilując.
Czas wykonywania
Jeśli chcesz określić całkowity czas wykonania w czasie działania, możesz użyć synchronicznego interfejsu API wykonania i zmierzyć czas potrzebny na wywołanie. Jeśli chcesz określić łączny czas wykonania na niższym poziomie stosu oprogramowania, możesz użyć funkcji ANeuralNetworksExecution_setMeasureTiming i ANeuralNetworksExecution_getDuration, aby uzyskać:
- czas wykonania na akceleratorze (nie w sterowniku, który działa na procesorze hosta);
- czas wykonania w sterowniku, w tym czas na akceleratorze.
Czas wykonania w sterowniku nie obejmuje narzutu, takiego jak narzut środowiska wykonawczego i IPC potrzebny do komunikacji środowiska wykonawczego ze sterownikiem.
Te interfejsy API mierzą czas między przesłaniem zadania a jego ukończeniem, a nie czas, jaki sterownik lub akcelerator poświęca na przeprowadzenie wnioskowania, które może być przerywane przez przełączanie kontekstu.
Jeśli na przykład rozpocznie się wnioskowanie 1, a następnie sterownik przerwie pracę, aby przeprowadzić wnioskowanie 2, po czym wznowi i zakończy wnioskowanie 1, czas wykonania wnioskowania 1 będzie obejmował czas, w którym praca została przerwana na potrzeby wnioskowania 2.
Te informacje o czasie mogą być przydatne w przypadku wdrożenia aplikacji w środowisku produkcyjnym w celu zbierania danych telemetrycznych do użytku offline. Dane o czasie możesz wykorzystać do zmodyfikowania aplikacji w celu zwiększenia jej wydajności.
Korzystając z tej funkcji, pamiętaj o tych kwestiach:
- Zbieranie informacji o czasie może wiązać się z kosztami związanymi z wydajnością.
- Tylko sterownik może obliczyć czas spędzony w nim samym lub na akceleratorze, z wyłączeniem czasu spędzonego w środowisku wykonawczym NNAPI i w IPC.
- Tych interfejsów API możesz używać tylko w przypadku
ANeuralNetworksExecutionutworzonych za pomocąANeuralNetworksCompilation_createForDevicesznumDevices = 1. - Aby zgłaszać informacje o czasie, kierowca nie musi być zalogowany.
Profilowanie aplikacji za pomocą narzędzia Android Systrace
Od Androida 10 interfejs NNAPI automatycznie generuje zdarzenia systrace, których możesz używać do profilowania aplikacji.
Źródło NNAPI zawiera narzędzie parse_systrace do przetwarzania zdarzeń systrace generowanych przez aplikację i tworzenia widoku tabeli pokazującego czas spędzony w różnych fazach cyklu życia modelu (tworzenie instancji, przygotowanie, wykonanie kompilacji i zakończenie) oraz w różnych warstwach aplikacji. Aplikacja jest podzielona na te warstwy:
Application: główny kod aplikacjiRuntime: Środowisko wykonawcze NNAPIIPC: komunikacja międzyprocesowa między środowiskiem wykonawczym NNAPI a kodem sterownikaDriver: proces sterownika akceleratora.
Generowanie danych analizy profilowania
Załóżmy, że drzewo źródłowe AOSP zostało pobrane do katalogu $ANDROID_BUILD_TOP. Jako aplikację docelową wykorzystamy przykład klasyfikacji obrazów TFLite. Dane profilowania NNAPI możesz wygenerować, wykonując te czynności:
- Uruchom śledzenie systemu Android za pomocą tego polecenia:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
Parametr -o trace.html wskazuje, że ślady będą zapisywane w trace.html. Podczas profilowania własnej aplikacji musisz zastąpić symbol org.tensorflow.lite.examples.classification nazwą procesu podaną w manifeście aplikacji.
Spowoduje to zajęcie jednej z konsol powłoki. Nie uruchamiaj polecenia w tle, ponieważ interaktywnie czeka ono na zakończenie działania enter.
- Po uruchomieniu narzędzia do zbierania danych Systrace uruchom aplikację i przeprowadź test porównawczy.
W naszym przypadku możesz uruchomić aplikację Image Classification w Android Studio lub bezpośrednio z interfejsu testowego telefonu, jeśli aplikacja została już zainstalowana. Aby wygenerować niektóre dane NNAPI, musisz skonfigurować aplikację do korzystania z NNAPI, wybierając NNAPI jako urządzenie docelowe w oknie konfiguracji aplikacji.
Po zakończeniu testu zakończ śledzenie systemowe, naciskając
enterw terminalu konsoli, który jest aktywny od kroku 1.Uruchom narzędzie
systrace_parsergenerate cumulative statistics:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
Parser akceptuje te parametry:
- --total-times: pokazuje łączny czas spędzony w warstwie, w tym czas oczekiwania na wykonanie wywołania warstwy bazowej.
- --print-detail: drukuje wszystkie zdarzenia zebrane z systrace.
- --per-execution: drukuje tylko wykonanie i jego podfazy (jako czasy poszczególnych wykonań) zamiast statystyk wszystkich faz.
- --json: generuje dane wyjściowe w formacie JSON.
Przykład danych wyjściowych:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
Jeśli zebrane zdarzenia nie stanowią pełnego śladu aplikacji, analizator może nie działać prawidłowo. Może się to zdarzyć w szczególności wtedy, gdy w śladzie występują zdarzenia systrace wygenerowane w celu oznaczenia końca sekcji, ale nie ma powiązanego z nimi zdarzenia oznaczającego początek sekcji. Zwykle dzieje się tak, gdy podczas uruchamiania narzędzia do zbierania śladów systemowych generowane są zdarzenia z poprzedniej sesji profilowania. W takim przypadku musisz ponownie przeprowadzić profilowanie.
Dodawanie statystyk kodu aplikacji do danych wyjściowych narzędzia systrace_parser
Aplikacja parse_systrace jest oparta na wbudowanej funkcji systrace Androida. Ślady dotyczące konkretnych operacji w aplikacji możesz dodawać za pomocą interfejsu systrace API (w przypadku Javy, w przypadku aplikacji natywnych) z nazwami zdarzeń niestandardowych.
Aby powiązać zdarzenia niestandardowe z fazami cyklu życia aplikacji, dodaj na początku nazwy zdarzenia jeden z tych ciągów znaków:
[NN_LA_PI]: zdarzenie na poziomie aplikacji dotyczące inicjowania[NN_LA_PP]: zdarzenie na poziomie aplikacji dotyczące przygotowania[NN_LA_PC]: wydarzenie na poziomie aplikacji dotyczące kompilacji[NN_LA_PE]: zdarzenie na poziomie aplikacji dotyczące wykonania
Oto przykład, jak zmodyfikować kod przykładu klasyfikacji obrazów TFLite, dodając sekcję runInferenceModel dla fazy Execution i warstwę Application zawierającą inne sekcje preprocessBitmap, które nie będą uwzględniane w śladach NNAPI. Sekcja runInferenceModel będzie częścią zdarzeń systrace przetwarzanych przez analizator systrace nnapi:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Jakość usługi
W Androidzie 11 i nowszych wersjach interfejs NNAPI umożliwia lepszą jakość usług (QoS), ponieważ pozwala aplikacji określać względne priorytety modeli, maksymalny czas potrzebny na przygotowanie danego modelu i maksymalny czas potrzebny na wykonanie danego obliczenia. Android 11 wprowadza też dodatkowe kody wyników interfejsu NNAPI, które umożliwiają aplikacjom rozpoznawanie błędów, takich jak niedotrzymanie terminów wykonania.
Ustawianie priorytetu zadania
Aby ustawić priorytet zbioru zadań NNAPI, przed wywołaniem funkcji ANeuralNetworksCompilation_finish() wywołaj funkcję ANeuralNetworksCompilation_setPriority().
Ustawianie terminów
Aplikacje mogą ustawiać terminy zarówno kompilacji modelu, jak i wnioskowania.
- Aby ustawić limit czasu kompilacji, wywołaj funkcję
ANeuralNetworksCompilation_setTimeout()przed wywołaniem funkcjiANeuralNetworksCompilation_finish(). - Aby ustawić limit czasu wnioskowania, wywołaj
ANeuralNetworksExecution_setTimeout()przed rozpoczęciem kompilacji.
Więcej informacji o operandach
W następnej sekcji znajdziesz zaawansowane informacje o używaniu operandów.
Skwantyzowane tensory
Skwantowany tensor to zwarty sposób reprezentowania n-wymiarowej tablicy wartości zmiennoprzecinkowych.
NNAPI obsługuje 8-bitowe asymetryczne tensory skwantyzowane. W przypadku tych tensorów wartość każdej komórki jest reprezentowana przez 8-bitową liczbę całkowitą. Z tenzorem powiązane są wartość skali i punktu zerowego. Służą one do przekształcania 8-bitowych liczb całkowitych na reprezentowane wartości zmiennoprzecinkowe.
Wzór to:
(cellValue - zeroPoint) * scale
gdzie zeroPoint to 32-bitowa liczba całkowita, a scale to 32-bitowa liczba zmiennoprzecinkowa.
W porównaniu z tensorami 32-bitowych wartości zmiennoprzecinkowych tensory 8-bitowe mają 2 zalety:
- Aplikacja jest mniejsza, ponieważ wytrenowane wagi zajmują jedną czwartą rozmiaru tensorów 32-bitowych.
- Obliczenia można często wykonywać szybciej. Wynika to z mniejszej ilości danych, które trzeba pobrać z pamięci, oraz z wydajności procesorów, takich jak DSP, w wykonywaniu obliczeń na liczbach całkowitych.
Chociaż można przekonwertować model zmiennoprzecinkowy na model poddany kwantyzacji, nasze doświadczenie pokazuje, że lepsze wyniki uzyskuje się, trenując bezpośrednio model poddany kwantyzacji. W efekcie sieć neuronowa uczy się kompensować zwiększoną szczegółowość każdej wartości. W przypadku każdego skwantyzowanego tensora wartości scale i zeroPoint są określane podczas procesu trenowania.
W NNAPI typy skwantowanych tensorów definiuje się, ustawiając pole typu struktury danych ANeuralNetworksOperandType na ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
W tej strukturze danych określasz też skalę i wartość zeroPoint tensora.
Oprócz 8-bitowych asymetrycznych tensorów skwantyzowanych interfejs NNAPI obsługuje:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL, których możesz używać do reprezentowania wag w operacjachCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMMktórego możesz użyć w przypadku stanu wewnętrznegoQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMMktóre mogą być danymi wejściowymi dlaANEURALNETWORKS_DEQUANTIZE.
Operandy opcjonalne
Niektóre operacje, np. ANEURALNETWORKS_LSH_PROJECTION, przyjmują opcjonalne operandy. Aby wskazać w modelu, że opcjonalny operand został pominięty, wywołaj funkcję ANeuralNetworksModel_setOperandValue(), przekazując NULL jako bufor i 0 jako długość.
Jeśli decyzja o tym, czy operand jest obecny, różni się w przypadku każdego wykonania, możesz wskazać, że operand jest pomijany, używając funkcji ANeuralNetworksExecution_setInput() lub ANeuralNetworksExecution_setOutput(), przekazując NULL dla bufora i 0 dla długości.
Tensory o nieznanej randze
W Androidzie 9 (poziom 28 interfejsu API) wprowadzono operandy modelu o nieznanych wymiarach, ale znanym rankingu (liczbie wymiarów). W Androidzie 10 (poziom 29 interfejsu API) wprowadzono tensory o nieznanym stopniu, co pokazano w ANeuralNetworksOperandType.
Test porównawczy NNAPI
Test porównawczy NNAPI jest dostępny w AOSP w platform/test/mlts/benchmark(aplikacja do testów porównawczych) i platform/test/mlts/models (modele i zbiory danych).
Test porównawczy ocenia opóźnienie i dokładność oraz porównuje sterowniki z tą samą pracą wykonaną za pomocą TensorFlow Lite działającego na procesorze w przypadku tych samych modeli i zbiorów danych.
Aby skorzystać z analizy porównawczej:
Podłącz docelowe urządzenie z Androidem do komputera, otwórz okno terminala i upewnij się, że urządzenie jest dostępne za pomocą narzędzia adb.
Jeśli podłączonych jest więcej niż jedno urządzenie z Androidem, wyeksportuj zmienną środowiskową urządzenia docelowego
ANDROID_SERIAL.Otwórz katalog źródłowy najwyższego poziomu Androida.
Uruchom te polecenia:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Po zakończeniu testu porównawczego jego wyniki zostaną przedstawione jako strona HTML przekazana do
xdg-open.
Logi NNAPI
NNAPI generuje przydatne informacje diagnostyczne w dziennikach systemowych. Do analizowania logów używaj narzędzia logcat.
Włącz szczegółowe logowanie NNAPI w przypadku określonych faz lub komponentów, ustawiając właściwość debug.nn.vlog (za pomocą adb shell) na tę listę wartości rozdzielonych spacją, dwukropkiem lub przecinkiem:
model: Budowanie modelucompilation: generowanie planu wykonania modelu i kompilacjaexecution: wykonywanie modelucpuexe: wykonywanie operacji przy użyciu implementacji NNAPI na procesorze;manager: informacje o rozszerzeniach NNAPI, dostępnych interfejsach i funkcjachalllub1: wszystkie powyższe elementy
Aby na przykład włączyć pełne logowanie szczegółowe, użyj polecenia adb shell setprop debug.nn.vlog all. Aby wyłączyć logowanie szczegółowe, użyj polecenia adb shell setprop debug.nn.vlog '""'.
Po włączeniu logowanie szczegółowe generuje wpisy logu na poziomie INFO z tagiem ustawionym na nazwę fazy lub komponentu.
Oprócz debug.nn.vlogkontrolowanych wiadomości komponenty interfejsu NNAPI API udostępniają inne wpisy logu na różnych poziomach, z których każdy używa określonego tagu logu.
Aby uzyskać listę komponentów, wyszukaj w drzewie źródłowym za pomocą tego wyrażenia:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
To wyrażenie zwraca obecnie te tagi:
- BurstBuilder
- Wywołania zwrotne
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Menedżer
- Pamięć
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operacje
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Aby kontrolować poziom komunikatów dziennika wyświetlanych przez logcat, użyj zmiennej środowiskowej ANDROID_LOG_TAGS.
Aby wyświetlić pełny zestaw komunikatów dziennika NNAPI i wyłączyć wszystkie inne, ustaw ANDROID_LOG_TAGS na:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Wartość ANDROID_LOG_TAGS możesz ustawić za pomocą tego polecenia:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Pamiętaj, że jest to tylko filtr, który ma zastosowanie do logcat. Aby wygenerować szczegółowe informacje o logach, musisz ustawić wartość właściwości debug.nn.vlog na all.