
وقتی چندین ردپا را با استفاده از ProfilingManager جمعآوری کردید، بررسی جداگانه آنها برای یافتن مشکلات عملکرد غیرعملی میشود. تجزیه و تحلیل ردپاهای انبوه به شما امکان میدهد تا به طور همزمان از مجموعهای از ردپاها پرسوجو کنید تا:
- رگرسیونهای عملکرد رایج را شناسایی کنید.
- توزیعهای آماری را محاسبه کنید (برای مثال، تأخیر P50، P90، P99).
- الگوهایی را در چندین ردپا پیدا کنید.
- برای درک و اشکالزدایی مشکلات عملکرد، ردپاهای پرت را پیدا کنید.
این بخش نحوه استفاده از پردازنده ردیابی دستهای Perfetto Python را برای تجزیه و تحلیل معیارهای راهاندازی در مجموعهای از ردیابیهای ذخیره شده محلی و یافتن ردیابیهای پرت برای تجزیه و تحلیل عمیقتر نشان میدهد.
طراحی پرس و جو
اولین قدم برای انجام یک تحلیل گروهی، ایجاد یک کوئری PerfettoSQL است.
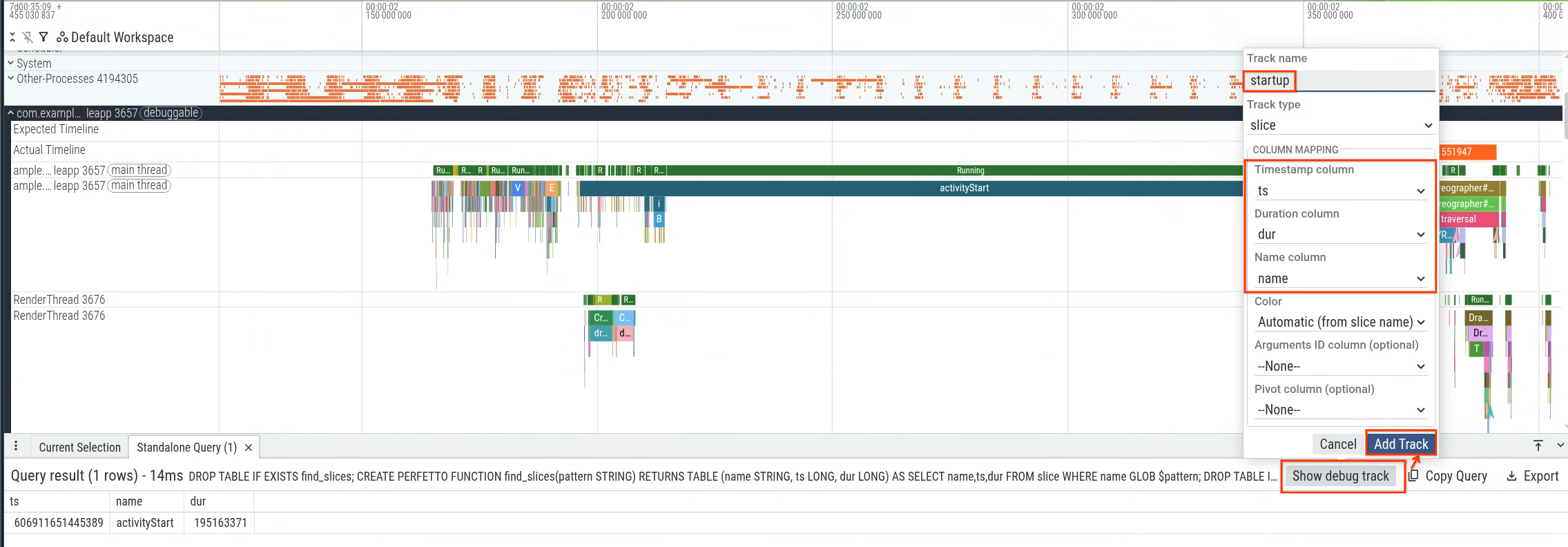
در این بخش، یک پرسوجوی نمونه ارائه میدهیم که تأخیر راهاندازی برنامه را اندازهگیری میکند. بهطور خاص، میتوانید مدت زمان را از activityStart تا اولین فریم تولید شده (اولین رخداد برش Choreographer#doFrame ) اندازهگیری کنید تا تأخیر راهاندازی برنامه را که در کنترل برنامه شماست، اندازهگیری کنید. شکل 1 بخشی را که باید پرسوجو شود نشان میدهد.

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
شما میتوانید کوئری را در رابط کاربری Perfetto اجرا کنید و سپس از نتایج کوئری برای تولید یک مسیر اشکالزدایی (شکل ۲) استفاده کنید و آن را در جدول زمانی (شکل ۳) تجسم کنید.

محیط پایتون را تنظیم کنید
پایتون و کتابخانههای مورد نیاز آن را روی دستگاه محلی خود نصب کنید :
pip install perfetto pandas plotly
اسکریپت تحلیل ردیابی انبوه را ایجاد کنید
اسکریپت نمونه زیر، با استفاده از پردازنده پایتون BatchTraceProcessor مربوط به Perfetto، پرسوجو را در چندین مسیر اجرا میکند.
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
# Collect all trace files in the local directory
traces = glob.glob('*.perfetto-trace')
if not traces:
print("No .perfetto-trace files found in the current directory.")
exit(1)
if __name__ == '__main__':
# Process all traces in parallel to aggregate metrics across runs
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
# Plot the distribution of startup times, tracking trace file paths on
# hover
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
فیلمنامه را درک کنید
وقتی اسکریپت پایتون را اجرا میکنید، اقدامات زیر را انجام میدهد:
- این اسکریپت در دایرکتوری محلی شما به دنبال تمام ردپاهای Perfetto که با پسوند
.perfetto-traceهستند، جستجو میکند و از آنها به عنوان ردپاهای منبع برای تجزیه و تحلیل استفاده میکند. - این یک کوئری ردیابی انبوه اجرا میکند که زیرمجموعهای از زمان راهاندازی مربوط به زمان از برش ردیابی
activityStartتا اولین فریم تولید شده توسط برنامه شما را محاسبه میکند. - این برنامه با استفاده از نمودار ویولونی، تأخیر را بر حسب میلیثانیه رسم میکند تا توزیع زمانهای راهاندازی را به تصویر بکشد.
نتایج را تفسیر کنید
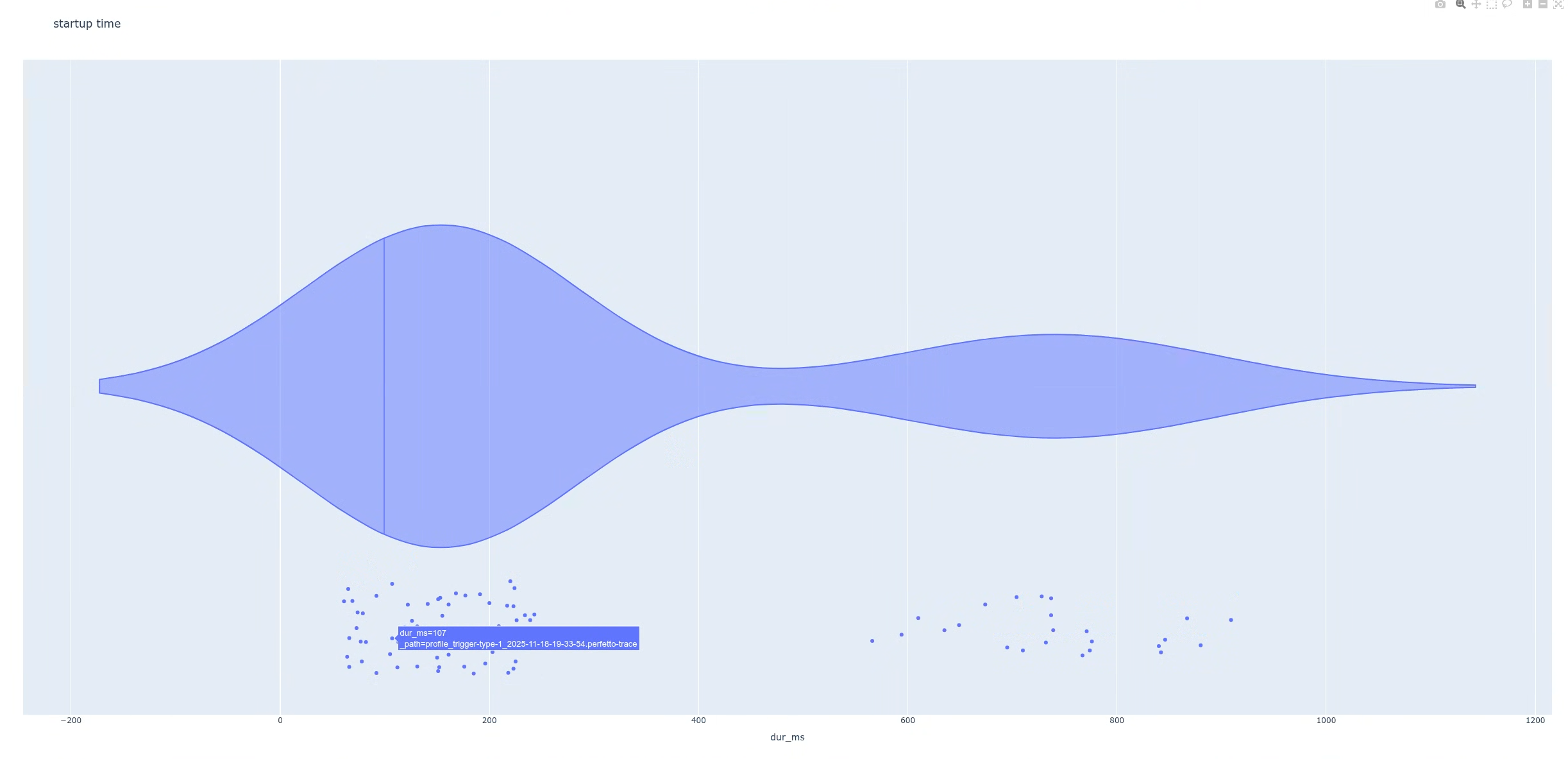
پس از اجرای اسکریپت، اسکریپت یک نمودار ایجاد میکند. در این حالت، نمودار یک توزیع دووجهی با دو قله مجزا را نشان میدهد (شکل ۴).
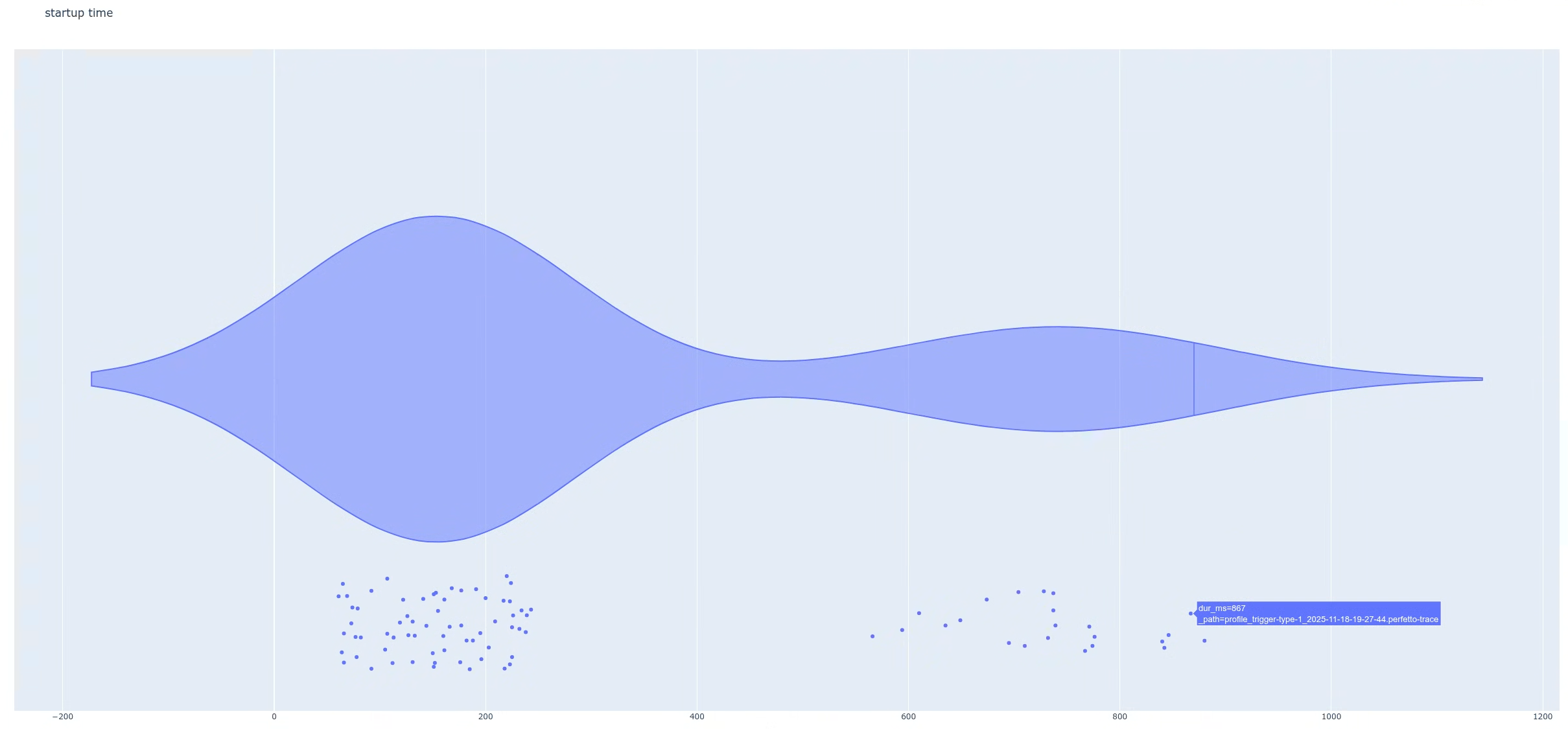
در مرحله بعد، تفاوت بین دو جمعیت را پیدا کنید. این به شما کمک میکند تا ردپاهای منفرد را با جزئیات بیشتری بررسی کنید. در این مثال، نمودار طوری تنظیم شده است که وقتی نشانگر ماوس را روی نقاط داده (تاخیرها) نگه میدارید، میتوانید نام فایلهای ردیابی را شناسایی کنید. سپس میتوانید یکی از ردپاهایی را که بخشی از گروه با تأخیر بالا است، باز کنید.
وقتی یک ردپا از گروه با تأخیر بالا (شکل ۵) را باز میکنید، یک برش اضافی به نام MyFlaggedFeature را خواهید دید که در هنگام راهاندازی اجرا میشود (شکل ۶). برعکس، انتخاب یک ردپا از جمعیت با تأخیر کمتر (سمت چپترین قله) عدم وجود همان برش را تأیید میکند (شکل ۷). این مقایسه نشان میدهد که یک پرچم ویژگی خاص، که برای زیرمجموعهای از کاربران فعال شده است، رگرسیون را فعال میکند.
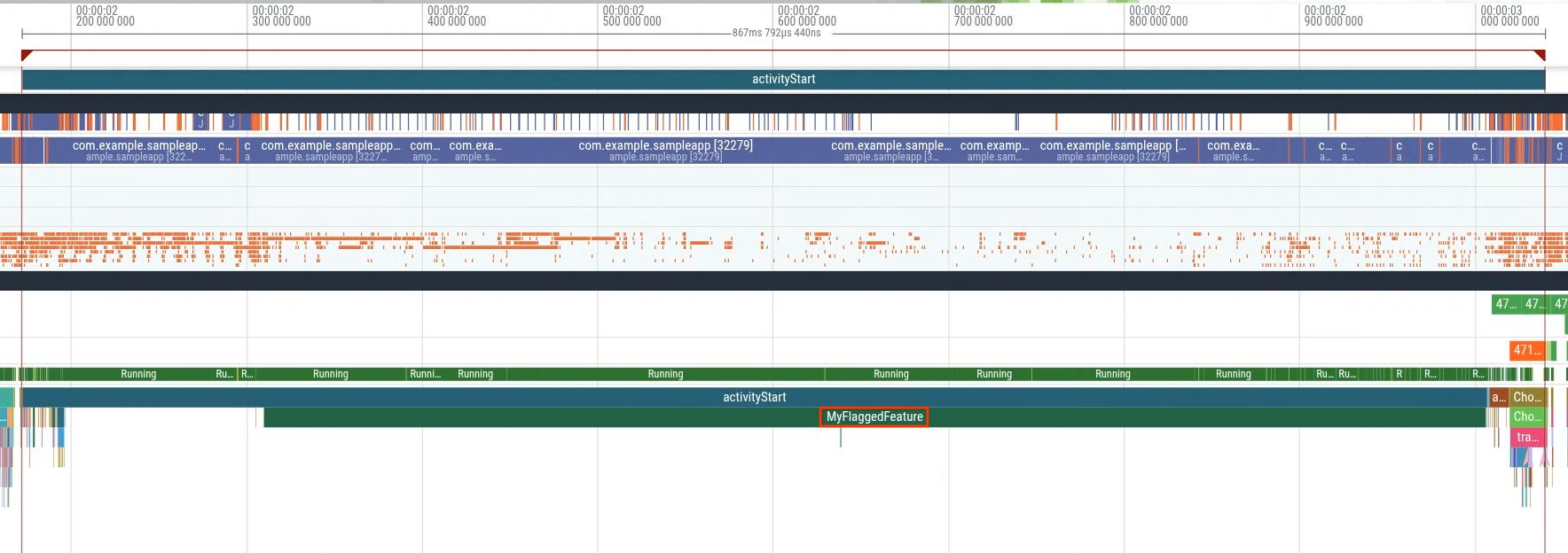
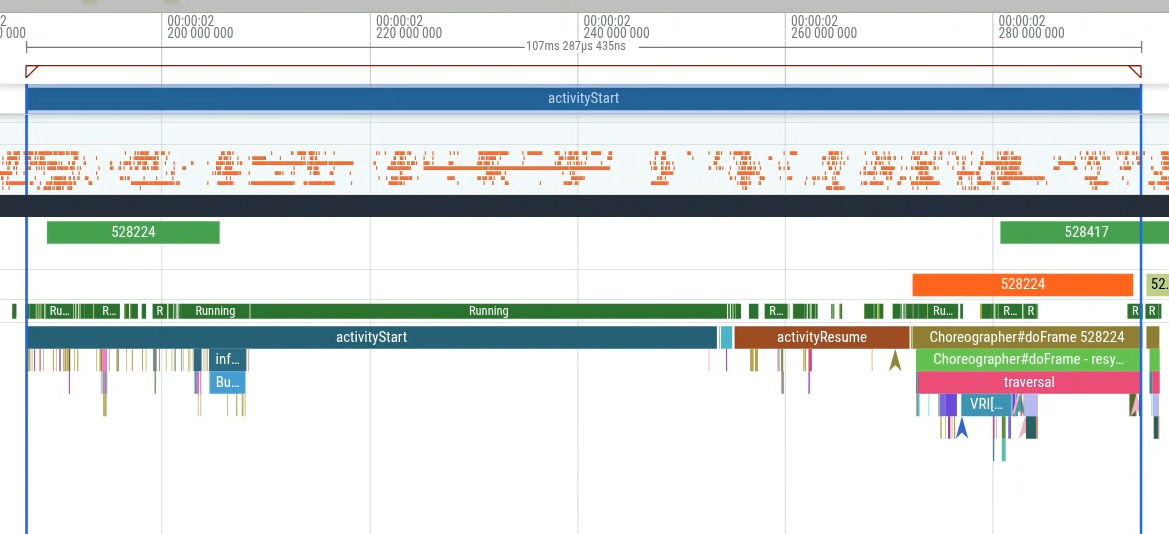
این مثال یکی از روشهای متعدد استفاده از تحلیل ردیابی انبوه را نشان میدهد. موارد استفاده دیگر شامل استخراج آمار از میدان برای سنجش تأثیر، تشخیص رگرسیونها و موارد دیگر است.