
ProfilingManager를 사용하여 여러 트레이스를 수집한 후 성능 문제를 찾기 위해 개별적으로 탐색하는 것은 비실용적입니다. 대량 추적 분석을 사용하면 추적 데이터 세트를 동시에 쿼리하여 다음 작업을 할 수 있습니다.
- 일반적인 성능 저하를 식별합니다.
- 통계 분포 (예: P50, P90, P99 지연 시간)를 계산합니다.
- 여러 트레이스에서 패턴을 찾습니다.
- 이상치 트레이스를 찾아 성능 문제를 파악하고 디버그합니다.
이 섹션에서는 Perfetto Python 배치 트레이스 프로세서를 사용하여 로컬에 저장된 트레이스 집합에서 시작 측정항목을 분석하고 자세한 분석을 위해 이상치 트레이스를 찾는 방법을 보여줍니다.
쿼리 설계
일괄 분석을 실행하는 첫 번째 단계는 PerfettoSQL 쿼리를 만드는 것입니다.
이 섹션에서는 앱 시작 지연 시간을 측정하는 쿼리의 예를 보여줍니다.
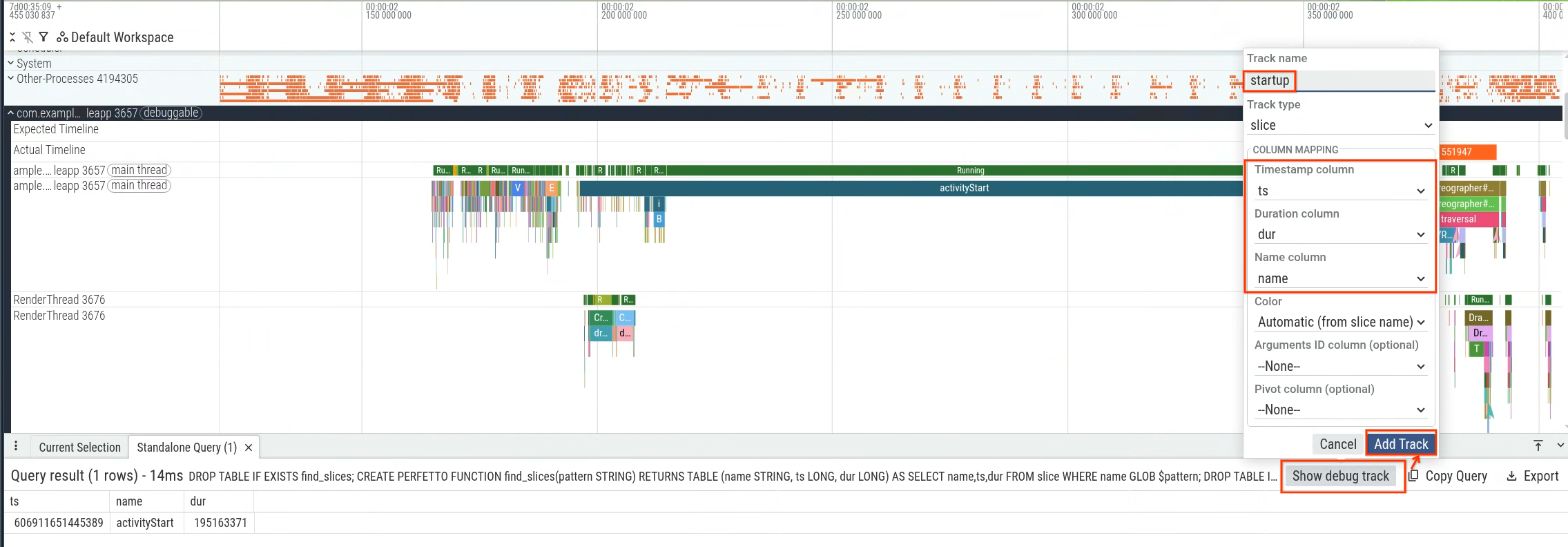
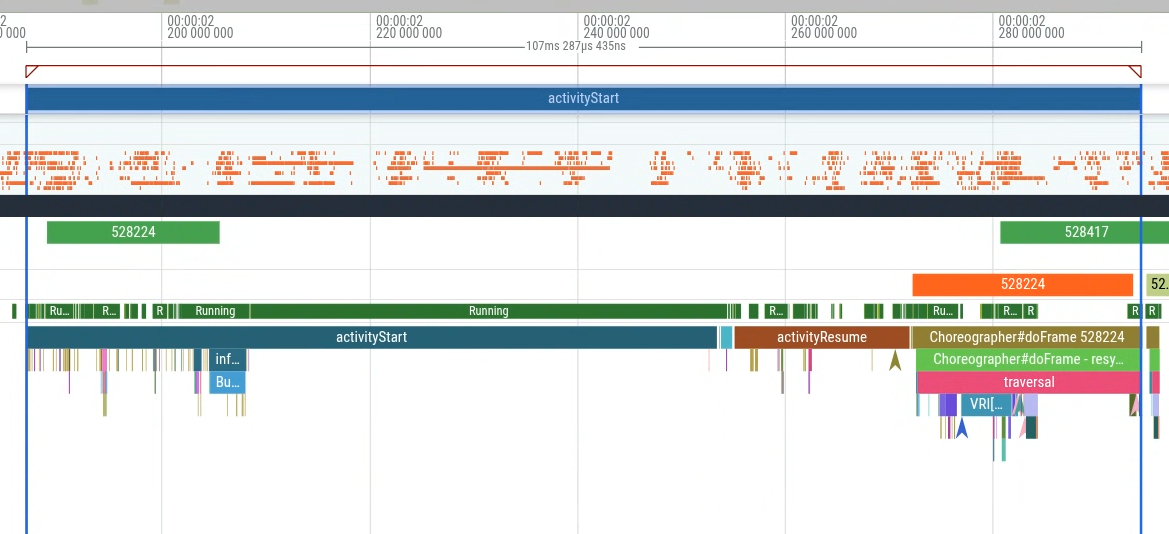
특히 activityStart부터 생성된 첫 번째 프레임 (Choreographer#doFrame 슬라이스의 첫 번째 발생)까지의 기간을 측정하여 앱의 제어 범위 내에 있는 앱 시작 지연 시간을 측정할 수 있습니다. 그림 1은 쿼리할 섹션을 보여줍니다.

CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
Perfetto UI 내에서 쿼리를 실행한 다음 쿼리 결과를 사용하여 디버그 트랙을 생성하고 (그림 2) 타임라인 내에서 시각화할 수 있습니다 (그림 3).

Python 환경 설정
로컬 머신에 Python 및 필수 라이브러리를 설치합니다.
pip install perfetto pandas plotly
대량 추적 분석 스크립트 만들기
다음 샘플 스크립트는 Perfetto의 Python BatchTraceProcessor를 사용하여 여러 트레이스에서 쿼리를 실행합니다.
from perfetto.batch_trace_processor import BatchTraceProcessor
import glob
import plotly.express as px
# Collect all trace files in the local directory
traces = glob.glob('*.perfetto-trace')
if not traces:
print("No .perfetto-trace files found in the current directory.")
exit(1)
if __name__ == '__main__':
# Process all traces in parallel to aggregate metrics across runs
with BatchTraceProcessor(traces) as btp:
query = """
CREATE OR REPLACE PERFETTO FUNCTION find_slices(pattern STRING) RETURNS
TABLE (name STRING, ts LONG, dur LONG) AS
SELECT name,ts,dur FROM slice WHERE name GLOB $pattern;
CREATE OR REPLACE PERFETTO FUNCTION generate_start_to_end_slices(startSlicePattern STRING, endSlicePattern STRING, inclusive BOOL) RETURNS
TABLE(name STRING, ts LONG, dur LONG) AS
SELECT name, ts, MIN(startToEndDur) as dur
FROM
(SELECT S.name as name, S.ts as ts, E.ts + IIF($inclusive, E.dur, 0) - S.ts as startToEndDur
FROM find_slices($startSlicePattern) as S CROSS JOIN find_slices($endSlicePattern) as E
WHERE startToEndDur > 0)
GROUP BY name, ts;
SELECT ts,name,dur / 1000000 as dur_ms from generate_start_to_end_slices('activityStart','*Choreographer#doFrame [0-9]*', true)
"""
df = btp.query_and_flatten(query)
# Plot the distribution of startup times, tracking trace file paths on
# hover
violin = px.violin(df, x='dur_ms', hover_data='_path', title='startup time', points='all')
violin.show()
스크립트 이해
Python 스크립트를 실행하면 다음 작업이 실행됩니다.
- 이 스크립트는 로컬 디렉터리에서
.perfetto-trace접미사가 붙은 모든 Perfetto 트레이스를 검색하고 이를 분석의 소스 트레이스로 사용합니다. activityStart트레이스 슬라이스부터 앱에서 생성된 첫 번째 프레임까지의 시간에 해당하는 시작 시간의 하위 집합을 계산하는 대량 트레이스 쿼리를 실행합니다.- 바이올린 플롯을 사용하여 시작 시간의 분포를 시각화하여 지연 시간을 밀리초 단위로 표시합니다.
결과 해석
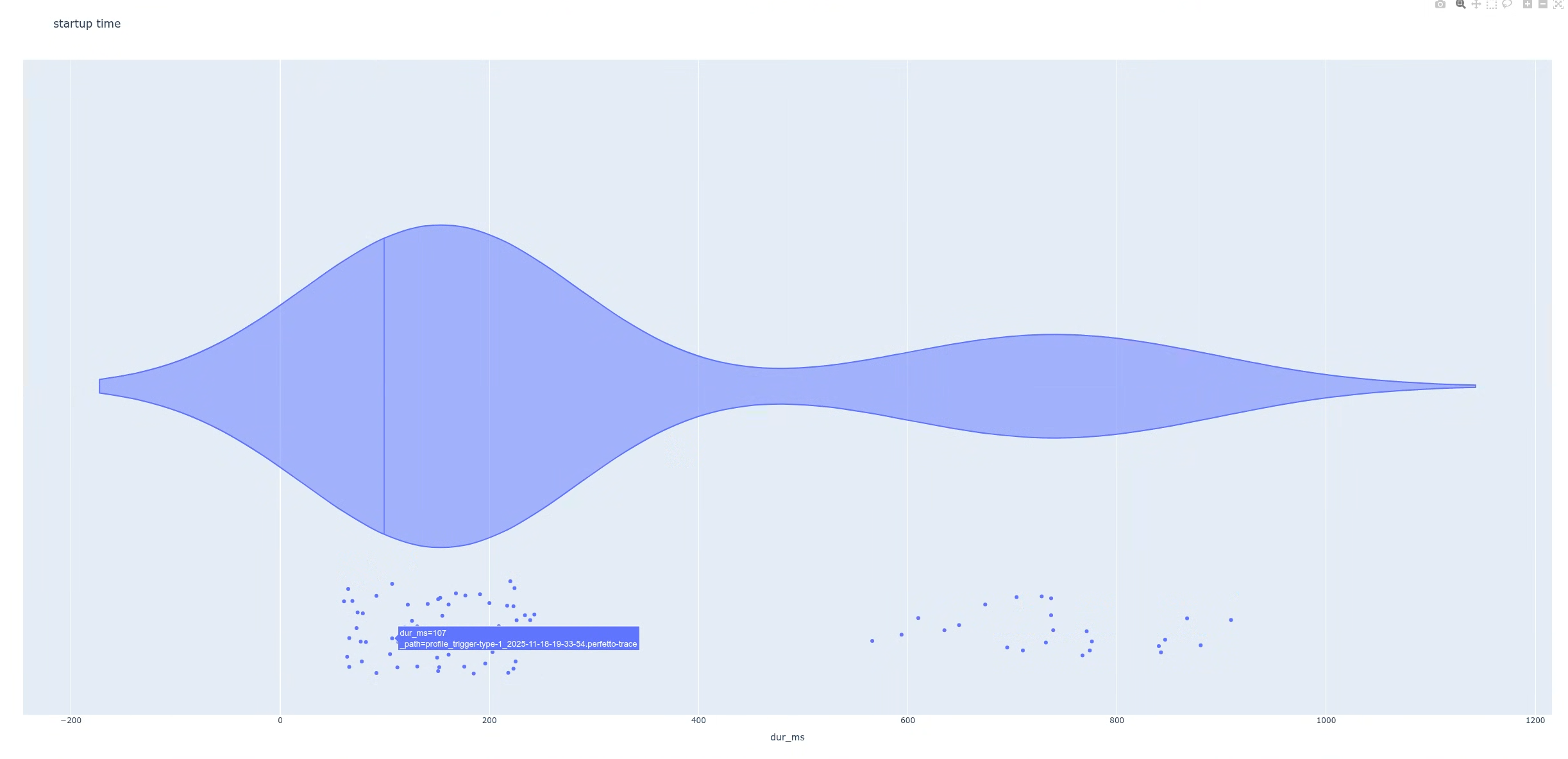
스크립트를 실행하면 스크립트에서 플롯을 생성합니다. 이 경우 플롯은 두 개의 뚜렷한 피크가 있는 이봉 분포를 보여줍니다 (그림 4).
그런 다음 두 모집단의 차이를 찾습니다. 이를 통해 개별 트레이스를 더 자세히 검사할 수 있습니다. 이 예시에서는 데이터 포인트 (지연 시간) 위로 마우스를 가져가면 트레이스 파일 이름을 식별할 수 있도록 플롯이 설정되어 있습니다. 그런 다음 지연 시간이 긴 그룹에 속하는 트레이스 중 하나를 열 수 있습니다.
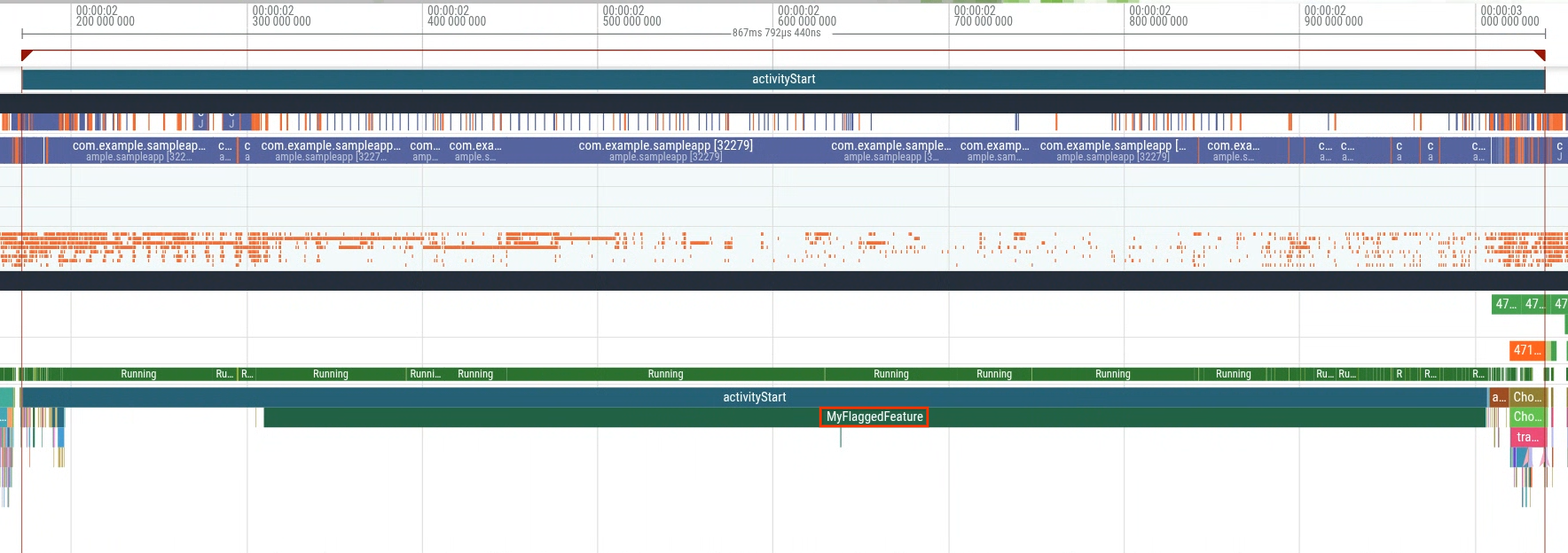
지연 시간이 긴 그룹에서 트레이스를 열면 (그림 5) 시작 중에 실행되는 MyFlaggedFeature라는 추가 슬라이스가 표시됩니다 (그림 6).
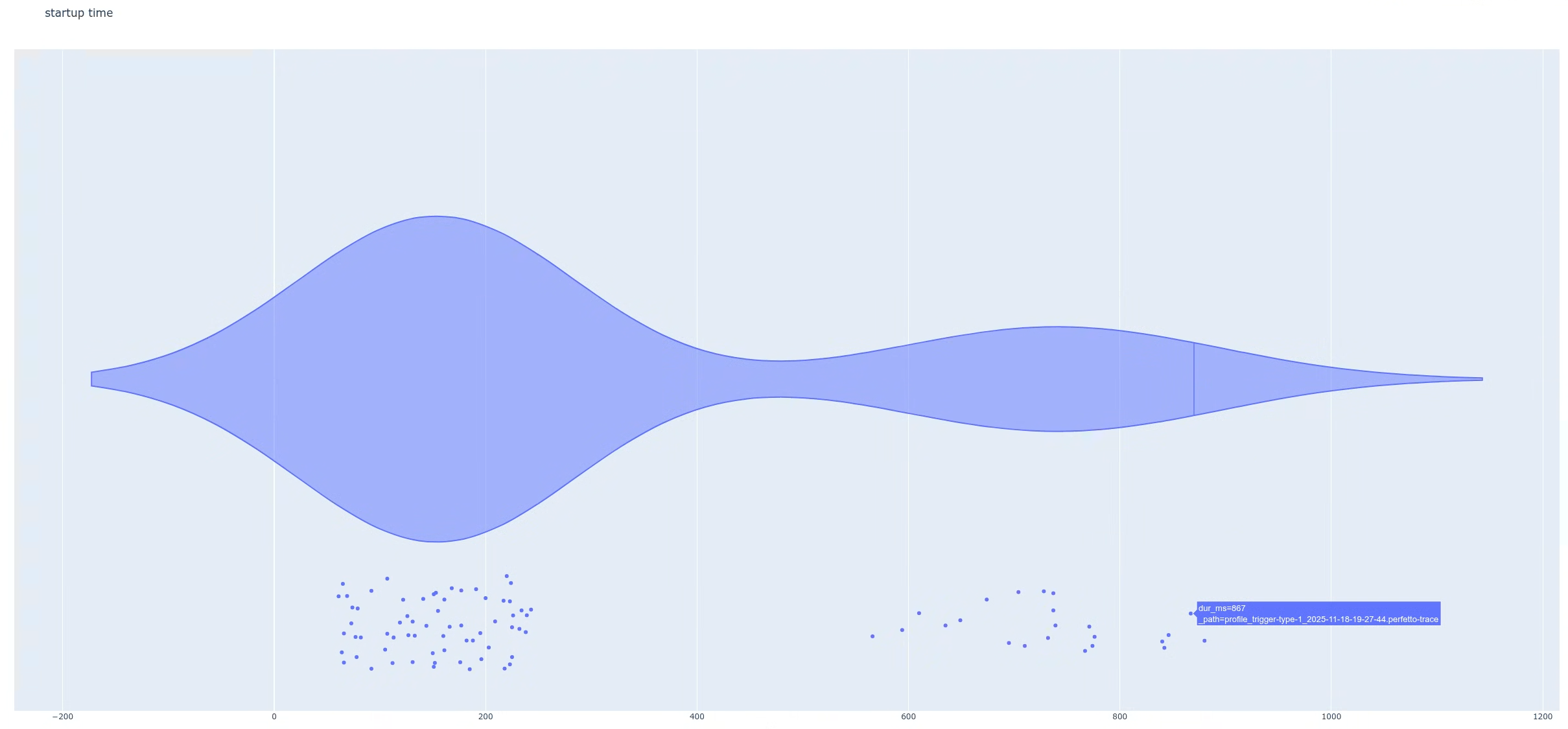
반대로 지연 시간이 짧은 인구 (가장 왼쪽 피크)에서 트레이스를 선택하면 동일한 슬라이스가 없음을 확인할 수 있습니다 (그림 7). 이 비교를 통해 일부 사용자에게 사용 설정된 특정 기능 플래그가 회귀를 트리거함을 알 수 있습니다.
이 예시에서는 대량 추적 분석을 사용할 수 있는 여러 방법 중 하나를 보여줍니다. 다른 사용 사례로는 필드에서 통계를 추출하여 영향을 측정하고, 회귀를 감지하는 등이 있습니다.