
La API de Neural Networks (NNAPI) de Android C está diseñada con el objetivo de ejecutar operaciones con mucha carga de cálculo para aprendizaje automático en dispositivos Android. La NNAPI está diseñada para proporcionar una capa básica de funcionalidad en frameworks de aprendizaje automático de nivel superior (como TensorFlow Lite y Caffe2), que crean y preparan redes neuronales. La API está disponible en todos los dispositivos Android que ejecutan Android 8.1 (nivel de API 27) o versiones posteriores, pero se dejó de usar en Android 15.
La NNAPI admite la formulación de inferencias mediante la aplicación de datos de dispositivos Android a modelos previamente definidos por el programador y preparados. Algunos ejemplos de la formulación de inferencias son la clasificación de imágenes, la predicción del comportamiento del usuario y la selección de respuestas apropiadas para una búsqueda.
La formulación de inferencias en el dispositivo tiene muchos beneficios:
- Latencia: No necesitas enviar una solicitud a través de una conexión de red y esperar una respuesta. Por ejemplo, este aspecto puede ser crítico para las apps de video que procesan fotogramas sucesivos provenientes de una cámara.
- Disponibilidad: La app se ejecuta incluso cuando se encuentra fuera de la cobertura de la red.
- Velocidad: El nuevo hardware específico para procesamiento de redes neuronales proporciona un cálculo considerablemente más rápido que con la CPU de uso general.
- Privacidad: Los datos no salen del dispositivo Android.
- Costo: No se necesitan torres de servidores cuando se realizan todos los cálculos en el dispositivo Android.
También hay intercambios que un desarrollador debe tener en cuenta:
- Utilización del sistema: La evaluación de las redes neuronales implica muchos cálculos, lo que puede aumentar el consumo de la batería. Debes supervisar el estado de la batería si esto es importante para tu app, en especial para cálculos de ejecución prolongada.
- Tamaño de aplicación: Presta atención al tamaño de tus modelos. Los modelos pueden ocupar varios megabytes. Si la agrupación de modelos grandes en tu APK tiene un efecto indebido para los usuarios, puedes descargarlos después de la instalación de la app, usar modelos más pequeños o ejecutar tus cálculos en la nube. La NNAPI no proporciona una funcionalidad para ejecutar modelos en la nube.
Consulta el ejemplo de la API de Neural Networks de Android para ver cómo usar la NNAPI.
Comprende el tiempo de ejecución de la API de Neural Networks
A la NNAPI deben llamarla herramientas, frameworks y bibliotecas de aprendizaje automático que permiten a los desarrolladores preparar sus modelos sin el dispositivo y, luego, implementarlos en dispositivos Android. Por lo general, las apps no usan la NNAPI directamente, sino que emplean marcos de trabajo de aprendizaje automático de nivel superior. Estos marcos de trabajo a la vez pueden usar la NNAPI para realizar operaciones de inferencia aceleradas por hardware en dispositivos compatibles.
Según los requisitos de la app y las capacidades del hardware de un dispositivo Android, el tiempo de ejecución de las redes neuronales de Android puede distribuir de manera eficaz la carga de trabajo de cálculo en procesadores disponibles del dispositivo; se incluyen el hardware de red neuronal dedicado, las unidades de procesamiento de gráficos (GPU) y los procesadores de señal digital (DSP).
En el caso de los dispositivos que no tienen un controlador de proveedores especializado, el tiempo de ejecución de la NNAPI ejecuta las solicitudes en la CPU.
En la figura 1, se muestra una arquitectura de sistema de nivel superior para la NNAPI.
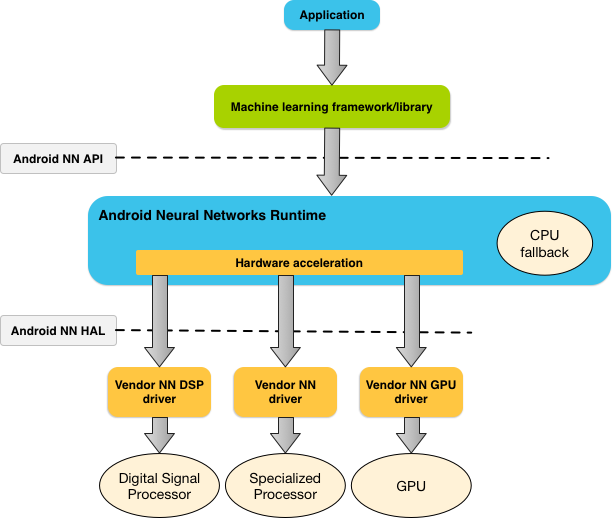
Modelo de programación de la API de redes neuronales
Para realizar cálculos con la NNAPI, primero debes construir un gráfico dirigido que defina los cálculos que se realizarán. Este gráfico de cálculos, combinado con tus datos de entrada (por ejemplo, las ponderaciones y las personalizaciones transmitidas desde un marco de trabajo de aprendizaje automático), forma el modelo para la evaluación del tiempo de ejecución de la NNAPI.
La NNAPI usa cuatro abstracciones principales:
- Modelo: Es un gráfico de cómputos de operaciones matemáticas y de los valores constantes aprendidos a través de un proceso de preparación. Estas operaciones son específicas de las redes neuronales. Entre otras, incluyen la convolución bidimensional (2D), la activación logística (sigmoide) y la activación lineal rectificada (ReLU). La creación de un modelo es una operación sincrónica,
pero una vez que se realiza con éxito, el modelo puede reutilizarse en subprocesos y compilaciones.
En la NNAPI, se representa un modelo como una instancia de
ANeuralNetworksModel. - Compilación: Representa una configuración para la compilación de un modelo de la NNAPI en un código de nivel inferior. La creación de una compilación es una operación sincrónica, pero una vez que se realiza con éxito, el modelo puede reutilizarse en subprocesos y ejecuciones. En la NNAPI, se representa cada compilación como una instancia de
ANeuralNetworksCompilation. - Memoria: Representa la memoria compartida, los archivos asignados a la memoria y los búferes de memoria similares. El uso de un búfer de memoria permite que el tiempo de ejecución de la NNAPI transfiera datos a los controladores de un modo más eficaz. Por lo general, una app crea un búfer de memoria compartido que contiene todos los tensores que se necesitan para definir un modelo. También puedes usar los búferes de memoria a fin de almacenar las entradas y las salidas para una instancia de ejecución. En la NNAPI, se representa cada búfer de memoria como una instancia de
ANeuralNetworksMemory. Ejecución: Interfaz para aplicar un modelo de la NNAPI en un conjunto de entradas y recopilar resultados. La ejecución se puede realizar de forma síncrona o asíncrona.
Para la ejecución asíncrona, varios subprocesos pueden esperar en la misma ejecución. Cuando la ejecución se completa, se liberan todos los subprocesos.
En la NNAPI, se representa cada ejecución como una instancia de
ANeuralNetworksExecution.
En la Figura 2, se muestra el flujo de programación básico.
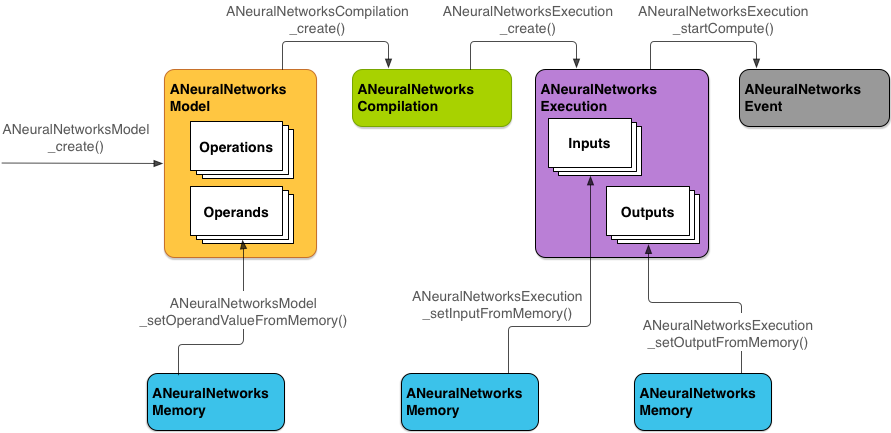
En el resto de esta sección, se describen los pasos para configurar tu modelo de la NNAPI a fin de realizar cómputos, compilar el modelo y ejecutar el modelo compilado.
Proporciona acceso a los datos de preparación
Es probable que tus datos de ponderaciones preparadas y sesgos se almacenen en un archivo. Para proporcionar el tiempo de ejecución de la NNAPI con acceso eficiente a estos datos, crea una instancia de ANeuralNetworksMemory llamando a la función ANeuralNetworksMemory_createFromFd() y, luego, transmite el descriptor del archivo de datos abierto. También puedes especificar marcas de protección de memoria y un desplazamiento donde comienza la región de memoria compartida en el archivo.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Aunque en este ejemplo usamos únicamente una instancia de ANeuralNetworksMemory para todas las ponderaciones, es posible usar más de una instancia de ANeuralNetworksMemory para varios archivos.
Cómo usar búferes de hardware nativo
Puedes usar búferes de hardware nativo para entradas y salidas del modelo, y valores de operandos de constantes. En ciertos casos, un acelerador de NNAPI puede acceder a objetos AHardwareBuffer sin necesidad de que el controlador copie los datos. AHardwareBuffer tiene varias configuraciones diferentes, y no todos los aceleradores NNAPI son compatibles con todas estas configuraciones. Debido a esta limitación, consulta las restricciones que se enumeran en la documentación de referencia de ANeuralNetworksMemory_createFromAHardwareBuffer y prueba la configuración en los dispositivos de destino a fin de garantizar que las compilaciones y las ejecuciones que usan AHardwareBuffer se comporten como esperas; usa la asignación de dispositivos para especificar el acelerador.
Para permitir que el entorno de ejecución de la NNAPI acceda a un objeto AHardwareBuffer, crea una instancia de ANeuralNetworksMemory llamando a la función ANeuralNetworksMemory_createFromAHardwareBuffer y pasando el objeto AHardwareBuffer, como se observa en la siguiente muestra de código:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Cuando la NNAPI ya no necesite acceder al objeto AHardwareBuffer, libera la instancia de ANeuralNetworksMemory correspondiente:
ANeuralNetworksMemory_free(mem2);
Nota:
- Solo puedes usar
AHardwareBufferpara el búfer completo; no puedes usarlo con un parámetroARect. - El tiempo de ejecución de la NNAPI no vaciará el búfer. Deberás asegurarte de que sea posible acceder a los búferes de entrada y salida antes de programar la ejecución.
- Los descriptores de archivo de valla de sincronización no son compatibles.
- Para instancias de
AHardwareBuffercon formatos y bits de uso específicos del proveedor, corresponde a la implementación del proveedor determinar si el cliente o el controlador son responsables de vaciar la caché.
Modelo
Un modelo es la unidad fundamental de cálculos de la NNAPI. Cada modelo se define mediante uno o más operandos y operaciones.
Operandos
Los operandos son objetos de datos usados en la definición del gráfico. Entre estos, se incluyen las entradas y salidas del modelo, los nodos intermedios que contienen los datos que van de una operación a otra y las constantes que se pasan a estas operaciones.
Hay dos tipos de operandos que se pueden agregar a los modelos de la NNAPI: escalares y tensores.
Un operando escalar representa un valor único. La NNAPI es compatible con valores escalares en un punto flotante booleano de 16 bits, un punto flotante de 32 bits, un entero de 32 bits y formatos enteros de 32 bits sin firma.
En la mayoría de las operaciones con la NNAPI se incluyen tensores. Los tensores son arreglos de dimensión n. La NNAPI admite tensores con un punto flotante de 16 bits, un punto flotante de 32 bits, 8 bits cuantificados, 16 bits cuantificados, entero de 32 bits y valores booleanos de 8 bits.
Por ejemplo, en la Figura 3, se representa un modelo con dos operaciones: una suma seguida de una multiplicación. El modelo toma un tensor de entrada y genera uno de salida.
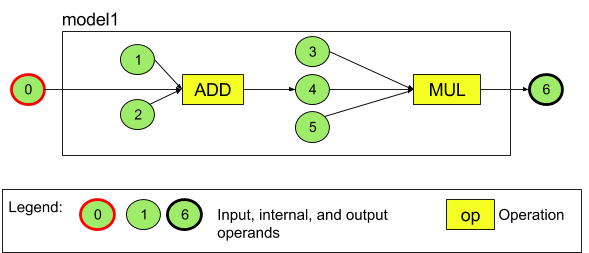
El modelo anterior cuenta con siete operandos. Estos operandos se identifican de forma implícita con el índice del orden en el que se agregan al modelo. Para el primer operando agregado el índice es 0; para el segundo, 1 y así sucesivamente. Los operandos 1, 2, 3 y 5 son operandos de constantes.
No importa el orden en que agregues los operandos. Por ejemplo, el operando de salida del modelo puede ser el primero en agregarse. Lo importante es usar el valor de índice correcto al hacer referencia a un operando.
Los operandos se clasifican por tipos. Estos se especifican cuando se agregan al modelo.
No se puede usar un operando como entrada y salida de un modelo.
Todos los operandos deben ser una entrada de modelo, una constante o el operando de salida de exactamente una operación.
Para obtener información adicional sobre el uso de los operandos, consulta Más información sobre los operandos.
Operaciones
Una operación especifica los cómputos que se realizarán. Cada operación consiste en estos elementos:
- un tipo de operación (por ejemplo, suma, multiplicación y convolución)
- una lista de índices de los operandos que usa la operación para la entrada
- una lista de índices de los operandos que la operación usa para la salida
El orden de estas listas es importante; consulta la referencia de la API NNAPI para ver las entradas y las salidas esperadas de cada tipo de operación.
Debes agregar al modelo los operandos que consume o produce una operación antes de agregar la operación.
No importa el orden en que agregues las operaciones. La NNAPI emplea las dependencias establecidas por el gráfico de cálculos de operandos y operaciones para determinar el orden en que se ejecutan las operaciones.
Las operaciones que admite la NNAPI se resumen en la siguiente tabla:
Problema conocido en el nivel de API 28: Cuando se pasan los tensores ANEURALNETWORKS_TENSOR_QUANT8_ASYMM a la operación ANEURALNETWORKS_PAD, que está disponible en Android 9 (nivel de API 28) y en versiones posteriores, es posible que la salida de la NNAPI no coincida con la salida de los frameworks de aprendizaje automático de nivel superior, como TensorFlow Lite. En su lugar, solo debes pasar ANEURALNETWORKS_TENSOR_FLOAT32.
El problema se resolvió en Android 10 (nivel de API 29) y en versiones posteriores.
Cómo diseñar modelos
En el siguiente ejemplo, creamos el modelo de dos operaciones que se muestra en la Figura 3.
Para crear un modelo, sigue estos pasos:
Llama a la función
ANeuralNetworksModel_create()para definir un modelo vacío.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Agrega los operandos a tu modelo llamando a
ANeuralNetworks_addOperand(). Sus tipos de datos se definen usando la estructura de datosANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Para los operandos con valores constantes, como ponderaciones y sesgos que la app obtiene de un proceso de preparación, usa las funciones
ANeuralNetworksModel_setOperandValue()yANeuralNetworksModel_setOperandValueFromMemory().En el siguiente ejemplo, configuramos los valores de constantes desde el archivo de datos de preparación correspondiente al búfer de memoria que creamos en Proporciona acceso a los datos de preparación.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Para cada operación del gráfico dirigido que desees calcular, agrega la operación a tu modelo llamando a la función
ANeuralNetworksModel_addOperation().Como parámetros para este llamado, tu app debe proporcionar lo siguiente:
- el tipo de operación
- el conteo de valores de entrada
- el arreglo de los índices para operandos de entrada
- el conteo de valores de salida
- la matriz de los índices para operandos de salida
Ten en cuenta que un operando no se puede usar para la entrada y la salida de la misma operación.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Identifica qué operandos debe tratar el modelo como entradas y salidas llamando a la función
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
También puedes especificar si
ANEURALNETWORKS_TENSOR_FLOAT32se puede calcular con un rango o una precisión tan bajos como los del formato de punto flotante IEEE 754 de 16 bits llamando aANeuralNetworksModel_relaxComputationFloat32toFloat16().Llama a
ANeuralNetworksModel_finish()para finalizar la definición de tu modelo. Si no hay errores, esta función muestra un código de resultadoANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Una vez que creas un modelo, puedes compilarlo y ejecutar cada compilación la cantidad de veces que quieras.
Flujo de control
Para incorporar el flujo de control en un modelo de la NNAPI, haz lo siguiente:
Construye los subgrafos de ejecución correspondientes (
thenyelsepara una declaraciónIF;conditionybodypara un bucleWHILE) como modelosANeuralNetworksModel*independientes:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Crea operandos que hagan referencia a esos modelos dentro del modelo que contiene el flujo de control:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Agrega la operación de flujo de control:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Compilación
El paso de compilación determina los procesadores en los que se ejecutará tu modelo y solicita a los controladores correspondientes que se prepararen para su ejecución. Esto puede incluir la generación de código máquina específico de los procesadores en los que se ejecutará el modelo.
Para compilar un modelo, sigue estos pasos:
Llama a la función
ANeuralNetworksCompilation_create()para crear una nueva instancia de compilación.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
También puedes usar la asignación de dispositivos para seleccionar de forma explícita en cuáles dispositivos se ejecutará.
Como alternativa, puedes condicionar el modo en que el tiempo de ejecución realiza intercambios entre el uso de la batería y la velocidad de ejecución. Puedes hacerlo llamando a
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
Estas son algunas de las preferencias que puedes especificar:
ANEURALNETWORKS_PREFER_LOW_POWER: Prioriza la ejecución en un modo que minimiza el consumo de la batería. Esto se recomienda para las compilaciones que se ejecutan con frecuencia.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: Prioriza mostrar una única respuesta lo más rápido posible, aun cuando esto produzca un mayor consumo de energía. Es el valor predeterminado.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: Prioriza la maximización de la capacidad de procesamiento de fotogramas sucesivos; por ejemplo, cuando se procesan fotogramas sucesivos provenientes de la cámara.
De manera opcional, puedes configurar el almacenamiento en caché de la compilación llamando a
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Usa
getCodeCacheDir()para el objetocacheDir. Eltokenespecificado debe ser único para cada modelo dentro de la aplicación.Llama a
ANeuralNetworksCompilation_finish()para finalizar la definición de la compilación. Si no hay errores, esta función muestra un código de resultadoANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Cómo detectar y asignar dispositivos
En dispositivos que ejecutan Android 10 (nivel de API 29) y versiones posteriores, la NNAPI proporciona funciones que permiten que las apps y las bibliotecas del framework de aprendizaje automático obtengan información sobre los dispositivos disponibles y especifiquen los que se usarán para ejecución. Proporcionar información sobre los dispositivos disponibles permite a las apps obtener la versión exacta de los controladores que se encuentran en un dispositivo para evitar incompatibilidades conocidas. Al otorgar a las apps la capacidad de especificar cuáles dispositivos ejecutarán diferentes secciones de un modelo, las apps se pueden optimizar para el dispositivo Android en el que se implementarán.
Cómo detectar dispositivos
Usa ANeuralNetworks_getDeviceCount para obtener la cantidad de dispositivos disponibles. Para cada dispositivo, usa ANeuralNetworks_getDevice a fin de configurar una instancia de ANeuralNetworksDevice en una referencia a ese dispositivo.
Una vez que tengas referencia de un dispositivo, podrás encontrar más información adicional sobre él con las siguientes funciones:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Cómo asignar dispositivos
Usa ANeuralNetworksModel_getSupportedOperationsForDevices para detectar las operaciones de un modelo que se pueden ejecutar en dispositivos específicos.
Para controlar qué aceleradores se usarán en la ejecución, llama a ANeuralNetworksCompilation_createForDevices en lugar de a ANeuralNetworksCompilation_create.
Usa el objeto ANeuralNetworksCompilation resultante con normalidad.
La función muestra un error si el modelo proporcionado contiene operaciones que no son compatibles con los dispositivos seleccionados.
Si se especifican varios dispositivos, el tiempo de ejecución es responsable de distribuir el trabajo en los dispositivos.
Al igual que con otros dispositivos, la implementación de CPU de la NNAPI se representa con una instancia de ANeuralNetworksDevice con el nombre nnapi-reference y el tipo ANEURALNETWORKS_DEVICE_TYPE_CPU. Cuando se llama a ANeuralNetworksCompilation_createForDevices, la implementación de la CPU no se usa para controlar los casos de falla de la compilación y la ejecución del modelo.
Es responsabilidad de la aplicación hacer una partición de un modelo en submodelos que se puedan ejecutar en los dispositivos especificados. En las aplicaciones que no requieren particiones manuales, se debe seguir llamando a ANeuralNetworksCompilation_create para usar todos los dispositivos disponibles (incluida la CPU) con el fin de acelerar el modelo. Si el modelo no es completamente compatible con los dispositivos que especificas con ANeuralNetworksCompilation_createForDevices, se mostrará ANEURALNETWORKS_BAD_DATA.
Cómo realizar particiones de modelos
Si hay varios dispositivos disponibles para el modelo, el tiempo de ejecución de la NNAPI distribuye el trabajo entre los dispositivos. Por ejemplo, si se proporcionó más de un dispositivo a ANeuralNetworksCompilation_createForDevices, se considerarán todos los dispositivos especificados en el momento de asignar el trabajo. Ten en cuenta que, si el dispositivo de la CPU no está en la lista, se inhabilitará la ejecución de la CPU. Cuando uses ANeuralNetworksCompilation_create, se tendrán en cuenta todos los dispositivos disponibles, incluida la CPU.
La distribución se realiza seleccionando de la lista de dispositivos disponibles, para cada operación del modelo, el dispositivo que admite la operación y declara el mejor rendimiento, es decir, el tiempo de ejecución más rápido o el consumo de energía más bajo, según la preferencia de ejecución especificada por el cliente. Este algoritmo de partición no considera posibles ineficiencias causadas por el IO entre los diferentes procesadores, por lo que, cuando se especifican varios procesadores (ya sea de manera explícita cuando se usa ANeuralNetworksCompilation_createForDevices o implícita cuando se usa ANeuralNetworksCompilation_create), es importante perfilar la aplicación resultante.
Para comprender cómo se particionó tu modelo mediante la NNAPI, busca en los registros de Android un mensaje (en el nivel INFO con la etiqueta ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name es el nombre descriptivo de la operación en el gráfico y device-index es el índice del dispositivo candidato en la lista de dispositivos.
Esta lista es la entrada proporcionada a ANeuralNetworksCompilation_createForDevices o, si se usa ANeuralNetworksCompilation_createForDevices, la lista de dispositivos que se muestra durante la iteración en todos los dispositivos que usan ANeuralNetworks_getDeviceCount y ANeuralNetworks_getDevice.
El mensaje (en el nivel INFO con la etiqueta ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Este mensaje indica que se aceleró todo el gráfico en el dispositivo device-name.
Ejecución
El paso de ejecución aplica el modelo a un conjunto de entradas y almacena las salidas de cálculo en uno o más búferes de usuario o espacios de memoria asignados por tu app.
Para ejecutar un modelo compilado, sigue estos pasos:
Llama a la función
ANeuralNetworksExecution_create()para crear una nueva instancia de ejecución.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Especifica el lugar en que tu app lee los valores de entrada para el cálculo. Tu app puede leer valores de entrada en un búfer de usuario o en un espacio de memoria asignado llamando a
ANeuralNetworksExecution_setInput()oANeuralNetworksExecution_setInputFromMemory(), según corresponda.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Especifica el punto en el que tu app escribe los valores de salida. Tu app puede escribir valores de salida en un búfer de usuario o en un espacio de memoria asignado llamando a
ANeuralNetworksExecution_setOutput()oANeuralNetworksExecution_setOutputFromMemory(), respectivamente.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Programa el comienzo de la ejecución llamando a la función
ANeuralNetworksExecution_startCompute(). Si no hay errores, esta función muestra un código de resultadoANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Llama a la función
ANeuralNetworksEvent_wait()para esperar a que se complete la ejecución. Si no hay errores, esta función muestra un código de resultadoANEURALNETWORKS_NO_ERROR. La espera puede producirse en un subproceso diferente del que inició la ejecución.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
También puedes aplicar un conjunto diferente de entradas al modelo compilado usando la misma instancia de compilación para crear una nueva instancia
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Ejecución síncrona
La ejecución asíncrona dedica tiempo a la generación y la sincronización de los subprocesos. Además, la latencia puede variar mucho y tener un retraso de hasta 500 microsegundos entre el momento en el que se notifica o se activa un subproceso y el momento en el que se enlaza al núcleo de la CPU.
Para mejorar la latencia, puedes dirigir una aplicación con el fin de realizar una llamada de inferencia síncrona al tiempo de ejecución. La llamada mostrará una inferencia solo cuando se complete, en lugar de mostrarla cuando se inicie. En lugar de llamar a ANeuralNetworksExecution_startCompute para una llamada de inferencia asíncrona al tiempo de ejecución, la aplicación llama a ANeuralNetworksExecution_compute a fin de hacer una llamada síncrona al tiempo de ejecución. Una llamada a ANeuralNetworksExecution_compute no realiza un ANeuralNetworksEvent y no se sincroniza con una llamada a ANeuralNetworksEvent_wait.
Ejecuciones en ráfaga
En dispositivos Android que ejecutan Android 10 (nivel de API 29) y versiones posteriores, la NNAPI es compatible con ejecuciones en ráfaga mediante el objeto ANeuralNetworksBurst. Las ejecuciones en ráfaga son una secuencia de ejecuciones de la misma compilación que se producen en una sucesión rápida, por ejemplo, en los marcos de una captura de cámara o en ejemplos de audio sucesivos. El uso de objetos ANeuralNetworksBurst puede generar ejecuciones más rápidas, ya que indica a los aceleradores que los recursos se pueden volver a usar entre ejecuciones y que los aceleradores deben permanecer en un estado de alto rendimiento mientras dure la ráfaga.
ANeuralNetworksBurst introduce solo un cambio pequeño en la ruta de ejecución normal. Puedes crear un objeto de ráfaga con ANeuralNetworksBurst_create, como se muestra en el siguiente fragmento de código:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
Las ejecuciones en ráfaga son síncronas. Sin embargo, en lugar de usar ANeuralNetworksExecution_compute para llevar a cabo cada inferencia, se sincronizan los diversos objetos ANeuralNetworksExecution con el mismo ANeuralNetworksBurst en llamadas a la función ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Libera el objeto ANeuralNetworksBurst con ANeuralNetworksBurst_free cuando ya no sea necesario.
// Cleanup ANeuralNetworksBurst_free(burst);
Colas de comandos asíncronas y ejecución cercada
En Android 11 y versiones posteriores, la NNAPI admite una forma adicional de programar la ejecución asíncrona a través del método ANeuralNetworksExecution_startComputeWithDependencies(). Cuando usas este método, la ejecución espera a que se marquen todos los eventos dependientes antes de comenzar la evaluación. Una vez que se completa la ejecución y las salidas están listas para consumirse, se marca el evento que se muestra.
Según qué dispositivos controlen la ejecución, el evento puede estar respaldado por una valla de sincronización. Debes llamar a ANeuralNetworksEvent_wait() para esperar al evento y recuperar los recursos que usó la ejecución. Puedes importar las vallas de sincronización en un objeto de evento mediante ANeuralNetworksEvent_createFromSyncFenceFd(), y puedes exportarlas desde un objeto de evento mediante ANeuralNetworksEvent_getSyncFenceFd().
Salidas con tamaño dinámico
Para compatibilidad con modelos en los que el tamaño de la salida depende de los datos de entrada, es decir, en los que el tamaño no se puede determinar durante el tiempo de ejecución del modelo, usa ANeuralNetworksExecution_getOutputOperandRank y ANeuralNetworksExecution_getOutputOperandDimensions.
En el siguiente ejemplo de código, se muestra cómo hacerlo:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Cómo realizar la limpieza
El paso de limpieza controla la liberación de recursos internos usados para tu cálculo.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Cómo administrar errores y resguardar la CPU
Si se produce un error durante la partición, si un controlador no puede compilar un modelo (o parte de él) o si un controlador no puede ejecutar un modelo compilado (o parte de él), la NNAPI puede recurrir a su propia implementación de CPU de una o más operaciones.
Si el cliente de la NNAPI contiene versiones optimizadas de la operación (por ejemplo, TFLite), puede ser ventajoso inhabilitar la recuperación de la CPU y manejar las fallas con la implementación optimizada de la operación del cliente.
En Android 10, si la compilación se realiza con ANeuralNetworksCompilation_createForDevices, se inhabilitará el resguardo de la CPU.
En Android P, la ejecución de la NNAPI se resguarda en la CPU si falla la ejecución en el controlador.
Esto también se aplica en Android 10 cuando se usa ANeuralNetworksCompilation_create en lugar de ANeuralNetworksCompilation_createForDevices.
La primera ejecución se resguarda en esa única partición, y si la falla continúa, vuelve a intentar todo el modelo en la CPU.
Si falla la partición o la compilación, se probará todo el modelo en la CPU.
Hay casos en que algunas operaciones no son admitidos por la CPU; en estas situaciones, la compilación o ejecución fallará en lugar de resguardarse.
Incluso después de inhabilitar la recuperación de la CPU, es posible que haya operaciones en el modelo que estén programadas en la CPU. Si la CPU está en la lista de procesadores permitidos proporcionados a ANeuralNetworksCompilation_createForDevices, y es el único procesador que admite esas operaciones o es el procesador que afirma el mejor rendimiento para esas operaciones, se elegirá como un ejecutor primario (no de resguardo).
Para asegurarte de que no haya ejecución en la CPU, usa ANeuralNetworksCompilation_createForDevices y, al mismo tiempo, excluye la nnapi-reference de la lista de dispositivos.
A partir de Android P, es posible inhabilitar la recuperación en el momento de la ejecución en las compilaciones DEBUG estableciendo la propiedad debug.nn.partition en 2.
Dominios de memoria
En Android 11 y versiones posteriores, la NNAPI admite dominios de memoria que proporcionan interfaces asignables para memorias opacas. Esto permite que las aplicaciones pasen memorias nativas del dispositivo entre ejecuciones, para que la NNAPI no copie ni transforme datos de forma innecesaria cuando se realicen ejecuciones consecutivas en el mismo controlador.
La función de dominio de la memoria está diseñada para tensores que son mayormente internos en el controlador y que no necesitan acceso frecuente al lado del cliente. Algunos ejemplos incluyen los tensores de estado en modelos de secuencia. Para los tensores que necesitan acceso frecuente a la CPU en el lado del cliente, usa grupos de memoria compartida en su lugar.
Para asignar una memoria opaca, realiza los siguientes pasos:
Llama a la función
ANeuralNetworksMemoryDesc_create()para crear un nuevo descriptor de memoria:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Llama a
ANeuralNetworksMemoryDesc_addInputRole()yANeuralNetworksMemoryDesc_addOutputRole()para especificar todas las funciones de entrada y salida previstas.// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
De manera opcional, llama a
ANeuralNetworksMemoryDesc_setDimensions()para especificar las dimensiones de la memoria.// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Llama a
ANeuralNetworksMemoryDesc_finish()para finalizar la definición del descriptor.ANeuralNetworksMemoryDesc_finish(desc);
Asigna todos las memorias necesarias pasando el descriptor a
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Libera el descriptor de la memoria cuando ya no lo necesites.
ANeuralNetworksMemoryDesc_free(desc);
El cliente solo puede usar el objeto ANeuralNetworksMemory creado con ANeuralNetworksExecution_setInputFromMemory() o ANeuralNetworksExecution_setOutputFromMemory() según las funciones especificadas en el objeto ANeuralNetworksMemoryDesc. Los argumentos de desplazamiento y longitud se deben establecer en 0, lo que indica que se usa toda la memoria. El cliente también puede configurar o extraer explícitamente el contenido de la memoria mediante ANeuralNetworksMemory_copy().
Puedes crear memorias opacas con funciones de dimensiones o clasificaciones sin especificar.
En ese caso, la creación de memoria puede fallar y mostrar el estado ANEURALNETWORKS_OP_FAILED si no es compatible con el controlador subyacente. Se recomienda al cliente que implemente la lógica de resguardo mediante la asignación de un búfer lo suficientemente grande respaldado por AHardwareBuffer de modo BLOB o Ashmen.
Cuando la NNAPI ya no necesite acceder al objeto de memoria opaco, libera la instancia ANeuralNetworksMemory correspondiente:
ANeuralNetworksMemory_free(opaqueMem);
Cómo medir el rendimiento
Para evaluar el rendimiento de tu app, puedes medir el tiempo de ejecución o generar perfiles.
Tiempo de ejecución
Si quieres determinar el tiempo de ejecución total, puedes usar la API de ejecución síncrona y medir el tiempo que ocupa la llamada. Si quieres determinar el tiempo de ejecución total en un nivel inferior de la pila de software, puedes usar ANeuralNetworksExecution_setMeasureTiming y ANeuralNetworksExecution_getDuration para obtener lo siguiente:
- tiempo de ejecución en un acelerador (no en el controlador, que se ejecuta en el procesador del host)
- tiempo de ejecución en el controlador, incluido el tiempo en el acelerador
El tiempo de ejecución en el controlador excluye la sobrecarga, como la que corresponde al tiempo de ejecución y el IPC necesario para que el tiempo de ejecución se comunique con el controlador.
Estas API miden la duración entre los eventos de trabajo enviado y los eventos de trabajo completado, en lugar del tiempo que dedica un controlador o un acelerador a llevar a cabo la inferencia, posiblemente interrumpida por el cambio de contexto.
Por ejemplo, si se inicia la inferencia 1, el controlador detiene el trabajo a fin de realizar la inferencia 2, luego reanuda y completa la inferencia 1; el tiempo de ejecución para la inferencia 1 incluirá el tiempo durante el que se detuvo el trabajo para realizar la inferencia 2.
Esta información de tiempo puede ser útil con el objetivo de que la implementación de producción de una aplicación recopile la telemetría para uso sin conexión. Puedes usar los datos de tiempo para modificar la app con el fin de obtener un mayor rendimiento.
Cuando uses esta funcionalidad, ten en cuenta lo siguiente:
- Es posible que recopilar información de tiempo tenga un costo de rendimiento.
- Solo un controlador es capaz de calcular el tiempo dedicado a sí mismo o al acelerador, excluyendo el tiempo de ejecución en la NNAPI y en el IPC.
- Puedes usar estas API solo con una
ANeuralNetworksExecutioncreada conANeuralNetworksCompilation_createForDevicesconnumDevices = 1. - No se requiere ningún controlador para informar el registro de tiempo.
Cómo generar el perfil de tu aplicación con Android Systrace
A partir de Android 10, la NNAPI genera automáticamente eventos systrace que puedes usar para generar un perfil de tu aplicación.
La fuente de la NNAPI viene con una utilidad parse_systrace para procesar los eventos systrace generados por tu aplicación y generar una vista de tabla que muestre el tiempo empleado en las diferentes fases del ciclo de vida del modelo (creación de instancia, preparación, ejecución de compilación y finalización) y las diferentes capas de las aplicaciones. Las capas en las que está dividida tu aplicación son las siguientes:
Application: Es el código de la aplicación principal.Runtime: Indica el entorno de ejecución de NNAPI.IPC: Es la comunicación entre procesos que se lleva a cabo entre el entorno de ejecución de NNAPI y el código del controlador.Driver: Es el proceso del controlador del acelerador.
Cómo generar los datos del análisis de perfiles
Si revisaste el árbol fuente de AOSP en $ANDROID_BUILD_TOP y usas el ejemplo de clasificación de imágenes de TFLite como aplicación de destino, puedes generar los datos de perfiles de la NNAPI mediante los siguientes pasos:
- Inicia el systrace de Android con el siguiente comando:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
El parámetro -o trace.html indica que los registros se escribirán en trace.html. Cuando generes perfiles de tu propia aplicación, deberás reemplazar org.tensorflow.lite.examples.classification por el nombre del proceso especificado en el manifiesto de tu app.
Esto mantendrá una de las consolas de shell ocupadas. No ejecutes el comando en segundo plano, ya que espera interactivamente a que finalice un enter.
- Una vez que se haya iniciado el recopilador systrace, inicia tu app y ejecuta la prueba comparativa.
En nuestro caso, puedes iniciar la app de clasificación de imágenes desde Android Studio o directamente desde la IU de tu teléfono de prueba si ya está instalada. Si deseas generar algunos datos NNAPI, debes configurar la app para el uso de NNAPI seleccionando NNAPI como dispositivo de destino en el cuadro de diálogo de configuración de la app.
Cuando se complete la prueba, presiona
enteren la terminal de la consola activa desde el paso 1 para finalizar systrace.Ejecuta la utilidad
systrace_parserpara generar estadísticas acumulativas:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
El analizador muestra los siguientes parámetros:
- --total-times: Muestra el tiempo total empleado en una capa, incluido el tiempo que se esperó para la ejecución de una llamada a una capa subyacente
- --print-detail: Imprime todos los eventos que se recopilaron de systrace
- --per-execution: Solo imprime la ejecución y sus subfases (según los tiempos por ejecución) en lugar de las estadísticas para todas las fases
- --json: Genera el resultado en formato JSON
A continuación, se muestra un ejemplo del resultado:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
El analizador puede fallar si los eventos recopilados no representan un seguimiento completo de la aplicación. En particular, podría fallar si los eventos systrace generados para marcar el final de una sección están presentes en el registro sin un evento de inicio de sección asociado. Esto suele suceder si se generan algunos eventos de una sesión de generación de perfiles anterior cuando inicias el recolector de systrace. En este caso, tendrás que volver a ejecutar la generación de perfiles.
Cómo agregar estadísticas para el código de tu aplicación al resultado de systrace_parser
La aplicación de parse_systrace se basa en la funcionalidad incorporada de systrace de Android. Puedes agregar registros para operaciones específicas en tu app mediante la API de systrace (para Java, para aplicaciones nativas) con nombres de eventos personalizados.
Para asociar tus eventos personalizados con las fases del ciclo de vida de la aplicación, agrega el nombre del evento a una de las siguientes strings:
[NN_LA_PI]: Evento a nivel de la aplicación para la inicialización[NN_LA_PP]: evento a nivel de la aplicación para la preparación[NN_LA_PC]: evento a nivel de la aplicación para la compilación[NN_LA_PE]: Evento a nivel de la aplicación para la ejecución
A continuación, se muestra un ejemplo de cómo puedes modificar el código de ejemplo de clasificación de imágenes TFLite si agregas una sección runInferenceModel para la fase Execution y la capa Application que contiene otras secciones preprocessBitmap que no se tendrán en cuenta en los registros de NNAPI. La sección runInferenceModel será parte de los eventos systrace que procesará el analizador nnapi systrace:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Calidad de servicio
En Android 11 y versiones posteriores, la NNAPI habilita una mejor calidad de servicio (QoS), ya que permite que una aplicación indique las prioridades relativas de sus modelos, el tiempo de espera máximo para que se prepare un modelo determinado y el tiempo de espera máximo para que se complete un cálculo en particular. Android 11 también incluye códigos de resultado adicionales de la NNAPI que permiten que las apps comprendan fallas, como plazos de ejecución caducados.
Cómo establecer la prioridad de una carga de trabajo
Para establecer la prioridad de una carga de trabajo de la NNAPI, llama a ANeuralNetworksCompilation_setPriority() antes de llamar a ANeuralNetworksCompilation_finish().
Cómo establecer plazos
Las aplicaciones pueden establecer plazos tanto para la compilación del modelo como la inferencia.
- A fin de configurar el tiempo de espera de la compilación, llama a
ANeuralNetworksCompilation_setTimeout()antes de llamar aANeuralNetworksCompilation_finish(). - Para configurar el tiempo de espera de la inferencia, llama a
ANeuralNetworksExecution_setTimeout()antes de iniciar la compilación.
Más información sobre los operandos
En la siguiente sección, se describen temas avanzados vinculados al uso de operandos.
Tensores cuantificados
Un tensor cuantificado es un modo compacto de representar un arreglo de dimensión n de los valores de punto flotante.
La NNAPI admite tensores cuantificados asimétricos de 8 bits. Para estos tensores, el valor de cada celda está representado por un entero de 8 bits. Una escala y un valor de punto cero se asocian con el tensor. Estos se usan para convertir los enteros de 8 bits en los valores de punto flotante que se representan.
La fórmula es:
(cellValue - zeroPoint) * scale
El valor "zeroPoint" es un entero de 32 bits y la escala un valor de punto flotante de 32 bits.
En comparación con los tensores de valores de punto flotante de 32 bits, los tensores cuantificados de 8 bits tienen dos ventajas:
- Tu aplicación será más pequeña, ya que las ponderaciones preparadas tomarán un cuarto del tamaño de los tensores de 32 bits.
- A menudo, los cálculos se pueden ejecutar más rápido. Esto se debe a la menor cantidad de datos que deben obtenerse de la memoria y a la eficacia de los procesadores, como DSP, para realizar cálculos con enteros.
Aunque es posible convertir un modelo de punto flotante a uno cuantificado, nuestra experiencia demuestra que se logran mejores resultados con el entrenamiento directo de un modelo cuantificado. Por lo tanto, la red neuronal aprende a compensar el aumento de granularidad de cada valor. Para cada tensor cuantizado, la escala y los valores zeroPoint se determinan durante el proceso de preparación.
En la NNAPI, se definen tipos de tensores cuantizados fijando el campo de tipos ANeuralNetworksOperandType de la estructura de datos en ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
También se especifican la escala y el valor zeroPoint del tensor en esa estructura de datos.
Además de los tensores cuantizados asimétricos de 8 bits, la NNAPI es compatible con lo siguiente:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL, que puedes usar para representar ponderaciones en operacionesCONV/DEPTHWISE_CONV/TRANSPOSED_CONVANEURALNETWORKS_TENSOR_QUANT16_ASYMM, que puedes usar para el estado interno deQUANTIZED_16BIT_LSTMANEURALNETWORKS_TENSOR_QUANT8_SYMM, que puede ser una entrada deANEURALNETWORKS_DEQUANTIZE
Operandos opcionales
En algunas operaciones, como ANEURALNETWORKS_LSH_PROJECTION, se toman operandos opcionales. Para indicar en el modelo que se omitió el operando opcional, llama a la función ANeuralNetworksModel_setOperandValue() y pasa NULL por el búfer y 0 por la longitud.
Si la decisión respecto de que el operando esté presente o no varía para cada ejecución, se indica que el operando se omite mediante la función ANeuralNetworksExecution_setInput() o ANeuralNetworksExecution_setOutput(), y se pasa NULL por el búfer y 0 por la longitud.
Tensores de clasificación desconocida
Android 9 (nivel de API 28) presentó operandos de modelo de dimensiones desconocidas, pero clasificación conocida (el número de dimensiones). Android 10 (API nivel 29) presentó tensores de clasificación desconocida, como se muestra en ANeuralNetworksOperandType.
Comparativas de la NNAPI
Las comparativas de la NNAPI están disponibles en AOSP en platform/test/mlts/benchmark (app de comparativas) y platform/test/mlts/models (modelos y conjuntos de datos).
Las comparativas evalúan la latencia y la precisión, y comparan los controladores con el mismo trabajo usando Tensorflow Lite, que se ejecuta en la CPU, para los mismos modelos y conjuntos de datos.
Para usar la comparativa, haz lo siguiente:
Conecta un dispositivo Android de destino a tu computadora, abre una ventana de terminal y asegúrate de que se pueda acceder al dispositivo mediante adb.
Si hay más de un dispositivo Android conectado, exporta la variable de entorno
ANDROID_SERIALdel dispositivo de destino.Navega hasta el directorio de fuentes de nivel superior de Android.
Ejecuta los siguientes comandos:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
Cuando finalice la ejecución de la comparativa, se mostrarán los resultados en el formato de una página HTML que se pasa a
xdg-open.
Registros de la NNAPI
La NNAPI genera información de diagnóstico útil en los registros del sistema. Para analizar los registros, usa la utilidad logcat.
Habilita el registro detallado de la NNAPI para fases o componentes específicos estableciendo la propiedad debug.nn.vlog (usa adb shell) en la siguiente lista de valores, separados por espacio, dos puntos o coma:
model: Construcción de modeloscompilation: Generación del plan de ejecución del modelo y la compilaciónexecution: Ejecución del modelocpuexe: Ejecución de operaciones mediante la implementación de CPU de la NNAPImanager: Extensiones, interfaces disponibles e información relacionada con las capacidades de la NNAPIallo1: Todos los elementos anteriores
Por ejemplo, para habilitar el registro detallado completo, usa el comando adb shell setprop debug.nn.vlog all. Para inhabilitar el registro detallado, usa el comando adb shell setprop debug.nn.vlog '""'.
Una vez habilitado, el registro detallado genera entradas de registro en el nivel INFO, con una etiqueta establecida para el nombre de fase o componente.
Además de los mensajes controlados de debug.nn.vlog, los componentes de la API NNAPI proporcionan otras entradas de registro en varios niveles, cada una con una etiqueta de registro específica.
Si quieres obtener una lista de los componentes, usa la siguiente expresión para buscar en el árbol de fuentes:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
Por el momento, con esta expresión se muestran las siguientes etiquetas:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Manager
- Memory
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operaciones
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Para controlar el nivel de mensajes de registro que muestra logcat, usa la variable de entorno ANDROID_LOG_TAGS.
Si quieres ver el conjunto completo de mensajes de registro de la NNAPI y también inhabilitar el resto, configura ANDROID_LOG_TAGS de la siguiente manera:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Puedes configurar ANDROID_LOG_TAGS con el siguiente comando:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Ten en cuenta que este es solo un filtro que se aplica a logcat. Deberás establecer la propiedad debug.nn.vlog en all para generar información de registro detallada.