


Android Çalışma Zamanı (ART) ekibi, derlenen koddan veya bellek regresyonlarından ödün vermeden derleme süresini% 18 kısalttı. Bu iyileştirme, derleme süresini kısaltırken bellek kullanımından veya derlenen kodun kalitesinden ödün vermemeyi amaçlayan 2025 girişimimizin bir parçasıydı.
Derleme süresi hızını optimize etmek ART için çok önemlidir. Örneğin, tam zamanında (JIT) derleme, uygulamaların verimliliğini ve genel cihaz performansını doğrudan etkiler. Daha hızlı derlemeler, optimizasyonların devreye girmesinden önceki süreyi kısaltarak daha sorunsuz ve daha hızlı yanıt veren bir kullanıcı deneyimi sağlar. Ayrıca, hem JIT hem de AOT için derleme süresi hızındaki iyileştirmeler, derleme işlemi sırasında kaynak tüketiminin azalmasına yol açar. Bu da özellikle alt düzey cihazlarda pil ömrü ve cihazın ısınması açısından faydalıdır.
Derleme zamanı hızını artıran bu iyileştirmelerin bazıları Haziran 2025 Android sürümünde kullanıma sunuldu. Diğerleri ise yıl sonu Android sürümünde kullanıma sunulacak. Ayrıca, 12 ve sonraki sürümleri kullanan tüm Android kullanıcıları, Mainline güncellemeleri aracılığıyla bu iyileştirmeleri alabilir.
Optimizasyon derleyicisini optimize etme
Derleyiciyi optimize etmek her zaman bir denge oyunudur. Hızı ücretsiz olarak elde edemezsiniz, bir şeylerden vazgeçmeniz gerekir. Kendimize çok net ve zorlu bir hedef belirledik: Derleyiciyi hızlandırmak ancak bunu yaparken bellek gerilemelerine yol açmamak ve en önemlisi, ürettiği kodun kalitesini düşürmemek. Derleyici daha hızlı olmasına rağmen uygulamalar daha yavaş çalışıyorsa başarısız olmuşuzdur.
Bu katı ölçütleri karşılayan akıllı çözümler bulmak için harcamaya razı olduğumuz tek kaynak, kendi geliştirme süremizdi. İyileştirilecek alanları bulmak ve çeşitli sorunlara doğru çözümler üretmek için nasıl çalıştığımıza daha yakından bakalım.
Değerli olabilecek optimizasyonları bulma
Bir metriği optimize etmeye başlamadan önce bu metriği ölçebilmeniz gerekir. Aksi takdirde, iyileştirme yapıp yapmadığınızdan asla emin olamazsınız. Neyse ki, bir değişiklikten önce ve sonra ölçüm yapmak için kullandığınız cihazı kullanmak ve cihazınızın termal kısılmasını önlemek gibi bazı önlemler aldığınız sürece derleme süresi hızı oldukça tutarlıdır. Ayrıca, neler olup bittiğini anlamamıza yardımcı olan derleyici istatistikleri gibi deterministik ölçümlerimiz de var.
Bu iyileştirmeler için feda ettiğimiz kaynak geliştirme süremiz olduğundan, olabildiğince hızlı bir şekilde yineleme yapmak istedik. Bu nedenle, çözümlerin prototipini oluşturmak için bir avuç temsili uygulamayı (birinci taraf uygulamaları, üçüncü taraf uygulamaları ve Android işletim sisteminin kendisi) kullandık. Daha sonra, hem manuel hem de otomatik testlerle son uygulamanın buna değdiğini geniş kapsamlı bir şekilde doğruladık.
Özenle seçilmiş bu APK'larla yerel olarak manuel derleme başlatır, derlemenin profilini alır ve zamanımızı nerede geçirdiğimizi görselleştirmek için pprof'u kullanırız.
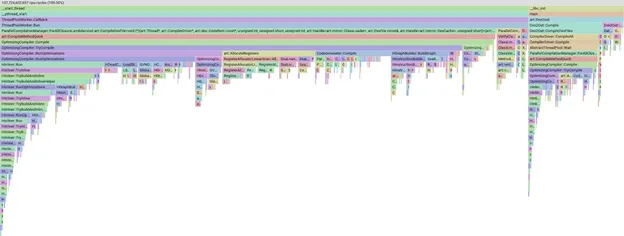
pprof'taki bir profilin flame grafiği örneği
pprof aracı çok güçlüdür ve verileri dilimlememize, filtrelememize ve sıralamamıza olanak tanır. Böylece, örneğin hangi derleyici aşamalarının veya yöntemlerinin en çok zaman aldığını görebiliriz. pprof'un kendisi hakkında ayrıntılı bilgi vermeyeceğiz. Yalnızca çubuğun daha büyük olmasının derleme işleminin daha uzun sürdüğü anlamına geldiğini bilmeniz yeterlidir.
Bu görünümlerden biri, en çok zamanı hangi yöntemlerin aldığını görebileceğiniz "aşağıdan yukarıya" görünümüdür. Aşağıdaki resimde, derleme süresinin% 1'inden fazlasını oluşturan Kill adlı bir yöntem görüyoruz. Diğer önemli yöntemlerden bazıları da blog yayınında daha sonra ele alınacaktır.
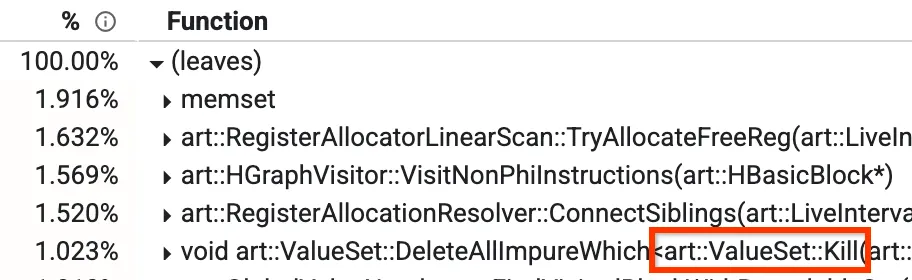
Profilin alttan üste görünümü
Optimizasyon yapan derleyicimizde Global Value Numbering (GVN) adlı bir aşama vardır. Bu işlevin genel olarak ne yaptığıyla ilgili endişelenmenize gerek yoktur. Ancak ilgili kısım, bu işlevin bir filtreye göre bazı düğümleri sileceği "Kill" adlı bir yönteme sahip olduğunu bilmektir. Tüm düğümleri tek tek kontrol etmesi gerektiğinden bu işlem zaman alır. O sırada etkin olan düğümlerden bağımsız olarak, kontrolün yanlış olacağını önceden bildiğimiz bazı durumlar olduğunu fark ettik. Bu gibi durumlarda, iterasyon tamamen atlanabilir. Böylece, iterasyon sayısı% 1,023'ten yaklaşık% 0,3'e düşürülerek GVN'nin çalışma süresi yaklaşık %15 oranında iyileştirilir.
Değerli optimizasyonları uygulama
Zamanın nerede harcandığını nasıl ölçeceğinizi ve tespit edeceğinizi ele aldık ancak bu sadece başlangıç. Bir sonraki adım, derleme için harcanan süreyi nasıl optimize edeceğinizdir.
Genellikle yukarıdaki "Kill" örneğinde olduğu gibi bir durumda, düğümler arasında nasıl yineleme yaptığımıza bakarız ve örneğin işlemleri paralel olarak yaparak veya algoritmanın kendisini iyileştirerek bunu daha hızlı hale getiririz. Aslında ilk başta bunu denedik ve yapacak bir şey bulamadığımızda "Bir dakika..." diyerek çözümün (bazı durumlarda) hiç yineleme yapmamak olduğunu fark ettik. Bu tür optimizasyonlar yapılırken bütünü gözden kaçırmak kolaydır.
Diğer durumlarda ise aşağıdakiler de dahil olmak üzere çeşitli teknikler kullandık:
- bir optimizasyonun değerli sonuçlar üretip üretmeyeceğine ve dolayısıyla atlanıp atlanamayacağına karar vermek için sezgisel yöntemler kullanma
- hesaplanmış verileri önbelleğe almak için ek veri yapıları kullanma
- Hız artışı elde etmek için mevcut veri yapılarını değiştirme
- bazı durumlarda döngüleri önlemek için sonuçları geç hesaplama
- Doğru soyutlamayı kullanın. Gereksiz özellikler kodu yavaşlatabilir.
- sık kullanılan bir işaretçinin birçok yükleme boyunca takip edilmesini önleme
Optimizasyonların uygulanmaya değer olup olmadığını nasıl anlarız?
İşin güzel yanı da bu. Bir alanın çok fazla derleme süresi kullandığı tespit edildikten ve bu alanı iyileştirmek için geliştirme süresi ayrıldıktan sonra bazen çözüm bulamayabilirsiniz. Belki de yapacak bir şey yoktur, uygulaması çok uzun sürer, başka bir metriği önemli ölçüde geriletir, kod tabanı karmaşıklığını artırır vb. Bu blog yayınında görebileceğiniz her başarılı optimizasyonun yanı sıra, sonuç vermeyen sayısız optimizasyon olduğunu unutmayın.
Benzer bir durumdaysanız mümkün olduğunca az çalışarak metriği ne kadar iyileştireceğinizi tahmin etmeye çalışın. Bu, sırasıyla şu anlama gelir:
- Daha önce topladığınız metriklerle veya sadece içgüdüsel olarak tahmin yapma
- Hızlı ve basit bir prototiple tahmin yapma
- Çözüm uygulayın.
Çözümünüzün dezavantajlarını tahmin etmeyi unutmayın. Örneğin, ek veri yapılarını kullanacaksanız ne kadar bellek kullanmaya razısınız?
Daha ayrıntılı bilgi
Daha fazla uzatmadan, uyguladığımız değişikliklerden bazılarına göz atalım.
FindReferenceInfoOf adlı bir yöntemi optimize etmek için değişiklik yaptık. Bu yöntem, bir girişi bulmak için vektörde doğrusal arama yapıyordu. Bu veri yapısını, FindReferenceInfoOf'un O(n) yerine O(1) olması için talimatın kimliğine göre dizine eklenecek şekilde güncelledik. Ayrıca, yeniden boyutlandırmayı önlemek için vektörü önceden ayırdık. Vektöre kaç giriş eklediğimizi sayan ekstra bir alan eklememiz gerektiğinden belleği biraz artırdık. Ancak bu, en yüksek bellek artmadığı için küçük bir fedakarlıktı. Bu, LoadStoreAnalysis aşamamızın% 34-66 oranında hızlanmasını sağladı ve derleme süresinde% 0,5-1,8 oranında iyileşme elde edildi.
Çeşitli yerlerde kullandığımız HashSet'in özel bir uygulaması var. Bu veri yapısını oluşturmak önemli ölçüde zaman alıyordu ve bunun nedenini öğrendik. Bu veri yapısı, uzun yıllar önce yalnızca çok büyük HashSet'lerin kullanıldığı birkaç yerde kullanılıyordu ve bu nedenle optimize edilecek şekilde ayarlandı. Ancak günümüzde bu özellik, yalnızca birkaç girişle ve kısa bir kullanım ömrüyle ters yönde kullanılıyordu. Bu, bu büyük HashSet'i oluşturarak döngüleri boşa harcadığımız ancak onu silmeden önce yalnızca birkaç giriş için kullandığımız anlamına geliyordu. Bu değişiklikle derleme süresini yaklaşık% 1, 3-2 oranında iyileştirdik. Ek bir avantaj olarak, daha önce olduğu gibi büyük veri yapıları kullanmadığımız için bellek kullanımı yaklaşık% 0,5-1 oranında azaldı.
Veri yapılarını kopyalamayı önlemek için lambda'ya referansla veri yapıları ileterek derleme süresini yaklaşık% 0,5-1 oranında kısalttık. Bu, ilk incelemede gözden kaçırılan ve yıllarca kod tabanımızda kalan bir sorundu. pprof'taki profillere göz attığımızda bu yöntemlerin çok sayıda veri yapısı oluşturup yok ettiğini fark ettik. Bu durum, yöntemleri inceleyip optimize etmemize yol açtı.
Derlenmiş çıktıyı yazma aşamasını hesaplanmış değerleri önbelleğe alarak hızlandırdık. Bu, toplam derleme süresinde yaklaşık% 1,3-2,8'lik bir iyileşme sağladı. Ancak ek muhasebe işlemleri çok fazla zamanımızı alıyordu ve otomatik testlerimiz bellek gerilemesi konusunda bizi uyardı. Daha sonra aynı koda ikinci kez baktık ve yalnızca bellek gerilemesini gidermekle kalmayıp derleme süresini de yaklaşık %0,5-1,8 daha iyileştiren bir yeni sürüm uyguladık. Bu ikinci değişiklikte, iki veri yapısından birini ortadan kaldırmak için bu aşamanın nasıl çalışması gerektiğini yeniden düzenlememiz ve yeniden tasarlamamız gerekti.
Daha iyi performans elde etmek için işlev çağrılarını satır içi yapan bir optimize edici derleyicimiz var. Hangi yöntemlerin satır içine alınacağını seçmek için hem herhangi bir hesaplama yapmadan önce sezgisel yöntemler kullanırız hem de satır içine alma işlemini tamamlamadan hemen önce, işlem yapıldıktan sonra son kontrolleri gerçekleştiririz. Bu yöntemlerden herhangi biri, satır içi eklemenin uygun olmadığını (örneğin, çok fazla yeni talimat ekleneceği) tespit ederse yöntem çağrısı satır içi eklenmez.
Zaman açısından maliyetli bir hesaplama yapmadan önce satır içi yerleştirmenin başarılı olup olmayacağını tahmin etmek için "son kontroller" kategorisindeki iki kontrolü "bulgusal" kategorisine taşıdık. Bu bir tahmin olduğundan mükemmel değildir ancak yeni sezgisel yöntemlerimizin, performansı etkilemeden daha önce satır içi olanların% 99,9'unu kapsadığını doğruladık. Bu yeni sezgisel yöntemlerden biri gerekli DEX kayıtları (~% 0,2-1,3 iyileştirme), diğeri ise talimat sayısı (~% 2 iyileştirme) ile ilgiliydi.
Çeşitli yerlerde kullandığımız özel bir BitVector uygulamamız var. Belirli sabit boyutlu bit vektörleri için yeniden boyutlandırılabilir BitVector sınıfını daha basit bir BitVectorView ile değiştirdik. Bu, bazı dolaylılıkları ve çalışma zamanı aralığı kontrollerini ortadan kaldırır ve bit vektörü nesnelerinin oluşturulmasını hızlandırır.
Ayrıca, BitVectorView sınıfı, her zaman eski BitVector'da olduğu gibi uint32_t kullanmak yerine temel depolama türünde şablonlaştırıldı. Bu sayede, örneğin Union() gibi bazı işlemler 64 bit platformlarda iki kat daha fazla biti birlikte işleyebilir. Etkilenen işlevlerin örnekleri, Android OS derlenirken toplamda% 1'den fazla azaltıldı. Bu işlem, çeşitli değişiklikler [1, 2, 3, 4, 5, 6] kapsamında yapıldı.
Tüm optimizasyonlardan ayrıntılı olarak bahsetseydik bütün gün burada kalırdık. Başka optimizasyonlarla da ilgileniyorsanız uyguladığımız diğer değişikliklere göz atın:
- Derleme sürelerini yaklaşık %0,6-1,6 oranında iyileştirmek için muhasebe ekleyin.
- Mümkünse döngüleri önlemek için verileri geç hesaplayın.
- Kullanılmayacaksa önceden hesaplama çalışmasını atlamak için kodumuzu yeniden düzenleyin.
- Ayırıcı başka yerlerden kolayca alınabildiğinde bazı bağımlı yükleme zincirlerinden kaçının.
- Gereksiz işi önlemek için onay işareti eklemenin bir başka örneği.
- Kayıt ayırıcıda kayıt türüne (çekirdek/FP) göre sık sık dallanmaktan kaçının.
- Derleme zamanında bazı dizilerin başlatıldığından emin olun. Bunu yapmak için clang'e güvenmeyin.
- Bazı döngüleri temizleyin. Döngü yan etkileri nedeniyle kapsayıcının dahili işaretçilerini yeniden yüklemesi gerekmediğinden, clang'in daha iyi optimize edebileceği aralık döngülerini kullanın. Her giriş için satır içi "InputAt(.)" aracılığıyla döngüde "HInstruction::GetInputRecords()" sanal işlevini çağırmaktan kaçının.
- Derleyici optimizasyonundan yararlanarak ziyaretçi kalıbı için Accept() işlevlerinden kaçının.
Sonuç
ART'nin derleme süresi hızını iyileştirme konusundaki çalışmalarımız önemli gelişmelerle sonuçlandı. Bu sayede Android daha akıcı ve verimli hale gelirken pil ömrü ve cihazın ısınması da iyileştirildi. Optimizasyonları titizlikle belirleyip uygulayarak, bellek kullanımından veya kod kalitesinden ödün vermeden derleme süresinde önemli kazanımlar elde etmenin mümkün olduğunu gösterdik.
Bu süreçte pprof gibi araçlarla profil oluşturma, yineleme isteği ve bazen daha az verimli yolları terk etme gibi adımlar yer aldı. ART ekibinin ortak çabaları, derleme süresini önemli bir oranda azaltmakla kalmadı, gelecekteki gelişmelerin de temelini oluşturdu.
Bu iyileştirmelerin tümü, 2025 yıl sonu Android güncellemesinde ve Android 12 ile sonraki sürümlerde ana hat güncellemeleri aracılığıyla kullanılabilir. Optimizasyon sürecimizle ilgili bu ayrıntılı incelemenin, derleyici mühendisliğinin karmaşıklıkları ve avantajları hakkında değerli bilgiler sağladığını umuyoruz.
Yazan:
Okumaya devam edin
-


Ürün Haberleri
Android XR'da Unreal Engine ve Godot için resmi desteğin kullanıma sunulduğunu duyurmaktan heyecan duyuyoruz. Ayrıca, üretkenliğinizi artırmak ve yeni XR özelliklerini etkinleştirmek için tasarlanmış yeni araçlar da kullanıma sunuyoruz: Android XR Engine Hub ve Android XR Interaction Framework.
Luke Hopkins • Okuma süresi: 4 dakika
-


Ürün Haberleri
Android 17'nin yayınlanmasıyla birlikte uyarlanabilir öncelikli geliştirme standardına geçiş yapıyoruz. Kullanıcılarınız artık tek bir form faktörüne bağlı kalmıyor. Gün içinde telefonlar, katlanabilir cihazlar, tabletler, dizüstü bilgisayarlar, otomotiv ekranları ve etkileyici XR ortamları arasında geçiş yapıyorlar.
Fahd Imtiaz • Okuma süresi: 4 dakika
-


Ürün Haberleri
İçeriğinizin keşfedilebilirliğini artırmak ve uygulamanızı gelecekteki TV deneyimlerine hazırlamak için tasarlanmış Google TV özelliklerini ve geliştirici araçlarını sizinle paylaşmaktan heyecan duyuyoruz.
Paul Lammertsma • Okuma süresi: 4 dakika
Gelişmelerden haberdar olun
Android geliştirmeyle ilgili en son analizleri her hafta gelen kutunuza alın.
