
Android Neural Networks API (NNAPI) הוא Android C API שנועד להפעיל פעולות עתירות חישוב ללמידת מכונה במכשירי Android. NNAPI נועד לספק שכבת בסיס של פונקציונליות למסגרות למידת מכונה ברמה גבוהה יותר, כמו TensorFlow Lite ו-Caffe2, שיוצרות ומאמנות רשתות עצביות. ה-API זמין בכל מכשירי Android עם Android 8.1 (רמת API 27) ומעלה, אבל הוא הוצא משימוש ב-Android 15.
NNAPI תומך בהסקת מסקנות על ידי החלת נתונים ממכשירי Android על מודלים שאומנו בעבר והוגדרו על ידי מפתחים. דוגמאות להסקת מסקנות כוללות סיווג של תמונות, חיזוי של התנהגות משתמשים ובחירה של תשובות מתאימות לשאילתת חיפוש.
להסקת מסקנות במכשיר יש הרבה יתרונות:
- זמן אחזור: לא צריך לשלוח בקשה דרך חיבור לרשת ולחכות לתשובה. לדוגמה, זה יכול להיות קריטי לאפליקציות וידאו שמבצעות עיבוד של פריימים עוקבים שמגיעים ממצלמה.
- זמינות: האפליקציה פועלת גם כשאין כיסוי רשת.
- מהירות: חומרה חדשה שספציפית לעיבוד של רשתות נוירונים מספקת חישוב מהיר משמעותית בהשוואה ליחידת עיבוד מרכזית (CPU) למטרות כלליות בלבד.
- פרטיות: הנתונים לא יוצאים ממכשיר Android.
- עלות: לא נדרשת חוות שרתים כשכל החישובים מתבצעים במכשיר Android.
יש גם פשרות שהמפתחים צריכים לקחת בחשבון:
- ניצול המערכת: הערכה של רשתות עצביות כוללת הרבה חישובים, מה שעלול להגביר את השימוש בסוללה. אם אתם חוששים שהסוללה תתרוקן מהר מדי באפליקציה שלכם, במיוחד אם מדובר בחישובים ארוכים, כדאי לעקוב אחרי תקינות הסוללה.
- גודל האפליקציה: חשוב לשים לב לגודל של המודלים. יכול להיות שהמודלים יתפסו כמה מגה-בייט של נפח אחסון. אם הוספת מודלים גדולים לחבילת ה-APK תשפיע באופן לא רצוי על המשתמשים, כדאי לשקול להוריד את המודלים אחרי התקנת האפליקציה, להשתמש במודלים קטנים יותר או להריץ את החישובים בענן. NNAPI לא מספק פונקציונליות להרצת מודלים בענן.
בדוגמה Android Neural Networks API sample אפשר לראות איך משתמשים ב-NNAPI.
הסבר על זמן הריצה של Neural Networks API
ספריית NNAPI נועדה לשמש ספריות, מסגרות וכלים של למידת מכונה, שמאפשרים למפתחים לאמן את המודלים שלהם מחוץ למכשיר ולפרוס אותם במכשירי Android. בדרך כלל אפליקציות לא משתמשות ב-NNAPI באופן ישיר, אלא במסגרות למידת מכונה ברמה גבוהה יותר. המסגרות האלה יכולות להשתמש ב-NNAPI כדי לבצע פעולות היסק עם האצת חומרה במכשירים נתמכים.
בהתאם לדרישות של האפליקציה וליכולות החומרה במכשיר Android, זמן הריצה של רשת הנוירונים ב-Android יכול להפיץ ביעילות את עומס העבודה של החישוב בין המעבדים הזמינים במכשיר, כולל חומרה ייעודית של רשת נוירונים, יחידות לעיבוד גרפי (GPU) ומעבדים של אותות דיגיטליים (DSP).
במכשירי Android שאין להם דרייבר ספציפי של ספק, זמן הריצה של NNAPI מבצע את הבקשות ב-CPU.
איור 1 מציג את ארכיטקטורת המערכת ברמה גבוהה של NNAPI.
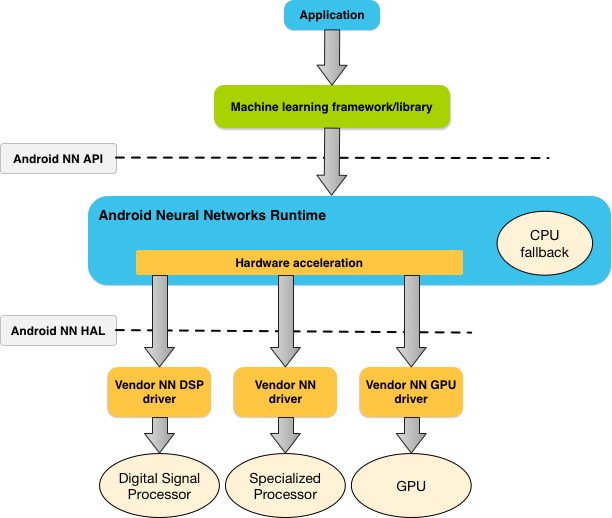
מודל התכנות של Neural Networks API
כדי לבצע חישובים באמצעות NNAPI, קודם צריך ליצור גרף מכוון שמגדיר את החישובים שיש לבצע. גרף החישוב הזה, בשילוב עם נתוני הקלט (לדוגמה, המשקלים וההטיות שמועברים ממסגרת של למידת מכונה), יוצר את המודל להערכת זמן הריצה של NNAPI.
ממשק NNAPI משתמש בארבעה רכיבי הפשטה עיקריים:
- מודל: גרף חישוב של פעולות מתמטיות והערכים הקבועים שנלמדו בתהליך אימון. הפעולות האלה ספציפיות לרשתות עצביות. הן כוללות קונבולוציה דו-ממדית (2D), הפעלה לוגיסטית (סיגמואידית), הפעלה לינארית מתוקנת (ReLU) ועוד. יצירת מודל היא פעולה סינכרונית.
אחרי שיוצרים אותו בהצלחה, אפשר להשתמש בו שוב בשרשורים ובהידור.
ב-NNAPI, מודל מיוצג כמופע של
ANeuralNetworksModel. - Compilation: מייצג הגדרה של קומפילציה של מודל NNAPI לקוד ברמה נמוכה יותר. יצירת קומפילציה היא פעולה סינכרונית. אחרי שיוצרים אותו בהצלחה, אפשר להשתמש בו שוב בשרשורים ובהפעלות. ב-NNAPI, כל קומפילציה מיוצגת כמופע
ANeuralNetworksCompilation. - זיכרון: מייצג זיכרון משותף, קבצים עם מיפוי זיכרון ומאגרי זיכרון דומים. שימוש במאגר זיכרון מאפשר לזמן הריצה של NNAPI להעביר נתונים למנהלי התקנים בצורה יעילה יותר. בדרך כלל אפליקציה יוצרת מאגר משותף של זיכרון שמכיל כל טנסור שנדרש להגדרת מודל. אפשר גם להשתמש במאגרי זיכרון כדי לאחסן את הקלט והפלט של מופע הפעלה. ב-NNAPI, כל מאגר זיכרון מיוצג כמופע
ANeuralNetworksMemory. הפעלה: ממשק להחלת מודל NNAPI על קבוצת קלט ולאיסוף התוצאות. אפשר לבצע את ההפעלה באופן סינכרוני או אסינכרוני.
בהרצה אסינכרונית, כמה שרשורים יכולים להמתין לאותה הרצה. כשההרצה הזו מסתיימת, כל ה-threads משוחררים.
ב-NNAPI, כל הרצה מיוצגת כמופע
ANeuralNetworksExecution.
תרשים 2 מציג את תהליך התכנות הבסיסי.
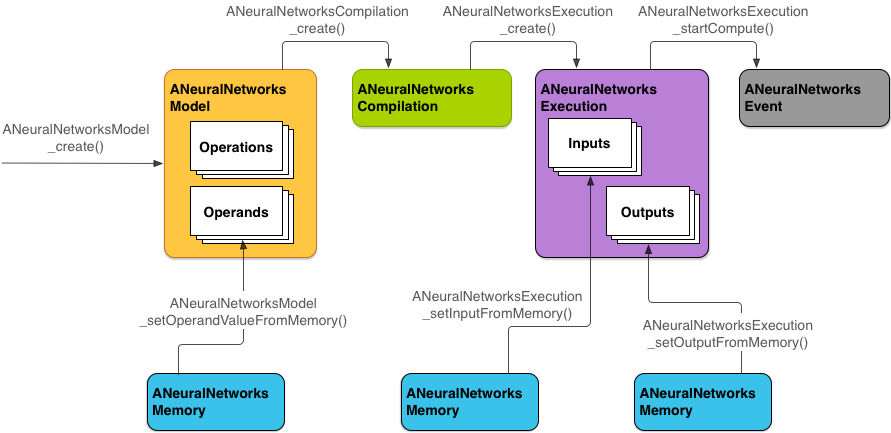
בהמשך הקטע הזה מתוארים השלבים להגדרת מודל NNAPI לביצוע חישובים, לקומפילציה של המודל ולהרצה של המודל שעבר קומפילציה.
מתן גישה לנתוני אימון
הנתונים של המשקלים וההטיות שאומנו כנראה מאוחסנים בקובץ. כדי לספק לזמן הריצה של NNAPI גישה יעילה לנתונים האלה, יוצרים מופע של ANeuralNetworksMemory על ידי קריאה לפונקציה ANeuralNetworksMemory_createFromFd() והעברת מתאר הקובץ של קובץ הנתונים שנפתח. אפשר גם לציין דגלים להגנה על הזיכרון ואת ההיסט שבו מתחיל אזור הזיכרון המשותף בקובץ.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
בדוגמה הזו השתמשנו רק במופע אחד של ANeuralNetworksMemory לכל המשקלים, אבל אפשר להשתמש ביותר ממופע אחד של ANeuralNetworksMemory לכמה קבצים.
שימוש במאגרי חומרה מקוריים
אפשר להשתמש במאגרי חומרה מקוריים עבור ערכי קלט, פלט וערכי אופרנד קבועים של המודל. במקרים מסוימים, מאיץ NNAPI יכול לגשת לאובייקטים AHardwareBuffer בלי שהמנהל יצטרך להעתיק את הנתונים. AHardwareBuffer כולל הרבה תצורות שונות, ויכול להיות שמאיץ NNAPI מסוים לא יתמוך בכל התצורות האלה. בגלל המגבלה הזו, כדאי לעיין במגבלות שמפורטות בANeuralNetworksMemory_createFromAHardwareBufferמאמרי עזרה ולבצע בדיקה מראש במכשירי היעד כדי לוודא שהקומפילציות וההפעלות שמשתמשות ב-AHardwareBuffer מתנהלות כמצופה. לשם כך, צריך להשתמש בהקצאת מכשירים כדי לציין את המאיץ.
כדי לאפשר לזמן הריצה של NNAPI לגשת לאובייקט AHardwareBuffer, צריך ליצור מופע ANeuralNetworksMemory על ידי קריאה לפונקציה ANeuralNetworksMemory_createFromAHardwareBuffer והעברת האובייקט AHardwareBuffer, כמו בדוגמת הקוד הבאה:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
כש-NNAPI כבר לא צריך לגשת לאובייקט AHardwareBuffer, צריך לשחרר את המופע ANeuralNetworksMemory המתאים:
ANeuralNetworksMemory_free(mem2);
הערה:
- אפשר להשתמש ב-
AHardwareBufferרק עבור המאגר כולו, ולא עם הפרמטרARect. - זמן הריצה של NNAPI לא ינקה את המאגר. לפני שתקבעו את מועד ההפעלה, תצטרכו לוודא שיש גישה למאגרי הקלט והפלט.
- אין תמיכה בתיאורי קבצים של גדרות סנכרון.
- במקרה של
AHardwareBufferעם פורמטים ספציפיים לספק וביטים של שימוש, ההטמעה של הספק קובעת אם הלקוח או מנהל ההתקן אחראים לניקוי המטמון.
דגם
מודל הוא יחידת החישוב הבסיסית ב-NNAPI. כל מודל מוגדר על ידי אופרנד אחד או יותר ופעולות.
אופרנדים
אופרנדים הם אובייקטים של נתונים שמשמשים להגדרת הגרף. הם כוללים את נתוני הקלט והפלט של המודל, את הצמתים הביניים שמכילים את הנתונים שזורמים מפעולה אחת לאחרת ואת הקבועים שמועברים לפעולות האלה.
יש שני סוגים של אופרנדים שאפשר להוסיף למודלים של NNAPI: סקלרים וטנסורים.
ערך סקלרי מייצג ערך יחיד. NNAPI תומך בערכים סקלריים בפורמטים של בוליאני, נקודה צפה של 16 ביט, נקודה צפה של 32 ביט, מספר שלם של 32 ביט ומספר שלם לא חתום של 32 ביט.
רוב הפעולות ב-NNAPI כוללות טנסורים. טנסורים הם מערכים n-ממדיים. NNAPI תומך בטנסורים עם נקודה צפה של 16 ביט, נקודה צפה של 32 ביט, קוונטיזציה של 8 ביט, קוונטיזציה של 16 ביט, מספר שלם של 32 ביט וערכים בוליאניים של 8 ביט.
לדוגמה, באיור 3 מוצג מודל עם שתי פעולות: חיבור ואחריו כפל. המודל מקבל טנסור קלט ומפיק טנסור פלט אחד.
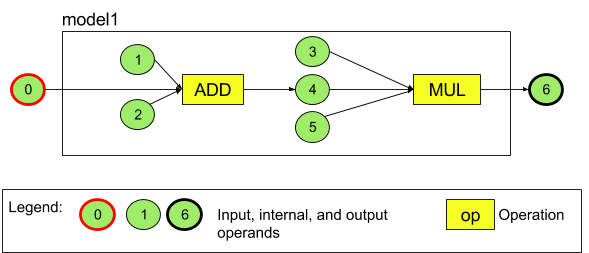
למודל שלמעלה יש שבעה אופרנדים. האופרנדים האלה מזוהים באופן מרומז לפי האינדקס של הסדר שבו הם נוספים למודל. האופרנד הראשון שנוסף הוא באינדקס 0, השני באינדקס 1 וכן הלאה. האופרנדים 1, 2, 3 ו-5 הם אופרנדים קבועים.
הסדר שבו מוסיפים את האופרנדים לא משנה. לדוגמה, אופרנד הפלט של המודל יכול להיות הראשון שמוסיפים. החלק החשוב הוא להשתמש בערך האינדקס הנכון כשמתייחסים לאופרנד.
לאופרנדים יש סוגים. הם מצוינים כשהם מתווספים למודל.
אי אפשר להשתמש באופרנד גם כקלט וגם כפלט של מודל.
כל אופרנד חייב להיות קלט של מודל, קבוע או אופרנד פלט של פעולה אחת בלבד.
מידע נוסף על שימוש באופרנדים זמין במאמר מידע נוסף על אופרנדים.
תפעול
פעולה מציינת את החישובים שיש לבצע. כל פעולה מורכבת מהרכיבים הבאים:
- סוג פעולה (לדוגמה, חיבור, כפל, קונבולוציה),
- רשימה של אינדקסים של האופרנדים שהפעולה משתמשת בהם כקלט, וגם
- רשימה של אינדקסים של האופרנדים שהפעולה משתמשת בהם לפלט.
הסדר ברשימות האלה חשוב. אפשר לעיין בהפניה ל-NNAPI API כדי לראות את הקלט והפלט הצפויים של כל סוג פעולה.
צריך להוסיף למודל את האופרנדים שהפעולה צורכת או מייצרת לפני שמוסיפים את הפעולה.
אין חשיבות לסדר שבו מוסיפים פעולות. NNAPI מסתמך על התלות שנוצרת על ידי גרף החישוב של אופרנדים ופעולות כדי לקבוע את סדר הביצוע של הפעולות.
בטבלה הבאה מפורטות הפעולות ש-NNAPI תומך בהן:
בעיה מוכרת ברמת API 28: כשמעבירים טנסורים של ANEURALNETWORKS_TENSOR_QUANT8_ASYMM לפעולה ANEURALNETWORKS_PAD, שזמינה ב-Android 9 (רמת API 28) ובגרסאות מתקדמות יותר, יכול להיות שהפלט מ-NNAPI לא יהיה זהה לפלט ממסגרות למידת מכונה ברמה גבוהה יותר, כמו TensorFlow Lite. במקום זאת, צריך להעביר רק את ANEURALNETWORKS_TENSOR_FLOAT32.
הבעיה נפתרה ב-Android 10 (רמת API 29) ואילך.
יצירת מודלים
בדוגמה הבאה, אנחנו יוצרים את המודל עם שתי הפעולות שמופיע באיור 3.
כדי לבנות את המודל, מבצעים את השלבים הבאים:
קוראים לפונקציה
ANeuralNetworksModel_create()כדי להגדיר מודל ריק.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
מוסיפים את האופרנדים למודל על ידי קריאה ל-
ANeuralNetworks_addOperand(). סוגי הנתונים שלהם מוגדרים באמצעות מבנה הנתוניםANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6לגבי אופרנדים עם ערכים קבועים, כמו משקלים והטיות שהאפליקציה מקבלת מתהליך אימון, משתמשים בפונקציות
ANeuralNetworksModel_setOperandValue()ו-ANeuralNetworksModel_setOperandValueFromMemory().בדוגמה הבאה, אנחנו מגדירים ערכים קבועים מקובץ נתוני האימון בהתאם למאגר הזיכרון שיצרנו בקטע מתן גישה לנתוני אימון.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));לכל פעולה בגרף המכוון שרוצים לחשב, מוסיפים את הפעולה למודל על ידי קריאה לפונקציה
ANeuralNetworksModel_addOperation().האפליקציה צריכה לספק את הפרמטרים הבאים לקריאה הזו:
- סוג הפעולה
- מספר ערכי הקלט
- מערך של האינדקסים של האופרנדים של הקלט
- מספר ערכי הפלט
- מערך של האינדקסים של אופרנדים של פלט
שימו לב: אי אפשר להשתמש באופרנד גם כקלט וגם כפלט של אותה פעולה.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);כדי לזהות אילו אופרנדים המודל צריך להתייחס אליהם כאל מקורות קלט ותוצאות פלט, צריך לקרוא לפונקציה
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
אפשר גם לציין אם מותר לחשב את
ANEURALNETWORKS_TENSOR_FLOAT32עם טווח או דיוק נמוכים כמו אלה של פורמט הנקודה הצפה של IEEE 754 16-bit על ידי קריאה ל-ANeuralNetworksModel_relaxComputationFloat32toFloat16().מתקשרים אל
ANeuralNetworksModel_finish()כדי לסיים את הגדרת המודל. אם אין שגיאות, הפונקציה הזו מחזירה קוד תוצאה שלANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
אחרי שיוצרים מודל, אפשר לקמפל אותו כמה פעמים שרוצים ולהריץ כל קומפילציה כמה פעמים שרוצים.
בקרת זרימה
כדי לשלב זרימת בקרה במודל NNAPI, מבצעים את הפעולות הבאות:
בונים את תתי-הגרפים המתאימים של הרצה (תתי-גרפים
thenו-elseעבור הצהרתIF, תתי-גרפיםconditionו-bodyעבור לולאתWHILE) כמודלים עצמאיים שלANeuralNetworksModel*:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
יוצרים אופרנדים שמפנים למודלים האלה בתוך המודל שמכיל את זרימת הבקרה:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
מוסיפים את פעולת זרימת הבקרה:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
קומפילציה
בשלב הקומפילציה נקבע באילו מעבדים המודל יופעל, והמערכת מבקשת מהדרייברים המתאימים להתכונן להפעלה שלו. זה יכול לכלול יצירה של קוד מכונה שספציפי למעבדים שהמודל יפעל עליהם.
כדי לקמפל מודל:
קוראים לפונקציה
ANeuralNetworksCompilation_create()כדי ליצור מופע חדש של קומפילציה.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
אפשר גם להשתמש בהקצאת מכשירים כדי לבחור במפורש באילו מכשירים לבצע את הפעולה.
אופציונלית, אתם יכולים להשפיע על האופן שבו זמן הריצה מתחלק בין השימוש בסוללה לבין מהירות הביצוע. אפשר לעשות זאת באמצעות קריאה ל-
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
ההעדפות שאפשר לציין כוללות:
-
ANEURALNETWORKS_PREFER_LOW_POWER: עדיף לבצע את הפעולה באופן שממזער את התרוקנות הסוללה. זה רצוי עבור קומפילציות שמופעלות לעיתים קרובות. ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: עדיף להחזיר תשובה אחת כמה שיותר מהר, גם אם זה גורם לצריכת חשמל גבוהה יותר. זוהי ברירת המחדל.-
ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: עדיפות למקסימום תפוקה של פריימים עוקבים, למשל כשמעבדים פריימים עוקבים שמגיעים מהמצלמה.
-
אפשר גם להגדיר שמירה במטמון של קומפילציה על ידי קריאה ל-
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
משתמשים ב-
getCodeCacheDir()עבורcacheDir. הערך שלtokenחייב להיות ייחודי לכל מודל באפליקציה.כדי להשלים את הגדרת ההידור, קוראים ל-
ANeuralNetworksCompilation_finish(). אם אין שגיאות, הפונקציה הזו מחזירה קוד תוצאה שלANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
גילוי מכשירים והקצאתם
במכשירי Android שמותקנת בהם גרסת Android 10 (API ברמה 29) ומעלה, NNAPI מספק פונקציות שמאפשרות לספריות ולאפליקציות של מסגרות למידת מכונה לקבל מידע על המכשירים הזמינים ולציין מכשירים לשימוש בהרצה. המידע על המכשירים הזמינים מאפשר לאפליקציות לקבל את הגרסה המדויקת של מנהלי ההתקנים שנמצאים במכשיר, כדי למנוע בעיות תאימות ידועות. אם נותנים לאפליקציות את האפשרות לציין אילו מכשירים יפעילו חלקים שונים במודל, אפשר לבצע אופטימיזציה של האפליקציות למכשיר Android שבו הן נפרסות.
גילוי מכשירים
כדי לראות כמה מכשירים זמינים, משתמשים בפקודה
ANeuralNetworks_getDeviceCount
לכל מכשיר, משתמשים ב-ANeuralNetworks_getDevice כדי להגדיר מופע של ANeuralNetworksDevice כהפניה למכשיר הזה.
אחרי שמקבלים הפניה למכשיר, אפשר לקבל מידע נוסף על המכשיר באמצעות הפונקציות הבאות:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
הקצאת מכשירים
אפשר להשתמש ב-ANeuralNetworksModel_getSupportedOperationsForDevices כדי לגלות אילו פעולות של מודל אפשר להריץ במכשירים ספציפיים.
כדי לשלוט באילו מאיצים להשתמש להרצה, קוראים ל-ANeuralNetworksCompilation_createForDevices במקום ל-ANeuralNetworksCompilation_create.
משתמשים באובייקט ANeuralNetworksCompilation שמתקבל כרגיל.
הפונקציה מחזירה שגיאה אם המודל שצוין מכיל פעולות שלא נתמכות במכשירים שנבחרו.
אם מציינים כמה מכשירים, סביבת זמן הריצה אחראית לחלוקת העבודה בין המכשירים.
בדומה למכשירים אחרים, הטמעת ה-CPU של NNAPI מיוצגת על ידי ANeuralNetworksDevice עם השם nnapi-reference והסוג ANEURALNETWORKS_DEVICE_TYPE_CPU. כשמבצעים קריאה ל-ANeuralNetworksCompilation_createForDevices, ההטמעה של ה-CPU לא משמשת לטיפול במקרים של כשלים בהידור ובביצוע של המודל.
באחריות האפליקציה לחלק מודל למודלים משניים שיכולים לפעול במכשירים שצוינו. אפליקציות שלא צריכות לבצע חלוקה ידנית למחיצות צריכות להמשיך לקרוא לפונקציה הפשוטה יותר ANeuralNetworksCompilation_create כדי להשתמש בכל המכשירים הזמינים (כולל המעבד) להאצת המודל. אם המודל לא נתמך באופן מלא במכשירים שצוינו באמצעות ANeuralNetworksCompilation_createForDevices, מוחזר הערך ANEURALNETWORKS_BAD_DATA.
חלוקת המודל למחיצות
אם יש כמה מכשירים שזמינים לדגם, זמן הריצה של NNAPI מחלק את העבודה בין המכשירים. לדוגמה, אם סופקו יותר ממכשיר אחד ל-ANeuralNetworksCompilation_createForDevices, כל המכשירים שצוינו ייחשבו כשמקצים את העבודה. שימו לב שאם מכשיר ה-CPU לא נמצא ברשימה, הביצוע של ה-CPU יושבת. כשמשתמשים ב-ANeuralNetworksCompilation_create
כל המכשירים הזמינים נלקחים בחשבון, כולל המעבד.
ההפצה מתבצעת על ידי בחירה מתוך רשימת המכשירים הזמינים, לכל אחת מהפעולות במודל, המכשיר שתומך בפעולה והצהרה על הביצועים הטובים ביותר, כלומר זמן הביצוע המהיר ביותר או צריכת החשמל הנמוכה ביותר, בהתאם להעדפת הביצוע שצוינה על ידי הלקוח. אלגוריתם החלוקה הזה לא לוקח בחשבון חוסר יעילות אפשרי שנגרם בגלל קלט/פלט בין המעבדים השונים. לכן, כשמציינים כמה מעבדים (באופן מפורש כשמשתמשים ב-ANeuralNetworksCompilation_createForDevices או באופן מרומז כשמשתמשים ב-ANeuralNetworksCompilation_create), חשוב ליצור פרופיל של האפליקציה שמתקבלת.
כדי להבין איך המודל שלכם חולק על ידי NNAPI, בודקים את היומנים של Android אם יש הודעה (ברמת INFO עם התג ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name הוא השם התיאורי של הפעולה בתרשים, ו-device-index הוא האינדקס של המכשיר המועמד ברשימת המכשירים.
הרשימה הזו היא הקלט שמועבר אל ANeuralNetworksCompilation_createForDevices, או, אם משתמשים ב-ANeuralNetworksCompilation_createForDevices, רשימת המכשירים שמוחזרת כשמבצעים איטרציה על כל המכשירים באמצעות ANeuralNetworks_getDeviceCount ו-ANeuralNetworks_getDevice.
ההודעה (ברמת INFO עם התג ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
ההודעה הזו מציינת שכל הגרף עבר האצה במכשיר device-name.
ביצוע
בשלב הביצוע, המודל מוחל על קבוצה של נתוני קלט, ותוצאות החישוב מאוחסנות במאגר אחד או יותר של משתמשים או באזורי זיכרון שהוקצו לאפליקציה.
כדי להפעיל מודל שעבר קומפילציה:
קוראים לפונקציה
ANeuralNetworksExecution_create()כדי ליצור מופע חדש של הפעלה.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
מציינים איפה האפליקציה קוראת את ערכי הקלט לחישוב. האפליקציה יכולה לקרוא ערכי קלט ממאגר משתמשים או ממרחב זיכרון שהוקצה על ידי קריאה של
ANeuralNetworksExecution_setInput()או שלANeuralNetworksExecution_setInputFromMemory(), בהתאמה.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
מציינים איפה האפליקציה כותבת את ערכי הפלט. האפליקציה יכולה לכתוב ערכי פלט למאגר זמני של המשתמש או למרחב זיכרון שהוקצה, באמצעות קריאה ל-
ANeuralNetworksExecution_setOutput()או ל-ANeuralNetworksExecution_setOutputFromMemory()בהתאמה.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
מתזמנים את ההפעלה כדי שתתחיל על ידי קריאה לפונקציה
ANeuralNetworksExecution_startCompute(). אם אין שגיאות, הפונקציה הזו מחזירה קוד תוצאה שלANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
קוראים לפונקציה
ANeuralNetworksEvent_wait()כדי להמתין לסיום ההרצה. אם ההפעלה בוצעה ללא שגיאות, הפונקציה הזו מחזירה קוד תוצאה שלANEURALNETWORKS_NO_ERROR. ההמתנה יכולה להתבצע ב-thread אחר מזה שמתחיל את ההרצה.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
אפשר גם להחיל קבוצה אחרת של נתוני קלט על המודל המהודר באמצעות אותו מופע של קומפילציה כדי ליצור מופע חדש של
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
ביצוע סינכרוני
בביצוע אסינכרוני, המערכת משקיעה זמן בהפעלת שרשורים ובסנכרון שלהם. בנוסף, זמן האחזור יכול להשתנות מאוד, והעיכובים הארוכים ביותר יכולים להגיע ל-500 מיקרו-שניות בין הזמן שבו ה-thread מקבל הודעה או מתעורר לבין הזמן שבו הוא נקשר בסופו של דבר לליבת CPU.
כדי לשפר את זמן האחזור, אפשר להנחות אפליקציה לבצע קריאת הסקה סינכרונית לסביבת זמן הריצה. הקריאה הזו תחזיר ערך רק אחרי שההסקה תושלם, ולא אחרי שהיא תתחיל. במקום להתקשר אל ANeuralNetworksExecution_startCompute כדי לבצע קריאת הסקה אסינכרונית לזמן הריצה, האפליקציה מתקשרת אל ANeuralNetworksExecution_compute כדי לבצע קריאה סינכרונית לזמן הריצה. שיחה אל ANeuralNetworksExecution_compute לא תופסת ANeuralNetworksEvent ולא משויכת לשיחה אל ANeuralNetworksEvent_wait.
הרצות של קוד בכמות גדולה
במכשירי Android עם Android 10 (רמת API 29) ומעלה, ה-NNAPI תומך בהפעלות של פרצי נתונים באמצעות האובייקט ANeuralNetworksBurst. ביצועים מהירים הם רצף של ביצועים של אותה קומפילציה שמתרחשים ברצף מהיר, כמו ביצועים שפועלים על פריימים של צילום ממצלמה או על דגימות אודיו עוקבות. שימוש באובייקטים מסוג ANeuralNetworksBurst עשוי להוביל לביצועים מהירים יותר, כי הם מציינים למאיצים שאפשר לעשות שימוש חוזר במשאבים בין ביצועים, ושהמאיצים צריכים להישאר במצב של ביצועים גבוהים למשך פרק הזמן של השימוש.
ANeuralNetworksBurst מציג רק שינוי קטן בנתיב הביצוע הרגיל. יוצרים אובייקט burst באמצעות ANeuralNetworksBurst_create, כמו בקטע הקוד הבא:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
הפעלות של פרץ הן סינכרוניות. אבל במקום להשתמש ב-ANeuralNetworksExecution_compute כדי לבצע כל הסקה, משייכים את האובייקטים השונים של ANeuralNetworksExecution לאותו ANeuralNetworksBurst בקריאות לפונקציה ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
כשאין יותר צורך באובייקט ANeuralNetworksBurst, משחררים אותו באמצעות הפקודה
ANeuralNetworksBurst_free.
// Cleanup ANeuralNetworksBurst_free(burst);
תורי פקודות אסינכרוניים וביצוע מוגבל
ב-Android מגרסה 11 ואילך, NNAPI תומך בדרך נוספת לתזמון ביצוע אסינכרוני באמצעות ה-method ANeuralNetworksExecution_startComputeWithDependencies(). כשמשתמשים בשיטה הזו, ההפעלה ממתינה עד שכל האירועים התלויים מסומנים לפני שההערכה מתחילה. אחרי שהביצוע מסתיים והפלט מוכן לשימוש, האירוע שמוחזר מסומן.
בהתאם למכשירים שמטפלים בהרצה, יכול להיות שהאירוע יגובה על ידי גדר סנכרון. צריך להתקשר אל
ANeuralNetworksEvent_wait()
כדי להמתין לאירוע ולשחזר את המשאבים שבהם נעשה שימוש במהלך ההפעלה. אפשר לייבא גדרות סנכרון לאובייקט אירוע באמצעות ANeuralNetworksEvent_createFromSyncFenceFd(), ואפשר לייצא גדרות סנכרון מאובייקט אירוע באמצעות ANeuralNetworksEvent_getSyncFenceFd().
פלטים בגודל דינמי
כדי לתמוך במודלים שבהם גודל הפלט תלוי בנתוני הקלט – כלומר, במקרים שבהם אי אפשר לקבוע את הגודל בזמן ההפעלה של המודל – צריך להשתמש ב-ANeuralNetworksExecution_getOutputOperandRank וב-ANeuralNetworksExecution_getOutputOperandDimensions.
בדוגמת הקוד הבאה אפשר לראות איך עושים את זה:
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
הסרת המשאבים
בשלב הניקוי, המשאבים הפנימיים שמשמשים לחישובים מתפנים.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
ניהול שגיאות ומעבר חזרה למעבד
אם יש שגיאה במהלך החלוקה למחיצות, אם קומפילציה של מודל (או חלק ממנו) נכשלת, או אם הפעלה של מודל (או חלק ממנו) שעבר קומפילציה נכשלת, יכול להיות ש-NNAPI יחזור להטמעה שלו במעבד של פעולה אחת או יותר.
אם לקוח NNAPI מכיל גרסאות אופטימליות של הפעולה (כמו TFLite), יכול להיות שכדאי להשבית את הגיבוי למעבד ולטפל בכשלים באמצעות הטמעה אופטימלית של הפעולה בלקוח.
ב-Android 10, אם הקומפילציה מתבצעת באמצעות ANeuralNetworksCompilation_createForDevices, הגיבוי של ה-CPU יושבת.
ב-Android P, אם הביצוע בדרייבר נכשל, הביצוע של NNAPI חוזר ל-CPU.
זה נכון גם ב-Android 10 כשמשתמשים ב-ANeuralNetworksCompilation_create במקום ב-ANeuralNetworksCompilation_createForDevices.
הביצוע הראשון נכשל עבור המחיצה הזו, ואם הוא עדיין נכשל, המערכת מנסה שוב להריץ את המודל כולו במעבד.
אם החלוקה או הקומפילציה נכשלות, המערכת תנסה להריץ את המודל כולו ב-CPU.
יש מקרים שבהם פעולות מסוימות לא נתמכות ב-CPU, ובמקרים כאלה הקומפילציה או ההפעלה ייכשלו במקום לחזור אחורה.
גם אחרי השבתת הגיבוי למעבד, יכול להיות שעדיין יהיו פעולות במודל שמתוזמנות במעבד. אם המעבד מופיע ברשימת המעבדים שסופקו ל-ANeuralNetworksCompilation_createForDevices, והוא המעבד היחיד שתומך בפעולות האלה או שהוא המעבד שמציע את הביצועים הכי טובים לפעולות האלה, הוא ייבחר כמעבד ראשי (לא כמעבד חלופי).
כדי לוודא שלא מתבצעת הרצה של CPU, משתמשים ב-ANeuralNetworksCompilation_createForDevices
תוך החרגת nnapi-reference מרשימת המכשירים.
החל מ-Android P, אפשר להשבית את החזרה לגרסה קודמת בזמן ההפעלה בגרסאות DEBUG על ידי הגדרת המאפיין debug.nn.partition לערך 2.
דומיינים של זיכרונות
ב-Android מגרסה 11 ואילך, NNAPI תומך בתחומי זיכרון שמספקים ממשקי הקצאה לזיכרונות אטומים. כך אפליקציות יכולות להעביר זיכרונות מקוריים של המכשיר בין ביצועים, כדי ש-NNAPI לא יעתיק או ישנה נתונים שלא לצורך כשמבצעים ביצועים עוקבים באותו מנהל התקן.
התכונה 'דומיין זיכרון' מיועדת לטנסורים שהם בעיקר פנימיים למנהל ההתקן, ושלא נדרשת גישה תכופה לצד הלקוח. דוגמאות לטנסורים כאלה כוללות את טנסורי המצב במודלים של רצפים. עבור טנסורים שזקוקים לגישה תכופה למעבד בצד הלקוח, כדאי להשתמש במאגרי זיכרון משותפים.
כדי להקצות זיכרון אטום, מבצעים את השלבים הבאים:
מפעילים את הפונקציה
ANeuralNetworksMemoryDesc_create()כדי ליצור מתאר זיכרון חדש:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
מציינים את כל תפקידי הקלט והפלט המיועדים על ידי קריאה ל-
ANeuralNetworksMemoryDesc_addInputRole()ול-ANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
אפשר לציין את מאפייני הזיכרון על ידי קריאה ל-
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
כדי להשלים את הגדרת התיאור, מתקשרים אל
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
כדי להקצות כמה זיכרונות שצריך, מעבירים את המתאר אל
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
משחררים את מתאר הזיכרון כשכבר לא צריך אותו.
ANeuralNetworksMemoryDesc_free(desc);
הלקוח יכול להשתמש באובייקט ANeuralNetworksMemory שנוצר רק עם ANeuralNetworksExecution_setInputFromMemory() או ANeuralNetworksExecution_setOutputFromMemory() בהתאם לתפקידים שצוינו באובייקט ANeuralNetworksMemoryDesc. הארגומנטים offset ו-length צריכים להיות מוגדרים כ-0, כדי לציין שנעשה שימוש בכל הזיכרון. הלקוח יכול גם להגדיר באופן מפורש את תוכן הזיכרון או לחלץ אותו באמצעות ANeuralNetworksMemory_copy().
אפשר ליצור זיכרונות אטומים עם תפקידים של מאפיינים או דרגות לא מוגדרים.
במקרה כזה, יכול להיות שיצירת הזיכרון תיכשל עם הסטטוס ANEURALNETWORKS_OP_FAILED אם היא לא נתמכת על ידי מנהל ההתקן הבסיסי. מומלץ ללקוח להטמיע לוגיקה של חזרה למצב קודם על ידי הקצאת מאגר גדול מספיק שמגובה על ידי Ashmem או AHardwareBuffer במצב BLOB.
כש-NNAPI כבר לא צריך לגשת לאובייקט הזיכרון האטום, צריך לשחרר את מופע ANeuralNetworksMemory המתאים:
ANeuralNetworksMemory_free(opaqueMem);
מדידת ביצועים
כדי להעריך את הביצועים של האפליקציה, אפשר למדוד את זמן הביצוע או ליצור פרופיל.
זמן הביצוע
כדי לקבוע את זמן הביצוע הכולל דרך זמן הריצה, אפשר להשתמש ב-API של ביצוע סינכרוני ולמדוד את הזמן שלוקח לקריאה. אם רוצים לקבוע את זמן הביצוע הכולל דרך רמה נמוכה יותר של מחסנית התוכנה, אפשר להשתמש ב-ANeuralNetworksExecution_setMeasureTiming וב-ANeuralNetworksExecution_getDuration כדי לקבל:
- זמן הביצוע במאיץ (לא במנהל ההתקן, שפועל במעבד המארח).
- זמן הביצוע בדרייבר, כולל הזמן שבו הדוושה לוחצת.
זמן ההרצה בדרייבר לא כולל תקורה כמו זו של זמן הריצה עצמו וה-IPC שנדרש כדי שזמן הריצה יתקשר עם הדרייבר.
ממשקי ה-API האלה מודדים את משך הזמן בין אירועי שליחת העבודה והשלמת העבודה, ולא את הזמן שמוקדש לביצוע ההסקה על ידי הדרייבר או המאיץ, שאולי מופרע על ידי החלפת הקשר.
לדוגמה, אם הסקת מסקנות 1 מתחילה, ואז הנהג מפסיק לעבוד כדי לבצע הסקת מסקנות 2, ואז הוא ממשיך ומסיים את הסקת מסקנות 1, זמן הביצוע של הסקת מסקנות 1 יכלול את הזמן שבו העבודה הופסקה כדי לבצע הסקת מסקנות 2.
המידע הזה על התזמון יכול להיות שימושי לפריסה של אפליקציה בסביבת ייצור כדי לאסוף טלמטריה לשימוש אופליין. אפשר להשתמש בנתוני התזמון כדי לשנות את האפליקציה ולשפר את הביצועים שלה.
כשמשתמשים בפונקציונליות הזו, חשוב לזכור את הנקודות הבאות:
- איסוף נתוני תזמון עלול לפגוע בביצועים.
- רק מנהל התקן יכול לחשב את הזמן שחלף בתוכו או במאיץ, לא כולל הזמן שחלף בזמן הריצה של NNAPI וב-IPC.
- אפשר להשתמש בממשקי ה-API האלה רק עם
ANeuralNetworksExecutionשנוצר באמצעותANeuralNetworksCompilation_createForDevicesעםnumDevices = 1. - לא נדרש נהג כדי לדווח על נתוני תזמון.
יצירת פרופיל של האפליקציה באמצעות Android Systrace
החל מ-Android 10, NNAPI יוצר באופן אוטומטי אירועי systrace שאפשר להשתמש בהם כדי ליצור פרופיל של האפליקציה.
הכלי NNAPI Source כולל כלי עזר parse_systrace לעיבוד אירועי systrace שנוצרו על ידי האפליקציה שלכם, וליצירת תצוגת טבלה שבה מוצג הזמן שהוקדש לשלבים השונים במחזור החיים של המודל (יצירת מופע, הכנה, ביצוע קומפילציה וסיום) ולשכבות השונות של האפליקציות. השכבות שאליהן האפליקציה מחולקת הן:
-
Application: קוד האפליקציה הראשי -
Runtime: זמן ריצה של NNAPI -
IPC: תקשורת בין תהליכים בין NNAPI Runtime לבין קוד ה-Driver -
Driver: תהליך מנהל ההתקן של המאיץ.
יצירת נתוני ניתוח פרופילים
נניח שבדקתם את עץ המקור של AOSP ב-$ANDROID_BUILD_TOP, ושאתם משתמשים בדוגמה לסיווג תמונות ב-TFLite כאפליקציית היעד. כדי ליצור את נתוני הפרופיל של NNAPI, פועלים לפי השלבים הבאים:
- מריצים את הפקודה הבאה כדי להתחיל את Android systrace:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
הפרמטר -o trace.html מציין שהנתונים של העקבות ייכתבו ב-trace.html. כשמבצעים פרופיל לאפליקציה, צריך להחליף את org.tensorflow.lite.examples.classification בשם התהליך שצוין בקובץ מניפסט של האפליקציה.
אחת ממסופי ה-Shell תהיה עסוקה, לכן אל תריצו את הפקודה ברקע כי היא ממתינה באופן אינטראקטיבי ל-enter כדי להסתיים.
- אחרי שמפעילים את הכלי לאיסוף נתונים של systrace, מפעילים את האפליקציה ומריצים את בדיקת הביצועים.
במקרה שלנו, אפשר להפעיל את האפליקציה Image Classification מ-Android Studio או ישירות מממשק המשתמש של טלפון הבדיקה, אם האפליקציה כבר הותקנה. כדי ליצור נתונים מסוימים של NNAPI, צריך להגדיר את האפליקציה לשימוש ב-NNAPI על ידי בחירה ב-NNAPI כמכשיר היעד בתיבת הדו-שיח של הגדרת האפליקציה.
כשהבדיקה מסתיימת, מפסיקים את ה-systrace על ידי הקשה על
enterבטרמינל של המסוף שהופעל בשלב 1.מריצים את כלי השירות
systrace_parserכדי ליצור נתונים סטטיסטיים מצטברים:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
הכלי לניתוח מקבל את הפרמטרים הבאים:
- --total-times: מציג את הזמן הכולל שחלף בשכבה, כולל הזמן שחלף בהמתנה להפעלה בקריאה לשכבה בסיסית
- --print-detail: מדפיס את כל האירועים שנאספו מ-systrace
- --per-execution: מדפיס רק את ההפעלה ואת שלבי המשנה שלה (כמו זמנים לכל הפעלה) במקום נתונים סטטיסטיים לכל השלבים
- --json: יוצר את הפלט בפורמט JSON
דוגמה לפלט מוצגת בהמשך:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
יכול להיות שהניתוח ייכשל אם האירועים שנאספו לא מייצגים מעקב מלא של האפליקציה. בפרט, יכול להיות שהפעולה תיכשל אם אירועי systrace שנוצרו כדי לסמן את סוף הקטע מופיעים בנתוני המעקב ללא אירוע התחלה של קטע משויך. זה קורה בדרך כלל אם חלק מהאירועים מסשן קודם של יצירת פרופיל נוצרים כשמתחילים את כלי האיסוף של systrace. במקרה כזה, תצטרכו להריץ שוב את יצירת הפרופיל.
הוספת נתונים סטטיסטיים לקוד האפליקציה לפלט של systrace_parser
האפליקציה parse_systrace מבוססת על הפונקציונליות המובנית של Android systrace. אפשר להוסיף עקבות לפעולות ספציפיות באפליקציה באמצעות systrace API (ל-Java, לאפליקציות מקוריות) עם שמות אירועים מותאמים אישית.
כדי לשייך את האירועים המותאמים אישית לשלבים במחזור החיים של האפליקציה, צריך להוסיף בתחילת שם האירוע את אחד המחרוזות הבאות:
-
[NN_LA_PI]: אירוע ברמת האפליקציה לאתחול -
[NN_LA_PP]: אירוע ברמת האפליקציה להכנה [NN_LA_PC]: אירוע ברמת האפליקציה של אוסף-
[NN_LA_PE]: אירוע ברמת האפליקציה להפעלה
הנה דוגמה לאופן שבו אפשר לשנות את קוד הדוגמה של סיווג תמונות ב-TFLite על ידי הוספת קטע runInferenceModel לשלב Execution ולשכבה Application שמכילה קטעים אחרים preprocessBitmap שלא ייכללו במעקב אחר NNAPI. הקטע runInferenceModel יהיה חלק מהאירועים של systrace שעובדו על ידי כלי הניתוח של nnapi systrace:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
איכות השירות
ב-Android 11 ואילך, NNAPI מאפשר איכות שירות (QoS) טובה יותר. הוא מאפשר לאפליקציה לציין את העדיפויות היחסיות של המודלים שלה, את משך הזמן המקסימלי שנדרש להכנת מודל נתון ואת משך הזמן המקסימלי שנדרש להשלמת חישוב נתון. ב-Android 11 נוספו קודי תוצאה נוספים של NNAPI, שמאפשרים לאפליקציות להבין כשלים כמו החמצה של מועדי ביצוע.
הגדרת העדיפות של עומס עבודה
כדי להגדיר את העדיפות של עומס עבודה ב-NNAPI, קוראים ל-ANeuralNetworksCompilation_setPriority() לפני שקוראים ל-ANeuralNetworksCompilation_finish().
הגדרת דדליינים
אפליקציות יכולות להגדיר מועדים גם להידור של המודל וגם להסקת מסקנות.
- כדי להגדיר את הזמן הקצוב לתהליך הקומפילציה, צריך להתקשר אל
ANeuralNetworksCompilation_setTimeout()לפני שמתקשרים אלANeuralNetworksCompilation_finish(). - כדי להגדיר את הזמן הקצוב להיקש, צריך להתקשר אל
ANeuralNetworksExecution_setTimeout()לפני התחלת ההידור.
מידע נוסף על אופרנדים
בקטע הבא מפורטים נושאים מתקדמים לגבי שימוש באופרנדים.
טנסורים שעברו קוונטיזציה
טנסור שעבר קוונטיזציה הוא דרך קומפקטית לייצג מערך n-ממדי של ערכים מסוג נקודה צפה.
NNAPI תומך בטנסורים אסימטריים עם כימות של 8 ביט. בטנסורים האלה, הערך של כל תא מיוצג על ידי מספר שלם בן 8 ביט. למטריצה משויכים ערך קנה מידה וערך נקודת אפס. הערכים האלה משמשים להמרה של מספרים שלמים בני 8 ביט לערכים של נקודה צפה שמיוצגים.
הנוסחה היא:
(cellValue - zeroPoint) * scale
כאשר הערך של zeroPoint הוא מספר שלם של 32 ביט, והערך של scale הוא מספר צף של 32 ביט.
בהשוואה לטנסורים של ערכי נקודה צפה (floating-point) של 32 ביט, לטנסורים של 8 ביט שעברו קוונטיזציה יש שני יתרונות:
- האפליקציה קטנה יותר, כי המשקלים המאומנים תופסים רבע מהגודל של טנסורים של 32 ביט.
- לרוב אפשר לבצע את החישובים מהר יותר. הסיבה לכך היא כמות הנתונים הקטנה יותר שצריך לאחזר מהזיכרון והיעילות של מעבדים כמו DSP בביצוע מתמטיקה של מספרים שלמים.
אפשר להמיר מודל של נקודה צפה למודל עם כימות, אבל מניסיוננו עולה שתוצאות טובות יותר מתקבלות כשמאמנים מודל עם כימות ישירות. למעשה, רשת הנוירונים לומדת לפצות על הגרנולריות המוגברת של כל ערך. עבור כל טנזור שעבר קוונטיזציה, הערכים של scale ו-zeroPoint נקבעים במהלך תהליך האימון.
ב-NNAPI, מגדירים סוגים של טנסורים שעברו קוונטיזציה על ידי הגדרת שדה הסוג של מבנה הנתונים ANeuralNetworksOperandType לערך ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
במבנה הנתונים הזה מציינים גם את הערך scale ואת הערך zeroPoint של הטנסור.
בנוסף לטנסורים אסימטריים עם כימות של 8 ביט, NNAPI תומך גם בטנסורים הבאים:
-
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNELשאפשר להשתמש בו לייצוג משקלים בפעולותCONV/DEPTHWISE_CONV/TRANSPOSED_CONV. -
ANEURALNETWORKS_TENSOR_QUANT16_ASYMMשאפשר להשתמש בו למצב הפנימי של QUANTIZED_16BIT_LSTM. -
ANEURALNETWORKS_TENSOR_QUANT8_SYMMיכול להיות קלט ל-ANEURALNETWORKS_DEQUANTIZE.
אופרנדים אופציונליים
יש כמה פעולות, כמו
ANEURALNETWORKS_LSH_PROJECTION,
שמקבלות אופרנדים אופציונליים. כדי לציין במודל שהאופרנד האופציונלי הושמט, קוראים לפונקציה ANeuralNetworksModel_setOperandValue(), ומעבירים את NULL למאגר ואת 0 לאורך.
אם ההחלטה אם האופרנד קיים או לא משתנה בכל הפעלה, מציינים שהאופרנד הושמט באמצעות הפונקציות ANeuralNetworksExecution_setInput() או ANeuralNetworksExecution_setOutput(), ומעבירים את הערך NULL למאגר ואת הערך 0 לאורך.
טנסורים בדרגה לא ידועה
ב-Android 9 (רמת API 28) הוצגו אופרנדים של מודלים עם מימדים לא ידועים אבל עם דרגה ידועה (מספר המימדים). ב-Android 10 (רמת API 29) נוספו טנסורים בדרגה לא ידועה, כמו שמוצג ב-ANeuralNetworksOperandType.
בנצ'מרק של NNAPI
המדד NNAPI זמין ב-AOSP ב-platform/test/mlts/benchmark
(אפליקציית מדד) וב-platform/test/mlts/models (מודלים ומערכי נתונים).
ההשוואה בודקת את זמן האחזור והדיוק, ומשווה בין מנהלי התקנים לאותה עבודה שבוצעה באמצעות TensorFlow Lite שפועל על המעבד (CPU), עבור אותם מודלים ומערכי נתונים.
כדי להשתמש בהשוואה לשוק:
מחברים למחשב מכשיר Android שרוצים לטרגט, פותחים חלון טרמינל ומוודאים שאפשר להגיע למכשיר דרך ADB.
אם מחוברים יותר ממכשיר Android אחד, צריך לייצא את משתנה הסביבה
ANDROID_SERIALשל מכשיר היעד.עוברים לספריית קובצי המקור ברמה העליונה של Android.
מריצים את הפקודות הבאות:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
בסיום הרצת בדיקת ביצועים, התוצאות יוצגו כדף HTML שמועבר אל
xdg-open.
יומנים של NNAPI
NNAPI יוצר מידע שימושי לניתוח ביצועים ביומני המערכת. כדי לנתח את היומנים, משתמשים בכלי logcat.
כדי להפעיל רישום מפורט ביומן של NNAPI עבור שלבים או רכיבים ספציפיים, צריך להגדיר את המאפיין debug.nn.vlog (באמצעות adb shell) לרשימת הערכים הבאה, כשהם מופרדים באמצעות רווח, נקודתיים או פסיק:
-
model: בניית מודלים -
compilation: יצירה של תוכנית ההפעלה והקומפילציה של המודל -
execution: הפעלת המודל cpuexe: הרצת פעולות באמצעות הטמעת NNAPI במעבד-
manager: תוספים של NNAPI, ממשקים זמינים ומידע שקשור ליכולות -
allאו1: כל הרכיבים שלמעלה
לדוגמה, כדי להפעיל רישום מפורט מלא ביומן, משתמשים בפקודה adb shell setprop debug.nn.vlog all. כדי להשבית את הרישום המפורט ביומן, משתמשים בפקודה adb shell setprop debug.nn.vlog '""'.
אחרי שמפעילים את האפשרות הזו, נוצרות רשומות ביומן ברמת INFO עם תג שמוגדר לשם השלב או הרכיב.
בנוסף לdebug.nn.vlog הודעות מבוקרות, רכיבי NNAPI API מספקים רשומות אחרות ביומן ברמות שונות, וכל אחת מהן משתמשת בתג יומן ספציפי.
כדי לקבל רשימה של רכיבים, מחפשים בעץ המקור באמצעות הביטוי הבא:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
הביטוי הזה מחזיר כרגע את התגים הבאים:
- BurstBuilder
- התקשרות חזרה
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- מנהל
- זיכרון
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- תפעול
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
כדי לשלוט ברמת הודעות היומן שמוצגות על ידי logcat, משתמשים במשתנה הסביבה ANDROID_LOG_TAGS.
כדי להציג את כל ההודעות ביומן של NNAPI ולהשבית את כל השאר, מגדירים את ANDROID_LOG_TAGS באופן הבא:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
אפשר להגדיר את ANDROID_LOG_TAGS באמצעות הפקודה הבאה:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
חשוב לזכור שמדובר רק במסנן שחל על logcat. עדיין צריך להגדיר את המאפיין debug.nn.vlog לערך all כדי ליצור מידע מפורט ביומן.