
A API Android Neural Networks (NNAPI) é uma API do Android C desenvolvida para executar operações com uso intenso de recursos computacionais para aprendizado de máquina em dispositivos Android. A NNAPI foi criada para oferecer uma camada básica de funcionalidade para frameworks de aprendizado de máquina de nível mais alto, como TensorFlow Lite e Caffe2, que criam e treinam redes neurais. A API está disponível em todos os dispositivos Android com o Android 8.1 (nível da API 27) ou versões mais recentes, mas foi descontinuada no Android 15.
A NNAPI oferece suporte a inferências ao aplicar dados de dispositivos Android a modelos definidos pelo desenvolvedor e treinados previamente. Exemplos de inferências incluem classificação de imagens, previsão de comportamento de usuário e seleção de respostas apropriadas para uma consulta de pesquisa.
Inferências em dispositivos têm muitos benefícios:
- Latência: não é preciso enviar uma solicitação por uma conexão de rede e aguardar uma resposta. Por exemplo, isso pode ser essencial para aplicativos de vídeo que processam frames sucessivos originados em uma câmera.
- Disponibilidade: o app é executado mesmo fora da cobertura de rede.
- Velocidade: o novo hardware específico para o processamento de redes neurais oferece uma computação significativamente mais rápida do que uma CPU de uso geral sozinha.
- Privacidade: os dados não saem do dispositivo Android.
- Custo: nenhum grupo de servidores é necessário quando todas as computações são realizadas no dispositivo Android.
Há também algumas desvantagens que o desenvolvedor precisa ter em mente:
- Utilização do sistema: a avaliação de redes neurais envolve muita computação, o que pode aumentar o consumo de bateria. Monitore a integridade da bateria se essa for uma preocupação para seu app, especialmente para computações com execução longa.
- Tamanho do aplicativo: preste atenção no tamanho dos seus modelos. Os modelos podem ocupar vários megabytes de espaço. Se o empacotamento de grandes modelos no APK afetar seus usuários de forma negativa, considere fazer o download dos modelos após a instalação do app, usar modelos menores ou executar as computações na nuvem. A NNAPI não oferece funcionalidade para a execução de modelos na nuvem.
Consulte o exemplo da API Android Neural Networks (em inglês) para saber como usar a NNAPI.
Entender o ambiente de execução da API Neural Networks
A NNAPI precisa ser chamada por bibliotecas de aprendizado de máquina, frameworks e ferramentas que permitam que os desenvolvedores treinem modelos fora do dispositivo e os implantem em dispositivos Android. Os apps não costumam usar a NNAPI diretamente, e sim frameworks de aprendizado de máquina de nível mais alto. Por sua vez, esses frameworks podem usar a NNAPI para realizar operações de inferência aceleradas por hardware em dispositivos compatíveis.
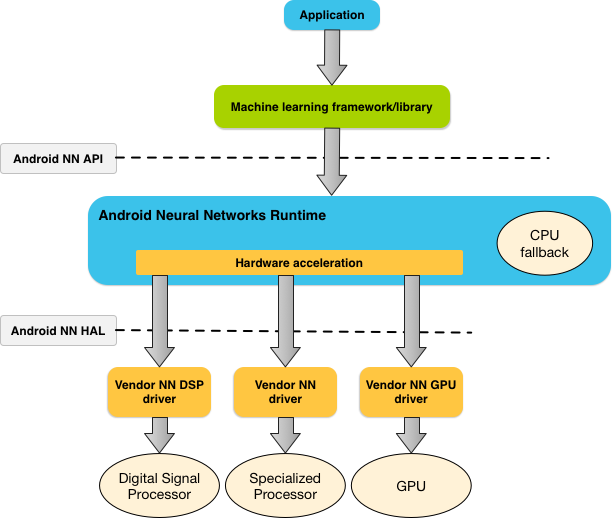
Com base nos requisitos do app e na capacidade de hardware de um dispositivo Android, o ambiente de execução das redes neurais do Android pode distribuir de forma eficiente a carga de trabalho de computação nos processadores disponíveis no dispositivo, incluindo hardware de rede neural dedicado, unidades de processamento gráfico (GPUs) e processadores de sinal digital (DSPs).
Para dispositivos Android sem um driver de fornecedor especializado, o ambiente de execução da NNAPI executa as solicitações na CPU.
A Figura 1 mostra a arquitetura do sistema de alto nível para a NNAPI.
Modelo de programação da API Neural Networks
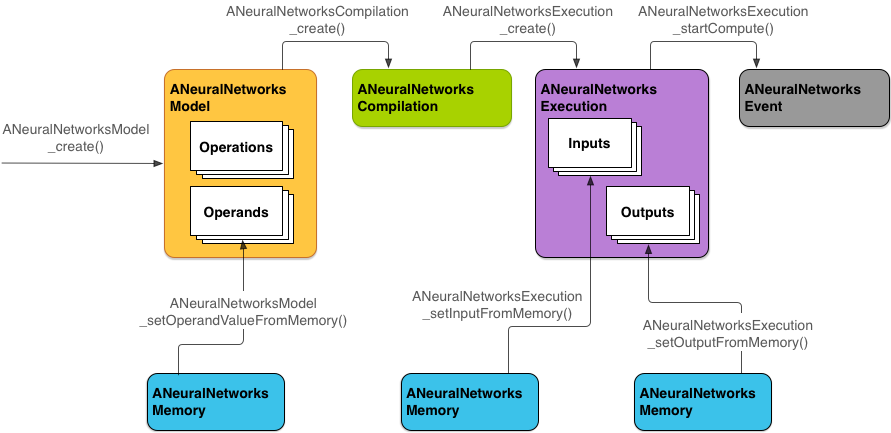
Para executar computações usando a NNAPI, primeiro construa um gráfico direcionado que defina as computações a serem executadas. Esse gráfico de computação, combinado aos seus dados de entrada (por exemplo, os pesos e vieses transmitidos do framework de aprendizado de máquina), forma o modelo para a avaliação do ambiente de execução da NNAPI.
A NNAPI usa quatro abstrações principais:
- Modelo: gráfico de computação de operações matemáticas e os valores constantes
aprendidos por um processo de treinamento. Essas operações são específicas para redes neurais. Elas incluem a
convolução
bidimensional (2D), a ativação logística
(sigmoide),
a ativação
linear retificada
(ReLU, na sigla em inglês) e muito mais (links em inglês). A criação de um modelo é uma operação síncrona.
Uma vez criado, ele pode ser reutilizado em linhas de execução e compilações.
Na NNAPI, um modelo é representado como uma
instância
ANeuralNetworksModel. - Compilação: representa uma configuração para compilar um modelo de NNAPI em um
código de nível mais baixo. A criação de uma compilação é uma operação síncrona. Uma vez criada, ela pode ser reutilizada em linhas de execução e compilações. Na
NNAPI, cada compilação é representada como uma
instância
ANeuralNetworksCompilation. - Memória: representa a memória compartilhada, os arquivos mapeados de memória e buffers de memória
semelhantes. O uso de um buffer de memória permite que o ambiente de execução da NNAPI transfira dados para os drivers
de forma mais eficiente. Um app geralmente cria um buffer de memória compartilhado, que contém todos os tensores necessários para definir um modelo. Também é possível usar buffers de memória para armazenar entradas e saídas para uma instância de execução. Na NNAPI, cada buffer de memória é representado como uma instância
ANeuralNetworksMemory. Execução: interface para aplicar um modelo de NNAPI a um conjunto de entradas e para coletar resultados. A execução pode ser realizada de forma síncrona ou assíncrona.
Para a execução assíncrona, várias linhas podem esperar na mesma execução. Quando a execução é concluída, todas as linhas são liberadas.
Na NNAPI, cada execução é representada como uma instância
ANeuralNetworksExecution.
A Figura 2 mostra o fluxo de programação básico.
O restante desta seção descreve as etapas para configurar seu modelo de NNAPI para realizar a computação, compilar o modelo e executar o modelo compilado.
Conceder acesso aos dados de treinamento
Seus dados de viés e pesos treinados provavelmente são armazenados em um arquivo. Para fornecer acesso a
esses dados ao ambiente de execução da NNAPI, crie uma instância
ANeuralNetworksMemory,
chamando a função
ANeuralNetworksMemory_createFromFd()
e transmitindo o descritor de arquivo do arquivo de dados aberto. Você também
pode especificar sinalizações de proteção de memória e um deslocamento em que a região da memória compartilhada
começa no arquivo.
// Create a memory buffer from the file that contains the trained data
ANeuralNetworksMemory* mem1 = NULL;
int fd = open("training_data", O_RDONLY);
ANeuralNetworksMemory_createFromFd(file_size, PROT_READ, fd, 0, &mem1);
Apesar de nesse exemplo usarmos apenas uma instância
ANeuralNetworksMemory
para todos os nossos pesos, é possível usar mais de uma instância
ANeuralNetworksMemory para diversos arquivos.
Usar buffers de hardware nativos
É possível usar buffers de hardware nativos
para modelar entradas, saídas e valores de operando constantes. Em alguns casos, um acelerador de NNAPI pode acessar objetos AHardwareBuffer sem que o driver precise copiar os dados. AHardwareBuffer tem muitas configurações diferentes, e nem todo acelerador de NNAPI será compatível com todas essas configurações. Devido a essa limitação, consulte as restrições
listadas na
documentação de referência de ANeuralNetworksMemory_createFromAHardwareBuffer
e faça testes com antecedência nos dispositivos de destino para garantir que as compilações e execuções
que usam AHardwareBuffer se comportem como esperado, usando a
atribuição de dispositivos para especificar o acelerador.
Para permitir que o ambiente de execução da NNAPI acesse um objeto AHardwareBuffer, crie uma instância
ANeuralNetworksMemory
chamando a função
ANeuralNetworksMemory_createFromAHardwareBuffer e transmitindo o objeto
AHardwareBuffer, conforme mostrado neste exemplo de código:
// Configure and create AHardwareBuffer object AHardwareBuffer_Desc desc = ... AHardwareBuffer* ahwb = nullptr; AHardwareBuffer_allocate(&desc, &ahwb); // Create ANeuralNetworksMemory from AHardwareBuffer ANeuralNetworksMemory* mem2 = NULL; ANeuralNetworksMemory_createFromAHardwareBuffer(ahwb, &mem2);
Quando a NNAPI não precisar mais acessar o objeto AHardwareBuffer, libere a instância ANeuralNetworksMemory correspondente:
ANeuralNetworksMemory_free(mem2);
Observação:
- É possível usar
AHardwareBuffersomente para o buffer inteiro. Não é possível usá-lo com um parâmetroARect. - O ambiente de execução da NNAPI não limpará o buffer. Verifique se os buffers de entrada e saída estão acessíveis antes de programar a execução.
- Não há compatibilidade para descritores de arquivo de limite de sincronização.
- Para um
AHardwareBuffercom bits de uso e formatos especificados pelo fornecedor, cabe à implementação do fornecedor determinar se o cliente ou o driver será responsável por limpar o cache.
Modelo
Um modelo é a unidade fundamental da computação na NNAPI. Cada modelo é definido por um ou mais operandos e operações.
Operandos
Operandos são objetos de dados usados para definir o gráfico. Eles incluem as entradas e saídas do modelo, os nós intermediários que contêm os dados que fluem de uma operação a outra e as constantes passadas para essas operações.
Há dois tipos de operandos que podem ser adicionados aos modelos da NNAPI: escalares e tensores.
Um escalar representa um valor único. A NNAPI oferece suporte a valores escalares em formatos booleanos, de ponto flutuante de 16 e de 32 bits, inteiros de 32 bits e inteiros de 32 bits não assinados.
A maioria das operações na NNAPI envolve tensores. Tensores são matrizes de dimensão n. A NNAPI é compatível com tensores com ponto flutuante de 16 e de 32 bits, quantizados de 8 e de 16 bits, inteiros de 32 bits e valores booleanos de 8 bits.
Por exemplo, a Figura 3 abaixo representa um modelo com duas operações: uma adição seguida de uma multiplicação. O modelo comporta um tensor de entrada e produz um tensor de saída.
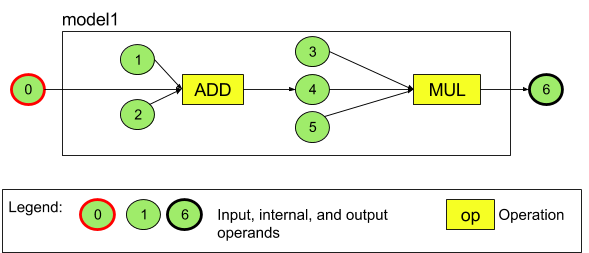
O modelo acima tem sete operandos. Esses operandos são identificados implicitamente pelo índice da ordem em que são adicionados ao modelo. O primeiro operando adicionado tem um índice de 0, o segundo de 1 e assim por diante. Os operandos 1, 2, 3 e 5 são constantes.
A ordem em que os operandos são adicionados não importa. Por exemplo, o operando de saída do modelo pode ser o primeiro a ser adicionado. O importante é usar o valor de índice correto ao referenciar um operando.
Operandos têm tipos. Eles são especificados quando são adicionados ao modelo.
Um operando não pode ser usado como entrada e saída de um modelo.
Todos os operandos precisam ser uma entrada de modelo, uma constante ou o operando de saída de exatamente uma operação.
Para ver mais informações sobre como usar operandos, consulte Mais informações sobre operandos.
Operações
Uma operação especifica as computações a serem realizadas. Cada operação consiste nos seguintes elementos:
- Um tipo de operação (por exemplo, adição, multiplicação, convolução)
- Uma lista de índices dos operandos que a operação usa para entrada
- Uma lista de índices dos operandos que a operação usa para saída
A ordem nessas listas é importante. Consulte a referência da NNAPI para saber quais são as entradas e saídas esperadas para cada tipo de operação.
Você precisa adicionar ao modelo os operandos que uma operação consome ou produz antes de adicionar a operação.
A ordem em que as operações são adicionadas não importa. A NNAPI usa as dependências estabelecidas pelo gráfico de computação dos operandos e operações para determinar a ordem em que as operações são executadas.
As operações com que a NNAPI é compatível estão resumidas na tabela abaixo:
Problema conhecido no nível 28 da API: ao transmitir
tensores
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM para a
operação
ANEURALNETWORKS_PAD, que está disponível no Android 9 (nível 28 da API) e versões mais recentes, a
saída da NNAPI pode não corresponder à saída de frameworks de aprendizado de máquina de
nível mais alto, como o
TensorFlow Lite. Passe apenas ANEURALNETWORKS_TENSOR_FLOAT32.
O problema foi resolvido no Android 10 (nível 29 da API) e versões mais recentes.
Criar modelos
No exemplo a seguir, criamos o modelo de duas operações encontrado na Figura 3.
Para criar um modelo, siga estas etapas:
Chame a função
ANeuralNetworksModel_create()para definir um modelo vazio.ANeuralNetworksModel* model = NULL; ANeuralNetworksModel_create(&model);
Adicione os operandos ao seu modelo chamando
ANeuralNetworks_addOperand(). Os tipos de dados são definidos usando a estrutura de dadosANeuralNetworksOperandType.// In our example, all our tensors are matrices of dimension [3][4] ANeuralNetworksOperandType tensor3x4Type; tensor3x4Type.type = ANEURALNETWORKS_TENSOR_FLOAT32; tensor3x4Type.scale = 0.f; // These fields are used for quantized tensors tensor3x4Type.zeroPoint = 0; // These fields are used for quantized tensors tensor3x4Type.dimensionCount = 2; uint32_t dims[2] = {3, 4}; tensor3x4Type.dimensions = dims;
// We also specify operands that are activation function specifiers ANeuralNetworksOperandType activationType; activationType.type = ANEURALNETWORKS_INT32; activationType.scale = 0.f; activationType.zeroPoint = 0; activationType.dimensionCount = 0; activationType.dimensions = NULL;
// Now we add the seven operands, in the same order defined in the diagram ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 0 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 1 ANeuralNetworksModel_addOperand(model, &activationType); // operand 2 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 3 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 4 ANeuralNetworksModel_addOperand(model, &activationType); // operand 5 ANeuralNetworksModel_addOperand(model, &tensor3x4Type); // operand 6Para operandos que têm valores constantes, como pesos e vieses que seu app adquire de um processo de treinamento, use as funções
ANeuralNetworksModel_setOperandValue()eANeuralNetworksModel_setOperandValueFromMemory().No exemplo a seguir, definimos valores constantes do arquivo de dados de treinamento correspondente ao buffer de memória criado em Conceder acesso aos dados de treinamento.
// In our example, operands 1 and 3 are constant tensors whose values were // established during the training process const int sizeOfTensor = 3 * 4 * 4; // The formula for size calculation is dim0 * dim1 * elementSize ANeuralNetworksModel_setOperandValueFromMemory(model, 1, mem1, 0, sizeOfTensor); ANeuralNetworksModel_setOperandValueFromMemory(model, 3, mem1, sizeOfTensor, sizeOfTensor);
// We set the values of the activation operands, in our example operands 2 and 5 int32_t noneValue = ANEURALNETWORKS_FUSED_NONE; ANeuralNetworksModel_setOperandValue(model, 2, &noneValue, sizeof(noneValue)); ANeuralNetworksModel_setOperandValue(model, 5, &noneValue, sizeof(noneValue));Para cada operação no gráfico direcionado que você quer computar, adicione a operação ao seu modelo chamando a função
ANeuralNetworksModel_addOperation().Como parâmetros para essa chamada, seu app precisa fornecer:
- o tipo de operação;
- a contagem de valores de entrada;
- a matriz dos índices para operandos de entrada;
- a contagem de valores de saída;
- a matriz dos índices para operandos de saída.
Um operando não pode ser usado para entrada e saída da mesma operação.
// We have two operations in our example // The first consumes operands 1, 0, 2, and produces operand 4 uint32_t addInputIndexes[3] = {1, 0, 2}; uint32_t addOutputIndexes[1] = {4}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_ADD, 3, addInputIndexes, 1, addOutputIndexes);
// The second consumes operands 3, 4, 5, and produces operand 6 uint32_t multInputIndexes[3] = {3, 4, 5}; uint32_t multOutputIndexes[1] = {6}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_MUL, 3, multInputIndexes, 1, multOutputIndexes);Identifique quais operandos o modelo tratará como entradas e saídas chamando a função
ANeuralNetworksModel_identifyInputsAndOutputs().// Our model has one input (0) and one output (6) uint32_t modelInputIndexes[1] = {0}; uint32_t modelOutputIndexes[1] = {6}; ANeuralNetworksModel_identifyInputsAndOutputs(model, 1, modelInputIndexes, 1 modelOutputIndexes);
Opcionalmente, especifique se
ANEURALNETWORKS_TENSOR_FLOAT32pode ser calculado com precisão ou alcance tão baixos quanto o do formato de ponto flutuante de 16 bits IEEE 754 chamandoANeuralNetworksModel_relaxComputationFloat32toFloat16().Chame
ANeuralNetworksModel_finish()para finalizar a definição do seu modelo. Se não houver erros, essa função retornará um código de resultado deANEURALNETWORKS_NO_ERROR.ANeuralNetworksModel_finish(model);
Depois de criar um modelo, você pode compilá-lo e executar cada compilação quantas vezes quiser.
Fluxo de controle
Para incorporar o fluxo de controle em um modelo da NNAPI, faça o seguinte:
Construa os subgráficos de execução correspondentes (subgráficos
theneelsepara uma instruçãoIFe subgráficosconditionebodypara um loopWHILE) como modelosANeuralNetworksModel*independentes:ANeuralNetworksModel* thenModel = makeThenModel(); ANeuralNetworksModel* elseModel = makeElseModel();
Crie operandos que se refiram a esses modelos dentro do modelo que contém o fluxo de controle:
ANeuralNetworksOperandType modelType = { .type = ANEURALNETWORKS_MODEL, }; ANeuralNetworksModel_addOperand(model, &modelType); // kThenOperandIndex ANeuralNetworksModel_addOperand(model, &modelType); // kElseOperandIndex ANeuralNetworksModel_setOperandValueFromModel(model, kThenOperandIndex, &thenModel); ANeuralNetworksModel_setOperandValueFromModel(model, kElseOperandIndex, &elseModel);
Adicione a operação de fluxo de controle:
uint32_t inputs[] = {kConditionOperandIndex, kThenOperandIndex, kElseOperandIndex, kInput1, kInput2, kInput3}; uint32_t outputs[] = {kOutput1, kOutput2}; ANeuralNetworksModel_addOperation(model, ANEURALNETWORKS_IF, std::size(inputs), inputs, std::size(output), outputs);
Compilação
A etapa de compilação determina em quais processadores seu modelo será executado e solicita que os drivers correspondentes se preparem para a execução. Isso pode incluir a geração de código de máquina específico para os processadores em que seu modelo será executado.
Para compilar um modelo, siga estas etapas:
Chame a função
ANeuralNetworksCompilation_create()para criar uma nova instância de compilação.// Compile the model ANeuralNetworksCompilation* compilation; ANeuralNetworksCompilation_create(model, &compilation);
Você também pode usar a atribuição de dispositivos para escolher explicitamente em que dispositivos executar.
Se quiser, você poderá influenciar como o ambiente de execução afeta o uso da bateria e a velocidade de execução. É possível fazer isso chamando
ANeuralNetworksCompilation_setPreference().// Ask to optimize for low power consumption ANeuralNetworksCompilation_setPreference(compilation, ANEURALNETWORKS_PREFER_LOW_POWER);
As preferências que você pode especificar incluem:
ANEURALNETWORKS_PREFER_LOW_POWER: prefira realizar a execução de uma forma que minimize o consumo da bateria. Isso é útil para compilações que são executadas com frequência.ANEURALNETWORKS_PREFER_FAST_SINGLE_ANSWER: prefira retornar uma só resposta assim que possível, mesmo que isso cause mais consumo de energia. Esse é o padrão.ANEURALNETWORKS_PREFER_SUSTAINED_SPEED: prefira maximizar a capacidade de frames sucessivos, por exemplo, ao processar frames sucessivos originados da câmera.
Você também pode configurar o armazenamento em cache da compilação chamando
ANeuralNetworksCompilation_setCaching.// Set up compilation caching ANeuralNetworksCompilation_setCaching(compilation, cacheDir, token);
Use
getCodeCacheDir()para ocacheDir. Otokenespecificado precisa ser único para cada modelo no aplicativo.Finalize a definição de compilação chamando
ANeuralNetworksCompilation_finish(). Se não houver erros, essa função retornará um código de resultado deANEURALNETWORKS_NO_ERROR.ANeuralNetworksCompilation_finish(compilation);
Descoberta e atribuição de dispositivos
Em dispositivos Android versão 10 (API nível 29) e mais recentes, a NNAPI oferece funções que permitem que bibliotecas e apps do framework de machine learning recebam informações sobre os dispositivos disponíveis e especifiquem os dispositivos a serem usados para a execução. A disponibilização de informações sobre os dispositivos disponíveis permite que os apps saibam a versão exata dos drivers encontrados em um dispositivo para evitar incompatibilidades conhecidas. Ao conceder aos apps a capacidade de especificar quais dispositivos precisam executar seções diferentes de um modelo, os apps podem ser otimizados para o dispositivo Android em que são implantados.
Descoberta de dispositivos
Use
ANeuralNetworks_getDeviceCount
para ver o número de dispositivos disponíveis. Use ANeuralNetworks_getDevice para cada dispositivo para configurar uma instância ANeuralNetworksDevice para um referência ao dispositivo em questão.
Depois de extrair uma referência de dispositivo, você pode descobrir mais informações sobre ele usando estas funções:
ANeuralNetworksDevice_getFeatureLevelANeuralNetworksDevice_getNameANeuralNetworksDevice_getTypeANeuralNetworksDevice_getVersion
Atribuição de dispositivos
Use
ANeuralNetworksModel_getSupportedOperationsForDevices
para descobrir quais operações de um modelo podem ser executadas em dispositivos específicos.
Para controlar quais aceleradores serão usados para a execução, chame
ANeuralNetworksCompilation_createForDevices
em vez de ANeuralNetworksCompilation_create.
Use o objeto ANeuralNetworksCompilation resultante normalmente.
A função retornará um erro se o modelo indicado tiver operações incompatíveis com os dispositivos selecionados.
Se vários dispositivos forem especificados, o ambiente de execução será responsável pela distribuição do trabalho entre os dispositivos.
Assim como em outros dispositivos, a implementação de CPU com NNAPI é representada por um ANeuralNetworksDevice com o nome nnapi-reference e o tipo ANEURALNETWORKS_DEVICE_TYPE_CPU. Ao chamar
ANeuralNetworksCompilation_createForDevices, a implementação da CPU não é
usada para processar casos de falha para a compilação e a execução de modelos.
É responsabilidade do app particionar um modelo em submodelos que
possam ser executados nos dispositivos especificados. Os apps que não precisam realizar particionamentos manuais
devem continuar chamando o
ANeuralNetworksCompilation_create
mais simples para usar todos os dispositivos disponíveis (inclusive a CPU) para acelerar o modelo. Se o modelo não oferecer suporte total aos dispositivos especificados
usando ANeuralNetworksCompilation_createForDevices,
ANEURALNETWORKS_BAD_DATA
será retornado.
Particionamento de modelos
Quando vários dispositivos estiverem disponíveis para o modelo, o ambiente de execução da NNAPI
distribuirá o trabalho entre os dispositivos. Por exemplo, se mais de um dispositivo foi
fornecido para ANeuralNetworksCompilation_createForDevices, todos os especificados
serão considerados ao alocar o trabalho. Se o dispositivo da CPU não estiver na lista, a execução da CPU será desativada. Ao usar ANeuralNetworksCompilation_create, todos os dispositivos disponíveis serão considerados, incluindo a CPU.
A distribuição é realizada selecionando da lista de dispositivos disponíveis, para cada
operação no modelo, o dispositivo que oferece suporte à operação e que declara o melhor desempenho, ou seja, o menor tempo de execução ou o
menor consumo de energia, dependendo da preferência de execução especificada
pelo cliente. Esse algoritmo de particionamento não considera possíveis
ineficiências causadas pelo pedido de veiculação entre os diferentes processadores. Portanto, ao
especificar vários processadores (explicitamente usando
ANeuralNetworksCompilation_createForDevices ou implicitamente usando
ANeuralNetworksCompilation_create), é importante definir o perfil do aplicativo
resultante.
Para entender como seu modelo foi particionado pela NNAPI, verifique se há uma mensagem
nos registros do Android (no nível INFO com a tag ExecutionPlan):
ModelBuilder::findBestDeviceForEachOperation(op-name): device-index
op-name é o nome descritivo da operação no gráfico, e device-index é o índice do dispositivo candidato na lista de dispositivos.
Essa lista é a entrada fornecida para ANeuralNetworksCompilation_createForDevices ou, se estiver usando ANeuralNetworksCompilation_createForDevices, a lista de dispositivos retornados ao iterar em todos os dispositivos usando ANeuralNetworks_getDeviceCount e ANeuralNetworks_getDevice.
A mensagem (no nível INFO com a tag ExecutionPlan):
ModelBuilder::partitionTheWork: only one best device: device-name
Essa mensagem indica que o gráfico inteiro foi acelerado no dispositivo device-name.
Execução
A etapa de execução aplica o modelo a um conjunto de entradas e armazena as saídas de computação em um ou mais buffers de usuário ou espaços de memória que seu app tenha alocado.
Para executar um modelo compilado, siga estas etapas:
Chame a função
ANeuralNetworksExecution_create()para criar uma nova instância de execução.// Run the compiled model against a set of inputs ANeuralNetworksExecution* run1 = NULL; ANeuralNetworksExecution_create(compilation, &run1);
Especifique onde seu app lê os valores de entrada para a computação. Seu app pode ler valores de entrada de um buffer de usuário ou de um espaço de memória alocado chamando
ANeuralNetworksExecution_setInput()ouANeuralNetworksExecution_setInputFromMemory(), respectivamente.// Set the single input to our sample model. Since it is small, we won't use a memory buffer float32 myInput[3][4] = { ...the data... }; ANeuralNetworksExecution_setInput(run1, 0, NULL, myInput, sizeof(myInput));
Especifique onde seu app grava os valores de saída. Seu app pode gravar valores de saída em um buffer de usuário ou em um espaço de memória alocado chamando
ANeuralNetworksExecution_setOutput()ouANeuralNetworksExecution_setOutputFromMemory()respectivamente.// Set the output float32 myOutput[3][4]; ANeuralNetworksExecution_setOutput(run1, 0, NULL, myOutput, sizeof(myOutput));
Programe o início da execução chamando a função
ANeuralNetworksExecution_startCompute(). Se não houver erros, essa função retornará um código de resultado deANEURALNETWORKS_NO_ERROR.// Starts the work. The work proceeds asynchronously ANeuralNetworksEvent* run1_end = NULL; ANeuralNetworksExecution_startCompute(run1, &run1_end);
Chame a função
ANeuralNetworksEvent_wait()para aguardar a execução ser concluída. Se a execução ocorrer corretamente, essa função retornará um código de resultado deANEURALNETWORKS_NO_ERROR. É possível aguardar em uma linha de execução diferente daquela que inicia a execução.// For our example, we have no other work to do and will just wait for the completion ANeuralNetworksEvent_wait(run1_end); ANeuralNetworksEvent_free(run1_end); ANeuralNetworksExecution_free(run1);
Opcionalmente, aplique um conjunto diferente de entradas ao modelo compilado usando a mesma instância de compilação para criar uma instância de
ANeuralNetworksExecution.// Apply the compiled model to a different set of inputs ANeuralNetworksExecution* run2; ANeuralNetworksExecution_create(compilation, &run2); ANeuralNetworksExecution_setInput(run2, ...); ANeuralNetworksExecution_setOutput(run2, ...); ANeuralNetworksEvent* run2_end = NULL; ANeuralNetworksExecution_startCompute(run2, &run2_end); ANeuralNetworksEvent_wait(run2_end); ANeuralNetworksEvent_free(run2_end); ANeuralNetworksExecution_free(run2);
Execução síncrona
A execução assíncrona demora para gerar e sincronizar linhas de execução. Além disso, a latência pode ser extremamente variável, com os atrasos mais longos atingindo até 500 microssegundos entre o momento em que uma linha de execução é notificada ou iniciada e o momento em que ela é vinculada a um núcleo da CPU.
Para melhorar a latência, você pode direcionar um aplicativo para fazer uma chamada de inferência
síncrona para o ambiente de execução. Essa chamada só retornará depois que uma inferência for
concluída, não quando iniciada. Em vez
de chamar
ANeuralNetworksExecution_startCompute
para uma chamada de inferência assíncrona ao ambiente de execução, o app chama
ANeuralNetworksExecution_compute
para fazer uma chamada síncrona ao ambiente de execução. Uma chamada para
ANeuralNetworksExecution_compute não usa um ANeuralNetworksEvent e
não é pareada com uma chamada para ANeuralNetworksEvent_wait.
Execuções em burst
Em dispositivos Android 10 (nível 29 da API) e mais recentes, a NNAPI oferece suporte a execuções
em burst pelo
objeto
ANeuralNetworksBurst. As execuções em burst são uma sequência de execuções da mesma compilação que ocorrem em uma sucessão rápida, como aquelas que ocorrem em frames de uma captura de câmera ou amostras de áudio sucessivas. O uso de objetos ANeuralNetworksBurst pode
resultar em execuções mais rápidas, porque eles indicam aos aceleradores que os recursos podem
ser reutilizados entre as execuções e que os aceleradores devem permanecer em um
estado de alto desempenho durante o burst.
ANeuralNetworksBurst introduz apenas uma pequena mudança no caminho de execução
normal. Um objeto burst é criado usando
ANeuralNetworksBurst_create,
conforme mostrado no snippet de código a seguir:
// Create burst object to be reused across a sequence of executions ANeuralNetworksBurst* burst = NULL; ANeuralNetworksBurst_create(compilation, &burst);
As execuções burst são síncronas. Entretanto, em vez de usar
ANeuralNetworksExecution_compute
para realizar a inferência, pareie os diversos
objetos ANeuralNetworksExecution
com a mesma ANeuralNetworksBurst em chamadas para a função
ANeuralNetworksExecution_burstCompute.
// Create and configure first execution object // ... // Execute using the burst object ANeuralNetworksExecution_burstCompute(execution1, burst); // Use results of first execution and free the execution object // ... // Create and configure second execution object // ... // Execute using the same burst object ANeuralNetworksExecution_burstCompute(execution2, burst); // Use results of second execution and free the execution object // ...
Libere o objeto ANeuralNetworksBurst com
ANeuralNetworksBurst_free
quando ele não for mais necessário.
// Cleanup ANeuralNetworksBurst_free(burst);
Execução delimitada e filas de comando assíncronas
No Android 11 e versões mais recentes, a NNAPI oferece suporte a outra maneira de programar
a execução assíncrona usando o
método
ANeuralNetworksExecution_startComputeWithDependencies(). Quando você usa esse método, a execução aguarda todos os eventos
dependentes serem sinalizados antes do início da avaliação. Quando a execução for
concluída e as saídas estiverem prontas para serem consumidas, o evento retornado será
sinalizado.
Dependendo de quais dispositivos processam a execução, o evento pode ser apoiado por um
limite de sincronização. Você
precisa chamar
ANeuralNetworksEvent_wait()
para aguardar o evento e recuperar os recursos usados pela execução. É
possível importar limites de sincronização de um objeto de evento usando
ANeuralNetworksEvent_createFromSyncFenceFd()
e exportar limites de sincronização de um objeto de evento usando
ANeuralNetworksEvent_getSyncFenceFd().
Saídas dimensionadas de forma dinâmica
Para oferecer suporte a modelos em que o tamanho da saída depende dos dados
da entrada, ou seja, o tamanho não pode ser determinado durente a execução
do modelo, use
ANeuralNetworksExecution_getOutputOperandRank
e
ANeuralNetworksExecution_getOutputOperandDimensions.
O exemplo de código abaixo mostra como fazer isso.
// Get the rank of the output uint32_t myOutputRank = 0; ANeuralNetworksExecution_getOutputOperandRank(run1, 0, &myOutputRank); // Get the dimensions of the output std::vector<uint32_t> myOutputDimensions(myOutputRank); ANeuralNetworksExecution_getOutputOperandDimensions(run1, 0, myOutputDimensions.data());
Limpeza
A etapa de limpeza realiza a liberação de recursos internos usados para sua computação.
// Cleanup ANeuralNetworksCompilation_free(compilation); ANeuralNetworksModel_free(model); ANeuralNetworksMemory_free(mem1);
Gerenciamento de erros e substituição de CPU
Se ocorrer um erro durante o particionamento, ou se um driver não compilar um modelo (ou parte dele) ou não executar um modelo compilado (ou parte dele), a NNAPI poderá usar a própria implementação de CPU das operações.
Se o cliente NNAPI contiver versões otimizadas da operação (por exemplo, TFLite), poderá ser vantajoso desativar o substituto da CPU e processar as falhas com a implementação de operação otimizada do cliente.
No Android 10, se a compilação for realizada usando ANeuralNetworksCompilation_createForDevices, o substituto da CPU será desativado.
No Android P, a execução de NNAPI será substituída pela CPU se a execução no driver falhar.
Isso também ocorre no Android 10 quando ANeuralNetworksCompilation_create é usado em vez de ANeuralNetworksCompilation_createForDevices.
A primeira execução é substituída pela partição única e se isso ainda falhar, ela repetirá todo o modelo na CPU.
Se o particionamento ou a compilação falhar, todo o modelo será testado na CPU.
Há casos em que algumas operações não oferecem suporte à CPU e, nessas situações, a compilação e a execução falham em vez de serem substituídas.
Mesmo após a desativação do substituto de CPU, ainda pode haver operações no modelo que estão programadas na CPU. Se a CPU estiver na lista de processadores fornecidos
a ANeuralNetworksCompilation_createForDevices e se for o único
processador com suporte a essas operações ou for o processador com indicação de melhor
desempenho para essas operações, ela será escolhida como executor principal
(não substituto).
Para garantir que não haja execução da CPU, use ANeuralNetworksCompilation_createForDevices ao excluir nnapi-reference da lista de dispositivos.
No Android P e mais recentes, é possível desativar a substituição durante a execução nos
builds de depuração, definindo a propriedade debug.nn.partition como 2.
Domínios de memória
No Android 11 e versões mais recentes, a NNAPI oferece suporte a domínios de memória que oferecem interfaces para alocar memórias opacas. Isso permite que os aplicativos transmitam memórias nativas do dispositivo entre execuções, para que a NNAPI não copie ou transforme dados desnecessariamente quando realizar execuções consecutivas no mesmo driver.
O recurso de domínio de memória é destinado a tensores que são, na maioria das vezes, internos ao driver e que não precisam de acesso frequente no lado do cliente. Alguns exemplos desses tensores incluem os tensores de estado em modelos sequenciais. Para tensores que precisam de acesso frequente à CPU no lado do cliente, use pools de memória compartilhada.
Para alocar uma memória opaca, execute as seguintes etapas:
Chame a função
ANeuralNetworksMemoryDesc_create()para criar um novo descritor de memória:// Create a memory descriptor ANeuralNetworksMemoryDesc* desc; ANeuralNetworksMemoryDesc_create(&desc);
Especifique todos os papéis pretendidos de entrada e saída chamando
ANeuralNetworksMemoryDesc_addInputRole()eANeuralNetworksMemoryDesc_addOutputRole().// Specify that the memory may be used as the first input and the first output // of the compilation ANeuralNetworksMemoryDesc_addInputRole(desc, compilation, 0, 1.0f); ANeuralNetworksMemoryDesc_addOutputRole(desc, compilation, 0, 1.0f);
Opcionalmente, especifique as dimensões da memória chamando
ANeuralNetworksMemoryDesc_setDimensions().// Specify the memory dimensions uint32_t dims[] = {3, 4}; ANeuralNetworksMemoryDesc_setDimensions(desc, 2, dims);
Finalize a definição do descritor chamando
ANeuralNetworksMemoryDesc_finish().ANeuralNetworksMemoryDesc_finish(desc);
Aloque quantas memórias forem necessárias transmitindo o descritor para
ANeuralNetworksMemory_createFromDesc().// Allocate two opaque memories with the descriptor ANeuralNetworksMemory* opaqueMem; ANeuralNetworksMemory_createFromDesc(desc, &opaqueMem);
Libere o descritor de memória quando você não precisar mais dele.
ANeuralNetworksMemoryDesc_free(desc);
O cliente só pode usar o objeto ANeuralNetworksMemory criado com
ANeuralNetworksExecution_setInputFromMemory() ou
ANeuralNetworksExecution_setOutputFromMemory() de acordo com os papéis
especificados no objeto ANeuralNetworksMemoryDesc. Os argumentos de compensação e comprimento
precisam ser definidos como 0, indicando que toda a memória é usada. O cliente
também pode definir ou extrair explicitamente o conteúdo da memória usando
ANeuralNetworksMemory_copy().
Você pode criar memórias opacas com papéis de dimensões ou classificações não especificadas.
Nesse caso, a criação da memória pode falhar com o
status ANEURALNETWORKS_OP_FAILED se não for compatível com o
driver. É recomendado que o cliente implemente a lógica de substituição, alocando um
buffer grande o suficiente com Ashmem ou o modo BLOB AHardwareBuffer.
Quando a NNAPI não precisar mais acessar o objeto de memória opaca, libere a
instância ANeuralNetworksMemory correspondente:
ANeuralNetworksMemory_free(opaqueMem);
Avaliar o desempenho
Para avaliar o desempenho do seu aplicativo, você pode medir o tempo de execução ou criar um perfil.
Tempo de execução
Quando você quiser determinar o tempo total de execução, use
a API de execução síncrona e meça o tempo utilizado pela chamada. Quando quiser
determinar o tempo de execução total por um nível inferior da pilha
de software, você pode usar
ANeuralNetworksExecution_setMeasureTiming
e
ANeuralNetworksExecution_getDuration
para determinar:
- o tempo de execução em um acelerador (não no driver, que é executado no processador host);
- o tempo de execução no driver, incluindo o tempo no acelerador.
O tempo de execução no driver exclui sobrecargas, como a do próprio ambiente de execução e da IPC, necessária para que o ambiente de execução se comunique com o driver.
Essas APIs medem a duração entre o trabalho enviado e os eventos concluídos, não do tempo que um driver ou acelerador dedica à realização da inferência, possivelmente interrompido pela alternância de contexto.
Por exemplo, se a inferência 1 começar, o driver interromperá o trabalho para realizar a inferência 2 e, em seguida, vai retomar e concluir a inferência 1. O tempo de execução da inferência 1 incluirá o momento em que o trabalho foi interrompido para a execução da inferência 2.
Essas informações de tempo podem ser úteis para a implantação de produção de um aplicativo, para coletar dados de telemetria para uso off-line. Você pode usar os dados de tempo para modificar o app, melhorando o desempenho.
Ao usar essa funcionalidade, lembre-se de que:
- a coleta de informações de tempo pode afetar o desempenho;
- somente um driver é capaz de computar o tempo gasto nele mesmo ou no acelerador, exceto o tempo gasto no ambiente de execução da NNAPI e na IPC;
- você pode usar essas APIs somente com uma
ANeuralNetworksExecutionque foi criada comANeuralNetworksCompilation_createForDevicescomnumDevices = 1; - nenhum driver é necessário para relatar informações de tempo.
Criar perfil do aplicativo com o Android Systrace
No Android 10 e mais recentes, a NNAPI gera automaticamente eventos do systrace que podem ser usados para criar o perfil do seu aplicativo.
O código-fonte da NNAPI vem com um utilitário parse_systrace para processar os eventos systrace gerados pelo aplicativo e gerar uma visualização de tabela mostrando o tempo gasto nas diferentes fases do ciclo de vida do modelo (instanciação, preparação, execução de compilação e encerramento) e camadas diferentes dos aplicativos. Estas são as camadas em que seu aplicativo está dividido:
Application: o código principal do aplicativoRuntime: o ambiente de execução da NNAPIIPC: a comunicação entre processos entre o ambiente de execução da NNAPI e o código do driverDriver: o processo do driver do acelerador
Gerar os dados da análise do perfil
Supondo que você verificou a árvore de origem AOSP em $ANDROID_BUILD_TOP e, usando o exemplo de classificação de imagem TFLite (em inglês) como aplicativo de destino, você pode gerar os dados do perfil da NNAPI com as seguintes etapas:
- Inicie o Android Systrace com o seguinte comando:
$ANDROID_BUILD_TOP/external/chromium-trace/systrace.py -o trace.html -a org.tensorflow.lite.examples.classification nnapi hal freq sched idle load binder_driver
O parâmetro -o trace.html indica que os traces serão gravados no trace.html. Ao caracterizar o perfil do próprio aplicativo, você precisará
substituir org.tensorflow.lite.examples.classification pelo nome do processo
especificado no manifesto do seu app.
Isso manterá um console do shell ocupado. Não execute o comando em
segundo plano, já que ele está aguardando interativamente o encerramento de um enter.
- Depois que o coletor do systrace for iniciado, abra o app e execute o teste comparativo.
Neste caso, você pode iniciar o aplicativo Image Classification no Android Studio ou diretamente na IU do smartphone de teste, caso o aplicativo já esteja instalado. Para gerar alguns dados da NNAPI, é necessário configurar o app para usá-la. Selecione-a como dispositivo de destino na caixa de diálogo de configuração do app.
Quando o teste for concluído, encerre o systrace pressionando
enterno terminal do console ativo desde a etapa 1.Executar o utilitário
systrace_parsergera estatísticas cumulativas:
$ANDROID_BUILD_TOP/frameworks/ml/nn/tools/systrace_parser/parse_systrace.py --total-times trace.html
O analisador aceita os seguintes parâmetros:
- --total-times: mostra o tempo total gasto em uma camada, incluindo o tempo
gasto aguardando execução em uma chamada a uma camada
- --print-detail: mostra todos os eventos que foram coletados do systrace
- --per-execution: mostra apenas a execução e as subfases
(conforme os tempos de execução) em vez das estatísticas para todas as fases
- --json: produz a saída no formato JSON
Veja abaixo um exemplo da saída:
===========================================================================================================================================
NNAPI timing summary (total time, ms wall-clock) Execution
----------------------------------------------------
Initialization Preparation Compilation I/O Compute Results Ex. total Termination Total
-------------- ----------- ----------- ----------- ------------ ----------- ----------- ----------- ----------
Application n/a 19.06 1789.25 n/a n/a 6.70 21.37 n/a 1831.17*
Runtime - 18.60 1787.48 2.93 11.37 0.12 14.42 1.32 1821.81
IPC 1.77 - 1781.36 0.02 8.86 - 8.88 - 1792.01
Driver 1.04 - 1779.21 n/a n/a n/a 7.70 - 1787.95
Total 1.77* 19.06* 1789.25* 2.93* 11.74* 6.70* 21.37* 1.32* 1831.17*
===========================================================================================================================================
* This total ignores missing (n/a) values and thus is not necessarily consistent with the rest of the numbers
O analisador poderá falhar se os eventos coletados não representarem um rastro de aplicativo completo. Em particular, ele poderá falhar se os eventos do systrace gerados para marcar o final de uma seção estiverem presentes no trace sem um evento de início de seção associado. Isso geralmente acontecerá se alguns eventos de uma sessão anterior de criação de perfil estiverem sendo gerados quando você iniciar o coletor do systrace. Nesse caso, seria necessário executar a criação de perfil novamente.
Adicionar estatísticas do código do aplicativo à saída systrace_parser
O aplicativo parse_systrace tem como base a funcionalidade integrada do Android Systrace. É possível adicionar rastros para operações específicas no seu aplicativo usando a API do systrace (para Java, para aplicativos nativos) com nomes de eventos personalizados.
Para associar seus eventos personalizados a fases do ciclo de vida do aplicativo, inclua o nome do evento com uma das seguintes strings:
[NN_LA_PI]: evento no nível do aplicativo para inicialização[NN_LA_PP]: evento no nível do aplicativo para preparação[NN_LA_PC]: evento no nível do aplicativo para compilação[NN_LA_PE]: evento no nível do aplicativo para execução
Veja um exemplo de como modificar o código de exemplo de classificação de imagem TFLite adicionando uma seção runInferenceModel para a fase Execution e a camada Application contendo outras seções preprocessBitmap que não serão consideradas em traces da NNAPI. A seção runInferenceModel será parte dos eventos do systrace processados pelo analisador de sintaxe da NNAPI:
Kotlin
/** Runs inference and returns the classification results. */ fun recognizeImage(bitmap: Bitmap): List{ // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap") convertBitmapToByteBuffer(bitmap) Trace.endSection() // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel") long startTime = SystemClock.uptimeMillis() runInference() long endTime = SystemClock.uptimeMillis() Trace.endSection() ... return recognitions }
Java
/** Runs inference and returns the classification results. */ public ListrecognizeImage(final Bitmap bitmap) { // This section won’t appear in the NNAPI systrace analysis Trace.beginSection("preprocessBitmap"); convertBitmapToByteBuffer(bitmap); Trace.endSection(); // Run the inference call. // Add this method in to NNAPI systrace analysis. Trace.beginSection("[NN_LA_PE]runInferenceModel"); long startTime = SystemClock.uptimeMillis(); runInference(); long endTime = SystemClock.uptimeMillis(); Trace.endSection(); ... Trace.endSection(); return recognitions; }
Qualidade de serviço
No Android 11 e versões mais recentes, a NNAPI oferece uma melhor qualidade do serviço (QoS) ao permitir que um aplicativo indique as prioridades relativas dos modelos, o tempo máximo necessário para preparar determinado modelo e a quantidade máxima de tempo esperado para concluir determinado cálculo. O Android 11 também introduz outros códigos de resultado da NNAPI que permitem aos aplicativos entender falhas, como prazos de execução perdidos.
Definir a prioridade de uma carga de trabalho
Para definir a prioridade de uma carga de trabalho da NNAPI, chame
ANeuralNetworksCompilation_setPriority()
antes de chamar ANeuralNetworksCompilation_finish().
Estabelecer prazos
Os aplicativos podem estabelecer prazos para a compilação e a inferência de modelo.
- Para definir o tempo limite de compilação, chame
ANeuralNetworksCompilation_setTimeout()antes de chamarANeuralNetworksCompilation_finish(). - Para definir o tempo limite de inferência, chame
ANeuralNetworksExecution_setTimeout()antes de iniciar a compilação.
Mais informações sobre operandos
A seção a seguir aborda temas avançados sobre o uso de operandos.
Tensores quantizados
Um tensor quantizado é uma forma compacta para representar uma matriz de dimensão n de valores de ponto flutuante.
A NNAPI oferece suporte a tensores quantizados assimétricos de 8 bits. Para esses tensores, o valor de cada célula é representado por um número inteiro de 8 bits. Associados ao tensor estão uma escala e um valor de ponto zero. Eles são usados para converter os inteiros de 8 bits nos valores de ponto flutuante que estão sendo representados.
A fórmula é a seguinte:
(cellValue - zeroPoint) * scale
Onde o valor zeroPoint é um número inteiro de 32 bits e a escala é um valor de ponto flutuante de 32 bits.
Em comparação com os tensores de valores de ponto flutuante de 32 bits, os tensores quantizados de 8 bits têm duas vantagens:
- Seu app será menor, já que os pesos treinados ocuparão um quarto do tamanho dos tensores de 32 bits.
- Com frequência, as computações podem ser executadas com mais rapidez. Isso se deve à menor quantidade de dados que precisa ser buscada da memória e à eficiência dos processadores, como DSPs, no cálculo de inteiros.
Embora seja possível converter um modelo de ponto flutuante em um quantizado, nossa experiência mostrou que é possível alcançar resultados melhores ao treinar um modelo quantizado diretamente. Na prática, a rede neural aprende a compensar pelo aumento de granularidade de cada valor. Para cada tensor quantizado, os valores de escala e zeroPoint são determinados durante o processo de treinamento.
Na NNAPI, defina tipos de tensores quantizados configurando o tipo de campo da estrutura de dados de
ANeuralNetworksOperandType
como
ANEURALNETWORKS_TENSOR_QUANT8_ASYMM.
Especifique também o valor de escala e zeroPoint do tensor nessa estrutura de dados.
Além dos tensores quantizados assimétricos de 8 bits, a NNAPI é compatível com:
ANEURALNETWORKS_TENSOR_QUANT8_SYMM_PER_CHANNEL, que pode ser usado para representar pesos em operaçõesCONV/DEPTHWISE_CONV/TRANSPOSED_CONV.ANEURALNETWORKS_TENSOR_QUANT16_ASYMM, que você pode usar para o estado interno deQUANTIZED_16BIT_LSTM.ANEURALNETWORKS_TENSOR_QUANT8_SYMM, que pode ser uma entrada paraANEURALNETWORKS_DEQUANTIZE.
Operandos opcionais
Algumas operações, como
ANEURALNETWORKS_LSH_PROJECTION,
usam operandos opcionais. Para indicar no modelo que o operando opcional é
omitido, chame a
função ANeuralNetworksModel_setOperandValue(),
transmitindo NULL para o buffer e 0 para o comprimento.
Se a decisão de incluir ou não o operando variar para cada
execução, indique que o operando foi omitido usando as funções
ANeuralNetworksExecution_setInput()
ou
ANeuralNetworksExecution_setOutput(),
transmitindo NULL para o buffer e 0 para o comprimento.
Tensores de classificação desconhecida
O Android 9 (nível 28 da API) introduziu operandos de modelo de dimensões desconhecidas, mas com classificação conhecida (número de dimensões). O Android 10 (nível da API 29) introduziu tensores de classificação desconhecida, como mostrado em ANeuralNetworksOperandType.
Comparativo de mercado da NNAPI
O comparativo de mercado da NNAPI está disponível no AOSP em platform/test/mlts/benchmark (app de comparativo de mercado) e platform/test/mlts/models (modelos e conjuntos de dados).
O comparativo de mercado avalia a latência e a precisão e compara os drivers com o mesmo trabalho realizado usando o TensorFlow Lite em execução na CPU, para os mesmos modelos e conjuntos de dados.
Para usar o comparativo de mercado, faça o seguinte:
Conecte um dispositivo Android de destino ao seu computador, abra uma janela do terminal e verifique se o dispositivo está acessível usando o adb.
Se mais de um dispositivo Android estiver conectado, exporte a variável de ambiente
ANDROID_SERIALdo dispositivo de destino.Navegue para o diretório original de nível superior do Android.
Execute os seguintes comandos:
lunch aosp_arm-userdebug # Or aosp_arm64-userdebug if available ./test/mlts/benchmark/build_and_run_benchmark.sh
No final de uma execução de comparativo de mercado, os resultados serão apresentados como uma página HTML transmitida para
xdg-open.
Registros NNAPI
A NNAPI gera informações de diagnóstico úteis nos registros do sistema. Para analisar os registros, use o recurso logcat.
Ative o registro da NNAPI detalhado para fases ou componentes específicos definindo a propriedade debug.nn.vlog (usando adb shell) como a seguinte lista de valores, separados por espaço, dois pontos ou vírgula:
model: modelismocompilation: geração do plano de execução e compilação do modeloexecution: execução do modelocpuexe: execução de operações usando a implementação da CPU da NNAPImanager: extensões NNAPI, interfaces disponíveis e informações relacionadas aos recursosallou1: todos os elementos acima
Por exemplo, para ativar a geração de registros detalhados completos, use o comando adb shell setprop debug.nn.vlog all. Para desativar o registro detalhado, use o comando adb shell setprop debug.nn.vlog '""'.
Depois de ativado, o registro detalhado gera entradas de registro no nível INFO com uma tag definida para o nome da fase ou do componente.
Ao lado das mensagens controladas debug.nn.vlog, os componentes da API NNAPI fornecem outras entradas de registro em vários níveis, cada uma usando uma tag de registro específica.
Para ver uma lista de componentes, pesquise a árvore de origem usando a seguinte expressão:
grep -R 'define LOG_TAG' | awk -F '"' '{print $2}' | sort -u | egrep -v "Sample|FileTag|test"
No momento, essa expressão retorna as seguintes tags:
- BurstBuilder
- Callbacks
- CompilationBuilder
- CpuExecutor
- ExecutionBuilder
- ExecutionBurstController
- ExecutionBurstServer
- ExecutionPlan
- FibonacciDriver
- GraphDump
- IndexedShapeWrapper
- IonWatcher
- Administrador
- Memória
- MemoryUtils
- MetaModel
- ModelArgumentInfo
- ModelBuilder
- NeuralNetworks
- OperationResolver
- Operações
- OperationsUtils
- PackageInfo
- TokenHasher
- TypeManager
- Utils
- ValidateHal
- VersionedInterfaces
Para controlar o nível de mensagens de registro mostradas por logcat, use a variável de ambiente ANDROID_LOG_TAGS.
Para mostrar o conjunto completo de mensagens de registro da NNAPI e desativar outros, configure ANDROID_LOG_TAGS como o seguinte:
BurstBuilder:V Callbacks:V CompilationBuilder:V CpuExecutor:V ExecutionBuilder:V ExecutionBurstController:V ExecutionBurstServer:V ExecutionPlan:V FibonacciDriver:V GraphDump:V IndexedShapeWrapper:V IonWatcher:V Manager:V MemoryUtils:V Memory:V MetaModel:V ModelArgumentInfo:V ModelBuilder:V NeuralNetworks:V OperationResolver:V OperationsUtils:V Operations:V PackageInfo:V TokenHasher:V TypeManager:V Utils:V ValidateHal:V VersionedInterfaces:V *:S.
Você pode definir ANDROID_LOG_TAGS usando o seguinte comando:
export ANDROID_LOG_TAGS=$(grep -R 'define LOG_TAG' | awk -F '"' '{ print $2 ":V" }' | sort -u | egrep -v "Sample|FileTag|test" | xargs echo -n; echo ' *:S')
Esse é apenas um filtro que se aplica a logcat. Você ainda precisa
definir a propriedade debug.nn.vlog como all para gerar informações de registro detalhadas.