
在协程中,与仅返回单个值的挂起函数相反,数据流可按顺序发出多个值。例如,您可以使用数据流从数据库接收实时更新。
数据流以协程为基础构建,可提供多个值。从概念上来讲,数据流是可通过异步方式进行计算处理的一组数据序列。所发出值的类型必须相同。例如,Flow<Int> 是发出整数值的数据流。
数据流与生成一组序列值的 Iterator 非常相似,但它使用挂起函数通过异步方式生成和使用值。这就是说,例如,数据流可安全地发出网络请求以生成下一个值,而不会阻塞主线程。
数据流包含三个实体:
- 提供方会生成添加到数据流中的数据。得益于协程,数据流还可以异步生成数据。
- (可选)中介可以修改发送到数据流的值,或修正数据流本身。
- 使用方则使用数据流中的值。
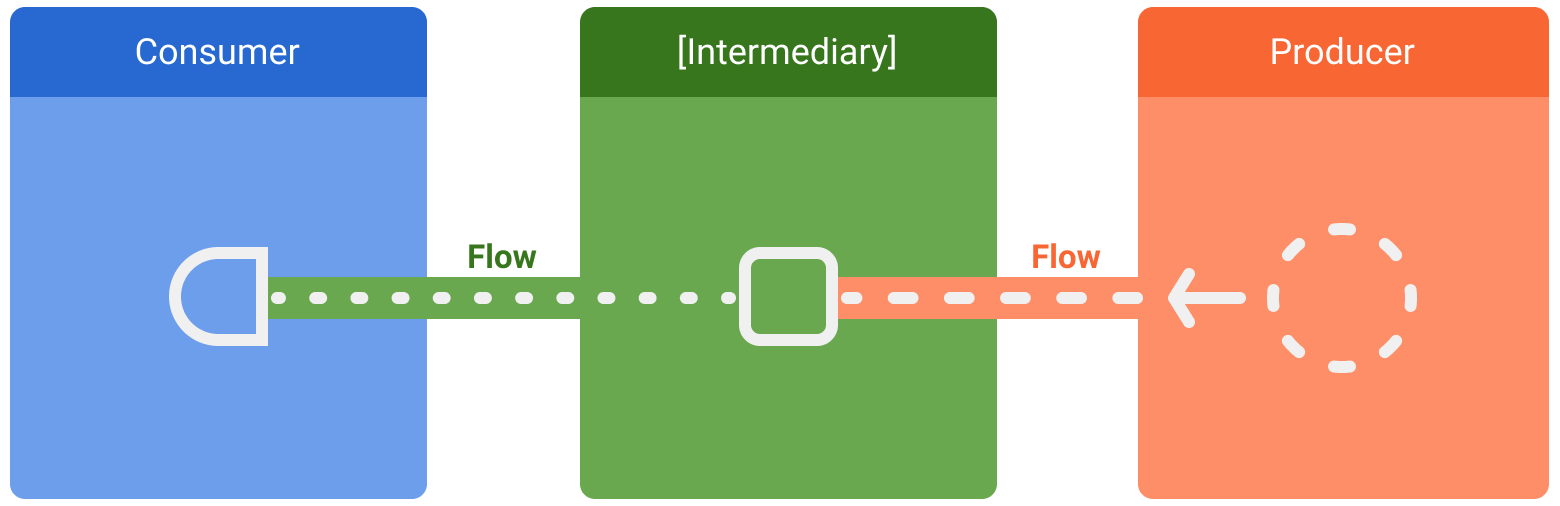
在 Android 中,代码库通常是界面数据的提供方,其将界面用作最终显示数据的使用方。而其他时候,界面层是用户输入事件的提供方,而层次结构中的其他层则是这些数据的使用方。提供方和使用方之间的层通常充当中介,负责修改数据流,以满足其后层的要求。
创建数据流
如需创建数据流,请使用数据流构建器 API。flow 构建器函数会创建一个新数据流,您可使用 emit 函数手动将新值发送到数据流中。
在以下示例中,数据源以固定时间间隔自动获取最新资讯。由于挂起函数不能返回多个连续值,数据源将创建并返回数据流来满足此要求。在这种情况下,数据源将会充当提供方。
class NewsRemoteDataSource(
private val newsApi: NewsApi,
private val refreshIntervalMs: Long = 5000
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
while(true) {
val latestNews = newsApi.fetchLatestNews()
emit(latestNews) // Emits the result of the request to the flow
delay(refreshIntervalMs) // Suspends the coroutine for some time
}
}
}
// Interface that provides a way to make network requests with suspend functions
interface NewsApi {
suspend fun fetchLatestNews(): List<ArticleHeadline>
}
flow 构建器在协程内执行。因此,它将受益于相同异步 API,但也存在一些限制:
- 数据流是有序的。当协程内的提供方调用挂起函数时,提供方会挂起,直到挂起函数返回。在此示例中,提供方会挂起,直到
fetchLatestNews网络请求完成为止。只有这样,请求结果才会发送到数据流中。 - 使用
flow构建器时,提供方不能提供来自不同CoroutineContext的emit值。因此,请勿通过创建新协程或使用withContext代码块,在不同CoroutineContext中调用emit。在这些情况下,您可使用其他数据流构建器,例如callbackFlow。
修改数据流
中介可以利用中间运算符在不使用值的情况下修改数据流。这些运算符都是函数,可在应用于数据流时,设置一系列暂不执行的链式运算,留待将来使用值时执行。如需详细了解中间运算符,请参阅数据流参考文档。
在以下示例中,存储库层将使用中间运算符 map 来转换将在 View 上显示的数据:
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData
) {
/**
* Returns the favorite latest news applying transformations on the flow.
* These operations are lazy and don't trigger the flow. They just transform
* the current value emitted by the flow at that point in time.
*/
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
// Intermediate operation to filter the list of favorite topics
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
// Intermediate operation to save the latest news in the cache
.onEach { news -> saveInCache(news) }
}
中间运算符可以接连应用,形成链式运算,在数据项被发送到数据流时延迟执行。请注意,仅将一个中间运算符应用于数据流不会启动数据流收集。
从数据流中进行收集
使用终端运算符可触发数据流开始监听值。如需获取数据流中的所有发出值,请使用 collect。如需详细了解终端运算符,请参阅官方数据流文档。
由于 collect 是挂起函数,因此需要在协程中执行。它接受 lambda 作为在每个新值上调用的参数。由于它是挂起函数,调用 collect 的协程可能会挂起,直到该数据流关闭。
继续之前的示例,下面将展示一个简单的 ViewModel 实现,展示其如何使用存储库层中的数据:
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
// Trigger the flow and consume its elements using collect
newsRepository.favoriteLatestNews.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
收集数据流会触发提供方刷新最新资讯,并以固定时间间隔发出网络请求。由于提供方始终通过 while(true) 循环保持活跃状态,因此,在清除 ViewModel 并取消 viewModelScope 数据流后,数据流将关闭。
数据流收集可能会由于以下原因而停止:
- 如上例所示,协程收集被取消。此操作也会让底层提供方停止活动。
- 提供方完成发出数据项。在这种情况下,数据流将关闭,调用
collect的协程则继续执行。
除非使用其他中间运算符指定流,否则数据流始终为冷数据并延迟执行。这意味着,每次在数据流上调用终端运算符时,都会执行提供方代码。在前面的示例中,拥有多个数据流收集器会导致数据源以不同的固定时间间隔多次获取最新资讯。如需在多个使用方同时收集时优化并共享数据流,请使用 shareIn 运算符。
数据流捕获异常
提供方的数据实现可来自第三方库。这意味着它可能会引发异常情况。如需处理这些异常,请使用 catch 中间运算符。
class LatestNewsViewModel(
private val newsRepository: NewsRepository
) : ViewModel() {
init {
viewModelScope.launch {
newsRepository.favoriteLatestNews
// Intermediate catch operator. If an exception is thrown,
// catch and update the UI
.catch { exception -> notifyError(exception) }
.collect { favoriteNews ->
// Update View with the latest favorite news
}
}
}
}
在之前的示例中,发生异常时,系统不会调用 collect lambda 参数,因为未收到新数据项。
catch 还可执行 emit 操作,向数据流发出数据项。示例存储库层可以改为对缓存值执行 emit 操作:
class NewsRepository(...) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> news.filter { userData.isFavoriteTopic(it) } }
.onEach { news -> saveInCache(news) }
// If an error happens, emit the last cached values
.catch { exception -> emit(lastCachedNews()) }
}
在此示例中,发生异常时,系统会调用 collect lambda 参数,因为已因异常而向数据流发出新数据项。
在不同 CoroutineContext 中执行
默认情况下,flow 构建器的提供方会通过从中收集的协程的 CoroutineContext 执行,并且如前所述,它无法从不同 CoroutineContext 对值执行 emit 操作。在某些情况下,可能不需要此行为。例如,在本主题所用示例中,存储库层不应在 viewModelScope 所使用的 Dispatchers.Main 上执行操作。
如需更改数据流的 CoroutineContext,请使用中间运算符 flowOn。flowOn 会更改上游数据流的 CoroutineContext,这表示会在 flowOn 之前(或之上)应用提供方以及任何中间运算符。下游数据流(晚于 flowOn 的中间运算符和使用方)不会受到影响,并会在 CoroutineContext 上执行以从数据流执行 collect 操作。如果有多个 flowOn 运算符,每个运算符都会更改当前位置的上游数据流。
class NewsRepository(
private val newsRemoteDataSource: NewsRemoteDataSource,
private val userData: UserData,
private val defaultDispatcher: CoroutineDispatcher
) {
val favoriteLatestNews: Flow<List<ArticleHeadline>> =
newsRemoteDataSource.latestNews
.map { news -> // Executes on the default dispatcher
news.filter { userData.isFavoriteTopic(it) }
}
.onEach { news -> // Executes on the default dispatcher
saveInCache(news)
}
// flowOn affects the upstream flow ↑
.flowOn(defaultDispatcher)
// the downstream flow ↓ is not affected
.catch { exception -> // Executes in the consumer's context
emit(lastCachedNews())
}
}
借助此代码,onEach 和 map 运算符使用 defaultDispatcher,其中catch 运算符和使用方在 viewModelScope 所使用的 Dispatchers.Main 上执行。
随着数据源层执行 I/O 操作,您应该使用针对 I/O 操作进行优化的调度程序:
class NewsRemoteDataSource(
...,
private val ioDispatcher: CoroutineDispatcher
) {
val latestNews: Flow<List<ArticleHeadline>> = flow {
// Executes on the IO dispatcher
...
}
.flowOn(ioDispatcher)
}
Jetpack 库中的数据流
许多 Jetpack 库已集成数据流,并且在 Android 第三方库中非常受欢迎。数据流非常适合实时数据更新和无限数据流。
您可以使用 Flow with Room 接收有关数据库更改的通知。在使用数据访问对象 (DAO) 时,返回 Flow 类型以获取实时更新。
@Dao
abstract class ExampleDao {
@Query("SELECT * FROM Example")
abstract fun getExamples(): Flow<List<Example>>
}
每当 Example 数据表发生更改时,系统都会发出包含数据库新数据项的新列表。
将基于回调的 API 转换为数据流
callbackFlow 是一个数据流构建器,允许您将基于回调的 API 转换为数据流。例如,Firebase Firestore Android API 会使用回调。
如需将这些 API 转换为数据流并监听 Firestore 数据库的更新,您可使用以下代码:
class FirestoreUserEventsDataSource(
private val firestore: FirebaseFirestore
) {
// Method to get user events from the Firestore database
fun getUserEvents(): Flow<UserEvents> = callbackFlow {
// Reference to use in Firestore
var eventsCollection: CollectionReference? = null
try {
eventsCollection = FirebaseFirestore.getInstance()
.collection("collection")
.document("app")
} catch (e: Throwable) {
// If Firebase cannot be initialized, close the stream of data
// flow consumers will stop collecting and the coroutine will resume
close(e)
}
// Registers callback to firestore, which will be called on new events
val subscription = eventsCollection?.addSnapshotListener { snapshot, _ ->
if (snapshot == null) { return@addSnapshotListener }
// Sends events to the flow! Consumers will get the new events
try {
offer(snapshot.getEvents())
} catch (e: Throwable) {
// Event couldn't be sent to the flow
}
}
// The callback inside awaitClose will be executed when the flow is
// either closed or cancelled.
// In this case, remove the callback from Firestore
awaitClose { subscription?.remove() }
}
}
与 flow 构建器不同,callbackFlow 允许通过 send 函数从不同 CoroutineContext 发出值,或者通过 trySend 函数在协程外发出值。
在协程内部,callbackFlow 会使用通道,它在概念上与阻塞队列非常相似。通道都有容量配置,限定了可缓冲元素数的上限。在 callbackFlow 中所创建通道的默认容量为 64 个元素。当您尝试向完整通道添加新元素时,send 会将数据提供方挂起,直到新元素有空间为止,而 offer 不会将相关元素添加到通道中,并会立即返回 false。